
初級から中級まで:オーバーロード

はじめに
前回の「初級から中級まで:浮動小数点」では、浮動小数点数の基本について解説しました。なぜこれを出発点としたかといえば、それが非常に重要だからです。私の考えでは、floatやdouble型がどのように動作するかを理解することは、より複雑な問題に取り組むために絶対に必要なことです。
この記事の内容は、優れたプログラマーを目指す人が必ず習得すべきことのごく一部にすぎませんが、それでもすでに他のトピックに進むには十分です。とはいえ、ある時点で浮動小数点数に再び立ち戻る必要が出てくるでしょう。ただし、そのときはより高度なレベルで扱うことになります。すべてには順序があるのです。
それでもなお、この記事は多くの人に、プログラム、特に取引プラットフォームを扱う際には、誤りは金銭的損失に直結するという現実を理解してもらう助けになったと思います。私たちは計算において絶対的な正確さを追求することはできません。なぜなら、浮動小数点数そのものの性質が完全な正確さを許さないからです。私たちにできるのは、受け入れ可能または妥当だと考えられる値にできる限り近づけることだけであり、そのうえで特定の資産や金融商品の売買を決定する必要があります。
ただし、これらの問題はプラットフォームのオペレーターやユーザーにより深く関わるものであり、私たちの主な活動、すなわちプログラミングそのものとは少し異なります。プログラマーとして私たちは、計算にはある種のリスクがあることをアプリケーションの利用者に警告しなければなりません。その後はユーザーやトレーダー自身が、データを調整し「その時点でどれほど意味があるか」を判断して売買の意思決定をおこなう必要があります。
それにもかかわらず、私はまだインジケーターやエキスパートアドバイザー(自動売買ロボット)を実際にプログラムすることについて語るだけの十分に強固で整った基盤があるとは考えていません。必要なことについてすでに良い理解はできていますが、状況によっては「手が縛られた状態」に陥る可能性があります。なぜなら、まだ説明していないことがあるからです。そしてそれらは、さまざまな状況や目的において本当に必要となるものです。それらの知識がなければ実装不可能なことも多いのです。
そして、今後の記事で退屈で煩雑な細部に入り込むのは望ましくないため、私はあらかじめ「本当に強固な基盤」を築いておきたいと考えています。そうすることで、記事をより面白くできるだけでなく、提供する内容の質も高められます。細かい説明に時間を割かずに済めば、その分さらに多くの知識を伝えることが可能になるからです。
まだいくつか説明しなければならない事柄が残っています。そしてそれは、多くの初心者にとってかなり難しいものでもあります。しかし、上のレベルに進む前にそれらにきちんと時間を割く必要があります。
配列と文字列について一方が他方に繋がるという形で示したのと同じように、ここでも、より複雑なものに進む前に、まず明らかにしておくべき仕組みが存在します。その理由は単純です。一見するとややこしい仕組みが、実は別の仕組みを実現する助けになるということを理解すれば、はるかに明確に見えてくるからです。そして初心者の多くは、それを理解していないために無駄に多くのルーチンや関数、手続きを作ってしまっています。より洗練されたコード、つまり、特定の言語でどう実装すればよいかを深く理解しているプログラマーが書くコードであれば不要となるものをです。私たちの場合はMQL5において。
それでは話を切り替えて、新しいトピックに進みましょう。
オーバーロードとは
初心者プログラマー、あるいはアマチュアプログラマーを完全に混乱させ、コードの断片をまったく理解できなくさせるものがあるとすれば、それは「同じコード内に同じ名前を持つ関数や手続きが2つ存在する場合」です。そう、これは実際に起こり得ることであり、起こったときには経験の浅いプログラマーや知識の少ないプログラマーは完全に方向感覚を失い、そのコードを修正することも、改善することも、さらにはそれを基に自分自身のコードを作成することすらできなくなります。
このようなことは、知らない人にとっては極めて混乱を招き、まったく論理がないように見えるかもしれませんが、いくつかの簡単なルールさえ守れば、コンパイラにとっては十分可能であり、許容され、正しく扱えるものなのです。
多くの人が、私が正気を失ったのではないか、話の筋道を完全に見失ったのではないかと感じるかもしれません。なぜなら、同じ名前を持ちながら異なる目的で呼び出される2つの関数をどのように使うのか、まったく見当がつかないからです。では、非常にシンプルな例を1つ見てみましょう。ごく単純なものです。これによって、私が何を話しているのか、そしてこれから何を説明しようとしているのかがわかるでしょう。
それでは、以下のコードを見てみましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
コード01
ここで「コード01」を見て、できるだけ正直に、結果を見る前に考えてみてください。このコードは一体どう実行されるでしょうか。もう少し分かりやすく言えば、コード内でPrint呼び出しを使うのはMetaTrader 5端末に値を出力したいときだということは知っているはずです。そしてここでは、Printライブラリ手続きの呼び出しが4回あります。
つまり、先ほどの質問を言い換えると、端末には何が表示されるかということです。もちろん、6行目と7行目を見れば「値35と値15が出力されるだろう」と言うかもしれません。そして、それが最も明白な部分です。私が興味を持っているのは、どちらの関数が実行されるのかという点です。10行目のSum関数なのか、それとも16行目のSum関数なのか。「ちょっと考えてみましょう。でもこれはコンパイルされません。なぜなら、10行目と16行目に同じ名前を持つ関数が2つあるからです。もしかして私を引っかけようとしましたか。」
実際にその通りで、あなたは完全に正しいのです。ここには確かに「引っかけ」があります。というのも、2つの関数や手続きが同じ名前を持つことはできないからです。これは事実であり、それに反することを言う人は、嘘をついているか、あるいは何かを隠しているのです。しかし、奇妙に聞こえるかもしれませんが、このケースはそのルールに当てはまりません。なぜなら、10行目と16行目に示されたSum関数は同じ関数ではないからです。両者が同じ処理をおこない、正しく動作するとしても、名前が同じでも、コンパイラはそれらを1つの関数とは見なさず、異なる2つの関数として扱うのです。
しかし、ここで私自身が混乱してしまいました。なぜなら、同じコード内で同じ名前の関数や手続きは使えないことは知っているからです。そしてこれは事実です。使えません。けれどもここで私たちがやっているのは「関数や手続きのオーバーロード」と呼ばれるものです。
この「オーバーロード」という概念は、プログラミングをしていて最も楽しいもののひとつです。なぜなら、オーバーロードをうまく設計すれば、コードをずっと読みやすくできるからです。もちろん、同じことを達成するためのより効率的な方法は存在しますが、コード01に示されているオーバーロードを理解しない限り、MQL5言語に存在する別の仕組みを理解することはほぼ不可能です(いや、完全に不可能かもしれません)。ですがその話は後回しにしましょう。まずはオーバーロードとは何か、そしてそれがどのように動作するのかを整理する必要があります。
オーバーロードとは、まさにコード01の10行目と16行目に見られる現象です。これを完成させると、下の図に示されているものが生成されます。
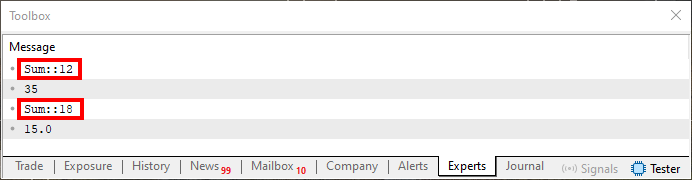
図01
ここで私たちが注目すべきなのは、6行目と7行目に出力される値そのものではなく、画像中で強調されている値です。今重要なのはこのデータです。ここで一方は12行目を参照し、もう一方は18行目を参照していることに気づくでしょう。何故でしょうか。
理由は、6行目と7行目の呼び出しで渡される値の型にあります。コンパイラが実行ファイルを生成しようとするとき、それらの値を見て「この値はこの関数の期待されるパラメータに対応している。この値は別の関数のパラメータに対応している」と判断します。そして、同じ名前を持つ複数の呼び出しを許可するのです。
ただし、ここで重要なのは引数や期待されるパラメータは同一であってはならないという点です。部分的に似ていることはあってもかまいませんが、数が異なるか、少なくとも1つは型が異なる必要があります。そうでなければ、コンパイラはどちらのコードに処理を送ればいいのかを理解できず、これはエラーと見なされます。
今回のケースでは、10行目のSumと16行目のSumは異なる型を使っています。7行目の第2引数が整数型とは異なるため、コンパイラは、この場合は浮動小数点数の引数を期待する関数を呼び出す必要があると理解するのです。
この知識を定着させるために、次は別のケースを見てみましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum((char)-10, 25)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(int arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(char arg1, ulong arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return (double)(arg1 + arg2); 20. } 21. //+------------------------------------------------------------------+
コード02
さて注意してください。コード02は、画像01に示されたものと同じ結果を出力します。しかし、ここで扱っているのは前回のように単純なものではありません。この種のコードは、多くの経験の浅いプログラマーにとって非常に混乱を招くものであり、そのために彼らは混乱を避けるためコードを書き換えようとします。しかしそうしてしまうと、かえって自分自身に問題を作り出すことになります。なぜなら、その結果は期待していたものでも、コードを書いた作者の意図するものでもなくなってしまうからです。
このため、未知のコードを変更しようとする前に、まずはそのコードがどのように動作するのかを調べるようにしてください。可能であれば、制御された環境で実行し、処理の流れを理解しましょう。自分が何かを見落としている可能性があるのに、それを理解せずに変更を加えようとするのは、初心者プログラマーが犯す最大の過ちのひとつです。
それでは整理してみましょう。コード02の10行目と16行目にあるSum関数は、依然として同じ型の値を返します。19行目で明示的な型変換を使っているのは、コンパイラが型の不一致に文句を言わないようにするためです。
ここで重要なのは次の点です。10行目のSumと16行目のSumの違いは、受け取る第1引数の型にあります。多くの人が混乱するのはこの部分です。一見すると、10行目の関数で4バイト型を使い、16行目の関数で1バイト型を使うことに意味がないように思えるからです。
実際、この例では完全に不要です。しかし、何らかの理由でプログラマーが関数内での処理を工夫したい場合、16行目の関数はchar型を受け取るべきであり、int型では適切でないということも考えられます。この問題には別の解決方法があり、その方法については別の記事で解説する予定です。ここでは、あなたがまだその方法を知らないという前提で、コード02のように実装することを選んだとしましょう。
では、それは悪いことなのでしょうか。いいえ、コード02のようにコードを作成し、記述し、実装することは悪いことではありません。それは単に、MQL5でのプログラミング方法について、もう少し学ぶべきであるということを意味するに過ぎません。ですが決して悪いことではありません。
以上が、オーバーロードの単純な形式でした。もうひとつの形式として異なる型のパラメータを使うのではなく、異なる数のパラメータを使うというものがあります。おそらく、これが最も一般的なケースでしょう。なぜなら、CやC++とは異なり、MQL5では関数や手続きの宣言を変えずにほぼ無限の数のパラメータを実装することはできないからです。もっとも、テスト的にではありますが、それを実現する方法は存在します。その方法については前回の記事で少し触れましたが、あれは本当に「序章」に過ぎません。特定の仕組みを説明すれば、実際にどこまでできるのかを示すことができます。
ここで改めて考えてください。本当に「学びたい」「きちんと勉強したい」と思っているのであれば、このもうひとつの形式のオーバーロードはどのように見えるでしょうか。それは、このすぐ下で確認できます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25, 4)); 08. } 09. //+------------------------------------------------------------------+ 10. long Sum(long arg1, long arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. long Sum(long arg1, long arg2, long arg3) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2 + arg3; 20. } 21. //+------------------------------------------------------------------+
コード03
この場合、結果は次の画像のようになります。
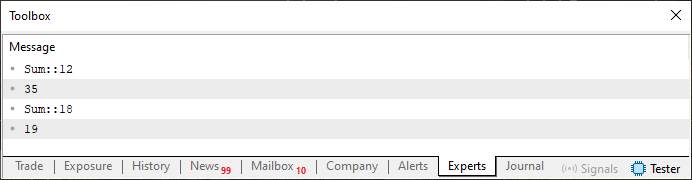
図02
私が見たところ、例03のようなコードは、多くの初心者にとって他のものより理解しやすいようです。なぜなら、それぞれのケースでどの関数や手続きが呼び出されるのかを直感的に把握しやすいからです。多くの人は、この(コード03で示された)実装方法を「オーバーロード」とは考えません。しかし文献によっては、多くの著者がこれをオーバーロードの一種として扱っています。なぜなら、関数名は同じままだからです。
さて、何がオーバーロードで何がそうでないかは、これで明確になったと思います。ですが、まだひとつ疑問が残っています。それは、なぜこれが動作するのか、そしてコンパイラは「異なる型が使われている」というだけで、どうやってこれら2つの実装を区別できるのかということです。少なくとも一見すると、あまり論理的には思えません。
実際のところ、これは完全に論理的というわけではありません。なぜなら、私たちが関数を使うときは「宣言された名前」で呼び出すのであって、別の名前を使うわけではないからです。では、なぜ動作するのでしょうか。理由はこうです。コードを実行可能なものにするために、コンパイラは「実行フローを正しく誘導する方法」を理解する必要があるのです。そして、関数や手続きのオーバーロードが使われた場合、コンパイラは内部的に一意な名前を生成します。ここで「内部的」と言ったのは、その名前が正確にどのように作られるのかを私たちは知らないからです。ただし一般的には、いくつかの単純なルールでおこなわれています。
たとえば、コード03を見てみましょう。10行目のSum関数を、コンパイラは内部的にSum_long_longと呼ぶかもしれません。そして16行目の関数はSum_long_long_longとして呼ばれるかもしれません。見た目は単純ですが、これは大きな違いを生みます。なぜなら、これは、一意な名前を持つ関数を作成することに非常によく似ているからです。
同じことはコード02にも当てはまります。10行目の関数をコンパイラはSum_int_ulongと解釈し、16行目の関数をSum_char_ulongと解釈するかもしれません。ここまでくれば、すべてが筋が通り始めます。つまり、コンパイラはその瞬間ごとに「実行フローをどこに送るべきか」を理解できるということです。
重要な注意点があります。ここで使った命名規則は、あくまで説明のためのものです。実際には、実装やコンパイラ開発者の意図によって、この命名はまったく異なる可能性があります。ただし、内部的にコンパイラはこれと似た処理をおこなっているということを理解しておけば十分です。
これでオーバーロードの使い方については、ほぼ完了です。残っているのは2つの例だけであり、これらは非常に興味深いものなので、ぜひお見せしたいと思います。最初のものを以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int v = -5; 07. 08. Sum(v, Sum(10, 25)); 09. Print(v); 10. } 11. //+------------------------------------------------------------------+ 12. long Sum(long arg1, long arg2) 13. { 14. Print(__FUNCTION__, "::", __LINE__); 15. return arg1 + arg2; 16. } 17. //+------------------------------------------------------------------+ 18. void Sum(int &arg1, long arg2) 19. { 20. Print(__FUNCTION__, "::", __LINE__); 21. 22. arg1 += (int)arg2; 23. } 24. //+------------------------------------------------------------------+
コード04
この場合、オーバーロードされた関数を手続きと併用することができます。名前は同じですが、型の違いによって実行フローをこちらに向けるか、あちらに向けるかを切り替えることができるのです。ここで重要なのは、コード04がどのように実装されているか、どの型の引数が使われているか、コード自体がどのように構造化されているかによって、結果が変わってくる可能性があるという点です。その違いは、宣言におけるちょっとした変更、つまり、型の違いであったり、8行目がどのように解釈されるかにすぎません。
次の事実に注目してください。8行目は一見すると12行目で提供された関数を参照しているように見えます。しかし、最初の引数として変数を使用しているという事実そのものが、実際には18行目を呼び出そうとしていることを示しています。ところが、もし8行目で宣言された型が18行目で期待されている型と互換性がなければ、18行目を呼び出すことは決してできず、すべての処理は12行目で実行されることになります。このため、関数や手続きのオーバーロードを不適切に、または注意を欠いて使用することは推奨されません。そうすると、期待していたものとは大きく異なる結果につながる可能性があるからです。
それでもなお、提示されている形のコード04を実行すれば、次の画像に示された結果が得られることになります。
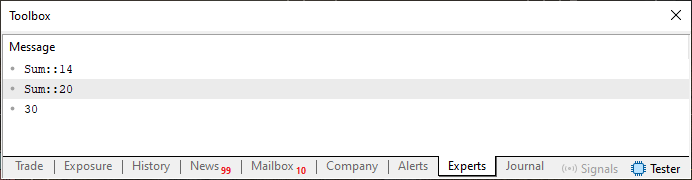
図03
改めて強調しておきたいのは、この結果が得られたのは型が完全に一致していたからこそであり、コンパイラが私たちの意図を正しく理解できたからです。しかし、もしあるプログラマーが、コードをよく学んで理解することなく、自分のコードではlong型(64ビット)は使いたくない、int型(32ビット)だけを使いたいと判断したとしたら、何が起きるでしょうか。そのようにして記述を変更した場合、コード04はコード05に変わります。それが以下に示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int v = -5; 07. 08. Sum(v, Sum(10, 25)); 09. Print(v); 10. } 11. //+------------------------------------------------------------------+ 12. int Sum(int arg1, int arg2) 13. { 14. Print(__FUNCTION__, "::", __LINE__); 15. return arg1 + arg2; 16. } 17. //+------------------------------------------------------------------+ 18. void Sum(int &arg1, int arg2) 19. { 20. Print(__FUNCTION__, "::", __LINE__); 21. 22. arg1 += (int)arg2; 23. } 24. //+------------------------------------------------------------------+
コード05
ここで注意してください。今回おこなった変更は、特に問題を起こす意図があったわけではなく、まったく無害なものでした。しかし、実行ファイルを作成しようとすると、コンパイラは何が正確に実装されようとしているのかを理解できないことがわかります。コンパイラの出力に表示されるメッセージは、以下の通りです。

図04
つまり、プログラマーの考えでは「より適切にするための、まったく無害な変更」であったにもかかわらず、最終的にはコードが完全に理解不能になってしまったのです。なぜなら、コンパイラは8行目を実行する際に、12行目に向かうべきか18行目に向かうべきかを判断できないからです。
しかし、ここで理解してほしいことがあります。それはエラーは8行目にあるのではないということです。実際の間違いは、コンパイラの理解では、まったく同じ呼び出しが2つ存在しているという点にあります。経験の浅いプログラマーは、すぐに「問題は8行目にある」と考えてしまいがちですが、実際には12行目か18行目にあるのです(前述の通り、コンパイラは最終的な実行ファイルを生成しようとするときに一意な内部名を作成することがあります)。
ここで一見すると単純に解決できそうな問題も、実際には非常に難しくなることがあります。なぜなら、呼び出しのひとつがあるヘッダーファイルにあり、もうひとつがまったく別のヘッダーファイルにある場合もあるからです。しかも、両者は全く関係のないものだったりします。こうなると状況はさらに複雑で混乱しやすくなります。
最後の例として、オーバーロードの別の使用例を考えてみましょう。以下のコードに示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long v = -16, 07. m[]; 08. bool b; 09. 10. Add(m, Sum(10, 25)); 11. Print("Return: ", b = Sum(v, m)); 12. if (b) Print("Value: ", v); 13. ArrayFree(m); 14. } 15. //+------------------------------------------------------------------+ 16. void Add(long &arg[], long value) 17. { 18. ArrayResize(arg, arg.Size() + 1); 19. arg[arg.Size() - 1] = value; 20. } 21. //+------------------------------------------------------------------+ 22. long Sum(long arg1, long arg2) 23. { 24. Print(__FUNCTION__, "::", __LINE__); 25. return arg1 + arg2; 26. } 27. //+------------------------------------------------------------------+ 28. bool Sum(long &arg1, const long &arg2[]) 29. { 30. Print(__FUNCTION__, "::", __LINE__); 31. 32. if (arg2.Size() == 0) 33. return false; 34. 35. for (uchar c = 0; c < arg2.Size(); c++) 36. arg1 += arg2[c]; 37. 38. return true; 39. } 40. //+------------------------------------------------------------------+
コード06
このケースは非常に興味深く、実際的な影響も多くあります。なぜなら、少なくともMQL5環境では、価格や取引をグラフィカルに解釈するための仕組みを作成することが目的である場合が多く、複数のティック(クオート)を使ってある種の計算や処理をおこなうコードを実装することがあるからです。通常、このような計算や処理は、特定のインジケーターやEA用の取引モデルの開発に関連しており、視覚的なシグナルを形成してトレーダーやMetaTrader 5プラットフォームのユーザーに、ポジションのオープンやクローズ、あるいは将来的に起こり得る特定の動きに注意を向けさせることを目的としています。
多くの人、特に初心者は、何かを作ってすぐに動作を確認したいと思うことでしょう。しかし、その前に、現在この記事で考察しているような事項を十分に理解することが必要です。ここで扱う内容はより基本的なものであり、後により複雑で目的志向のタスクに取り組めるよう、しっかりした基盤を作ることを目的としています。将来、単純な細かい説明に時間をかけたくないため、今この知識ベースを作成しているのです。こうすることで、親愛なる読者の皆さんは、記事で示された内容を、自分でより専門的に応用・改善できるようになります。それは私の記事だけでなく、他のプログラマーが書いたコードやアイデアにも応用可能です。
さて、コード06では、オーバーロードの例を示しています。一方のケースでは離散値を非常に興味深い方法で使い、もう一方のケースではデータ配列に含まれる値の集合を使っています。外見上は単純ですが、計算の実行時には小さな理解の誤りによって問題が生じることがあります。その典型的な例として、関数に渡すパラメータの初期値に注意を払わないことがあります。こうした誤りは、失敗の本当の原因を理解するまでは追跡・修正が難しい場合があります。
しかし、このようなことは実践の中で理解しやすくなり、経験を積むにつれてこうした誤りは減っていきます。それでも発生する場合は、単に実装時の注意不足が原因です。
それでは、コード06が示している内容を見てみましょう。上記のコードを実行すると、以下のような結果が得られます。
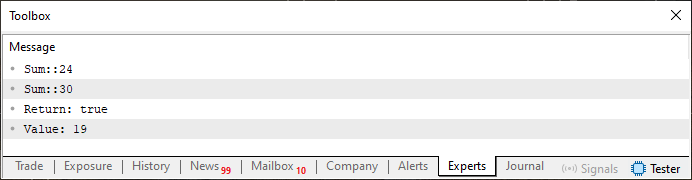
図05
さて、ここを理解してください。前にも述べたように、私たちは複数の値に対する処理(factorization)をおこなう際に、実行時に問題を抱えることがよくあります。これは、処理する要素の数を間違えてしまうことが原因です。これを避けるために、関数から単純に値を返すのではなく、フラグや機能(feature)を返す方法を採用します。これにより、処理された値を受け入れるかどうかを示すことができます。したがって、32行目ではまさにこのチェックをおこなっています。なお、Sum関数は依然としてオーバーロードされています。なぜなら、22行目の関数名は28行目のものと同じだからです。しかし、返り値の目的が異なることは、関数がオーバーロードであるという事実を否定するものではありません。
このようなケースは、特に関数が使われている行だけを見ていると混乱しやすいものです。10行目と11行目を見てください。返される値が完全に論理的でないことに気づくでしょう。したがって、コードの動作に疑問がある場合は、詳細までよく調べることが重要です。単に関数や手続きの名前が既存のものと同じだからといって、必ずしも同じ動作をするわけではありません。そうとは限らないのです。
最後に、コード06に小さな変更を加えることができます。それは以下のコードスニペットに示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long v = -16, 07. m[]; 08. bool b; 09. 10. // Add(m, Sum(10, 25)); 11. Print("Return: ", b = Sum(v, m)); 12. if (b) Print("Value: ", v); 13. ArrayFree(m); 14. } 15. //+------------------------------------------------------------------+ . . .
スニペット01
このスニペットでは、コードの1行を削除し、コメントにしています。今回は10行目です。しかし、一見すると「因数分解のために正しい数の要素を追加していないという意味に過ぎないこの単純な変更が、結果として以下に示すような動作を引き起こします。
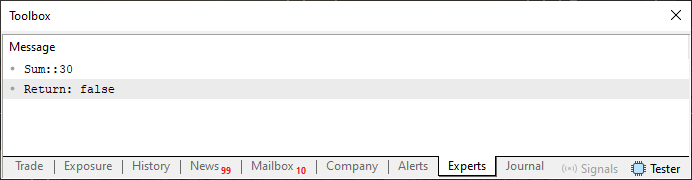
図06
将来的に大いに役立つので、コード06に他の変更を加えて実験してみて、別の観点から理解を深めることをおすすめします。
最終的な考察
おそらく、この記事は初心者プログラマーにとって最も混乱を招くものになったかもしれません。なぜなら、同じコード内ではすべての関数や手続きが必ずしも一意の名前を持つわけではないことを示したからです。同じ名前の関数や手続きを使うことができるのです。これをオーバーロードと呼びます。この方法は許容されるものではありますが、使用する際には注意が必要です。なぜなら、オーバーロードを安易に使うと、コードの実装が難しくなるだけでなく、後から修正するのも困難になることが多いからです。
この記事が、既知の関数や手続きが必ずしも同じ動作をするわけではないということを理解するための説明となり、オーバーロードされた関数や手続きの挙動を自動的に推測しないように注意する助けになればと思います。
付録として、この記事で扱ったコードのスニペットを残しておきます。アプリケーション上でコードに変更を加えながら学習し、オーバーロードがコードの理解や、誤用によって発生する可能性のあるエラーにどのような影響を与えるかを確認してみてください。複雑なシステムでエラーに対応するよりも、メカニズムがまだ単純な段階でエラーに対処する方法を学ぶほうが効果的です。ですから、今のうちにオーバーロードの問題を学んでおくことをおすすめします。進むにつれて、すべてはより複雑になっていくのですから。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15642
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索