
Entwicklung eines Roboters in Python und MQL5 (Teil 2): Auswahl, Erstellung und Training von Modellen, Python Custom Tester

Kurze Zusammenfassung des vorherigen Artikels
Im vorangegangenen Artikel haben wir ein wenig über maschinelles Lernen gesprochen, eine Datenerweiterung durchgeführt, Merkmale für das zukünftige Modell entwickelt und die besten davon ausgewählt. Jetzt ist es an der Zeit, ein funktionierendes, maschinelles Lernmodell zu erstellen, das aus unseren Merkmalen lernt und (hoffentlich erfolgreich) handelt. Um das Modell zu evaluieren, werden wir einen nutzerdefinierten Python-Tester schreiben, der uns hilft, die Leistung des Modells und die Schönheit der Testgraphen zu bewerten. Um schönere Testgraphen und eine größere Modellstabilität zu erreichen, werden wir außerdem eine Reihe klassischer Funktionen des maschinellen Lernens entwickeln.
Unser oberstes Ziel ist es, ein funktionierendes und maximal profitables Modell für die Preisprognose und den Handel zu entwickeln. Der gesamte Code wird in Python geschrieben sein, mit Einbindung der MQL5-Bibliothek.
Python-Version und erforderliche Module
Ich habe bei meiner Arbeit Python in der Version 3.10.10 verwendet. Der unten angefügte Code enthält mehrere Funktionen für die Datenvorverarbeitung, die Merkmalsextraktion und das Training eines maschinellen Lernmodells. Dazu gehören insbesondere:
- Die Funktion zum Clustern von Merkmalen unter Verwendung des Gaussian Mixture Model (GMM) aus der Bibliothek sklearn
- Die Funktion zur Merkmalsextraktion mittels rekursiver Merkmaleliminierung mit Kreuzvalidierung (RFECV) aus der sklearn-Bibliothek
- Die Funktion für das Training des XGBoost-Klassifikators
Um den Code auszuführen, müssen Sie die folgenden Python-Module installieren:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
Sie können sie mit „pip“ - dem Python-Paketinstallationsprogramm - installieren. Hier ist ein Beispielbefehl zur Installation aller erforderlichen Module:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Los geht's!
Klassifizierung oder Regression?
Dies ist eine der ewigen Fragen bei der Datenprognose. Die Klassifizierung eignet sich besser für binäre Probleme, bei denen eine klare Ja-Nein-Antwort erforderlich ist. Es gibt auch eine Mehrklassen-Klassifizierung. Wir werden dies in künftigen Artikeln der Reihe erörtern, da es die Modelle erheblich stärken kann.
Die Regression eignet sich für eine spezifische Vorhersage eines bestimmten zukünftigen Wertes einer kontinuierlichen Reihe, einschließlich einer Preisreihe. Auf der einen Seite kann dies sehr viel bequemer sein, aber auf der anderen Seite ist die Kennzeichnung von Daten für die Regression, genau wie die Kennzeichnung selbst, ein schwieriges Thema, da wir kaum etwas anderes tun können, als den zukünftigen Preis des Vermögenswertes zu nehmen.
Mir persönlich gefällt die Klassifizierung besser, weil sie die Arbeit mit der Datenkennzeichnung vereinfacht. Viele Dinge können in Ja-Nein-Bedingungen getrieben werden, während die Multi-Klassen-Klassifizierung auf ganze komplexe manuelle Handelssysteme wie Smart Money angewendet werden kann. Sie haben den Code für die Datenbeschriftung bereits im vorigen Artikel dieser Reihe gesehen, und er ist eindeutig für die binäre Klassifizierung geeignet. Aus diesem Grund werden wir diese besondere Modellstruktur wählen.
Es bleibt die Entscheidung über das Modell selbst.
Auswahl eines Klassifikationsmodells
Wir müssen ein geeignetes Klassifizierungsmodell für unsere Daten mit den ausgewählten Merkmalen auswählen. Die Wahl hängt von der Anzahl der Merkmale, der Datentypen und der Anzahl der Klassen ab.
Beliebte Modelle sind die logistische Regression für die binäre Klassifizierung, der Zufallsforst für hohe Dimensionen und Nichtlinearitäten sowie neuronale Netze für komplexe Probleme. Die Auswahl ist riesig. Nachdem ich viele Dinge ausprobiert habe, bin ich zu dem Schluss gekommen, dass unter den heutigen Bedingungen das Boosten und darauf basierende Modelle am effektivsten sind.
Ich habe mich für das hochmoderne XGBoost-Modell entschieden - Boosting über Entscheidungsbäume mit Regularisierung, Parallelität und vielen Einstellungen. XGBoost gewinnt aufgrund seiner hohen Genauigkeit häufig Wettbewerbe in der Datenwissenschaft. Dies wurde zum Hauptkriterium für die Wahl eines Modells.
Generierung des Klassifikationsmodellcodes
Der Code verwendet das hochmoderne XGBoost-Modell - Gradient Boosting über Entscheidungsbäume. Eine Besonderheit von XGBoost ist die Verwendung von zweiten Ableitungen für die Optimierung, was die Effizienz und Genauigkeit im Vergleich zu anderen Modellen erhöht.
Die Funktion train_xgboost_classifier erhält die Daten und die Anzahl der Boosting-Runden. Es teilt die Daten in X-Features und y-Labels auf, erstellt das XGBClassifier-Modell mit Hyperparameter-Tuning und trainiert es mit der fit()-Methode.
Die Daten werden in Training/Test aufgeteilt, das Modell wird mit Hilfe der Funktion auf den Trainingsdaten trainiert. Das Modell wird an den verbleibenden Daten getestet, und die Genauigkeit der Vorhersagen wird berechnet.
Die Hauptvorteile von XGBoost sind die Kombination mehrerer Modelle zu einem hochpräzisen Modell unter Verwendung von Gradient Boosting und die Optimierung für zweite Ableitungen zur Steigerung der Effizienz.
Außerdem müssen wir die OpenMP-Laufzeitbibliothek installieren, um sie zu verwenden. Für Windows müssen Sie die Microsoft Visual C++ Redistributable herunterladen, die zu Ihrer Python-Version passt.
Kommen wir nun zum Code selbst. Zu Beginn des Codes importieren wir die xgboost-Bibliothek auf folgende Weise:
import xgboost as xgb Der Rest des Codes:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Trainieren wir das Modell und sehen wir, dass die Genauigkeit bei 52 % liegt.
Unsere Klassifizierungsgenauigkeit liegt jetzt bei 53 % der gewinnbringenden Kennzeichnungen. Bitte beachten Sie, dass wir hier von Prognosesituationen sprechen, wenn der Kurs sich um mehr als den Take-Profit (200 Pips) verändert hat und den Stop (100 Pips) nicht mit dem Heck berührt hat. In der Praxis werden wir einen Gewinnfaktor von etwa drei haben, was für einen profitablen Handel völlig ausreichend ist. Der nächste Schritt ist das Schreiben eines nutzerdefinierten Testers in Python, um die Rentabilität der Modelle in USD (nicht in Punkten) zu analysieren. Es ist wichtig zu verstehen, ob das Modell unter Berücksichtigung des Aufschlags Geld einbringt oder ob es die Mittel aufzehrt.
Implementierung von der Funktion des nutzerdefinierten Tester in Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
Der Code erstellt eine Funktion zum Testen des maschinellen Lernmodells anhand von Testdaten und zur Analyse seiner Rentabilität unter Berücksichtigung des Aufschlags (dies sollte Verluste bei Spreads und verschiedene Arten von Provisionen einschließen). Swaps werden nicht berücksichtigt, da sie dynamisch sind und von den Leitzinsen abhängen. Sie können berücksichtigt werden, indem man einfach ein paar Pips zum Aufschlag hinzufügt.
Die Funktion empfängt ein Modell, Testdaten, einen Aufschlag und einen Anfangssaldo. Der Handel wird anhand der Modellvorhersagen simuliert: Kaufen bei 1, Verkaufen bei 0. Wenn der Gewinn den Aufschlag übersteigt, wird die Position geschlossen und der Gewinn dem Saldo hinzugefügt.
Handel und Gewinn/Verlust jeder Position werden gespeichert. Die Saldenkurve wird erstellt. Der kumulierte Gesamtgewinn/-verlust wird berechnet.
Am Ende erhalten wir Testdaten und entfernen überflüssige Spalten. Das trainierte Modell xgb_clf wird mit dem gegebenen Aufschlag und Anfangssaldo getestet. Testen wir es!
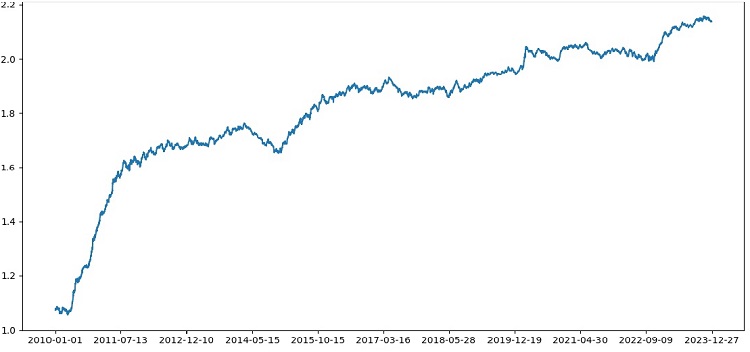
Der Tester arbeitet insgesamt erfolgreich, und wir sehen eine sehr schöne Saldenkurve. Dies ist ein nutzerdefinierter Tester zur Analyse des Gewinns eines Handelsmodells für maschinelles Lernen unter Berücksichtigung von Markup und Labels.
Implementierung der Kreuzvalidierung in das Modell
Um eine zuverlässigere Bewertung der Qualität eines maschinellen Lernmodells zu erhalten, müssen wir eine Kreuzvalidierung durchführen. Die Kreuzvalidierung ermöglicht die Bewertung eines Modells anhand mehrerer Datenuntergruppen, wodurch eine Überanpassung vermieden und eine objektivere Bewertung ermöglicht wird.
In unserem Fall verwenden wir eine 5-fache Kreuzvalidierung, um das XGBoost-Modell zu bewerten. Dazu verwenden wir die Funktion cross_val_score aus der Sklearn-Bibliothek.
Ändern wir den Code der Funktion train_xgboost_classifier wie folgt:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Beim Training des Modells führt die Funktion train_xgboost_classifier eine 5-fache Kreuzvalidierung durch und gibt die durchschnittliche Vorhersagegenauigkeit aus. Die Schulung umfasst weiterhin die Probe bis zum FORWARD-Datum.
Die Kreuzvalidierung wird nur zur Bewertung des Modells verwendet, nicht zum Training. Das Training wird mit allen Daten bis zum FORWARD-Datum ohne Kreuzvalidierung durchgeführt.
Die Kreuzvalidierung ermöglicht eine zuverlässigere und objektivere Bewertung der Modellqualität, was theoretisch die Robustheit des Modells gegenüber neuen Preisdaten erhöhen wird. Oder nicht? Schauen wir uns an, wie der Tester funktioniert.
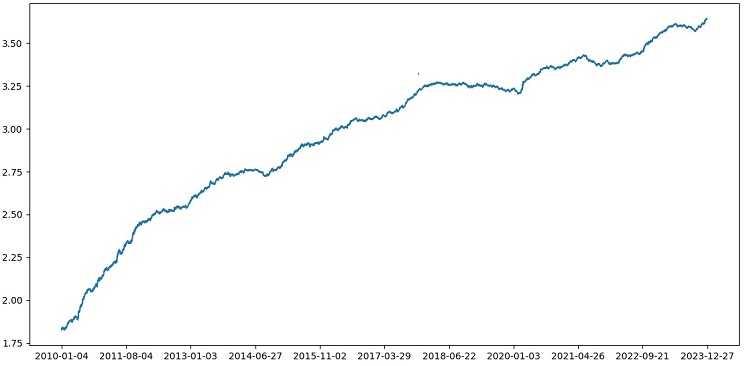
Das Testen von XGBoost mit Kreuzvalidierung auf Daten von 1990-2024 ergab eine Genauigkeit von 56 % für den Test nach 2010. Das Modell erwies sich beim ersten Versuch als sehr robust gegenüber neuen Daten. Auch die Genauigkeit hat sich deutlich verbessert, was eine gute Nachricht ist.
Optimierung von Modellhyperparametern auf einem Raster
Die Optimierung der Hyperparameter ist ein wichtiger Schritt bei der Erstellung eines maschinellen Lernmodells, um dessen Genauigkeit und Leistung zu maximieren. Es ist ähnlich wie bei der Optimierung von MQL5 EAs, man muss sich nur vorstellen, dass es anstelle eines EAs ein maschinelles Lernmodell gibt. Mit der Rastersuche finden wir die Parameter, die am besten funktionieren.
Schauen wir uns die rasterbasierte XGBoost-Hyperparameteroptimierung mit Scikit-learn an.
Wir werden GridSearchCV aus Scikit-learn verwenden, um das Modell über alle Hyperparametersätze des Rasters hinweg kreuzvalidieren zu können. Der Satz mit der höchsten durchschnittlichen Genauigkeit bei der Kreuzvalidierung wird ausgewählt.
Optimierungscode:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Hier definieren wir ein Raster von Hyperparametern param_grid, erstellen das XGBoost clf-Modell und suchen mit der Methode GridSearchCV nach optimalen Hyperparametern über dem Raster. Anschließend werden die besten Hyperparameter grid_search.best_params_ und die durchschnittliche Vorhersagegenauigkeit der Kreuzvalidierung grid_search.best_score_ ausgegeben.
Beachten Sie, dass wir in diesem Code die Kreuzvalidierung zur Optimierung der Hyperparameter verwenden. Dies ermöglicht uns eine zuverlässigere und objektivere Bewertung der Modellqualität.
Nachdem wir diesen Code ausgeführt haben, erhalten wir die besten Hyperparameter für unser XGBoost-Modell und die durchschnittliche Vorhersagegenauigkeit bei der Kreuzvalidierung. Anschließend können wir das Modell mit den besten Hyperparametern auf allen Daten trainieren und es auf neuen Daten testen.
Daher ist die Optimierung der Modellhyperparameter über ein Raster eine wichtige Aufgabe bei der Erstellung von Modellen für maschinelles Lernen. Mit der GridSearchCV-Methode aus der Scikit-Learn-Bibliothek können wir diesen Prozess automatisieren und die besten Hyperparameter für ein gegebenes Modell und die Daten finden.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Model ensembling
Es ist an der Zeit, unser Modell noch cooler und besser zu machen! Modell-Ensembling ist ein leistungsfähiger Ansatz beim maschinellen Lernen, der mehrere Modelle kombiniert, um die Vorhersagegenauigkeit zu verbessern. Beliebte Methoden sind Bagging (Erstellung von Modellen auf der Grundlage verschiedener Teilstichproben von Daten) und Boosting (sequentielles Training von Modellen, um die Fehler der vorherigen Modelle zu korrigieren).
In unserer Aufgabe verwenden wir das XGBoost-Ensemble mit Bagging und Boosting. Wir erstellen mehrere XGBoosts, die auf verschiedenen Teilstichproben trainiert wurden, und kombinieren ihre Vorhersagen. Außerdem optimieren wir die Hyperparameter der einzelnen Modelle mit GridSearchCV.
Vorteile des Ensembling: höhere Genauigkeit, geringere Varianz, verbesserte Gesamtmodellqualität.
Die endgültige Modell-Trainingsfunktion verwendet Kreuzvalidierung, Ensembling und Grid-Bagging-Hyperparameterauswahl.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Wir implementieren das Modell-Ensemble durch Bagging, führen den Test durch und erhalten das folgende Testergebnis:
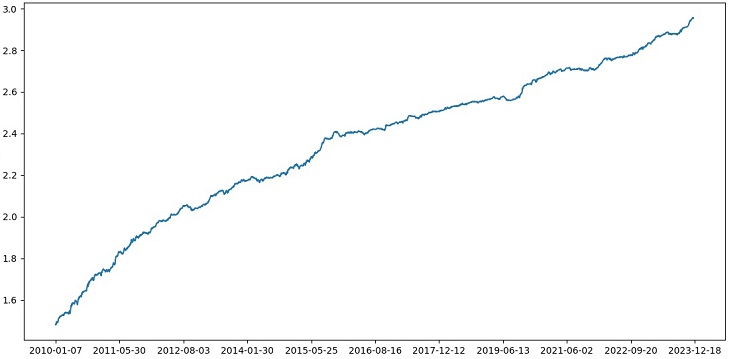
Die Genauigkeit bei der Klassifizierung von Geschäften mit einem Risiko-Ertrags-Verhältnis von 1:8 stieg auf 73 %. Mit anderen Worten: Ensembling und Rastersuche haben die Klassifizierungsgenauigkeit im Vergleich zur vorherigen Version des Codes enorm verbessert. Ich halte dies für ein mehr als ausgezeichnetes Ergebnis, und aus den vorangegangenen Charts zur Leistung des Modells im vorderen Teil kann man deutlich erkennen, wie sehr es sich im Laufe der Codeentwicklung verbessert hat.
Umsetzung der Untersuchungsstichprobe und Prüfung der Robustheit des Modells
Jetzt verwende ich für den Test Daten nach dem EXAMWARD-Datum. Auf diese Weise kann ich die Leistung des Modells mit völlig neuen Daten testen, die nicht zum Trainieren und Testen des Modells verwendet wurden. Auf diese Weise kann ich objektiv beurteilen, wie sich das Modell unter realen Bedingungen verhält.
Ein wichtiger Schritt bei der Validierung eines Modells für maschinelles Lernen ist das Testen an einer Prüfungsprobe. Dadurch wird sichergestellt, dass das Modell auch bei neuen Daten gut funktioniert und einen Eindruck von seiner Leistung in der Praxis vermittelt. Hier müssen wir den Stichprobenumfang richtig bestimmen und sicherstellen, dass er repräsentativ ist.
In meinem Fall verwende ich Post-EXAMWARD-Daten, um das Modell an völlig unbekannten Daten außerhalb von Train und Test zu testen. Auf diese Weise erhalte ich eine objektive Bewertung der Effizienz des Modells und der Bereitschaft für den tatsächlichen Einsatz.
Ich habe das Training mit Daten aus den Jahren 2000-2010 durchgeführt, den Test mit Daten aus den Jahren 2010-2019, die Prüfung mit Daten aus 2019. Die Prüfung simuliert den Handel in einer unbekannten Zukunft.
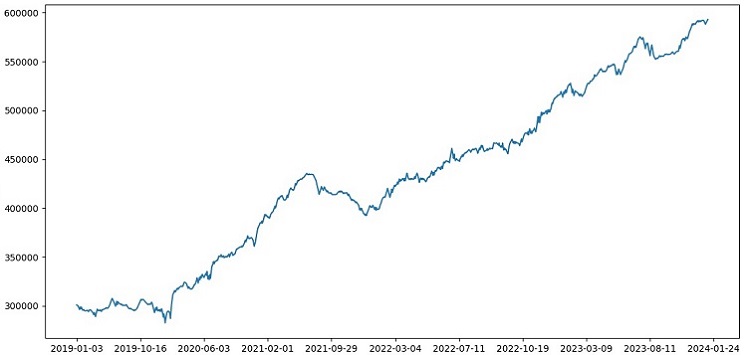
Insgesamt sieht alles gut aus. Die Genauigkeit bei der Prüfung ist auf 60 % gesunken, aber das Wichtigste ist, dass das Modell rentabel und recht robust ist und keine starken Drawdowns aufweist. Erfreulich ist, dass das Modell das Konzept von Risiko und Gewinn erlernt - es sagt Situationen mit geringem Risiko und hohem Gewinnpotenzial voraus (wir verwenden ein Verhältnis von 1:8).
Schlussfolgerung
Dies ist der zweite Artikel in der Serie über die Erstellung eines Handelsroboters in Python. Derzeit ist es uns gelungen, die Probleme der Arbeit mit Daten, der Arbeit mit Merkmalen, der Auswahl und sogar der Erzeugung von Merkmalen sowie das Problem der Auswahl und des Trainings eines Modells zu lösen. Wir haben auch einen nutzerdefinierten Tester implementiert, der das Modell testet, und es scheint, dass alles ziemlich gut funktioniert. Übrigens habe ich auch andere Funktionen ausprobiert, einschließlich der einfachsten, und versucht, die Daten zu vereinfachen - ohne Erfolg. Modelle mit diesen Merkmalen leeren das Konto im Tester. Dies bestätigt einmal mehr, dass Merkmale und Daten nicht weniger wichtig sind als das Modell selbst. Wir können ein gutes Modell erstellen und verschiedene Verbesserungen und Methoden anwenden, aber wenn die Merkmale unbrauchbar sind, dann wird es auch schamlos unsere Kaution für unbekannte Daten aufbrauchen. Im Gegenteil, mit einer guten Ausstattung können Sie selbst mit einem mittelmäßigen Modell ein stabiles Ergebnis erzielen.
Weitere Entwicklungen
Für die Zukunft plane ich, eine eigene Version des Online-Handels im MetaTrader 5-Terminal zu erstellen, um direkt über Python zu handeln und den Komfort zu erhöhen. Schließlich war mein ursprünglicher Anreiz, eine Version speziell für Python zu erstellen, die Probleme bei der Übertragung von Funktionen auf MQL5. Es ist immer noch viel schneller und bequemer für mich, Merkmale, ihre Auswahl, Datenbeschriftung und Datenerweiterung in Python zu handhaben.
Ich glaube, dass die MQL5-Bibliothek für Python zu Unrecht unterschätzt wird. Es ist klar, dass nur wenige Menschen sie nutzen. Es ist eine leistungsstarke Lösung, mit der man wirklich schöne Modelle erstellen kann, die sowohl das Auge als auch den Geldbeutel erfreuen!
Ich würde auch gerne eine Version implementieren, die aus den historischen Daten der Markttiefe einer echten Börse - CME oder MOEX - lernt. Auch dies ist ein vielversprechendes Unterfangen.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14910
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Eugene, durch Ihre Artikel habe ich begonnen, ML in Bezug auf den Handel zu studieren, vielen Dank dafür.
Könnten Sie mir die folgenden Punkte erklären.
Nachdem die Funktion label_data die Daten verarbeitet hat, wird ihr Volumen erheblich reduziert (wir erhalten einen zufälligen Satz von Balken, die die Bedingungen der Funktion erfüllen). Dann durchlaufen die Daten mehrere Funktionen und werden in Trainings- und Testproben unterteilt. Das Modell wird mit der Trainingsstichprobe trainiert. Danach werden die ['labels']-Spalten aus der Teststichprobe entfernt und wir versuchen, ihre Werte vorherzusagen, um das Modell zu schätzen. Gibt es keine Konzeptsubstitution in den Testdaten? Schließlich verwenden wir für die Tests Daten, die die Funktion label_data durchlaufen haben (d. h. eine Reihe von nicht sequentiellen Balken, die im Voraus von einer Funktion ausgewählt wurden, die zukünftige Daten berücksichtigt). Und dann gibt es im Tester den Parameter 10, der, so wie ich es verstehe, dafür verantwortlich sein sollte, wie viele Balken zum Abschluss gebracht werden sollen, aber da wir einen nicht sequentiellen Satz von Balken haben, ist es nicht klar, was wir erhalten.
Daraus ergeben sich folgende Fragen: Wo liege ich falsch? Warum werden nicht alle Balken >= FORWARD für die Tests verwendet? Und wenn wir nicht alle Balken >= FORWARD verwenden, wie können wir dann die für die Vorhersage notwendigen Balken auswählen, ohne die Zukunft zu kennen?
Vielen Dank!
Großartige Arbeit, sehr interessant, praktisch und bodenständig. Selten habe ich einen so guten Artikel mit konkreten Beispielen gesehen und nicht nur Theorie ohne Ergebnisse. Vielen Dank für Ihre Arbeit und den Austausch, ich werde diese Serie verfolgen und freue mich darauf.
Herzlichen Dank! Ja, es gibt noch viele Umsetzungen von Ideen, einschließlich der Erweiterung dieses Artikels mit der Übersetzung in ONNX)
Kritische Schwachstellen:
Empfehlungen zur Verbesserung: