
ヒルベルト=シュミット独立性基準(HSIC)

はじめに
金融商品の価格データを扱うトレーダーにとっての主な課題は、正の期待値を有する取引システム(EA)を構築することです。このようなシステムを設計する際には、学習および実運用に使用されるデータ内に隠れた依存関係が存在することを前提とする場合が一般的です。しかし、この仮定を統計的に検証するという問題が十分に検証されることはほとんどありません。一般には、アウトオブサンプルデータでのテスト結果を通じて間接的に答えが得られると考えられています。
一方で、特徴量と目的変数の間に関係が存在するかどうかという問いに対する統計的に妥当な結論は、極めて重要です。肯定的な結果は予測モデルの利用を支持しますが、否定的な結果は「アルゴリズムはいったい何を予測しようとしているのか」という疑問を生じさせます。
数理統計学において、確率変数間に確率的依存関係が存在するかどうかという問いには、独立性検定によって答えます。そのような基準の一つがHSIC統計検定であり、2005年に統計学者アーサー・グレットンによって提案された強力なノンパラメトリック手法です。
相関係数が線形関係しか検出できないのに対し、HSICは線形および非線形の両方の関係を検出することができます。この性質により、特徴選択、因果分析、その他の機械学習タスクで広く利用されています。本記事では、HSICの動作原理を分析し、MQL5環境で実装します。
HSICについて
HSICは、カーネルアプローチに基づく2つの確率変数XとYの依存性の尺度です。この手法では、カーネル関数(たとえばガウスカーネル(図1))の数学的な「魔法」を利用し、データを特殊な再生核ヒルベルト空間 (RKHS, Reproducing Kernel Hilbert Spaces)空間へ変換します。この空間では依存関係がより検出しやすくなります。
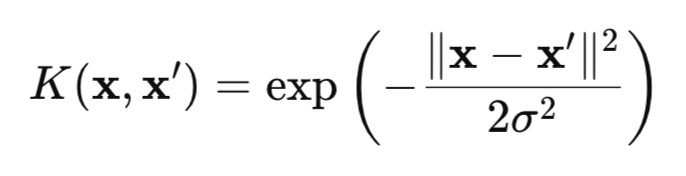
図1:ガウスカーネル(RBFカーネル)
ここで
- x、x':観測ベクトル(データ点)
- || || 2:ユークリッドノルムの二乗
- σ:カーネル幅
HSIC検定に利用可能なカーネルには、カテゴリデータ用カーネルやラプラスカーネルなど、多くの種類があります。しかし本記事では、汎用性が高く特性カーネルとしての性質を持つガウスカーネルに焦点を当てます。この性質により、データ内のあらゆる依存関係を検出できるため、ガウスカーネルは特に有効です。
古典的なHSICは、条件P(X,Y)=P(X)P(Y)が満たされるかどうかを検証することで、2つの確率変数XとYの対独立性を検定します。そのためにHSICは、カーネル行列(各要素がカーネル関数によって計算されたデータ点ペア間の類似度を表す行列)を用いて、同時分布と周辺分布の積からの偏差を解析します。
HSICの重要な利点の一つは、任意の次元のデータを扱えることです。スカラー、ベクトル、あるいはその組み合わせにも対応できます。これは、高次元データにより多変量同時分布P(X,Y)を明示的に構築することが困難な問題において、特に有用です。
数学的には、HSIC基準はRKHSにおける相互共分散作用素のヒルベルト=シュミットノルムの二乗として定義されます。
![]()
ここで
- K(X,X'):確率変数Xに対するカーネル関数
- L(Y,Y'):確率変数Yに対するカーネル関数
- || || HS:ヒルベルト=シュミットノルム
ここでHSICを通常の共分散と比較すると分かりやすいでしょう。古典的な共分散は、元の空間におけるXとYの線形関係を測定します。一方、HSICはXとYを再生核ヒルベルト空間(RKHS)へ写像して解析します。つまり関数空間上で処理することで、複雑な非線形依存関係を明らかにできるのです。
実際には、ヒルベルト=シュミットノルムを直接計算する必要はありません。その代わりに、データサンプルに対して構築されたカーネル行列に基づく経験統計量によってHSICを推定します。
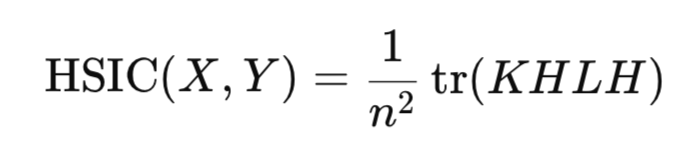
ここで
- K、L:n*nカーネル行列
- H:n*n中心化行列 ( I - 1/n 11 ^T)
- tr():行列トレース
- n:観測数
相関係数と同様に、HSICは確率変数XとYの分布を明示的に構築することなく、標本統計量を用いて両者の関係の存在を推定します。
HSIC統計量は常に非負です。
- HSIC > 0は依存関係の存在を示す
- HSIC = 0はデータが独立であることを示す
HSIC有意性検定
しかし、統計量を計算するだけでは、信頼できる結論を導くには不十分です。ランダムな結果を排除するために、その統計的有意性を確認する必要があります。HSIC統計量については、帰無仮説の下での分布の厳密な解析形式は存在しません。つまり、たとえば正規分布を単純に用いて、計算コストなしに迅速かつ容易に臨界値やp値を得ることはできません。この問題を解決するための主なアプローチは2つあります。
- 置換検定
- ガンマ近似
置換検定は、H0の下でのHSIC分布を推定するための基本的かつ最も正確な方法です。その目的は、一方の変数のインデックスをランダムに並べ替える、またはその変数の結果として得られたカーネル行列を置換することによって、XとYの間の依存関係を崩すことです。正確な結果を得るためには、このような並べ替えをかなり多く(約1000回)実行する必要があります。そのため、置換検定はかなり計算コストが高くなります。なぜなら、そのような各並べ替えに対してHSICを計算する必要があるためです。
置換検定(permutation test)の主な利点は、データ分布の形状についていかなる仮定も必要としないことです。その代わりに、並べ替えによって得られる統計量の経験分布に依存します。その後、このHSICの経験分布を用いてp値の推定値を取得します。
ガンマ近似は、統計計算を高速化するために使用されます。このアプローチでは、HSIC統計量はサンプルサイズによってスケーリングされ(n*HSIC)、ガンマ分布のパラメータはHSICサンプルモーメント(平均と分散)から推定されます。この方法は置換検定よりも大幅に高速ですが、小さなサンプルに対しては精度が低くなる可能性があります。独立性の帰無仮説の下でHSIC分布を推定するための他の方法も存在しますが、それらは実装が複雑であり、実際にはほとんど使用されないため、本記事では扱いません。
MQL5におけるHSIC置換検定の実装
置換検定はhsic_test関数で実装されています。
//+------------------------------------------------------------------+ //| Permutation test function | //+------------------------------------------------------------------+ vector hsic_test(matrix &X,matrix &Y,const double alpha,bool Bootstrap = false,int n_permutations=1000) { vector ret = vector::Zeros(3); int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix //-------------------------------------- // Kc centered kernel matrix К matrix Kc(n, n); if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return ret; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return ret; } Kc = Kc.Transpose(); double coef = 1/pow(n,2); // Calculate the observed value of the HSIC statistic double hsic_obs = compute_hsic(L,Kc,coef); ret[0]= hsic_obs; //------------ Permutation test ---------------------------------------- if (Bootstrap == true){ vector hsic_perms = vector::Zeros(n_permutations); for ( int i = 0; i<n_permutations; i++) { ShuffleMatrix(L); // Shuffle the matrix hsic_perms[i] = compute_hsic(L,Kc,coef); } int count = 0; for(int i = 0; i < n_permutations; i++) { if(hsic_perms[i] >= hsic_obs) count++; } // Calculate the p-value double p_value = (n_permutations > 0) ? (double)count / n_permutations : 0.0; ret[1] = p_value; // Calculate the critical value double hsic_sort[]; VectortoArray(hsic_perms,hsic_sort); ArraySort(hsic_sort); double CV = hsic_sort[(int)round((1-alpha)*n_permutations)]; ret[2] = CV; } //---------------------------------------------------------------------------------- return ret; }
この関数は、2つのデータセットXおよびYを受け取ります(これらはn*dサイズの行列であり、nは観測数、dはデータの次元です)。
alphaパラメータは有意水準を設定します(これは第I種過誤、すなわち実際には真である帰無仮説を棄却する確率です)。
Bootstrapパラメータは、trueの場合はp値を得るために置換検定を実行し、falseの場合は統計量のみを計算します。
n_permutationsはランダムな並べ替えの回数です。
この関数は、観測されたHSIC値、p_value、および選択されたalpha水準に対する臨界値を含むベクトルを返します。
ガウスカーネル行列の計算は、RBF_kernel関数で実行されます。
//+------------------------------------------------------------------+ //| Gaussian kernel | //+------------------------------------------------------------------+ matrix RBF_kernel(const matrix &X) { int n = (int)X.Rows(); // Calculate the distance matrix using the scalar product matrix XX(n, n); if(!XX.GeMM(X, X.Transpose(), 1.0, 0.0)) { Print("Error: Failed to calculate XX = X * X^T"); } matrix diag(n,1); diag.Col(XX.Diag(),0); // vector of diagonal elements // squares of distances matrix D_sq = matrix::Ones(n, 1).MatMul(diag.Transpose()) + diag.MatMul(matrix::Ones(1, n)) - 2*XX; // Calculate sigma on the first n_sigma rows int n_sigma = MathMin(n, 100); int num_elements = (n_sigma * (n_sigma - 1)) / 2; vector upper_tri(num_elements); int idx = 0; for(int i = 0; i < n_sigma; i++) { for(int j = i + 1; j < n_sigma; j++) { upper_tri[idx] = D_sq[i, j]; idx++; } } double sigma = MathSqrt(0.5 * upper_tri.Median()); return MathExp((-1* D_sq) / (2 * sigma*sigma)); }
この関数は、データ点間の距離の二乗、sigmaカーネルの幅を計算し、目的のn*nカーネル行列を返します。
距離の二乗を効率的に計算するために、通常のループの代わりに行列形式が使用されます。
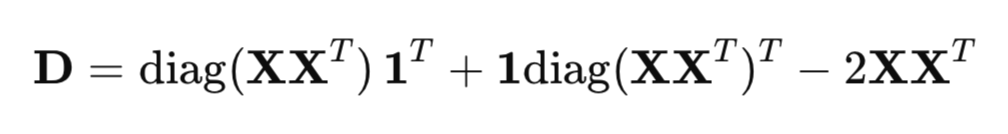
ここで
- XX^T:グラム行列(内積行列)
- diag(XX^T):対角要素のベクトル
- 1:1のベクトル
ガウスカーネルにおけるsigmaパラメータは、カーネルの幅を決定し、データ内の依存関係を検出するHSICの感度に大きく影響します。sigmaパラメータは類似性のスケールを決定します。大きなsigma値はカーネルを広くし(より離れた点も依然として類似していると見なされる)、小さな値はカーネルを狭くします(非常に近い点のみが類似していると見なされる)。
sigmaを選択する一般的な方法の1つは、次のmedian heuristicを使用することです。

係数0.5は、RBFカーネルの分母がデータ点間のユークリッド距離二乗の中央値と等しくなるように取られており、これによりデータのスケールを考慮した適応的な推定が保証されます。
n_sigma = MathMin (n, 100)変数は、sigma計算に使用するデータ量を100に制限します。これは、大きなサンプルに対する計算コストを削減しつつ、sigma推定の代表性を維持するためにおこなわれます。ユークリッド距離の二乗はupper_triベクトルにコピーされ、重複およびゼロ距離を避けるために、距離行列の上三角部分のみ(対角成分i=jを除く)が使用されます。
以下は、HSIC統計を計算する関数compute_hsicです。
//+------------------------------------------------------------------+ //| Function to calculate HSIC | //+------------------------------------------------------------------+ double compute_hsic(const matrix &L, const matrix& Kc, const double coef){ matrix KcL= Kc*L; return coef*KcL.Sum(); }
観測されたHSIC統計量を計算した後、その統計的有意性を検定するために置換検定が実行されます。ShuffleMatrix(matrix &m)関数は、Y変数に対応するLカーネル行列に対してこの並べ替えを実装します。統計的には、HSICはXおよびYに関して対称であるため、LまたはKのどちらを置換しても違いはなく、HSICの置換検定では等価な結果が得られます。Y変数自体を置換し、その後で置換ごとにL行列を再計算することは非効率です。
//+------------------------------------------------------------------+ //| Function for shuffling matrix data | //+------------------------------------------------------------------+ void ShuffleMatrix(matrix &m) { int rows = (int)m.Rows(); int cols = (int)m.Cols(); if (rows != cols) { Print("Error: Matrix should be square"); } int perm[]; GeneratePermutation(rows, perm); // Generate a random permutation of indices matrix temp = m; // Rearrange rows and columns for(int i = 0; i < rows; i++) { for(int j = 0; j < cols; j++) { m[i,j] = temp[perm[i], perm[j]]; } } }
ランダムインデックスの生成は、GeneratePermutation関数を使用しておこないます。
//+------------------------------------------------------------------+ //| Function to create a random permutation of indices | //+------------------------------------------------------------------+ void GeneratePermutation(int size, int &perm[]) { MathSequence(0,size,1,perm); // Fisher-Yates algorithm for permutation for(int i = size - 1; i > 0; i--) { // Generate a random index from 0 to i int j = (int)(MathRand() / 32768.0 * (i + 1)); int temp = perm[i]; perm[i] = perm[j]; perm[j] = temp; } }
Lカーネル行列に対する複数回の置換の後、独立性の帰無仮説の下でのHSIC統計量の経験分布が、ShuffleMatrix関数を用いて形成されます。p値は、観測された統計量以上となる置換後のHSIC統計量の割合として定義されます。p値がalpha有意水準より小さい場合、独立性の帰無仮説は棄却されます。
臨界値は、1−alpha水準における経験分布の分位点として選択されます。すなわち、置換によって得られたHSIC値のうち、上位alpha×100%に対応する値です。
HSICガンマ近似の実装
hsic_Gamma_test関数は、Gamma近似の計算を担当します。
//+------------------------------------------------------------------+ //| HSIC Gamma approximation function | //+------------------------------------------------------------------+ double hsic_Gamma_test(matrix &X, matrix &Y, double &CV, double & pvalue) { int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix matrix Kc(n, n); // Calculate the centered X kernel matrix if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return 0; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return 0; } matrix KcT = Kc.Transpose(); matrix Lc(n, n); // Calculate the centered Y kernel matrix if(!Lc.GeMM(H, L, 1.0, 0.0)) { Print("Error: Failed to calculate Lc = H * L"); return 0; } if(!Lc.GeMM(Lc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Lc * H"); return 0; } double m = (double)n; double coef = 1/m; // Calculate the observed HSIC value matrix KcLc; double hsic_obs = compute_hsic_Gamma(Lc,KcT,coef,KcLc); // n*HSIC matrix varHSIC_m = KcLc*KcLc; varHSIC_m = (1.0/36.0)*varHSIC_m; double varHSIC = 1/(m)/(m-1) * (varHSIC_m.Sum() - varHSIC_m.Trace() ); varHSIC = 72*(m-4)*(m-5)/m/(m-1)/(m-2)/(m-3) * varHSIC; // HSIC variance matrix KD; KD.Diag(K.Diag(),0); matrix LD; LD.Diag(L.Diag(),0); K = K-KD; L = L-LD; matrix one = matrix::Ones(n,1); matrix a = 1/m/(m-1)*one.Transpose(); matrix muX; muX.GeMM(a,K.MatMul(one),1,0); matrix muY; muY.GeMM(a,L.MatMul(one),1,0); double mHSIC = 1/m * ( 1 +muX[0,0]*muY[0,0] - muX[0,0] - muY[0,0] ) ; // HSIC mathematical expectation //Gamma distribution parameters double alphaG = mHSIC*mHSIC / varHSIC; double beta = varHSIC*m / mHSIC; int err; CV = MathQuantileGamma(1-alpha_,alphaG,beta,err); // Critical value pvalue = 1 - MathCumulativeDistributionGamma(hsic_obs,alphaG,beta,err); // p-value //---------------------------------------------------------------------------------- return hsic_obs; }
ここでは、サンプルサイズnでスケーリングされたHSIC統計量(n*HSIC)を計算します。これは、shape(alpha)およびscale (beta)パラメータを持つガンマ分布によって近似されます。これらのパラメータは、HSIC統計量の期待値と分散に基づいて決定されます。
合成データを用いたテスト
HSICが非線形依存関係を検出する能力を評価するために、取引問題に典型的な実験をシミュレートします。Yスカラー目的変数と非線形に関連しているが、線形相関を持たない2つの特徴量X={X1,X2}を考えます(図2)。この状況は、トレーダーが直面する現実的な課題を反映しています。すなわち、取引システムで使用する前に、選択した特徴量が予測変数に影響を与えるかどうかを検定することです。
以下のようにデータを生成します。
Y = X1^2 * cos(pi * X2) + Noise
ここで
- X1およびX2:独立同分布の一様変数[-5,5]
- Noise:ガウスノイズ
- Y:X1およびX2と非線形関係によって関連付けられた目的変数

図2: Y目的変数およびX特徴量の散布図
実験の目的は、次の形式の独立性仮説を検定することです。
P(X1,X2,Y) = P(X1,X2)P(Y),
すなわち、2つの特徴量が組み合わさって目的変数に影響しているのか、それともそれらの間に関係が存在しないのかを判定することです。
特徴量の数が多くなる現実的な問題において、HSICは依存関係を柔軟に検定できます。たとえば、個別の特徴量(X1またはX2とY)に対しても、任意のデータ部分集合に対しても適用可能です。これにより、この手法は有益な特徴量の選択に役立ちます。たとえば、p値によって特徴量を順位付けし、取引システム構築に最も重要なものを選択できます。
図3は、Gamma近似を用いたHSIC検定の結果を示しています。得られたHSIC値、および対応するp値と臨界値は、XとYの間に統計的に有意な非線形関係が存在することを確認しています。これは、HSICがデータ内の複雑な関係を効果的に検出できる能力を示しており、特徴量が予測変数に対してしばしば非線形な影響を持つ株式市場分析において特に重要です。一方で、X1、X2、およびYに対して計算された相関係数はゼロに近く、線形関係は検出されませんでした。

図3: HSIC検定結果、ガンマ近似
同じサンプルサイズで実行された厳密なHSIC置換検定は、著者が使用した比較的低スペックなPC(4コアRyzen 3)で8.5秒を要しました。しかし、ガンマ近似の計算時間は大幅に高速であり、金融データの大規模リアルタイム分析のように計算速度が重要なタスクにおいては、こちらが推奨されます。ガンマ近似は、小さなサンプルでは精度上の誤差が生じる可能性があるにもかかわらず、速度と精度のバランスを提供し、MQL5取引アルゴリズムにHSICを実装するための有用な手法となっています。
結論
本記事では、HSIC (Hilbert-Schmidt Independence Criterion)について説明しました。これは、ランダム変数間の関係を評価するための強力なノンパラメトリック手法です。HSICはカーネルアプローチを使用しており、結合分布を明示的にモデリングすることなく、複雑な非線形関係を特定することができます。
HSICの主な長所
- 任意の次元のスカラーおよびベクトルデータに対応できる
- 複雑な非線形依存関係を捉えることができる
- 比較的簡単に実装できる
しかし、この手法には以下のような制限もあります。
- カーネル幅σパラメータの選択に対する感度
- サンプルサイズへの依存性:小さなサンプルでは置換検定の検出力が低くなる可能性があり、大きなサンプルではKおよびLカーネル行列の計算にかなり時間がかかる
- HSICは関係の存在のみを示し、その強さを相関係数のように特徴付けることはできない
本記事では、非線形依存を持つ合成データに対するHSICの適用を示し、Pearson相関のような従来手法では捉えられない関係を検出できる能力を確認しました。MQL5におけるHSICの実装は、取引システム開発において有益な特徴量を選択するための実用性を示しました。
本記事ではガウスカーネルを用いた基本的な手法を取り上げましたが、HSICにはカテゴリカルデータの処理や条件付き独立性の検定を含む、より高度な機能もあります。これらの方向性は、取引、機械学習、およびデータ分析の問題における今後の研究や応用の可能性を広げます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18099
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
iidの総和として得られる系列は従属性を持たず、定常性の特性を失い、統計的基準を用いることができない。
計算負荷の高い基準に関して、このようなことが許されるのか疑問である。
情報損失がなければ、変換は依存性の推定結果に影響を与えないはずである。
取引、自動取引システム、取引戦略のテストに関するフォーラム
論文 "Hilbert-Schmidt Independence Criterion (HSIC)" の議論
fxsaber、2025.05.13 05時46分。
。
系列を変換した後に(情報を失うことなく - 我々は最初の状態に戻ることができます)独立性が得られる場合は、最初の系列は独立している。
計算が超重要な基準に関して、これが受け入れられるかどうかは疑問だ。
情報損失がなければ、変換は依存性評価の結果に影響を与えるべきではない。
残念ながら、これは複雑なものであれ単純なものであれ、ほとんどの統計的手法に当てはまります。つまり、MO手法の95%は同値の仮定に基づいている(ARIMA、ダイナミック・ニューラル・ネットワーク、隠れマルコフモデルなどを除く)。このことを覚えておかないと、おかしなことになる。
IO手法の95%はIIDの仮定に基づいている
MOを使って依存性基準を作ろうとする試みがあると思うが、同じアプローチで、ONNXファイルに基準そのものを入れるだけだ。
MOを使って依存性の基準を作ろうとする試みがあると思うが、同じアプローチで、基準そのものをONNXファイルに入れるだけだ。
MOモデルは予測を行うように学習し、この予測が「素朴な」ものよりも優れていれば、データに関係があると結論づける。つまり、有意性検定なしで間接的に関係を検出するのである。独立性基準は、予測はしないが、検出された従属性を統計的に確認するものである。これは同じコインの裏表のようなものである。Rパッケージには、より一般的なdHSIC基準の実装があります。これは、私が対独立性のために与えた実装を含み、さらに共同独立性へと検定を拡張します。