
初級から中級まで:テンプレートとtypename(V)

はじめに
前回の「初級から中級まで:テンプレートとtypename (IV)」では、テンプレートを作成することで型を一般化し、事実上データ型のオーバーロードを作る方法をできるだけわかりやすく説明しました。しかし、その記事の最後で、多くの読者にとって理解が難しかったかもしれない内容を紹介しました。それは、テンプレートとして実装された関数や手続きにデータを渡す方法です。この概念にはより詳細な説明が必要であるため、今回の記事ではそのテーマに専念することにしました。さらに、このテーマにはもうひとつ密接に関連する概念があります。それは、テンプレートを使って特定の解決策を実装できるかどうかの違いを生む可能性のある概念です。
そこでこの記事を正しく始めるために、前回の記事の最後のコードが実際に動作する理由を、新しいトピックとして説明していきます。
視野を広げる
前回の記事では、少し珍しい実装をおこないました。多くの方にとって、これまで見たことのないような内容だったのではないかと思います。これが何を意味するのか正しく説明するためには、使用したコードを振り返る必要があります。以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 <T> &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
コード01
前回の記事のコードで十分に試した方にとって、このコード01は目を引いたはずです。特に注目すべきは、35行目で宣言されている手続きの部分です。コード01でなぜこのように宣言されているのか、そして重要なのはなぜそうする必要があるのかを理解するために、もう少し詳しく見ていきます。
まず理解しておくべきことは、35行目の手続きはコンパイラが実行可能コードを生成する過程でオーバーロードされるということです。前回の記事でも述べた通り、私は挑戦として「コード01と同じ処理をおこなうが、35行目で実装されている、テンプレートを用いた手続きのオーバーロードで実装する」方法を提案しました。この演習の目的は、なぜ手続きをあの特定の書き方で宣言する必要があるのかを明確にすることです。
理論上は簡単に思えますが、実際にはやや複雑です。そこで一緒に考えていきましょう。これにより、コード01の手続き宣言がなぜそのように書かれているのかを理解できます。
手続き全体を変更するのではなく、下記の断片(フラグメント01)の部分だけを扱います。
. . . 33. //+------------------------------------------------------------------+ 34. void Swap(un_01 <ulong> &arg) 35. { 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. arg.u8_bits[i] = arg.u8_bits[j]; 40. arg.u8_bits[j] = tmp; 41. } 42. } 43. //+------------------------------------------------------------------+ 44. void Swap(un_01 <ushort> &arg) 45. { 46. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 47. { 48. tmp = arg.u8_bits[i]; 49. arg.u8_bits[i] = arg.u8_bits[j]; 50. arg.u8_bits[j] = tmp; 51. } 52. } 53. //+------------------------------------------------------------------+
フラグメント01
このフラグメント01は、コード01の35行目の手続きを置き換えたものです。注意してください。フラグメント01が示す内容は、コンパイラがコード01の手続きを翻訳・オーバーロードするときに生成する正確なコードです。ただし、フラグメント01ではulongとushort型だけを扱っています。コード01はすべてのプリミティブ型に対応しています。
では、なぜフラグメント01のように宣言する必要があるのでしょうか。前回の記事の説明を理解していれば、コード01の14行目と24行目が特定の書き方で宣言される理由がわかるはずです。そして同じ理由で、フラグメント01の34行目と44行目も似た構造で宣言する必要があります。
ここで、以前の記事で扱った「値渡しか参照渡しか」という話を思い出してください。変数を宣言する際には、型と名前の両方を指定する必要があります。関数や手続きの宣言内では、場合によって定数であるかどうかが異なる変数を宣言していることになります。
手続き内での変数宣言は比較的単純に見えますが、疑問が残ります。以前、特殊変数について説明した際、関数もそのひとつになり得ると述べました。今回のケースでは、必要な処理を関数でどう実装できるでしょうか。
これは非常に良い質問です。値を返す場合、手続きとは異なる宣言方法が必要になります。しかし、基本的な概念はこれまで見てきた内容と非常に似ています。返す値はそれ自体が変数のようなものであり、関数名がその変数名として機能すると考えると理解しやすいです。この考え方を応用すれば、コードを正しく実装できます。
一般化された形式に進む前に、フラグメント01に似たアプローチで関数を使う場合を見てみましょう。ただし、関数は手続きと挙動が異なるため、コード01を少し変更します。結果を以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. un_01 <ulong> Swap(const un_01 <ulong> &arg) 33. { 34. un_01 <ulong> local; 35. 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. local.u8_bits[i] = arg.u8_bits[j]; 40. local.u8_bits[j] = tmp; 41. } 42. 43. return local; 44. } 45. //+------------------------------------------------------------------+ 46. un_01 <ushort> Swap(const un_01 <ushort> &arg) 47. { 48. un_01 <ushort> local; 49. 50. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 51. { 52. tmp = arg.u8_bits[i]; 53. local.u8_bits[i] = arg.u8_bits[j]; 54. local.u8_bits[j] = tmp; 55. } 56. 57. return local; 58. } 59. //+------------------------------------------------------------------+
コード02
コード02はコード01と少し異なりますが、実行結果は同じです。MetaTrader 5ターミナルでコード02をコンパイルして実行すると、コード01と同じ出力が得られます。
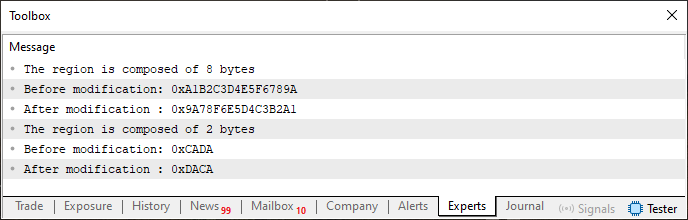
図01
ご覧の通り、結果はコード01を実行した場合とまったく同じです。たとえ手続きをフラグメント01に置き換えた後でも同じです。しかし、フラグメント01はコンパイラがun_01ユニオンで扱えるデータ型を制限しています。
コード02も同じ制限があります。ここで注目してほしいのは、フラグメント01を関数として使えるように書き換えた点です。コード02の19行目と28行目に注目してください。ここではSwapという特殊変数を使用していますが、これは実際には関数であり、読み取り専用の変数として使えるように設計されています。
面白いですね。フラグメント01がコード01の手続きがおこなう処理を示しているように、コード02の関数もテンプレート化することができます。そうすることで、コード01と同じ挙動と、型を自由に選べる柔軟性を得ることができます。そのためには、コード02の関数に共通する部分を一般化すればよく、コンパイラは必要に応じてデータ型を動的に置き換えることが可能です。この概念を理解すれば、コード02をコード03のように書き換えることができます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. template <typename T> 33. un_01 <T> Swap(const un_01 <T> &arg) 34. { 35. un_01 <T> local; 36. 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. local.u8_bits[i] = arg.u8_bits[j]; 41. local.u8_bits[j] = tmp; 42. } 43. 44. return local; 45. } 46. //+------------------------------------------------------------------+
コード03
コード03はコード02の改良版であり、任意のデータ型を使えるようになっています。コンパイラは正しく解釈し、必要なオーバーロードを自動的に生成するため、アプリケーションは問題なく動作します。
これにより、以前は非常に複雑で理解が難しく見えていた処理も、簡単で明確になりました。初心者でもテンプレートを容易に使えるようになります。初めは難しく見えることも、概念を正しく理解すれば簡単になるのです。そのため、私は繰り返し練習することを推奨しています。ただコードの書き方を覚えるのではなく、各文脈で概念がどのように適用されているのかを理解するためです。
ここまでの内容は、多くの人が中級者あるいは上級者向けだと考える部分かもしれません。しかし私の考えでは、ここまで扱った内容はまだ基礎の範囲です。次に、これまでずっと使ってきたにも関わらず明示的に説明してこなかった重要なテーマがあります。それが予約語「typename」です。
このテーマを正しく説明するために、新しいトピックとして落ち着いて解説していきます。始めましょう。
Typename:それは本当は何のためなのか
非常に重要で本質的な質問として、「typenameとは正確には何か?」そして「実際のプログラムでの本当の目的は何か?」というものがあります。これを理解することによって、かなり興味深い種類のコードを実装できるようになります。一般的に言えば、typenameは非常に特定の目的で使われるものであり、多くの場合、型の確認やテストに関連しています。
少なくとも私の知る限りでは、typenameは、コンパイラによってオーバーロードされた関数や手続きが予期せぬ動作をしないことを保証する以外の用途ではほとんど使われません。テンプレートとして何かを実装する際、使用中に不整合や矛盾した結果が出ることは珍しくなく、多くの場合それはテンプレートがある型を正しく扱えていないことが原因です。
また別のケースとして、コンパイラによってオーバーロードされた関数や手続きを、使用するデータ型によって異なる動作をさせたい場合があります。同じ関数でも、ある型では一つの動作を、別の型では別の動作をさせることができます。これは一見混乱を招くように思えますが、実務では必要になることもあります。typenameの仕組みを理解しておくことで、こうした状況に自信をもって対処できるようになります。
これを示すために、少し楽しい例を作ってみましょう。typenameを扱う話題はやや技術的で退屈になりがちです。そこで、少し遊び心を加えながら理解しやすくします。以下のコードを使います。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = arg.u8_bits[i]; 43. local.u8_bits[i] = arg.u8_bits[j]; 44. local.u8_bits[j] = tmp; 45. } 46. 47. return local; 48. } 49. //+------------------------------------------------------------------+
コード04
このコード04では、これまでに学んだことをすべて活用しています。目的は、typenameが実際のプログラムでどのように使えるかを理解することです。具体的には、メモリ(あるいは変数)に格納された情報を左右反転(ミラー)させ、右半分と左半分を入れ替えることです。シンプルです。
コード04を見ると、これまで扱った例の軽微なバリエーションであることがわかります。これは意図的であり、新しい重要な理解点に集中できるようにしています。
MetaTrader 5でこのコード04を実行すると、以下の結果が得られます。
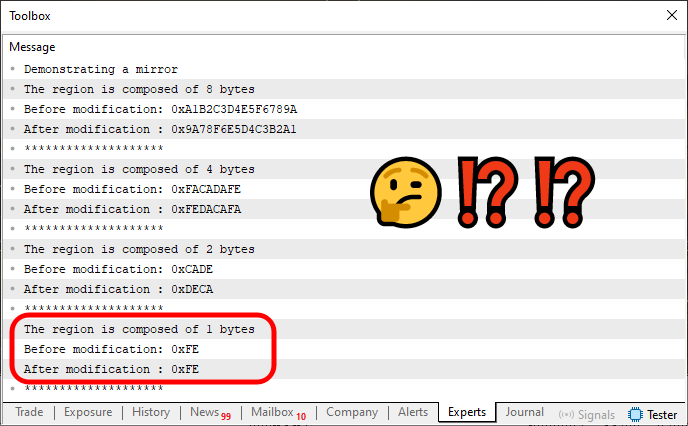
図02
値のひとつがハイライトされていることに注目してください。理由は単純です。反転されていないのです。右側が左側と入れ替わっていません。しかし他のすべての値では、反転は完全に機能しています。この問題は、1バイトしか占有しないデータ型を使用した場合に発生します。
MQL5では、この1バイトの条件を満たす型は2種類しかありません。uchar(符号なし)とchar(符号あり)です。ただし、これらの型それぞれに対して個別のオーバーロード呼び出しを実装するのはやや面倒で、操作の統一性が崩れてしまいます。理想的な解決策は、36行目で実装したMirror関数をそのまま使ってこの挙動を処理することです。
しかしここで重要な質問です。「ucharやchar型の値を、反転操作が正しくおこなわれるようにコンパイラにどう扱わせるか」ということです。
方法はいくつもあります。実務的かつ簡単な方法としては、ビットを1つずつ読み取り、右から左、左から右へ入れ替える方法があります。これにより、関数や手続きをオーバーロードする必要はなくなります。ただし、それは今回の目的ではありません。この課題は宿題として考えてみてください。入力情報のビットをひとつずつ入れ替えて反転させる実装に挑戦するのです。概念を確実に理解し、真のプログラマの思考を身につける優れた演習になります。
では現時点のケースではどうすればよいでしょうか。ここで面白い点が出てきます。typenameは、受け取っているデータ型の名前を文字通り教えてくれるのです。つまり、typenameに「この変数やパラメータの型は何か?」と尋ねることができます。この概念をより具体的で理解しやすくするために、コード04に小さな修正を加えます。以下のコードをご覧ください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
コード05
このコード05を実行すると、以下のような出力が得られます。
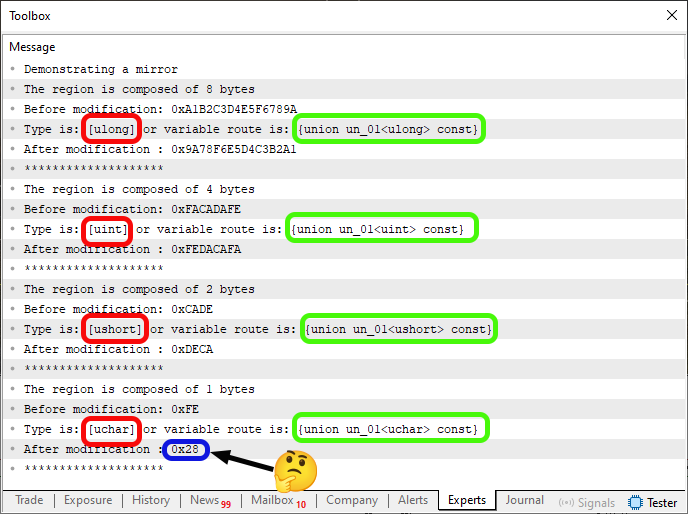
図03
さて、図03では、私にはまったく意味が理解できない表示が現れました。この表示には意味がありません。そのため青でハイライトされています。本当に奇妙です。しかし、重要なのはそこではありません。重要なのは赤と緑でハイライトされた領域です。では、この情報はどこから来たのでしょうか。これはコード05の40行目によって出力されたものです。ここをしっかり理解することが非常に重要です。理解していないと、後で図03の赤や緑でハイライトされた情報を使用する際に問題が発生する可能性があります。
赤いハイライトは、関数で使用されているプリミティブ型をコンパイラに尋ねた結果です。一方、緑のハイライトは、変数自体で実際に使用されているデータ型に対するコンパイラの応答です。この2つの質問には微妙な違いがあります。しかし、回答はまったく異なる場合があります。
通常、多くのプログラマは変数の型をコンパイラに尋ねます。しかし必ずしも期待通りの答えが返るとは限りません。上記の例のように、プリミティブ型は単純でも、変数のデータ型はそれに派生したより複雑な型である場合があります。
とはいえ、この確認方法については今すぐ気にする必要はありません。これらのコードは添付されているので、学習や実験に使用できます。本題に戻ります。私たちが注目すべきは、図03の赤でハイライトされた情報です。これらはすべてコード実装時に宣言された通りに文字列として出力されています。重要なのは、これらの値は文字列であるという点です。これにより、実行時に他の文字列と比較することができます。そして、それこそがここで重要なポイントです。
これで基盤ができました。次に、ucharやcharの単一バイト型を特定し、値を正しく反転させるために小さな修正をおこないます。今回は元のコード04に戻って、必要な調整をおこないます。修正版は以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 41. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
コード06
注目してください。ここでおこなっていることは、さまざまな方法で達成可能です。それぞれに利点と欠点があり、理解しやすいものもあれば難しいものもあります。もしコード06の内容を完全に理解できなくても心配はいりません。添付されたコードを使って自由に変更・実験しながら理解を深めてください。
その前に、まず私が実装した内容と、このコードを実行したときの最終結果を理解しておくことが重要です。そうでないと、誤って変更してしまい、期待した結果とは異なる出力を得てしまう可能性があります。
それでは先に進みましょう。まず、MetaTrader 5ターミナルでプログラムを実行した結果を見てみましょう。以下に示します。
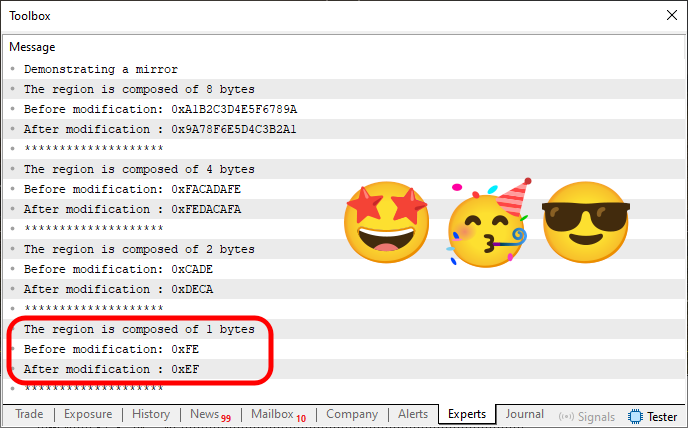
図04
ただただ素晴らしいです。このコードは各変数の値を右半分と左半分で正しく反転させるという目的を達成しました。しかし、コード04と比較すると、コード06で追加されたのは40行目(および41行目の小さな修正)のみです。強調したいのはそこではありません。注目してほしいのは、どの方法で反転させるかを判定するために使用した関数です。
MQL5標準ライブラリのStringFind関数を使用して、typenameが返す文字列内で特定の部分文字列を検索しています。これは非常に重要です。なぜなら、変数の宣言型であるかコンパイラのプリミティブ型であるかに関係なく、検索対象のフラグメントがどちらに現れるか分からないからです。私が特にこの関数を使用している主な理由は、ucharとcharの両方を確実に検出できるということです。違いはucharの先頭の「u」だけです。いずれの場合もテストが実行され、結果が返されます。
ただし、各ケースはユニークです。コードで何を構築しようとしているかによって、同じバイトサイズであっても型名の微妙な違いが最終結果に影響する場合があります。たとえば、ある場合は負の値が存在し、別の場合は存在しないかもしれません。必要に応じて型キャストを明示的に適用することも可能です。コンパイラが生成した型情報に依存する場合は注意してください。
ここからが面白い部分です。図04の結果は正しく、すべて完璧に動作しています。しかし、図03で見られた奇妙な結果も考慮する必要があります。なぜコンパイラが「ちょっとしたいたずら」をしたのか、理由は不明です。コード06を修正してコード05と同じ型情報を表示させると、すべて正常に動作します。しかし、コード05のコンパイル時には奇妙な出力が生成され、図03のような結果になりました。
その証明として、修正版のコードは以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 42. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 43. { 44. tmp = arg.u8_bits[i]; 45. local.u8_bits[i] = arg.u8_bits[j]; 46. local.u8_bits[j] = tmp; 47. } 48. 49. return local; 50. } 51. //+------------------------------------------------------------------+
コード07
コード07はコード05とコード06の組み合わせです。実行すると以下の出力が得られます。
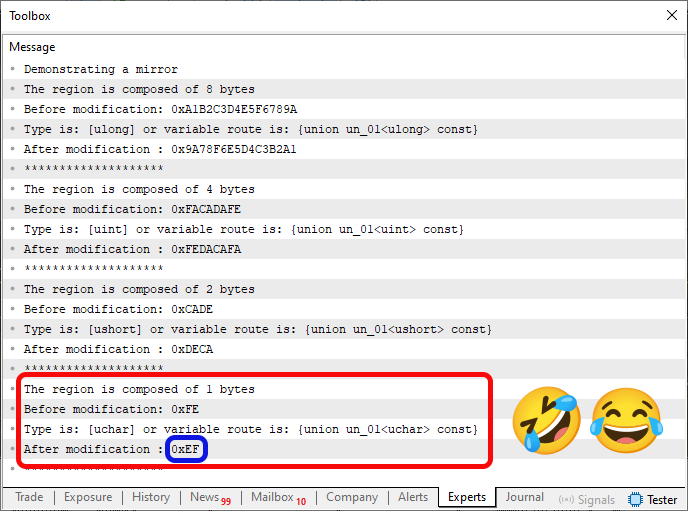
図05
面白いですね。コード05のコンパイルや実行中に実際に何が起こったのかは分かりません。幸いなことに、今回の例は少しの挙動の違いや不整合が問題にならないものです。それでも、こうしたコンパイラの奇妙な動作を見るのは楽しいものです。
最後に
この記事では、関数や手続きのオーバーロードについて、本当に理解できるように設計された説明と演習をまとめました。目的は、同じ関数や手続き名を異なるデータ型で再利用できることを示すことでした。
この学習の旅は、「初級から中級まで:オーバーロード」にあるような簡単な例から始まり、徐々により複雑なケースへと進み、関数や手続きのテンプレート構築まで取り組みました。これらの概念は関数や手続きだけに留まらないため、テンプレートを使ってコーディング作業を軽減する方法を学びました。テンプレートを使うことで、オーバーロードされたバージョンの生成をコンパイラに任せることができ、プログラマとしての作業が格段に楽になります。
しかし、テンプレートの概念はさらに拡張可能です。たとえば、より複雑なデータ型を作成したり管理したりする場合などです。本連載では、特に共用体(union)に焦点を当て、例をそのモデリングの枠組みに限定しました。これにより、型のオーバーロードを実験的に試すことができました。その結果、少ないコードでより多くのことが実現可能になったのです。コンパイラが一貫性と正確性の維持を担当し、私たちはどのプリミティブ型を使用するかを指示するだけで済みました。
さらに進めることも可能です。コードで使用されるプリミティブ型に応じて動作を制御する方法を導入できます。そのために使用するのがtypenameです。これにより、コンパイラによって決定された型であれ、変数自体によって決まった型であれ、正確な型を特定できるのです。
特に初心者の皆さんにとっては、ここまでの内容は複雑または混乱しやすいと感じるかもしれません。しかし忘れないでください。私たちはまだ、プログラミング概念の最も基本的で理解しやすいレベルにいます。ですから、読者の皆さんへのアドバイスは、ここまで取り上げた内容をしっかり学習し、練習することです。これまでの記事で説明された各概念に注意を払ってください。ここから先は、さらに挑戦的で面白くなるからです。そして、プログラミングが本当に好きな方には、MQL5というまったく新しい遊び場が待っています。
次の記事では、さらに魅力的で楽しいトピックの探求を始めます。そこでまたお会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15671
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索