
MQL5で自己最適化エキスパートアドバイザーを構築する(第12回):行列分解を用いた線形分類器の構築

行列分解は、数値的に駆動されるアプリケーションを構築したいアルゴリズムトレーダーにとって重要なツールです。これらの手法を用いることで、さまざまな種類の機械学習アルゴリズムを構築することができ、それ以上の応用も可能です。これまでの議論では回帰タスクのみを扱いましたが、ここでは分類問題に焦点を移します。本日のテーマは、市場分類器の構築です。この分類器は、市場の上昇および下降の動きを識別できるように設計します。目的は、取引を正確におこなうための適切な判断を支援することです。分類器のタスクは、市場の過去の動きを学習し、特定の取引日に取るべき正しいアクションを推論することにあります。
私たちの取引戦略は、以下のように機能します。目的は、移動平均インジケーターの期待される挙動に基づいて市場の動きを予測することです。加えて、価格も移動平均に沿った挙動を示すことを期待します。つまり、分類モデルが移動平均の下降を予測する場合、価格レベルもインジケーターを下回ることを確認したうえで売りポジションを開きます。移動平均は価格の方向を示しますが、ポジションを取る前に価格がインジケーターを超えて加速することも確認したいと考えます。
同様に、買いポジションの場合も同じロジックが適用されます。移動平均の上昇を予測し、価格がその上を大きく上回る場合に強い買いポジションを取ります。
この説明からわかるように、私たちのモデルは同時に2つのカテゴリカル出力を予測します。しかし、これはマルチクラス分類モデルと混同してはいけません。モデルが予測する2つの変数はどちらも二値結果です。言い換えれば、モデルは2つの独立した二値アウトカムを追跡します。ここで説明するアーキテクチャは、2つ以上のクラスを同時に分類するには適していません。
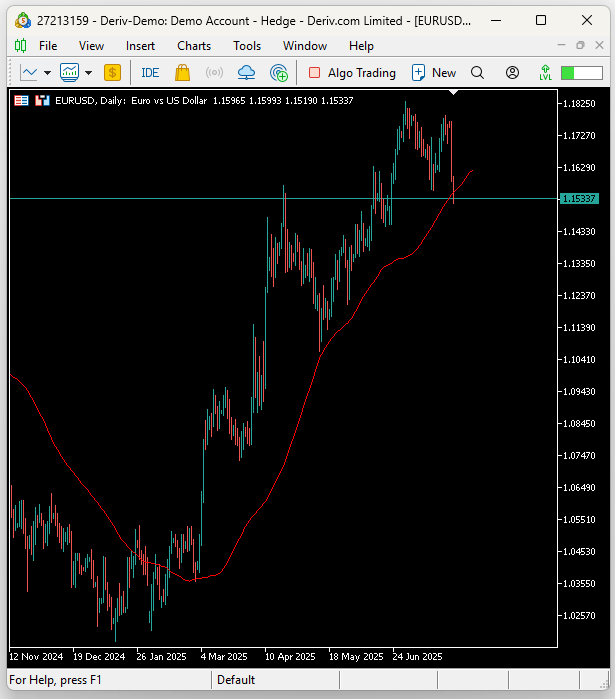
図1:取引戦略の動作イメージ
線形分類器構築のための行列分解
ほとんどの取引アプリケーションと同様に、まずシステム定義を行います。今回の場合、入力データ行列Xで追跡する6つの入力があります。
//+------------------------------------------------------------------+ //| Linear Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define TOTAL_INPUTS 6
次に進みます。システム定義をおこなった後、次はエンドユーザーが調整できるユーザー入力を定義します。特に、エンドユーザーには適切な時間枠とストップロスのサイズを選択できるようにしたいと考えています。
//+------------------------------------------------------------------+ //| System Inputs | //+------------------------------------------------------------------+ int bars = 200;//Number of historical bars to fetch int horizon = 1;//How far into the future should we forecast int MA_PERIOD = 50; //Moving average period ENUM_TIMEFRAMES TIME_FRAME = PERIOD_D1;//User Time Frame input ENUM_TIMEFRAMES RISK_TIME_FRAME = PERIOD_D1; input double sl_size = 2;
加えて、必要な重要なシステムライブラリも含める必要があります。例えば、取引ライブラリや、私が作成した時間の管理や重要な取引情報の取得をおこなう2つのカスタムライブラリです。
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
次に進みます。私たちのシステムは、演習のために重要なグローバル変数を作成することにも依存しています。今回の場合、テクニカルインジケーターのハンドラ として機能するグローバル変数が必要です。また、市場から受け取る入力データや出力データを追跡するためのグローバル変数も必要です。さらに、テクニカルインジケーターの現在の値を取得するためのバッファも必要です。
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ int ma_close_handler; double ma_close[]; Time *Timer; TradeInfo *TradeInformation; vector bias,temp,Z1,Z2; matrix X,y,prediction,b; int time; CTrade Trade; int state; int atr_handler; double atr[];
システムが初めてロードされる際には、すべてのシステム変数を初期化するために呼び出される、initializeという専用のメソッドを用意します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- initialize(); //--- return(INIT_SUCCEEDED); }
システムの使用が終了した際には、テクニカルインジケーターが使用していたメモリを解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(atr_handler); IndicatorRelease(ma_close_handler); }
新しい価格足が形成されるたびに、2つの専用メソッドを呼び出します。最初のメソッドはsetupメソッドで、最後のメソッドはfindSetupユニットです。これらについては、進めながら後ほど詳しく説明します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(Timer.NewCandle()) { setup(); find_setup(); } }
システムが初めて初期化される際には、ハンドラの新しいインスタンスをそれぞれの適切な識別子にロードします。たとえば、ローソク足の形成を追跡するtimeライブラリの新しいオブジェクトを動的に作成します。また、取引情報クラスの新しいオブジェクトも作成します。 このクラスは、現在の市場で取引可能な最小ロットサイズや、現在の買値・売値など、重要な情報を管理する役割を持つことを覚えておいてください。 さらに、initialize関数は、すべてのデフォルト値を行列およびそれに関連付けられた識別子にロードする役割も担います。
//+------------------------------------------------------------------+ //| Initialize our system variables | //+------------------------------------------------------------------+ void initialize(void) { Timer = new Time(Symbol(),TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),TIME_FRAME); ma_close_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_CLOSE); atr_handler = iATR(Symbol(),RISK_TIME_FRAME,14); bias = vector::Ones(TOTAL_INPUTS); Z1 = vector::Ones(TOTAL_INPUTS); Z2 = vector::Ones(TOTAL_INPUTS); X = matrix::Ones(TOTAL_INPUTS,bars); y = matrix::Ones(1,bars); time = 0; state = 0; }
find_setup()関数は、これまでに扱ってきた他の関数よりも少し複雑です。まず、findSetup関数は現在の終値を追跡し、その後インジケーターの現在の値をコピーします。そのため、ATRや移動平均の値をそれぞれ対応するバッファにコピーします。そこから、もしポジションが開かれていなければ、システム状態をリセットします。次に、線形分類器から受け取る予測を考慮する必要があります。
私たちの分類器は、同時に2つの出力をモデル化していることを思い出してください。最初の予測は、移動平均インジケーターが将来どの方向に動くと予測されるかです。2つ目の予測は、価格と移動平均とのギャップです。したがって、これら2つの予測は互いに整合していることが望まれます。移動平均インジケーターが下降すると予測される場合、価格もそれより下に落ちていることを確認したいです。また、移動平均が上昇すると予測される場合、価格もそれを上回ることを確認します。
これら2つの設定が、私たちの取引戦略の基盤を形成します。買いをおこなう場合は、両方の予測が0.5より大きくなければなりません。逆に、売りをおこなう場合は、両方の予測が0.5より小さくなる必要があります。それ以外の場合で、もしすでにポジションを持っている場合は、単にポジションと線形分類器の予測を追跡します。例えば売りポジションを持っているが、モデルが移動平均インジケーターの上昇を予測している場合は、ポジションをクローズします。買いの場合も同様の逆の処理をおこないます。
それ以外は、問題がなければ、ストップロスをより利益の出る設定に更新し、そこから取引を継続します。
//+------------------------------------------------------------------+ //| Find a trading setup for our linear classifier model | //+------------------------------------------------------------------+ void find_setup(void) { double c = iClose(Symbol(),TIME_FRAME,0); CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_close_handler,0,0,1,ma_close); if(PositionsTotal() == 0) { state = 0; if((prediction[0,0] > 0.5) && (prediction[1,0] > 0.5)) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),(TradeInformation.GetBid() - (sl_size * atr[0])),0); state = 1; } if((prediction[0,0] < 0.5) && (prediction[1,0] < 0.5)) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),(TradeInformation.GetAsk() + (sl_size * atr[0])),0); state = -1; } } if(PositionsTotal() > 0) { if(((state == -1) && (prediction[0,0] > 0.5)) || ((state == 1)&&(prediction[0,0] < 0.5))) Trade.PositionClose(Symbol()); if(PositionSelect(Symbol())) { double current_sl = PositionGetDouble(POSITION_SL); if((state == 1) && ((ma_close[0] - (2 * atr[0]))>current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] - (2 * atr[0])),0); } else if((state == -1) && ((ma_close[0] + (2 * atr[0]))<current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] + (2 * atr[0])),0); } } } }
線形分類器を適合させるための専用メソッドがあります。以下に示すfitメソッドは、過去の価格入力を私たちが追跡したい2つのターゲットにマッピングする形でデータに適合させます。 思い出してください。私たちは、OpenBLASライブラリに含まれる特異値分解(SVD)メソッドを使用して、モデルを迅速に因数分解し、最適な係数を求めてBに格納できる形式にしています。
//+------------------------------------------------------------------+ //| Fir our classification model | //+------------------------------------------------------------------+ void fit(void) { //--- Fit the model matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); b = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); }
いつも通り、データの取得と保存は、どの機械学習モデルにおいても重要な部分です。各データエントリについて、平均値を引き、標準偏差で割ります。
たとえば、始値、最高値、最安値、およびテクニカルインジケーターの値を追跡したいと考えます。これらすべての値は、データ行列Xに格納する前に、平均値を引き、標準偏差で割る必要があります。
その後、Y行列をコピーして形状を整えたら、出力をゼロ(価格レベルが下落したことを示す)または1(価格レベルが上昇したことを示す)として保存します。これが分類モデルを構築する方法です。
//+------------------------------------------------------------------+ //| Prepare the data needed for our classifier | //+------------------------------------------------------------------+ void fetch_data(void) { //--- Reshape the matrix X = matrix::Ones(TOTAL_INPUTS,bars); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,horizon,bars); Z1[0] = temp.Mean(); Z2[0] = temp.Std(); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,horizon,bars); Z1[1] = temp.Mean(); Z2[1] = temp.Std(); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,horizon,bars); Z1[2] = temp.Mean(); Z2[2] = temp.Std(); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); Z1[3] = temp.Mean(); Z2[3] = temp.Std(); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_close_handler,0,horizon,bars); Z1[4] = temp.Mean(); Z2[4] = temp.Std(); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); //--- Reshape the output target y.Reshape(2,bars); vector temp_2,temp_3,temp_4; //--- Prepare to label the target accordingly temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); temp_4.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_2.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_3.CopyIndicatorBuffer(ma_close_handler,0,0,bars); for(int i=0;i<bars;i++) { //--- Record if price levels appreciated or depreciated if(temp[i] > temp_4[i]) y[0,i] = 0; else if(temp[i] < temp_4[i]) y[0,i] = 1; //--- Record if price levels remained above the moving average indicator, or fell beneath it. if(temp_2[i] < temp_3[i]) y[1,i] = 0; if(temp_2[i] > temp_3[i]) y[1,i] = 1; } Print("Training Input Data: "); Print(X); Print("Training Target"); Print(y); }
その後、分類モデルから予測を取得する準備が整います。分類モデルから単純に予測を得るには、入力データXの最終行が必要です。別の言い方をすれば、現在の市場の読み取り値、つまり現在の市場状況です。その現在の市場状況を取り、過去のデータから学習した係数と掛け算することで、予測を得ることができます。
//+------------------------------------------------------------------+ //| Obtain a prediction from our classification model | //+------------------------------------------------------------------+ void predict(void) { //--- Prepare to get a prediction //--- Reshape the data X = matrix::Ones(TOTAL_INPUTS,1); //--- Get a prediction temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,0,1); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,0,1); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,0,1); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,1); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); temp.CopyIndicatorBuffer(ma_close_handler,0,0,1); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); Print("Prediction Inputs: "); Print(X); //--- Get a prediction prediction = b.MatMul(X); Print("Prediction"); Print(prediction); }
しかし、これらのメソッドを1つずつ呼び出すのは手間がかかります。そこで、これら3つのメソッドを必要な順序で呼び出す専用のsetupメソッドを設計しました。まず、データを取得します。次に、モデルをデータに適合させます。そして最後に、予測を取得します。
このシンプルなsetupメソッドにより、常に正しい順序で3つのステップを実行することができます。
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { fetch_data(); fit(); predict(); } //+------------------------------------------------------------------+
最後に、アプリケーションの開始時に作成したシステム定義を統一する必要があります。
#undef TOTAL_INPUTS バックテストは2020年1月に開始し、日足の時間枠で5年間、2025年まで実行します。アプリケーションはEURUSDでテストします。
図2:バックテストと最適化日の選択
さらに、可能な限り最適な設定を得るために、常にランダムディレイ設定を使用します。これにより、アプリケーションをテストする条件が将来予想される実際の市場環境に一致することを確認できます。
図3:バックテスト条件の選択も重要
バックテスト中のアプリケーションのパフォーマンスをスクリーンショットで確認しました。ご覧の通り、アプリケーションは与えられた予測入力を表示しています。最初の入力は常に切片を表す1ですが、実際にはモデルが出している予測値に主に注目しています。
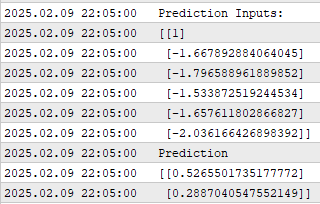
図4:線形分類アルゴリズムを実行して得られた出力
ご覧の通り、モデルは前述の通り2つの予測を出しています。最初の予測は将来の移動平均の位置変化に関連しており、2つ目の予測は価格と移動平均との変化に関連しています。そして、これら2つの変化が同じ方向に揃うことを望んでいます。
また、取引戦略によって生成された資産曲線も確認できます。時間経過とともに上昇傾向が見られますが、完全に安定しているわけではありません。
さらに、カーブには2つのラインが描かれていることに注意してください。青い線は時間経過に伴う口座残高で、緑の線は時間経過に伴う口座のエクイティです。緑の線(エクイティ)が青い線を上回る場面が多く見られます。
私の経験から、この現象は取引戦略において利益やシグナルを取り逃していることを示しています。このシグナルは戦略を通過しており、利益を取り切れていません。 これは、戦略に改善の余地があることを示唆しています。
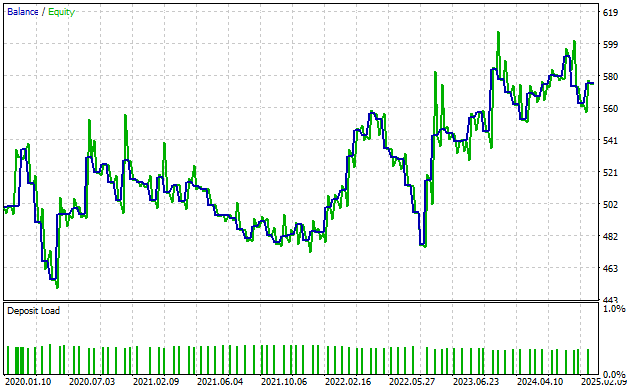
図5:資産曲線は、まだ取りこぼしているシグナルがあることを示している
最後に、時間経過に伴うパフォーマンスの詳細統計を確認します。ご覧の通り、平均して利益の出る取引は、損失の平均取引よりも大きくなっています。また、戦略に従って得た最大利益も最大損失より大きく、これは励みになります。
しかし、利益の出る取引の割合を見ると43%であり、半数には満たしていません。これは、資産曲線で見られた取り逃しのスパイクと一致し、システムがまだ取りこぼしているシグナルがあることを再確認させます。
これは、システムにはさらに改善の余地があるという認識を強化します。まだ取得できていない情報が存在します。現状でも強力なスタートですが、さらに多くのシグナルを発見し学習する余地があります。
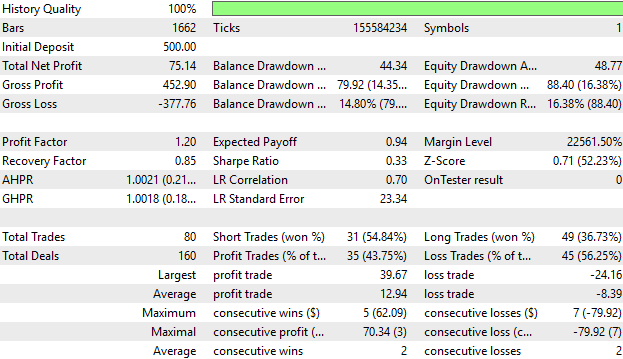
図6:パフォーマンスの詳細統計は、システムに改善の余地があるという先の推察を支持している
結論
結論として、本記事では、アルゴリズムトレーダーとして私たちがMQL5アプリケーションで活用できる行列分解の多様な応用について読者に示しました。行列分解を最初に取り上げた際には、回帰に使用できるツールとして見ていました。今回は、分類に使用できるツールとして取り上げています。
ただし、読者に1つだけお約束したいのは、まだ私たちがカバーすべきことはたくさんあるということです。ここで扱ったのは基本にすぎません。私の見解では、これらは行列分解の価値を迅速に示す簡単な応用です。本連載を追ってきた方であれば、今では行列分解を用いた回帰モデル、分類モデル、あるいはその両方を組み合わせたモデルを構築する方法を理解していることでしょう。これらのモデルは、単一の予測に限定されず、複数のターゲットを同時に予測することも可能です。
そして、読者の皆さんに約束します。行列分解には、まだまだ多くの利点が存在し、これから学ぶべきことがたくさんあります。しかし、その利点を探求する前に、まず基本をマスターする必要があります。さらに、MQL5 APIで提供されている専用関数のおかげで、これらの強力な行列手法を取引アプリケーションに簡単に組み込めることも確認しました。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18987
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索