
ONNXをマスターする:MQL5トレーダーにとってのゲームチェンジャー

「ONNX形式でAIモデルをエクスポートおよびインポートできる機能により、開発プロセスが合理化され、AIを多様な言語エコシステムに統合する際の時間とリソースが節約されます。」
はじめに
AIと機械学習の時代が始まっていることは否定できません。毎日、金融、芸術、ゲーム、教育、その他生活のさまざまな側面に新しいAIベースのテクノロジーが導入されています。
私たちトレーダーは、人工知能の力を活用することを学べば、人間の目では見ることができなかったパターンや関係を検出できるようになり、市場で優位に立つことができるようになります。
AIはクールで魔法のように見えますが、モデルの背後には複雑な数学的演算があり、これらの機械学習モデルをゼロから実装する場合、正しく理解して実装するには膨大な量の作業と高い精度と集中力が必要です。オープンソースのおかげで、これは必要ではありません。
現在では、AIモデルを構築して実装するのに数学やプログラミングの天才である必要はありません。必要なのは、プロジェクトに使用する特定のプログラミング言語やツールの基本的な理解、また、場合によってはPCです。Google Colabのようなサービスのおかげで、PCを所有する必要さえなく、Pythonを使用してAIモデルを無料でコーディング、構築、実行できます。
Pythonや他の一般的で成熟したプログラミング言語を使用して機械学習モデルを実装するのは簡単ですが、正直に言うと、MQL5でそれを実行するのはそれほど簡単ではありません。本連載でおこなっているように、MQL5で機械学習モデルを最初から作成するという車輪の再発明を希望しない限り、ONNXを使用してPythonで構築されたAIモデルをMQL5に統合することを強くお勧めします。私はONNXがMQL5でサポートされるようになったことをとても嬉しく思っていますし、読者も嬉しく思うべきだと思います。

この記事の内容を理解するには、人工知能と機械学習の基本的な理解が必要です。機械学習を参照してください。
ONNXについて
ONNXはOpen Neural Network Exchangeの略で、機械学習および深層学習モデルを表現するためのオープンソース形式です。これにより、1つの深層学習フレームワークで訓練されたモデルを、他のフレームワークで使用できる共通形式に変換できるため、さまざまなプラットフォームやツール間でのモデルの操作が容易になります。
つまり、MQL5以外の機械学習モデルをサポートする言語を使用して機械学習モデルを構築し、そのモデルをONNX形式に変換すると、このONNXモデルをMQL5プログラム内で使用できるようになります。
この記事では、私がPythonに慣れているため、Pythonを使用して機械学習を構築します。他の言語も使用できると言われていますが、よくわかりません。ちなみに、ONNXドキュメント全体はPythonベースのようです。現時点ではONNXはPython用に作られていると思います。高度なAIベースのライブラリとツールを備えた言語はPython以外にないと思うので、これは当然のことです。
ONNXの基本概念
ONNXについて説明する前に、いくつかの重要な概念を理解しておく必要があります。
- ONNXモデル:ONNXモデルは機械学習モデルを表現したものです。これは、ノードが演算(畳み込み、加算など)を表し、エッジが演算間のデータフローを表す計算グラフで構成されます。
- ノード:ONNXグラフ内のノードは、入力データに適用される操作または関数を表します。これらのノードは、畳み込み、加算、カスタム演算などの演算にすることができます。
- テンソル:テンソルは、計算グラフ内のノード間を流れるデータを表す多次元配列です。これらは、入力、出力、または中間データである可能性があります。
- 演算子:演算子は、ONNXのテンソルに適用される関数です。各演算子は、行列の乗算や要素ごとの加算などの特定の演算を表します。
Pythonでのモデルの構築とONNXを使用したMQL5でのデプロイ
Pythonで機械学習モデルを正常に構築するには、そのモデルをEA、指標、またはMQL5のスクリプト内にデプロイします。これには、モデルのPythonコード以上のものが必要です。最終的にONNXモデルだけでなく、必要な正確な予測を提供するモデルを作成するために従うべき重要な手順を以下に示します。
- データ収集
- MQL5側のデータ正規化
- Pythonでのモデルの構築
- MQL5で構築されたONNXモデルの取得
- モデルのリアルタイム実行
01:データ収集
データ収集は、MQL5プログラム内でおこなう必要がある最初のことです。訓練データとライブ中に使用されるデータを収集する方法と一貫性を保つために、MQL5プログラム内ですべてのデータを収集することが最善であると考えています。モデルをリアルタイムで取引または実行するデータ収集は、解決しようとしている問題の性質によって異なる可能性があることに留意してください。この記事では回帰問題の解決を試みます。OHLC(始値、高値、安値、終値)市場情報を主要なデータセットとして使用します。始値、高値、安値は独立変数として使用され、終値値はターゲット変数として使用されます。
ONNX get data.mq5
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
この関数がおこなうことは、独立変数OHLとターゲット変数CLOSEを収集することです。教師あり機械学習では、ターゲット変数を指定してモデルに与える必要があります。これにより、モデルがターゲット変数を学習してターゲット変数間のパターンを理解できるようになります。残りの変数については、この場合、モデルはこれらの指標の読み取り値がどのように強気の動きまたは弱気の動きにつながるかを理解しようとします。
モデルをデプロイするときは、同じ方法でデータを収集する必要がありますが、今回はターゲット変数を使用せずに収集します。これは、訓練されたモデルにターゲット変数を見つけてもらいたいためです。いわば、予測してもらうためです。
そのため、市場での流暢な予測のために新しいデータをロードするためのGetLiveDataという別の関数が用意されています。
ONNX mt5.mq5
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); return return_matrix; }
訓練データの収集
matrixf dataset = GetTrainData(start_bar, total_bars); Print("Train data\n",dataset);
出力
DK 0 23:10:54.837 ONNX get data (EURUSD,H1) Train data PR 0 23:10:54.837 ONNX get data (EURUSD,H1) [[1.4243405,1.4130603,1.4215617,1.11194] HF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3976599,1.3894916,1.4053394,1.11189] RK 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.402994,1.3919021,1.397626,1.11123] PM 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3848507,1.3761013,1.3718294,1.11022] FF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3597701,1.3447646,1.3545419,1.1097701] CH 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3461626,1.3522644,1.3433729,1.1106] NL 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3683074,1.3525325,1.3582669,1.10996]
ライブデータの取得
現在のバー情報OHLを取得します。
matrixf live_data = GetLiveData(0,1); Print("Live data\n",live_data);
出力
MN 0 23:15:47.167 ONNX mt5 (EURUSD,H1) Live data KS 0 23:15:47.167 ONNX mt5 (EURUSD,H1) [[-0.21183228,-0.23540309,-0.20334835]]
error 2023.09.18 18:03:53.212 ONNX: invalid parameter size, expected 1044480 bytes instead of 32640
02:MQL5側のデータ正規化
データの正規化は、機械学習モデルで使用されるデータセットに対して適切に実行する必要がある最も重要な作業の1つです。
訓練データの準備に使用される正規化手法は、テストやライブデータの準備に使用されるものと同じである必要があることに注意してください。つまり、使用された手法がMinMaxScalerの場合、、訓練データの準備に使用された、MinMaxScaler式の基本変数であるmin値とmax値が、モデルの他の場所で処理される新しいデータを正規化し続けるために使用する必要があります。この一貫性を実現するには、各正規化手法の変数をcsvファイルに保存します。
データの正規化は独立変数のみを対象としています。解決しようとしている問題の種類は関係ありません。ターゲット変数を正規化する必要はありません。
ONNX get data.mq5スクリプト
//--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; }
出力

標準化スケーラーがcsvファイル内で使用された場合、パラメータは次のようになります。
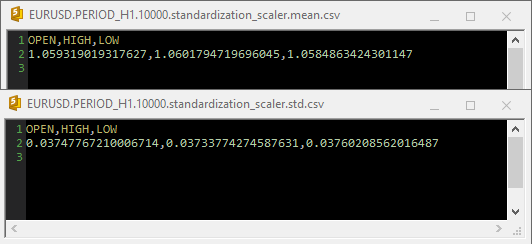
正規化はGetData関数内にも統合されていることに注意してください。正規化は非常に重要であるため、データ収集を担当する両方の関数によって返される各データ行列は、正規化された価格値を含む行列である必要があります。
ONNX get data.mq5スクリプト
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); matrixf norm_params = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; while (CheckPointer(norm_x) != POINTER_INVALID) delete (norm_x); norm_x = new CPreprocessing<vectorf, matrixf>(return_matrix, NORM); //--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; } return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
最後に、データはCSV内に保存され、Pythonコードと共有できるようになっています。
03:Pythonでのモデルの構築
ここでは多層パーセプトロンニューラルネットワークを構築しますが、任意のモデルを構築できます。この特定のタイプのモデルに限定されるわけではありません。まだシステムにPythonをインストールしていない場合は、まずインストールします。その後、Windows CMDから次のコマンドを実行してvirtualenvをインストールします。Powershellと混同しないようにしてください。
$ pip3 install virtualenv
実行後、
$ virtualenv venv
Windowsマシン用のPython仮想環境が作成されます。ほとんどの人はWindowsを使用していると思いますが、MacユーザーとLinuxユーザーではプロセスが少し異なることがあります。その後、次のコマンドを実行して仮想環境を開始します。
$ venv\Scripts\activate
その後、次のコマンドを実行して、このチュートリアルで使用するすべての依存関係をインストールします。
モジュールとPythonのバージョン間の競合を回避し、プロジェクトを共有しやすくするために、仮想環境を作成してプロジェクトを分離することが常に重要です。
MT5のインポートと初期化
import MetaTrader5 as mt5 if not mt5.initialize(): #This will open MT5 app in your pc print("initialize() failed, error code =",mt5.last_error()) quit() # program logic and ML code will be here mt5.shutdown() #This closes the program # Getting the data we stored in the Files path on Metaeditor data_path = terminal_info.data_path dataset_path = data_path + "\\MQL5\\Files\\ONNX Datafolder"
パスが存在するかどうかを確認する必要があります。パスが存在しない場合、MT5側でデータが収集されていません。
import os if not os.path.exists(dataset_path): print("Dataset folder doesn't exist | Be sure you are referring to the correct path and the data is collected from MT5 side of things") quit()
多層パーセプトロンニューラルネットワーク(MLP)の構築
MLPNNをクラス内にラップして、コードを読み取り可能なセクションにします。
01:クラスの初期化
データは収集され、訓練サンプルとテストサンプルに分割されますが、重要な変数はクラス全体で使用できるように宣言されます。
class NeuralNetworkClass(): def __init__(self, csv_name, target_column, batch_size=32): # Loading the dataset and storing to a variable Array self.data = pd.read_csv(dataset_path+"\\"+csv_name) if self.data.empty: print(f"No such dataset or Empty dataset csv = {csv_name}") quit() # quit the program print(self.data.head()) # Print 5 first rows of a given data self.target_column = target_column # spliting the data into training and testing samples X = self.data.drop(columns=self.target_column).to_numpy() # droping the targeted column, the rest is x variables Y = self.data[self.target_column].to_numpy() # We convert data arrays to numpy arrays compartible with sklearn and tensorflow self.train_x, self.test_x, self.train_y, self.test_y = train_test_split(X, Y, test_size=0.3, random_state=42) # splitting the data into training and testing samples print(f"train x shape {self.train_x.shape}\ntest x shape {self.test_x.shape}") self.input_size = self.train_x.shape[-1] # obtaining the number of columns in x variable as our inputs self.output_size = 1 # We are solving for a regression problem we need to have a single output neuron self.batch_size = batch_size self.model = None # Object to store the model self.plots_directory = "Plots" self.models_directory = "Models"
出力

02:ニューラルネットワークモデルの構築
単層ニューラルネットワークは、指定された数のニューロンで定義されます。
def BuildNeuralNetwork(self, activation_function='relu', neurons = 10): # Create a Feedforward Neural Network model self.model = keras.Sequential([ keras.layers.Input(shape=(self.input_size,)), # Input layer keras.layers.Dense(units=neurons, activation=activation_function, activity_regularizer=l2(0.01), kernel_initializer="he_uniform"), # Hidden layer with an activation function keras.layers.Dense(units=self.output_size, activation='linear', activity_regularizer=l2(0.01), kernel_initializer="he_uniform") ]) # Print a summary of the model's architecture. self.model.summary()
出力

03:ニューラルネットワークモデルの訓練とテスト
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) # Early stoppage mechanism | stop training when there is no major change in loss in the last to epochs, defined by the variable patience adam = optimizers.Adam(learning_rate=learning_rate) # Adam optimizer >> https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/ # Compile the model: Specify the loss function, optimizer, and evaluation metrics. self.model.compile(loss=loss, optimizer=adam, metrics=['mae']) # One hot encode the validation and train target variables validation_y = self.test_y y = self.train_y history = self.model.fit(self.train_x, y, epochs=epochs, batch_size=self.batch_size, validation_data=(self.test_x, validation_y), callbacks=[early_stopping], verbose=2) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) # save the loss and validation loss plot plt.figure(figsize=(12, 6)) plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() title = 'Training and Validation Loss Curves' plt.title(title) plt.savefig(fname=f"{self.plots_directory}\\"+title) # use the trained model to make predictions on the trained data pred = self.model.predict(self.train_x) acc = metrics.r2_score(self.train_y, pred) # Plot actual & pred count = [i*0.1 for i in range(len(self.train_y))] title = f'MLP {self.target_column} - Train' # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.train_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) self.model.save(f"Models\\lstm-pat.{self.target_column}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later def test_network(self): # Plot actual & pred count = [i*0.1 for i in range(len(self.test_y))] title = f'MLP {self.target_column} - Test' pred = self.model.predict(self.test_x) acc = metrics.r2_score(self.test_y, pred) # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.test_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) plt.savefig(fname=f"{self.plots_directory}\\"+title) return acc
出力
Epoch 1/50 219/219 - 2s - loss: 1.2771 - mae: 0.3826 - val_loss: 0.1153 - val_mae: 0.0309 - 2s/epoch - 8ms/step Epoch 2/50 219/219 - 1s - loss: 0.0836 - mae: 0.0305 - val_loss: 0.0582 - val_mae: 0.0291 - 504ms/epoch - 2ms/step Epoch 3/50 219/219 - 1s - loss: 0.0433 - mae: 0.0283 - val_loss: 0.0323 - val_mae: 0.0284 - 515ms/epoch - 2ms/step Epoch 4/50 219/219 - 0s - loss: 0.0262 - mae: 0.0272 - val_loss: 0.0218 - val_mae: 0.0270 - 482ms/epoch - 2ms/step Epoch 5/50 ... ... Epoch 48/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0121 - 490ms/epoch - 2ms/step Epoch 49/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0109 - 486ms/epoch - 2ms/step Epoch 50/50 219/219 - 1s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0097 - 501ms/epoch - 2ms/step 219/219 [==============================] - 0s 2ms/step C:\Users\Omega Joctan\OneDrive\Documents\onnx article\ONNX python\venv\Lib\site-packages\keras\src\engine\training.py:3079: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`. saving_api.save_model( 94/94 [==============================] - 0s 2ms/step Test accuracy = 0.9336617822086006

ニューラルネットワークモデルの精度は、訓練中は93%、テスト中は約95%でした。過剰学習の可能性がありますが、とにかく続行します。
04:ONNXモデルの保存
一般に、訓練が正常に完了し、訓練とサンプル外検証の両方でモデルのパフォーマンスに満足したら、モデルを保存することをお勧めします。クラスのtrain_network関数の実行中にモデルを保存するには、ONNXランタイムコードを追加する必要があります。まず最初に、2つのライブラリonnxとtf2onnxをインストールします。
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): # at the end of this function # .... self.model.save(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later self.saveONNXModel() def saveONNXModel(self, folder="ONNX Models"): path = data_path + "\\MQL5\\Files\\" + folder if not os.path.exists(path): # create this path if it doesn't exist os.makedirs(path) onnx_model_name = f"MLP.REG.{self.target_column}.{self.data.shape[0]}.onnx" path += "\\" + onnx_model_name loaded_keras_model = load_model(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") onnx_model, _ = tf2onnx.convert.from_keras(loaded_keras_model, output_path=path) onnx.save(onnx_model, path ) print(f'Saved model to {path}')
出力

ONNXモデルをFiles親ディレクトリに保存することにしたことに気づいたかもしれませんが、なぜこのディレクトリに保存するのでしょうか。 ONNXファイルをEAや指標などのMQL5プログラム内のリソースとして組み込む方が簡単だからです。
04: MQL5で構築されたONNXモデルの取得
#resource "\\Files\\ONNX Models\\MLP.REG.CLOSE.10000.onnx" as uchar RNNModel[]
これにより、ONNXモデルがインポートされ、それがRNNModel uchar配列内に保存されます。
次におこなう必要があるのは、ONNXハンドルをグローバル変数として定義し、OnInit関数内にハンドルを作成することです。
ONNX mt5.mq5 EA
long mlp_onnxhandle; #include <MALE5\preprocessing.mqh> CPreprocessing<vectorf, matrixf> *norm_x; int inputs[], outputs[]; vectorf OPEN, HIGH, LOW; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!LoadNormParams()) //Load the normalization parameters we saved once { Print("Normalization parameters csv files couldn't be found \nEnsure you are collecting data and Normalizing them using [ONNX get data.ex5] Script \nTrain the Python model again if necessary"); return INIT_FAILED; } //--- ONNX SETTINGS mlp_onnxhandle = OnnxCreateFromBuffer(RNNModel, MQLInfoInteger(MQL_DEBUG) ? ONNX_DEBUG_LOGS : ONNX_DEFAULT); //creating onnx handle buffer | rUN DEGUG MODE during debug mode if (mlp_onnxhandle == INVALID_HANDLE) { Print("OnnxCreateFromBuffer Error = ",GetLastError()); return INIT_FAILED; } //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(mlp_onnxhandle); Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(mlp_onnxhandle,i); Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(mlp_onnxhandle); Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(mlp_onnxhandle,i); Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- if (MQLInfoInteger(MQL_DEBUG)) { Print("Inputs & Outputs"); ArrayPrint(inputs); ArrayPrint(outputs); } const long input_shape[] = {batch_size, 3}; if (!OnnxSetInputShape(mlp_onnxhandle, 0, input_shape)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } const long output_shape[] = {batch_size, 1}; if (!OnnxSetOutputShape(mlp_onnxhandle, 0, output_shape)) //giving the onnx handle the output shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
出力
PR 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Creating and using per session threadpools since use_per_session_threads_ is true CN 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Dynamic block base set to 0 EE 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Initializing session. IM 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Adding default CPU execution provider. JN 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Use DeviceBasedPartition as default QK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Saving initialized tensors. GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Done saving initialized tensors RI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Session successfully initialized. JF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 input(s) QR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input name is input_1 NF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR PM 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR HI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 3] FS 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input shape must be defined explicitly before model inference NE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of input data can be reduced to [3] if undefined dimension set to 1 GD 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 output(s) GQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output name is dense_1 LJ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR NQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR LF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 1] KQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output shape must be defined explicitly before model inference CO 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of output data can be reduced to [1] if undefined dimension set to 1 GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) Inputs & Outputs IE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 3 CK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 1
ライブデータの取得
前に述べたように、ライブデータは市場から取得し、訓練用のデータを収集するときに正規化したのと同じ方法で正規化する必要があります。
ONNX mt5.mq5 EA
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); if (!norm_x.Normalization(return_matrix)) Print("Failed to Normalize"); return return_matrix; }
Norm_xクラスインスタンスは、機能するようにOnInit内のLoadNormParams()関数内で宣言されています。この関数は、保存された正規化パラメータをそれぞれのCSVファイルからロードします。
ONNX mt5.mq5 EA
bool LoadNormParams() { vectorf min = {}, max ={}, mean={} , std = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); switch(NORM) { case NORM_MEAN_NORM: mean = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv"); //--- Loading the mean min = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, mean, min); if (mean.Sum()<=0 && min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_MIN_MAX_SCALER: min = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, min); if (min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_STANDARDIZATION: mean = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.mean.csv"); //--- Loading the mean std = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.std.csv"); //--- Loading the std if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nStd ",std); norm_x = new CPreprocessing<vectorf,matrixf>(mean, std, NORM_STANDARDIZATION); if (mean.Sum()<=0 && std.Sum() <=0) return false; break; } return true; }
05:モデルのリアルタイム実行
OnTick関数内でモデルを使用するには、OnnxRun関数を呼び出して、入力と予測の両方にONNXハンドル、ベクトル、またはfloat値の行列を渡すだけで済みます。
ONNX mt5.mq5 EA
void OnTick() { //--- matrixf input_data = GetLiveData(0,1); vectorf output_data(1); //It is very crucial to resize this vector or matrix if (!OnnxRun(mlp_onnxhandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Failed to Get the Predictions Err=",GetLastError()); ExpertRemove(); return; } Comment("inputs_data\n",input_data,"\npredictions\n",output_data); }
ERR_ONNX_INVALID_PARAMETERを表すエラーコード5805を回避するには、出力データベクトルまたはfloat型行列のサイズを変更する必要があります。 ニューラルネットワークには出力が1つしかないため、このベクトルのサイズを1に変更しました。行列を使用する場合は、1行1列にサイズ変更する必要がありました。
出力

すべてがうまく機能しています。次に、Metatrader 5内でPythonを使用して作成および訓練されたニューラルネットワークモデルを使用します。ありがたいことに、プロセスはそれほど難しくありません。
MQL5でONNXを使用する利点
- 相互運用性:ONNXは、深層学習モデルを表現するための共通形式を提供します。この形式により、1つの深層学習フレームワーク(TensorFlow、PyTorch、scikit-learnなど)でモデルを訓練して、大規模なモデルの再実装を必要とせずにMQL5で使用できます。モデルをMQL5で動作させるためにモデルを最初からハードコーディングする必要がなくなるため、時間を大幅に節約できます。
- 柔軟性:ONNXは、従来のフィードフォワードニューラルネットワークから再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)などのより複雑なモデルに至るまで、幅広い種類の深層学習モデルをサポートしています。この柔軟性により、さまざまな用途に適しています。
- 効率:ONNXモデルは、さまざまなハードウェアやプラットフォームに効率的に導入できるように最適化できます。モデルをエッジデバイス、モバイルデバイス、クラウドサーバー、さらには専用のハードウェアアクセラレータにデプロイできます。
- コミュニティサポート:ONNXはコミュニティから多大なサポートを得ています。TensorFlow、PyTorch、scikit-learnなどの主要な深層学習フレームワークは、ONNX形式へのモデルのエクスポートをサポートしており、ONNXランタイムなどのさまざまなランタイムエンジンにより、ONNXモデルのデプロイが簡単になります。
- 広範なエコシステム:ONNXはさまざまなソフトウェアパッケージに統合されており、ONNXモデルを操作するための広範なツールがあります。これらのツールを使用して、モデルをONNX形式で変換、最適化、実行できます。
- クロスプラットフォーム互換性:ONNXはクロスプラットフォームになるように設計されており、ONNX形式でエクスポートされたモデルは、変更を加えることなく、外部のさまざまなオペレーティングシステムやハードウェア上で実行できます。
- モデルの進化:ONNXはモデルのバージョン管理と進化をサポートします。以前のバージョンとの互換性を維持しながら、時間の経過とともにモデルを改善および拡張できます。
- 標準化:ONNXは、さまざまな深層学習フレームワーク間の相互運用性の事実上の標準になりつつあり、コミュニティがモデルやツールを共有しやすくなっています。
最後に
ONNXは、さまざまなフレームワーク間でモデルを活用したり、さまざまなプラットフォームにモデルをデプロイしたり、さまざまな深層学習ツールを使用している可能性のある他のユーザーと共同作業したりする必要があるシナリオで特に役立ちます。これにより、深層学習モデルを使用するプロセスが簡素化され、エコシステムが成長し続けるにつれて、ONNXの利点はさらに重要になります。この記事では、実用的なモデルを開始するために従う必要がある5つの重要な手順について説明しました。控えめに言っても、このコードはニーズに合わせて拡張できます。また、プログラムがストラテジーテスターで動作するためには、正規化CSVファイルをテスター内で読み取る必要がありますが、これについてはこの記事では取り上げていません。
よろしくお願いします。
| ファイル | 使用法 |
|---|---|
| neuralnet.py | Python言語でのニューラルネットワークの実装がすべて含まれている、メインのPythonスクリプトファイル |
| ONNX mt5.mq5 | 取引状況でONNXモデルを使用する方法を示すEA |
| ONNXはdata.mq5を取得します | Pythonスクリプトと共有するデータを収集および準備するためのスクリプト |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13394
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
オメガ・J・ミシグワさん、この記事をどうもありがとうございました。MALE5の最後のバージョンにはCPreprocessingがないので、チュートリアルのファイルを更新していただけますか?可能でなければ、このチュートリアルを実行するために使用されたMALE5のバージョンを教えてください。
ライブラリのドキュメントがあるかどうかわかりません。
ありがとうございます。
このチュートリアルに関することは、この記事に添付されているcprecessi mgのコードを使用してください。
私はこの行を参照しています:
#include <MALE5preprocessing.mqh> // CPreprocessingを持たないhttps://github.com/MegaJoctan/MALE5/blob/MQL5-ML/preprocessing.mqh。
もしそうなら、その行を次のように変更してください:
#include <preprocessing.mqh>この zipファイル (記事に添付されている)にあるpreprocessing.mqhをincludeフォルダの下に保存した後、その行を次のように変更してください。
CPreprocessingはv2.0.0以降非推奨となっている。
あるいは,CPreprocessing の代わりに,前処理ファイルに存在する各スケーラーを呼び出してください。MALE5 バージョン 3.0.0 を使用していると仮定した場合
各スケーラークラスが提供する
データ行列 X にスケーラをフィットし,変換を行う.
フィットされたスケーラを用いてデータ行列 X を変換する.
フィットされたスケーラーを用いてデータベクトル X を変換する.
参考になったかどうか教えてほしい。
ONNXがMetaTrader 5でうまく動作するためには、Pythonモデルはシンプルである必要がありますか、それとも高度に最適化された複雑なアーキテクチャを使用できますか?
MetaTrader 5はどのような複雑なモデルでも動作します。