
从基础到中级:数组(四)

概述
在上一篇文章从基础到中级:数组(三)中,我们解释了如何使用数组在函数和过程之间传递数据。我们还讨论了一些关于初始化的重要细节和应该采取的基本预防措施,以避免从长远来看创建不可持续的代码。我相信你们中的许多人可能会认为,到目前为止所展示的内容可能价值有限,或者可能很少有实际应用。但在这篇文章中,我们终于要开始真正的乐趣了。到目前为止,我们一直在示例中应用某些概念和简单规则。但现在是时候开始深入了解 MetaTrader 5 的真正意义了。
然而,在我们开始实践之前,有些事情我们需要看看 —— 你们中的许多人可能不知道,而其他人可能完全不知道它们是如何工作的。现在,事情开始变得更加有趣和复杂。因此,我要求您耐心地对待这里和后面的文章中涵盖的主题。了解我们将要探索的内容将极大地帮助您掌握在为 MetaTrader 5 开发现实世界应用程序时发挥作用的其他概念。
我们将探索的第一件事是如何使用数组更好地利用内存。是的,我们还没有完成数组的主题。如果你认为这是你可以很快完全掌握的东西,那就别想了。这个话题很广泛,涉及面很广。因此,在我们前进的过程中,我们将继续在较小的部分中介绍数组以及其他主题。这种方法应该有助于防止材料变得令人厌烦或难以承受。
在我们开始之前,重要的是要注意有一个先决条件。您需要了解上一篇文章中最后一个主题的代码是如何工作的。具体来说,如何处理声明范围之外的数组。
sizeof 运算符
首先,我们来做一个小测试。它的目的是展示如何在内存中操纵数据。我们不会使用普通变量,但会尝试使用数组来完成所有事情。这将模拟直接在计算机 RAM 中创建、移动、读取和写入变量的过程。我知道这听起来可能有些牵强。但除了是逻辑和编程的绝佳练习外,它还将帮助你开始像真正的程序员一样思考。这是因为你需要执行许多程序员甚至不知道如何处理的任务。
我们将从对更大事物的简单介绍开始。不过,我会尽量让事情尽可能简单,这样每个人都能理解其中的道理。首先,我们需要了解 sizeof 运算符的实际作用以及它存在的原因。
sizeof 运算符负责告诉我们数据类型或变量在内存中占用了多少字节。这听起来可能有点神秘,但实际上它相当简单。首先,重要的是要理解数组中的元素数量并不直接对应于分配的内存量。一个数组可能有 X 个元素但占用 Y 个字节。如果使用的数据类型为 8 位或 1 个字节,则元素的数量将仅等于内存中使用或分配的字节数。在 MQL5 中,满足此标准的类型是 char 和 uchar。所有其他类型将占用比数组中存在的元素数量更多的字节。因此,不要将 “sizeof” 运算符与 “ArraySize” 运算或 “Size” 函数调用混淆。后面两者的目的是确定数组中元素的数量。
让我们看看下面的例子:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
代码 01
当执行代码 01 时,会产生以下结果:
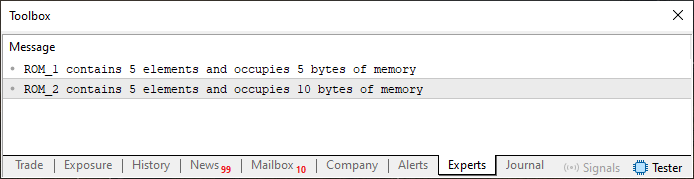
图 01
现在让我们分析一下图 01 告诉我们的内容。虽然仅仅通过观察它就相当直观,但让我们把它分解一下。在代码 01 中,创建了两个静态数组。它们之间的唯一区别是一个是 “char” 类型,另一个是 “short” 类型。除此之外,它们完全相同,各包含五个元素。但是,每个使用的内存量(以字节为单位)是不同的。为什么呢?
回到文章从基础到中级:变量(二)中,有一个表格显示每种基本数据类型在内存中占用的字节数。如果您参考该表,您会发现 “short” 类型占用两个字节。由于我们有 5 个元素,因此将数组中的元素数乘以每个元素占用的字节数,我们得到总共 10 个字节。事实上,使用‘sizeof’运算符来确定占用了多少内存非常简单。
这对我们为什么重要?了解给定数据块将消耗多少内存非常有用。例如,它允许我们以非常简单和直接的方式分配额外的内存或释放一定数量的内存。虽然我们还没有在实践中使用它。随着我们的进展,我们会更多地实施这种操作。但就我们目前的目的而言,我们在这里所涵盖的已经足够了。现在我们可以进入下一阶段。
枚举
本主题将重点解释一个非常简单的概念。然而,这一概念在无数情况下都非常有用。为了以一种非常简单易懂的方式解释枚举器是什么,我们将重新审视前一篇文章中讨论过的一些代码。您可以在下面看到它。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
代码 02
我们以前看过这个头文件,我们将在这里再次讨论它。此刻,它对我们非常有用。如您所见,要使用其中一种格式,我们需要任意的十进制值。然而,当我们在代码中使用它时,很难理解它的目的。这是因为使用代码 02 中所示方法的代码需要编写如下:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
代码 03
在这种情况下,代码 03 第 4 行指定的头文件正是代码 02 中显示的头文件。然而,这里的问题具体在于第 15 行和第 18 行之间看到的值。通过查看这些值,您能否确定生成输出字符串需要进行何种处理?肯定不能。您需要查阅头文件,找到 ValueToString 函数,分析每个值的处理方式,然后才决定使用哪个值。换句话说,工作量很大,但效率却很低。正因为如此,需要一种更实用、更高效的结构,这种结构被称为枚举。枚举创建了一种特殊的数据类型,该数据类型在每次添加新值时都遵循递增计数。它非常方便和易于使用。
因此,通过将代码 02 更新为使用枚举的代码,我们得到以下代码:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
代码 04
请注意,这实际上很容易实现。当然,在这里我们要创建一个基本枚举。但我希望你能轻松理解第 4 行发生的事情。一旦定义了枚举,我们就可以进行您在其余代码中看到的替换。在这种情况下,之前的代码 03 将如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
代码 05
说实话,只要看一下代码 05,就很清楚代码在做什么,不是吗?尽管有这个小变化,代码 03 仍可继续工作而无需进行任何修改,至少在我们对枚举进行进一步更改之前。但现在,我们还是维持现状吧。现在深入研究枚举的更高级细节还没有意义。我们将在不久的将来再次回到这个话题,但目的不同。
无限数量的参数
现在,让我们继续讨论一个稍微高级一些的话题,让这篇文章更有趣。在上一篇文章中,我演示了如何在 MetaTrader 5 终端中创建用于可视化的二进制值表示。我提到过,在 MQL5 中创建一个与在 C 和 C++ 中可以轻松完成的行为类似的过程存在一些困难。事实上,据我所知,C 和 C++ 是唯一原生支持这种实现的语言,尽管 Java 也提供了类似的东西。
在这些语言中,您可以创建一个不需要固定数量的参数或参数的函数或过程。相反,在调用函数时声明了最少数量的必需参数,必须至少提供一个参数。
一旦满足了这个最小值,您就可以根据需要传递尽可能多的额外参数。在函数或过程内部,有三个特殊的调用,允许您单独访问每个额外的参数。对于那些感兴趣或好奇的人,请查阅 va_start、va_arg 和 va_end - 这是 C 和 C++ 使用的三个函数。在 Java 中,名称略有不同,但操作原理基本相同。通过理解这些函数背后的概念,我们可以在 MQL5 中构建非常相似的东西。
有些人可能认为这些内容很高级。然而,在我看来,这是每个初学者都应该知道如何实施的基本知识。我们主要要做的是在 MQL5 中尝试数组操作。但是,为了使这个技巧在我们迄今为止所涵盖的知识水平上发挥作用,我们需要使用一个小的变通方法。我们将使用 sizeof 运算符以及对数组执行的一些简单操作。
现在,考虑以下情况:当我们声明一个动态数组时,我们可以根据需要向其中添加新元素。由于最简单的类型是 uchar(或 char,视情况而定),我们可以将其用作其他类型的基础。但是简单地在数组中堆叠值将不允许我们传递数据,我们需要一些更周到的东西。
这让我们回到字符串类型。原因是字符串允许我们传递值,我们知道每个字符串如何结束。也就是说,使用 null 或 0 终止符。
这就是我们的解决方法和乐趣所在:如果我们创建一个类似于 BASIC 中使用的字符串呢?对于那些不熟悉的人,我在上一篇文章中讨论过这个问题。这实际上可能更有用,这就是重点。在二进制值中使用 null 终止符是不合适的。
另一方面,在数组中使用中性元素来创建任何所需长度的数组是非常巧妙的。说这应该是任何初学者程序员的常识,可能会有点苛刻。但是,是的,基于我们迄今为止所涵盖的内容,我们可以构建一些实现这一目标的东西。
我们将实现一种很少有语言能够原生支持的机制。更重要的是,我们将开发一些基本的东西。然而,许多所谓的有经验的程序员从未意识到 MQL5 中这是可能的。
为了保持教育性和简单性,我们将从定义示例模型中使用的变量和常量开始。因此,我们有如下所示的代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
代码 06
好的,当您运行代码 06 时,您会在终端中看到类似于图 02 中显示的内容。
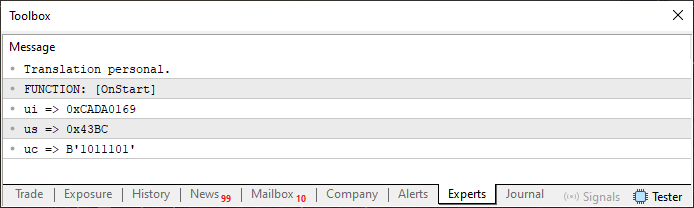
图 02
现在,这个结果并不奇怪。事实上,这正是我们所期望的。但这就是事情变得有趣的地方。请注意,在代码 06 的第 12 行,我已经添加了我们稍后需要的数组。就我个人而言,我更喜欢使用无符号类型,这就是我选择 uchar 的原因。其他人可能更喜欢使用有符号类型,在这种情况下他们会使用 char。无论哪种方式,这个选择都不会影响我们的预期结果。
也就是说,我想提醒你,这里展示的实施纯粹是为了教育目的。无论如何,这都不是实施这一机制的最佳方式,有更合适的方法可以实现这一目标。但它们需要我们尚未涵盖的某些方法和概念。然而,由于创建这些概念是为了简化我们即将探索的内容,我认为首先向您展示核心概念,然后介绍后来开发的方法,使实现更清晰、更容易,这是有用的。这是一个相当自然的过程,一件事导致下一件事。
因此,我们将创建的代码将包含许多内联实现。但这只是因为如果我们使用另一种实现,很难解释底层方法是如何工作的。
那么,让我们开始将第 8、9 和 10 行声明的值传输到数组中。记住,我们需要以一种允许我们以后重建这些完全相同的值的方式来做到这一点。否则,整个实现将毫无意义。
考虑到这一要求,让我们继续进行实现的第一部分。我将逐步介绍它,这样即使是初学者也可以跟随并完全理解我们正在创造的东西。以下是实现的第一部分:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
代码 07
执行代码后,我们将在终端中看到以下结果。
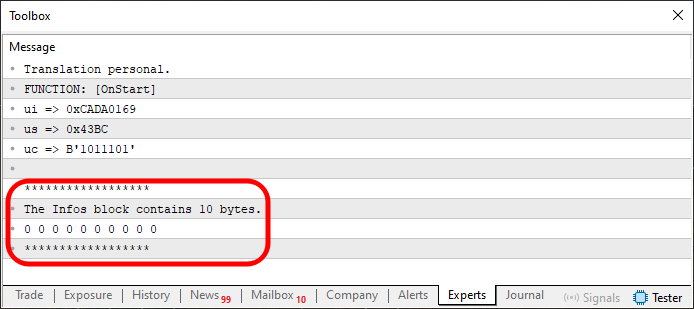
图 03
现在,亲爱的读者,请密切关注,以免迷失在解释中。图 03 中突出显示的部分是执行第 31 至 34 行的结果。但是,您会注意到,我们同时显示了内存的内容和分配的内存量。请注意,内存分配是在第 25 行和第 27 行之间进行的。但请记住,这只是代码的开始。我们正在逐步采取行动。从某种意义上来说,第 29 行的代码是不必要的。它只是用来定义我们如何处理这些值。
我相信到目前为止,我们所涵盖的一切都应该已经很好地理解了。因此,我们可以进入第二步。您可以在下面看到它。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
代码 08
现在,当我们运行代码 08 时,结果开始变得更加有趣,如下图所示:
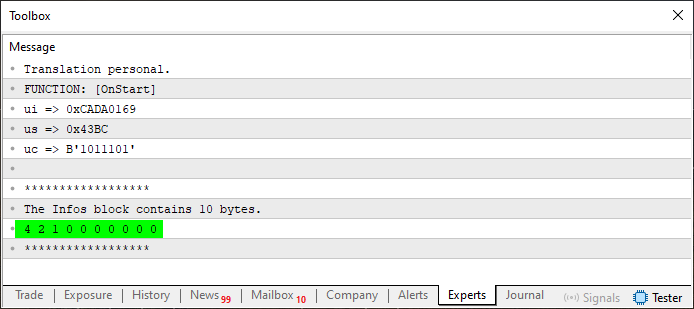
图 04
我们现在有一些值出现在正在创建的数组中。这些值是由于第 32、38 和 44 行而出现的,这些行指示了正在使用的字节数。然而,这里有一个小问题,我们将在下一步解决。但在讨论这个之前,让我们先了解一下代码 07 和代码 08 之间发生了什么变化。我们开始形成可以很容易地移动到函数甚至外部过程中的小块代码。这在第 28 行和第 32 行之间非常明显。
然后,我们在第 34 行和第 38 行之间看到非常相似的内容,接着在第 40 行和第 44 行之间看到几乎相同的重复。但正如我之前提到的,我们还不会将其作为外部函数或过程来实现。因为我们决定不使用任何尚未涉及的概念。
好吧,如果您已经知道如何将这些块合并为一个函数 —— 太好了。它们之间唯一真正的区别是用于分配足够内存来存储值的变量。这将带我们进入下一步,就是将值放入数组中。下一步如下面的代码所示。请注意代码中还有其他变化。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
代码 09
我们快要完成了,在一切都完全理解和实现之前还剩一步。但是,如果运行代码 09,您会注意到输出略有变化,如图 05 所示。
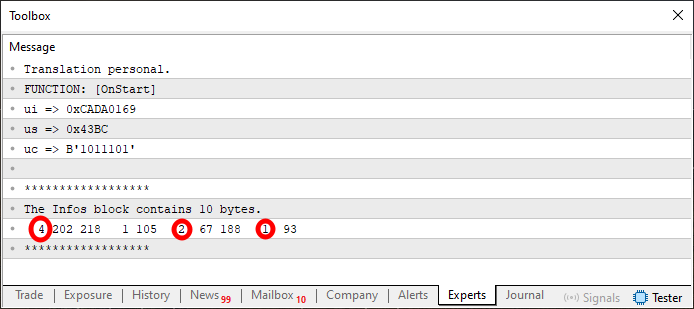
图 05
在这种情况下,我们标记了最初在图 04 中的值。我知道图 05 中显示的值乍一看可能有点奇怪。但如果你仔细看看代码 09 中发生了什么,你会发现这些实际上是第 8、9 和 10 行的确切值。您可能仍然对此持怀疑态度,那么让我们进入最后一步。它在下面显示的下一个代码块中实现。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
代码 10
这就是我们所得到的 —— 由编程初学者编写的代码。它完全用 MQL5 开发,能够在单个数组块内传输无限量的信息。该代码的执行结果如下所示:
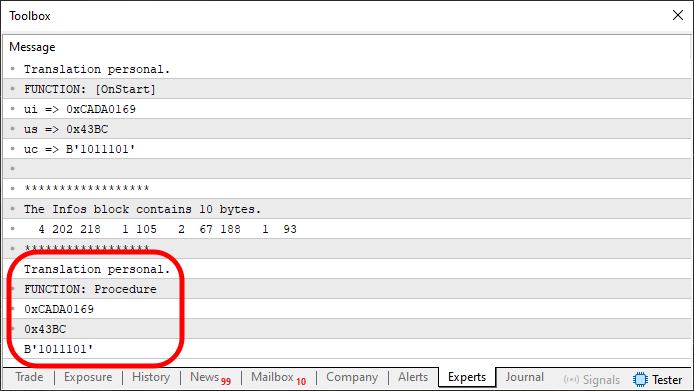
图 06
乍一看,这似乎是在 MQL5 中不可能实现的事情。也就是说,实现了一种存在于 C 和 C++ 等语言中的机制,该机制允许您将不确定数量的值从一个函数发送到另一个函数。这取决于您如何构建事物,甚至在 MetaTrader 5 中从一个应用程序到另一个应用程序。然而,这是一个更高级的主题,需要对 MQL5 中的一些其他概念和组件有深入的了解。您还需要了解 MetaTrader 5 的真正运作方式。
当我说运行时,我并不是在谈论简单地在图表上显示事物。这没有什么刺激或挑战。我的意思是理解为什么 MetaTrader 5 会这样做。更重要的是,如何使用它提供的内部机制来完成我们在这里演示的事情。在我看来,这些都是基本而简单的技术,但很少有人真正理解或有效地实施它们。
现在,请注意,当我们正确应用基本概念时,一切是如何完美地结合在一起的。以下是代码 10 中发生的情况:在第 28 行和第 48 行之间,我们构造了数组。然后,使用第 55 行的一个简单命令,我们将相同的数组发送到一个过程(尽管它可以是其他任何东西)。在里面,我们使用一种简单的技术来解构我们之前在那些早期代码行之间构建的内容。
你可以问:“为什么要创造这样的东西?你只是把事情复杂化了。”我明白,但我要提醒你,这绝不是最好的或最有效的方法。然而,亲爱的读者,如果你真正理解这里所展示的内容背后的逻辑和机制,那么我们就可以继续讨论其他概念了。
也就是说,由于即将发表的文章中的主题与代码 10 直接相关,因此在这里创建代码 10 既相关又合理。事实上,这并不是什么复杂的事情。此逐步细分将包含在下面的附件中。对于任何真正想要在更高级层面上探索 MQL5 和 MetaTrader 5 的人来说,它都非常有价值。
所以,亲爱的读者,不要浪费时间等待你脑海中自然出现的问题的答案。研究本文和其他文章中讨论的每个细节,最重要的是,实践所展示的内容。知识积累得很快,就像缺乏练习而产生的疑虑一样。
最后,为了完美地结束这篇文章,我将向您展示如何以更简洁的形式重写代码 10。这是为了证明,完全有可能以更紧凑、更优雅的方式实现相同的功能。如果你发现分析基本上执行相同任务的更精简的代码更舒服,请查看下面的替代版本。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
代码 11
执行代码 11 后,您将看到以下输出:
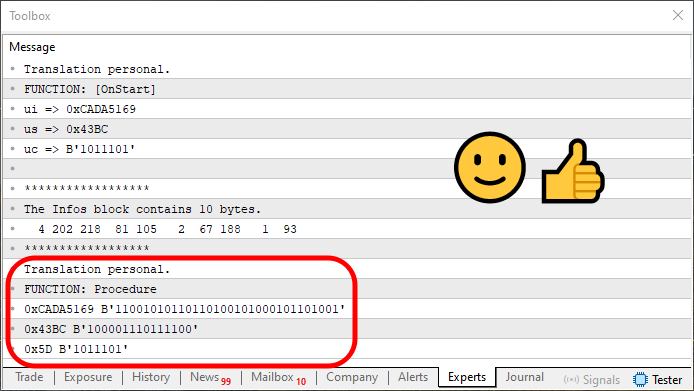
图 07
请注意,图 07 中显示的信息与我们在图 06 中看到的略有不同。这种差异是由于当我们重建原始数据时,我们现在是在一个循环内完成的。它显示在第 70 行。这个循环比较简单。但我强烈建议你,亲爱的读者,仔细研究它,以了解它是如何重建之前保存的数据的。
本质上,循环不断地查看告诉我们给定块中包含多少字节或元素的位置。因此,第67行所示的外环必须稍作调整。如果没有此更改,我们将无法从数组中正确检索存储的数据。
最后的探讨
本文旨在作为我们之前讨论的内容和接下来讨论的内容之间的桥梁。我明白,许多人可能会觉得这里展示的实现方式有些过度,甚至有点疯狂。但是,如果您能够理解本文中所介绍内容背后的目的和推理,您可能会意识到确实需要在语言中创建或使用更多内容。
事实上,MQL5 中已经存在这样的机制。这将是我下一篇文章的主题。但如果你还不明白,请考虑以下几点:我们需要做什么来消除在第 28 行和第 48 行之间实现代码的需要?并且不会丢失任何功能。换句话说,我们如何才能将代码行简化为更清晰、更高效的形式?想一想,答案就会在下一篇文章中揭晓。在此之前,请学习并练习使用此处显示的代码示例。所有代码示例均在附件中提供。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15501
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
