Ciência de Dados e Aprendizado de Máquina (Parte 08): Agrupamento K-Means em MQL5

Os dados são como o lixo, é melhor você saber o que vai fazer com eles antes de coletá-los
Mark Twain
Aprendizado não supervisionado
É um paradigma de aprendizado de máquina para problemas em que os dados disponíveis consistem em exemplos não rotulados. Ao contrário das técnicas de aprendizado supervisionado, como métodos de regressão, SVM, árvores de decisão, redes neurais e muitos outros discutidos nesta série de artigos, onde sempre temos conjuntos de dados rotulados nos quais ajustamos os nossos modelos. No aprendizado não supervisionado, os dados não são rotulados, portanto, cabe ao algoritmo descobrir a relação e tudo mais por si mesmo.Exemplos de tarefas de aprendizagem não supervisionadas são o clustering (agrupamento), redução de dimensão e estimativa de densidade.
Análise de Agrupamento
A análise de agrupamento é uma tarefa de agrupar um conjunto de objetos de forma que os objetos com os mesmos atributos sejam colocados dentro dos mesmos grupos (clusters).
Se você for ao shopping, encontrará itens semelhantes mantidos juntos, certo? Alguém fez o processo de agrupá-los. Quando o conjunto de dados não estiver agrupado, a análise de agrupamento fará exatamente isso, agrupará os valores de dados que são mais semelhantes (em certo sentido) entre si do que o restante dos grupos (clusters).
A própria análise de agrupamento não é um algoritmo específico. A tarefa geral pode ser resolvida por meio de vários algoritmos que diferem significativamente em termos de entendimento sobre o que constitui um cluster.
Existem três tipos de agrupamento amplamente conhecidos;
Img src: wikipedia
- Agrupamento exclusivo
- Agrupamento sobreposto
- Agrupamento hierárquico
Agrupamento exclusivo
Este é um agrupamento rígido no qual os pontos/itens de dados pertencem exclusivamente uns aos outros, por exemplo, o agrupamento k-means
Agrupamento sobreposto
É um tipo de clustering no qual os pontos/itens de dados pertencem a vários clusters. Por exemplo algoritmo Fuzzy/c-means.
Agrupamento hierárquico
Esse tipo de clustering busca construir uma hierarquia de clusters.
Onde os algoritmos de agrupamento são usados?
As técnicas de agrupamento são usadas pela amazon e muitos sites de comércio eletrônico para recomendar itens semelhantes que foram reunidos anteriormente, a Netflix faz a mesma coisa, recomendando os filmes que foram assistidos juntos com base nos interesses.
Basicamente, eles são usados para identificar grupos de objetos ou interesses semelhantes em um conjunto de dados multivariados coletados de campos como marketing, biomédico e geoespacial.
Agrupamento K-Means
Não confundir com o k-vizinhos mais próximos (KNN), ele será abordado no próximo artigo
O algoritmo k-means é um método de quantização vetorial, que visa particionar n observações em k clusters em que cada observação pertence ao cluster com a média/centroide mais próximo onde k < n.Este é um algoritmo de agrupamento amplamente conhecido e usado.
A matemática por trás do algoritmo é simples, abaixo está a imagem dos processos envolvidos no algoritmo.

Agora, para entender como funciona esse processo, vamos fazer as operações de forma manual e a mão enquanto automatizamos o processo desenvolvendo-o no MetaEditor. Vamos criar uma matriz para armazenar os centroides de nosso conjunto de dados de amostra na seção privada da biblioteca CKMeans.
class CKMeans { private: ulong n; uint m_clusters; ulong m_cols; matrix InitialCentroids; //Intitial Centroids matrix vector cluster_assign; }
Como sempre, vamos usar um conjunto de dados simples para construir a biblioteca, nós veremos então como podemos usar o algoritmo em uma situação real do conjunto de dados.
matrix DMatrix = { {2,10}, {2,5}, {8,4}, {5,8}, {7,5}, {6,4}, {1,2}, {4,9} };
01: Iniciando o Algoritmo & 02: Calculando os Centróides
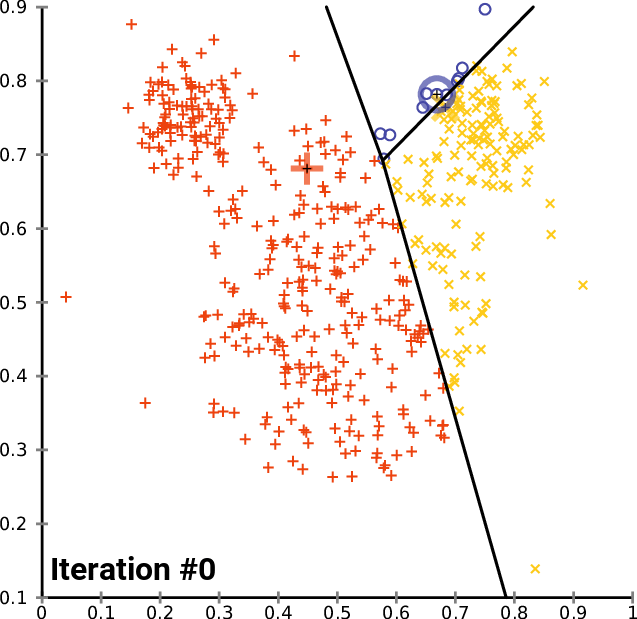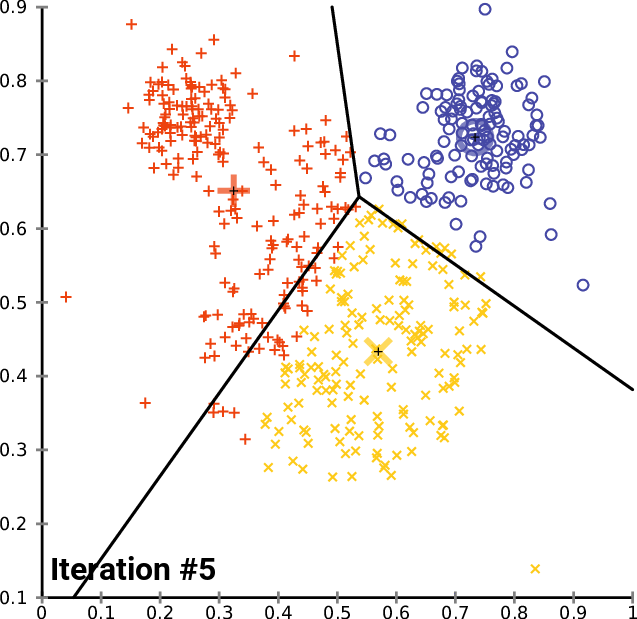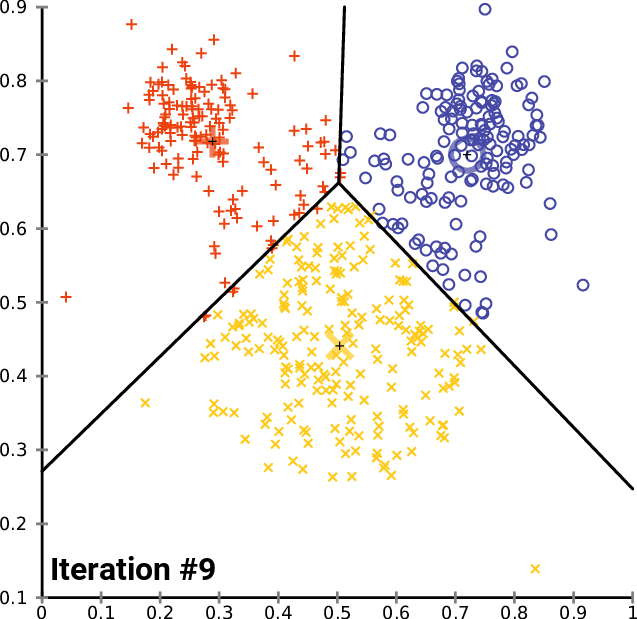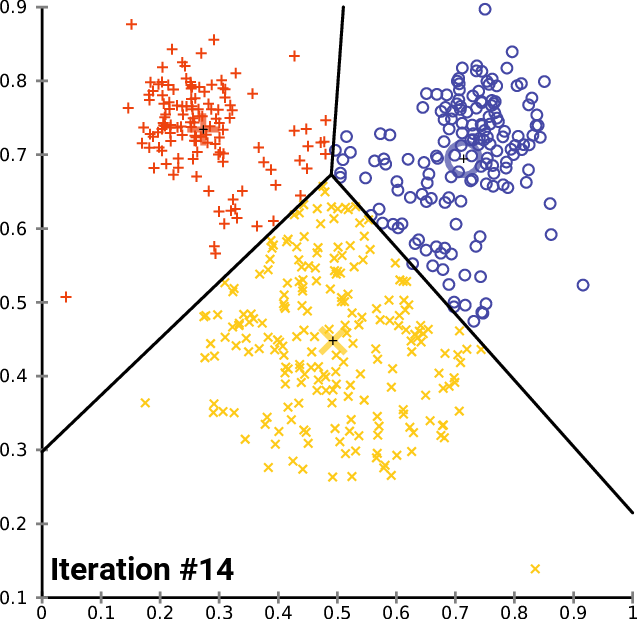
Para iniciar o algoritmo nós precisamos ter os centros iniciais para cada um dos clusters que procuramos, então vamos escolher os centroides aleatórios armazená-los em um array chamado InitialCentroid.
m_cols = Matrix.Cols(); n = Matrix.Rows(); //number of elements | Matrix Rows InitialCentroids.Resize(m_clusters,m_cols); vector cluster_comb_v = {}; matrix cluster_comb_m = {}; vector rand_v = {}; for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i * m_clusters); InitialCentroids.Row(rand_v,i); } Print("Initial Centroids matrix\n",InitialCentroids);
Aqui estão os centroides iniciais,
CS 0 06:44:02.152 K-means test (EURUSD,M1) Initial Centroids matrix CS 0 06:44:02.152 K-means test (EURUSD,M1) [[2,10] CS 0 06:44:02.152 K-means test (EURUSD,M1) [5,8] CS 0 06:44:02.152 K-means test (EURUSD,M1) [1,2]]
Concluímos a etapa inicial, mas muito crucial. A próxima etapa, de acordo com a imagem, é calcular os centroides,espere um segundo, não acabamos de calcular o centroide acima? é isso mesmo, não precisamos calcular o centroide na primeira vez, pois temos os centroides iniciais, os centroides serão atualizados no final.
03: Agrupamento baseado na Distância Mínima
Agora, olhamos para a distância entre cada ponto no conjunto de dados dos centroides obtidos. Um ponto de dados mais próximo de um centroide específico do que todos os centroides será atribuído a esse cluster.
Para encontrar a distância, existem duas fórmulas matemáticas que podemos usar, a distância euclidiana ou a distância retilínea.
Distância Euclidiana
Este é um método de medir a distância entre os dois pontos com base no Teorema de Pitágoras, sua fórmula é dada abaixo;

Distância retilínea
A distância retilínea é simplesmente a soma da diferença nas coordenadas x e y entre dois pontos. Sua fórmula é dada abaixo;

Devido à simplicidade, eu prefiro usar o método Retilíneo para encontrar a distância entre os centroides e os pontos. Vamos plotar a matriz no Excel.

Para obter os mesmos resultados no MetaEditor, teremos que criar uma matriz de 8 linhas x 3 clusters para armazenar essas distâncias retilíneas que vamos usar para atribuir aos clusters. Por que três clusters? Eu escolhi três clusters ao inicializar a biblioteca, você pode escolher qualquer número inicial de cluster com base no que deseja alcançar, nós veremos isso em detalhes mais adiante, abaixo está o construtor da biblioteca.
CKMeans::CKMeans(int clusters=3) { m_clusters = clusters; }Abaixo está como nós criamos uma matriz para armazenar as distâncias retilíneas;
matrix rect_distance = {}; //matrix to store rectilinear distances rect_distance.Reshape(n,m_clusters);
Agora, vamos calcular as distâncias retilíneas e armazenar os resultados na matriz rect_distance que acabamos de criar;
vector v_matrix = {}, v_centroid = {}; double output = 0; for (ulong i=0; i<rect_distance.Rows(); i++) for (ulong j=0; j<rect_distance.Cols(); j++) { v_matrix = Matrix.Row(i); v_centroid = InitialCentroids.Row(j); ZeroMemory(output); for (ulong k=0; k<v_matrix.Size(); k++) output += MathAbs(v_matrix[k] - v_centroid[k]); //Rectilinear distance rect_distance[i][j] = output; } Print("Rectilinear distance matrix\n",rect_distance);
Saída;
CS 0 15:17:52.136 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 15:17:52.136 K-means test (EURUSD,M1) [[0,5,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [5,6,4] CS 0 15:17:52.136 K-means test (EURUSD,M1) [12,7,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [5,0,10] CS 0 15:17:52.136 K-means test (EURUSD,M1) [10,5,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [10,5,7] CS 0 15:17:52.136 K-means test (EURUSD,M1) [9,10,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [3,2,10]]
Como dito anteriormente, a maneira como o k-means agrupa os dados é dada pelo ponto de menor distância de um cluster específico pertencente a esse cluster. Agora, da matriz rect_distance, cada coluna representa um cluster, então, olhamos para o valor mínimo em uma linha, uma coluna com o menor número de todas é atribuída a esse cluster, veja a imagem abaixo,

Código para atribuição dos clusters;
//--- Assigning the Clusters matrix cluster_cent = {}; //cluster centroids ulong cluster = 0; for (ulong i=0; i<rect_distance.Rows(); i++) { v_row = rect_distance.Row(i); cluster = v_row.ArgMin(); cluster_assign[i] = (uint)cluster; } Print("Assigned clusters\n",cluster_assign);
Saída:
CS 0 15:17:52.136 K-means test (EURUSD,M1) Assigned clusters CS 0 15:17:52.136 K-means test (EURUSD,M1) [0,2,1,1,1,1,2,1]
Agora que atribuímos os pontos aos seus respectivos clusters, é hora de agrupar os pontos de dados com base nos clusters recém-encontrados. Se fizermos o processo no Excel, os clusters da forma que são mostrados na imagem abaixo;

Por mais simples que tenha sido o processo de agrupar manualmente os pontos de dados, não é tão simples quando tentamos codificá-lo porque os clusters sempre terão tamanhos diferentes. Então, se tentarmos usar uma matriz para armazenar os clusters, haverá uma diferença no número de linhas para as colunas, o método array é inconveniente e difícil de ler, se tentarmos usar o arquivo CSV para armazenar os valores o processo irá falhar porque devemos escrever dinamicamente as colunas para cada um dos clusters.
Eu tive uma ideia para usar 3 x n clusters_matrix para armazenar os clusters, Esta é uma matriz de valores iguais a zero que foram inicialmente redimensionados de forma que o número de linhas seja igual ao número de clusters e o número de colunas seja definido como o maior número que o cluster pode ter.
No final, cada cluster é armazenado horizontalmente na linha da matriz.
Abaixo está a saída;
CS 0 15:17:52.136 K-means test (EURUSD,M1) clustered Matrix CS 0 15:17:52.136 K-means test (EURUSD,M1) [[2,10,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [2,5,1,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [8,4,5,8,7,5,6,4,4,9,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]Uma vez que esta matriz é passada como uma referência na função KMeansClustering onde todas estas operações são feitas, ela pode ser extraída e você pode filtrar os valores de forma a ignorar os valores zero após o último valor zero não negativo.
void CKMeans::KMeansClustering(const matrix &Matrix, matrix &clustered_matrix)
04: Atualizando os Centróides
Os novos centroides para cada cluster são obtidos encontrando a média de todos os elementos individuais no cluster. Aqui está o código para isso,
vector x_y_z = {0,0}; ZeroMemory(rand_v); for (ulong k=0; k<cluster_cent.Cols(); k++) { x_y_z.Resize(cluster_cent.Cols()); rand_v = cluster_cent.Col(k); x_y_z[k] = rand_v.Mean(); } InitialCentroids.Row(x_y_z, i); if (index >= n_each_cluster.Size()) break; } Print("New Centroids\n",InitialCentroids,"\nclustered Matrix\n",clustered_matrix);
Abaixo está a saída:
CS 0 15:17:52.136 K-means test (EURUSD,M1) New Centroids CS 0 15:17:52.136 K-means test (EURUSD,M1) [[2,10] CS 0 15:17:52.136 K-means test (EURUSD,M1) [1.5,3.5] CS 0 15:17:52.136 K-means test (EURUSD,M1) [6,6]]
Agora que vimos como funciona todo o processo, temos que repetir da segunda etapa até a última até que os dados estejam bem colocados nos respectivos clusters, isso pode ser feito de duas maneiras, algumas pessoas colocam a lógica de tal forma que sempre que os novos centroides para os clusters param de mudar, então os valores ótimos para todos os clusters já são encontrados, enquanto alguns colocam o número limitado de iterações para este algoritmo. Acho que o problema com a primeira maneira é que ela exige que coloquemos um loop infinito que será controlado pela instrução if para acionar a instrução break. Acho que é uma coisa inteligente limitar o algoritmo ao número de iterações.
Abaixo está a função completa do algoritmo de agrupamento k-means com as iterações adicionadas;
void CKMeans::KMeansClustering(const matrix &Matrix, matrix &clustered_matrix,int iterations = 10) { m_cols = Matrix.Cols(); n = Matrix.Rows(); //number of elements | Matrix Rows InitialCentroids.Resize(m_clusters,m_cols); cluster_assign.Resize(n); clustered_matrix.Resize(m_clusters, m_clusters*n); clustered_matrix.Fill(NULL); vector cluster_comb_v = {}; matrix cluster_comb_m = {}; vector rand_v = {}; for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i * m_clusters); InitialCentroids.Row(rand_v,i); } Print("Initial Centroids matrix\n",InitialCentroids); //--- vector v_row; vector n_each_cluster; //Each cluster content matrix rect_distance = {}; //matrix to store rectilinear distances rect_distance.Reshape(n,m_clusters); vector v_matrix = {}, v_centroid = {}; double output = 0; //--- for (int iter=0; iter<iterations; iter++) { printf("\n<<<<< %d >>>>>\n",iter ); for (ulong i=0; i<rect_distance.Rows(); i++) for (ulong j=0; j<rect_distance.Cols(); j++) { v_matrix = Matrix.Row(i); v_centroid = InitialCentroids.Row(j); ZeroMemory(output); for (ulong k=0; k<v_matrix.Size(); k++) output += MathAbs(v_matrix[k] - v_centroid[k]); //Rectilinear distance rect_distance[i][j] = output; } Print("Rectilinear distance matrix\n",rect_distance); //--- Assigning the Clusters matrix cluster_cent = {}; //cluster centroids ulong cluster = 0; for (ulong i=0; i<rect_distance.Rows(); i++) { v_row = rect_distance.Row(i); cluster = v_row.ArgMin(); cluster_assign[i] = (uint)cluster; } Print("Assigned clusters\n",cluster_assign); //--- Combining the clusters n_each_cluster.Resize(m_clusters); for (ulong i=0, index =0, sum_count = 0; i<cluster_assign.Size(); i++) { for (ulong j=0, count = 0; j<cluster_assign.Size(); j++) { //printf("cluster_assign[%d] cluster_assign[%d]",i,j); if (cluster_assign[i] == cluster_assign[j]) { count++; n_each_cluster[index] = (uint)count; cluster_comb_m.Resize(count, m_cols); cluster_comb_m.Row(Matrix.Row(j) , count-1); cluster_cent.Resize(count, m_cols); // New centroids cluster_cent.Row(Matrix.Row(j),count-1); sum_count++; } else continue; } //--- MatrixToVector(cluster_comb_m, cluster_comb_v); // solving for new cluster and updtating the old ones if (iter == iterations-1) clustered_matrix.Row(cluster_comb_v, index); //--- index++; //--- vector x_y_z = {0,0}; ZeroMemory(rand_v); for (ulong k=0; k<cluster_cent.Cols(); k++) { x_y_z.Resize(cluster_cent.Cols()); rand_v = cluster_cent.Col(k); x_y_z[k] = rand_v.Mean(); } InitialCentroids.Row(x_y_z, i); if (index >= n_each_cluster.Size()) break; } Print("New Centroids\n",InitialCentroids);//,"\nclustered Matrix\n",clustered_matrix); } //end of iterations } //+------------------------------------------------------------------+
Após 10 iterações, o algoritmo registra o seguinte;
CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 0 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[0,5,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,6,4] CS 0 20:40:05.438 K-means test (EURUSD,M1) [12,7,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,0,10] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,7] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9,10,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3,2,10]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,2,1,1,1,1,2,1] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2,10] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [6,6]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 1 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[0,7,8] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,2,5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [12,7,4] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,8,3] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,7,2] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,2] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9,2,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3,8,5]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,2,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3,9.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [6.5,5.25]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 2 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[1.5,7,9.25] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.5,2,4.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10.5,7,2.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3.5,8,4.25] CS 0 20:40:05.438 K-means test (EURUSD,M1) [8.5,7,0.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [8.5,5,1.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.5,2,8.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,8,6.25]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 3 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2.666666666666667,7,10.66666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.666666666666666,2,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.333333333333334,7,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [2.333333333333333,8,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,7,0.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,5,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.666666666666666,2,8.333333333333332] CS 0 20:40:05.438 K-means test (EURUSD,M1) [0.3333333333333335,8,7.666666666666667]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]] CS 0 20:40:05.438 K-means test (EURUSD,M1) ..... ..... ..... ..... CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 9 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2.666666666666667,7,10.66666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.666666666666666,2,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.333333333333334,7,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [2.333333333333333,8,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,7,0.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,5,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.666666666666666,2,8.333333333333332] CS 0 20:40:05.438 K-means test (EURUSD,M1) [0.3333333333333335,8,7.666666666666667]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]]
Após 2 iterações, o Algoritmo já convergiu e forneceu os valores ótimos para os centroides. Isso nos leva ao ponto de quantas iterações são as melhores para esse tipo de algoritmo. Ao contrário do gradiente descendente e de outros algoritmos, o agrupamento pelo k-means não precisa de muitas iterações para alcançar os valores ideais, ele leva geralmente de 5 a 10 iterações para agrupar completamente um conjunto de dados simples.
Dentro do script de teste K-Means
Na função Main do script de teste, inicializamos a biblioteca, chamamos a função k-MeansClustering, plotamos os clusters no mesmo eixo e, por último, excluímos o objeto da biblioteca. void OnStart() { //--- matrix DMatrix = { {2,10}, {2,5}, {8,4}, {5,8}, {7,5}, {6,4}, {1,2}, {4,9} }; int clusters =3; matrix clusterd_mat; clustering = new CKMeans(clusters); clustering.KMeansClustering(DMatrix,clusterd_mat); ObjectsDeleteAll(0,0); ScatterPlotsMatrix("graph",clusterd_mat,"cluster 1"); delete(clustering); }
abaixo está o gráfico dos clusters;

Ótimo, dentro da função ScatterPlotsMatrix() foi chamada a função para filtrar os valores iguais a zero antes que os valores pudessem ser plotados no gráfico. Todos os valores exatamente na linha do eixo x ou y no gráfico devem ser ignorados.
vectortoArray(x,x_arr); FilterZeros(x_arr); graph.CurveAdd(x_arr,CURVE_POINTS," cluster "+string(i+1));
Qual é o número correto de k clusters?
Agora entendemos como o algoritmo funciona, mas podemos chamar a função principal de k-means clustering e colocar o número de clusters e pronto, como sabemos que o número do cluster que selecionamos é o ideal porque esse algoritmo é afetado pelos inicializadores, para entender isso, vamos ver algo chamado de Elbow Method (Técnica do cotovelo).
A Técnica do Cotovelo
A técnica do cotovelo é usada para encontrar o número ideal de clusters no agrupamento pelo k-means. A técnica do cotovelo plota o gráfico de uma função de custo que foi produzida por diferentes valores de clusters (k).
À medida que o número de k aumenta, a função de custo diminui, isso pode ser identificado como overfitting
Quando se analisa o gráfico do cotovelo pode-se ver um ponto onde haverá uma rápida mudança na direção do gráfico e depois disso, o gráfico começa a se mover paralelamente ao eixo x.

WCSS
A Soma dos Quadrados dos Resíduos Dentro do Cluster ( WCSS ) é a soma da distância ao quadrado entre cada ponto e o centroide no cluster.
Sua fórmula é dada abaixo;

Uma vez que a técnica do cotovelo é um método de otimização para o agrupamento k-means, cada uma de suas iterações requer a chamada da função de agrupamento K-means.
Agora, para executar a técnica do cotovelo e obter os resultados, há várias coisas que precisamos alterar na função principal para o agrupamento k-means. O primeiro lugar que precisamos mudar é ao obter os centroides, porque quando os clusters escolhidos se tornam iguais ao número de linhas na matriz, ou em qualquer lugar próximo disso, o método para selecionar aleatoriamente o centroide inicial fica aquém.
for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i); InitialCentroids.Row(rand_v,i); }
Também precisamos alterar a lógica para que o maior número de clusters iniciais não exceda o número de n amostras que estão no conjunto de dados, lembre-se da definição de agrupamento k-means que k < n.
void CKMeans::ElbowMethod(const int initial_k=1, int total_k=10, bool showPlot = true) { matrix clustered_mat, _centroids = {}; if (total_k > (int)n) total_k = (int)n; //>>k should always be less than n
Abaixo está o código completo para a técnica do cotovelo;
void CKMeans::ElbowMethod(const int initial_k=1, int total_k=10, bool showPlot = true) { matrix clustered_mat, _centroids = {}; if (total_k > (int)n) total_k = (int)n; //k should always be less than n vector centroid_v={}, x_y_z={}; vector short_v = {}; //vector for each point vector minus_v = {}; //vector to store the minus operation output double wcss = 0; double WCSS[]; ArrayResize(WCSS,total_k); double kArray[]; ArrayResize(kArray,total_k); for (int k=initial_k, count_k=0; k<ArraySize(WCSS)+initial_k; k++, count_k++) { wcss = 0; m_clusters = k; KMeansClustering(clustered_mat,_centroids,1); for (ulong i=0; i<_centroids.Rows(); i++) { centroid_v = _centroids.Row(i); x_y_z = clustered_mat.Row(i); FilterZero(x_y_z); for (ulong j=0; j<x_y_z.Size()/m_cols; j++) { VectorCopy(x_y_z,short_v,uint(j*m_cols),(uint)m_cols); //--- WCSS ( within cluster sum of squared residuals ) minus_v = (short_v - centroid_v); minus_v = MathPow(minus_v,2); wcss += minus_v.Sum(); } } WCSS[count_k] = wcss; kArray[count_k] = k; } Print("WCSS"); ArrayPrint(WCSS); Print("kArray"); ArrayPrint(kArray); //--- Plotting the Elbow on the graph if (showPlot) { ObjectDelete(0,"elbow"); ScatterCurvePlots("elbow",kArray,WCSS,WCSS,"Elbow line","k","WCSS"); } }
Abaixo está a saída do bloco de código acima:

Olhando para o gráfico de cotovelo, está muito claro que o número ideal de cluster é encontrado em 3. Os valores de WCSS caíram drasticamente neste ponto do que em todos os outros, de 51.4667 para 14.333.
Ok, então é isso, temos tudo o que nós precisamos para implementar o algoritmo de agrupamento k-means em MQL5, então vamos ver como podemos implementar o algoritmo no ambiente de negociação.
Vamos ver como nós podemos agrupar os mesmos dados de preços de mercado em vários clusters;
matrix DMatrix = {}; DMatrix.Resize(bars, 1); //columns determines the dimension of the dataset 1D won't be visualized properly vector column_v = {}; column_v.CopyRates(symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,1,bars); DMatrix.Col(column_v,0);
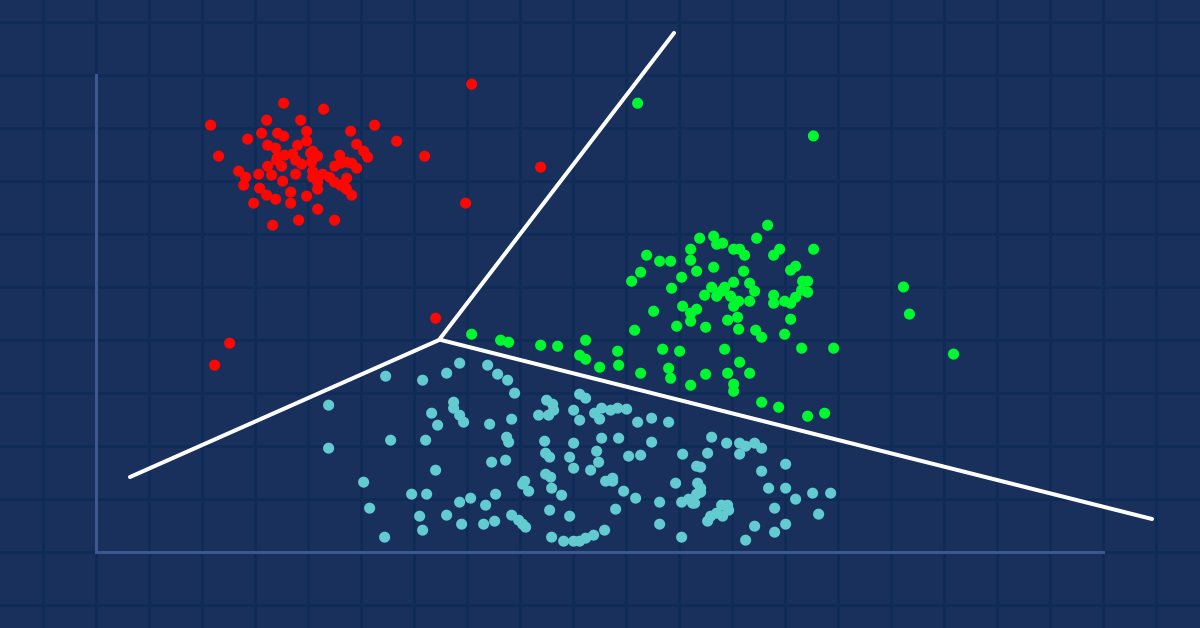
Acabamos de substituir a matriz pela matriz nx1 para os valores de preço de mercado. Desta vez, usamos uma matriz unidimensional. De acordo com a forma como codificamos o algoritmo de agrupamento, as matrizes unidimensionais não serão bem visualizadas e agrupadas, por exemplo; Veja o resultado de toda a operação de agrupamento para o símbolo NASDAQ para 20 barras nas imagens dos gráficos abaixo.

Os 4 clusters que melhor se ajustam de acordo com a técnica do cotovelo no gráfico acima os clusters parecem melhores quando plotados no gráfico,

Agora vamos colocar os valores para o mesmo símbolo em uma matriz 3D e ver o que acontece com os clusters.
matrix DMatrix = {}; DMatrix.Resize(bars, 3); //columns determines the dimension of the dataset 1D won't be visualized properly vector column_v = {}; ulong start = 0; for (ulong i=0; i<2; i++) { column_v.CopyRates(symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,start,bars); DMatrix.Col(column_v,i); start += bars; }
Abaixo está a aparência dos clusters no gráfico;

Parece que a matriz tridimensional quando agrupada no mesmo eixo fornece muitos outliers nos clusters.
Posso pensar em usar uma matriz maior que uma unidimensional ao tentar agrupar diferentes amostras cujos valores estão em diferentes níveis/escalas, por exemplo; Tentando com os valores do indicador RSI e o Indicador de média móvel, mas o ideal é conectar esses valores em uma matriz unidimensional em uma coluna de uma matriz, sinta-se à vontade para explorar isso e compartilhar com todos na seção de discussão.
Uma coisa que eu esqueci de dizer antes de mostrar as imagens dos gráficos, é que eu normalizei os valores dos preços da NASDAQ usando a técnica da Normalização pela média.
MeanNormalization(DMatrix);
Isso é para tornar os dados bem distribuídos no gráfico. Abaixo está o código completo;
void MeanNormalization(matrix &mat) { vector v = {}; for (ulong i=0; i<mat.Cols(); i++) { v = mat.Col(i); MeanNormalization(v); mat.Col(v,i); } } //+------------------------------------------------------------------+ void MeanNormalization(vector &v) { double mean = v.Mean(), max = v.Max(), min = v.Min(); for (ulong i=0; i<v.Size(); i++) v[i] = (v[i] - mean) / (max - min); }
Pensamentos finais
O agrupamento k-means é um algoritmo muito útil que precisa estar na caixa de ferramentas de todos os traders e cientistas de dados. Uma coisa a lembrar é que esse algoritmo é fortemente afetado pelos inicializadores. Se você iniciar a busca pelo algoritmo ótimo usando a técnica do cotovelo começando com 2 clusters, você pode atingir o número ideal de clusters diferente daquele que escolheu o cluster inicial como 4. Além disso, os centroides iniciais importam muito, é por isso que eu tive que adicionar a entrada na função de agrupamento principal para ajudar a escolher se os centroides iniciais deveriam ser selecionados aleatoriamente ou as três primeiras linhas da matriz deveriam ser selecionadas.void CKMeans::KMeansClustering(matrix &clustered_matrix,matrix ¢roids,int iterations = 1,bool rand_cluster =false)
O argumento da função rand_cluster para selecionar o centroide aleatoriamente é definido como false por padrão, isso é para ajudar quando a função de agrupamento K-means é chamada sob a função da técnica do cotovelo. Isso ocorre porque selecionar os centroides aleatórios enquanto busca os agrupamentos ideais não funciona bem. Mas funciona bem quando o número de clusters é conhecido.
Meus cumprimentos.
Os arquivos com o código em mql5 usados neste artigo estão anexados abaixo, há uma pequena alteração no código encontrado nos arquivos zip para o código apresentado acima, algumas linhas foram removidas para fins de desempenho enquanto outras foram adicionadas apenas para facilitar todo o processo de entendimento.
GITHUB REPO >> https://github.com/MegaJoctan/Data-Mining-MQL5
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11615
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Como desenvolver um sistema de negociação baseado no indicador Fractais
Como desenvolver um sistema de negociação baseado no indicador Fractais
 Como desenvolver um sistema de negociação baseado no indicador Alligator
Como desenvolver um sistema de negociação baseado no indicador Alligator
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Antes de mais nada, gostaria de agradecer ao autor por compartilhar este artigo. Espero que o autor, além de explicar essas teorias, possa dar exemplos de como o agrupamento K-mean é usado em negociações reais. Se não houver um exemplo correspondente, este ou outros artigos do autor são praticamente indistinguíveis dos livros didáticos. O aprendizado de máquina é usado em muitos campos.
Seria bom se o autor pudesse ilustrar melhor essas teorias de aprendizado de máquina com exemplos de mecanismos de negociação do MT5. Mais uma vez, obrigado por compartilhar.
Novo artigo Ciência de dados e aprendizado de máquina (Parte 08): K-Means Clustering em MQL5 simples foi publicado:
Autor: Omega J Msigwa
Olá, Omega J Msigwa, obrigado pelo seu artigo muito útil.
Estou perdendo alguma coisa ou no código acima você quer dizer DMatrix?
oi Omega J Msigwa, obrigado pelo seu artigo muito útil.
Estou perdendo alguma coisa ou no código acima você quer dizer DMatrix?
Quero dizer Matrix, conforme explicado no artigo, já que esse código é encontrado na função