
初級から中級まで:配列(IV)

はじめに
前回の「初級から中級まで:配列(III)」では、配列を使って関数や手続き間でデータを渡す方法を説明しました。また、初期化に関する注意点や、長期的に見て持続可能でないコードを避けるための基本的な配慮についても取り上げました。これまでに示してきた内容は、実用性が低い、あるいは実際に使う機会が少ないと思った方もいるかもしれません。しかし今回から、いよいよ実践的で面白い内容に踏み込んでいきます。ここまでは、いくつかの基本概念やルールを使って簡単な例を示してきましたが、いよいよMetaTrader 5の本質に迫っていきます。
とはいえ、実際に手を動かす前に、まず理解しておくべき事柄がいくつかあります。中には、皆さんの多くが知らないこと、あるいは全く予想していないような仕組みもあるでしょう。これから扱う内容は、興味深くなると同時に、少しずつ複雑にもなっていきます。ですので、今回以降の記事は、ぜひ焦らずじっくりと取り組んでください。これから学ぶことは、MetaTrader 5で実用的なアプリケーションを開発する際に大いに役立つはずです。
まず最初に取り上げるのは、配列を使ったより効率的なメモリの使い方です。実は配列の話はまだ終わっていません。そして、もし配列についてすぐに完全に理解できると思っていたなら、それは忘れてください。このトピックは非常に広範で奥が深いのです。ですから、今後も他のテーマと並行して、配列については少しずつ掘り下げていきます。このアプローチの方が、退屈にもならず、無理なく理解を深めていけるはずです。
この記事の内容に入る前に、前回の記事の最後に扱ったコードの仕組みを理解している必要があります。特に、配列を宣言スコープの外でどのように扱うかを理解していることが重要です。
sizeof演算子
まずは小さなテストから始めましょう。これは、データがメモリ上でどのように操作されるかを示すためのものです。ここでは通常の変数は使用せず、すべてを配列のみでおこなおうとします。つまり、変数を直接RAM上で作成・移動・読み取り・書き込みするプロセスをシミュレーションするのです。これが突飛に聞こえるかもしれませんが、論理的思考力とプログラミング力を鍛えるのに非常に優れた演習ですし、本物のプログラマのように考える第一歩にもなります。なぜなら、多くのプログラマがどのように取り組めばよいかわからない作業を自分でおこなう必要があるからです。
小さな導入から始めてより大きなテーマへと進みます。ただし、皆が理解できるようにできる限りシンプルに説明しようと思います。まず、sizeof演算子が実際に何をしているのか、なぜ存在するのかを理解する必要があります。
sizeof演算子は、データ型や変数がメモリ上で何バイト占めているかを教えてくれます。これは少し神秘的に聞こえるかもしれませんが、実際はとても単純です。まず理解すべきことは、配列の要素数が割り当てられたメモリの量に直接対応しているわけではないということです。配列はX個の要素を持っていてもYバイトのメモリを占有しているかもしれません。要素数がメモリに割り当てられたバイト数と等しくなるのは、その配列のデータ型が8ビット、つまり1バイトの場合のみです。MQL5では、この条件を満たす型はcharとucharです。他のすべての型は、配列の要素数よりも多くのバイト数を占有します。したがって、sizeof演算子をArraySizeやSize関数と混同しないでください。これらは配列の要素数を求めるためのものです。
次の例を見てみましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
コード01
コード01を実行すると、次の結果が生成されます。
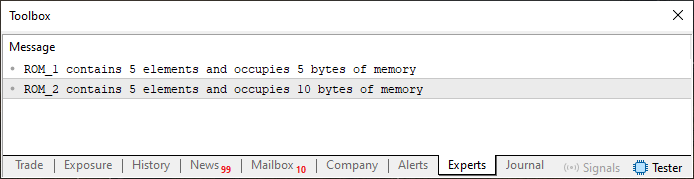
図01
では、次に画像01が何を示しているのかを分析してみましょう。見ただけでもかなり直感的ですが、分解して説明します。コード01では、2つの静的配列が作成されています。違いは1つがchar型で、もう1つがshort型であることだけです。それ以外はまったく同じで、それぞれ5つの要素を持っています。しかし、それぞれが使うメモリ量(バイト数)は異なります。なぜでしょうか。
「初級から中級へ:変数(II)」には、基本データ型がメモリ上で占めるバイト数を示す表があります。その表を見ると、short型は2バイトを占めることがわかります。要素数が5つなので、配列の要素数に各要素が占めるバイト数を掛け合わせると合計10バイトになります。実際、sizeof演算子を使ってどれだけメモリを使っているかを調べるのは非常に簡単です。
そして、なぜこれが私たちにとって重要なのでしょうか。特定のデータがどれだけのメモリを消費するかを知ることは非常に有用です。たとえば、追加のメモリを割り当てたり、ある一定のメモリを解放したりする際に、とても簡単かつ直接的に操作できるようになるからです。まだ実際にはこの操作を使っていませんが、今後進めていく中で頻繁に実装していくことになります。しかし、現時点での目的には、ここまでの内容で十分です。ですので、次の段階に進みましょう。
列挙体
このトピックでは非常にシンプルな概念について説明します。しかし、この概念は数え切れないほど多くの場面で非常に役立ちます。列挙子とは何かを、とてもわかりやすく簡単に説明するために、前回の記事で扱ったコードを改めて見ていきます。すぐ下にあります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
コード02
このヘッダーファイルは以前にも見たことがあり、ここでも再度取り上げます。現時点で非常に役立つ内容です。ご覧の通り、あるフォーマットを使うには任意の10進数の値が必要です。しかし、コード内でこれを使うと、その目的が何なのか理解しづらくなります。なぜなら、コード02で示された方法を用いる場合、コードは次のように書かざるを得ないからです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
コード03
この場合、コード03の4行目で指定されているヘッダーファイルは、まさにコード02に示されているものです。しかし、問題は特に15行目から18行目の間にある値にあります。これらの値を見ただけで、どのような処理がおこなわれて出力文字列が生成されているのかを判断できるでしょうか。絶対にできません。ヘッダーファイルを参照し、ValueToString関数を探して、各値がどのように扱われているかを解析してから、どの値を使うべきかを判断する必要があります。言い換えれば、生産性が非常に低いにもかかわらず、多くの作業が必要になるのです。まさにこの理由から、はるかに実用的で効率的な構造が求められます。この構造がENUM(列挙型)として知られています。列挙型は、新しい値が追加されるたびに連続した番号を持つ特別なデータ型を作り出します。とても便利で使いやすいものです。
したがって、コード02を列挙型を使うように更新すると、以下のコードになります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
コード04
これは実際のところ、非常に簡単に実装できることに注目してください。もちろん、ここで扱っているのは基本的な列挙型の作成ですが、4行目で何が起きているのかは簡単に理解できることを願っています。enumが定義されると、それ以降のコードにおいて、見られるような置き換えが可能になります。この場合、先ほどのコード03は、以下に示すような形になります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
コード05
正直に言いましょう。コード05を見ただけで、そのコードが何をしているのかは完全に明らかだとおもいます。この小さな変更だけで、コード03はそのまま正常に動作します。少なくとも、列挙型にさらなる変更を加えるまでは。しかし今のところは、現状のままにしておきます。列挙子に関するより高度な詳細に今すぐ踏み込むのは意味がありません。このトピックには近いうちに再び戻ってくることになりますが、そのときは別の目的で扱うことになります。
無限の数の引数
では、この記事をもう少し興味深いものにするために、少しだけ高度なトピックに進みましょう。以前の記事では、MetaTrader 5の端末で可視化するためのバイナリ値の表現方法を紹介しました。その際、MQL5でCやC++のような動作をする手続きを作成するのが難しいという点についても触れました。実際、私の知る限りでは、CとC++だけがこの種の実装をネイティブにサポートしている言語です。Javaも似たようなことは可能ですが。
これらの言語では、引数の数が固定されていない関数や手続きを作ることができます。関数を呼び出すとき、最小限の引数は宣言されており、少なくとも1つの引数を渡す必要があります。
その最小限の条件を満たした後は、必要なだけ追加の引数を渡すことができます。関数や手続き内部では、追加の引数に個別にアクセスできる3つの特別な呼び出しがあります。興味がある人は、va_start、va_arg、va_endという3つの関数を調べてみてください。これらはCおよびC++で使われる関数です。Javaでは名称こそ異なりますが、動作原理は本質的に同じです。これらの関数の背後にあるコンセプトを理解することで、MQL5でも非常によく似たものを構築することができます。
この内容を上級者向けだと考える人もいるかもしれません。しかし、私の意見では、これは初心者が実装方法を知っておくべき基本知識です。実際に私たちがこれからおこなうことは、MQL5における配列操作を使ったちょっとしたトリックにすぎません。ただし、これまでに扱ってきた知識レベルでこのトリックを機能させるには、ちょっとした回避策が必要です。そのために、sizeof演算子と、配列に対していくつかの簡単な操作を組み合わせて使用します。
さて、次の点を考えてみてください。動的配列を宣言したとき、必要に応じて新しい要素を追加することができます。そして、最も単純な型であるuchar(あるいは場合によってはchar)を他の型のベースとして使用することができます。しかし、単に値を配列に積み重ねただけでは、データを渡すことはできません。もう少し工夫が必要です。
ここで再び登場するのが文字列型(string)です。なぜかというと、文字列は値を渡すことができるからです。私たちは、文字列がどのように終わるのか(つまり、ヌルまたはゼロの終端子で終わる)を知っています。
ここで回避策、そして楽しい部分の登場です。BASICで使われていたような文字列を作るとしたらどうでしょう。ご存じない方のために補足すると、これは以前の記事で取り上げた内容です。実際、これはもっと実用的かもしれません。それこそがポイントです。バイナリ値にヌル終端子を使うのは適切ではありません。
一方で、配列内に中立的な要素を使用して、任意の長さの配列を作成するという方法は非常に巧妙です。初心者プログラマにとって常識であるべきだと言うのは少し厳しく聞こえるかもしれませんが、これまでに説明してきたことを踏まえれば、実現できるはずです。
ここで、ほとんどの言語ではネイティブにサポートされていない仕組みを実装します。さらに重要なのは、非常に基本的なものを開発するということです。そして、多くの「経験豊富な」プログラマでさえ、MQL5で実現可能だと気づいていないのです。
教育的かつシンプルに保つために、まずは今回のモデルで使用する変数や定数を定義することから始めましょう。以下にそのコードを示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
コード06
さて、コード06を実行すると、端末に画像02のようなものが表示されます。
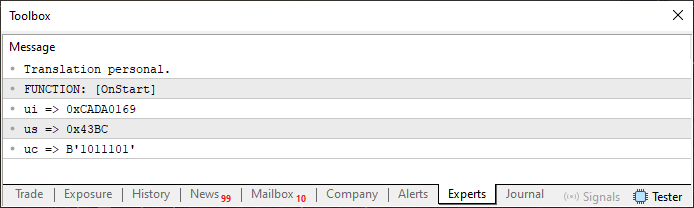
図02
さて、この結果自体は特に驚くようなものではありません。実際、これはまさに予想していた通りの結果です。しかし、ここからが面白くなってきます。コード06の12行目を見てください。すでに、後で必要になる配列を追加してあるのがわかるはずです。個人的には符号なし型を使うのが好みなので、ucharを使います。符号付き型を好む人であれば、charを使うことになるでしょう。どちらを選んでも、今回の目的の結果には影響しません。
とはいえ、ここで紹介する実装は教育目的であることを改めてお伝えしておきます。決して、この機構を実装するための最適な方法ではありません。もっと適切な実現方法は存在します。ただし、それらを使うには、まだ解説していない特定の手法や概念が必要になります。しかし、それらの概念は、これから取り組む内容を簡単にするために作られたものです。だからこそ、まずはこのコアとなる仕組みを理解してもらい、その後に実装をより洗練させる方法を紹介したいと思います。これは非常に自然な流れであり、一つのことが次のことへとつながっていくのです。
そのため、今回作成するコードには多くのインライン実装が含まれます。しかしそれは、他の実装手法を使うと、本質的な仕組みの説明が難しくなるからにすぎません。
では、8行目、9行目、10行目で定義した値を、配列へと転送する処理を始めましょう。このときに重要なのは、後で同じ値を完全に復元できる形で格納することです。そうでなければ、今回の実装全体が無意味になってしまいます。
この要件を踏まえて、実装の第一段階に進みましょう。初心者の方でも理解しやすいように、少しずつ段階を追って紹介していきます。実装の最初の部分は次のとおりです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
コード07
コードを実行すると、端末に次の結果が表示されます。
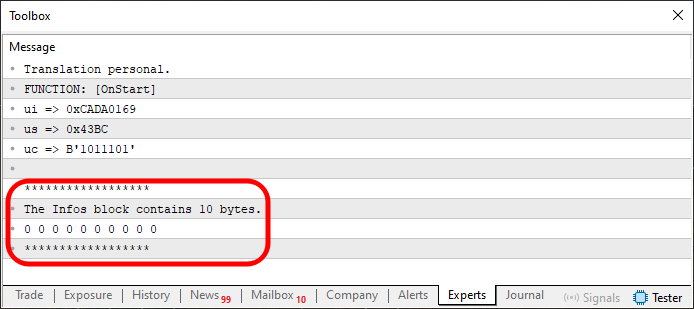
図03
さて、読者の皆さん、ここからの説明で混乱しないように、非常に注意深く読んでください。図03にハイライトされている部分は、31~34行目を実行した結果です。ただし、ここではメモリの内容と確保されたメモリのサイズの両方を表示していることに注目してください。なお、メモリの確保は25〜27行目でおこなわれています。ですが、これはまだコードの初期段階にすぎません。ここでも、私たちは一歩一歩、段階的に進めています。ある意味で、29行目のコードは不要とも言えます。あくまで、これから扱う値をどのように操作するかを定義するために使われているだけです。
これまでに解説した内容は、もう十分に理解できているかと思います。ですので、ここからは第2段階に進みましょう。すぐ下にあります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
コード08
コード08を実行すると、以下のように結果が少し興味深いものになってきます。
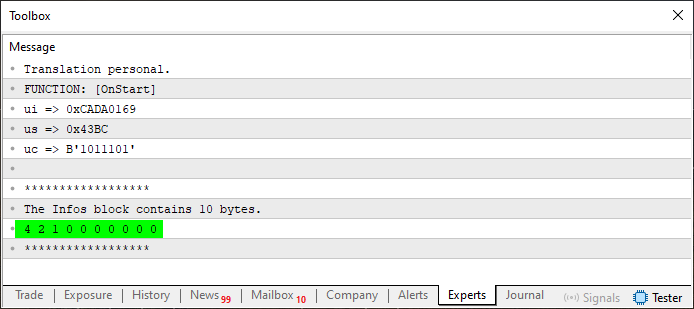
図04
ここで、配列にいくつかの値が格納されているのが確認できます。これらの値は、32行目、38行目、44行目によって挿入されています。これらの行は、それぞれ使用されているバイト数を示しています。しかし、ここで小さな問題が発生しています。これは次のステップで解決していきます。ですがその前に、コード07とコード08の違いについて理解しておきましょう。今、私たちは小さなコードブロックを形成し始めており、それらは関数や外部プロシージャに簡単にまとめることができそうです。この傾向は、28〜32行目を見ると明らかです。
次に、34〜38行目にもよく似たコードがあります。その後、40〜44行目にもほぼ同じ処理が繰り返されています。ただし、先ほども述べたように、まだ関数や外部プロシージャとして実装することはしません。なぜなら、まだ触れていない概念は使わないと決めたからです。
もちろん、すでにこれらのコードブロックを一つの関数にまとめる方法をご存じであれば、それは素晴らしいことです。実際のところ、これらの違いは主に「値を格納するために確保するメモリサイズを決定する変数」だけなのです。そして、これが次のステップへとつながります。つまり、値を配列に格納する処理です。この次のステップは、以下のコードに示されています。なお、このコードには他にも変更点があるので、注意して見てください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
コード09
もう少しです。すべてを完全に理解し、実装するまでにあと一歩だけ残っています。ただし、コード09を実行してみると、出力結果がわずかに変化していることに気づくでしょう(図05を参照)。
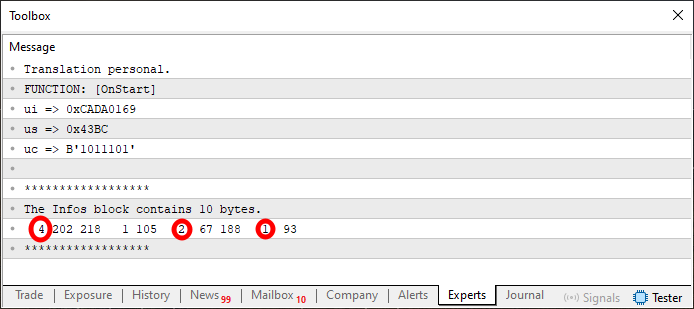
図05
この場合、図04に元々表示されていた値に印を付けました。図05に表示されている値は、一見すると少し奇妙に見えるかもしれません。ですが、コード09の動作を注意深く見てみると、これらが実際には8行目、9行目、10行目にある値そのものであることが分かるはずです。それでも、まだ半信半疑かもしれませんね。ですので、最後のステップへと進みましょう。このステップは、次のコードブロックに実装されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
コード10
そして、ついにここまでたどり着きました。これはプログラミング初心者によって書かれたコードです。すべてMQL5で開発されており、単一の配列ブロック内で無制限の情報を転送できる機能を持っています。このコードを実行した結果を以下に示します。
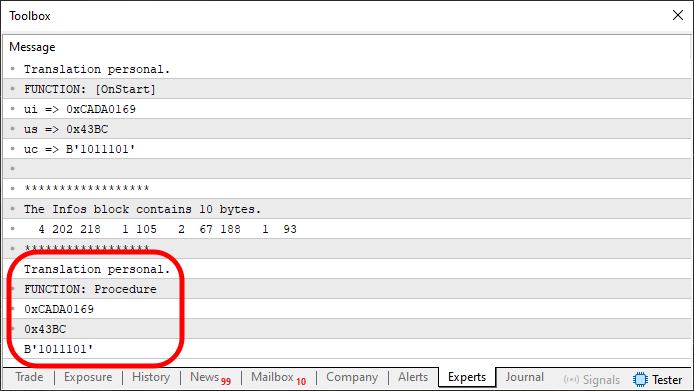
図06
一見すると、これはMQL5では実現不可能に思えるかもしれません。つまり、CやC++のような言語で存在する仕組み、すなわち関数間で不定数の値をやり取りするメカニズムを、MQL5で実装しているのです。構造次第では、MetaTrader5内の別のアプリケーション間でさえ値をやり取りすることも可能です。ただし、これはより高度なトピックであり、MQL5における他の概念やコンポーネントをしっかり理解していることが前提となります。そして同時に、MetaTrader 5が実際にどのように動作しているのかを理解している必要があります。
ここで「動作」と言っているのは、単にチャートに何かを表示するといった表面的なことではありません。そんなものには、興奮も挑戦もありません。私が言いたいのは、MetaTrader 5がなぜそのような振る舞いをするのか、そしてさらに重要なことに、それが提供している内部メカニズムをどのように活用すれば、今回のようなことが実現できるのかという本質的な部分です。これらは私の考えでは、「基本的でシンプルなテクニック」であるにもかかわらず、真に理解し、実践できている人はほとんどいません。
さて、基本的な概念を正しく適用すれば、すべてが見事に連携することに気づいてください。たとえばコード10の場合、28〜48行目で配列を構築し、その後、55行目のシンプルなコマンドで、その配列を手続き(または他の構造)へと送ります。その内部では、簡単なテクニックを使って、先ほど構築したデータを元通りに分解(復元)しています。
なぜこんなものをわざわざ作るのか。もっと単純にできるだろうと思うかもしれません。わかります。しかし、もう一度申し上げておきますが、これは最善でも最適でも効率的でもない方法です。ただし、ここで示されたロジックと仕組みを本当に理解できたならば、私たちは次の段階へ進む準備が整ったということです。
そういうわけで、今後の記事で扱うトピックはコード10に直接関係しているため、ここでそれを作成しておくのは極めて意味があり、正当なステップなのです。これは「複雑化」ではありません。むしろ、段階的にブレイクダウンした解説は、MQL5やMetaTrader 5をより高度なレベルで学びたい人にとって、非常に貴重な資料になるでしょう。
その解説は、このあと添付資料として掲載される予定です。ですから、親愛なる読者の皆さん、疑問の答えを待って時間を浪費するのではなく、ここまでと他の記事で取り上げたすべての細部を丁寧に学んでください。知識はすぐに蓄積されます。練習不足から生じる疑問と同じです。
そして最後に、この連載を良い形で締めくくるために、コード10をより簡潔な形に書き直す方法をご紹介します。これは、同じ機能をよりコンパクトでエレガントな方法で実現することが十分可能であることを示すためのものです。よりシンプルなコードの方が分析しやすいと感じる方は、以下の代替バージョンをご覧ください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
コード11
コード11を実行すると、次の出力が表示されます。
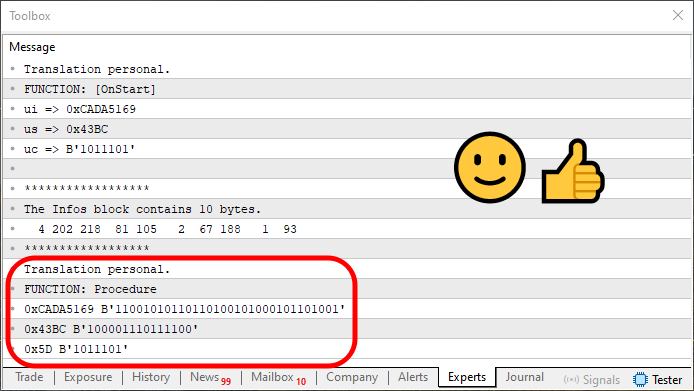
図07
図07に表示されている情報が、図06で見たものとわずかに異なっていることに注目してください。この違いは、元のデータを再構築する際に、今回は1つのループ内で処理していることに起因します(70行目に示されています)。このループは比較的シンプルですが、読者の皆さんにはぜひ注意深く読み解いていただきたい部分です。なぜなら、このループがどのようにして以前保存されたデータを再構築しているのかを理解する鍵となるからです。
本質的には、このループは常に「あるブロックに含まれているバイト数(または要素数)」を示す位置を参照しています。そのため、67行目に示されている外側のループも少し調整が必要となりました。この変更がなければ、配列から保存済みのデータを正しく取り出すことはできなかったでしょう。
最終的な考察
この記事は、これまでに議論してきた内容と、次回扱うトピックとの架け橋となることを目的としています。ここで紹介した実装が、やりすぎ、あるいは少しクレイジーに感じられた方もいるかもしれません。しかし、この記事で提示した目的とその背後にある考え方を理解できたなら、プログラミング言語において、より高度な仕組みを作る、あるいは利用する必要性があることに気づけるはずです。
実際、MQL5にはそのような仕組みがすでに存在しています。これが次回の記事のテーマです。ですが、まだピンと来ていない方は、28行目から48行目までのコードを実装せずに、しかも機能を一切損なわずに済ませるにはどうすればいいのかを考えてみてください。つまり、どうすればこの部分をもっとシンプルかつ効率的な形にできるかということです。その答えは、次回の記事で明かします。それまでの間は、ここで紹介したコード例をよく読み込み、実際に手を動かして試してみてください。すべてのコード例は、添付ファイルに含まれています。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15501
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 初級から中級まで:共用体(I)
初級から中級まで:共用体(I)
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索