
Von der Grundstufe bis zur Mittelstufe: Array (IV)

Einführung
Im vorherigen Artikel „Von der Grundstufe zur Mittelstufe: Arrays (III)“ haben wir erklärt, wie man Arrays verwendet, um Daten zwischen Funktionen und Prozeduren zu übergeben. Wir haben auch einige wichtige Details in Bezug auf die Initialisierung und grundlegende Vorsichtsmaßnahmen besprochen, die getroffen werden sollten, um zu vermeiden, dass auf lange Sicht ein nicht nachhaltiger Code entsteht. Ich glaube, viele von Ihnen sind der Meinung, dass das, was bisher gezeigt wurde, nur von begrenztem Wert ist oder nur selten praktische Anwendung findet. Aber in diesem Artikel werden wir endlich anfangen, richtig Spaß zu haben. Bis jetzt haben wir bestimmte Konzepte und einfache Regeln in Beispielen angewandt. Aber jetzt ist es an der Zeit, dass wir uns damit beschäftigen, was MetaTrader 5 wirklich ausmacht.
Bevor wir uns jedoch in die Praxis stürzen, müssen wir uns einige Dinge ansehen - Dinge, die viele von Ihnen vielleicht nicht kennen und von denen andere überhaupt keine Ahnung haben, wie sie funktionieren. Jetzt werden die Dinge sowohl interessanter als auch komplexer. Ich bitte Sie daher, die hier und in den folgenden Artikeln behandelten Themen mit Geduld anzugehen. Das Verständnis dessen, was wir hier erforschen werden, wird Ihnen sehr dabei helfen, andere Konzepte zu verstehen, die bei der Entwicklung von realen Anwendungen für MetaTrader 5 ins Spiel kommen.
Als erstes werden wir untersuchen, wie man den Speicher mit Hilfe von Arrays besser nutzen kann. Ja, wir sind noch nicht fertig mit dem Thema Arrays. Und wenn Sie dachten, dass Sie das schnell in den Griff bekommen - vergessen Sie es. Dieses Thema ist breit und umfangreich. Daher werden wir die Arrays weiterhin in kleineren Abschnitten behandeln, zusammen mit anderen Themen, wenn wir vorankommen. Auf diese Weise soll verhindert werden, dass der Stoff ermüdend oder überwältigend wird.
Bevor wir beginnen, ist es wichtig zu wissen, dass es eine Voraussetzung gibt. Sie müssen verstanden haben, wie der Code aus dem letzten Thema des vorherigen Artikels funktioniert. Insbesondere, wie man mit Arrays außerhalb ihres Deklarationsbereichs arbeitet.
Die Größe des Operators
Lassen Sie uns zunächst einen kleinen Test durchführen. Sie soll zeigen, wie Daten im Speicher manipuliert werden können. Wir werden keine gewöhnlichen Variablen verwenden, sondern versuchen, alles mit Arrays zu machen. Dadurch wird der Prozess des Erstellens, Verschiebens, Lesens und Schreibens von Variablen direkt im RAM des Computers simuliert. Ich weiß, das mag weit hergeholt klingen. Aber es ist nicht nur eine ausgezeichnete Übung in Logik und Programmierung, sondern hilft Ihnen auch, wie ein echter Programmierer zu denken. Das liegt daran, dass Sie Aufgaben erfüllen müssen, von denen viele Programmierer nicht einmal wissen, wie sie sie angehen sollen.
Wir beginnen mit einer kleinen Einführung in etwas viel Größeres. Ich werde jedoch versuchen, die Dinge so einfach wie möglich zu halten, damit jeder die Argumentation nachvollziehen kann. Zunächst müssen wir verstehen, was der sizeof-Operator eigentlich tut und warum es ihn gibt.
Der sizeof-Operator ist dafür zuständig, uns mitzuteilen, wie viele Bytes ein Datentyp oder eine Variable im Speicher belegt. Das mag ein wenig mystisch klingen. Aber eigentlich ist es ganz einfach. Zunächst ist es wichtig zu verstehen, dass die Anzahl der Elemente in einem Array nicht direkt mit der Größe des zugewiesenen Speichers übereinstimmt. Ein Array kann X Elemente haben, aber Y Bytes belegen. Die Anzahl der Elemente entspricht nur dann der Anzahl der verwendeten oder im Speicher zugewiesenen Bytes, wenn der verwendete Datentyp 8 Bit oder 1 Byte beträgt. In MQL5 sind die Typen, die dieses Kriterium erfüllen, char und uchar. Alle anderen Typen belegen mehr Bytes als die Anzahl der im Array vorhandenen Elemente. Verwechseln Sie also den „sizeof“-Operator nicht mit einer „ArraySize“-Operation oder einem „Size“-Funktionsaufruf. Sie dient dazu, die Anzahl der Elemente in einem Array zu bestimmen.
Betrachten wir das folgende Beispiel:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
Code 01
Wenn der Code 01 ausgeführt wird, ergibt sich folgendes Ergebnis:
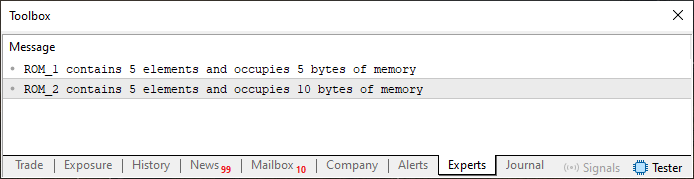
Abbildung 01
Analysieren wir nun, was uns Bild 01 sagt. Auch wenn es auf den ersten Blick recht intuitiv ist, sollten wir es etwas genauer erklären. In Code 01 werden zwei statische Arrays erstellt. Der einzige Unterschied zwischen ihnen ist, dass der eine vom Typ „char“ und der andere vom Typ „short“ ist. Ansonsten sind sie genau gleich und enthalten jeweils fünf Elemente. Der Speicherbedarf (in Bytes) ist jedoch bei beiden unterschiedlich. Warum?
Im früheren Artikel „Von der Grundstufe zur Mittelstufe: Variablen (II)“ gibt es eine Tabelle, die die Anzahl der Bytes angibt, die jeder Grunddatentyp im Speicher belegt. In dieser Tabelle sehen Sie, dass der Typ „short“ zwei Bytes belegt. Da wir fünf Elemente haben, ergibt die Multiplikation der Anzahl der Elemente im Array mit der Anzahl der Bytes, die jedes Element belegt, eine Gesamtzahl von zehn Bytes. Mit dem Operator „sizeof“ lässt sich nämlich ganz einfach feststellen, wie viel Speicherplatz belegt ist.
Und warum ist das für uns wichtig? Es ist äußerst nützlich zu wissen, wie viel Speicherplatz ein bestimmtes Datenpaket verbraucht. Sie ermöglicht es uns zum Beispiel, auf sehr einfache und direkte Weise zusätzlichen Speicher zuzuweisen oder eine bestimmte Menge an Speicher freizugeben. Allerdings haben wir das in der Praxis noch nicht angewendet. Wir werden diese Art von Maßnahmen im weiteren Verlauf häufig durchführen. Aber für unseren aktuellen Zweck ist das, was wir hier behandelt haben, mehr als ausreichend. Wir können also zur nächsten Phase übergehen.
Enumerationen
In diesem Thema geht es darum, ein sehr einfaches Konzept zu erklären. Dieses Konzept kann jedoch in zahlreichen Situationen äußerst nützlich sein. Um zu erklären, was ein Enumerator ist, und zwar auf sehr einfache und leicht verständliche Weise, greifen wir auf einen Code zurück, der in einem früheren Artikel behandelt wurde. Sie können es gleich unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Code 02
Wir haben diese Header-Datei schon einmal gesehen und werden sie hier erneut besprechen. Zu diesem Zeitpunkt wird es für uns sehr nützlich sein. Wie Sie sehen können, benötigen wir für die Verwendung eines der Formate einen beliebigen Dezimalwert. Wenn wir sie jedoch im Code verwenden, ist es ziemlich schwierig zu verstehen, was ihr Zweck ist. Der Grund dafür ist, dass ein Code, der den in Code 02 gezeigten Ansatz verwendet, wie folgt geschrieben werden müsste:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
Code 03
In diesem Fall ist die in Zeile 4 von Code 03 angegebene Header-Datei genau diejenige, die in Code 02 angegeben ist. Das Problem liegt hier jedoch speziell bei den Werten, die Sie zwischen den Zeilen 15 und 18 sehen. Können Sie anhand dieser Werte feststellen, welche Art von Verarbeitung durchgeführt wird, um die Ausgabezeichenfolge zu erzeugen? Definitiv NICHT. Sie müssten die Header-Datei konsultieren, die Funktion ValueToString finden, analysieren, wie jeder der Werte gehandhabt wird, und erst dann entscheiden, welcher Wert zu verwenden wäre. Mit anderen Worten: viel Arbeit für sehr wenig Produktivität. Gerade deshalb ist eine viel praktischere und effizientere Struktur erforderlich. Diese Struktur wird als ENUM bezeichnet. Mit der Enumeration wird ein spezieller Datentyp geschaffen, der mit jedem neu hinzugefügten Wert einer fortschreitenden Zählung folgt. Es ist sehr bequem und einfach zu bedienen.
Wenn wir also den Code 02 in einen Code ändern, der eine Enumeration verwendet, erhalten wir den folgenden Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
Code 04
Dies ist eigentlich sehr einfach zu realisieren. Natürlich geht es hier um die Erstellung einer einfachen Enumeration. Aber ich hoffe, dass Sie leicht verstehen können, was in der vierten Zeile vor sich geht. Sobald die Enumeration definiert ist, können wir die Ersetzungen vornehmen, die Sie im Rest des Codes sehen. In diesem Fall sieht der vorherige Code 03 wie unten abgebildet aus.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
Code 05
Seien wir ehrlich. Wenn man sich den Code 05 ansieht, ist doch klar, was der Code macht, oder? Trotz dieser kleinen Änderung würde der Code 03 weiterhin ohne Änderungen funktionieren. Zumindest bis wir weitere Änderungen an der Enumeration vornehmen. Aber im Moment lassen wir die Dinge so, wie sie sind. Es wäre nicht sinnvoll, sich jetzt schon mit fortgeschrittenen Details über Enumerationen zu befassen. Wir werden in naher Zukunft noch einmal auf dieses Thema zurückkommen, allerdings mit einem anderen Ziel.
Eine unendliche Anzahl von Argumenten
Lassen Sie uns nun zu einem etwas fortgeschritteneren Thema übergehen, um diesen Artikel interessanter zu gestalten. In einem früheren Artikel habe ich gezeigt, wie man eine Binärwertdarstellung für die Visualisierung im MetaTrader 5-Terminal erstellt. Ich erwähnte, dass es einige Schwierigkeiten bei der Erstellung einer Prozedur in MQL5 mit einem ähnlichen Verhalten wie in C und C++ gab. Soweit ich weiß, sind C und C++ die einzigen Sprachen, die diese Art der Implementierung von Haus aus unterstützen. Allerdings bietet auch Java etwas Ähnliches.
In diesen Sprachen können Sie eine Funktion oder Prozedur erstellen, die keine feste Anzahl von Argumenten oder Parametern erfordert. Stattdessen gibt es eine Mindestanzahl von Argumenten, die beim Aufruf der Funktion angegeben werden müssen. Es muss mindestens ein Parameter angegeben werden.
Sobald dieses Minimum erfüllt ist, können Sie so viele zusätzliche Argumente wie nötig übergeben. Innerhalb der Funktion oder Prozedur gibt es drei spezielle Aufrufe, mit denen Sie auf jedes zusätzliche Argument einzeln zugreifen können. Für Interessierte oder Neugierige gibt es die drei Funktionen va_start, va_arg und va_end, die von C und C++ verwendet werden. In Java unterscheiden sich die Namen geringfügig, aber das Funktionsprinzip ist im Wesentlichen dasselbe. Wenn wir das Konzept hinter diesen Funktionen verstehen, können wir hier in MQL5 etwas sehr Ähnliches aufbauen.
Manche mögen dieses Material als fortgeschritten betrachten. Meiner Meinung nach ist dies jedoch ein grundlegendes Wissen, das jeder Anfänger beherrschen sollte. Im Wesentlichen werden wir mit der Array-Manipulation in MQL5 herumspielen. Aber um den Trick auf dem bisherigen Wissensstand anzuwenden, müssen wir eine kleine Umgehung anwenden. Wir werden den sizeof-Operator zusammen mit einigen einfachen Manipulationen an einem Array verwenden.
Wenn wir ein dynamisches Array deklarieren, können wir ihm bei Bedarf neue Elemente hinzufügen. Und da der einfachste Typ uchar (oder char, je nach Fall) ist, können wir ihn als Basis für andere Typen verwenden. Aber das einfache Stapeln von Werten in einem Array erlaubt es uns nicht, Daten zu übergeben. Wir brauchen etwas Nachdenklicheres.
Damit sind wir wieder beim Typ String. Der Grund dafür ist, dass Strings es uns ermöglichen, Werte zu übergeben. Wir wissen, wie jeder String endet. Das heißt, mit einer Null oder einem Nullterminator.
Und hier kommen unsere Abhilfe und der Spaßfaktor ins Spiel: Was wäre, wenn wir eine Zeichenkette ähnlich der in BASIC verwendeten erstellen würden? Für diejenigen, die damit nicht vertraut sind, habe ich dies in einem früheren Artikel erläutert. Das könnte tatsächlich viel nützlicher sein. Genau das ist der Punkt. Die Verwendung eines Nullterminators in Binärwerten wäre nicht angemessen.
Andererseits ist die Verwendung eines neutralen Elements innerhalb eines Arrays zur Erstellung eines Arrays beliebiger Länge ziemlich genial. Es mag sogar ein wenig hart erscheinen, zu sagen, dass dies für jeden Programmieranfänger zum Allgemeinwissen gehören sollte. Aber ja, basierend auf dem, was wir bisher behandelt haben, können wir etwas bauen, das dies erreicht.
Wir werden einen Mechanismus implementieren, den nur wenige Sprachen von Haus aus unterstützen können. Viel wichtiger ist, dass wir etwas Grundlegendes entwickeln. Und doch haben viele so genannte erfahrene Programmierer nie realisiert, dass dies in MQL5 möglich ist.
Um die Dinge einfach und lehrreich zu halten, beginnen wir mit der Definition von Variablen und Konstanten, die in unserem Beispielmodell verwendet werden sollen. Daraus ergibt sich der folgende Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
Code 06
Ok, wenn Sie Code 06 ausführen, sehen Sie im Terminal etwas, das wie in Abbildung 02 aussieht.
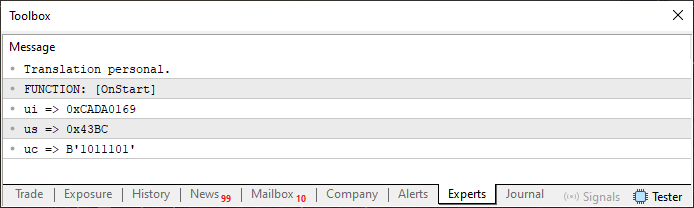
Abbildung 02
Nun, dieses Ergebnis ist nichts Außergewöhnliches. Tatsächlich ist es genau das, was wir erwartet haben. Aber jetzt wird es interessant. Beachten Sie, dass ich in Code 06 in Zeile 12 bereits ein Array hinzugefügt habe, das wir später brauchen werden. Ich persönlich ziehe es vor, den vorzeichenlosen Typ zu verwenden, weshalb ich uchar verwende. Andere ziehen es vielleicht vor, den Typ mit Vorzeichen zu verwenden; in diesem Fall würden sie char verwenden. Wie auch immer, diese Entscheidung wird unser angestrebtes Ergebnis nicht beeinträchtigen.
Ich möchte Sie jedoch darauf hinweisen, dass die hier gezeigte Umsetzung nur zu Lehrzwecken dient. Dies ist keineswegs der optimale Weg, um diesen Mechanismus umzusetzen. Es gibt weitaus geeignetere Wege, dies zu erreichen. Sie erfordern jedoch bestimmte Methoden und Konzepte, die wir noch nicht behandelt haben. Da diese Konzepte jedoch geschaffen wurden, um genau das zu vereinfachen, was wir jetzt erforschen wollen, halte ich es für sinnvoll, Ihnen zunächst das Kernkonzept zu zeigen und dann die Methoden vorzustellen, die später entwickelt wurden, um die Implementierung sauberer und einfacher zu gestalten. Es ist eine ganz natürliche Entwicklung, bei der eine Sache zur nächsten führt.
Aus diesem Grund wird der Code, den wir erstellen werden, viele Inline-Implementierungen enthalten. Das liegt aber nur daran, dass es schwierig wäre, zu erklären, wie die zugrunde liegende Methode funktioniert, wenn wir eine andere Implementierung verwenden würden.
Beginnen wir also damit, die in den Zeilen 8, 9 und 10 deklarierten Werte in das Array zu übertragen. Denken Sie daran, dass wir dies so tun müssen, dass wir später genau dieselben Werte rekonstruieren können. Andernfalls wäre die gesamte Umsetzung völlig sinnlos.
Mit dieser Vorgabe im Hinterkopf können wir nun zum ersten Teil der Implementierung übergehen. Ich werde es in kleinen Schritten darstellen, sodass auch Anfänger folgen können und vollständig verstehen, was wir schaffen. Hier ist der erste Teil der Umsetzung:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
Code 07
Nach der Ausführung des Codes sehen wir im Terminal das folgende Ergebnis.
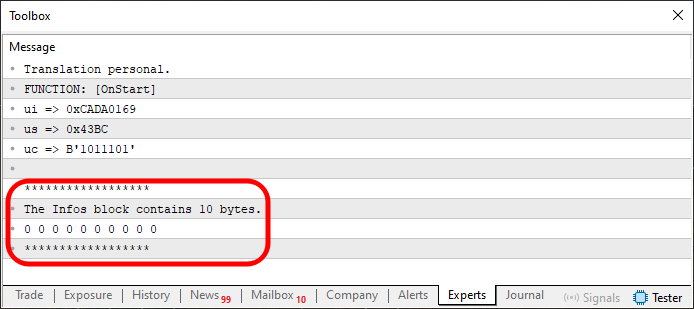
Abbildung 03
Passen Sie nun gut auf, liebe Leserin, lieber Leser, damit Sie sich nicht in der Erklärung verlieren. Der in Abbildung 03 hervorgehobene Abschnitt ist das Ergebnis der Ausführung der Zeilen 31-34. Sie werden jedoch feststellen, dass wir sowohl den Inhalt des Speichers als auch die Menge des zugewiesenen Speichers anzeigen. Beachten Sie, dass die Speicherzuweisung zwischen den Zeilen 25 und 27 erfolgt. Aber bedenken Sie, dass dies nur der Anfang des Codes ist. Wir gehen die Dinge Schritt für Schritt an. In gewisser Weise ist der Code in Zeile 29 unnötig. Er dient nur dazu, zu definieren, wie wir mit den Werten arbeiten werden.
Ich glaube, dass alles, was wir bisher behandelt haben, inzwischen ziemlich gut verstanden sein sollte. Wir können also zum zweiten Schritt übergehen. Sie können es gleich unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
Code 08
Wenn wir nun Code 08 ausführen, werden die Ergebnisse etwas interessanter, wie Sie unten sehen können:
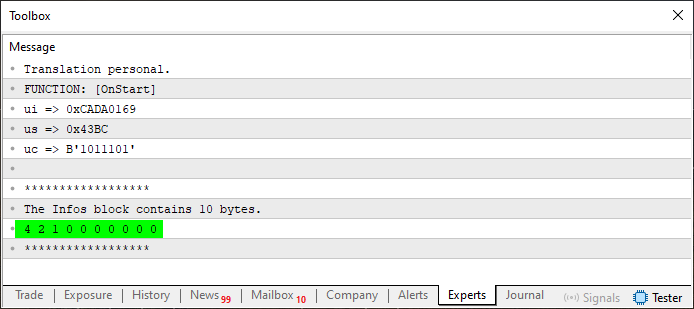
Abbildung 04
Jetzt erscheinen einige Werte in dem zu erstellenden Array. Diese Werte erscheinen aufgrund der Zeilen 32, 38 und 44, die angeben, wie viele Bytes verwendet werden. Allerdings gibt es hier ein kleines Problem, das wir im nächsten Schritt beheben werden. Doch bevor wir dazu kommen, wollen wir erst einmal verstehen, was sich zwischen Code 07 und Code 08 geändert hat. Wir beginnen, kleine Codeblöcke zu bilden, die leicht in eine Funktion oder sogar eine externe Prozedur verschoben werden können. Dies ist zwischen den Zeilen 28 und 32 deutlich zu erkennen.
Dann sehen wir etwas sehr Ähnliches zwischen den Zeilen 34 und 38, gefolgt von einer fast identischen Wiederholung zwischen den Zeilen 40 und 44. Aber wie ich bereits erwähnt habe, werden wir sie noch nicht als externe Funktion oder Prozedur implementieren. Denn wir haben beschlossen, kein Konzept zu verwenden, das nicht schon einmal behandelt wurde.
Nun, wenn Sie bereits wissen, wie Sie diese Blöcke in einer einzigen Funktion zusammenfassen können – großartig. Der einzige wirkliche Unterschied zwischen ihnen ist die Variable, die verwendet wird, um genügend Speicherplatz für den Wert zuzuweisen. Und damit sind wir beim nächsten Schritt angelangt. Damit wird der Wert in das Array eingefügt. Dieser nächste Schritt ist im nachstehenden Code dargestellt. Bitte beachten Sie, dass es weitere Änderungen im Code gibt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
Code 09
Wir sind fast am Ziel. Es bleibt noch ein weiterer Schritt, bevor alles vollständig verstanden und umgesetzt ist. Wenn Sie jedoch Code 09 ausführen, werden Sie feststellen, dass sich die Ausgabe leicht verändert hat, wie in Abbildung 05 dargestellt.
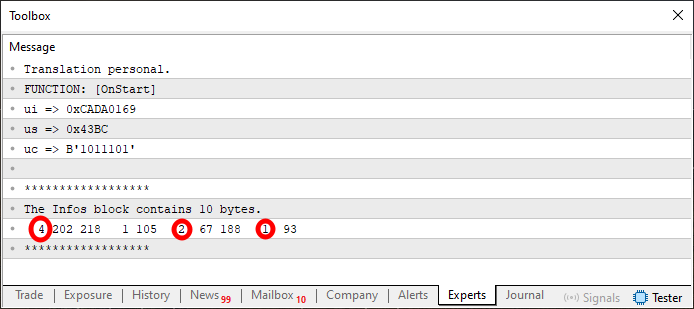
Abbildung 05
In diesem Fall haben wir die Werte markiert, die ursprünglich in Abbildung 04 enthalten waren. Mir ist klar, dass die in Abbildung 05 dargestellten Werte auf den ersten Blick etwas seltsam aussehen könnten. Wenn Sie sich jedoch genau ansehen, was in Code 09 passiert, werden Sie feststellen, dass dies genau die Werte aus den Zeilen acht, neun und zehn sind. Vielleicht sind Sie da noch skeptisch. Lassen Sie uns also zum letzten Schritt übergehen. Er wird im nächsten Codeblock implementiert, der unten gezeigt wird.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
Code 10
Und da haben wir ihn - den von einem Programmieranfänger geschriebenen Code. Es ist vollständig in MQL5 entwickelt und kann eine unbegrenzte Menge an Informationen innerhalb eines einzigen Array-Blocks übertragen. Das Ergebnis der Ausführung dieses Codes ist unten dargestellt:
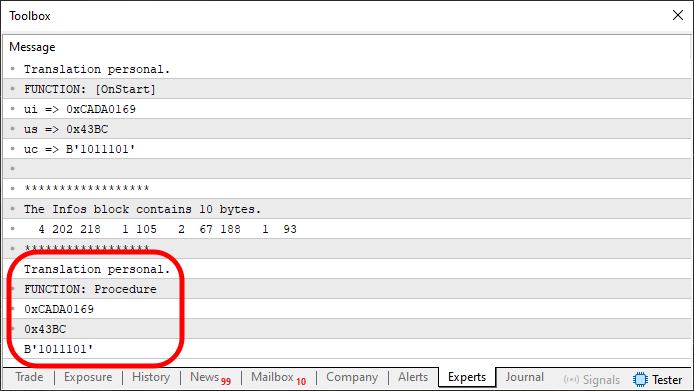
Abbildung 06
Auf den ersten Blick mag es so aussehen, als sei dies in MQL5 nicht möglich. Das heißt, es wird ein in Sprachen wie C und C++ vorhandener Mechanismus implementiert, der es ermöglicht, eine unbestimmte Anzahl von Werten von einer Funktion an eine andere zu senden. Je nachdem, wie wir die Dinge strukturieren, sogar von einer Anwendung zur anderen innerhalb von MetaTrader 5. Dies ist jedoch ein fortgeschrittenes Thema, das ein solides Verständnis einiger anderer Konzepte und Komponenten in MQL5 erfordert. Sie müssen auch verstehen, wie MetaTrader 5 wirklich funktioniert.
Wenn ich von Operationen spreche, meine ich nicht einfach nur die Darstellung von Dingen in einem Chart. Das ist weder aufregend noch eine Herausforderung. Was ich meine, ist zu verstehen, warum MetaTrader 5 tut, was er tut. Und, was noch wichtiger ist, wie man die internen Mechanismen, die es bietet, nutzt, um Dinge zu erreichen, wie wir sie hier demonstriert haben. Meiner Meinung nach handelt es sich dabei um grundlegende und einfache Techniken, die jedoch nur wenige wirklich verstehen oder effektiv anwenden.
Sie werden sehen, dass sich alles wunderbar zusammenfügt, wenn wir die grundlegenden Konzepte richtig anwenden. In Code 10 geschieht Folgendes: Zwischen den Zeilen 28 und 48 wird das Array konstruiert. Dann schicken wir mit einem einfachen Befehl in Zeile 55 dasselbe Array in eine Prozedur (obwohl es auch etwas anderes sein könnte). Im Inneren dekonstruieren wir mit einer einfachen Technik das, was wir zuvor zwischen diesen früheren Zeilen aufgebaut haben.
Sie könnten fragen: „Warum so etwas schaffen? Sie machen die Dinge nur zu kompliziert.“ Und ich verstehe das. Ich möchte Sie jedoch darauf hinweisen, dass dies keineswegs die beste oder effizienteste Methode ist, um dies zu tun. Wenn Sie, liebe Leserin, lieber Leser, die Logik und die Mechanik hinter dem, was hier gezeigt wurde, wirklich verstanden haben, können wir zu anderen Konzepten übergehen.
Da die Themen der folgenden Artikel in direktem Zusammenhang mit dem Kodex 10 stehen, ist seine Einführung hier sowohl relevant als auch gerechtfertigt. Dies ist in der Tat keine Komplikation. Diese schrittweise Aufschlüsselung, die in der Anlage enthalten ist, wird im Folgenden erläutert. Es ist sehr wertvoll für jeden, der MQL5 und MetaTrader 5 auf einer fortgeschrittenen Ebene erforschen möchte.
Verschwenden Sie also keine Zeit damit, auf die Antworten auf die Fragen zu warten, die sich in Ihrem Kopf auftun. Studieren Sie jedes Detail, das in diesem und anderen Artikeln besprochen wird. Und das Wichtigste: Üben Sie das, was demonstriert wird. Wissen sammelt sich schnell an. Genauso wie die Zweifel, die aus mangelnder Übung entstehen.
Und zum Abschluss dieses Artikels zeige ich Ihnen, wie Code 10 in einer prägnanteren Form umgeschrieben werden könnte. Damit soll gezeigt werden, dass es durchaus möglich ist, die gleiche Funktionalität auf kompaktere, elegantere Weise zu erreichen. Wenn Sie es bequemer finden, schlankeren Code zu analysieren, der im Wesentlichen dieselbe Aufgabe erfüllt, sehen Sie sich die alternative Version unten an.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Code 11
Nach der Ausführung von Code 11 erscheint folgende Ausgabe:
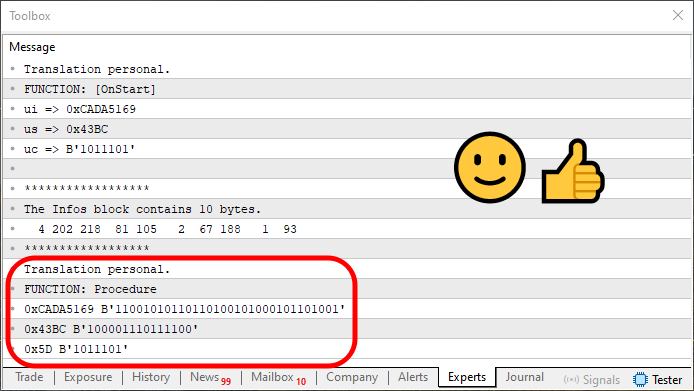
Abbildung 07
Beachten Sie, dass sich die in Abbildung 07 angezeigten Informationen leicht von denen in Abbildung 06 unterscheiden. Dieser Unterschied ist auf die Tatsache zurückzuführen, dass wir die ursprünglichen Daten nun in einer einzigen Schleife rekonstruieren. Sie wird in Zeile 70 angezeigt. Diese Schleife ist relativ einfach. Aber ich möchte Sie, liebe Leserin, lieber Leser, dringend bitten, sie sorgfältig zu studieren, um zu verstehen, wie sie die zuvor gespeicherten Daten wiederherstellt.
Im Wesentlichen schaut die Schleife ständig auf die Position, die uns sagt, wie viele Bytes oder Elemente in einem bestimmten Block enthalten sind. Aus diesem Grund musste die äußere Schleife in Zeile 67 leicht angepasst werden. Ohne diese Änderung wäre es nicht möglich, die gespeicherten Daten korrekt aus dem Array abzurufen.
Abschließende Überlegungen
Dieser Artikel soll als Brücke zwischen dem, was wir bisher besprochen haben, und dem, was als Nächstes kommt, dienen. Ich verstehe, dass viele die hier gezeigte Umsetzung als übertrieben oder sogar ein wenig verrückt empfinden könnten. Wenn Sie jedoch in der Lage waren, den Zweck und die Argumentation hinter dem, was in diesem Artikel vorgestellt wurde, zu verstehen, werden Sie wahrscheinlich erkennen, dass es einen echten Bedarf gibt, etwas mehr in der Sprache zu schaffen oder zu verwenden.
Ein solcher Mechanismus existiert bereits in MQL5. Und das wird das Thema meines nächsten Artikels sein. Wenn Sie es noch nicht verstanden haben, sollten Sie Folgendes bedenken: Was müssten wir tun, um den Code zwischen den Zeilen 28 und 48 nicht implementieren zu müssen? Und das ohne Verlust an Funktionalität. Mit anderen Worten: Wie könnten wir die Linien in eine viel sauberere und effizientere Form bringen? Denken Sie darüber nach, und die Antwort wird im nächsten Artikel gegeben. Bis dahin lernen und üben Sie anhand der hier gezeigten Code-Beispiele. Alle Code-Beispiele sind im Anhang zu finden.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15501
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.