
初級から中級まで:共用体(I)

はじめに
ここに掲載されている資料は、教育目的のみのものです。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを利用することは避けてください。
前回の「初級から中級まで:配列(IV)」では、とても素晴らしく非常に興味深い概念を取り上げました。多くの人がそれを上級者向けのトピックだと考えているかもしれませんが、私のささやかな意見では、それは初心者こそ知っておくべき概念です。なぜなら、正しく使えば、前回の記事で紹介した概念は、まさに無限の可能性を開いてくれるからです。それによって、通常では非常に困難、あるいは不可能に思えることも実現できます。
さらに、その同じ概念は、今後より適切なタイミングで取り上げる予定の別の文脈でも使われています。ここで過度な不安を与えないように、ちょっとしたヒントだけお伝えします。前回の記事をしっかりと勉強して、何度も実践してください。その知識を深く理解することがとても重要です。それを理解していなければ、以降の内容を正しく理解することが難しくなるでしょう。すべてがまるで魔法のように見えるかもしれません。
何も理解できなくなると言うのは少し大げさかもしれませんが、それでも、前回の記事がこれまでで最も重要なものであるという事実に変わりはありません。少なくとも、本気で良いプログラマーになりたい方、プログラミング言語を使って何でもできるようになりたい方にとっては、そう言えるでしょう。前回紹介した概念は、MQL5に限ったものではなく、どんなプログラミング言語にも共通する内容です。特に、計算資源を正しく活用するという点において非常に重要です。
さて、今回の記事に入る前に、いくつかの前提知識について触れておく必要があります。一部の講師の方々からは少し大げさだと思われるかもしれませんが、私としては、前回の記事の内容を少しでも理解していない限り、今回の内容についていくのは非常に難しいと思います。理解できないとは言いませんが、説明についていくのは間違いなく難しくなるでしょう。
つまり、前回の記事はひとつの分岐点です。それまでは基礎的な内容でしたが、これからはやや発展的な内容に進んでいきます。そして、今回のタイトルにもあるように、ここからはunionについて学んでいきます。ただし、一般的な意味でのunionではありません。ここで扱うのは、特定のプログラミング言語で使用される構文上のunionというキーワードです。そしていつものように、これからの実装とコーディングがもっと楽しく、面白くなるような新しいトピックの扉を開いていきます。
unionの誕生
前回の記事では、次のコードを実装しました。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
コード01
コード01を実行すると、以下のような結果が得られます。
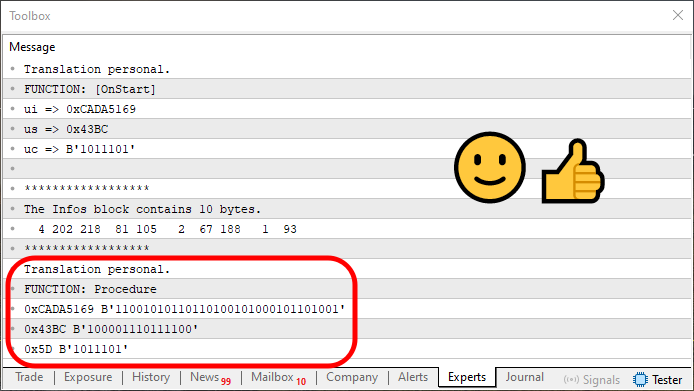
図01
図01を見ると、8行目、9行目、10行目で定義された値が、60行目にある手続き(プロシージャ)に渡されているのが分かります。しかし、その手続きが要求しているデータ型を確認してみると、個々の値が渡されているのではなく、配列として渡されていることに気づきます。最初は、これが何のことだか意味が分からないかもしれません。多くの人は、60行目の手続きを見たとき、配列を扱う操作がおこなわれるものと想像するでしょう。しかし、実際にはそうではありません。ここで実際におこなわれているのは、配列に含まれる値を書き換えて再構築しているのです。つまり、値の転写または変換とも言える処理です。
ここで注目すべきなのは、手続き呼び出し時に使用された変数の名前や型が一切わからないという点です。なぜなら、そのような情報への参照が一切存在しないからです。分かるのは、要素の数と、それぞれの変数に対応する各要素の値だけです。
多くのプログラマー(中には経験豊富な人も含まれます)は、このようなアプローチを完全に受け入れがたいものと考えることがあります。なぜなら、値とソースコード中の名前付き変数との間に直接的な対応関係が存在しないからです。しかし、彼らがしばしば見落としているのは、CPUにとって変数名など全く関係ないという事実です。CPUが見ているのは、ただの数値の並びだけです。それだけです。CPUは変数名や定数名など一切認識していません。そのような情報は全く関係ありません。
したがって、コード01に示されたメモリモデルは、以下のような形で表現されると考えることができます。
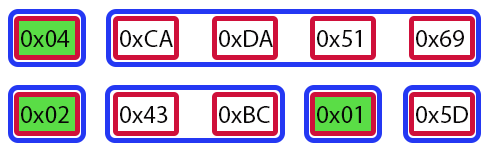
図02
私たちが議論しているこの概念は、特に後で非常によく似た別の概念を見ていくときに、かなり混乱を招く可能性があります。
図02には、図01で強調表示されていた値に加えて、いくつかのマーカーが表示されています。これらのマーカーは緑色で表されており、次のような意味を持っています。
ここから新しい値が始まり、この数の要素で構成されている
また、青い長方形はそれぞれの要素ブロックを表しています。つまり、配列を使わずに個別の変数を使っていた場合、図02に青い長方形が6個あるので、6つの変数が必要だったことになります。一方で、赤い長方形も存在します。これらは配列の各要素を表しています。赤い長方形が10個あるということは、配列には10個の要素があるということです。もし1つの要素が2つの値で構成されていたとしたら、赤い長方形は5つになっていたでしょう。
ただし、断片化の懸念から(このトピックはやや高度で、ここでは詳しく説明しません)、各要素の最小サイズを定義して使うようにしています。これは、後でデコード処理が少し遅くなることを意味しますが、断片化を避けるのに役立ちます。このデコード処理は、多くの人が67行目のループだと思いがちですが、実際には70行目のループでおこなわれています。
さて、ここまでの内容は、そこまで難しくなかったと思います。ですが、図02をじっくり見て、以下のことについて考えてみてください。青い長方形を読み取るのに、赤い長方形を通らずに済ませる方法はあるでしょうか。言い換えれば、青い長方形だけを見て、赤い長方形の値を取得することは可能でしょうか。もしそれが可能であれば、私たちの作業は格段にシンプルになります。なぜなら、28行目〜48行目にかけておこなっているエンコード処理が高速化されるだけでなく、デコード処理も簡略化されるからです。つまり、直接青い長方形から処理できるようになるわけです。これは、コード01で現在おこなっているような、青い長方形を分解して赤い要素を取り出し、それを配列に格納するというやり方とは異なります。
実際、この発想こそが、私たちがunionとして知っている概念の発端なのです。unionを使うことで、ひとつの共有メモリ構造を定義できます。この構造の中では、青い長方形を、さまざまなサイズのユニットに分割することができます。各ユニットまたは要素のサイズは、開発中のコードまたはアプリケーションの目的と目標によって異なります。unionを一度定義すれば、その大きなブロックの各部分を、完全に個別に制御することが可能になります。この概念は、C言語やC++では非常に一般的に使われており、unionによって複雑な要素の並びや構造体を簡単に、安全に操作することができるようになります。
unionがどのように動作するかを理解するために、まずは簡単な例から見ていきましょう。 そしてその後に、コード01をどのように修正していくかを検討していきます。では、以下のコードを見ていきましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. union un_01 07. { 08. ulong u64_bits; 09. uint u32_bits[2]; 10. }info; 11. 12. uint tmp; 13. 14. info.u64_bits = 0xA1B2C3D4E5F6789A; 15. 16. PrintFormat("Before modification: 0x%I64X", info.u64_bits); 17. 18. tmp = info.u32_bits[0]; 19. info.u32_bits[0] = info.u32_bits[1]; 20. info.u32_bits[1] = tmp; 21. 22. PrintFormat("After modification : 0x%I64X", info.u64_bits); 23. } 24. //+------------------------------------------------------------------+
コード02
ひとつの概念が、いかに自然に次の概念へとつながっていくかに注目してください。配列について前回説明した内容を理解していなければ、今このコードで何が行われているのかを理解することはできません。そして、前回の記事の内容を理解していなければ、ここで紹介することはまったく意味を成さないでしょう。ですが、今こそまさに良いタイミングだと思います。ここで、unionとは何か、そしてその実用的な目的とは何かを説明していきましょう。
コード02を実行すると、MetaTrader 5端末に以下の画像が表示されます。
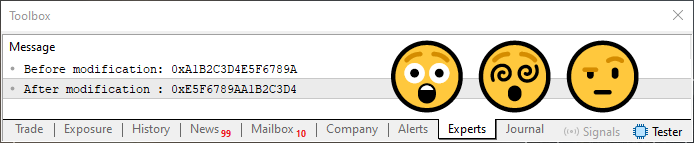
図03
これがunionの重要な点です。まるで魔法のように見えることに注目してください。これは私たちができることのほんの第一段階にすぎません。でも、まずはコード02で実際に何が起こっているのかを正確に理解しましょう。まず、unionは宣言されなければなりません。これは6行目で確認できます。つまり、予約語unionの後に、共用体の名前として機能する識別子を付ける必要があります。ここで、MQL5におけるunionの宣言方法と、CやC++での宣言方法との間に違いがあります。MQL5では匿名unionを作成することはできません。つまり、unionキーワードの後に識別子を必ず指定しなければならないということです。
一方、CやC++などの言語では、識別子を省略することで「匿名union」を作成することができます。匿名unionの欠点は、その宣言ブロックの外で参照できないという点です。この点については、別のコードスニペットで例を見ていきます。しかし今は、コード02に集中しましょう。ご覧の通り、unionが宣言されて名前が付けられたら、中括弧{}で囲まれたブロックが始まり、その中に含まれるすべての要素が同じメモリ領域を共有します。
さて、ここからが本題です。メモリ上のすべてのデータはバイト単位で考える必要があります。絶対にすべてです。したがって、unionを正しく定義するためには、メモリがどのようにバイト単位で分割されるかを考えなければなりません。図02をもう一度見てください。そこには10バイトが表されています。これらをどうグループ化するか(正確には「グループ化」という言葉は少し違うかもしれませんが)、それがunionを作る上での指針になります。6行目で定義されたunionは、8バイトのメモリを占有します。その中で最も大きなメンバーはu64_bitsです。
では、配列であるu32_bitsはどうでしょうか。各要素が4バイトなので、全部で8バイトになるはずですよね。ならばunion全体で16バイト必要なのではないでしょうか。いいえ、読者の皆さん、そうではありません。実際にはunion全体で8バイトしか使用しません。なぜなら、u64_bitsとu32_bitsは同じメモリ領域を共有しているからです。
最初は非常に混乱するかもしれません。でも、焦らずにゆっくり進めましょう。説明の中で1つでも段階を飛ばすと、事態はどんどん複雑になります。
コード02の目的は、メモリ内のある部分と別の部分の内容を入れ替えることです。最終的には、メモリ内に格納されている情報を回転させたいのです。そのためには、一時変数が必要になります。これは12行目で宣言されています。ここで重要な注意点があります。この一時変数は、union内の最小の変数サイズ以上のバイト数を持っていなければなりません。通常は、同じ型を使うことで正しいサイズを確保します。これは、期待した結果を得るために重要です。
続いて14行目で、unionを初期化します。ここはよく注意してください。実際に使用されるメモリ領域の変数は10行目で宣言されています。しかし、そのメモリ領域には複数の変数が含まれている可能性があるため、どのメンバー変数を使うのかをコンパイラに明示的に伝えなければなりません。unionに属するどのメンバーを使ってもかまいません。正しくおこなえば、コンパイラは理解し、メモリ領域に正しい値を代入します。
これをよりよく理解するために、もう一度図02に戻ってみましょう。図全体がunionであると想像してみてください。実際それほど遠くない考えです(この考えは後でより詳しく説明します)。そして、赤い四角のそれぞれに名前がついているとします。特定の四角にアクセスしたければ、その名前をコンパイラに伝えるだけで、そのメモリの該当部分を読み書きすることができます。
なかなか面白いですよね。でも、焦らず一歩ずつ進みましょう。まずはコード02を理解することです。u64_bitsメンバーに値を代入すると、そのunionの名前であるinfoが示すメモリ領域全体に、その値が格納されます(14行目の操作です)。
これを確認するために、16行目でメモリの内容を表示します。これが、最初の出力行として端末に表示されます。そして、ここからが一番面白い部分です。このメモリ内の値を入れ替えて、新しい値を同じメモリ領域に作り出そうとしているのです。unionによって実現されるメモリの共有を利用すれば、これは簡単かつ高速におこなうことができます。
最初のステップとして、一時変数にどちらかの値を保存します。これは18行目でおこなわれます。次に19行目で、配列のインデックス1の値をインデックス0に代入します。この時点では、メモリ内は一部だけ元の値が残っている状態、つまりごちゃごちゃな状態になります。最後に、20行目で元々インデックス0にあった値をインデックス1に移動させ、入れ替え処理が完了します。そして22行目で結果を出力します。これが図03に示されている2行目の出力です。
もしこれを見てすごいと思ったなら、次はさらに面白い例が待っています。メモリ全体の内容を、簡単かつ効率的に反転(ミラー)する方法です。それがコード03です。以下をご覧ください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. union un_01 07. { 08. ulong u64_bits; 09. uchar u8_bits[sizeof(ulong)]; 10. }; 11. 12. un_01 info; 13. 14. info.u64_bits = 0xA1B2C3D4E5F6789A; 15. 16. PrintFormat("The region is composed of %d bytes", sizeof(info)); 17. 18. PrintFormat("Before modification: 0x%I64X", info.u64_bits); 19. 20. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 21. { 22. tmp = info.u8_bits[i]; 23. info.u8_bits[i] = info.u8_bits[j]; 24. info.u8_bits[j] = tmp; 25. } 26. 27. PrintFormat("After modification : 0x%I64X", info.u64_bits); 28. } 29. //+------------------------------------------------------------------+
コード03
このコード03は、前のコードよりもさらに興味深いものです。そして、これを実行すると、MetaTrader 5端末に、下の図04に示されている内容が表示されます。
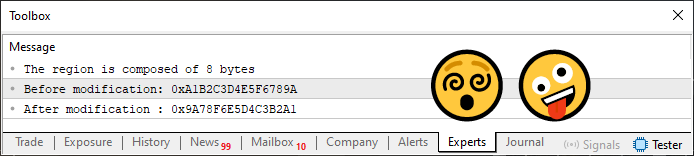
図04
非常に興味深く、印象的な内容です。私自身もこのような処理を試みており、何とか動作させようと苦労を重ねていました。しかし、今回示された方法は、非常に簡潔かつ実用的であり、本当に感銘を受けました。素晴らしいです。しかし、今いくつか質問があります。
よりよく理解できるように、段階的に進めていきましょう。最初の質問は、9行目では具体的に何が行われているのかということです。unionを使用する際、配列を含めるのは一般的です。これは、共用されているメモリ領域の特定の部分に直接アクセスする手段として有効だからです。もちろん、配列を使用しない方法も存在しますが、それについては後述します。通常、メモリ領域全体にアクセスできる構造を提供しておくことが望ましく、9行目に見られるような記述はその一例です。実際の運用コードでは異なる記法を用いる場合もありますが、目的は変わりません。すなわち、union内部のメモリブロックに属する各要素にアクセスする方法を用意することです。
次の質問は、12行目で宣言されている構文は何を意味しているのかということです。12行目は、コード02で説明された内容を実際に示すものです。MQL5では匿名unionの使用が許可されないため、6行目でun_01という識別子を用いてunion型を明示的に定義する必要がありました。これにより、12行目ではそのunion型に基づく変数を宣言しています。型が明示されていれば、複数のunion型変数を定義し、それぞれに異なるデータを格納することが可能です。このように、unionは特殊な型でありながら、他の型と同様に再利用が可能です。
なお、識別子のスコープと可視性については、通常の変数や定数と同じ規則に従います(これについては以前の記事でも言及されています)。また、重要な点として、unionは常に変数であり、定数としては使用できないことを強調しておきます。仮に定数的な値を格納しても、union自体は常に変数として扱われます。文字列と同様に特別な型であるとはいえ、依然として可変のオブジェクトである点に留意が必要です。
このような概念を理解するために、記事が段階的な構成となっているのです。変数と定数の違いが理解できていなければ、現在取り扱っている内容は把握しづらいでしょう。加えて、union内の配列は常に静的であり、絶対に動的にはならないということも重要な技術的制約です。
したがって、動的配列を用いて大規模なunionを構築することは不可能です。そのような記述をおこなうと、コンパイラは処理内容を解釈できません。
最後にひとつ、まだ気づいていないかもしれない重要な点があります。20行目のループが、どのようにしてメモリ領域の内容を反転できているのかということです。反転を実現するには、メモリ領域のちょうど半分までカウンタを使って繰り返し処理を行う必要があります。今回は常に偶数個の要素を使っているため、これが簡単に可能になっています。したがって、20行目のループは、unionの6行目にあるブロックの宣言(ループ自体ではなく)を適切に調整すれば、あらゆる離散型の値を反転することが可能です。当然ながら、14行目で代入されている値も、それに応じて調整する必要があります。それ以外にコードを変更する必要はありません。
たとえば、int型の変数、つまり32ビットの値を反転したい場合は、8行目と9行目の型をulongからintに変更するだけです。その後、14行目で代入する値を目的のint値に変更すれば完了です。これで、コードはulongではなくintの反転に対応するようになります。非常に簡単です。
さらに簡単な方法も存在します。ただし、MQL5で使用できる別の概念をまだ紹介していないため、現時点では上述の方法が最も単純なアプローチとなります。
この記事を締めくくる前に、unionを使ってできる最後のことを紹介しましょう。これは、関数と手続きでの使用に関連しています。これを示すために、コード03を修正して、まずループを関数内に移動し、次に同じ処理を手続き形式で実装します。いずれの場合も、目的はその関数またはプロシージャに反転処理を任せ、その結果をメインルーチンで表示することにあります。
この処理にはさまざまな方法がありますが、ここでは教育的なアプローチを採用します。目的は、unionをより広い文脈でどのように利用できるかを示すことにあります。まずは、コード03に非常に近い構成で、最も理解しやすいと考えられるコードから始めましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. ulong u64_bits; 07. uchar u8_bits[sizeof(ulong)]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. info.u64_bits = 0xA1B2C3D4E5F6789A; 15. 16. PrintFormat("The region is composed of %d bytes", sizeof(info)); 17. 18. PrintFormat("Before modification: 0x%I64X", info.u64_bits); 19. 20. Swap(info); 21. 22. PrintFormat("After modification : 0x%I64X", info.u64_bits); 23. } 24. //+------------------------------------------------------------------+ 25. void Swap(un_01 &info) 26. { 27. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 28. { 29. tmp = info.u8_bits[i]; 30. info.u8_bits[i] = info.u8_bits[j]; 31. info.u8_bits[j] = tmp; 32. } 33. } 34. //+------------------------------------------------------------------+
コード04
コード04は非常に簡単に理解できます。ただし、いくつかの重要な点に注意を払う必要があります。まず最初に挙げられるのは、unionがローカルではなくグローバルに変更されているという点です。これは、25行目で宣言されている手続きから、4行目で定義された特殊な型にアクセスできるようにするための措置です。unionをグローバルにしなければ、25行目のパラメータ定義でun_01として宣言された特殊型を使用することはできません。ここでおこなっているのは、以前メインルーチン内に書かれていたコードを別の手続きとして切り出しただけです。そして、コード03の20行目にあったループの代わりに、同じ行で新しい手続きを呼び出すようにしています。つまり、本質的には以前はprivateだったコードブロックを、publicに変更しただけなのです。コード04は、おそらく特に苦労することなく理解できると確信しています。それでは、手続きを使用する代わりに関数を使用する別のシナリオを見てみましょう。この例を以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. ulong u64_bits; 07. uchar u8_bits[sizeof(ulong)]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. info.u64_bits = 0xA1B2C3D4E5F6789A; 15. 16. PrintFormat("The region is composed of %d bytes", sizeof(info)); 17. 18. PrintFormat("Before modification: 0x%I64X", info.u64_bits); 19. 20. PrintFormat("After modification : 0x%I64X", Swap(info).u64_bits); 21. } 22. //+------------------------------------------------------------------+ 23. un_01 Swap(const un_01 &arg) 24. { 25. un_01 info = arg; 26. 27. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 28. { 29. tmp = info.u8_bits[i]; 30. info.u8_bits[i] = info.u8_bits[j]; 31. info.u8_bits[j] = tmp; 32. } 33. 34. return info; 35. } 36. //+------------------------------------------------------------------+
コード05
ここでは少し複雑に感じられるかもしれませんが、それはあくまで、現時点でこの概念が新しいものである可能性があるからです。コード自体は、以前手続きを使用したときに見たものと非常によく似ています。しかし、過去3つの例における20行目に注目すると、コード05に示されているバージョンは、経験の浅いプログラマにとって最も理解しにくいかもしれません。それでも、心配する必要はありません。結局のところ、私たちが扱っているのは、23行目で宣言された関数にすぎません。まず注目すべき点をひとつ挙げましょう。コード03とコード04では、12行目で宣言された変数の内容は必ず変更されます。これは事実です。しかし、コード05では、同じ12行目の変数の内容が変更されることはありません。
それはどういうことでしょうか。私たちはメモリ内容を反転させて、図04に示された結果を得ようとしているのではないでしょうか。反転処理は確かにおこなわれています。そして、これら3つのコードすべてにおいて、出力結果は図04と一致します。ただし、12行目の変数が変更されないと言っているのは、その変数自体が変わらないという意味です。このことは、23行目で定義されている関数の引数が定数参照として渡されていることから確認できます。
ここで混乱が生じるかもしれません。先ほど、unionは定数として使用できないと述べました。それにもかかわらず、ここでは使用できているように見えます。たしかに混乱を招きやすい部分です。あるいは、私の説明が不十分だったか、代入と宣言を混同している可能性もあります。23行目の宣言は、関数のパラメータとして定数を受け取るという意味です。つまり、関数内でその変数の内容を変更することは許されません。しかし、関数を機能させるには、変更可能な変数が必要になります。それが、25行目で新たに作られている変数です。この変数は関数内で変更され、最終的に34行目で返されます。
このあたりで多くの人が混乱しがちです。コード05においてSwapが関数であり、変数を返すならば、その戻り値を別の変数に代入すべきではないかと考えるかもしれません。これは一概には言えません。ただし、以前の記事でも述べたように、関数も変数の一種であるため、4行目で定義された特殊な型を使って返されたデータに直接アクセスすることが可能です。
これは、関数が特定の型(ここではunion型)を明示的に返している場合にのみ可能です。もし戻り値が離散型であれば、コード05の20行目に示されているような実装は不可能です。その場合は、同様の結果を得るために別の方法を用いる必要があります。ただし、これ以上の説明は、現時点では不要な混乱を招く可能性があるため、ここでは扱いません。とはいえ、そうした実現方法が存在することは確かです。
最後に
本記事では、union(共用体)とは何かについての探究を始め、unionが実際に使用されるいくつかの基本的なシナリオを試しました。しかし、ここで紹介したのは、unionに関するより広範な概念と技術のごく一部に過ぎません。これらの内容は今後の記事でさらに掘り下げていく予定です。したがって、ここで読者の皆さんにお伝えしたい黄金のアドバイスは、本記事で学んだすべてをしっかりと復習し、練習することです。
添付ファイルには、記事内で解説した主なコード例が収録されています。そして、次回の記事では、MQL5プログラミングの基礎をさらに深く掘り下げていきます。それではまた、お会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15502
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
何も分からない!どなたか「ゼロレベルから初級者まで」の連載を始めてください!そして、あなたはプログラムにおいて2つの優れたフォームを持つ初心者を持つ。
しかし、私のこの記事の目的はまさにそれだ。人をまったくのゼロからスタートさせること。しかし、あなたはすでに少し進んだ内容の記事に入っている。この記事から始めることをお勧めする:
基礎から中級へ:変数(I)
詳細:より高度な内容の記事にはすべて冒頭にリンクがあり、前の記事を見ることができます。しかし、私がお勧めするのはこの記事だ。実際、これが最初の記事だ。ゼロから説明を始めるところ🙂👍。
何もはっきりしない!誰か「レベルゼロから初心者へ」という連載を始めてくれないかなあ!プログラミングの学位を2つ持っている初心者が......。
ポルトガル語からの翻訳で、ベストではない。![😑]()
本来はロシア語で書かれているものの方がずっとわかりやすいでしょう。例えばこの本。