
From Basic to Intermediate: Array (IV)

Introduction
In the previous article From Basic to Intermediate: Arrays (III), we explained how to use arrays to pass data between functions and procedures. We also discussed some important details regarding initialization and basic precautions that should be taken to avoid creating unsustainable code in the long run. I believe many of you might think that what has been shown so far may have limited value or might rarely find practical application. But in this article, we're finally going to start having some real fun. Until now, we've been applying certain concepts and simple rules in examples. But it's time for us to start diving into what MetaTrader 5 is really all about.
However, before we jump into practice, there are some things we need to see - the things many of you might not know, and others may have absolutely no idea how they work. Now, things start to become both more interesting and more complex. So, I ask that you approach the topics covered here and in the following articles with patience. Understanding what we're about to explore will greatly help you grasp other concepts that come into play when developing real-world applications for MetaTrader 5.
The first thing we'll explore is how to utilize memory better using arrays. Yes, we're still not finished with the topic of arrays. And if you thought this was something you could fully master quickly — forget it. This topic is broad and extensive. Therefore, we will continue covering arrays in smaller sections, together with other subjects as we move forward. This approach should help keep the material from becoming tiresome or overwhelming.
Before we begin, it's important to note that there is a prerequisite. You need to have understood how the code from the last topic in the previous article works. Specifically, how to work with arrays outside of their declaration scope.
The sizeof Operator
First, let's do a small test. Its purpose is to show how data can be manipulated in memory. We will not use ordinary variables, but will try to do everything using arrays. This will simulate the process of creating, moving, reading, and writing variables directly in the computer's RAM. I know this may sound far-fetched. But in addition to being an excellent exercise in logic and programming, it will also help you start thinking like a true programmer. That's because you'll need to perform tasks that many programmers don't even know how to approach.
We'll start with a small introduction to something much larger. Though, I'll try to keep things as simple as possible so everyone can follow the reasoning. To begin, we need to understand what the sizeof operator actually does and why it exists.
The sizeof operator is responsible for telling us how many bytes a data type or variable occupies in memory. This may sound a bit mystical. But it's actually quite simple. First, it's important to understand that the number of elements in an array does not directly correspond to the amount of allocated memory. An array may have X elements but occupy Y bytes. The number of elements will only equal the number of bytes used or allocated in memory if the data type used is 8 bits, or 1 byte. In MQL5, the types that meet this criterion are char and uchar. All other types will occupy more bytes than the number of elements present in the array. So do not confuse the 'sizeof' operator with an 'ArraySize' operation or a 'Size' function call. Its purpose is to determine the number of elements in an array.
Let's look at the following example:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char ROM_1[] = {2, 3, 3, 5, 8}; 07. const short ROM_2[] = {2, 3, 3, 5, 8}; 08. 09. PrintFormat("ROM_1 contains %d elements and occupies %d bytes of memory", ROM_1.Size(), sizeof(ROM_1)); 10. PrintFormat("ROM_2 contains %d elements and occupies %d bytes of memory", ROM_2.Size(), sizeof(ROM_2)); 11. } 12. //+------------------------------------------------------------------+
Code 01
When code 01 is executed, the following result is produced:
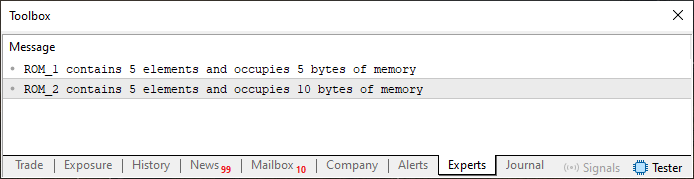
Figure 01
Now let's analyze what Image 01 is telling us. Although it's fairly intuitive just by looking at it, let's break it down. In Code 01, two static arrays are created. The only difference between them is that one is of type 'char' and the other is of type 'short'. Other than that, they are exactly the same, each containing five elements. However, the amount of memory (in bytes) used by each is different. Why?
Back in the article From Basic to Intermediate: Variables (II), there's a table that shows the number of bytes each basic data type occupies in memory. If you refer to that table, you'll see that the 'short' type occupies two bytes. Since we have five elements, multiplying the number of elements in the array by the number of bytes each element occupies gives us a total of ten bytes. In fact, using the 'sizeof' operator to determine how much memory is occupied is quite simple.
And why is this important to us? Knowing how much memory a given piece of data will consume is extremely useful. It allows us, for instance, to allocate additional memory or free up a certain amount of memory in a very easy and direct manner. Although we haven't yet used this in practice. We will frequently implement this kind of operation as we progress. But for our current purpose, what we've covered here is more than sufficient. So we can now move on to the next stage.
Enumerations
This topic will focus on explaining a very simple concept. However, this concept can be extremely useful in countless situations. To explain what an enumerator is, in a very simple and easy-to-understand way, we'll revisit some code that was discussed in a previous article. You can see it just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Code 02
We have seen this header file before and we will discuss it again here. At this moment, it will be very useful to us. As you can see, to use one of the formats, we need any decimal value. However, when we use it in code, it is quite difficult to understand what its purpose. This is because code using the approach shown in Code 02 would need to be written as follows:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, 0), 16. ValueToString(value, 1), 17. ValueToString(value, 2), 18. ValueToString(value, 3) 19. ); 20. } 21. //+------------------------------------------------------------------+
Code 03
In this case, the header file specified in line 4 of Code 03 is exactly the one shown in Code 02. However, the issue here lies specifically with the values you see between lines 15 and 18. By looking at those values, would you be able to determine what kind of processing is done to generate the output string? Definitely NOT. You would need to consult the header file, locate the ValueToString function, analyze how each of the values is handled, and only then decide which value would be appropriate to use. In other words, a lot of work for very little productivity. Precisely because of this, a much more practical and efficient structure becomes necessary. This structure is known as an ENUM. Enumeration creates a special data type that follows a progressive count with each new value added. It is quite convenient and easy to use.
Thus, by updating Code 02 to one that uses an enumeration, we arrive at the following code shown below:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. enum eConvert { 05. FORMAT_DECIMAL, 06. FORMAT_OCTAL, 07. FORMAT_HEX, 08. FORMAT_BINARY 09. }; 10. //+------------------------------------------------------------------+ 11. string ValueToString(ulong arg, eConvert format) 12. { 13. const string szChars = "0123456789ABCDEF"; 14. string sz0 = ""; 15. 16. while (arg) 17. switch (format) 18. { 19. case FORMAT_DECIMAL: 20. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 21. arg /= 10; 22. break; 23. case FORMAT_OCTAL: 24. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 25. arg >>= 3; 26. break; 27. case FORMAT_HEX: 28. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 29. arg >>= 4; 30. break; 31. case FORMAT_BINARY: 32. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 33. arg >>= 1; 34. break; 35. default: 36. return "Format not implemented."; 37. } 38. 39. return sz0; 40. } 41. //+------------------------------------------------------------------+
Code 04
Note that this is actually very simple to implement. Of course, here we are looking at creating a basic enumeration. But I hope you can easily understand what's going on in the fourth line. Once the enum is defined, we can make the substitutions you see in the rest of the code. In this case, the previous Code 03 will look like the one shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation personal.\n" + 11. "Decimal: %s\n" + 12. "Octal : %s\n" + 13. "Hex : %s\n" + 14. "Binary : %s", 15. ValueToString(value, FORMAT_DECIMAL), 16. ValueToString(value, FORMAT_OCTAL), 17. ValueToString(value, FORMAT_HEX), 18. ValueToString(value, FORMAT_BINARY) 19. ); 20. } 21. //+------------------------------------------------------------------+
Code 05
Let's be honest. Just by looking at Code 05, it's perfectly clear what the code is doing, isn't it? Despite this small change, Code 03 would still continue to work without any modifications. At least until we make further changes to the enum. But for now, we'll leave things as they are. It wouldn't make sense to dive into more advanced details about enumerators just yet. We'll return to this topic again in the near future, but with different purposes.
An Infinite Number of Arguments
Now let's move on to a slightly more advanced topic to make this article more interesting. In a previous article, I demonstrated how to create a binary value representation for visualization in the MetaTrader 5 terminal. I mentioned that there was some difficulty creating a procedure in MQL5 with behavior similar to what can be easily done in C and C++. In fact, as far as I know, C and C++ are the only languages that natively support this kind of implementation. Though Java also offers something similar.
In these languages, you can create a function or procedure that doesn't require a fixed number of arguments or parameters. Instead, there's a minimum number of required arguments declared when calling the function. At least one parameter must be provided.
Once this minimum is satisfied, you can pass as many additional arguments as needed. Inside the function or procedure, there are three special calls that allow you to access each additional argument individually. For those interested or curious, look up va_start, va_arg, and va_end - these are the three functions used by C and C++. In Java, the names differ slightly, but the operating principle is essentially the same. By understanding the concept behind these functions, we can build something very similar here in MQL5.
Some may consider this material to be advanced. However, in my opinion, this is fundamental knowledge that every beginner should know how to implement. What we're essentially going to do is play around with array manipulation in MQL5. But to make the trick work at the level of knowledge we've covered so far, we'll need to use a small workaround. We will use the sizeof operator along with some simple manipulations performed on an array.
Now, consider the following: when we declare a dynamic array, we can add new elements to it as needed. And since the simplest type is uchar (or char, depending on the case), we can use it as a base for other types. But simply stacking values in an array will not allow us to pass data. We need something more thoughtful.
This brings us back to the string type. The reason for this is that strings allow us to pass values. We know how each string ends. That is, with a null or zero terminator.
And this is where our workaround and the fun part come in: What if we created a string similar to those used in BASIC? For those unfamiliar, I discussed this in a previous article. This might actually be far more useful. That's the whole point. Using a null terminator in binary values wouldn't be appropriate.
On the other hand, using a neutral element inside an array to create an array of any desired length is quite ingenious. It may even seem a bit harsh to say this should be common knowledge for any beginner programmer. But yes, based on what we've covered so far, we can build something that achieves this.
We'll implement a mechanism that few languages can natively support. More importantly, we'll develop something basic. And yet many so-called experienced programmers have never realized is possible in MQL5.
To keep things educational and simple, we'll begin by defining variables and constants to be used in our example model. Thus, we have the following code shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayFree(Infos); 26. } 27. //+------------------------------------------------------------------+
Code 06
Ok, when you run Code 06, you'll see something in the terminal that looks like what's shown in Image 02.
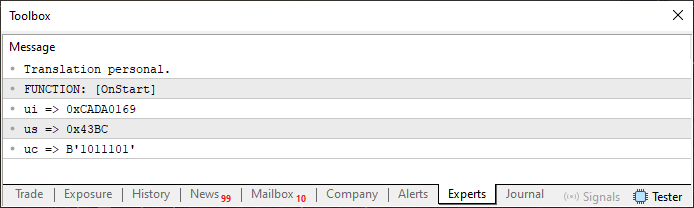
Figure 02
Now, this result isn't anything extraordinary. In fact, it's exactly what we expected. But here's where things get interesting. Notice that in Code 06, on line 12, I've already added an array that we'll need later. Personally, I prefer using the unsigned type, which is why I go with uchar. Others might prefer to use the signed type, in which case they would use char. Either way, this choice won't affect our intended outcome.
That said, I'd like to remind you that the implementation shown here is intended purely for educational purposes. It is not, by any means, the optimal way to implement this mechanism. There are far more appropriate ways of achieving this. But they require certain methods and concepts that we haven't covered yet. However, since those concepts were created to simplify exactly what we're about to explore, I believe it's useful to show you the core concept first and then introduce the methods that were later developed to make the implementation cleaner and easier. It's quite a natural progression, where one thing leads into the next.
Because of this, the code we’ll create will include many inline implementations. But that's only because it would be difficult to explain how the underlying method works if we used another implementation.
So, let's begin the process of transferring the values declared on lines 8, 9, and 10 into the array. Remember, we need to do this in a way that allows us to later reconstruct these exact same values. Otherwise, the whole implementation would be completely pointless.
With that requirement in mind, let's proceed to the first part of the implementation. I'll present it in small steps so that even beginners can follow along and fully understand what we are creating. Here is this first part of the implementation:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[]; 13. 14. PrintFormat("Translation personal.\n" + 15. "FUNCTION: [%s]\n" + 16. "ui => 0x%s\n" + 17. "us => 0x%s\n" + 18. "uc => B'%s'\n", 19. __FUNCTION__, 20. ValueToString(ui, FORMAT_HEX), 21. ValueToString(us, FORMAT_HEX), 22. ValueToString(uc, FORMAT_BINARY) 23. ); 24. 25. ArrayResize(Infos, Infos.Size() + sizeof(ui) + 1); 26. ArrayResize(Infos, Infos.Size() + sizeof(us) + 1); 27. ArrayResize(Infos, Infos.Size() + sizeof(uc) + 1); 28. 29. ZeroMemory(Infos); 30. 31. Print("******************"); 32. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 33. ArrayPrint(Infos); 34. Print("******************"); 35. 36. ArrayFree(Infos); 37. } 38. //+------------------------------------------------------------------+
Code 07
After executing the code, we will see in the terminal the following result.
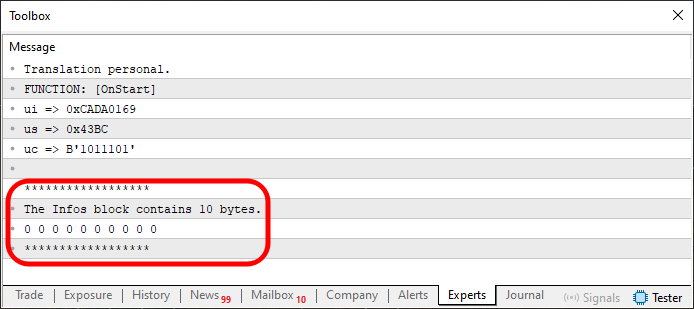
Figure 03
Now, pay very close attention, dear reader, to avoid getting lost in the explanation. The section highlighted in Figure 03 is the result of executing lines 31-34. However, you'll notice that we're displaying both the contents of memory and the amount of memory allocated. Note that memory allocation is performed between lines 25 and 27. But keep in mind, this is only the beginning of the code. We're taking things step by step. In a sense, the code on line 29 is unnecessary. It's just used to define how we will work with the values.
I believe everything we've covered so far should be pretty well understood by now. So, we can move on to the second step. You can see it just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. ArrayFill(Infos, start, number, 0); 32. Infos[counter++] = sizeof(ui); 33. 34. number = sizeof(us) + 1; 35. start = Infos.Size(); 36. ArrayResize(Infos, start + number); 37. ArrayFill(Infos, start, number, 0); 38. Infos[counter++] = sizeof(us); 39. 40. number = sizeof(uc) + 1; 41. start = Infos.Size(); 42. ArrayResize(Infos, start + number); 43. ArrayFill(Infos, start, number, 0); 44. Infos[counter++] = sizeof(uc); 45. 46. Print("******************"); 47. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 48. ArrayPrint(Infos); 49. Print("******************"); 50. 51. ArrayFree(Infos); 52. } 53. //+------------------------------------------------------------------+
Code 08
Now, when we run Code 08, the results start to become a bit more interesting, as you can see below:
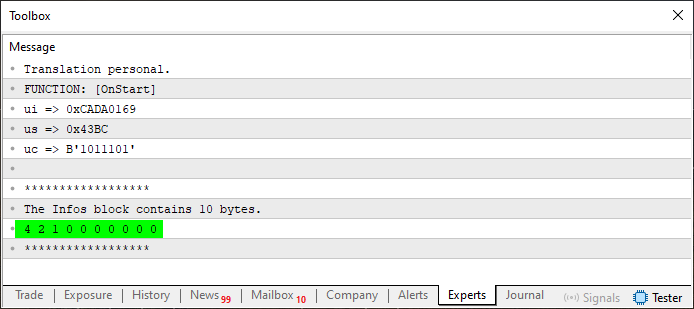
Figure 04
We now have some values appearing in the array being created. These values appear due to lines 32, 38, and 44, which indicate how many bytes are being used. However, there's a small issue here, which we will resolve in the next step. But before we get to that, let's understand what changed between Code 07 and Code 08. We're beginning to form small blocks of code that could easily be moved into a function or even an external procedure. This is clearly noticeable between lines 28 and 32.
Then, we see something very similar between lines 34 and 38, followed by a nearly identical repetition between lines 40 and 44. But as I mentioned earlier, we will not implement it as an external function or procedure yet. Because we decided not to use any concept that hasn't already been covered.
Well, if you already know how to consolidate these blocks into a single function – great. The only real difference between them is the variable used to allocate enough memory to store the value. And that brings us to the next step. This is placing the value into the array. This next step is shown in the code below. Please note that there are other changes in the code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. ArrayFree(Infos); 56. } 57. //+------------------------------------------------------------------+
Code 09
We're almost there. One more step remains before everything is fully understood and implemented. However, if you run Code 09, you'll notice that the output has changed slightly, as shown in Figure 05.
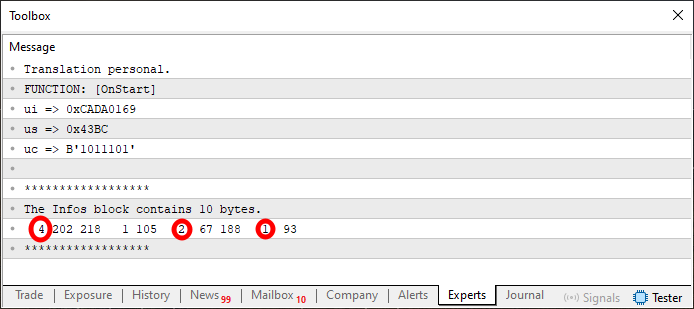
Figure 05
In this case, we marked the values that were originally in Figure 04. I understand that the values displayed in Figure 05 might look a bit strange at first glance. But if you carefully look at what's happening in Code 09, you'll see that these are, in fact, the exact values from lines eight, nine, and ten. You might still be skeptical about that. So let's move on to the final step. It is implemented in the next code block shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA0169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. for (uchar c = 0; c < arg.Size(); ) switch(arg[c++]) 66. { 67. case 4: 68. { 69. uint value = 0; 70. 71. for (uchar i = 0; (c < arg.Size()) && (i < (sizeof(value))); c++, i++) 72. value = (value << 8) | arg[c]; 73. Print("0x", ValueToString(value, FORMAT_HEX)); 74. } 75. break; 76. case 2: 77. { 78. ushort value = 0; 79. 80. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 81. value = (value << 8) | arg[c]; 82. Print("0x", ValueToString(value, FORMAT_HEX)); 83. } 84. break; 85. case 1: 86. { 87. uchar value = 0; 88. 89. for (uchar i = 0; (c < arg.Size()) && (i < sizeof(value)); c++, i++) 90. value = (value << 8) | arg[c]; 91. Print("B'", ValueToString(value, FORMAT_BINARY), "'"); 92. } 93. break; 94. } 95. 96. } 97. //+------------------------------------------------------------------+
Code 10
And there we have it - code written by a beginner in programming. It is entirely developed in MQL5, with the capability to transfer an unlimited amount of information within a single array block. The result of executing this code is shown below:
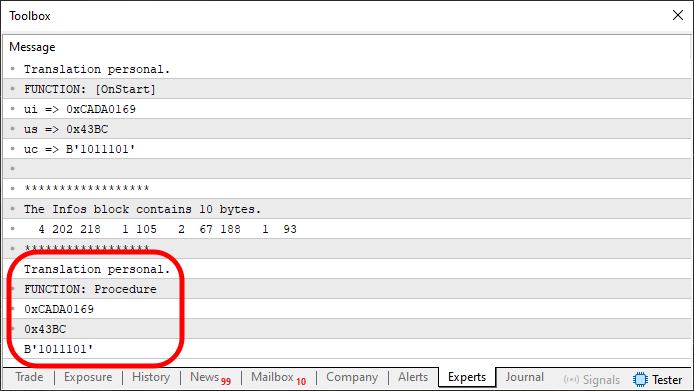
Figure 06
At first glance, this might seem like something impossible to achieve in MQL5. That is, implementing a mechanism existing in languages such as C and C++, which allows you to send an indefinite number of values from one function to another. Depending on how you structure things, even from one application to another within MetaTrader 5. However, this is a more advanced topic that requires a solid understanding of some other concepts and components in MQL5. You also need to understand how MetaTrader 5 truly operates.
When I say operates, I'm not talking about simply displaying things on a chart. There's no excitement or challenge in that. What I mean is understanding why MetaTrader 5 does what it does. And more importantly, how to use the internal mechanisms it provides in order to accomplish things like what we've demonstrated here. These are, in my view, basic and simple techniques, yet few truly understand or implement them effectively.
Now notice how everything comes together beautifully when we properly apply basic concepts. Here's what happens in Code 10: between lines 28 and 48, we construct the array. Then, with a simple command at line 55, we send the same array into a procedure (though it could be anything else). Inside, using a simple technique, we deconstruct what we previously built between those earlier lines.
You could ask: "Why create something like this? You're just overcomplicating things." And I understand. But let me remind you that this is by no means the best or most efficient way to do it. However, if you, my dear reader, truly understand the logic and mechanics behind what has been shown here, then we'll be ready to move on to other concepts.
That said, because the subjects in the upcoming articles are directly related to Code 10, its creation here is both relevant and justified. This is not a complication, in fact. This step-by-step breakdown, which will be included in the attachment below. It will be very valuable for anyone who genuinely wants to explore MQL5 and MetaTrader 5 on a more advanced level.
So, dear reader, don't waste time waiting for answers to the questions that naturally arise in your mind. Study each detail discussed in this and other articles. And most importantly, practice what is demonstrated. Knowledge accumulates quickly. Just like the doubts that come from a lack of practice.
And finally, to complete this article on a high note, I'll show you how Code 10 could be rewritten in a more concise form. This is to demonstrate that it's entirely possible to achieve the same functionality in a more compact, elegant manner. If you find it more comfortable to analyze leaner code that essentially performs the same task, check out the alternative version below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Code 11
Upon executing Code 11, you'll see the following output:
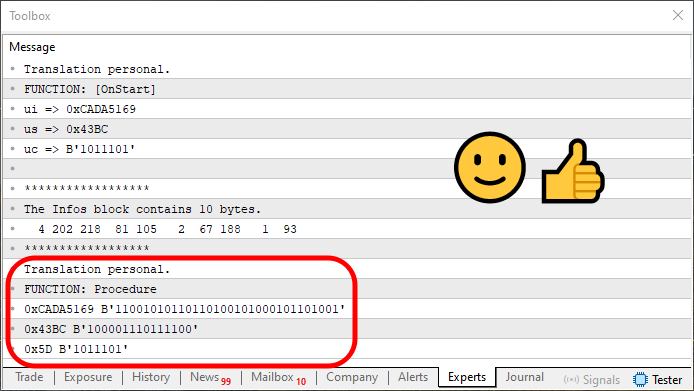
Figure 07
Notice that the information displayed in Figure 07 is slightly different from what we saw in Figure 06. This difference is due to the fact that when we reconstruct the original data, we now do it within a single loop. It is shown in line 70. This loop is relatively simple. But I strongly encourage you, dear reader, to study it carefully in order to understand how it rebuilds the data that was previously saved.
Essentially, the loop constantly looks at the position that tells us how many bytes or elements are included in a given block. Because of this, the outer loop shown in line 67 had to be slightly adjusted. Without this change, we wouldn't be able to correctly retrieve the stored data from the array.
Final Considerations
This article is intended to serve as a bridge between what we've discussed previously and what's coming next. I understand that many might find the implementation shown here to be excessive or even a bit crazy. However, if you were able to understand the purpose and reasoning behind what was presented in this article, you'll likely realize that there is a real need to create or use something more within the language.
Indeed, such a mechanism already exists in MQL5. And this will be the topic of my next article. But if you don't get the idea yet, consider the following: What would we need to do to eliminate the need to implement the code between lines 28 and 48? And without losing any functionality. In other words, how could we simplify the lines into a much cleaner and more efficient form? Think about that, and the answer will come in the next article. Until then, study and practice using the code examples shown here. All the code examples are provided in the attachment.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15501
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use