
交易中的神经网络:配备注意力机制(MASAAT)的智代融汇(终章)

概述
投资组合管理在投资决策中扮演着关键角色,旨在经由跨资产的资本动态再配置,强化回报、并降低风险。《基于注意力的融汇学习框架,进行金融投资组合优化》研究并阐述了一种创新的多智代自适应框架 MASAAT,其整合了注意力机制、和时间序列分析。该方式创建了一组交易智代,在多个粒度层级上执行方向性价格走势的交叉分析。这样的设计能持续投资组合再平衡,在高度波动的金融市场中达成盈利与风险之间的有效权衡。
为了捕捉显著的价格变动,智代套用具有不同阈值的方向性走势过滤器。这就能从所分析价格时间序列中提取关键趋势特征,改善对不同强度市场转变的解读。该方法提出了一种新颖的序列词元生成技术,令横断面注意力(CSA)和时态分析(TA)模块能够有效识别多元化的相关性。具体而言,在重造特征映射时,CSA 模块中的序列词元是基于单独资产指标生成,并经由注意力机制进行优化。同时,TA 模块中的词元由时态特征构造,其令识别跨时间点的有意义关系成为可能。
资产和时间点相关评估,衍生自 CSA 和 TA 模块,随后由 MASAAT 智代利用注意力机制组合,检测目标是覆盖观察区间内相对每个时间点的资产依赖性。
下面提供了 MASAAT 框架的原版可视化。
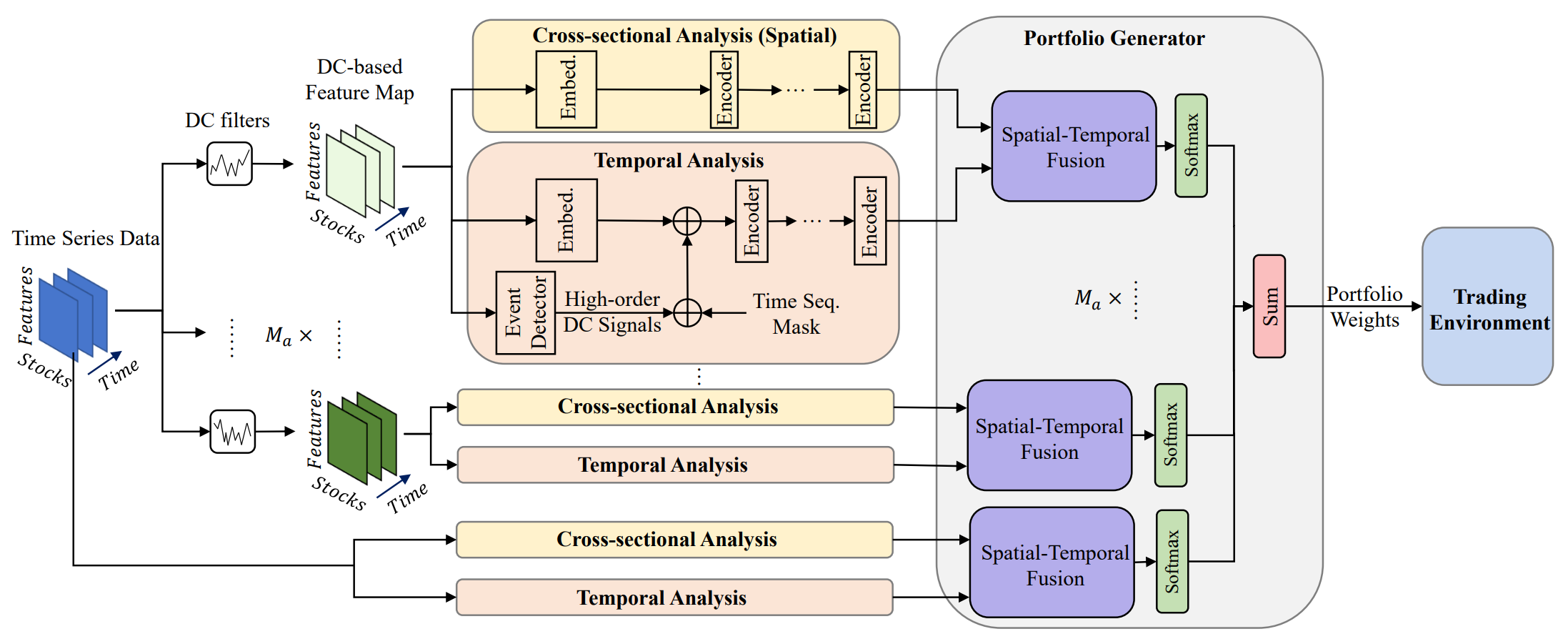
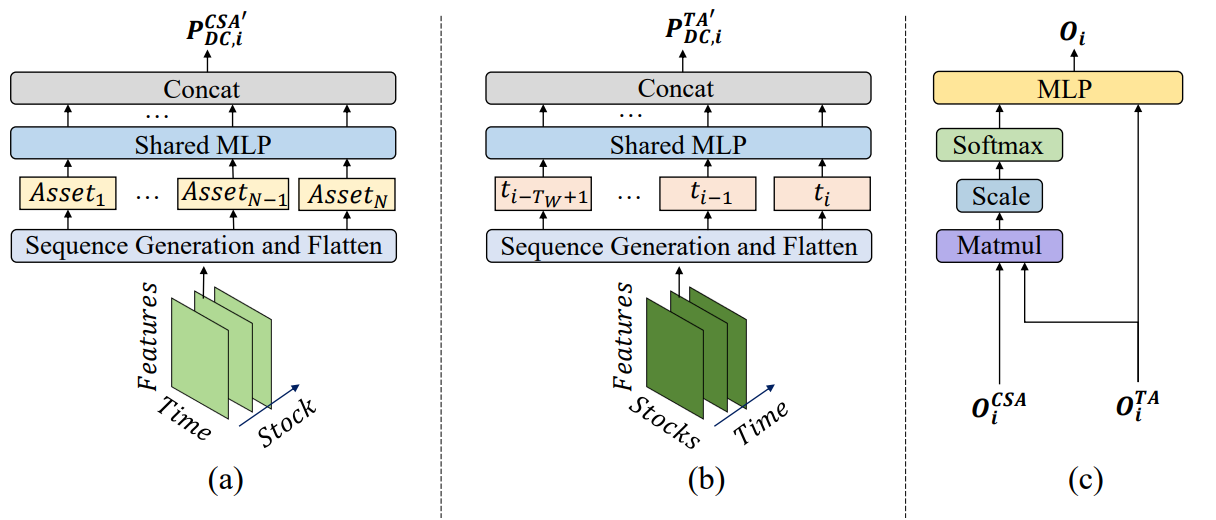
MASAAT 框架展现出清晰定义的模块化架构。这令每个模块都可作为独立类实现,然后将出品的对象集成到统一的结构之中。在前一篇文章中,我们讲述了多智代对象 CNeuronPLRMultiAgentsOCL 的实现算法,其将所分析的多模态时间序列转换为多尺度分段式线性表示。我们还复查了 CSA 的 CNeuronCrossSectionalAnalysis 模块算法。在本文中,我们将继续这条工作线。
时间分析模块
我们在上一篇文章的结尾介绍了实现 CSA 模块的 CNeuronCrossSectionalAnalysis 对象。此外,MASAAT 框架还包括时态分析模块(TA)。它设计用于揭示所分析多模态序列中各时间点之间的依赖性。仔细观察这两个模块的结构,发现它们近乎完全相似。不过,它们会对原始数据进行交叉分析。换言之,它们从不同角度有效地分析序列。
这当然提出了一个直截了当的方案:在将其投喂给之前开发的 CNeuronCrossSectionalAnalysis对象之前,先转置原始序列。此刻,我们面临在三维张量内进行二维转置的需求。重点要记住,我们旨在针对若干多模时间序列并行分析。更准确地说,每个智代都按自己的分段式线性尺度处理源多模序列的表示。由此,对象的输入期待一个三维张量,形式为 [智代、资产、时间]。为了分析跨时间点的依赖关系,我们必须将最后两个维度进行置换。鉴于我们的函数库尚不支持该功能,故必须实现它。
有多种途径能完成三维张量最后两个维度的置换。最直接的解决方案是在 OpenCL 程序中开发一个新内核,然后在主程序中创建一个新类来管理该内核。该方式在计算性能方面可能是最高效的。然而,这对开发者来说也是最费人工的。为了降低编程复杂度,就要牺牲计算资源,我们选用先前创建的应用三个顺序换位层来替代实现该过程。更具体地说,首先,我们将最后两个维度合并为一个,然后应用该二维矩阵换位层:
[智代,[资产,时间]] → [[时间,资产],智代]
接下来,我们使用 CNeuronTransposeRCDOCL对象转置三维张量的前两个维度:
[时间,资产,智代] → [资产,时间,智代]
最后,我们再应用一个二维矩阵换位层,将其它两个维度合并为一个,将智代维度恢复到第一位:
[[资产,时间,智代] → [智代,[时间,资产]]]
该过程在新类 CNeuronTransposeVRCOCL 中实现,其结构如下所示。
class CNeuronTransposeVRCOCL : public CNeuronTransposeOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronTransposeRCDOCL cTransposeRCD; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronTransposeVRCOCL(void) {}; ~CNeuronTransposeVRCOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronTransposeVRCOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
作为父对象,我们运用二维矩阵置换层,并发执行数据置换的最后阶段。这种设计允许我们在新类的主体中仅声明两个静态对象。所有对象的初始化由 Init 方法处理,其接收将被转置张量的所有三个维度作为参数。
bool CNeuronTransposeVRCOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, count * window, variables, optimization_type, batch)) return false;
在该方法内,我们调用父类的同名方法。然而,重点要注意,父对象专用于最终的数据重排。因此,调用父方法时,必须提供正确的参数。具体而言,第一维定义为原始张量最后两个维度的乘积。剩下的维度很直接。
父类方法成功执行后,我们继续初始化内部对象。首先,我们初始化主矩阵置换层。其参数与之前提供给父类的参数相反。
if(!cTranspose.Init(0, 0, OpenCL, variables, count * window, optimization, iBatch)) return false;
接下来,我们初始化负责转置三维张量前两维的对象。这一步实际上是资产维度、和时间维度的互换。
if(!cTransposeRCD.Init(0, 1, OpenCL, count, window, variables, optimization, iBatch)) return false; //--- return true; }
最后,我们将这些操作的逻辑结果返回给调用程序,结束方法的执行。
此处呈现的初始化方法简单易懂。对于该三维张量置换类的其它方法,也可说均为相同情况。例如,在 feedForward 方法中,我们顺序调用内部对象的相应方法,过程由父类的同名方法最终完成。
bool CNeuronTransposeVRCOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!cTransposeRCD.FeedForward(cTranspose.AsObject())) return false; //--- return CNeuronTransposeOCL::feedForward(cTransposeRCD.AsObject()); }
反向通验方法的算法已在附件中单独提供。鉴于该对象不包含可训练参数,我们不会在此详研。
现在我们有了必要的数据置换对象,就可以继续实现时态分析模块(TA),其算法在 CNeuronTemporalAnalysis 类中实现。该新类的功能实在简单。我们转置输入数据,然后应用横断面注意力(CSA)模块的机制。新对象的结构如下所示。
class CNeuronTemporalAnalysis : public CNeuronCrossSectionalAnalysis { protected: CNeuronTransposeVRCOCL cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTemporalAnalysis(void) {}; ~CNeuronTemporalAnalysis(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) const override { return defNeuronTemporalAnalysis; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
作为父类,我们使用横断面注意力模块。如早前所述,该模块的功能奠定了我们算法的基础。我们仅添加一个内部对象,用来置换三维张量最后两个维度。新对象和继承对象的初始化在 Init 方法里执行,与其对应的父类参数结构相呼应。
bool CNeuronTemporalAnalysis::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronCrossSectionalAnalysis::Init(numOutputs, myIndex, open_cl, 3 * units_count, window_key, heads, heads_kv, window / 3, layers, layers_to_one_kv, variables, optimization_type, batch)) return false;
在该方法内,我们立即调用父类的初始化方法,传递所有接收到的参数。
此刻,我们应当被注意实现中的若干细微差别。首先,外部参数指定原始数据的维度。回想一下,我们计划将三维张量的最后两个维度转置。因此,当参数传递给父类初始化方法时,我们交换对应的维度。
其次,我们必须考虑输入数据的结构。该对象接收多智代趋势检测模块的输出。相应地,模型输入由一个张量组成,表示多模时间序列的分段式线性近似。在我们的实现中,单变量时间序列的每个有向区段由三个元素表示。逻辑上,分析期间应将这些数据视为一个整体单元。因此,我们将分析窗口大小增加三倍,并相应地将序列长度减少三倍。
在父类初始化成功完成后,我们调用内部三维张量转置对象的初始化方法。
if(!cTranspose.Init(0, 0, OpenCL,variables, units_count, window, optimization_type, batch)) return false; //--- return true; }
然后,我们将操作的逻辑结果返回给调用程序,终结该方法。
CNeuronTemporalAnalysis 对象的前馈和反向通验算法相当简单。因此,本文不打算详细展开。该类及其所有方法的完整源代码均可在本文附件中找到。
投资组合生成模块
在 CSA 和 TA 模块的输出处,我们分别得到有关资产至资产、以及时间至时间的丰富依赖性信息。这些信息通过注意力机制被整合,令每个智代能够构造自己的投资组合版本。更准确地说,每个智代首先形成参考了时态依赖性的资产嵌入。这些嵌入随后通过一个全连通层,生成一个权重矢量,表示资产组合配比,所有矢量元素的合计等于 1。
投资组合生成函数的数学表示如下:
![]()
基于投资组合提案,构造最终的投资组合代表。
此处我们略微偏离了作者最初阐述的 MASAAT 框架。然而,这种偏离更多是逻辑上的,而非数学本质。在实际中,紧随原始函数的同时,我们重新解释得到的输出。
我们与 MASAAT 作者的任务有所不同。在模型输出处,我们旨在获得一个智代的动作向量,即指定交易方向、仓位规模、以及止损和止盈价位。为了判定仓位规模,我们需要账户状态信息,加上金融产品动态,但来自输入的数据缺少这些信息。因此,在我们实现 MASAAT 时,我们期望输出是一个隐藏状态嵌入,封装了当前市场形势的综合分析。
MASAAT 的最终功能在 CNeuronPortfolioGenerator 对象中实现,其结构如下所示。
class CNeuronPortfolioGenerator : public CNeuronBaseOCL { protected: uint iAssets; uint iTimePoints; uint iAgents; uint iDimension; //--- CNeuronBaseOCL cAssetTime[2]; CNeuronTransposeVRCOCL cTransposeVRC; CNeuronSoftMaxOCL cSoftMax; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPortfolioGenerator(void) {}; ~CNeuronPortfolioGenerator(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronPortfolioGenerator; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
在该新类结构中,我们声明了几个内部对象,其函数将在方法实现过程中描述。所有内部对象都声明为静态,允许我们保持类的构造和析构函数为空。这些声明和继承的内部对象的初始化均在 Init 方法中执行。请注意这里的一些细微差别。
bool CNeuronPortfolioGenerator::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(assets <= 0 || time_points <= 0 || dimension <= 0 || agents <= 0) return false;
该方法包含若干参数,需进行澄清:
- assets — CSA 模块中所分析资产的数量;
- time_points — TA 模块中所分析时间点的数量;
- dimension — 所分析序列中每个元素的嵌入向量大小(CSA 和 TA 模块共有);
- agents — 智代的数量;
- projection — 所分析状态在模块输出处的大小。
在方法内部,我们首先验证参数值。所有这些都必须大于零。然后我们调用父类初始化方法,传递所分析状态的投影大小。它对应于模块输出时的预期张量。
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, projection, optimization_type, batch)) return false;
父类初始化执行成功后,我们将外部参数值存储在内部变量之中。
iAssets = assets; iTimePoints = time_points; iDimension = dimension; iAgents = agents;
接着我们开始初始化内部对象。回头参考早前讲述的公式,我们注意到 TA 模块输出被用过两次:一次是转置形式,一次是原始形式。
回想 TA 模块输出一个三维张量 [智代、时间、嵌入]。由此,在这种情况下,我们必须用一个三维张量对象转置最后两个维度。
if(!cTransposeVRC.Init(0, 0, OpenCL, iAgents, iTimePoints, iDimension, optimization, iBatch)) return false;
接下来,我们将 CSA 模块结果乘以转置的 TA 输出。矩阵乘法继承自父类。为了存储结果,我们初始化一个内部全连接层。
if(!cAssetTime[0].Init(0, 1, OpenCL, iAssets * iTimePoints * iAgents, optimization, iBatch)) return false; cAssetTime[0].SetActivationFunction(None);
所得数值调用 Softmax 函数归一化。
if(!cSoftMax.Init(0, 2, OpenCL, cAssetTime[0].Neurons(), optimization, iBatch)) return false; cSoftMax.SetHeads(iAssets * iAgents);
需要强调的是,每个资产、每个智代都要执行归一化。因此,归一化头的数量等于资产数量与智代数量的乘积。
在跨智代的各个资产层面,归一化系数作为各时间点的注意力权重。将该系数矩阵乘以 TA 输出,我们得到所分析资产的嵌入。为了存储这些嵌入,我们初始化另一个全连接层。
if(!cAssetTime[1].Init(Neurons(), 3, OpenCL, iAssets * iDimension * iAgents, optimization, iBatch)) return false; cAssetTime[1].SetActivationFunction(None); //--- return true; }
为了将所有智代生成的嵌入投影为所分析环境的统一表示,我们采用了全连接层。此处重点要注意的是,这个全连接层是我们类的父对象。基于该事实,我们避免创建额外的内层,而是用父类功能替代。在最后一的内层,我们仅指定输出连接数量,与由外部程序提供的投影大小相对应。
所有内部对象成功初始化之后,我们将这些操作的逻辑结果返回给调用程序,并终结该方法。
我们下一阶段的工作是在 feedForward 方法中开发前馈算法。重点要注意,在这种情况下我们正在应对两个输入数据来源。同时,我们必须记住时态分析模块的结果会被用到两次。这种情况迫使我们将这条信息流指定为主要信息流。
bool CNeuronPortfolioGenerator::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false; //--- if(!cTransposeVRC.FeedForward(NeuronOCL)) return false;
在该方法内,我们首先验证指向第二个数据源的指针,并对第一个数据源进行转置。这些准备步骤完成后,我们继续实际计算。首先,我们将第二个数据源的张量乘以第一个数据源的转置张量。
if(!MatMul(SecondInput, cTransposeVRC.getOutput(), cAssetTime[0].getOutput(), iAssets, iDimension, iTimePoints, iAgents)) return false;
结果调用 SoftMax 函数归一化。
if(!cSoftMax.FeedForward(cAssetTime[0].AsObject())) return false;
然后它们会乘以原始信息流的数据。
if(!MatMul(cSoftMax.getOutput(), NeuronOCL.getOutput(), cAssetTime[1].getOutput(), iAssets, iTimePoints, iDimension, iAgents)) return false;
最后,利用父类功能,我们将获得的数据投影到指定的子空间之中。
return CNeuronBaseOCL::feedForward(cAssetTime[1].AsObject()); }
这些操作的逻辑结果会返回给调用程序,并结束方法。
前馈过程实现完成后,我们转到反向传播算法。于此,我们首先检验误差梯度分布法 calcInputGradients。
bool CNeuronPortfolioGenerator::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient || !SecondInput) return false;
方法参数包括指向输入数据对象的指针,以及两条信息流对应的误差梯度。在方法主体中,我们立即验证指针的有效性。如果指针无效,后续操作将毫无意义。
正如您所知,误差梯度的传播完全遵循前馈信息流的结构,仅逆反。该方法的操作从调用父类同名方法开始,将梯度传播到内部对象。
if(!CNeuronBaseOCL::calcInputGradients(cAssetTime[1].AsObject())) return false;
接下来,我们调用误差梯度分布方法进行矩阵乘法,将数据往下传递到输入层和内部的 Softmax 层。
if(!MatMulGrad(cSoftMax.getOutput(), cSoftMax.getGradient(), NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cAssetTime[1].getGradient(), iAssets, iTimePoints, iDimension, iAgents)) return false;
然而,重点要记住,主要信息流输入级别的误差梯度必须来自两个不同的流。因此,该阶段获得的值会存储在数据置换对象的辅助缓冲区之中。
然后我们将误差梯度传播回 Softmax 层,回到未归一化系数的级别。
if(!cAssetTime[0].calcHiddenGradients(cSoftMax.AsObject())) return false;
之后,我们将所得梯度分派到第二个数据源,和我们的置换层。
if(!MatMulGrad(SecondInput, SecondGradient, cTransposeVRC.getOutput(), cTransposeVRC.getGradient(), cAssetTime[0].getGradient(), iAssets, iDimension, iTimePoints, iAgents)) return false;
此刻,我们立即检查第二个数据源的激活函数,并在必要时使用相应导数调整误差梯度。
if(SecondActivation != None) if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false;
在该阶段,梯度已传递给 CSA 模块(这种情况下为第二数据源)。剩下的就是完成梯度向时态注意力模块(主要信息流)的转移。该模块通过两条信息流接收梯度:注意力系数,和直接结果。这两条流的数据目前存储在数据置换对象的不同缓冲区当中。在主梯度缓冲区中,我们找到注意力系数流的转置值。利用三维张量置换对象的核心功能,我们将这些值传播回输入级。
if(!NeuronOCL.calcHiddenGradients(cTransposeVRC.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cTransposeVRC.getPrevOutput(), NeuronOCL.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
接下来,我们汇总来自两条信息流的数据。最后,我们根据主流激活函数的导数调整所得梯度。
if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cTransposeVRC.getPrevOutput(), NeuronOCL.Activation())) return false; //--- return true; }
该方法的结尾是将操作的逻辑结果返回给调用程序。
至于负责更新模型参数的方法,我建议您独立复查。CNeuronPortfolioGenerator 类及其所有方法的完整源代码已在附件中提供。
MASAAT 框架的汇编
我们已经实现了 MASAAT 框架各个模块的功能,现在是时候将它们汇编到一个统一的结构了。该集成在 CNeuronMASAAT 类中实现。作为其父对象,我们选择了之前创建的 CNeuronPortfolioGenerator,其代表了我们 MASAAT 实现的最后一个模块。这一选择消除了将该模块声明为新类内部对象的必要,因为所有必要的功能都会被继承。新类结构如下所示。
class CNeuronMASAAT : public CNeuronPortfolioGenerator { protected: CNeuronTransposeOCL cTranspose; CNeuronPLRMultiAgentsOCL cPLR; CNeuronBaseOCL cConcat; CNeuronCrossSectionalAnalysis cCrossSectionalAnalysis; CNeuronTemporalAnalysis cTemporalAnalysis; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMASAAT(void) {}; ~CNeuronMASAAT(void) {}; //--- //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMASAAT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
在该类结构中,我们看到了所有先前创建的对象声明。如您所见,所有方法的算法都构建在顺序调用内部对象的对应方法。随着我们推进方法实现,执行顺序会变得更加清晰。
所有内部对象都声明为静态,这令该类的构造和析构函数可以保持留空。所有已声明和继承对象的初始化都在 Init 方法中执行。
bool CNeuronMASAAT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPortfolioGenerator::Init(numOutputs, myIndex, open_cl, window, units_cout / 3, window_key, (uint)min_distance.Size() + 1, projection, optimization_type, batch)) return false;
该方法的参数包括描述输入数据结构,并定义被初始化对象架构的关键常量。
在方法主体中,按照既定做法,我们立即调用父类初始化方法,其中已包含了初始化继承对象和基本接口的逻辑。然而,值得注意的是,在这种情况下,我们把父类作为更广泛算法中的一个全功能模块使用。该模块作为我们 MASAAT 实现的最终输出。因此,我们必须稍微提前看看,判定父对象的正确初始化参数。
在父对象输入处,我们计划提供 CSA 和 TA 模块的结果。对于这些模块,所分析资产数量等于输入窗口大小,而时间点数量对应输入序列的长度。但稍等 — 我们正在将原始多模态时间序列的变换为分段式线性表示。这意味着时间点数量将减少三倍。由此,在将参数传递给父类初始化方法时,我们将原始序列的长度除以三。
进一步验证参数后,我们得出了智代数量。如早前讨论,在构建多智代变换对象时,智代数量由阈值偏差向量的长度决定。然而,如果参考 MASAAT 作者对单独框架组件的分析,我们发现将时间序列的分段式线性表示、与原始序列结合,可以提升模型效率。因此,我们将智代数量增加一个,并分配额外的智代在未修改的原始时间序列上操作。
传递的其它参数不变。
一旦父类初始化成功执行,我们继续初始化新声明的对象。首先,我们初始化数据转置对象。
if(!cTranspose.Init(0, 0, OpenCL, units_cout, window, optimization, iBatch)) return false;
接下来,我们初始化生成分析序列分段式线性表示的多智代变换对象。
if(!cPLR.Init(0, 1, OpenCL, window, units_cout, false, min_distance, optimization, iBatch)) return false;
变换结果与原始数据级联。为此,我们初始化一个对应大小的全连接层。
if(!cConcat.Init(0, 2, OpenCL, cTranspose.Neurons() + cPLR.Neurons(), optimization, iBatch)) return false;
最后,我们初始化 CSA 和 TA 模块。两者都运行在相同的源数据上,因此接收的参数相同。
if(!cCrossSectionalAnalysis.Init(0, 3, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; if(!cTemporalAnalysis.Init(0, 4, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; //--- return true; }
所有内部对象初始化成功后,我们将这些操作的逻辑结果返回给调用程序,并终结该方法。
接下来我们进入 feedForward 方法中的前向通验算法。此处的一切都很简单。该方法参数提供了指向输入数据对象的指针,我们会立即将其传递给置换对象的同名方法。
bool CNeuronMASAAT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
所得数据随后被转换为多分段式线性时间序列表示的版本,输出与原始数据级联,尽管是以置换形式。
if(!cPLR.FeedForward(cTranspose.AsObject())) return false; if(!Concat(cTranspose.getOutput(), cPLR.getOutput(), cConcat.getOutput(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
准备好的数据随后传递到 CSA 和 TA 模块,其输出再提供给对应的父类方法。
if(!cCrossSectionalAnalysis.FeedForward(cConcat.AsObject())) return false; if(!cTemporalAnalysis.FeedForward(cConcat.AsObject())) return false; //--- return CNeuronPortfolioGenerator::feedForward(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput()); }
然后,该方法将操作的逻辑结果返回给调用方,并结束。
前向通验方法表面上看似简单,背后隐藏着信息流的复杂分支。注意,转置的原始数据和级联张量都会被用到两次。这导致了在 calcInputGradients 方法中误差梯度分布组织上的复杂性。
在该方法的参数中,我们收到一个指向输入数据对象的指针,其必须接收误差梯度。在方法主体中,我们立即检查所接收指针的相关性。
bool CNeuronMASAAT::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
随后,我们调用父类的同名方法,根据 CSA 和 TA 模块对模型输出的影响分配误差梯度。
if(!CNeuronPortfolioGenerator::calcInputGradients(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput(), cCrossSectionalAnalysis.getGradient(), (ENUM_ACTIVATION)cCrossSectionalAnalysis.Activation())) return false;
这两个模块都在级联张量上操作。因此,梯度必须从两个不同的流传播到该张量。首先,我们从一个模块传递梯度。
if(!cConcat.calcHiddenGradients(cCrossSectionalAnalysis.AsObject())) return false;
然后,应用缓冲区替换技术,我们从第二个数据流中提取梯度值,随后将两个来源的信息汇总。
CBufferFloat *grad = cConcat.getGradient(); if(!cConcat.SetGradient(cConcat.getPrevOutput(), false) || !cConcat.calcHiddenGradients(cTemporalAnalysis.AsObject()) || !SumAndNormilize(grad, cConcat.getGradient(), grad, 1, 0, 0, 0, 0, 1) || !cConcat.SetGradient(grad, false)) return false;
级联张量的梯度随后被分派到级联对象之间。此刻,我们必须记住,数据转置对象预期经由另一条流接收梯度。因此,我们在该阶段用到一个辅助数据缓冲区。
if(!DeConcat(cTranspose.getPrevOutput(), cPLR.getGradient(), cConcat.getGradient(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
继续在对象间分派梯度之前,我们先验证修正激活函数导数是否必要。
if(cPLR.Activation() != None) if(!DeActivation(cPLR.getOutput(), cPLR.getGradient(), cPLR.getGradient(), cPLR.Activation())) return false;
接下来,我们将梯度传播到多智代分段线性变换对象中,并汇总两个流的值。
if(!cTranspose.calcHiddenGradients(cPLR.AsObject()) || !SumAndNormilize(cTranspose.getGradient(), cTranspose.getPrevOutput(), cTranspose.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
如有需要,我们根据激活函数导数调整梯度,然后将其传回输入级别。
if(cTranspose.Activation() != None) if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), cTranspose.Activation())) return false; if(!prevLayer.calcHiddenGradients(cTranspose.AsObject())) return false; //--- return true; }
最后,该方法返回操作的逻辑结果给调用程序,并结束。
此刻,我们对 MASAAT 方法算法实现的探讨完毕。全部所呈现类和方法的完整源代码都能在附件中找到。在那里,您还会找到编写本文时用到的所有程序,以及模型架构。我们将简要触及模型架构。我们的 MASAAT 框架实现已集成到参与者模型当中。我们不会在此详研整个架构。它几乎完全继承自我们之前的作品。取而代之,我们看看新层的声明。
在动态窗口大小数组中,我们指定所分析数据窗口的大小,以及输出层产生的隐藏状态张量的长度。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMASAAT; //--- Windows { int temp[] = {BarDescr, LatentCount}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; }
我们三位智代的阈值是通过几何级数生成的。
//--- Min Distance { vector<float> ones = vector<float>::Ones(3); vector<float> cs = ones.CumSum() - 1; descr.radius = pow(ones * 2, cs) * 0.01f; }
其它参数保持标准值。
descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
如前所述,模型的完整架构可在附件中查看。
测试
我们实现 MASAAT 框架方式的 MQL5 版本的工作已抵达其逻辑终结。接下来进入最重要的阶段 — 评估已实现方法在真实历史数据上的有效性。
重点要强调的是,我们评估的是*所实现*的方式,而非 MASAAT 的原始框架。这是因为在实现期间中引入了一些修改。
模型依据 EURUSD 的 2023 年历史数据训练,时间帧为 H1。所有分析指标均以其默认参数设置。
在初始训练阶段,我们取用早期研究收集的数据集,并在训练过程中定期更新,以便适应参与者当前的政策。
经过若干次周期性训练和数据集更新后,我们获得了一项在训练和测试数据集上均具盈利性的政策。
训练政策的最终测试依据 2024 年 1 月的历史数据进行,其它参数保持不变。测试结果呈现如下。
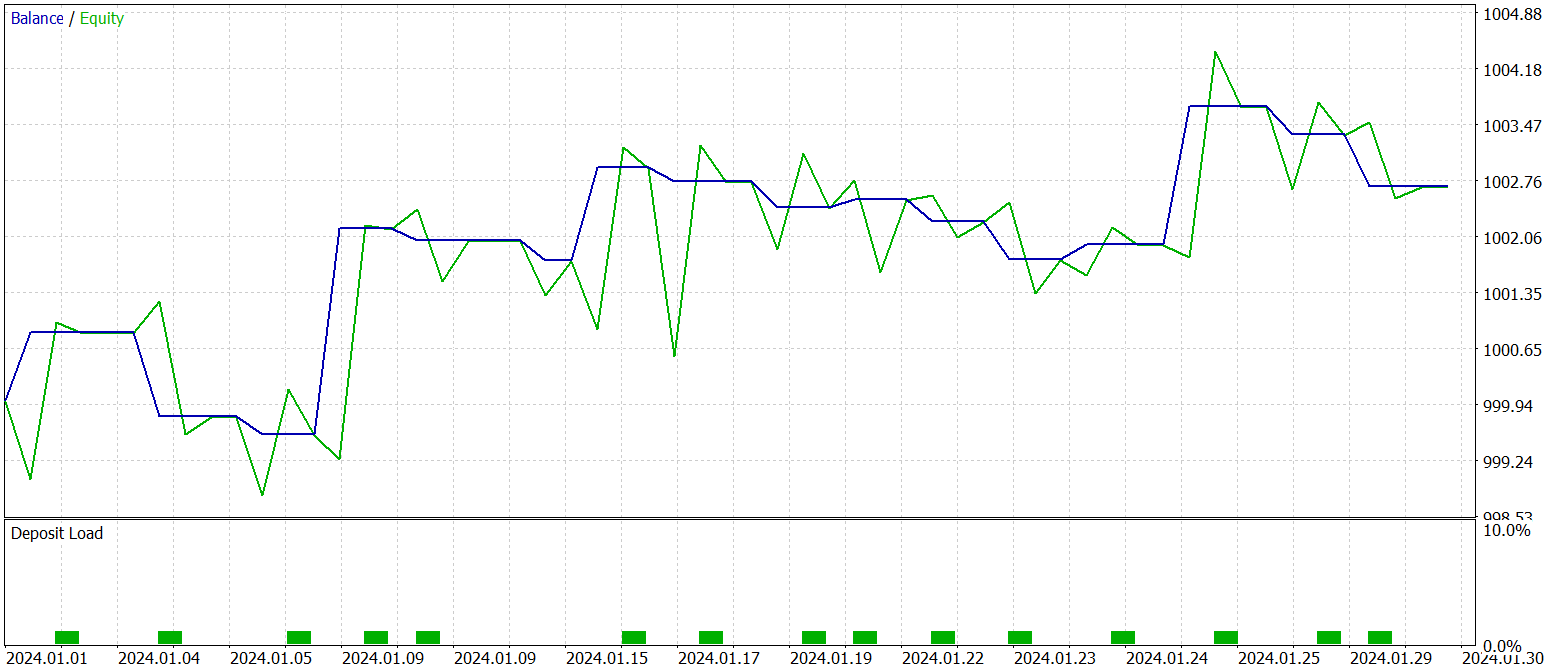
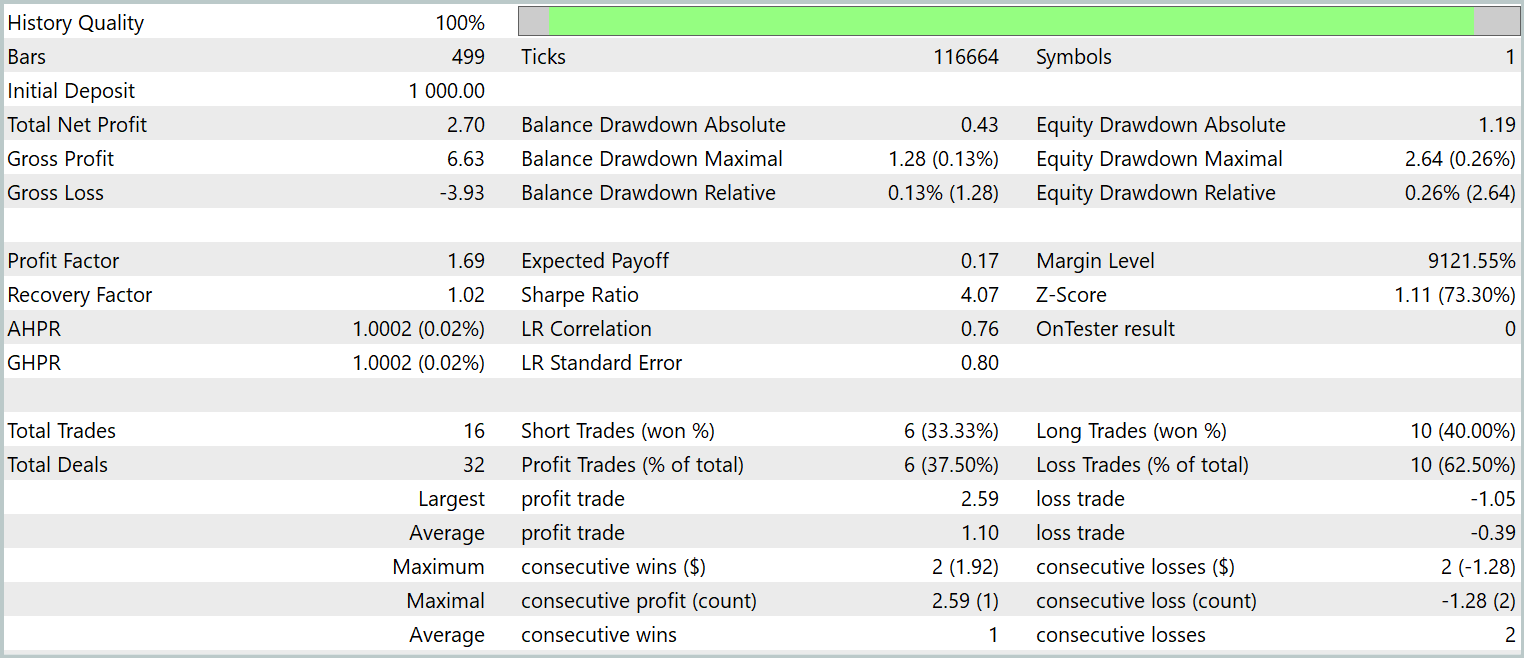
数据展示,该模型在测试期间执行了 16 笔交易。其中略多于三分之一赢利了结。然而,最大盈利交易超过了最大亏损 2.5 倍。甚至,每笔交易的平均盈利是平均亏损的三倍。如是结果,我们观察到账户余额呈明显上升趋势。
结束语
本项工作中,我们验证了多智代自适应 MASAAT 框架,其设计用于优化投资组合。MASAAT 结合了注意力机制、与时间序列分析。该框架采用一组交易智代进行多方面价格数据分析,从而降低交易决策中的偏见。每位智代采用基于注意力的横断面分析机制,识别观察期内资产与时间点之间的相关性。这些信息随后通过时空融合模块进行合并,实现数据的有效整合、及交易策略的强化。
在实操部分,我们利用 MQL5 实现了所提议方法的自我诠释 。我们将这些方式整合到模型,并依据真实历史数据进行训练。训练模型的测试结果展示出所提议方法的潜力。
参考
文章中所用程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | 智能系统 | 收集样本的智能系统 |
| 2 | ResearchRealORL.mq5 | 智能系统 | 利用 Real-ORL 方法收集样本的智能系统 |
| 3 | Study.mq5 | 智能系统 | 模型训练智能系统 |
| 4 | Test.mq5 | 智能系统 | 模型测试智能系统 |
| 5 | Trajectory.mqh | 类库 | 系统状态描述结构 |
| 6 | NeuroNet.mqh | 类库 | 创建神经网络的类库 |
| 7 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16631
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

