
Del básico al intermedio: Array (IV)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final, cuyo objetivo no sea el estudio de los conceptos mostrados aquí.
En el artículo anterior Del básico al intermedio: Array (III), se explicó cómo utilizar arrays para pasar datos entre funciones y procedimientos. También se abordaron algunos detalles relacionados con la cuestión de la inicialización y los cuidados básicos que se deben tener en cuenta, para no crear algo insostenible a largo plazo. Como creo que muchos de ustedes piensan que todo esto puede tener poco valor, o que nunca se aplicará realmente en la práctica. En este artículo vamos a empezar a jugar de verdad. Entonces es cuando la diversión empezará de verdad. Esto se debe a que, hasta este momento, solo hemos aplicado ciertos conceptos y reglas simples a los códigos que se han visto hasta ahora. Pero ha llegado el momento de empezar a adentrarnos en lo que realmente es MetaTrader 5.
Antes de hacer esto, en la práctica, necesitamos ver y entender ciertas cosas, que, posiblemente, muchos desconocen. Y otros seguramente no tienen ni la menor idea de cómo funciona. Entonces, como la cosa ahora empieza a ponerse mucho más divertida, y, al mismo tiempo, más elaborada. Te pido que tengas aún más paciencia con los temas que se tratarán, en este y en los próximos artículos. Esto es así porque entender lo que se verá aquí te ayudará a comprender mejor otras cosas, que suceden cuando se crean aplicaciones reales para MetaTrader 5.
Lo primero que vamos a hacer es entender cómo se puede aprovechar mejor la memoria mediante arrays. Sí, el tema de los arrays aún no ha terminado. Y si pensabas que lo verías completamente en poco tiempo, olvídalo. De hecho, es un tema muy largo y extenso. Precisamente por esta razón, lo veremos de forma más espaciada de ahora en adelante. Lo abordaremos en pequeños fragmentos junto con otros temas que se tratarán en los artículos. Así no resultará cansado y aburrido.
De acuerdo, antes de empezar, quiero recordar que hay un requisito previo para poder seguir lo que se explicará en este artículo. Básicamente, el requisito es haber comprendido el funcionamiento de los códigos del último tema, tratado en el artículo anterior. Es decir, cómo trabajar con arrays fuera del lugar donde han sido declarados.
Operador sizeof
Para empezar, haremos una pequeña prueba. El objetivo es mostrar cómo pueden manipularse los datos en la memoria. Es decir, no utilizaremos variables convencionales. El objetivo es hacer todo mediante arrays. De esta forma, simularemos la creación, el movimiento, la lectura y la escritura de variables en la memoria RAM del ordenador. Sé que esto puede parecer fuera de lugar. Pero hacerlo no solo es un excelente ejercicio de lógica y programación, sino que también ayuda a pensar como un verdadero programador. Esto es así porque será necesario ejecutar diversas acciones que muchos programadores ni siquiera saben cómo llevar a cabo.
Empezaremos nuestro ejercicio con una pequeña introducción a algo mucho más grande. Aunque intentaré explicar las cosas de la manera más sencilla posible para que todos puedan seguir el razonamiento utilizado. Para ello, lo primero que debemos hacer es entender qué hace realmente el operador sizeof. Y averiguaremos por qué existe.
El operador sizeof nos indica cuántos bytes está usando un determinado tipo o variable en la memoria. Parece algo místico. Pero es bastante sencillo de entender. En primer lugar, es importante saber que el número de elementos de un array no significa memoria asignada. Un array puede tener X elementos y, sin embargo, ocupar Y bytes. El número de elementos solo será igual al número de bytes usados o asignados en memoria, si el tipo de dato utilizado es igual a 8 bits, es decir, si es de 1 byte. En el caso de MQL5, los tipos que cumplen este requisito son char y uchar. Todos los demás tendrán un número de bytes mayor que el número de elementos presentes en el array. Entonces, no confundas el operador sizeof con una operación ArraySize o una llamada Size. Su propósito es saber el número de elementos en un array.
Para dejar esto debidamente aclarado y fácil de entender. Vamos a ver el siguiente ejemplo mostrado abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
Código 01
Este código 01, cuando se ejecuta, produce el siguiente resultado que se ve justo debajo.
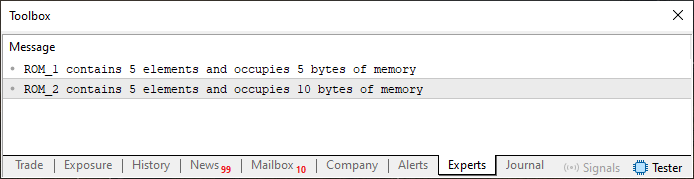
Imagen 01
Ahora veremos qué nos dice esta imagen. Aunque es algo que ya podemos percibir con solo mirar. Observa que en el código 01 se crean dos arrays estáticos. La única diferencia entre ellos es que uno es del tipo char y el otro, del tipo short. Más allá de eso, son exactamente iguales. Contienen los mismos cinco elementos. Sin embargo, la cantidad de bytes utilizados es diferente en cada uno. ¿Por qué?
Bien, mi querido lector, en el artículo Del básico al intermedio: Variables (II), hay una tabla que indica cuántos bytes ocupa cada tipo de dato básico en la memoria. Si la miras, verás que el tipo short ocupa dos bytes. Como tenemos cinco elementos, al multiplicar el número de elementos del array por la cantidad de bytes que ocupa cada elemento, llegamos al número de diez bytes. De hecho, el uso del operador sizeof es muy simple y directo para saber la cantidad de espacio que se ocupa en memoria.
Y ¿por qué es importante para nosotros? Esta información sobre cuánta memoria va a utilizar una determinada información es extremadamente útil. Nos permite asignar más memoria o liberar una cierta cantidad de forma muy fácil y directa. Aunque todavía no lo hayamos utilizado aquí. Con el tiempo, vamos a hacer muchas implementaciones de este tipo. Pero, para el tema que nos ocupa. Lo que se ha visto aquí ya es más que suficiente. Así que podemos pasar a la siguiente etapa.
Enumeradores
Este tema se centrará en explicar un concepto muy sencillo. Pero que puede resultar extremadamente útil en una gran cantidad de situaciones. Para explicar qué es un enumerador de forma muy sencilla y fácil de comprender, vamos a utilizar un código visto en un artículo anterior. Se puede observar justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Código 02
Este código, que es un archivo de encabezado, se mostró en otro artículo. Pero volverá a estar presente aquí. Nos será de gran utilidad en este momento. Puedes ver que para usar uno de los formatos necesitamos utilizar un valor decimal cualquiera. Sin embargo, cuando lo usamos en el código, es bastante difícil entender de qué se trata y cuál es el objetivo previsto. Esto se debe a que un código que utilizara este enfoque mostrado en el código 02 tendría que escribirse como se muestra justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
Código 03
En este caso, el archivo de encabezado indicado en la línea 4 de este código 03 es exactamente el mismo que se ve en el código 02. Sin embargo, la cuestión son precisamente los valores que se observan entre las líneas 15 y 18. A partir de esos valores, ¿podrías decir qué tipo de tratamiento se haría para crear la string de salida? Definitivamente no. Tendrías que recurrir al archivo de encabezado. Debes buscar la función ValueToString. Hay que analizar cómo trabaja cada uno de los valores y decidir cuál es el más adecuado. Después, tendrías que decidir cuál sería el valor adecuado. Es decir, mucho trabajo para poca recompensa. Precisamente por esto, es necesario un tipo de estructura mucho más práctica y eficaz. Este es el ENUMERADOR. En un enumerador, se crea un tipo especial de dato que sigue una cuenta progresiva con cada nuevo dato que se crea. Esto es bastante práctico y fácil de utilizar.
Así, actualizando el código 02, por uno que utilice enumeradores, podemos ver el código que surge a continuación, justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
Código 04
Fíjate que realmente es muy sencillo hacer que funcione. Claro, aquí estamos viendo cómo se crea un enumerador básico. Pero creo que no te costará nada entender lo que se está haciendo en la línea cuatro. Una vez definido este enumerador, podemos hacer las sustituciones que puedes observar en el resto del código. Con esto, el antiguo código 03 pasará a ser como el mostrado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
Código 05
Ahora dime la verdad. Solo con echar un vistazo a este código 05 ya es posible entender perfectamente lo que hace, ¿no crees? Pues bien, a pesar de este pequeño cambio, el código 03 seguirá funcionando como antes. Esto continuará así hasta que volvamos a modificar el enumerador. Pero, por ahora, vamos a dejar las cosas así. No tiene sentido hablar de ciertos detalles más avanzados con relación a los enumeradores. Volveremos a este tema en un futuro próximo. Pero con otros objetivos en mente.
Un número infinito de argumentos
Ahora vamos a un tema un poco más elaborado para hacer este artículo más interesante. En un artículo anterior, mostré cómo podríamos crear una representación de valores binarios. El objetivo era poder visualizarlo en el terminal de MetaTrader 5. Mencioné el hecho de que sería complicado crear un procedimiento en MQL5 para realizar un comportamiento que es muy fácil de lograr en C y C++. En realidad, hasta donde sé, los únicos lenguajes que permiten tal modelado de forma nativa son C y C++. Además de Java, que también tiene algo muy parecido en desarrollo.
Podríamos crear una función o procedimiento en el que no habría una cantidad fija de argumentos o parámetros. Pero sí habría un número mínimo de variables declaradas. Esto ocurre cuando se llama a una función o procedimiento determinado. Este valor mínimo sería de al menos un argumento.
Una vez hecho esto, podríamos pasar tantos argumentos como fueran necesarios para la función o el procedimiento. Dentro de la función o procedimiento, habría tres llamadas especiales que nos permitirían leer, uno a uno, cada argumento extra. Para quien tenga interés o simplemente curiosidad, puede ver va_start, va_arg y va_end, pues estas son las tres funciones que utilizan C y C++. En el caso de Java, el nombre de estas funciones es ligeramente diferente. Pero el principio de funcionamiento es el mismo. Al conocer el concepto aplicado en tales funciones, podemos crear algo muy parecido aquí, en MQL5.
En realidad, muchos podrían considerar lo que se mostrará como algo avanzado. Pero, en mi opinión, esto es material básico. Todo principiante debería saber cómo hacerlo. Básicamente, haremos una prueba para manipular un array en MQL5. Para que el truco funcione, será necesario hacer una pequeña artimaña, ya que con el nivel de información mostrado hasta ahora no es suficiente. Utilizaremos el operador sizeof junto con algunas pequeñas manipulaciones simples en un array.
Ahora pensemos lo siguiente: cuando declaramos un array dinámico, podemos añadir nuevos elementos a él a medida que los necesitemos. Y como el tipo más simple es el tipo uchar, o char dependiendo del caso, podemos usarlo como base para otros tipos. Sin embargo, simplemente apilar valores en un array no nos permitirá transmitir datos a través de él. Necesitamos algo un poco más elaborado.
Por tanto, volvemos nuestra atención al tipo string. Esto es así porque el tipo string nos permite transferir valores. Sabemos cómo termina cada string. Es decir, con un símbolo nulo o cero.
Sin embargo, aquí es donde entra nuestra artimaña y la parte divertida: ¿y si creáramos una string del tipo usado en BASIC? Para quien no lo sepa, hablé sobre esto en un artículo anterior. Tal vez esto nos resultaría mucho más útil. Y, de hecho, aquí está el truco clave. Ya que no sería adecuado utilizar un símbolo nulo en valores binarios.
Sin embargo, se puede usar un elemento neutro dentro de un array, hasta el punto de crear un array con cualquier cantidad de elementos. Esto sí que parece genial. Incluso puede parecer un poco cruel decir que esto debería ser conocido por cualquier programador principiante. Pero sí. Basándonos en lo que hemos visto hasta ahora. Podemos y vamos a construir algo que consiga hacer esto. Usaremos un tipo de implementación que pocos lenguajes logran hacer. No obstante, es mucho más que eso. Vamos a crear aquí algo básico. Y muchos programadores que se dicen más experimentados no lo hacían o no sabían que era posible hacerlo en MQL5.
Para hacer las cosas lo más didácticas y simples de entender. Vamos a comenzar haciendo lo siguiente: definiendo algunas variables y constantes para ser usadas en nuestro modelo de ejemplo. Así, surge el código que se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
Código 06
Está bien, cuando ejecutes este código 06, verás en el terminal algo parecido a lo que se muestra en la imagen justo debajo.
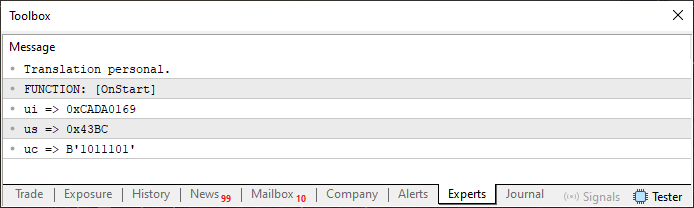
Imagen 02
Bien, esto no es nada extraordinario. De hecho, ya era de esperar. Pero ahora viene la parte interesante. Fíjate que en este código 06, en la línea 12, ya añadí un array del que vamos a necesitar. Personalmente prefiero el tipo sin signo, por eso utilizo el tipo uchar. Pero otros pueden preferir usar un tipo con signo. Por eso, preferirán usar el tipo char. De cualquier forma, esto no afectará a nuestro propósito.
Pero quiero recordar que la implementación que será vista aquí tiene como objetivo únicamente la didáctica. No es en absoluto la mejor manera de implementar el mecanismo que será mostrado. Existen formas mucho más adecuadas de hacer esto. Sin embargo, exigen el uso de algunos métodos y conceptos que aún no han sido explicados. Pero como estos mismos conceptos, que aún no han sido explicados, surgieron precisamente para facilitar lo que será visto aquí. Me parece perfectamente válido y práctico mostrar primero el concepto, y después los métodos creados para hacer más simple la propia implementación. Ya que una cosa llevará a la otra de una manera muy natural. De esta forma, el código que vamos a crear contiene muchas partes inline. Pero esto es solo porque sería difícil explicar cómo funciona el método, si la implementación se hiciera de otra manera.
A continuación, transferimos los valores declarados en las líneas ocho, nueve y diez al array. Recordemos que necesitamos hacer esto para poder reconstruir estos mismos valores después. De lo contrario, la implementación sería completamente inútil.
Una vez entendido este criterio, pasaremos a la primera parte de la implementación. La iré publicando poco a poco para que todos, incluso los que están empezando, puedan entender lo que se está creando. Esta primera parte puede observarse justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
Código 07
Cuando se ejecuta, vamos a ver en el terminal lo que se muestra en la imagen justo abajo.
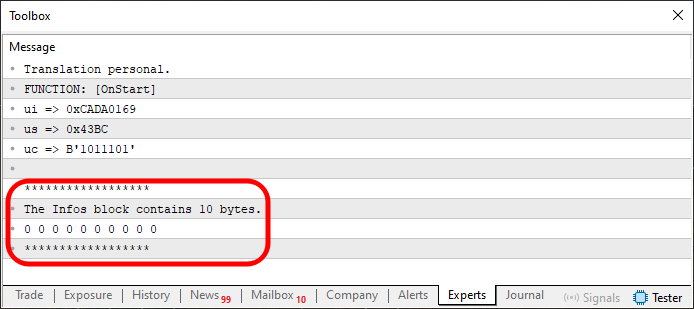
Imagen 03
Ahora presta mucha atención, querido lector. Así no te perderás en medio de la explicación. El fragmento que está siendo destacado en la imagen 03 no es más que la ejecución de las líneas 31 a 34. Sin embargo, puedes ver que mostramos tanto el contenido de la memoria como la cantidad de memoria asignada. Es interesante observar que la memoria se asigna entre las líneas 25 y 27. Pero esto aquí es solo el inicio del código. Como vamos a hacer las cosas un poco más agradables, debido a que estamos haciendo la implementación en pequeños pasos. De cierta forma, el código de la línea 29 es innecesario. Se define precisamente la forma en que se van a trabajar los valores.
Bueno, creo que ya tienes claro lo demás. Así que podemos pasar al segundo paso. Este se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
Código 08
Ahora, cuando usamos este código 08, el resultado ya empieza a ser un tanto más interesante. Esto puede verse en la imagen justo abajo.
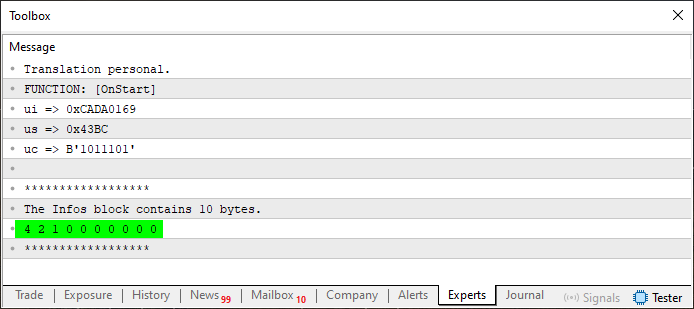
Imagen 04
Observa que ahora hay algunos valores en el array que se está creando. Estos valores se han colocado ahí precisamente por cuenta de las líneas 32, 38 y 44, lo que indica cuántos bytes tendremos. Pero hay un pequeño problema: Este problema se resolverá en el próximo paso. Pero antes, veamos qué ha cambiado entre el código 07 y este código 08. Esto se debe a que podemos observar que estamos creando pequeños bloques que podrían colocarse en alguna función o incluso en algún procedimiento externo. Esto se observa claramente entre las líneas 28 y 32.
Luego tenemos algo muy parecido entre las líneas 34 y 38, y una repetición muy similar entre las líneas 40 y 44. Pero, como se dijo anteriormente, no voy a implementar esto en un procedimiento o función externa. Al hacerlo, estaría infringiendo una regla que me impuse para demostrar este mecanismo. Que era no hacer nada que no haya sido mostrado previamente.
Si ya sabes cómo unir todos estos bloques en uno solo, genial. La única diferencia entre ellos es precisamente la variable que cada uno está utilizando para asignar memoria suficiente para soportar el valor. Y ese es el próximo paso. El siguiente paso es colocar el valor dentro del array. Puedes verlo justo a continuación. Esta vez, notarás que el código ha cambiado ligeramente.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
Código 09
Estamos a punto de terminar. Solo nos falta un paso más para comprender e implementar todo perfectamente. Sin embargo, si ejecutas este código 09, observarás que la salida es ligeramente diferente, como se puede ver en la imagen de abajo.
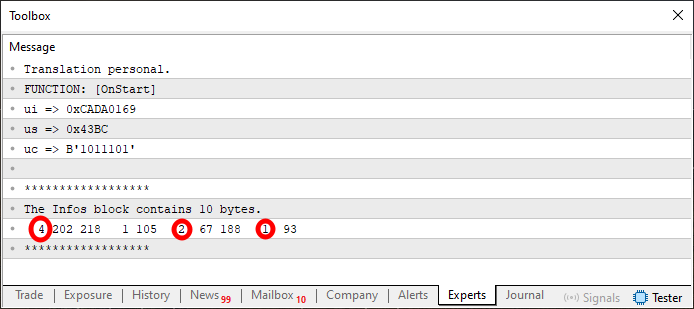
Imagen 05
En este caso, se han marcado los valores que estaban originalmente posicionados en la imagen 4. Puede parecer un tanto extraño la forma en que se muestran estos valores en la figura 5, pero si observas con atención lo que ocurre en el código 9, percibirás que estos son los valores que, de hecho, están contenidos en las líneas ocho, nueve y diez. Tal vez no te lo creas. Así que vamos al último paso. Este paso se implementa en el código que se ve justo a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
Código 10
Y ahí lo tienes, querido lector: un código creado por un principiante en programación. Está totalmente escrito en MQL5 y tiene la capacidad de transferir una cantidad infinita de información dentro de un único bloque de array. El resultado de la ejecución de este código puede observarse en la imagen de abajo.
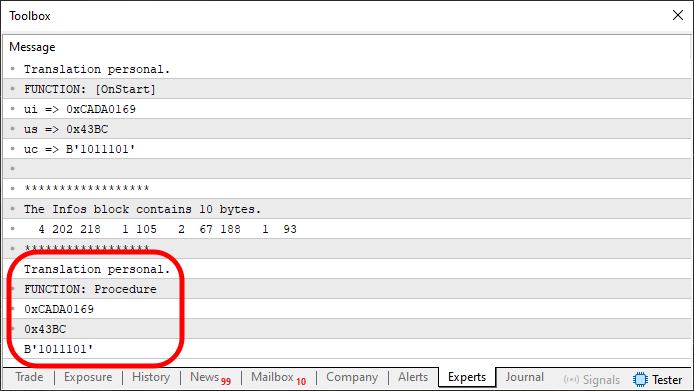
Imagen 06
Aparentemente, esto sería imposible de hacer en MQL5. Es decir, implementar un mecanismo existente en lenguajes como C y C++, que permita enviar una cantidad ilimitada de valores de una función a otra. Y, dependiendo de la manera en que lo agregues, hasta de una aplicación a otra dentro de MetaTrader 5. Sin embargo, hacer esto ya es un tema un poco más avanzado. Requiere que realmente llegues a comprender diversos otros conceptos y elementos presentes en MQL5. También es necesario comprender adecuadamente cómo funciona MetaTrader 5.
Y cuando digo «funciona», no me refiero a poner cosas en el gráfico. Eso no tiene ninguna gracia, es aburrido. No genera ningún tipo de emoción ni entusiasmo. Cuando digo «funciona», me refiero a que necesitas saber por qué MetaTrader 5 hace lo que HACE. Pero, sobre todo, cómo usar los mecanismos que pone a disposición para poder ejecutar cosas, como estas que estoy mostrando en este momento. Son cosas que, en mi opinión, son básicas y muy simples. Pero que pocos logran comprender e implementar.
Pero fíjate qué bonito y maravilloso es todo, cuando se ponen en práctica conceptos básicos. Aquí, en este código 10, podemos ver el siguiente trabajo realizado. Entre las líneas 28 y 48, creamos el array. Y luego, cuando ejecutamos la línea 55, enviamos este mismo array dentro de un procedimiento. Pero podría ser cualquier otra cosa. Allí, usando un mecanismo muy simple, desmontamos lo que se montó entre las líneas mencionadas anteriormente.
Seguramente muchos se pregunten: «Amigo, ¿para qué crear algo de este tipo?» Complicar el código de manera completamente innecesaria. Bien, lamento tener que repetir lo que se dijo al principio de este tema, que era precisamente el hecho de que lo que se iba a implementar aquí no era la mejor forma de hacerlo. Sin embargo, si asimilas este conocimiento y logras comprender lo que se ha mostrado aquí, podremos pasar a algo que, de otro modo, sería mucho más complicado de explicar.
No obstante, debido a que todo lo que se explicará en los próximos artículos está relacionado con este código 10, me parece bastante interesante y plausible su creación. No tiene ninguna complicación. Todo lo contrario. El procedimiento paso a paso, que estará en el anexo y que se ha mostrado aquí, servirá de gran ayuda para quienes realmente desean explorar MQL5 y MetaTrader 5 de una manera mucho más avanzada.
Así que, querido lector, no pierdas tiempo esperando respuestas a las preguntas que van surgiendo en tu mente. Procura estudiar cada detalle que veas en este y en los demás artículos. Y, sobre todo, practica lo que se va mostrando. El conocimiento se acumula muy rápido y no hay vuelta atrás. También surgen dudas debido a la falta de práctica.
Y, para cerrar este artículo por todo lo alto, voy a mostrar cómo se podría escribir el mismo código 10. Esto para mostrar que podemos hacer las cosas de una manera más compacta. Y, por si te sientes más cómodo analizando un código más compacto que hace básicamente lo mismo, puedes observarlo justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Código 11
Al ejecutar este código, obtendremos el resultado que se muestra en la imagen siguiente.
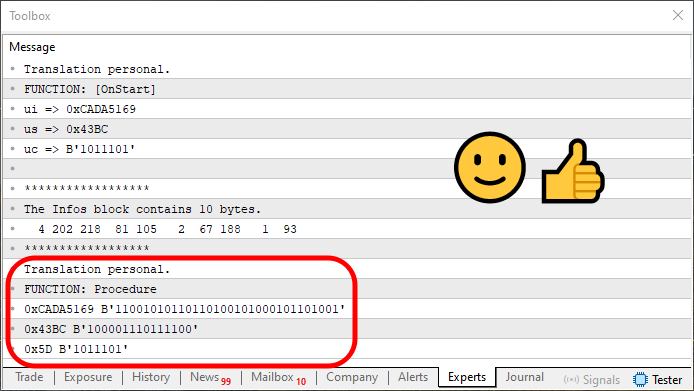
Imagen 07
Como se puede observar en la imagen 07, la información es ligeramente diferente a la de la imagen 06, debido precisamente a que, en el momento de recrear los datos originales, lo hacemos dentro de un único bucle. Este bucle se ve en la línea 70. Este bucle es relativamente simple. Sin embargo, es necesario que lo estudies con calma, querido lector. Así podrás entender cómo se recrea la información almacenada anteriormente.
Pero básicamente, él estará observando la posición en la que indicamos cuál es el número de bytes o elementos que forman parte de un bloque de información original. Precisamente por esta razón, el bucle externo, es decir, el de la línea 67, necesitó un pequeño cambio en su estructura. De lo contrario, no lograríamos recuperar realmente la información grabada en el array.
Consideraciones finales
Este artículo pretende servir de puente entre lo que hemos visto hasta ahora y lo que veremos en el próximo. Sé que muchos pueden pensar que lo que se ha visto e implementado aquí es innecesario y una locura. Sin embargo, si has comprendido el objetivo y propósito de lo presentado en este artículo, notarás que surge la necesidad de usar o desarrollar algo más en el lenguaje.
De hecho, esto se encuentra implementado en el lenguaje MQL5. Ese será el tema del próximo artículo. Pero si aún no has comprendido la idea, piensa en lo siguiente: ¿Qué sería necesario para que no fuera necesario implementar el código que se encuentra entre las líneas 28 y 48? Sin perder recursos. De este modo, se podrían simplificar esas mismas líneas en un código mucho más simple y práctico. Piensa en eso y la respuesta llegará en el próximo artículo. Hasta entonces, estudia y practica con los códigos vistos en este artículo. Estarán disponibles en el anexo.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15501
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso