
取引におけるニューラルネットワーク:概念強化を備えたマルチエージェントシステム(最終回)

はじめに
前回の記事では、金融分野での分析および自動化ツールとして開発されたFinConフレームワークの理論的側面を検討しました。このフレームワークの目的は、ビッグデータ処理、自然言語処理(NLP)、ポートフォリオ管理技術を活用して、金融市場における意思決定を支援することです。システムの核心はマルチエージェントアーキテクチャの採用にあり、各モジュールが特定のタスクを実行しながら、他のモジュールと相互作用して共通の目標を達成します。
このアーキテクチャの重要な構成要素はマネージャエージェントです。マネージャはアナリストエージェントの作業を調整し、アナリストが生成した結果を集約、リスク管理をおこない、投資戦略を洗練します。FinConは専門化されたアナリストエージェントを採用しており、各エージェントはデータ処理と分析、市場予測、リスク評価の異なる側面を担当します。この役割分担により情報の重複を減らし、データ処理を加速させます。
フレームワークは2層のリスク管理アーキテクチャを実装しています。
- 第1レベルはリアルタイムに動作し、短期的な損失を最小化します。
- 第2レベルは完了したエピソードに基づいてシステムの行動を評価し、エラーを特定して戦略を改善します。
FinConの重要な特徴のひとつは、概念的言語強化フィードバック(CVRF)の使用です。この仕組みは、アナリストエージェントのパフォーマンスとマネージャによる取引判断の両方を評価します。これにより、システムは自身の経験から学習し、最も影響力のある市場要因に焦点を当てて行動方策を洗練することができます。
フレームワークには3層の記憶(メモリ)システムも含まれています
- 作業記憶(ワーキングメモリ)は進行中の操作に必要なデータを一時的に保存します。
- 手続き型記憶は、再利用可能な実証済みの手法やアルゴリズムを保持します。
- エピソード記憶は、重要なイベントとその結果を記録し、過去の経験を分析して将来の意思決定に活用します。
FinConフレームワークの原著者による可視化図を以下に示します。

前回の記事では、フレームワーク著者によって提案されたアプローチの独自の解釈に基づく実装を開始しました。CNeuronMemoryDistilオブジェクト内で、3層記憶システムのアルゴリズムを構築しました。本日はこの作業をさらに進めます。
アナリストエージェントオブジェクト
まず、アナリストエージェントモジュールの構築から始めます。FinConの著者は、タスクの内容に依存せず、多様な分野で動作できるユニバーサルエージェントモジュールを設計しました。この柔軟性は、質問応答(QA)の原理で動作する事前学習済み大規模言語モデル(LLM)を中心としたアーキテクチャによって実現されています。エージェントの挙動は、受け取る質問やタスクによって決まります。
私たちのモデルはLLMを使用していませんが、それでも、さまざまな専門分野のアナリストエージェントに適応可能なユニバーサルオブジェクトを作成することは可能です。このアプローチにより、システムの柔軟性とモジュール性が確保されます。
FinConの著者によると、エージェントは複数の主要モジュールを統合しており、これらがエージェントの機能を支えています。
構成およびプロファイリングモジュールは、エージェントが担当するタスクの種類を定義する上で重要な役割を果たします。経済セクターやパフォーマンス指標の詳細を含む取引目標を設定するだけでなく、エージェント間の役割と責任を分配します。このモジュールは、記憶データベースへの機能的なクエリを生成するための基礎的なテキストフレームワークを形成します。
さらに、このモジュールは、各タスクに最も関連性の高い指標を特定することで、エージェントが異なる経済セクターに適応できるようにします。生成された情報は、システム内の他のすべてのコンポーネント間での一貫した相互作用の基盤となります。
知覚モジュールは、エージェントが環境とやり取りする際の管理を担当します。市場情報の認識を調整し、データをフィルタリングして意味のあるパターンを特定します。これにより、エージェントは変化する状況に適応しつつ、予測の精度と効率を維持できます。
記憶(メモリ)モジュールは意思決定に必要なデータの保存と処理を保証する重要なコンポーネントで、作業記憶、手続き記憶、エピソード記憶という3つの主要な部分から構成されます。作業記憶は、進行中のタスクを実行し、市場の変化を監視し、行動を調整するために使用します。手続き記憶は、エージェントが実行したすべての手順、結果、および結論を記録します。エピソード記憶は、完了したタスクに関するデータを保存し、長期的な戦略形成に寄与します。
前回の作業で、すでに記憶モジュールを開発済みであり、この既存のソリューションを使用することができます。元のFinConフレームワークでは、エピソード記憶へのアクセスはマネージャに限定されていました。しかし、私たちの実装では、すべてのエージェントが3層記憶構造を活用します。各エージェントは独自の記憶モジュールを持ち、特定のタスクに関連するデータへのアクセスが自然に制限されます。この設計により、エージェントは最近の変化だけでなく、その広い時間的文脈も考慮できます。
構成およびプロファイリングモジュールの機能は、各エージェントの専門分野と利用可能な入力データに基づきタスクを生成する専用外部オブジェクトの存在を前提としています。私たちの実装では入力データを均一に仮定します。つまり、エージェントの役割が固定されていれば、各ステップで同一のクエリが生成されます。しかし、モデル訓練時には、これらのクエリを調整してエージェントの現在の役割やスキルに合わせることができます。
この考えに基づき、エージェントモジュール内に学習可能なクエリテンソルを作成するアイデアが生まれます。このアプローチにより、追加の外部情報ストリームは不要になります。オブジェクト作成時に、このテンソルの初期値はランダムに初期化されます。これらのパラメータは、エージェントの「生得的認知能力」として機能し、将来の学習のための独自の基盤となります。
学習が進むにつれて、エージェントは初期化時に定義された固有能力に最も適合する役割を徐々に発展させます。これにより、エージェントは自然にタスクに適応しつつ、生得的特性を効率的に活用でき、さらなる発展の強力な基盤を形成します。学習可能なクエリテンソルは、最適な発展軌道を特定し強化するための主要なツールとなります。この設計により、エージェントの初期ランダム状態と目標役割との整合性が保たれ、訓練コストを削減し、モデル全体の効率が向上します。
知覚モジュールの主な目的は、エージェントのタスクに最も関連するパターンをデータストリームから抽出する方法を特定することです。この機能を実装するために、クロスアテンション機構を使用できます。これにより、モデルは最も関連性の高い情報を「強調」し、効果的なフィルタリングとデータ処理を実現します。
エージェントの内部モジュールを構築した後、次に重要なステップは出力の分析です。中心的な問題は結果の具体性にあります。一方で、具体性はエージェントのタスクに依存し、ユニバーサルエージェントの概念と矛盾するように見えます。もう一方で、多様な出力は結果処理を複雑にするため、標準化が必要です。
私たちの実装では、各エージェントは提案された取引決定を表すテンソルを出力します。元のFinConフレームワークでは、取引決定を生成する権限はマネージャにのみ与えられています。しかし、エージェント自身が提案を提出することに制限はありません。このアプローチにより、特定の役割に関係なく、エージェント出力を表現する統一データ構造を作成できます。標準化により、結果処理が簡素化され、システム全体の効率が向上します。
これらすべての概念は、CNeuronFinConAgentオブジェクト内で実装されます。その構造を以下に示します。
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
提示された構造では、オーバーライド可能なメソッドのよく知られたセットと、上記で説明したアプローチを整理するために使用される複数のオブジェクトを確認できます。これらのコンポーネントの具体的な目的は、オブジェクトメソッドのアルゴリズムを実装していく中で順次検討していきます。
また、クロスアテンションオブジェクトが親クラスとして使用されている点も重要です。このクラスから継承されたメソッドやオブジェクトも、作成するモジュールの動作を整理するために活用されます。
すべての内部オブジェクトはstaticとして宣言されており、クラス構造を簡略化するとともに、コンストラクタとデストラクタを空のままにできます。内部オブジェクトと継承オブジェクトの初期化は、Initメソッド内で処理されます。このメソッドは、作成されるオブジェクトのアーキテクチャを明確かつ一意に定義する一連の定数を受け取ります。
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
メソッド本体内では、(いつも通り)同名の親クラスのメソッドを呼び出すことから始めます。この親メソッドは、すでに継承オブジェクトの初期化や外部コンポーネントとのデータ交換用インターフェースの整理をおこなっています。
前述の通り、親クラスとしてクロスアテンションオブジェクトが選択されています。この種のオブジェクトは2つのデータストリームを処理するよう設計されています。FinConエージェントの文脈では疑問に思われるかもしれません。なぜなら、エージェントは最初、割り当てられたタスク固有の単一情報ストリームで動作するからです。しかし、エージェントは記憶モジュールからもデータを受け取ります。これにより第2のデータストリームが生じます。さらに、エージェントの行動において重要な側面は、逐次的な分析、すなわち自身の行動を振り返り、市場状況の変化に応じて調整する能力です。このリフレクションプロセスにより、事実上第3の情報ストリームが生成されます。
私たちの実装では、このリフレクション機能を親クラスから継承された仕組みを用いて整理します。クロスアテンションアプローチは、進化する市場状況において、過去の結果テンソルを調整するために有効であると考えられます。そのため、親オブジェクトの主要データストリームは結果テンソルのパラメータで構成され、第2のストリームは現在の環境状態に関する情報を含むことになります。
なお、エージェントの出力では、推奨される取引操作を表すテンソルが期待されます。
次に、2つのアテンションモジュールを初期化します。これらのモジュールは、市場状況の動態と、エージェントが提案する取引決定の順序を別々に保持します。この構造により、現在の市場動向の文脈内で適用される行動方策の有効性をより正確に評価できるようになります。
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
プロファイリングモジュールは、2つの連続した全結合層から構成されます。最初の層は固定値1の単一要素を持ち、第2の層は指定されたサイズのテンソルを生成します。私たちの実装では、生成されるベクトルの長さは、入力シーケンス内の単一要素の記述の長さの10倍となっています。これは、10要素のシーケンスを通じてエージェントの役割を表現していると解釈できます。
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
前述の通り、知覚モジュールは内部のクロスアテンションオブジェクトで表現されており、エージェントの専門性に応じて受け取った入力データを分析します。
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
すべての内部および継承オブジェクトの初期化に成功した後、真偽値を呼び出し元に返し、メソッドの実行を完了します。
開発の次の段階では、feedForwardメソッド内でフィードフォワードパスアルゴリズムを実装します。ここでは、先ほど初期化したオブジェクト間の情報の流れを整理する必要があります。
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
メソッドのパラメータには、環境状態の記述を含む入力データオブジェクトへのポインタが含まれます。各エージェントは、自身に割り当てられた役割に応じて受信情報を分析することを思い出してください。そのため、まず割り当てられたタスクを表すテンソルを生成します。
なお、エージェント役割テンソルは訓練時のみ生成されます。テストや本番モードでは、エージェントの専門性は固定されており、各ステップでこのテンソルを再生成する必要はありません。
次に、内部クロスアテンションオブジェクトを用いて、エージェントの割り当てタスクの解決に関連するパターンを抽出します。
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
取得した値は環境状態記憶モジュールに渡され、現在の状態を過去の市場動向に関する情報で補強します。これにより、より深い文脈理解が可能になります。
同様に、前回のフィードフォワードパスの結果もエージェント行動記憶モジュールに追加されます。
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
その結果、2つの記憶モジュールは、エージェントの直近の行動とそれに対応する環境変化を表すテンソルを出力します。これらのデータは同名の親クラスメソッドに渡され、現在の市場動向に基づいて推奨取引操作テンソルを調整します。
バックプロパゲーションの準備として、データバッファのポインタを交換し、前回の結果テンソルを保持します。これにより、モデル訓練時の逆伝播演算が正しく実行されます。
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
これらの操作の論理結果を呼び出し元プログラムに返して、メソッドを終了します。
フィードフォワードアルゴリズムを完了した後、バックプロパゲーションパスの情報フローを整理します。ご存じの通り、勾配伝播ではデータの流れはフィードフォワード段階の構造を反映しますが、逆方向に移動します。前向きと後ろ向きのパスが同一ルーティングであるため、モデルは各パラメータが最終結果に与える影響を効率的に考慮できます。
勾配分配の操作はcalcInputGradientsメソッド内で実装されます。このメソッドは入力データオブジェクトへのポインタを受け取りますが、今回は入力データがモデルの最終結果に与える影響を反映した誤差勾配値を渡す必要があります。
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッド内ではまず、受け取ったポインタの有効性を確認します。無効であれば以降の操作は意味を持ちません。
実際の勾配分配プロセスは、同名の親クラスメソッドを呼び出すことから始まります。このメソッドは誤差勾配をアテンションモジュールに伝播します。
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
その後、取引操作提案記憶モジュールを通して誤差勾配を現在のオブジェクトに戻します。ただし、前回のフィードフォワード結果が入力として使用されていたため、結果バッファには最新のフィードフォワード操作で取得された異なる値が含まれます。さらに、現在の勾配バッファの値を保持する必要があります。このため、まず前回のフィードフォワード結果を結果バッファポインタを交換することで復元し、次に勾配バッファポインタを空きデータバッファに置き換えます。準備作業が完了した後に誤差勾配の分配をおこないます。
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
重要な点として、私たちは以前のパスに対して勾配を再帰的に伝播させないということです。したがって、これらの操作で得られた勾配は再利用されません。それでも、この手順は記憶モジュール内部のオブジェクト間で誤差勾配を正しく分配するために必要です。これらの操作が完了した後、元のバッファポインタを復元します。
次に、環境状態記憶モジュールのパイプラインに沿って誤差勾配を分配します。ここでは、まず知覚モジュールに勾配を伝播させます。前述の通り、この知覚モジュールはクロスアテンションブロックで実装されています。
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
その後、取得した誤差勾配を、入力データとエージェント役割テンソルを生成するMLPの間で、それぞれのモデル性能への影響に応じて分配します。
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
ただし、役割テンソルを生成するMLPの第1層は固定値を持つため、この層を通しての勾配伝播はおこないません。
すべての必要な操作が完了すると、メソッドは呼び出し元プログラムに論理的な成功フラグを返し、実行を終了します。
これで、ユニバーサルアナリストエージェントオブジェクトのメソッド構築に使用されるアルゴリズムの解説は終了です。このクラスの完全なコードとすべてのメソッドは添付ファイルにあります。
マネージャオブジェクト
次の作業段階は、マネージャエージェントオブジェクトの構築です。ここで、わずかな概念上のずれが生じます。一方で、ユニバーサルエージェントを構築し、マネージャとしても機能させる方法について議論してきました。他方で、マネージャの役割は、すべてのエージェントの結果を統合し、その行動を調整することです。つまり、複数の情報源から情報を受け取る必要があります。
この実装は、さまざまな見方ができます。たとえば、先に構築したユニバーサルエージェントを管理機能を持つ形に適応させたものと見ることもできます。実際、ユニバーサルエージェントクラスは新しいオブジェクトの親クラスとして機能しており、その構造は下記の通りです。
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
マネージャオブジェクトでは、すべての内部エージェントを統合することで外部データフローを最小化しています。この構成により、マネージャは自己完結型のFinConフレームワークとして認識することも可能です。しかし、これは解釈の問題に過ぎません。ここでは、新しいオブジェクトの機能的能力の開発に焦点を当てます。
新しいオブジェクトの構造では、再びおなじみのオーバーライド可能なメソッドのセットと、内部オブジェクトが確認できます。これらの役割は、クラスメソッドのアルゴリズムを設計する中で順次検討していきます。
すべての内部オブジェクトは静的として宣言されているため、コンストラクタとデストラクタを空のままにすることができます。宣言済みおよび継承されたすべてのオブジェクトの初期化は、Initメソッド内でおこないます。
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
Initメソッドでは、通常通り親クラスのメソッドを呼び出しますが、ここには微妙なニュアンスがあります。マネージャの初期データは、内部エージェントの作業結果です。したがって、マネージャの入力ウィンドウは単一エージェントの結果ベクトルの次元に対応し、シーケンス長はリスク評価エージェントを含む内部エージェントの総数に等しくなります。
マネージャは、異なる観点から現在の環境を分析する2種類のアナリストエージェントを扱います。入力データの第2の投影を取得するために、行列転置オブジェクトを使用します。
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
次に、アナリストエージェントの初期化ループを2つ連続で整理します。
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
さらに、リスクコントロールエージェントを追加します。このエージェントの入力は現在のアカウント状態を表すベクトルであり、初期化パラメータで明示的に指定されています。
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
また、すべての内部エージェントの結果を連結するオブジェクトも必要です。この結合された出力は、親クラスから継承するマネージャエージェントの入力として使用されます。
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
特に強調しておきたいのは、口座状態情報は専用のデータバッファによって表現される補助的なデータストリームを通じて取得されるという点です。しかし、初期化されたリスクコントロールエージェントが正しく動作するためには、この入力データを保持するニューラルレイヤーオブジェクトが必要となります。そのため、第2データストリームからの情報を転送するための内部オブジェクトを作成します。
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
すべての必要な操作が完了すると、メソッドは呼び出し元プログラムに論理的な成功フラグを返し、実行を終了します。
次に、feedForwardメソッド内でフィードフォワードアルゴリズムを構築します。この場合、2つの入力データストリームを扱います。主ストリームは分析対象となる環境状態を記述するテンソルを提供し、第2ストリームはモデルの運用結果を示す口座状態ベクトルとして財務情報を運びます。
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
メソッドの内部では、まず簡単な前処理をおこないます。この処理では、第2入力データオブジェクト(口座状態)の出力バッファポインタを、対応するデータストリームのバッファに置き換えます。同時に、主ストリームから得られる入力データテンソルを転置します。
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
これらの準備ステップが完了した後、生成されたデータをアナリストエージェントに渡し、分析および提案生成をおこないます。
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
各エージェントの出力は、その後、単一のオブジェクトへと連結されます。
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
連結された結果は、すべてのエージェントの提案に基づいて最終的な取引判断をおこなうマネージャへと渡されます。
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
論理的な結果は呼び出し元プログラムに返されます。
これにより、マネージャメソッドを構築するために使用されるアルゴリズムの説明は完了です。バックプロパゲーションメソッドについては、独立した学習課題として残されています。クラスの完全な実装およびすべてのメソッドの詳細は、添付の資料をご参照ください。
モデルアーキテクチャ
学習可能なモデルのアーキテクチャについて、いくつか述べておく必要があります。本記事の準備において学習されたモデルは、取引意思決定エージェントのみでした。これは、FinConフレームワーク自体のエージェントと混同されるべきものではありません。
学習済みモデルのアーキテクチャは、FinAgent手法に関する先行研究から、ほぼ変更されることなく引き継がれました。ただし、FinConフレームワークで実装されたアプローチを統合できるようにするため、ニューラル層が1つだけ置き換えられました。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
完全なモデルアーキテクチャのコードは、添付資料に含まれています。また、学習およびテストに使用したプログラムも含まれています。これらのスクリプトは先行研究から修正なしで移行されたものであるため、ここでは詳細な分析はおこないません。
テスト
直近の2つの記事では、FinConフレームワークに焦点を当て、その中核原理を詳細に検討しました。フレームワークメソッドの解釈はMQL5で実装されており、実際の過去データを用いて、これらの実装の有効性を評価する段階に来ています。
なお、ここで提示する実装はオリジナルのものとは大きく異なっており、そのことが結果に自然と影響している点に留意する必要があります。したがって、ここで言及できるのは、実装されたアプローチの効率評価のみであり、オリジナル結果の再現についてではありません。
モデルの学習には、2024年のEUR/USDにおけるH1データを使用しました。アルゴリズム性能の評価に専念するため、分析対象となるインジケーターのパラメータは変更せずにそのまま使用しました。
学習用データセットは、ランダムに初期化されたパラメータを持つ複数モデルを用いた複数回の実行結果から構成されました。さらに、Real-ORL手法を用いて、利用可能な市場シグナルデータから得られた成功例も含めました。これにより、データセットには正例が追加され、想定される市場シナリオのカバレッジが拡張されました。
学習中には、エージェントに対して「ほぼ最適な」目標行動を生成するアルゴリズムを使用しました。これにより、データセットを継続的に更新することなくモデルを学習させることが可能になります。ただし、状態空間のカバレッジを拡張することで学習効果をさらに高めるため、定期的なデータ更新を推奨します。
最終的なテストは、他のすべてのパラメータを変更せず、2025年1月の利用可能なデータを用いて実施しました。結果は以下の通りです。
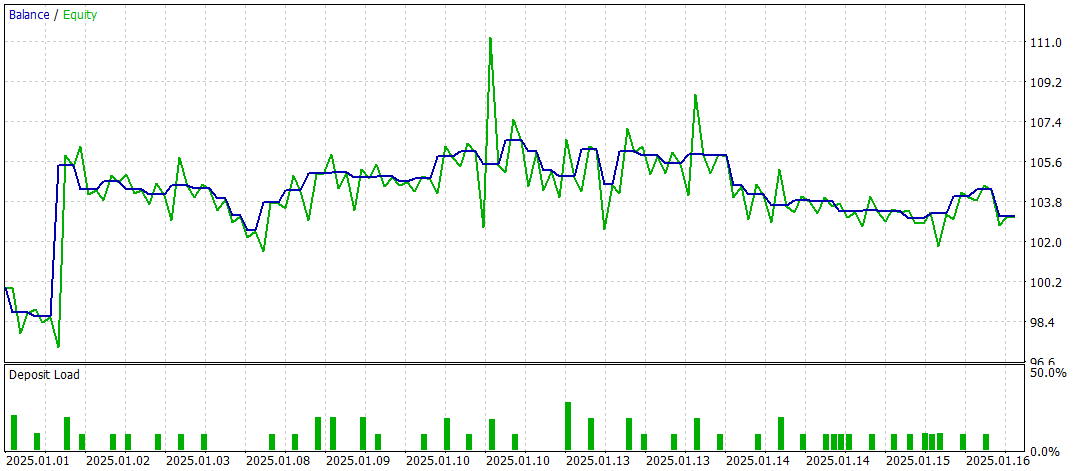
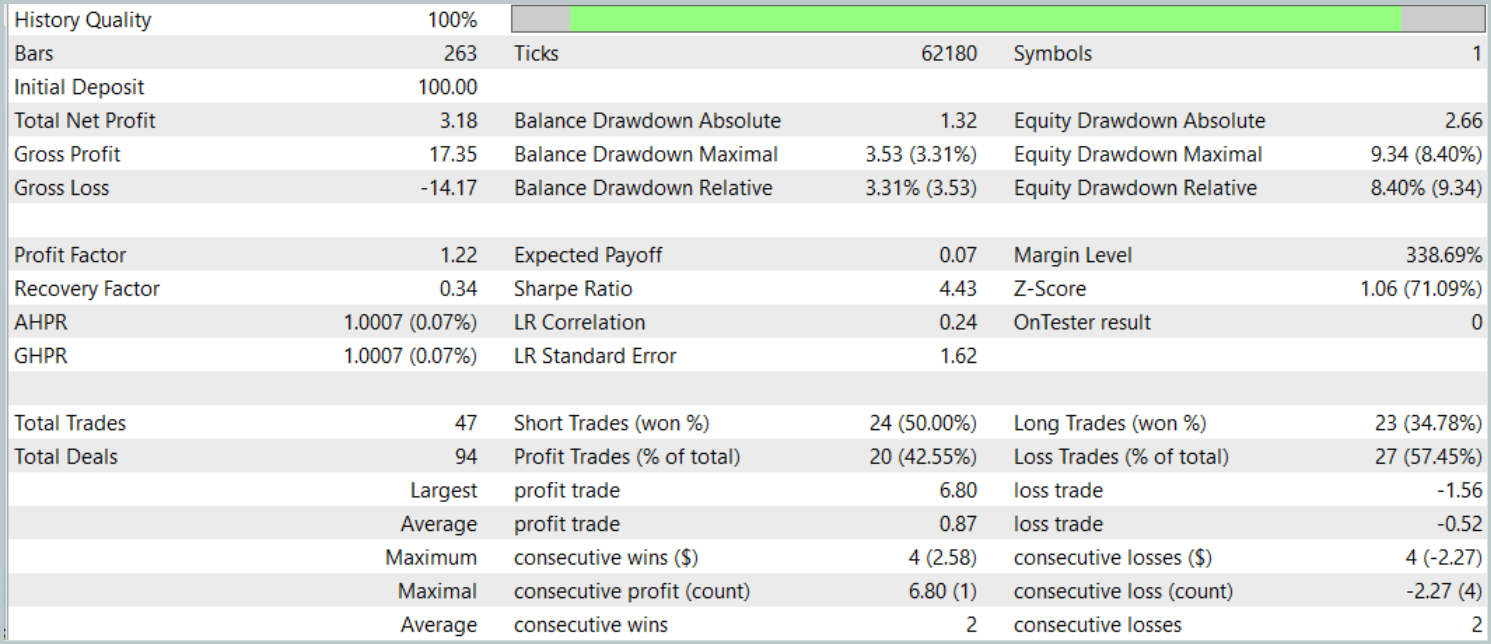
テスト結果からは、モデルの有効性について一長一短の評価が得られました。テスト期間中、モデルは47回の取引を通じて利益を上げましたが、そのうち成功した取引は42%にとどまりました。さらに、残高の増加の大部分は単一の利益取引によるものであり、それ以外の期間では残高曲線は狭い範囲内で推移していました。このことから、モデルにはさらなる最適化が必要であることが示唆されます。
結論
本記事では、FinConフレームワークの主要コンポーネントと機能的特性、ならびに取引意思決定の自動化および最適化における利点について検討しました。実践的なセクションでは、提案された手法をMQL5で実装しました。実際の過去データを用いてモデルを構築・学習し、その性能を評価しました。しかしながら、テスト結果は、モデルが一定の可能性を示している一方で、より安定し一貫して高い性能を達成するためには、さらなる改良と最適化が必要であることを示しています。
参照文献
- FinCon:A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- 本連載の他の記事
記事で使用されているプログラム
| # | 名前 | 種類 | 説明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16937
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索