
一次元特異スペクトル解析

はじめに
金融市場は高いボラティリティと複雑な動的プロセスを特徴としており、予測やパターンの特定は非常に困難です。特異スペクトル解析(SSA)は、時系列の複雑な構造をトレンド、季節性(周期的)変動、ノイズなどの単純な成分へ分解して表現できる強力な時系列解析手法です。線形代数に基づくSSA法は、定常性を仮定する必要がないため、時系列構造を研究するための汎用的なツールとなっています。
しかしながら、SSAに関する文献ではベクトルおよび行列代数理論が広範に使用されているため、学習への参入障壁が比較的高く、十分な準備ができていない読者にとっては内容の理解が難しく、この解析手法の詳細や利点を十分に把握できない場合があります。本記事の目的は、SSAの理論的基礎を分かりやすく明確に解説することにあります。これらの理論的理解なしでは、SSAは単なる「ブラックボックス」となってしまいます。また、記事では説明した概念の実践的な実装についても紹介します。
SSAという用語は、一連の解析手法群全体を指すものとして理解されるべきですが、それらはすべて以下の4つのステップを順次適用することに基づいています。
- 時系列を軌跡行列(ハンケル行列)へ変換する
- 軌跡行列をランク1の基本行列の和へ分解する
- 基本行列をグループ化する
- 時系列を復元(再構成)する
それでは、これら各段階について詳しく見ていきましょう。
軌跡行列の構築
基本的な考え方は、時系列を多次元空間におけるその構造を反映する行列へ変換することにあります。これは、系列の連続する値の間に存在する隠れた依存関係を明らかにするためにおこなわれます。軌跡行列は以下のように構築されます。まず、サイズ N の一次元時系列サンプルを取り、それをサイズ L(ウィンドウ長)のスライディング部分系列へ分割することで、K 個のベクトル(K=N−L+1)へ変換します。得られた長さLのベクトル(x1,x2,...,xL),(x2,x3,...,xL+1)などを、軌跡行列Xの列として配置します。

図1: X軌跡行列
ここで、Lパラメータは解析の深さを決定します。通常、この値はN/2に設定されます。
軌跡行列をランク1の行列の和に分解する
軌跡行列を構築した後、その分解をおこないます。軌跡行列の分解として特異値分解(SVD)を用いる場合、この解析手法はBasic-SSAと呼ばれます。
特異値分解を用いることで、いわゆる固有三重項(eigentriples)(√λi, Ui, Vi)が構築されます。ここで、
- σi = √λi は特異値であり、XX' 行列の固有値の根に等しい
- Ui:左特異ベクトル
- Vi:右特異ベクトル
- i:X軌跡行列のランクに等しい特異値の数
特異値σiは各成分の重みを示しており、大きな値は重要なパターン(トレンドや周期成分)に対応し、小さな値はノイズに対応します。
したがって、SVDを用いることで、軌跡行列はランク1の基本行列Xiの和として表現できます。

ランク1行列とは、より複雑な行列を構成する「基本構成要素」となる行列です。
SSA法における行列ランクの概念を説明しましょう。SSAの目的は、時系列から決定論的な信号を抽出することにあります。指数関数、多項式、正弦波などの決定論的系列は有限ランクを持つという特徴があります。これは、それらが線形回帰数列を満たしており、その軌跡行列が限られた数の線形独立ベクトルのみを含むためです。たとえば、指数系列の軌跡行列はランク1となります。これは、線形独立なベクトルを1つしか持たないためです。正弦波の場合、軌跡行列のランクは2となります。また、k次多項式の軌跡行列はランクk+1を持ちます。
Rankスクリプトでは、決定論的系列におけるランクの概念を示しています。
//+------------------------------------------------------------------+ //| Rank.mq5 | //| Eugene | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Eugene" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs input int N = 100; // N - length of generated time series input int L = 30; // L - window length input int T = 22; // T - period length of sine function //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { matrix X=matrix::Zeros(L,N-L+1); vector x_exp= vector::Zeros(N); vector x_sinus= vector::Zeros(N); vector x_polynom= vector::Zeros(N); for(int t=0; t <N; t++) { x_exp[t] = MathPow(1.01,t); // 1. Exponential sequence: x_t = 1.01^t x_sinus[t] = MathSin(2*M_PI*t/T); // 2. Sine wave: x_t = sin(2 * pi * t / T) x_polynom[t] = 1 + t+ MathPow(t,2); // 3. Polynomial of degree 2: x_t = 1 + t + t^2 } trajectory_matrix(x_exp,L,X); Print("Rank Exponential sequence = ",Rank_SVD(X)); trajectory_matrix(x_sinus,L,X); Print("Rank Sinus sequence = ",Rank_SVD(X)); trajectory_matrix(x_polynom,L,X); Print("Rank Polynom sequence = ",Rank_SVD(X)); } //+------------------------------------------------------------------+ //| Trajectory matrix X | //+------------------------------------------------------------------+ void trajectory_matrix(vector & series,int window_length, matrix & X) { int N_ = (int)series.Size(); int L_ = window_length; int K = N_ - L_ + 1; X=matrix::Zeros(L_,K); for(int i=0; i <L_; i++) { for(int j=0; j <K; j++) { X[i,j] = series[i+j]; } } } //+------------------------------------------------------------------+ //|Finds the rank of a matrix using SVD | //+------------------------------------------------------------------+ int Rank_SVD(matrix & X) { vector sv; matrix U,V; double tol = 1e-8; // Threshold for non-zero values X.SingularValueDecompositionDC(SVDZ_N,sv,U,V); double threshold = tol * sv.Max(); int rank=0; for(int i=0; i<(int)sv.Size(); i++) { if(sv[i] > threshold) rank++; } return rank; } //+------------------------------------------------------------------+
株価のような実際の時系列は、ノイズを含むため有限ランク系列ではなく、ランクがmin(L,K)の完全ランク系列となります。しかし、系列が有限ランクの決定論的信号とノイズの和で構成されている場合、SSA法はその決定論的信号を近似的に抽出することが可能です。その後、予測は決定論的成分に対してのみ行われ、ノイズ成分は除去されます。この目的のために、軌跡行列Xはランク1の基本行列へ分解され、その後、これらから有用な決定論的信号に対応するより複雑な行列が構成されます。これがSSA法の中核となる考え方です。
グループ化
グループ化の段階では、ランク1の基本行列を複数のグループへ統合し、それぞれを時系列の異なる成分(トレンド、季節性、ノイズ)として解釈します。最も一般的な方法の一つは、行列X の特異値の近さに基づいて行列をグループ化する方法があります。互いに素なm個のグループIが決定された後、軌跡行列Xの分解は次のように表されます。

例は以下の通りです。
- Itrend = {1}:トレンド
- Iseasonal = {2,3} :季節性
- Inoise = {4....,i}:ノイズ
ここで、i は特異値の数です。
左特異ベクトルのグラフィカル表現は、時系列における決定論的信号の存在を視覚的に評価する上で有用です。たとえば、時系列にトレンドが含まれている場合、対応する特異ベクトルは滑らかに変化する軌跡を示します。周期成分が存在する場合には、周期信号はランク2の構造を持つため、対応する特異ベクトルのペアは正弦波に類似した形状を示します。一方、小さな特異値に対応し、ガウス白色雑音に対応するようなランダムな形状の特異ベクトルは、ノイズ成分に対応します。これらの性質により、特異ベクトルの視覚的分析に基づいて各成分をグループ化することが可能となります。
時系列の復元(再構成)
次のステップでは、各グループ化された行列を対角平均化によって、長さNの新しい時系列へ変換します。
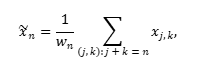
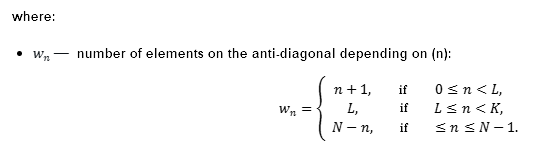
ここで、x_{j,k}はグループ化された(または基本)行列の要素を表します。
この方法で再構成された時系列は、トレンド成分または周期成分のいずれかを表します。これらの時系列の和は、元の時系列に対する非パラメトリックモデルとなり、その形状はウィンドウ長Lおよび基本行列のグループ化方法に依存します。この場合、すべての再構成系列(ノイズ成分を含む)の総和は、元の時系列を完全に復元します。
予測
SSA法におけるgi時系列のMステップ先予測は、再構成系列に基づき、線形回帰関係を用いておこなわれます。

ここで
- aj:LRR係数
- f i:再構成された時系列値
係数ベクトルajは、選択された特異ベクトルUiに基づいて決定されます。

ここで
- First:Ui特異ベクトルの最初の𝐿 − 1座標
- Last:Ui特異ベクトルの最後の座標
- 𝑑:有用な信号を表すために選択された特異ベクトルの数
Toeplitz-SSA
SSAには、従来の手法とは異なる別のバリエーションが存在します。Basic-SSAでは、時系列にスライディングウィンドウを適用して軌跡行列を構築しますが、Toeplitz-SSAではToeplitz構造を持つ自己共分散行列を構築します(これが手法名の由来です)。その後、この自己共分散行列に対してSVDが実行されます。その後の手順、すなわち成分のグループ化、対角平均化、LRR係数の推定、および予測は、Basic-SSAと完全に同様の方法でおこなわれます。
Toeplitz-SSAは定常時系列の解析に適しており、Basic-SSAと比較して予測誤差が小さくなる傾向があります。しかし、非定常時系列に対しては従来のSSAの方が良好な結果を示します。金融市場は本質的に非定常過程であるため、本記事ではBasic-SSAアルゴリズムに限定して使用しています。
Basic-SSA解析のサンプル
それでは理論から離れ、これまで説明した概念をMQL5言語で実際に実装する段階へ移ります。この目的のために、以下の4種類の合成時系列を生成するスクリプトを用意しています。
- 正弦波 + 白色ガウス雑音
- 線形トレンド + 正弦波 + 白色ガウス雑音
- 対称ガウスランダムウォーク+白色ガウス雑音
これらの系列は以下の特徴を持ちます。
- 最初の系列は周期成分を持つ定常過程です。
- 2つ目は決定論的トレンドと周期成分を含む非定常系列です。
- 3つ目は確率的トレンドを持つ非定常系列です。
- 4つ目は定常な白色雑音です。
これらのモデルは、実世界の問題で遭遇する時系列の特徴を部分的にカバーしています。
スクリプトは選択された合成系列を生成し、これまで説明した手順を順次実行します。また、以下のグラフを表示します。
- 生成データ
- 相対特異値(各特異三重項の分散比率)
- 第1・第2特異ベクトル
- 第1・第2特異ベクトルの散布図
- データ系列+再構成+予測
- MQL5SingularSpectrumAnalysisForecast関数による再構成と予測
相対特異スペクトルのグラフ(特異値の二乗を全特異値の二乗和で割ったもの:σi^2/∑ σj^2 - 図2 )は、時系列に含まれる成分の種類を判断し、信号再構成のための特異三重項の数を決定するために使用されます。通常、成分はグラフの急激な減少点(いわゆる「エルボー」)の前まで選択されます。
周期成分が存在する場合、近い大きさの特異値が2つ現れます。また、複数の調和成分(異なる周波数の正弦波)が存在する場合には、プラトー(平坦部)の後に減少が見られることがあります。これは、その後にノイズ成分が続くことを示しています。
一方で、スペクトルが滑らかに減少する場合、それは明確な決定論的信号が存在しないことを示します。

図2:相対スペクトル正弦波+ノイズ
SSAの欠点として、確率的トレンドと決定論的トレンドを区別できないという点が挙げられます。たとえばランダムウォーク系列の場合、トレンドを表す明確な成分が1つだけ現れます。しかし、このトレンドは本質的にはランダムであり、予測不可能です。この点を検証するために、ランダムウォークデータも解析対象に含めています。
最大の特異値をいくつか特定した後は、対応する左特異ベクトルのグラフを確認することが有用です(図3)。ノイズを含む周期信号の場合、最大の特異値に対応する最初の2つの特異ベクトルは、通常、正弦波または余弦波に近い形状を示し、信号の周期性を反映します。

図3:正弦波+ノイズにおける第1特異ベクトルと第2特異ベクトル
さらに、特異ベクトルのペアによる散布図を構築することも可能です。この場合、第1特異ベクトル(U₁)をX軸、第2特異ベクトル(U₂)をY軸にプロットします(図4)。

図4:正弦波+ノイズにおける第1特異ベクトルと第2特異ベクトルの散布図
周期成分を含む場合、散布図は楕円または円形の形状を示すことが多く、これは信号が正弦波的であることを裏付けます。これは、周期成分に対応する特異ベクトルのペアが、正弦波と余弦波のような直交する2つの調和成分に対応しているためです。一方で、散布図の点が明確な幾何学的構造を持たず、ランダムなクラスタ(混沌とした雲状)を形成する場合、それは明確な周期性や決定論的構造が存在しないことを示します。
図5は、正弦波+ノイズからなる合成系列、その再構成、および100ステップ先までの予測結果を示しています。強いノイズの影響により、元のデータから周期信号の存在を視覚的に識別することは困難ですが、SSAは周期成分を効果的に抽出します。もちろんこれは非常に単純な例であり、実際の金融データにおいてこのように明確な構造が得られることは稀です。しかしSSAは、価格に周期性が存在するという仮説を検証するための有効な手段を提供します。

図5:正弦波+ノイズ系列の予測
MQL5におけるSSAの実装
ここでは、MQL5における既存のSSA実装について考察します。ターミナルには、Matrix and Vector Methodsセクション(OpenBLAS)に SingularSpectrumAnalysisForecast 関数が用意されています。この関数の公式説明からは、どのSSA手法が実装されているのかは必ずしも明確ではありません。
当初、この関数は自己共分散行列の分解に基づくToeplitz-SSAの一種ではないかと考えました。しかし、Basic-SSAスクリプトとSingularSpectrumAnalysisForecast関数を用いた場合に、予測および再構成の結果が完全に一致したため、おそらく本実装はBasic-SSAアルゴリズムであると考えられます。例として、図6にトレンド+正弦波+ノイズ系列の主要3成分による予測結果の比較を示します。対象となる系列は200個の値から構成されており、100ステップ先まで予測をおこないます。

図6:MQL5とBasic-SSAによる再構成および予測結果の比較
軌跡行列の分解には、同じOpenBLASセクションに含まれる SingularValueDecompositionDC 関数を使用しました。この関数は開発者によって分割統治法アルゴリズムとして位置付けられており、他のSVDアルゴリズムと比較して最も高速であるとされています。また、この関数は完全な特異ベクトル行列だけでなく、トランケート(部分的)な特異ベクトル行列の計算にも対応している点が非常に便利です。
Basic-SSAスクリプトコード:
//+------------------------------------------------------------------+ //| Basic-SSA.mq5 | //| Eugene | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Eugene" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <Math\Stat\Stat.mqh> #include <Graphics\Graphic.mqh> enum SimpleData { SinusPlusNoise, Trend_Sinus_Noise, RandomWalk, WhiteNoise, }; input int L = 30; // L - window length input int N = 200; // N - length of generated time series input int T = 22; // T - period length of sine function input int fs = 100; // fs - forecast horizon input int r_ = 2; // r - singular components input SimpleData sd = SinusPlusNoise; // Data //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int err; vector x = vector::Zeros(N); // time series double x_array[]; double original_series[]; //------------1. Data -------------------- //------------------ sinus + noise --------- if(sd == SinusPlusNoise) { for(int i=0; i <N; i++) { x[i] = MathSin(2*M_PI*(i+1)/T) + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //------------------trend + sinus + noise ---- if(sd == Trend_Sinus_Noise) { for(int i=0; i <N; i++) { x[i] = 0.05 * i + MathSin(2*M_PI*(i+1)/T) + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //-------------- random walk ----------------- if(sd == RandomWalk) { x[0]=100; for(int i=1; i <N; i++) { x[i] = x[i-1] + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //-------------- white noise ----------------- if(sd == WhiteNoise) { for(int i=0; i <N; i++) { x[i] = MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); // white noise graph } //------------2. Trajectory matrix ------------------- matrix X; trajectory_matrix(x,L,X); //-------------3. Singular decomposition (SVD) ---- matrix U, V; vector singular_values; X.SingularValueDecompositionDC(SVDZ_A,singular_values,U,V); V = V.Transpose(); double total_variance; vector powv = singular_values*singular_values; total_variance = powv.Sum(); VectortoArray(powv/total_variance,x_array); PlotGraphic(x_array,5,2); // Singular spectrum graph double x_1[],x_2[]; VectortoArray(U.Col(0),x_1); VectortoArray(U.Col(1),x_2); PlotGraphic(x_1,x_2,5,3); // graph of the first two singular vectors PlotGraphic(x_1,x_2,5,4); // scatterplot of the first two singular vectors //---------- 4. Time series reconstruction---- int K = N - L + 1; matrix X_i = matrix::Zeros(L,K); matrix Ui = matrix::Zeros(L,1); matrix Vi = matrix::Zeros(1,K); vector x_tilde; vector recon_series = vector::Zeros(N); for(int i=0; i<r_;i++) { Ui.Col(U.Col(i),0); Vi.Row(V.Col(i),0); X_i = (Ui.MatMul(Vi))*singular_values[i]; // rank one matrices diagonal_averaging(X_i,x_tilde); recon_series = recon_series + x_tilde; // reconstructed series } double recon[]; VectortoArray(recon_series,recon); //------------5. LRR ratio vector -------------------- matrix U_r = U; U_r.Resize(L,r_); // r left singular vectors vector a = vector::Zeros(L-1); // vector a of LRR ratios double denom =0; vector u_k; double last; for(int k=0; k<r_;k++) { u_k = U_r.Col(k); // k th singular vector last = u_k[L-1]; u_k.Resize(L-1); a = a + last*u_k; denom = denom + MathPow(last,2); } denom = 1 - denom; a = a/denom; // vector a of LRR ratios //----------------- 6. Forecast using LRR ratios ----------- int forecast_steps = fs; double forecast[]; ArrayResize(forecast,forecast_steps); double fi[]; ArrayCopy(fi,recon,0,N-L+1,L-1); for(int i=0;i<forecast_steps;i++) { double sum = 0.0; for(int j = 0; j < L-1; j++) { sum += a[j] * fi[j]; } forecast[i]= sum; // Forecast // Update fi ArrayCopy(fi, fi, 0, 1, ArraySize(fi)-1); // Shift to the left fi[L-2] = forecast[i]; // Add a new value } double originalplusforecast[]; ArrayResize(originalplusforecast,N+forecast_steps); ArrayCopy(originalplusforecast,original_series,0,0,WHOLE_ARRAY); ArrayCopy(originalplusforecast,forecast,N,0,WHOLE_ARRAY); double reconstructedplusforecast[]; ArrayResize(reconstructedplusforecast,N+forecast_steps); ArrayCopy(reconstructedplusforecast,recon,0,0,WHOLE_ARRAY); ArrayCopy(reconstructedplusforecast,forecast,N,0,WHOLE_ARRAY); PlotGraphic(originalplusforecast,reconstructedplusforecast,15,5); //---- reconstructed data and forecast using the SingularSpectrumAnalysisForecast function vector MQLreconforecast; x.SingularSpectrumAnalysisForecast(L,r_,forecast_steps,MQLreconforecast); double MQL_RF[]; VectortoArray(MQLreconforecast,MQL_RF); PlotGraphic(reconstructedplusforecast,MQL_RF,10,6); } //+------------------------------------------------------------------+ //| Plot Graphic | //+------------------------------------------------------------------+ void PlotGraphic(double &data[], int sec, int n_graph) { ChartSetInteger(0,CHART_SHOW,false); CGraphic graphic; ulong width = ChartGetInteger(0,CHART_WIDTH_IN_PIXELS); ulong height = ChartGetInteger(0,CHART_HEIGHT_IN_PIXELS); if(ObjectFind(0,"Graphic")<0) graphic.Create(0,"Graphic",0,0,0,int(width),int(height)); else graphic.Attach(0,"Graphic"); string st; if(sd == SinusPlusNoise) { st = "Sinus + Noise"; } if(sd == Trend_Sinus_Noise) { st = "Trend + Sinus + Noise"; } if(sd == RandomWalk) { st = "Random Walk"; } if(sd == WhiteNoise) { st = "White Noise "; } if(n_graph==1) // data graph { CCurve *curve = graphic.CurveAdd(data,ColorToARGB(clrRed,255),CURVE_LINES,st); graphic.XAxis().Name("Series " + st); graphic.BackgroundMain(st); } if(n_graph==2) // chart of singular values (relative_variance = sigma_i^2/Sum Sigma_j^2) { CCurve *curve = graphic.CurveAdd(data,ColorToARGB(clrBlue,255),CURVE_LINES,st); graphic.XAxis().Name("Index "); graphic.YAxis().Name("Singular values "); graphic.BackgroundMain("Singular values " + st); } graphic.XAxis().NameSize(18); graphic.YAxis().NameSize(18); graphic.BackgroundMainColor(ColorToARGB(clrBlack,255)); graphic.BackgroundMainSize(24); graphic.CurvePlotAll(); graphic.Update(); Sleep(sec*1000); ChartSetInteger(0,CHART_SHOW,true); graphic.Destroy(); ChartRedraw(0); } //+------------------------------------------------------------------+ //| Plot Graphic | //+------------------------------------------------------------------+ void PlotGraphic(double &data1[],double &data2[], int sec,int n_graph) { ChartSetInteger(0,CHART_SHOW,false); CGraphic graphic; ulong width = ChartGetInteger(0,CHART_WIDTH_IN_PIXELS); ulong height = ChartGetInteger(0,CHART_HEIGHT_IN_PIXELS); if(ObjectFind(0,"Graphic")<0) graphic.Create(0,"Graphic",0,0,0,int(width),int(height)); else graphic.Attach(0,"Graphic"); if(n_graph==3) { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrRed,255),CURVE_LINES,"first"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrBlue,255),CURVE_LINES,"second"); graphic.XAxis().Name(" "); graphic.BackgroundMain("first and second singular vectors"); } if(n_graph==4) // scatter plot of singular vectors { CCurve *curve = graphic.CurveAdd(data1,data2,ColorToARGB(clrRed,255),CURVE_LINES,"first"); graphic.XAxis().Name("first singular vector"); graphic.YAxis().Name("second singular vector"); graphic.BackgroundMain("Scatter plot of singular vectors U_1 vs U_2"); } if(n_graph==5) // data chart plus forecast { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrBlue,255),CURVE_LINES,"original"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrRed,255),CURVE_POINTS_AND_LINES,"reconstructed"); graphic.XAxis().Name("Time "); graphic.YAxis().Name("Value "); graphic.BackgroundMain("Original(Blue) + reconstructed(Red) + forecast(Red) "); curve1.PointsSize(3); } // graph comparing the forecast of the MQL5 SingularSpectrumAnalysisForecast function with the Basic-SSA forecast if(n_graph==6) { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrBlue,255),CURVE_LINES,"BasicSSA"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrRed,255),CURVE_LINES,"MQL5"); graphic.XAxis().Name("reconstructed + forecast "); graphic.BackgroundMain(" MQL5 SingularSpectrumAnalysisForecast vs script Basic-SSA "); curve1.PointsSize(3); } graphic.XAxis().NameSize(18); graphic.YAxis().NameSize(18); graphic.BackgroundMainColor(ColorToARGB(clrBlack,255)); graphic.BackgroundMainSize(24); graphic.CurvePlotAll(); graphic.Update(); Sleep(sec*1000); ChartSetInteger(0,CHART_SHOW,true); graphic.Destroy(); ChartRedraw(0); } //+------------------------------------------------------------------+ //| Copy the vector into an array | //+------------------------------------------------------------------+ void VectortoArray(vector &v, double &array[]) { int v_size = (int)v.Size(); ArrayResize(array,v_size); for(int i=0; i<v_size; i++) { array[i] = v[i]; } } //+------------------------------------------------------------------+ //| Trajectory matrix X | //+------------------------------------------------------------------+ void trajectory_matrix(vector & series,int window_length, matrix & X) { int N_ = (int)series.Size(); int L_ = window_length; int K = N_ - L_ + 1; X=matrix::Zeros(L_,K); for(int i=0; i <L_; i++) { for(int j=0; j <K; j++) { X[i,j] = series[i+j]; } } } //+-------------------------------------------------------------------+ //| Diagonal averaging of a matrix | //| Input: Xi - matrix L x K (elementary matrix of the i th component)| //| Output: x_tilde - reconstructed time series | //+-------------------------------------------------------------------+ void diagonal_averaging(matrix &Xi,vector &x_tilde) { int L_ = (int)Xi.Rows(); int K = (int)Xi.Cols(); int N_ = L_ + K - 1; // Length of the original time series x_tilde = vector::Zeros(N_); double total; // Sum of elements on the anti diagonal int w_n; // Number of elements on the anti diagonal int k; for(int n=0; n < N_; n++) { total = 0; w_n = 0; for(int j=0; j <L_; j++) { k = n - j ; // Column index: n = j + k ---> k = n - j if(k >= 0 && k < K) // Check that the index is within the matrix { total = total + Xi[j, k]; w_n = w_n + 1; } } x_tilde[n] = total / w_n; // Averaging } } //+------------------------------------------------------------------+
結論
本記事では、データ中に潜在する構造を明らかにするために、軌跡行列の特異値分解(SVD)を用いる手法である特異スペクトル解析(SSA)の基礎について解説しました。SSAが時系列をトレンド、季節性、ノイズといった解釈可能な成分へ効果的に分解し、それらの再構成および予測を可能にすることを示しました。
しかし本手法には限界もあり、ガウス的ランダムウォークのような確率的トレンドと決定論的トレンドを確実に区別できないという点が挙げられます。一方で、SSAは厳密な統計的分類を目的とした手法ではなく、その強みはデータ構造を柔軟に分解し可視化する能力にあります。この点においてSSAは有効に機能します。
SSAの応用は単一時系列の解析に限定されるものではありません。この手法は多次元データにも適用可能であり、金融市場における急激な構造変化を検出するための変化点検出インジケーターの構築にも利用できます。これらの方向性は今後の研究において重要な発展領域であり、データの本質的な性質を正確に理解することは市場パターンの発見において極めて重要です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17845
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ちなみに、"この "トピックは、EMDのような関連するアプローチはもちろんのこと、論文(例えば1、2)や議論の中で何度も出てきている(そして、SSAとEMDを組み合わせることで結果が向上することを研究で発見した著者もいる)。