
Développement d'un robot en Python et MQL5 (Partie 2) : Sélection, création et formation de modèles, testeur personnalisé Python

Bref résumé de l'article précédent
Dans l'article précédent, nous avons parlé un peu de l'apprentissage automatique, augmenté les données, développé des caractéristiques pour le futur modèle et sélectionné les meilleures d'entre elles. Il est maintenant temps de passer à autre chose et de créer un modèle d'apprentissage automatique fonctionnel qui apprendra à partir de nos caractéristiques et effectuera des transactions (avec succès, nous l'espérons). Pour évaluer le modèle, nous écrirons un testeur Python personnalisé qui nous aidera à évaluer la performance du modèle et la beauté des graphiques de test. Pour obtenir de plus beaux graphiques de test et une plus grande stabilité du modèle, nous développerons également un certain nombre de fonctions classiques d'apprentissage automatique.
Notre objectif ultime est de créer un modèle fonctionnel et le plus rentable possible pour la prévision des prix et le trading. Tout le code sera en Python, avec des inclusions de la bibliothèque MQL5.
Version de Python et modules requis
J'ai utilisé la version 3.10.10 de Python dans mon travail. Le code joint ci-dessous contient plusieurs fonctions pour le prétraitement des données, l'extraction des caractéristiques et l'entraînement d'un modèle d'apprentissage automatique. Il comprend notamment :
- La fonction de regroupement des caractéristiques à l'aide du Modèle de Mélange Gaussien (GMM) de la bibliothèque sklearn
- La fonction d'extraction des caractéristiques utilisant l'Elimination Récursive des Caractéristiques avec Validation Croisée (RFECV) de la bibliothèque sklearn.
- La fonction d'entraînement du classificateur XGBoost
Pour exécuter le code, vous devez installer les modules Python suivants :
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
Vous pouvez les installer à l'aide de "pip", l'utilitaire d'installation de paquets Python. Voici un exemple de commande pour installer tous les modules nécessaires :
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Allons-y !
Classification ou régression ?
C'est l'une des questions éternelles de la prévision des données. La classification est mieux adaptée aux problèmes binaires pour lesquels une réponse claire de type oui/non est nécessaire. Il existe également une classification multi-classes. Nous l'aborderons dans les prochains articles de la série, car il peut renforcer considérablement les modèles.
La régression est adaptée à la prévision spécifique d'une certaine valeur future d'une série continue, y compris une série de prix. D'une part, cela peut être beaucoup plus pratique, mais d'autre part, l'étiquetage des données pour la régression, tout comme les étiquettes elles-mêmes, est un sujet difficile, car il n'y a pas grand-chose que nous puissions faire d'autre que de prendre le prix futur de l'actif.
Personnellement, je préfère la classification parce qu'elle simplifie le travail d'étiquetage des données. Un grand nombre de choses peuvent être soumises à des conditions de type oui-non, alors que la classification multi-classe peut être appliquée à des systèmes de trading manuels complexes entiers comme Smart Money. Vous avez déjà vu le code d'étiquetage des données dans l'article précédent de la série. Il est clairement adapté à la classification binaire. C'est pourquoi nous prendrons ce modèle de structure particulier.
Il reste à décider du modèle lui-même.
Choisir un modèle de classification
Nous devons sélectionner un modèle de classification adapté à nos données avec les caractéristiques sélectionnées. Le choix dépend du nombre de caractéristiques, des types de données et du nombre de classes.
Les modèles les plus courants sont la régression logistique pour la classification binaire, la forêt aléatoire pour les dimensions élevées et les non-linéarités, et les réseaux neuronaux pour les problèmes complexes. Le choix est immense. Après avoir essayé beaucoup de choses, je suis arrivé à la conclusion que dans les conditions actuelles, le plus efficace est le boosting et les modèles qui en découlent.
J'ai décidé d'utiliser le modèle de pointe XGBoost, qui permet d'améliorer les arbres de décision grâce à la régularisation, au parallélisme et à de nombreux paramètres. XGBoost remporte souvent des concours de data science grâce à sa grande précision. C'est devenu le principal critère de choix d'un modèle.
Générer le code du modèle de classification
Le code utilise le modèle de pointe XGBoost, c'est-à-dire le renforcement du gradient sur les arbres de décision. Une caractéristique particulière de XGBoost est l'utilisation des dérivées secondes pour l'optimisation, ce qui augmente l'efficacité et la précision par rapport à d'autres modèles.
La fonction train_xgboost_classifier reçoit les données et le nombre de tours de boosting. Elle divise les données en X caractéristiques et y étiquettes, crée le modèle XGBClassifier avec un réglage des hyper-paramètres et l'entraîne à l'aide de la méthode fit().
Les données sont divisées en formation et test, le modèle est formé sur les données de formation à l'aide de la fonction. Le modèle est testé sur les données restantes et la précision des prédictions est calculée.
Les principaux avantages de XGBoost sont la combinaison de plusieurs modèles en un seul très précis grâce à l'amplification du gradient et l'optimisation des dérivées secondes pour plus d'efficacité.
Nous devrons également installer la bibliothèque d'exécution OpenMP pour l'utiliser. Pour Windows, vous devez télécharger le Microsoft Visual C++ Redistributable correspondant à votre version de Python.
Passons maintenant au code lui-même. Au début du code, nous importons la bibliothèque xgboost de la manière suivante :
import xgboost as xgb Le reste du code :
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Entraînons le modèle et constatons que la précision est de 52%.
Notre précision de classification est maintenant de 53% des étiquettes profitables. Veuillez noter que nous parlons ici de situations de prévision lorsque le prix a changé de plus que le take profit (200 pips) et n'a pas touché le stop (100 pips) avec sa queue. Dans la pratique, nous aurons un facteur de profit d'environ 3, ce qui est tout à fait suffisant pour un trading rentable. La prochaine étape consiste à écrire un testeur personnalisé en Python pour analyser la rentabilité des modèles en USD (et non en points). Il est nécessaire de comprendre si le modèle rapporte de l'argent en tenant compte de la majoration ou s'il épuise les fonds.
Mise en œuvre de la fonction du testeur personnalisé en Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
Le code crée une fonction pour tester le modèle d'apprentissage automatique sur des données de test et analyser sa rentabilité en tenant compte de la marge (cela devrait inclure les pertes sur les spreads et les différents types de commissions). Les swaps ne sont pas pris en compte, car ils sont dynamiques et dépendent des taux directeurs. Ils peuvent être pris en compte en ajoutant simplement quelques pips à la majoration.
La fonction reçoit un modèle, des données de test, une majoration et un solde initial. Le trading est simulé en utilisant les prédictions du modèle : long à 1, short à 0. Si le bénéfice dépasse la majoration, la position est clôturée et le bénéfice est ajouté au solde.
Les transactions et les profits/pertes de chaque position sont sauvegardés. Le tableau d'équilibre est construit. Le bénéfice/la perte total(e) cumulé(e) est calculé(e).
À la fin, nous obtenons des données de test et nous supprimons les colonnes inutiles. Le modèle xgb_clf formé est testé avec la majoration et le solde initial donnés. Testons-le !
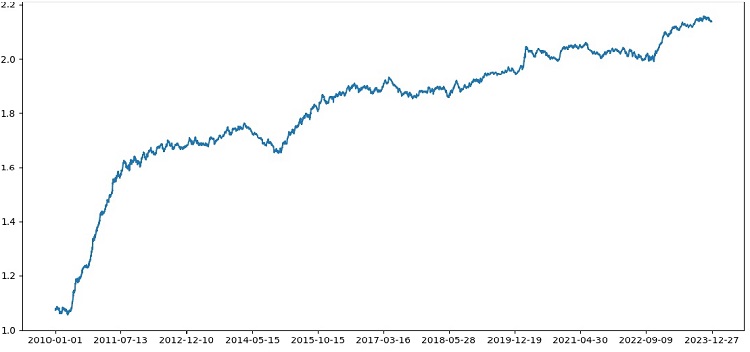
Le testeur travaille avec succès dans l'ensemble, et nous voyons un beau graphique de rentabilité. Il s'agit d'un testeur personnalisé permettant d'analyser la rentabilité d'un modèle de trading par apprentissage automatique en tenant compte du balisage et des étiquettes.
Mise en œuvre de la validation croisée dans le modèle
Nous devons utiliser la validation croisée pour obtenir une évaluation plus fiable de la qualité d'un modèle d'apprentissage automatique. La validation croisée permet d'évaluer un modèle sur plusieurs sous-ensembles de données, ce qui permet d'éviter le sur-ajustement et d'obtenir une évaluation plus objective.
Dans notre cas, nous utiliserons la validation croisée 5 fois pour évaluer le modèle XGBoost. Pour ce faire, nous utiliserons la fonction cross_val_score de la bibliothèque sklearn.
Modifions le code de la fonction train_xgboost_classifier comme suit :
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Lors de l'entraînement du modèle, la fonction train_xgboost_classifier effectue une validation croisée 5 fois et fournit la précision moyenne de la prédiction. L’entraînement comprendra toujours l'échantillon jusqu'à la date FORWARD.
La validation croisée n'est utilisée que pour évaluer le modèle, et non pour l'entraîner. La formation est effectuée sur toutes les données jusqu'à la date FORWARD sans validation croisée.
La validation croisée permet une évaluation plus fiable et plus objective de la qualité du modèle, ce qui, en théorie, augmentera sa robustesse face à de nouvelles données sur les prix. Ou non ? Voyons comment fonctionne le testeur.
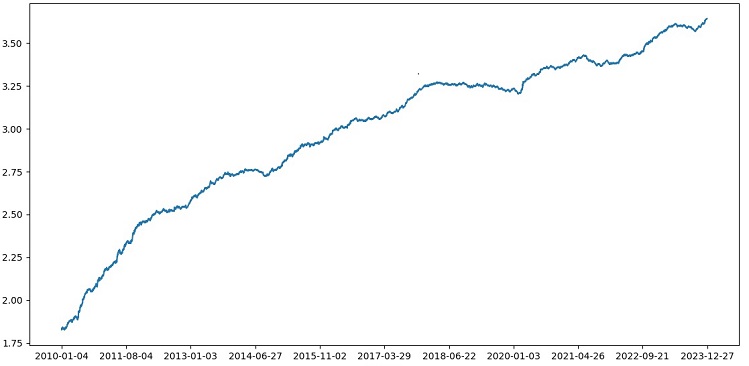
Le test de XGBoost avec validation croisée sur les données de 1990 à 2024 a permis d'obtenir une précision de 56% sur le test après 2010. Le modèle a montré une bonne robustesse aux nouvelles données dès le premier essai. La précision s'est également beaucoup améliorée, ce qui est une bonne nouvelle.
Optimisation des hyper-paramètres d'un modèle sur une grille
L'optimisation des hyper-paramètres est une étape importante dans la création d'un modèle d'apprentissage automatique afin de maximiser sa précision et ses performances. C'est similaire à l'optimisation des EA MQL5, mais imaginez qu'au lieu d'un EA vous ayez un modèle d'apprentissage automatique. La recherche par grille permet de trouver les paramètres les plus performants.
Examinons l'optimisation des hyper-paramètres XGBoost basée sur une grille à l'aide de Scikit-learn.
Nous utiliserons GridSearchCV de Scikit-learn pour effectuer une validation croisée du modèle sur tous les ensembles d'hyper-paramètres de la grille. L'ensemble présentant la précision moyenne la plus élevée lors de la validation croisée sera sélectionné.
Code d'optimisation :
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Nous définissons ici une grille d'hyper-paramètres param_grid, créons le modèle XGBoost clf et recherchons les hyper-paramètres optimaux sur la grille à l'aide de la méthode GridSearchCV. Nous produisons ensuite les meilleurs hyper-paramètres grid_search.best_params_ et la précision moyenne de la prédiction par validation croisée grid_search.best_score_.
Notez que dans ce code, nous utilisons la validation croisée pour optimiser les hyper-paramètres. Cela nous permet d'obtenir une évaluation plus fiable et plus objective de la qualité du modèle.
Après avoir exécuté ce code, nous obtenons les meilleurs hyper-paramètres pour notre modèle XGBoost et la précision moyenne de la prédiction sur la validation croisée. Nous pouvons ensuite entraîner le modèle sur toutes les données en utilisant les meilleurs hyper-paramètres et le tester sur de nouvelles données.
L'optimisation des hyper-paramètres du modèle sur une grille est donc une tâche importante lors de la création de modèles d'apprentissage automatique. En utilisant la méthode GridSearchCV de la bibliothèque Scikit-learn, nous pouvons automatiser ce processus et trouver les meilleurs hyper-paramètres pour un modèle et des données donnés.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Assemblage de modèles
Il est temps de rendre notre modèle encore plus cool et meilleur ! L'assemblage de modèles est une approche puissante de l'apprentissage automatique qui combine plusieurs modèles pour améliorer la précision des prédictions. Les méthodes les plus répandues sont le bagging (création de modèles sur différents sous-échantillons de données) et le boosting (formation séquentielle de modèles pour corriger les erreurs des modèles précédents).
Dans notre tâche, nous utilisons l'ensemble XGBoost avec le bagging et le boosting. Nous créons plusieurs XGBoosts formés sur différents sous-échantillons et combinons leurs prédictions. Nous optimisons également les hyper-paramètres de chaque modèle avec GridSearchCV.
Avantages de l'assemblage : une plus grande précision, une réduction de la variance et une amélioration de la qualité globale du modèle.
La fonction d'apprentissage du modèle final utilise la validation croisée, l'assemblage et la sélection d'hyper-paramètres de type "grid bagging".
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Mettez en œuvre l'ensemble de modèles par le biais du bagging, effectuez le test et obtenez le résultat suivant :
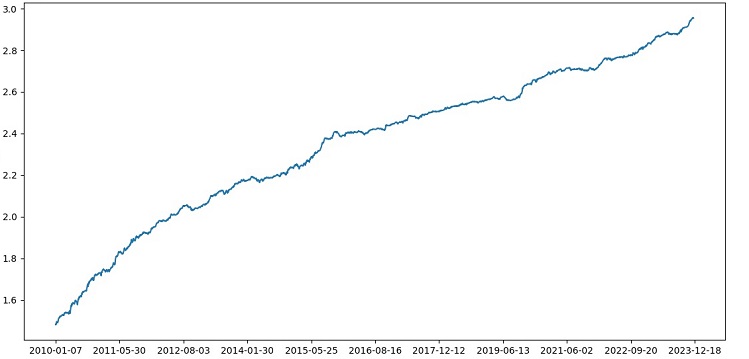
La précision de la classification des transactions avec un ratio risque/récompense de 1:8 est passée à 73%. En d'autres termes, l'assemblage et la recherche en grille nous ont permis d'améliorer considérablement la précision de la classification par rapport à la version précédente du code. Je considère qu'il s'agit d'un résultat plus qu'excellent et, d'après les graphiques précédents des performances du modèle dans la partie avant, on peut clairement comprendre à quel point il s'est renforcé au cours de l'évolution du code.
Mise en œuvre de l'échantillon d'examen et test de la robustesse du modèle
J'utilise maintenant des données postérieures à la date d'examen pour le test. Cela me permet de tester les performances du modèle sur des données entièrement nouvelles qui n'ont pas été utilisées pour former et tester le modèle. Je peux ainsi évaluer objectivement les performances du modèle en conditions réelles.
Le test sur un échantillon d'examen est une étape importante dans la validation d'un modèle d'apprentissage automatique. Cela permet de s'assurer que le modèle fonctionne bien sur de nouvelles données et donne une idée de ses performances dans le monde réel. Il s'agit ici de déterminer correctement la taille de l'échantillon et de s'assurer qu'il est représentatif.
Dans mon cas, j'utilise les données post-EXAMWARD pour tester le modèle sur des données totalement inconnues en dehors de la formation et du test. J'obtiens ainsi une évaluation objective de l'efficacité du modèle et de son aptitude à une utilisation réelle.
J'ai organisé une formation sur les données de 2000 à 2010, un test sur les données de 2010 à 2019, un examen sur les données de 2019. L'examen simule le trading dans un avenir inconnu.
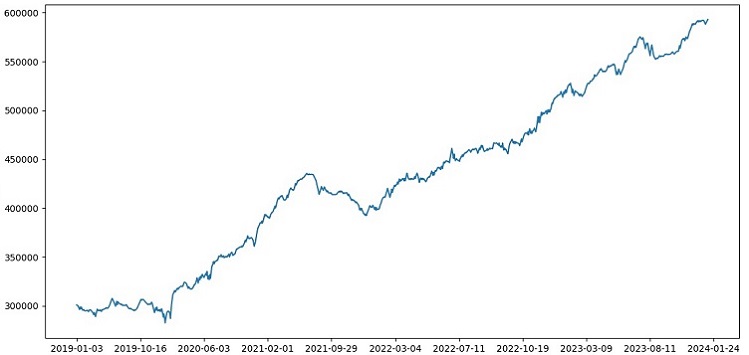
Dans l'ensemble, tout se présente bien. La précision de l'examen est tombée à 60%, mais l'essentiel est que le modèle est rentable et assez robuste, sans avoir de fortes pertes. Il est agréable de constater que le modèle apprend le concept de risque/récompense - il prédit des situations avec un risque faible et un profit potentiel élevé (nous utilisons un rapport risque/récompense de 1:8).
Conclusion
Ceci conclut le deuxième article de la série sur la création d'un robot de trading en Python. À l'heure actuelle, nous avons réussi à résoudre les problèmes de travailler avec les données, de travailler avec les caractéristiques, les problèmes de sélection et même de génération de caractéristiques, ainsi que le problème de la sélection et de l'entraînement d'un modèle. Nous avons également mis en place un testeur personnalisé qui teste le modèle, et il semble que tout fonctionne assez bien. J'ai d'ailleurs essayé d'autres fonctions, y compris les plus simples, pour simplifier les données, mais en vain. Les modèles présentant ces caractéristiques ont drainé le compte dans le testeur. Cela confirme une fois de plus que les caractéristiques et les données ne sont pas moins importantes que le modèle lui-même. Nous pouvons créer un bon modèle et appliquer diverses améliorations et méthodes, mais si les caractéristiques sont inutiles, elles épuiseront sans vergogne notre dépôt sur des données inconnues. Au contraire, avec de bonnes caractéristiques, vous pouvez obtenir un résultat stable même avec un modèle médiocre.
Développements à venir
À l'avenir, j'envisage de créer une version personnalisée du trading en ligne dans le terminal MetaTrader 5 afin de trader directement via Python pour plus de commodité. Après tout, ce qui m'a incité à créer une version spécifique pour Python, ce sont les problèmes liés au transfert de fonctionnalités vers MQL5. Il est encore beaucoup plus rapide et plus pratique pour moi de gérer les caractéristiques, leur sélection, l'étiquetage des données et l'augmentation des données en Python.
Je pense que la bibliothèque MQL5 pour Python est injustement sous-estimée. Il est clair que peu de gens l'utilisent. Il s'agit d'une solution puissante qui permet de créer des modèles d'une grande beauté, aussi bien pour l'œil que pour le porte-monnaie !
J'aimerais également mettre en œuvre une version qui apprendrait à partir des données historiques de profondeur de marché d'une bourse réelle - CME ou MOEX. Il s'agit également d'une initiative prometteuse.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/14910
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Eugène, grâce à vos articles, j'ai commencé à étudier le ML en relation avec le trading, merci beaucoup pour cela.
Pourriez-vous expliquer les points suivants.
Après le traitement des données par la fonction label_data, leur volume est considérablement réduit (nous obtenons un ensemble aléatoire de barres qui satisfont aux conditions de la fonction). Ensuite, les données passent par plusieurs fonctions et nous les divisons en échantillons de formation et de test. Le modèle est entraîné sur l'échantillon d'entraînement. Ensuite, les colonnes ['labels'] sont retirées de l'échantillon de test et nous essayons de prédire leurs valeurs pour estimer le modèle. N'y a-t-il pas de substitution de concepts dans les données de test ? Après tout, pour les tests, nous utilisons des données qui ont passé la fonction label_data (c'est-à-dire un ensemble de barres non séquentielles sélectionnées à l'avance par une fonction qui prend en compte les données futures). Dans le testeur, il y a le paramètre 10 qui, si j'ai bien compris, devrait être responsable du nombre de barres pour conclure l'affaire, mais comme nous avons un ensemble de barres non séquentielles, ce que nous obtenons n'est pas clair.
Les questions suivantes se posent : Où est-ce que je me trompe ? Pourquoi toutes les barres >= FORWARD ne sont-elles pas utilisées pour les tests ? Et si nous n'utilisons pas toutes les barres >= FORWARD, comment pouvons-nous choisir les barres nécessaires à la prédiction sans connaître l'avenir ?
Je vous remercie.
Excellent travail, très intéressant, pratique et terre à terre. Il est difficile de voir un article aussi bon avec des exemples réels et pas seulement de la théorie sans résultats. Merci beaucoup pour votre travail et votre partage, je vais suivre cette série et l'attendre avec impatience.
Merci beaucoup ! Oui, il y a encore beaucoup de mises en œuvre d'idées à venir, y compris l'expansion de celle-ci avec la traduction en ONNX)
Défauts critiques :
Recommandations d'amélioration :