
Нейросети в трейдинге: Ансамбль агентов с использованием механизмов внимания (Окончание)

Введение
Управление портфелем финансовых инструментов играет важную роль в инвестиционных решениях, направленных на увеличение доходности и снижение рисков путем динамического перераспределения капитала между активами. В работе "Developing an attention-based ensemble learning framework for financial portfolio optimisation" предложен инновационный мультиагентный адаптивный фреймворк MASAAT, который объединяет механизмы внимания и анализ временных рядов. В рамках предложенного подхода создается множество торговых агентов для перекрестного анализа направленных изменений цен активов на разных уровнях детализации. Такое решение позволяет пересматривать структуру инвестиционного портфеля для эффективного баланса между доходностью и рисками в условиях высокой волатильности финансовых рынков.
Для фиксирования существенных ценовых изменений, агенты используют фильтры направленного движения с различными пороговыми значениями. При этом извлекаются ключевые характеристики трендов анализируемых временных ценовых рядов, что улучшает понимание рыночных переходов различной силы. Предложенный подход вводит новую методику генерации токенов последовательностей, позволяя модулям поперечного анализа на основе внимания (CSA) и временного анализа (TA) эффективно выявлять различные корреляции. В частности, при реконструкции карт признаков, токены последовательностей в модуле CSA формируются на основе показателей отдельных активов, оптимизируемых применением механизмов внимания. В то же время, токены в модуле TA строятся на основе характеристик временных точек, что позволяет выделить значимые связи между отдельными моментами времени.
Оценки корреляции активов и временных точек, собранные в модулях CSA и TA, агенты MASAAT объединяют с помощью механизма внимания, стремясь найти зависимости для каждого актива по отношению к каждой временной точке в течение периода наблюдения.
Авторская визуализация фреймворка MASAAT представлена ниже.
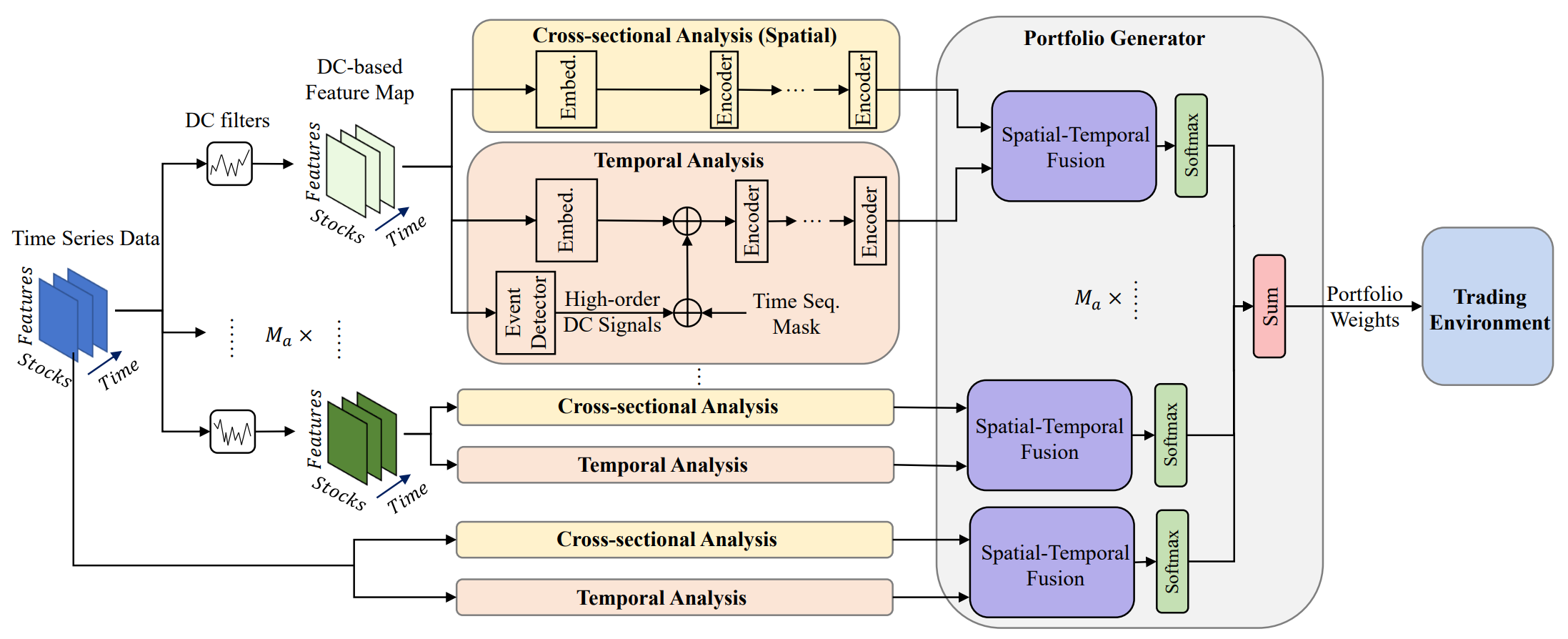
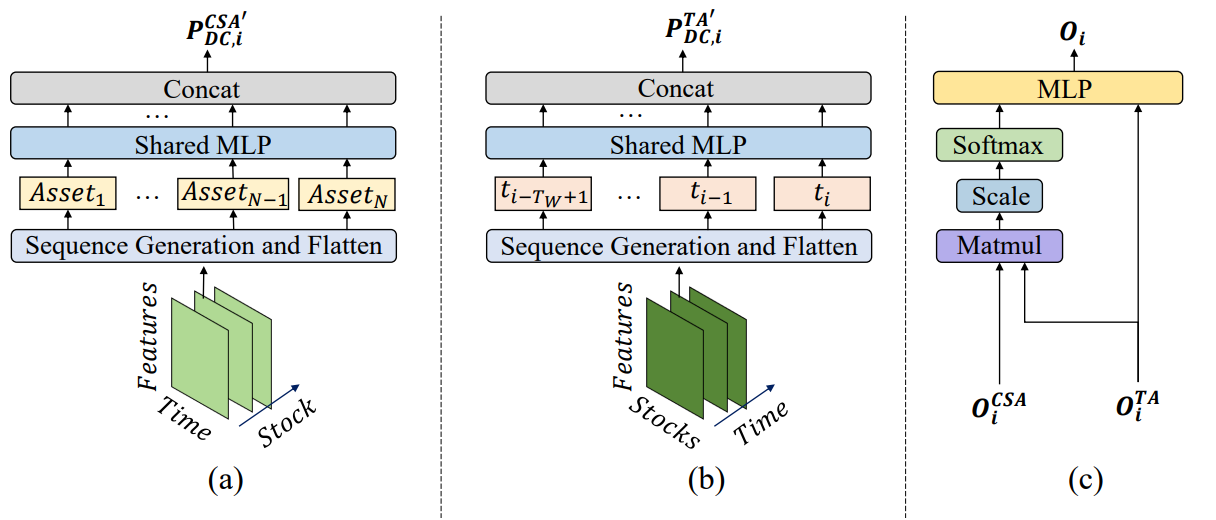
Фреймворк MASAAT имеет ярко выраженную блочную структуру. Это позволяет нам реализовать каждый блок в виде отдельного класса, а затем объединить созданные объекты в единую структуру. В прошлой статье уже были представлены алгоритмы реализации мультиагентного объекта параллельного преобразования анализируемого мультимодального временного ряда в кусочно-линейные представления различного масштаба CNeuronPLRMultiAgentsOCL. А также был рассмотрен алгоритм модуля поперечного внимания активов CSACNeuronCrossSectionalAnalysis. В данной статье мы продолжаем начатую работу.
Модуль временного анализа
Предыдущую статью мы завершили рассмотрением объекта CNeuronCrossSectionalAnalysis, в рамках которого реализован функционал модуля CSA. Параллельно с ним, в структуре фреймворка MASAAT работает модуль временного анализа TA. В нем организован поиск зависимостей между отдельными временными точками анализируемой мультимодальной последовательности. При детальном рассмотрении структуры двух указанных модулей можно найти их практически полное сходство. При этом они осуществляют перекрестный анализ исходных данных. Иными словами, смотрят на анализируемую последовательность с разных сторон.
Здесь напрашивается очевидное решение о транспонировании исходной последовательности перед передачей данных на вход созданного ранее объекта CNeuronCrossSectionalAnalysis. И тут мы сталкиваемся с необходимостью транспонирования двух измерений в трехмерном тензоре. Напомню, что нам предстоит провести параллельный анализ нескольких мультимодальных временных последовательностей. А точнее, каждый агент анализирует свой масштаб кусочно-линейного представления исходной мультимодальной последовательности. Следовательно, на вход объекта мы планируем получать трехмерный тензор [Агент, Актив, Время], и для целей анализа зависимостей временных точек нам предстоит транспонировать исходные данные по двум последним измерениям. Такого функционала в нашей библиотеке еще нет. А значит, нам предстоит его создать.
К решению задачи транспонирования трехмерного тензора по двум последним измерениям можно подойти по-разному. Конечно, первое решение — это решение задачи, что называется, "в лоб". То есть, создание нового кернела на стороне OpenCL-программы, с последующим построением нового класса на стороне основной программы для обслуживания этого кернела. Наверное, это решение наиболее эффективное с точки зрения использования вычислительных ресурсов. Но в то же время, оно наиболее затратное для программиста. Мы же решили сократить затраты программиста за счет вычислительных ресурсов и организовать процесс за счет 3 последовательных ранее созданных слоев транспонирования. А точнее, мы сначала используем слой транспонирования двухмерной матрицы, объединив два последних измерения в одно:
[Агент, [Актив, Время]] → [[Время, Актив], Агент]
Затем используем объект CNeuronTransposeRCDOCL для транспонирования трехмерного тензора по первым двум измерениям:
[Время, Актив, Агент] → [Актив, Время, Агент]
И в завершении, снова используем слой транспонирования матрицы для возврата измерения агентов на первое место, объединив два других измерений в одно:
[[Актив, Время], Агент] → [Агент, [Время, Актив]]
Описанный процесс мы организуем в рамках нового класса CNeuronTransposeVRCOCL, структура которого приведена ниже.
class CNeuronTransposeVRCOCL : public CNeuronTransposeOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronTransposeRCDOCL cTransposeRCD; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronTransposeVRCOCL(void) {}; ~CNeuronTransposeVRCOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronTransposeVRCOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В качестве родительского объекта мы используем слой транспонирования двухмерной матрицы, который одновременно выполняет функции последнего этапа перестановки данных. Это позволяет нам в теле нового класса объявить лишь 2 статичных объекта. Инициализация всех объектов осуществляется в методе Init, в параметрах которого получаем все 3 размерности транспонируемого тензора.
bool CNeuronTransposeVRCOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, count * window, variables, optimization_type, batch)) return false;
В теле метода вызываем одноименный метод родительского класса. Однако здесь стоит обратить внимание, что родительский объект мы будем использовать для финальной перестановки данных. Следовательно, при вызове метода родительского класса мы должны передать корректные параметры. В данном случае, первое измерение определяется как произведение двух последних измерений исходного тензора. Оставшееся измерение, думаю, очевидно.
После успешного выполнения операций метода родительского класса, мы переходим к инициализации внутренних объектов. Вначале инициализируем первичный слой транспонирования матрицы. Его параметры обратны ранее выполненному методу родительского класса.
if(!cTranspose.Init(0, 0, OpenCL, variables, count * window, optimization, iBatch)) return false;
А затем, инициализируем объект транспонирования первых двух измерений трехмерного тензора. Именно здесь мы поменяем местами измерения активов и времени.
if(!cTransposeRCD.Init(0, 1, OpenCL, count, window, variables, optimization, iBatch)) return false; //--- return true; }
Нам остается вернуть логический результат выполнения операций вызывающей программе и завершить работу метода.
Представленный метод инициализации довольно прост и понятен. То же самое можно сказать и об остальных метода представленного класса транспонирования трехмерного тензора. К примеру, в методе прямого прохода feedForward мы последовательно вызываем одноименные методы внутренних объектов, а завершает работу одноименный метод родительского класса.
bool CNeuronTransposeVRCOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!cTransposeRCD.FeedForward(cTranspose.AsObject())) return false; //--- return CNeuronTransposeOCL::feedForward(cTransposeRCD.AsObject()); }
С алгоритмами методов обратного прохода я предлагаю вам ознакомиться самостоятельно во вложении. Тем более объект не содержит обучаемых параметров.
И теперь, когда у нас есть необходимый объект транспонирования данных, мы можем перейти к реализации модуля временного анализа TA, алгоритмы которого реализуем в классе CNeuronTemporalAnalysis. Функционал нового класса будет максимально прост. Мы лишь транспонируем исходные данные, а далее используем средства модуля поперечного внимания активов. Структура нового объекта представлена ниже.
class CNeuronTemporalAnalysis : public CNeuronCrossSectionalAnalysis { protected: CNeuronTransposeVRCOCL cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTemporalAnalysis(void) {}; ~CNeuronTemporalAnalysis(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) const override { return defNeuronTemporalAnalysis; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В качестве родительского класса мы используем объект модуля поперечного внимания активов. Как было сказано выше, функционал этого объекта мы и планируем использовать для реализации основного алгоритма. Мы лишь добавляем внутренний объект транспонирования трехмерного тензора по двум последним измерением. Инициализация нового и унаследованных объектов осуществляется в методе Init, который полностью унаследовал структуру параметров аналогичного метода родительского класса.
bool CNeuronTemporalAnalysis::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronCrossSectionalAnalysis::Init(numOutputs, myIndex, open_cl, 3 * units_count, window_key, heads, heads_kv, window / 3, layers, layers_to_one_kv, variables, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод родительского класса, передав ему все полученные параметры.
И здесь следует обратить внимание на некоторые нюансы нашей реализации. Во-первых, во внешних параметрах мы получаем размерности исходных данных. А я хочу напомнить, что мы предполагаем транспонировать трехмерный тензор исходных данных по последним двум измерениям. Следовательно, при передаче параметров в метод инициализации родительского класса, мы меняем указанные размерности местами.
Во-вторых, необходимо вспомнить структуру получаемых исходных данных. На вход данного объекта мы предполагаем подавать результаты работы мультиагентного блока выявления тенденций. А значит, каждый раз на вход модели мы подаем тензор кусочно-линейного представления мультимодального временного ряда. Реализованный нами вариант кусочно-линейного представления временного ряда подразумевает выделение 3 элементов для сохранения параметров одного направленного отрезка унитарного временного ряда. Логика нам подсказывает, что в процессе анализа мы должны их рассматривать как нечто целое. Поэтому размер анализируемого окна мы увеличиваем в 3 раза и, соответственно, длину последовательности уменьшаем в 3 раза.
После успешного выполнения операций метода инициализации родительского класса, мы вызываем одноименный метод внутреннего объекта транспонирования трехмерного тензора.
if(!cTranspose.Init(0, 0, OpenCL,variables, units_count, window, optimization_type, batch)) return false; //--- return true; }
И завершаем работу метода, возвращая логический результат выполнения операций вызывающей программе.
Алгоритмы методов прямого и обратного проходов объекта временного анализа CNeuronTemporalAnalysis банально просты. Поэтому мы не будем сейчас останавливаться на их рассмотрении, а оставим для самостоятельного изучения. Полный код данного класса и всех его методов вы найдете во вложении к статье.
Модуль генерации портфелей
На выходе блоков CSA и TA мы получаем исходные данные, обогащенные информацией о зависимостях между активами и временными точками, соответственно. Данная информация объединяется с помощью механизма внимания для формирования каждым агентом собственного варианта инвестиционного портфеля. Точнее, сначала каждый агент формирует собственные эмбединги активов с учетом временных зависимостей, а затем, с помощью полносвязного слоя, генерируется вектор долевого представления инвестиционного пакета, где сумма всех элементов вектора равна 1.
Напомню математическое представление функции генерации инвестиционного пакета:
![]()
На основании предложений инвестиционного пакета формируется финальное представление инвестиционного пакета.
Здесь мы немного отступим от авторского представления фреймворка MASAAT. Хотя, надо сказать, наше отступление носит больше логический характер, чем математический. Практически, при полном повторении вышеуказанной функции, мы несколько меняем представление о получаемых результатах.
Дело в том, что наша задача несколько отличается от решаемой авторами фреймворка. На выходе модели мы бы хотели получить вектор действий Агента с указанием направления сделки, её объема, а так же уровней стоп-лосса и тейк-профита. При этом, для определения объема сделки, помимо данных о динамике анализируемого финансового инструмента нам необходима информация и о состоянии счета, отсутствующая в исходных данных. Поэтому на выходе нашего объекта реализации подходов фреймворка MASAAT, мы ожидаем получить некое скрытое состояние, содержащие эмбединг всестороннего анализа текущей рыночной ситуации.
Финальную часть функционала фреймворка MASAAT реализуем в рамках объекта CNeuronPortfolioGenerator, структура которого представлена ниже.
class CNeuronPortfolioGenerator : public CNeuronBaseOCL { protected: uint iAssets; uint iTimePoints; uint iAgents; uint iDimension; //--- CNeuronBaseOCL cAssetTime[2]; CNeuronTransposeVRCOCL cTransposeVRC; CNeuronSoftMaxOCL cSoftMax; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPortfolioGenerator(void) {}; ~CNeuronPortfolioGenerator(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronPortfolioGenerator; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В структуре нового класса мы объявляем несколько внутренних объектов, с функционалом которых познакомимся в процессе реализации методов. Все внутренние объекты мы объявляем статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех объявленных и унаследованных внутренних объектов осуществляется в методе Init. И здесь, надо сказать, есть ряд нюансов.
bool CNeuronPortfolioGenerator::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(assets <= 0 || time_points <= 0 || dimension <= 0 || agents <= 0) return false;
В параметрах метода мы получаем несколько параметров, значение которых требует пояснений:
- assets — количество активов, анализируемых в модуле CSA;
- time_points — количество временных точек, анализируемых в модуле TA;
- dimension — размерность вектора эмбединга одного элемента анализируемой последовательности (общий для модулей CSA и TA);
- agents — количество агентов;
- projection — размер проекции анализируемого состояния на выходе модуля.
В теле метода мы сразу проверяем значения параметров. Все они должны быть, как минимум, больше "0". А затем вызываем метод инициализации родительского класса, передав ему размерность проекции анализируемого состояния. Именно такой тензор мы ожидаем получить на выходе модуля.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, projection, optimization_type, batch)) return false;
После успешного выполнения операций метода родительского класса, мы сохраняем значения внешних параметров во внутренних переменных.
iAssets = assets; iTimePoints = time_points; iDimension = dimension; iAgents = agents;
После чего, мы переходим к инициализации внутренних объектов. И здесь следует обратиться к представленной выше формуле. Из нее следует, что результаты работы модуля временного анализа TA мы используем дважды. Первый раз в транспонированном варианте, а второй раз — нет.
Хочу напомнить, что на выходе модуля TA мы получаем трехмерный тензор с размерностями [Агент, Время, Эмбединг]. Следовательно, в данном случае, нам необходимо использовать объект транспонирования трехмерного тензора по последним двум измерениям.
if(!cTransposeVRC.Init(0, 0, OpenCL, iAgents, iTimePoints, iDimension, optimization, iBatch)) return false;
Далее необходимо умножить результаты модуля CSA на транспонированные данные модуля TA. Метод умножения матриц мы унаследовали от родительского класса. А вот для записи результатов, инициализируем внутренний полносвязный слой.
if(!cAssetTime[0].Init(0, 1, OpenCL, iAssets * iTimePoints * iAgents, optimization, iBatch)) return false; cAssetTime[0].SetActivationFunction(None);
Полученные значения мы нормализуем функцией SoftMax.
if(!cSoftMax.Init(0, 2, OpenCL, cAssetTime[0].Neurons(), optimization, iBatch)) return false; cSoftMax.SetHeads(iAssets * iAgents);
Следует обратить внимание, что нормализация данных осуществляется в разрезе отдельных активов для каждого агента. Поэтому количество голов нормализации укажем, как произведение количества активов на число агентов.
Нормализованные коэффициенты, полученные в результате данной операции, являются множителями внимания к каждой временной точке на уровне отдельно взятого актива в разрезе агентов. Путем умножения матрицы этих коэффициентов на результаты модуля TA, мы получаем эмбединги анализируемых активов. Для записи этих эмбедингов мы инициализируем полносвязный слой.
if(!cAssetTime[1].Init(Neurons(), 3, OpenCL, iAssets * iDimension * iAgents, optimization, iBatch)) return false; cAssetTime[1].SetActivationFunction(None); //--- return true; }
Для проекции множества полученных эмбедингов от всех агентов в единое представление анализируемого состояния окружающей среды, мы воспользуемся полносвязным слоем. И здесь следует обратить внимание на тот момент, что именно объект полносвязного слоя мы использовали в качестве родительского. Воспользовавшись этим обстоятельством, мы не будем создавать дополнительный внутренний полносвязный слой. Его функционал выполнят средства, унаследованные от родительского. Мы лишь в последнем внутреннем слое укажем количество исходящих связей на уровне размера проекции, полученного от внешней программы.
А после успешной инициализации всех внутренних объектов, мы завершаем работу метода, предварительно вернув результаты выполнения операций вызывающей программе.
Следующим этапом нашей работы мы переходим к построению алгоритмов прямого прохода в методе feedForward. Здесь следует обратить внимание, что в данном случае мы имеем дело с двумя источниками исходных данных. При этом мы помним о двойном использовании результатов модуля временного анализа. И это обстоятельство вынуждает нас использовать именно этот поток информации в качестве основного.
bool CNeuronPortfolioGenerator::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false; //--- if(!cTransposeVRC.FeedForward(NeuronOCL)) return false;
В теле метода мы проверяем актуальность указателя на второй источник данных и осуществляем транспонирование первого. А после проведения подготовительной работы, переходим к непосредственным вычислениям. Сначала умножаем тензор из второго источника исходных данных на транспонированный тензор первого.
if(!MatMul(SecondInput, cTransposeVRC.getOutput(), cAssetTime[0].getOutput(), iAssets, iDimension, iTimePoints, iAgents)) return false;
Результаты нормализуем функцией SoftMax.
if(!cSoftMax.FeedForward(cAssetTime[0].AsObject())) return false;
И умножаем на исходные данные основного потока информации.
if(!MatMul(cSoftMax.getOutput(), NeuronOCL.getOutput(), cAssetTime[1].getOutput(), iAssets, iTimePoints, iDimension, iAgents)) return false;
И теперь нам остается средствами родительского класса выполнить проекцию полученных данных в заданное подпространство.
return CNeuronBaseOCL::feedForward(cAssetTime[1].AsObject()); }
Логический результат выполнения операций возвращаем вызывающей программе и завершаем работу метода.
После завершения работы по организации процессов прямого прохода переходим к построению алгоритмов обратного прохода. И здесь мы прежде всего рассмотрим метод распределения градиента ошибки calcInputGradients.
bool CNeuronPortfolioGenerator::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient || !SecondInput) return false;
В параметрах метода мы получаем указатели на объекты исходных данных и соответствующих градиентов ошибки для обоих потоков информации. И в теле метода сразу проверяем корректность полученных указателей. Так как в противном случае все дальнейшие операции не имеют смысла.
Как вы знаете, распространение градиента ошибки осуществляется в полном соответствии информационному потоку прямого прохода, только в обратном направлении. Операции данного метода начинаются с вызова одноименного метода распределения градиента ошибки родительского класса до внутреннего объекта.
if(!CNeuronBaseOCL::calcInputGradients(cAssetTime[1].AsObject())) return false;
А затем. мы вызываем метод распределения градиента ошибки для операции умножения матриц, где мы передадим данные на уровень исходных данных и внутреннего слоя SoftMax.
if(!MatMulGrad(cSoftMax.getOutput(), cSoftMax.getGradient(), NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cAssetTime[1].getGradient(), iAssets, iTimePoints, iDimension, iAgents)) return false;
Однако мы помним, что на уровень исходных данных основного потока градиент ошибки должен прийти по двум информационным потокам. Поэтому, получаемые на данном этапе значения сохраним в свободный буфер транспонирования данных.
Далее мы пропускаем градиент ошибки через слой функции SoftMax до уровня ненормализованных коэффициентов.
if(!cAssetTime[0].calcHiddenGradients(cSoftMax.AsObject())) return false;
А затем распределяем полученный градиент ошибки до уровня второго источника данных и нашего слоя транспонирования.
if(!MatMulGrad(SecondInput, SecondGradient, cTransposeVRC.getOutput(), cTransposeVRC.getGradient(), cAssetTime[0].getGradient(), iAssets, iDimension, iTimePoints, iAgents)) return false;
Здесь сразу проверяем функцию активации второго источника данных и, при необходимости, корректируем полученный градиент ошибки на соответствующую производную.
if(SecondActivation != None) if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false;
На этом этапе мы передали градиент ошибки на уровень модуля CSA (в данном случае это второй источник исходных данных). И осталось завершить работу по передачи градиента ошибки модулю временного внимания (основной источник исходных данных). Он у нас получает данные по двум информационным потокам: от коэффициентов внимания и непосредственно от результатов. Данные обоих информационных потоков сейчас находятся в различных буферах объекта транспонирования данных. В основном буфере градиентов находятся транспонированные значения от информационного потока коэффициентов внимания. Воспользуемся основным функционалом объекта транспонирования трехмерного тензора и опустим их до уровня исходных данных.
if(!NeuronOCL.calcHiddenGradients(cTransposeVRC.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cTransposeVRC.getPrevOutput(), NeuronOCL.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
После чего, суммируем данные из двух информационных потоков. А в завершении операций метода, мы скорректируем полученный градиент ошибки на производную функции активации основного информационного потока.
if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cTransposeVRC.getPrevOutput(), NeuronOCL.Activation())) return false; //--- return true; }
И выходим из метода, передав логический результат выполнения операций вызывающей программе.
С методом обновления параметров модели я предлагаю вам ознакомиться самостоятельно. Полный код класса CNeuronPortfolioGenerator и всех его методов представлен во вложении.
Собираем фреймворк MASAAT
Мы уже реализовали работу отдельных блоков фреймворка MASAAT и пришло время собрать их в единую структуру фреймворка. Эту работу мы выполним в рамках класса CNeuronMASAAT. И в качестве родительского объекта для него был выбран созданный выше CNeuronPortfolioGenerator, который является последним блоком нашей реализации подходов фреймворка MASAAT. Это позволяет не объявлять нам данный модуль в числе внутренних объектов нашего класса. А весь необходимый функционал будет унаследован от родительского объекта. Структура нового класса представлена ниже.
class CNeuronMASAAT : public CNeuronPortfolioGenerator { protected: CNeuronTransposeOCL cTranspose; CNeuronPLRMultiAgentsOCL cPLR; CNeuronBaseOCL cConcat; CNeuronCrossSectionalAnalysis cCrossSectionalAnalysis; CNeuronTemporalAnalysis cTemporalAnalysis; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMASAAT(void) {}; ~CNeuronMASAAT(void) {}; //--- //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMASAAT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной структуре нового класса мы видим объявление всех вышесозданных объектов. И не сложно догадаться, что алгоритм всех методов данного класса будет построен на последовательном вызове одноименных методов внутренних объектов. А с последовательностью их вызовов мы познакомимся в процессе реализации методов.
Все внутренние объекты объявлены статично, что позволяет нам оставить "пустыми" конструктор и деструктор нашего класса. Инициализация всех объявленных и унаследованных объектов, как обычно, осуществляется в методе Init.
bool CNeuronMASAAT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPortfolioGenerator::Init(numOutputs, myIndex, open_cl, window, units_cout / 3, window_key, (uint)min_distance.Size() + 1, projection, optimization_type, batch)) return false;
В параметрах данного метода мы получаем основные константы, которые указывают на структуру исходных данных и определяют архитектуру инициализируемого объекта.
В теле метода мы, по уже сложившейся традиции, сразу вызываем одноименный метод родительского класса, в котором уже организован процесс инициализации унаследованных объектов и базовых интерфейсов. Однако, следует обратить внимание, что в данном случае мы используем родительский класс в качестве полноценного функционального блока выстраиваемых алгоритмов. И этот модуль мы будем использовать на выходе нашей реализации фреймворка MASAAT. Поэтому нам предстоит мысленно забежать немного вперед для определения параметров инициализации родительского объекта.
Итак, на вход родительского объекта мы планируем подавать результаты работы наших модулей CSA и TA. В них количество анализируемых активов равно размеру окна исходных данных, а количество временных точек ожидается на уровне длины последовательности исходных данных. Но подождите, мы же планируем преобразование исходной мультимодальной временной последовательности в кусочно-линейное представление. Значит, количество временных точек будет в 3 раза меньше. Как результат, при передаче параметров в метод родительского класса, мы делим размер исходной последовательности на 3.
Рассматриваем параметры родительского метода дальше и приходим к числу агентов. Как обсуждалось ранее, при построении объекта мультиагентного преобразования временного ряда в кусочно-линейное представление, количество агентов определяется длиной вектора предельных отклонений показателей. Но если мы посмотрим на проведенный авторами MASAAT анализ влияния отдельных составляющих фреймворка на результат, то обнаружим, что использование кусочно-линейного представления временного ряда совместно с оригинальным позволяет повысить эффективность работы модели. Поэтому мы увеличиваем число агентов на 1. Последний будет работать с оригинальным представлением анализируемого временного ряда.
Остальные параметры мы передаем без изменений.
После успешного выполнения операций метода родительского класса, мы переходим к инициализации вновь объявленных объектов. И здесь мы первым инициализируем объект транспонирования исходных данных.
if(!cTranspose.Init(0, 0, OpenCL, units_cout, window, optimization, iBatch)) return false;
А затем, инициализируем объект мультиагентного преобразования анализируемой последовательности в кусочно-линейное представление.
if(!cPLR.Init(0, 1, OpenCL, window, units_cout, false, min_distance, optimization, iBatch)) return false;
Результаты преобразования мы конкатенируем с исходными данными. Для этого инициализируем полносвязный слой соответствующего размера.
if(!cConcat.Init(0, 2, OpenCL, cTranspose.Neurons() + cPLR.Neurons(), optimization, iBatch)) return false;
И нам остается лишь инициализировать объекты модулей CSA и TA. Оба модуля работают с одним источником данных, поэтому получают одинаковые параметры.
if(!cCrossSectionalAnalysis.Init(0, 3, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; if(!cTemporalAnalysis.Init(0, 4, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; //--- return true; }
А после успешного выполнения инициализации всех внутренних объектов, возвращаем логический результат выполнения операций вызывающей программе и завершаем работу метода.
Далее мы переходим к построению алгоритма прямого прохода в методе feedForward. Здесь все довольно просто. В параметрах метода получаем указатель на объект исходных данных, который сразу передаем в одноименный метод объекта транспонирования данных.
bool CNeuronMASAAT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
Затем мы преобразуем полученные исходные данные в несколько вариантов кусочно-линейного представления временного ряда и конкатенируем полученные значения с исходными данными, только используем их транспонированный вид.
if(!cPLR.FeedForward(cTranspose.AsObject())) return false; if(!Concat(cTranspose.getOutput(), cPLR.getOutput(), cConcat.getOutput(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
Подготовленные таким образом данные мы передаем в модули CSA и ТА, а полученные результаты передаем в одноименный метод родительского класса.
if(!cCrossSectionalAnalysis.FeedForward(cConcat.AsObject())) return false; if(!cTemporalAnalysis.FeedForward(cConcat.AsObject())) return false; //--- return CNeuronPortfolioGenerator::feedForward(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput()); }
После чего, завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
За видимой простотой метода прямого прохода скрывается разветвленность информационных потоков. Обратите внимание, что мы дважды используем транспонированные исходные данные и конкатенированный тензор. Это приводит к некоторым осложнениям организации процесса распределения градиента ошибки в методе calcInputGradients.
В параметрах метода распределения градиента ошибки мы получаем указатель на объект исходных данных, в который нам предстоит передать градиент ошибки. И в теле метода мы сразу проверяем актуальность полученного указателя.
bool CNeuronMASAAT::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
После чего вызываем одноименный метод родительского класса для распределения градиента ошибки между модулями CSA и TA в соответствии с их влиянием на результат работы модели.
if(!CNeuronPortfolioGenerator::calcInputGradients(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput(), cCrossSectionalAnalysis.getGradient(), (ENUM_ACTIVATION)cCrossSectionalAnalysis.Activation())) return false;
Оба указанных модуля работают с данными конкатенированного тензора. Следовательно, на уровень конкатенированного тензора нам предстоит передать градиент ошибки по двум информационным потокам. Сначала мы передаем градиент ошибки от одного модуля.
if(!cConcat.calcHiddenGradients(cCrossSectionalAnalysis.AsObject())) return false;
А затем используем трюк с подменой буфера градиента ошибки и получаем значения второго информационного потока с последующим суммированием информации из двух источников.
CBufferFloat *grad = cConcat.getGradient(); if(!cConcat.SetGradient(cConcat.getPrevOutput(), false) || !cConcat.calcHiddenGradients(cTemporalAnalysis.AsObject()) || !SumAndNormilize(grad, cConcat.getGradient(), grad, 1, 0, 0, 0, 0, 1) || !cConcat.SetGradient(grad, false)) return false;
Градиент ошибки конкатенированного тензора мы распределяем между объектами конкатенации. При этом мы помним, что на уровень объекта транспонирования исходных данных планируется передача данных по другому информационному потоку. Поэтому, на данном этапе мы используем свободный буфер данных.
if(!DeConcat(cTranspose.getPrevOutput(), cPLR.getGradient(), cConcat.getGradient(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
И перед продолжением процесса распределения градиента ошибки между объектами, мы проверим необходимость корректировки на производную соответствующей функции активации.
if(cPLR.Activation() != None) if(!DeActivation(cPLR.getOutput(), cPLR.getGradient(), cPLR.getGradient(), cPLR.Activation())) return false;
Следующим этапом мы проводим градиент ошибки через объект мультиагентного преобразования в кусочно-линейное представление временного ряда и суммируем значения двух информационных потоков.
if(!cTranspose.calcHiddenGradients(cPLR.AsObject()) || !SumAndNormilize(cTranspose.getGradient(), cTranspose.getPrevOutput(), cTranspose.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
При необходимости, скорректируем градиент ошибки на производную функции активации и передадим его на уровень исходных данных.
if(cTranspose.Activation() != None) if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), cTranspose.Activation())) return false; if(!prevLayer.calcHiddenGradients(cTranspose.AsObject())) return false; //--- return true; }
В завершении работы метода, мы передаем логический результат выполнения операций вызывающей программе.
На этом мы завершаем рассмотрение алгоритмов реализации подходов фреймворка MASAAT. Полный код всех представленных классов и их методов вы найдете во вложении. Там же представлены все программы, используемые при подготовке статьи, а так же архитектуры моделей. Мы лишь совсем немного остановимся на архитектуре моделей. Нашу реализацию фреймворка MASAAT мы внедрили в модель Актера. Мы не будем сейчас полностью рассматривать архитектуру модели. Она практически полностью перенесена из предыдущих работ. Посмотрим лишь на объявление нового слоя.
В динамическом массиве размерностей окон мы укажем величину окна анализируемых данных и длину тензора скрытого состояния, получаемого на выходе слоя.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMASAAT; //--- Windows { int temp[] = {BarDescr, LatentCount}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; }
Пороговые значения для наших 3 агентов мы создали в виде геометрической прогрессии.
//--- Min Distance { vector<float> ones = vector<float>::Ones(3); vector<float> cs = ones.CumSum() - 1; descr.radius = pow(ones * 2, cs) * 0.01f; }
Остальные параметры имеют привычные значения.
descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
С полной архитектурой моделей, как уже было сказано выше, вы можете ознакомиться во вложении.
Тестирование
Наша работа по реализации подходов, предложенных авторами фреймворка MASAAT, средствами MQL5 подошла к своему логическому завершению. И мы переходим к самому ответственному этапу — оценке эффективности реализованных подходов на реальных исторических данных.
Следует подчеркнуть, что мы оцениваем именно *реализованные* подходы, а не фреймворк MASAAT в авторском представлении. Так как в процессе реализации были внесены изменения в оригинальную версию фреймворка.
Модели обучались на исторических данных за 2023 год для финансового инструмента EURUSD, таймфрейм H1. Все параметры анализируемых индикаторов использовались на уровне настроек по умолчанию.
Для начального этапа обучения была использована обучающая выборка, собранная в рамках предыдущих исследований, которая периодически обновлялась в ходе обучения моделей для адаптации к текущей стратегии Актера.
После нескольких циклов обучения и обновления выборки, была получена политика, демонстрирующая прибыльность как на обучающей, так и на тестовой выборках.
Тестирование финальной обученной политики проводилось на исторических данных за январь 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
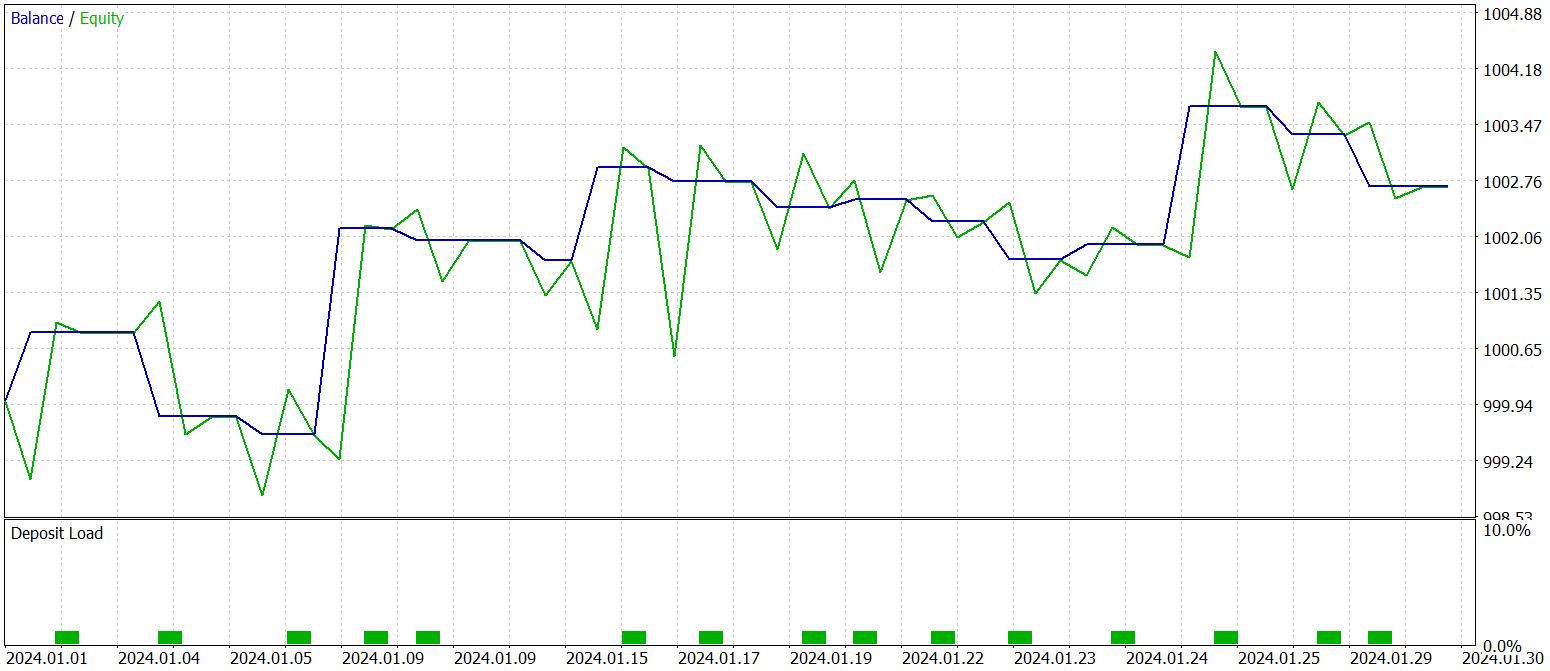
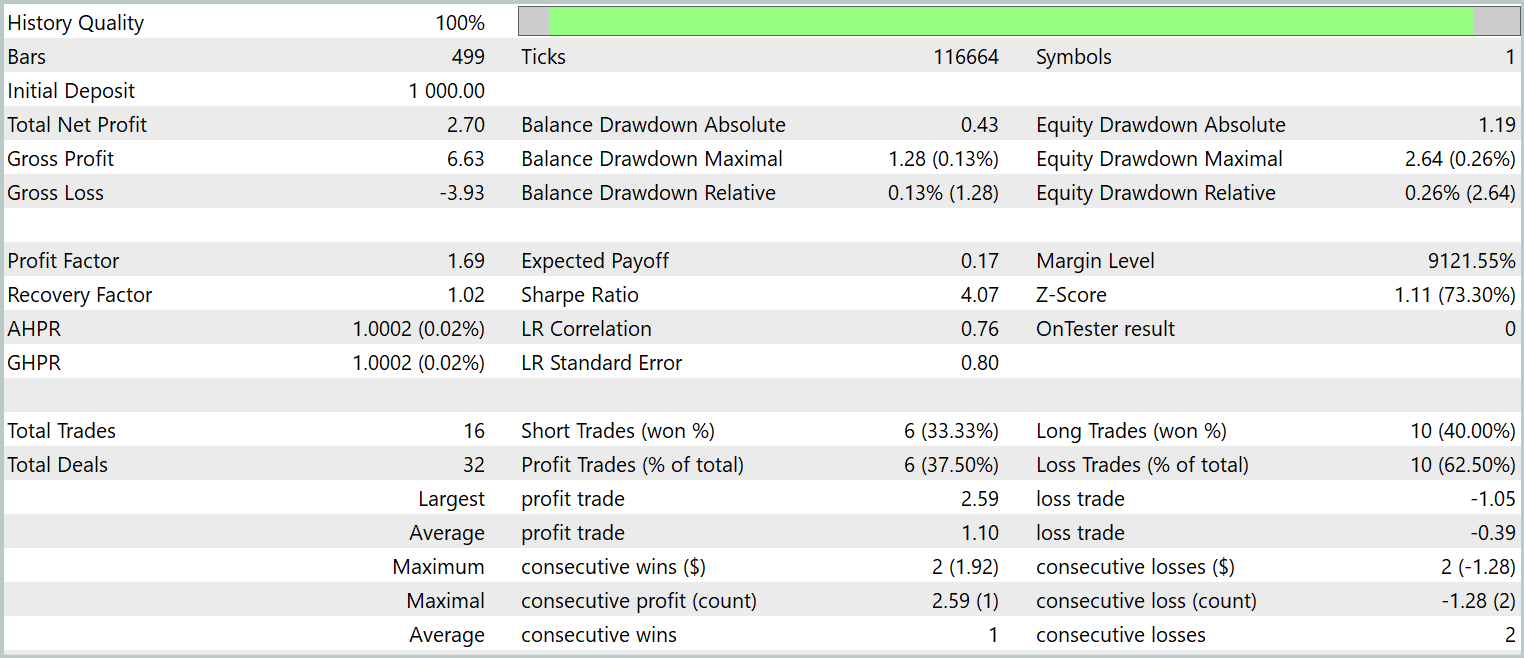
Как видно из представленных данных, за период тестирования модель совершила 16 торговых операций. И лишь чуть больше трети из них было закрыто с прибылью. Однако, максимальная прибыльная сделка превышает аналогичный показатель убыточных операций в 2.5 раза. А по средним значениям операций достигается трехкратное увеличение. Как следствие, мы видим явную тенденцию к росту баланса.
Заключение
В данной работе мы рассмотрели мультиагентную адаптивную структуру MASAAT, разработанную для оптимизации инвестиционного портфеля. MASAAT сочетает механизмы внимания и анализ временных рядов. Этот фреймворк использует ансамбль торговых агентов для многогранного анализа ценовых данных, что способствует снижению предвзятости в формируемых торговых решениях. Каждый агент применяет механизм перекрестного анализа на основе внимания для выявления корреляций между активами и временными точками в рамках наблюдаемого периода. Полученная информация затем объединяется с помощью модуля пространственно-временного слияния, что позволяет эффективно интегрировать данные и улучшить качество торговых стратегий.
В практической части нами было реализовано собственное видение предложенных подходов средствами MQL5. Мы внедрили предложенные подходы в модель и обучили её на реальных исторических данных. Результаты тестирования обученной модели свидетельствуют о потенциале предложенных подходов.
Ссылки
- Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования