
От начального до среднего уровня: Массив (IV)

Введение
В предыдущей статье От начального до среднего уровня: Массив (III) было объяснено, как использовать массивы для передачи данных между функциями и процедурами. Также были рассмотрены некоторые детали, касающиеся инициализации и базовых мер предосторожности, которые необходимо учитывать во избежание создания чего-то неустойчивого в долгосрочной перспективе. Так как я предполагаю, что многие из вас считают, что все это не имеет большой ценности или никогда не будет применено на практике, в этой статье мы начнем играть по-настоящему. Вот тут-то и начнется настоящее веселье. Потому что до сих пор мы лишь применяли некоторые простые концепции и правила к рассматриваемым ранее кодам. Но пришло время начать погружаться в то, чем на самом деле является MetaTrader 5.
Однако, прежде чем приступить к этому на практике, нам нужно рассмотреть и понять некоторые вещи, о которых многие, возможно, не знают. А другие, совершенно точно, даже представления не имеют, как это работает. Итак, теперь все становится более интересным и в то же время замысловатым. Я попрошу вас быть еще более внимательными в отношении тем, которые будут рассмотрены в этой и будущих статьях. Это связано с тем, что понимание того, что здесь будет представлено, поможет вам лучше разбираться с другими вещами, которые происходят при создании реальных приложений для MetaTrader 5.
Первое, что мы сделаем, — это разберемся, как эффективнее использовать память посредством массивов. Да, тема массивов еще не завершена. И если вы думали, что это нечто, что можно быстро охватить целиком — забудьте. На самом деле, это очень долгая и обширная тема. Именно поэтому мы будем рассматривать ее постепенно, небольшими частями, и вместе с другими темами, которые будут затронуты в ходе статей этой серии. Надеюсь, так это будет менее скучно и утомительно.
Хорошо, но прежде чем начать, я должен напомнить, что существует одно предварительное условие для того, чтобы вы могли понять то, что будет объяснено в этой статье. И это условие — обязательное понимание того, как работают коды из последней темы, рассмотренной в предыдущей статье. То есть, нужно хорошенько усвоить, как работать с массивами вне того места, где они были объявлены.
Оператор sizeof
Для начала проведем небольшой тест. Его цель — показать, как можно манипулировать данными в памяти. То есть, мы не будем использовать обычные переменные, а попробуем сделать все с помощью массивов. Таким образом мы будем моделировать создание, перемещение, чтение и запись переменных в оперативной памяти компьютера. Я знаю, это может показаться чем-то совершенно неуместным. Но это не только отличное упражнение по логике и программированию, оно поможет вам начать думать как настоящий программист. Вам придется выполнять множество разных вещей, о которых большинство программистов даже не имеют понятия.
Начнем наше упражнение с небольшого введения в нечто более масштабное. Хотя я постараюсь объяснить все максимально просто, чтобы каждый мог следить за ходом рассуждений. Первое, что нам нужно сделать, — это понять, что именно делает оператор sizeof и зачем он существует.
Оператор sizeof сообщает нам, сколько байт занимает в памяти определенный тип данных или переменная. Это кажется чем-то мистическим. Но это довольно просто понять. Прежде всего,вы должны знать, что количество элементов в массиве — это не то же самое, что объем выделенной памяти. Массив может содержать X элементов и при этом занимать Y байт. Количество элементов будет равно количеству байт, используемых или выделенных в памяти, только если используемый тип данных равен 8 битам, или 1 байту. В случае MQL5, этому требованию удовлетворяют типы char и uchar. Все остальные будут занимать больше байт, чем количество элементов в массиве. Поэтому не путайте оператор sizeof с операцией ArraySize или вызовом Size. Его цель — установить количество элементов в массиве.
Чтобы окончательно прояснить этот момент, давайте рассмотрим следующий пример, приведенный ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
Код 01
При выполнении кода 01 получается следующий результат, который можно увидеть на изображении:
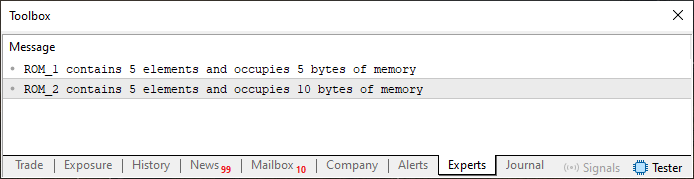
Рисунок 01
Теперь посмотрим, о чем нам говорит приведенный рисунок. Хотя это и так понятно, при первом же взгляде. Обратите внимание, что в коде 01 создаются два статических массива. Единственное различие между ними заключается в том, что один из них имеет тип char, а другой — тип short. В остальном они абсолютно одинаковы, оба содержат по пять элементов. Однако, количество используемых байт для каждого из них разное. Почему?
Итак, дорогой читатель, в статье От начального уровня до среднего: Переменные (II), есть таблица, в которой указано, сколько байт занимает каждый базовый тип данных в памяти. Если вы заглянете в нее, то увидите, что тип short занимает два байта. Так как у нас пять элементов, при умножении количества элементов в массиве на количество байт, которое занимает каждый элемент, мы получим десять байт. На самом деле, использование оператора sizeof позволяет проще и быстрее узнать объем занятого в памяти пространства.
И почему это важно для нас? Дело в том, что знание того, сколько памяти займет конкретная информация, чрезвычайно полезно. Это позволяет нам выделять больше памяти или освобождать определенный ее объем очень простым и прямым способом. Хотя мы его здесь пока еще не использовали. Со временем, мы будем выполнять много подобных реализаций. Но для нашей текущей цели, в рамках этой темы, того, что было рассмотрено, уже более чем достаточно. Так что можно переходить к следующему этапу.
Перечисления
В этой теме основное внимание будет уделено объяснению одного очень простого понятия. Однако которое, во многих ситуациях, может оказаться чрезвычайно полезным. Чтобы объяснить, что такое перечисление, самым простым и понятным способом, мы воспользуемся кодом, рассмотренным в одной из предыдущих статей. Его можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Код 02
Этот код представляет собой заголовочный файл, который уже был показан в другой статье, но снова будет разбираться здесь. В данный момент он будет нам очень полезен. Как можно заметить, для использования одного из форматов, нам понадобится любое десятичное значение. Однако, когда мы используем его в коде, довольно сложно понять, о чем именно идет речь, и какова предполагаемая цель. Это связано с тем, что код, использующий подход, показанный в коде 02, должен быть написан следующим образом:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
Код 03
В данном случае, заголовочный файл, указанный в строке 4 кода 03, точно такой же, как тот, что показан в коде 02. Вся суть заключается как раз в значениях, которые можно увидеть между строками 15 и 18. Можете ли вы на основе этих значений определить, какой тип обработки будет использован для создания выходной строки? Определенно нет. Вам пришлось бы обратиться к заголовочному файлу, найти функцию ValueToString, проанализировать, как работает каждое из значений, и только после этого решить, какое из них является наиболее подходящим. То есть, проделать много низкоэффективной работы. Именно по этой причине возникает необходимость в гораздо более практичной и эффективной структуре. Такая структура называется ПЕРЕЧИСЛЕНИЕМ (ENUM). При перечислении создается специальный тип данных, который следует прогрессивному счету при каждом новом добавленном значении. Это довольно удобно и просто в использовании.
Таким образом, обновив код 02 до версии, использующей перечисление, мы можем увидеть код, показанный ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
Код 04
Обратите внимание, что на самом деле это очень просто в реализации. Конечно, здесь мы рассмотриваем создание базового перечисления. Но я надеюсь, вам не составит труда понять, что происходит в четвертой строке. После определения перечисления, мы можем выполнить замены, которые вы видите в остальной части кода. При этом, прежний код 03 будет выглядеть так, как показано ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
Код 05
А теперь скажите правду. Просто взглянув на этот код 05, уже вполне можно понять, что он делает, не так ли? Что ж, несмотря на это небольшое изменение, код 03 продолжит работать, как и прежде. Это до тех пор, пока мы снова не начнем вносить правки в перечисление. Но пока давайте оставим все как есть. Нет смысла обсуждать некоторые более сложные детали, касающиеся перечисления. Мы вернемся к этой теме в ближайшем будущем. Но уже совершенно с другими целями.
Бесконечное количество аргументов
Теперь давайте перейдем к немного более сложной теме, чтобы сделать эту статью интереснее. В одной из предыдущих статей я показал, как можно создать представление двоичных значений, чтобы можно было визуализировать его в терминале MetaTrader 5. Я упомянул, что есть определенная сложность в создании процедуры на MQL5 для реализации поведения, которого очень легко добиться в C и C++. На самом деле, насколько мне известно, единственные языки, которые нативно допускают подобную модель, — это C и C++. Кроме них, есть еще и Java, в котором также реализовано нечто очень похожее.
Мы могли бы создать функцию или процедуру, в которой не было бы фиксированного числа аргументов или параметров, но при этом, существовало бы минимальное количество объявленных переменных, что происходит при вызове определенной функции или процедуры. И этим минимальным значением должен быть хотя бы один аргумент.
После реализации этого, мы сможем передавать функции или процедуре столько аргументов, сколько потребуется. Внутри функции или процедуры будет три специальных вызова, которые позволят нам считывать один за другим каждый дополнительный аргумент. Для тех, кому интересно или просто любопытно, рекомендую посмотреть va_start, va_arg и va_end — это три функции, используемые в C и C++. В случае Java, названия этих функций немного отличаются, но принцип действия тот же. Понимая концепцию, заложенную в таких функциях, мы можем создать нечто очень похожее здесь, на MQL5.
На самом деле, многие могут посчитать то, что будет показано, чем-то продвинутым и передовым. Но, на мой взгляд, это базовый материал, и каждый начинающий программист должен знать, как это реализовать. По сути, мы проведем тест по манипулированию массивом в MQL5. Чтобы этот трюк сработал, придется прибегнуть к небольшой хитрости, поскольку уровень представленной на данный момент информации недостаточен. Мы будем использовать оператор sizeof вместе с некоторыми простыми приемами манипуляции массивом.
Теперь давайте подумаем вот о чем: когда мы объявляем динамический массив, мы можем по мере необходимости добавлять в него новые элементы. А поскольку самым простым типом является тип uchar или char, в зависимости от случая, мы можем использовать его в качестве основы для других типов. Однако, простое помещение значений в массив не позволит нам передавать через него данные. Нам нужно что-то более продуманное.
Поэтому мы снова обращаем внимание на тип string. Это связано с тем, что строковый тип данных позволяет нам передавать значения. Мы знаем, чем заканчивается каждая строка. Пустым символом или нулем.
И здесь начинается наша хитрость и самое забавное: что, если мы создадим строку того типа, который используется в BASIC? Для тех, кто не знает, я рассказывал об этом в одной из предыдущих статей. Возможно, это было бы для нас гораздо полезнее. И действительно, вот в чем кроется вся суть. Так как было бы неуместно использовать нулевой символ в бинарных значениях.
Тем не менее, использовать нейтральный элемент внутри массива таким образом, чтобы можно было создать массив с любым количеством элементов — действительно выглядит здорово. Утверждение, что это должен знать каждый начинающий программист, может показаться немного жестким, но это так. Основываясь на том, что мы рассмотрели до этого момента, мы вполне можем, и будем, создавать вещи, способные это делать.
Мы будем использовать тот тип реализации, который доступен лишь немногим языкам программирования. Несмотря на то, что это нечто гораздо большее, здесь мы попробуем создать что-то простое. И при этом, многие программисты, называющие себя более опытными, либо никогда раньше этого не делали, либо даже не подозревают, что это возможно сделать в MQL5.
Нам нужно сделать материал максимально наглядным и простым для понимания. Поэтому, начнем со следующего: определим несколько переменных и констант, которые будут использоваться в нашем примере. Так появляется код, показанный ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
Код 06
Хорошо, когда вы запустите код 06, вы увидите в терминале что-то похожее на то, что показано на изображении:
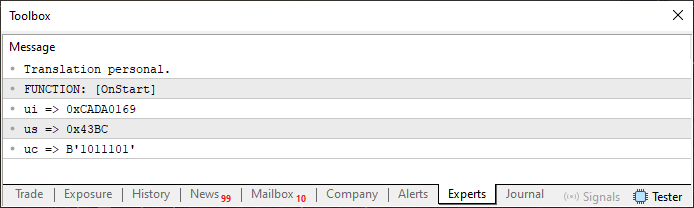
Рисунок 02
Как видим, в этом нет ничего необычного, и даже все вполне ожидаемо. Но вот тут и начинается самое интересное. Обратите внимание, что в коде 06, в строке 12, я уже добавил массив, который нам понадобится. Лично я предпочитаю беззнаковый тип (unsigned), поэтому выбираю uchar. Однако другие могут захотеть использовать знаковый тип (signed), и тогда они выберут char. В любом случае, для нашей цели это не имеет значения.
Но я хочу напомнить вам, что реализация, которую вы здесь увидите, предназначена исключительно для образовательных целей. Это далеко не лучший способ реализации механизма, который будет продемонстрирован. Есть гораздо более подходящие способы сделать это. Однако, они требуют использования некоторых методов и концепций, которые еще не были объяснены. Тем не менее, именно эти самые еще необъясненные концепции были придуманы как раз для того, чтобы упростить то, что сейчас будет показано. Я считаю совершенно уместным и практичным сначала показать концепцию, а затем методы, созданные для упрощения ее реализации. Поскольку одно ведет к другому вполне естественным образом.
Таким образом, код, который мы собираемся создать, будет содержать много встроенных (inline) элементов. Но это только потому, что было бы затруднительно объяснить, как работает метод, если бы его реализация была оформлена другим способом.
Далее, мы переносим в массив значения, объявленные в строках восемь, девять и десять. Помните, что нам нужно это сделать, чтобы иметь возможность позже восстановить эти же значения. В противном случае, реализация была бы абсолютно бесполезной.
Уяснив этот критерий, мы переходим к первой части реализации. Я буду публиковать ее постепенно, чтобы все, даже те, кто только начинает программировать, могли понять, что именно создается. Эту первую часть можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
Код 07
После выполнения кода мы увидим в терминале то, что показано на изображении ниже.
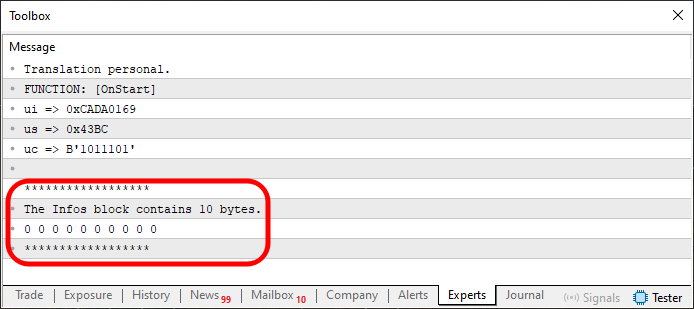
Рисунок 03
А теперь будь внимателен, дорогой читатель, чтобы не потеряться в ходе объяснения. Фрагмент, выделенный на изображении 03, представляет собой не что иное, как выполнение строк 31–34. Однако вы можете видеть, что мы показываем как содержимое памяти, так и объем выделенной памяти. Интересный момент — память выделяется между строками 25 и 27. Но это пока лишь начало кода, так как мы собираемся делать все немного приятнее, осуществляя реализацию небольшими шагами. В некотором смысле строка 29 в коде необязательна. Она просто фиксирует способ, которым мы будем обрабатывать значения.
Ну, я думаю, остальное вам понятно, так что мы можем перейти ко второму шагу. Его можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
Код 08
Теперь, когда мы используем этот код 08, результат становится несколько интереснее, как можно увидеть на этом изображении:
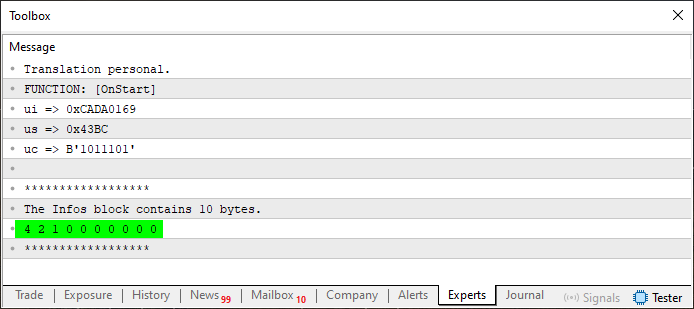
Рисунок 04
Обратите внимание, что теперь в создаваемом массиве есть некоторые значения. Эти значения были помещены туда именно благодаря строкам 32, 38 и 44, которые указывают, сколько байт нам потребуется. Но здесь есть небольшая проблема, которая будет решена на следующем этапе. Но сначала давайте разберемся, что изменилось между кодом 07 и кодом 08. Это о том, что как видно, мы создаем небольшие блоки, которые можно было бы вынести в какую-то отдельную функцию или даже внешнюю процедуру. Это особенно хорошо видно в строках с 28 по 32.
Далее, мы видим нечто очень похожее между строками 34 и 38, и почти идентичную повторяющуюся часть между строками 40 и 44. Но, как уже было сказано выше, я не собираюсь выносить это во внешнюю процедуру или функцию. Поступая так, я бы нарушил правило, которое сам себе установил для демонстрации этого механизма: не использовать ничего из того, что еще не было показано.
Если вы уже знаете, как объединить все эти блоки в один — отлично. Единственное различие между ними заключается конкретно в переменной, которую каждый из них использует для выделения достаточного объема памяти под значение. И это следующий шаг. Следующий шаг — поместить значение в массив. Вы можете увидеть это сразу ниже. На этот раз вы заметите, что код еще немного изменился.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
Код 09
Мы почти закончили. Остался только один шаг, чтобы все стало полностью понятно и реализуемо. Однако, если вы запустите код 09, то заметите, что вывод немного отличается, как вы можете увидеть на изображении ниже.
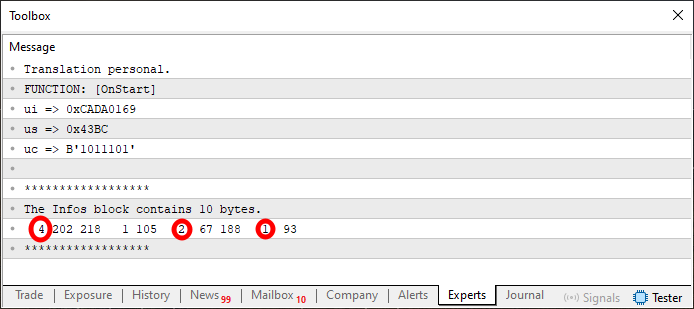
Рисунок 05
В данном случае была сделана разметка значений, которые изначально находились на изображении 4. Может показаться немного странным, как эти значения отображаются на рисунке 5, но если вы внимательно посмотрите на то, что происходит в коде 9, вы заметите, что это те значения, которые на самом деле содержатся в строках восемь, девять и десять. Возможно, вы пока не можете в это поверить. Поэтому, перейдем к последнему шагу. Этот шаг реализован в коде, представленном ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
Код 10
И вот он, дорогой читатель, — код, созданный начинающим программистом. Он полностью написан на MQL5 и позволяет передавать бесконечное количество информации в пределах одного блока массива. Результат выполнения этого кода можно увидеть на изображении:
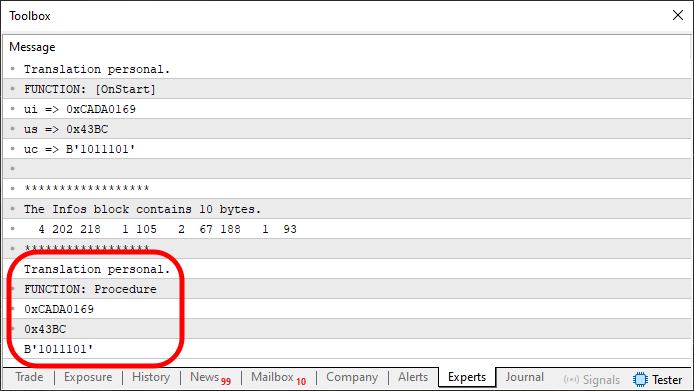
Изображение 06
Кажется, что это невозможно сделать в MQL5. То есть, реализовать механизм, существующий в таких языках, как C и C++, который позволяет передавать неограниченное количество значений из одной функции в другую. И в зависимости от способа организации данных, даже из одного приложения в другое, в пределах MetaTrader 5. Однако, это уже более сложная тема, требующая глубокого понимания различных других концепций и элементов, представленных в MQL5. Также необходимо правильно понимать, как работает MetaTrader 5.
И когда я говорю «это работает», я не имею в виду размещение объектов на графике. Это скучно и не вызывает никакого энтузиазма. Когда я говорю «это работает», я имею в виду, что вам нужно знать, почему MetaTrader 5 делает то, что он ДЕЛАЕТ. Но прежде всего, нужно понимать, как использовать механизмы, которые он предоставляет, чтобы иметь возможность реализовывать действия, подобные тем, которые я сейчас демонстрирую. Вещи, которые с моей точки зрения, являются базовыми и довольно простыми — но которые очень немногие действительно понимают и способны применять.
Посмотрите, как все становится красиво и понятно, когда базовые концепции применяются на практике. В этом коде 10, мы видим выполнение следующей задачи: между строками 28 и 48 создается массив. А затем, при выполнении строки 55, этот же массив передается внутрь процедуры. Хотя это могла бы быть и любая другая структура. И уже там, используя очень простой механизм, мы разбираем то, что было собрано между упомянутыми выше строками.
Наверняка многие могут сейчас подумать: «Зачем создавать что-то подобное? Зачем так усложнять код совершенно без надобности?». Что ж, мне жаль, но придется повторить то, что уже было сказано в начале этой статьи: то, что здесь реализовано — не является наилучшим и оптимальным способом реализации. Однако, если вы усвоите эти знания и поймете, что здесь показано, мы сможем перейти к тем вещам, которые в другом контексте было бы объяснить гораздо труднее.
Тем более, что все, что будет объяснено в следующих статьях, напрямую связано с этим кодом 10, поэтому его создание мне представляется вполне обоснованным и даже полезным. Это не усложнение. Наоборот, пошаговая процедура, которая будет приведена в приложении и показана здесь, окажет большую помощь тем, кто действительно хочет изучить MQL5 и MetaTrader 5 на более продвинутом уровне.
Так что, дорогие читатели, не тратьте время в ожидании ответов на вопросы, которые возникают у вас в голове. Обязательно изучите каждую деталь, которую вы увидите в этой и других статьях. И самое главное — практикуйте то, что демонстрируется. Знания накапливаются очень быстро, и этого не избежать. Равно как и сомнений, которые могут появляться от недостатка практики.
И чтобы завершить эту статью на высокой ноте, я покажу, как можно было бы по-другому написать этот же код 10. Для того, чтобы показать, что он может быть более компактным без потери функциональности. Так что, если вам комфортнее анализировать более компактный код, который выполняет, по сути, ту же самую задачу — он приведен ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Код 11
При запуске этого кода мы получим результат, показанный на следующем изображении:
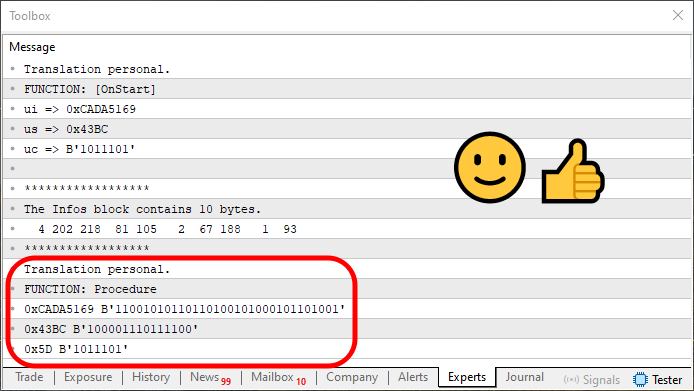
Рисунок 07
Обратите внимание, что на изображении 07 содержится информация, немного отличающаяся от той, что была на изображении 06, именно потому, что при воссоздании исходных данных мы делаем это в рамках одного цикла. Этот цикл находится в строке 70. И он относительно прост. Однако, дорогой читатель, вам следует его внимательно изучить, чтобы понять, как именно воссоздается ранее сохраненная информация.
Но по сути, он будет обращаться к позиции, где мы указываем количество байт или элементов, входящих в исходный блок информации. Именно по этой причине внешний цикл — тот, что начинается в строке 67 — потребовал небольшого изменения в своей структуре. В противном случае, мы не смогли бы корректно восстановить данные, записанные в массиве.
Заключительные соображения
Цель этой статьи — стать мостом между тем, что мы рассматривали ранее, и тем, что будет рассмотрено в следующем материале. Я понимаю, что для многих все показанное и реализованное здесь может показаться бесполезным и глупым. Однако, если вы поняли цель и назначение всего представленного в этой статье, вы почувствуете, что появляется необходимость использовать или разработать нечто большее в рамках языка.
И действительно, это заложено в язык MQL5. И это будет темой моей следующей статьи. Но если вы пока не уловили идею — подумайте вот о чем: что необходимо сделать, чтобы исключить необходимость реализации кода между строками 28 и 48? Без потери функциональности. Чтобы те же самые строки могли быть заменены на гораздо более простой и удобный код? Подумайте об этом, и ответ вы найдете в следующей статье. А пока — изучайте и практикуйтесь с примерами кода, представленными в этом материале. Все они будут доступны в приложении.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15501
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 От начального до среднего уровня: Объединение (I)
От начального до среднего уровня: Объединение (I)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования