
ニューラルネットワークが簡単に(第53回):報酬の分解

はじめに
強化学習の手法を引き続き検討します。ご存知のとおり、機械学習のこの分野におけるモデルを訓練するためのすべてのアルゴリズムは、環境からの報酬を最大化するというパラダイムに基づいています。報酬関数は、モデルの訓練プロセスにおいて重要な役割を果たします。その信号は通常、非常に曖昧です。
エージェントが望ましい行動を示すようにインセンティブを与えるために、追加のボーナスとペナルティを報酬関数に導入します。たとえば、エージェントが環境を探索することを奨励するために報酬関数をより複雑にし、何もしないことに対するペナルティを導入することがよくありました。同時に、モデルのアーキテクチャと報酬関数は、モデル設計者の主観的な考慮の成果のままです。
注意深く設計にアプローチしたとしても、訓練中にモデルはさまざまな問題に遭遇する可能性があります。さまざまな理由により、エージェントが望ましい結果を達成できない場合があります。しかし、エージェントが報酬関数の信号を正しく解釈していることがどうやってわかるのでしょうか。この問題を理解するために、報酬を別個のコンポーネントに分割したいという要望があります。分解された報酬を使用し、個々のコンポーネントの影響を分析することは、モデルの訓練を最適化する方法を見つけるのに非常に役立ちます。これにより、さまざまな側面がエージェントの動作にどのような影響を与えるかをより深く理解し、問題の原因を特定し、モデルアーキテクチャ、訓練プロセス、報酬関数を効果的に調整できるようになります。
1.報酬分解の必要性
報酬関数値の分解は、さまざまな課題に対処できるシンプルで広く適用可能な方法です。強化学習では、エージェントは多くのコンポーネントの合計である報酬を受け取ります。それらのそれぞれは、エージェントの望ましい動作のいくつかの側面をエンコードすることを目的としています。この複合報酬から、エージェントは単一の複雑な重要度関数を学習します。値の分解を使用して、エージェントは各報酬コンポーネントの重要度関数を学習します。それらから抽出された単一の関数は、より単純な形式になる可能性が高くなります。
戦略の最適化を目的として、複合重要度関数は、コンポーネント重要度関数の加重和をとることによって再構築されます。
報酬の分解は、ここで検討したActor-Criticファミリーを含む、さまざまな方法に含めることができます。
ただし、報酬関数分解の追加の診断機能と訓練機能には、より複雑な予測タスクが必要になります。単一の重要度関数を訓練する代わりに、複数の関数を訓練する必要があります。エージェントのパフォーマンスに対するこの要因の影響の分析は、記事「強化学習エージェントの反復設計のための値関数分解」で実行されます。記事の著者らは、報酬関数分解をSoft Actor-Criticアルゴリズムに追加すると、モデルの訓練結果が元のアルゴリズムよりも劣ることを発見しました。ただし、著者らはアルゴリズムを改善するためのオプションを提案しました。これにより、元のSoft Actor-Criticアルゴリズムに匹敵するだけでなく、場合によってはそのパフォーマンスを超えることさえ可能になりました。これらの改善は、報酬関数分解や Actor-Criticファミリの他のアルゴリズムに適用できます。
幅広い強化学習アルゴリズムを適応させて、次のパターンに従って報酬関数の分解を使用できます。
- モデルの出力で報酬関数の各コンポーネントに対して1つの要素を取得するように Q関数モデルを変更します。
- 基本的な Q関数学習アルゴリズムを使用して、各コンポーネントを更新します。
このパターンは、離散行動空間モデル学習アルゴリズムと連続行動空間モデル学習アルゴリズムの両方で機能します。
考え方は非常にシンプルです。しかし、上で述べたように、記事の著者は、Soft Actor-Criticアルゴリズムの枠組み内で報酬分解を使用する場合、「正面からの解決策」の非効率性を発見しました。このアルゴリズムの Q関数の最適化方程式を思い出してください。

ここでは、Criticsの2つの目標モデルからの最小将来状態推定の使用がわかります。パターンのポイント2で述べたように、基本アルゴリズムを使用してQ関数の各コンポーネントのパラメータを更新します。しかし、実践が示しているように、コンポーネントごとの最小値を使用すると、モデルの不均衡が生じます。全体スコアが最小のモデルを1つ選択すると、そのコンポーネント推定値を使用してモデルを訓練するのと同様に、より効率的に機能します。
一般に、モデルの報酬関数は、そのコンポーネントの線形関数であると想定されます。
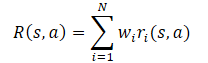
期待値の線形性を適用すると、Q関数が報酬関数から線形構造を継承していることがわかります。
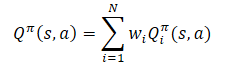
特に明記しない限り、すべてのiについて Wi=1であると仮定します。コンポーネントの重みは Q関数から取得されるため、コンポーネントの目標予測を変更せずに変更できます。これにより、重みの任意の組み合わせに対して方策を評価できるようになります。
注目すべき2番目の点は、分解された報酬関数の最適化は、多くの基準に従ってモデルを最適化することであるということです。これには、勾配の矛盾、曲率の高さ、勾配値の大きな違いなど、多基準最適化に特有の問題があります。この要因の悪影響を最小限に抑えるために、メソッドの作成者は、マルチタスク強化学習環境用に設計されたConflict-Averse Gradient Descent(CAGrad) 勾配を使用することを提案しています。この方法は、多目的最適化の上記の問題を軽減することを目的としています。基本的な考え方は、マルチタスクの目的関数の勾配を、個々のタスクごとの勾配の加重和で置き換えることです。これをおこなうには、次の最適化問題を解決します。
![]()
ここで、dは更新ベクトル、
g₀は平均勾配、
сは範囲 [0, 1) の収束率係数です。
この最適化問題を解決すると、最適化に対する各コンポーネントの影響を考慮し、各ステップでの最悪の推定値を改善することに重点を置くことができます。
2.MQL5を使用した実装
2.1新しいモデルクラスの作成
SAC+DICEアルゴリズムに基づいて報酬関数分解のバージョンを実装します。アルゴリズム実装の特殊性により、前の記事で作成したCNet_SAC_DICEクラスからは継承しません。ただし、以前に開発されたものは引き続き使用します。CNet_SAC_DICE と同様の CNet_SAC_D_DICEクラスを作成します。新しいクラス構造体を以下に示します。
class CNet_SAC_D_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; vector<float> fLambda; vector<float> fLambda_m; vector<float> fLambda_v; int iLatentLayer; float fCAGrad_C; int iCAGrad_Iters; int iUpdateDelay; int iUpdateDelayCount; //--- float fLoss1; float fLoss2; vector<float> fZeta; vector<float> fQWeights; //--- vector<float> GetLogProbability(CBufferFloat *Actions); vector<float> CAGrad(vector<float> &grad); public: //--- CNet_SAC_D_DICE(void); ~CNet_SAC_D_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } virtual bool TargetsUpdate(float tau); //--- virtual void SetQWeights(vector<float> &weights) { fQWeights=weights; } virtual void SetCAGradC(float c) { fCAGrad_C=c; } virtual void SetLambda(vector<float> &lambda) { fLambda=lambda; fLambda_m=vector<float>::Zeros(lambda.Size()); fLambda_v=fLambda_m; } virtual void TargetsUpdateDelay(int delay) { iUpdateDelay=delay; iUpdateDelayCount=delay; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
提供されたクラス構造体内に借用したモデルオブジェクトが表示されます。ただし、ラグランジュ係数とその平均を格納する変数の代わりに、サイズが報酬関数の成分の数に等しいベクトルを使用します。ここでは、各コンポーネントの重み付け係数を保存するためにfQWeightsベクトルを追加します。fCAGrad_C変数を選択して、CAGradメソッドの収束率係数を記録します。
もちろん、これらの変更はクラスコンストラクタに反映されます。初期段階では、単位長のすべてのベクトルを初期化します。
CNet_SAC_D_DICE::CNet_SAC_D_DICE(void) : fLoss1(0), fLoss2(0), fCAGrad_C(0.5f), iCAGrad_Iters(15), iUpdateDelay(100), iUpdateDelayCount(100) { fLambda = vector<float>::Full(1, 1.0e-5f); fLambda_m = vector<float>::Zeros(1); fLambda_v = vector<float>::Zeros(1); fZeta = vector<float>::Zeros(1); fQWeights = vector<float>::Ones(1); }
クラスの初期化とネストされたモデルの作成方法は、過去の記事から大幅に変更することなく引き継がれました。変更はベクトルサイズのみにおこなわれています。
bool CNet_SAC_D_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; } //--- if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; } //--- if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; } //--- cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- cZeta.getResults(fZeta); ulong size = fZeta.Size(); fLambda = vector<float>::Full(size,1.0e-5f); fLambda_m = vector<float>::Zeros(size); fLambda_v = vector<float>::Zeros(size); fQWeights = vector<float>::Ones(size); iLatentLayer = latent_layer; //--- return true; }
ここでは、単一の値を使用して重みのfQWeightsベクトルを初期化していることにご注意ください。報酬関数が他の係数を提供する場合は、SetQWeightsメソッドを使用する必要があります。ただし、Createメソッドを使用してクラスが初期化された後に呼び出す必要があります。そうしないと、係数が単一の値で上書きされます。
競合回避型勾配降下アルゴリズムを別のCAGradメソッドに移動しました。このメソッドはパラメータで勾配のベクトルを受け取り、調整されたベクトルを返します。
まず、メソッド本体でいくつかの準備作業をおこなう必要があります。
- 勾配の平均値を決定します。
- 計算の安定性を向上させるために勾配をスケールします。
- ローカル変数とベクトルを準備します。
vector<float> CNet_SAC_D_DICE::CAGrad(vector<float> &grad) { matrix<float> GG = grad.Outer(grad); GG.ReplaceNan(0); if(MathAbs(GG).Sum() == 0) return grad; float scale = MathSqrt(GG.Diag() + 1.0e-4f).Mean(); GG = GG / MathPow(scale,2); vector<float> Gg = GG.Mean(1); float gg = Gg.Mean(); vector<float> w = vector<float>::Zeros(grad.Size()); float c = MathSqrt(gg + 1.0e-4f) * fCAGrad_C; vector<float> w_best = w; float obj_best = FLT_MAX; vector<float> moment = vector<float>::Zeros(w.Size());
準備作業が完了したら、最適化問題を解くサイクルを整えます。ループ本体では、勾配降下法を使用して最適な更新ベクトルを見つける問題を繰り返し解決します。
for(int i = 0; i < iCAGrad_Iters; i++) { vector<float> ww; w.Activation(ww,AF_SOFTMAX); float obj = ww.Dot(Gg) + c * MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f); if(MathAbs(obj) < obj_best) { obj_best = MathAbs(obj); w_best = w; } if(i < (iCAGrad_Iters - 1)) { float loss = -obj; vector<float> derev = Gg + GG.MatMul(ww) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2) + ww.MatMul(GG) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2); vector<float> delta = derev * loss; ulong size = delta.Size(); matrix<float> ident = matrix<float>::Identity(size, size); vector<float> ones = vector<float>::Ones(size); matrix<float> sm_der = ones.Outer(ww); sm_der = sm_der.Transpose() * (ident - sm_der); delta = sm_der.MatMul(delta); if(delta.Ptp() != 0) delta = delta / delta.Ptp(); moment = delta * 0.8f + moment * 0.5f; w += moment; if(w.Ptp() != 0) w = w / w.Ptp(); } }
ループの反復が完了した後、最適な重みを使用して誤差勾配を調整します。結果は呼び出し側プログラムに返されます。
w_best.Activation(w,AF_SOFTMAX); float gw_norm = MathSqrt(w.MatMul(GG).Dot(w) + 1.0e-4f); float lmbda = c / (gw_norm + 1.0e-4f); vector<float> result = ((w * lmbda + 1.0f / (float)grad.Size()) * grad) / (1 + MathPow(fCAGrad_C,2)); //--- return result; }
CNet_SAC_DICEクラスと同様に、訓練全体がCNet_SAC_D_DICE::Studyメソッドに配置されます。しかし、アプローチの統一性と外部の類似性にもかかわらず、メソッドのアルゴリズムと構造には多くの違いがあります。メソッドパラメータに最初の変更を加えました。ここでは、「reward」変数を、分解された報酬のRewardsベクトルに置き換えました。
さらに、ActionsLogProbab行動確率対数ベクトルを除外しました。ご存知のとおり、Soft Actor-Criticアルゴリズムは、エントロピーコンポーネントを報酬関数に含めて、エージェントに確率の低い行動を繰り返すよう促すために使用されます。報酬関数の分解により、コンポーネントごとに個別の要素が割り当てられます。したがって、確率対数はRewards分解報酬ベクトルにすでに存在しており、それらを別のベクトルに複製する必要はありません。
bool CNet_SAC_D_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau) { //--- if(!Actions) return false;
メソッド本体では、完了した行動の結果として得られるバッファへのポインタの関連性を確認します。これで、このメソッドの制御ブロックは終了です。
次の段階に進むと、モデルの訓練の過程で、目標モデルによるその後の状態の推定値がかなり大幅に不当に増加することが認識されたと言わなければなりません。このような推定値は実際の報酬を大幅に上回っており、環境の実際の報酬を考慮せずに、訓練されたモデルとその目標 コピーの相互適応につながりました。
この影響を最小限に抑えるために、初期段階で実際の累積報酬を使用してモデルを訓練することが決定されました。対象モデルの使用を完全に拒否することも悪影響を及ぼします。経験再生バッファでは、累積評価は訓練期間に制限されます。同様の状態や行動であっても、訓練セットの最後までの距離に応じて大きく異なる場合があります。この差は目標モデルによって平滑化されます。さらに、目標モデルは、現在の方策 行動に基づいて状態を推定するのに役立ちます。エージェントパラメータの更新の反復回数が増加するにつれて、現在の方策は経験再生バッファ内の方策とますます異なってきます。これは無視できません。ただし、適切な推定値を備えた目標モデルが必要です。したがって、メソッド操作には、目標モデルを使用する場合と使用しない場合の2つのモードが必要です。
メソッドのアルゴリズムを調整する際には、次の考慮事項に従ってください。
- 目標モデルを使用する必要がある場合、ユーザーはパラメータで将来の状態へのポインタを渡します。Rewardsベクトルには、現在の状態で実行された行動のみに対する分解された報酬が含まれます。
- 目標モデルの使用を拒否した後、ユーザーは将来の状態へのポインタを渡しません(パラメータ変数にはNULLが含まれます)。 報酬ベクトルには、累積的に分解された報酬が含まれます。
したがって、次に将来の状態へのポインタを確認し、必要に応じて、現在の方策に基づいて将来の状態での行動を決定します。さらに、状態と行動のペアを評価します。
if(!!NextState) if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
次に現状の保守方策をそのまま継承します。行動を置き換えて、DICEブロックモデルを介して直接パスを実行します。
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
次に、分布補正推定法ブロックモデルの損失関数の値を決定します。この手順については、前の記事で詳しく説明しました。目標モデルの使用を拒否した場合、将来の状態を評価するためのベクトルnext_nuにはゼロ値が入力されることを強調しておきます。
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cZeta.getResults(zeta); if(!!NextState) cTargetNu.getResults(next_nu); else next_nu = vector<float>::Zeros(nu.Size()); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); int shift = (int)(Rewards.Size() - log_prob.Size()); if(shift < 0) return false; float policy_ratio = 0; for(ulong i = 0; i < log_prob.Size(); i++) policy_ratio += log_prob[i] - Rewards[shift + i] / LogProbMultiplier; policy_ratio = MathExp(policy_ratio / log_prob.Size()); vector<float> bellman_residuals = (next_nu * discount + Rewards) * policy_ratio - nu; vector<float> zeta_loss = MathPow(zeta, 2.0f) / 2.0f - zeta * (MathAbs(bellman_residuals) - fLambda) ; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; vector<float> lambda_los = fLambda * (ones - zeta);
次に、Adam最適化手法を使用してラグランジュ係数のベクトルを更新します。
上で説明した CAGradメソッドを使用して誤差勾配のベクトルを修正することにご注意ください。ベクトル演算を使用すると、単純な変数を扱うのと同じくらい簡単にベクトルを扱うことができます。
調整した値を対応するベクトルに保存します。
vector<float> grad_lambda = CAGrad((ones - zeta) * (lambda_los * (-1.0f))); fLambda_m = fLambda_m * b1 + grad_lambda * (1 - b1); fLambda_v = fLambda_v * b2 + MathPow(grad_lambda, 2) * (1.0f - b2); fLambda += fLambda_m * lr / MathSqrt(fLambda_v + lr / 100.0f);
次のステップは、v、ξモデルパラメータを更新することです。これらの操作のアルゴリズムは変わりません。変数をベクトルに置き換えてベクトル演算を使用するだけです。
CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = CAGrad(nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) - nu)); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
CNet_SAC_D_DICE::CAGradメソッドの競合回避勾配降下アルゴリズムを使用して、誤差勾配のベクトルを必ず修正します。
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = CAGrad(zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1.0f)); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
この段階で、分布補正推定法ブロックのオブジェクトの操作を終了し、Criticモデルの訓練に進みます。まず、彼らの前方へのパスを実行します。Actorの前方通過はすでに実行済みです。
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
次のステップは、Criticsパラメータを更新するための基準値のベクトルを決定することです。ここには2つのニュアンスがあります。どちらも対象モデルに関するものです。まず、その後の状態と行動を評価するためにそれらを使用する必要性をテストします。これをおこなうために、システムのその後の状態へのポインタを確認します。
目標モデルを使用して後続の状態と行動のペアを評価する場合は、最小の累積スコアを持つ目標Criticを選択する必要があります。累積推定値は、報酬関数コンポーネントの重み付け係数のベクトルと、目標モデルのフォワードパスから取得された分解された予測報酬のベクトルを乗算することで簡単に取得できます。次に、最小推定値を選択し、選択したモデルの予測値のベクトルを保存するだけです。
後続の状態の評価を拒否すると、予測値のベクトルはゼロ値で埋められます。
vector<float> result; if(fZeta.CompareByDigits(vector<float>::Zeros(fZeta.Size()),8) == 0) fZeta = MathAbs(zeta); else fZeta = fZeta * 0.9f + MathAbs(zeta) * 0.1f; zeta = MathPow(MathAbs(zeta), 1.0f / 3.0f) / (MathPow(fZeta, 1.0f / 3.0f) * 10.0f); vector<float> target = vector<float>::Zeros(Rewards.Size()); if(!!NextState) { cTargetCritic1.getResults(target); cTargetCritic2.getResults(result); if(fQWeights.Dot(result) < fQWeights.Dot(target)) target = result; }
予測推定値を割引係数で調整し、現在の状態の報酬と合計します。
target = (target * discount + Rewards); ulong total = log_prob.Size(); for(ulong i = 0; i < total; i++) target[shift + i] = log_prob[i] * LogProbMultiplier;
結果のベクトルで、現在の方策の行動確率の対数を調整します。経験再生バッファに保存されている行動確率の対数は、すでに報酬ベクトルに含まれています。Criticが現在の方策を考慮して評価できるように訓練するために、それらの値を現在の方策の対数に置き換えます。
目標値を決定した後、最初のCriticの予測誤差とQ関数の各成分の誤差勾配を計算します。結果の勾配は、競合回避勾配降下アルゴリズムを使用して調整されます。
//--- update critic1 cCritic1.getResults(result); vector<float> loss = zeta * MathPow(result - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); vector<float> grad = CAGrad(loss * zeta * (target - result) * 2.0f);
修正された誤差勾配を対応するCritic1バッファに転送し、リバースモデルパスを実行します。
last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
ここでは、ソースデータの準備処理のブロックを調整するために、Actorの部分的なリバースパスも実行します。
2番目のCriticに対してもこの操作を繰り返します。
//--- update critic2 cCritic2.getResults(result); loss = zeta * MathPow(result - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss2, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); grad = CAGrad(loss * zeta * (target - result) * 2.0f); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
メソッドの次のブロックでは、方策を更新します。SAC+DICE アルゴリズムは、保守的と楽観的という2つのActor方策を訓練するために提供されることを思い出してください。まず、保守的な方策を更新します。このモデルではすでにフォワードパスを実行しています。
Actorを訓練するには、最小平均誤差のCriticを使用します。このようなモデルを定義し、そのモデルへのポインタをローカル変数に格納しましょう。
vector<float> mean; CNet *critic = NULL; if(fLoss1 <= fLoss2) { cCritic1.getResults(result); cCritic2.getResults(mean); critic = GetPointer(cCritic1); } else { cCritic1.getResults(mean); cCritic2.getResults(result); critic = GetPointer(cCritic2); }
ここでは各Criticの予想評価をアップロードしていきます。次に、式を使用してモデルのリバースパスの基準値を決定します。
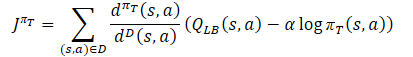
同時に、競合回避勾配降下法を使用して誤差勾配のベクトルを確実に修正します。
vector<float> var = MathAbs(mean - result) / 2.0f; mean += result; mean /= 2.0f; target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target - var * 2.5f) - result) + result;
次に、受信したデータをバッファに転送し、CriticとActorのリバースパスを実行するだけです。モデルの相互調整を防ぐため、操作を開始する前にクリティック訓練モードをオフにしてください。この場合、エラー勾配をActorに渡すためにのみ使用します。
CBufferFloat bTarget; bTarget.AssignArray(target); critic.TrainMode(false); if(!critic.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; }
保守的なActorとは対照的に、楽観的なActorのモデルはまだ使用していません。したがって、パラメータの更新を開始する前に、環境の現在の状態を直接渡す必要があります。
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { critic.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
保守的なActorの場合と同様に、楽観的な方策を考慮しながら、行動のベクトルを置き換え、確率の対数を取得します。
cActorExploer.GetLogProbs(log_prob);
楽観的方策方程式に従って、モデルのリバースパスの基準値のベクトルを決定します。
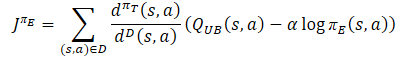
誤差勾配のベクトルは、競合回避勾配降下法を使用して修正されます。
target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target + var * 2.0f) - result) + result;
次に、モデルのリバースパスを実行し、Criticをモデル訓練モードに戻します。
bTarget.AssignArray(target); if(!critic.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; } critic.TrainMode(true);
次に、目標モデルを更新する必要があります。ここで、将来の状態の推定の歪みや、目標 コピーの値に対するCriticモデルの適応を防ぐために、さらに追加を加えました。
目標モデルのパラメータは、後続の状態の推定に使用されなくなった場合にのみ、反復ごとに更新されます。目標モデルが訓練で使用されている場合、その更新は遅れて実行されます。
したがって、最初にモデルを更新する必要があるかどうかを確認してから、操作を実行します。
if(!!NextState) { if(iUpdateDelayCount > 0) { iUpdateDelayCount--; return true; } iUpdateDelayCount = iUpdateDelay; } if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
メソッドのすべての反復が正常に完了した後、「true」の結果で作業を終了します。
報酬の分解とベクトルの使用により、ファイルの操作など、他の方法も変更されました。しかし、私たちは今それらにこだわるつもりはありません。これらと新しいクラスのすべてのメソッドの完全なコードは、添付ファイル「MQL5\Experts\SAC-D&DICE\Net_SAC_D_DICE.mqh」にあります。
2.2データストレージ構造体の調整
ここで、「MQL5\Experts\SAC-D&DICE\Trajectory.mqh」ファイルに注目してみましょう。以前はここでモデルのアーキテクチャを変更していました。今ではそれをほとんど変更せずにそのままにしておきます。Critic出力のニューロンの数を変更するだけです。それらは報酬関数を分解するのに十分である必要があります。ただし、その数を指定する前に、分解された報酬の構造を定義しましょう。
最初の要素のバランスの相対的な変化をインデックス「0」で示します。ご存知のとおり、私たちの主な目標は市場での利益を最大化することです。
インデックス「1」のパラメータには、資本変化の相対値が含まれます。負の値は、不要なドローダウンを示します。プラスは変動利益を示します。
オープンポジション不足に対するペナルティには、もう1つの要素が割り当てられます。
次に、行動確率の対数を加算します。ご存知のとおり、確率対数ベクトルの長さは行動 ベクトルと同じです。
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3... - LogProbs vector | //+------------------------------------------------------------------+
したがって、Critic結果のニューラル層のサイズは、行動の数より3要素大きくなります。
#define NActions 6 //Number of possible Actions #define NRewards 3+NActions //Number of rewards
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Actor ........ ........ //--- Critic critic.Clear(); //--- Input layer ........ ........ //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
報酬の分解により、経験再生バッファ内のデータ ストレージの構造も変更されました。ここで、報酬を設定するには変数が1つだけでは十分ではありません。データ配列が必要です。同時に、エントロピーコンポーネントを報酬配列に導入したため、これらの値をリセットするために別の配列は必要ありません。そこで、状態記述構造において、「log_prob」配列を「rewards」に置き換え、構造体のコピー方法やファイルの扱い方を調整します。
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float rewards[NRewards]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(rewards, obj.rewards); } };
SState状態構造体で報酬を記述するため、STrajectory軌道構造体でRewards配列を削除します。また、構造体メソッドに的を絞った変更を加えてみましょう。
struct STrajectory { SState States[Buffer_Size]; int Total; float DiscountFactor; bool CumCounted; //--- STrajectory(void); //--- bool Add(SState &state); void CumRevards(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
言及された構造体とそのメソッドの完全なコードは、添付ファイルで入手できます。
2.3モデル訓練EAの作成
モデル訓練EAに取り組む時期が来ました。訓練中は、以前と同様に3つのEAを使用します。
- Research:事例データベースの収集
- Study:モデルの訓練
- Test:得られた結果の確認
ResearchEAとTestEAでは、変更は環境状態記述構造の準備とOnTickメソッドの終了時に受け取る報酬にのみ影響しました。以前に報酬と罰金を合計しましたが、ここでは各コンポーネントを独自の配列要素に追加します。この場合、上記のデータ構造に準拠することが重要です。配列の各要素を入力する必要があります。コンポーネントの値が欠落している場合は、対応する配列要素に「0」を書き込みます。このアプローチにより、使用されるデータの有効性を確信できるようになります。
void OnTick() { //--- ........ ........ //--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f-bAccount[1]; vector<float> log_prob; Actor.GetLogProbs(log_prob); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) { sState.action[i] = ActorResult[i]; sState.rewards[i + 3] = log_prob[i] * LogProbMultiplier; } if(!Base.Add(sState)) ExpertRemove(); }
EAの完全なコードは添付ファイルにあります。
いつものように、モデルの訓練はStudy EAで実行されます。上で述べたように、モデルの訓練プロセスを2つの段階に分けます。
- 実際の累積報酬を伴う訓練(目標モデルなし)
- 目標モデルを使用した訓練
最初のステージの継続時間は定数によって決まります。
#define StartTargetIteration 20000
目標モデルを使用しない訓練は、Study EAを初めて起動するとき、つまり事前訓練されたモデルがない場合にのみ実行されることにご注意ください。
起動時に訓練EAが事前訓練されたモデルを読み込めた場合、最初の訓練反復から目標モデルが使用されます。
この制御は、EAのOnInitメソッドに実装されています。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; StartTargetIter = StartTargetIteration; } else StartTargetIter = 0; //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
ご覧のとおり、StartTargetIter変数は、新しいモデルの作成時にStartTargetIteration定数値を受け取ります。事前訓練されたモデルが読み込まれている場合は、遅延変数に「0」を格納します。
訓練の反復はTrainメソッド内に配置されます。メソッドの開始時に、通常どおり、経験再生バッファに保存された軌跡の数を決定し、EA外部パラメータで指定された反復数で訓練ループを配置します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
ループの本体では、保存された軌道の1つで状態を無作為にサンプリングします。その後、選択された状態に関する情報をデータバッファとベクターに渡します。
//--- bState.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- bActions.AssignArray(Buffer[tr].States[i].action); vector<float> rewards; rewards.Assign(Buffer[tr].States[i].rewards);
現段階では、選択された状態に関する情報のみが用意されていることにご注意ください。無駄な作業をおこなわないよう、必要な場合にのみその後の状態に関する情報を生成します。
現在の訓練反復とStartTargetIter変数の値を比較することで、目標モデルを使用してその後の状態を推定する必要性をテストします。反復回数がしきい値に達していない場合は、累積値で訓練を実行します。しかし、ここにはニュアンスがあります。データを経験再生バッファに保存するときに、すべての報酬コンポーネントの値の累積合計を計算しました。ただし、累積合計のないエントロピー成分が必要です。そこで、ループを設けて報酬関数のエントロピー成分のみから累積値を取り除きます。
//--- if(iter < StartTargetIter) { ulong start = rewards.Size() - bActions.Total(); for(ulong r = start; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, NULL, NULL, DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
次に、新しいクラスの訓練メソッドを呼び出します。ここでは後続の状態パラメータに「NULL」を指定します。
目的関数を使用するしきい値に達したら、まずシステムのその後の状態に関する情報を準備します。
else { //--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance == 0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
次に、報酬関数のすべてのコンポーネントの累積値を削除し、現在の状態の報酬だけを残します。
for(ulong r = 0; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, GetPointer(bNextState), GetPointer(bNextAccount), DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
クラスモデルの訓練メソッドを呼び出します。今回は、後続の状態データを持つオブジェクトを指定します。
ループの反復の最後に、ユーザーに通知するメッセージを出力し、次の反復に進みます。
//--- if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
すべてのループ反復が正常に完了したら、チャート上のコメントフィールドをクリアします。対象モデルを強制的に更新します。訓練結果をMetaTrader 5操作ログに表示し、EAのシャットダウンを開始します。
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); Net.TargetsUpdate(Tau); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
これで、モデル訓練EAでの作業は終了です。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。
3.検証
SAC+DICE アルゴリズムに基づいた報酬関数分解アプローチの実装オプションを提案し、実際におこなわれた作業の結果を評価できるようになりました。以前と同様に、モデルは2023年の最初の5か月間 EURUSD H1で訓練されました。すべての指標パラメータがデフォルトで使用されます。初期残高は10,000米ドルです。
モデルの訓練プロセスは反復的であり、経験蓄積バッファへのサンプルの収集とモデルパラメータの更新の段階が交互におこなわれます。
最初の段階では、無作為なパラメータが入力されたActorモデルを使用して、サンプルのプライマリデータベースを作成します。その結果、方策外の「状態 → 行動 → 新しい状態 → 報酬」データ セットを生成する一連の無作為パスが得られます。
これまでに検討したすべてのアルゴリズムとは異なり、この場合、エージェントの行動に対する環境報酬に関する分解データを収集します。
サンプルを収集した後、モデルの初期訓練を実行します。これを実現するには、「..\SAC-D&DICE\Study.mq5」EA を起動します。
目標モデルを使用しない最初の訓練中に、両方の Critics のエラーが減少するという安定した傾向が観察されました。ただし、目標モデルを使用してその後の状態を推定する場合、予測誤差の混沌とした(まれな)スパイクが観察され、その後、以前の誤差レベルにスムーズに戻ります。
第2段階では、パラメータを完全に検索して、ストラテジー テスターの最適化モードで訓練データ収集EAを再起動します。今回は、最初の段階で訓練された楽観的なActorをすべてのパスに使用します。個々のパスの結果のばらつきは、最初のデータ収集よりも低くなりますが、これはActorの方策の確率性によるものです。
サンプルの収集とモデルの訓練は、目的の結果が得られるまで数回繰り返されるか、サンプルの収集とモデルの訓練の次の反復で進歩が得られない場合は極小値に達します。
モデルの訓練中に、訓練期間中に少額の利益を生み出すことができるActor方策を取得しました。


利益は得られたものの、得られた方策は私たちが望むものとは程遠いものでした。残高グラフでは、かなり振幅の大きな波状の動きが見られます。28件の取引のうち、利益を上げて終了したのはわずか32%でした。利益を上げた取引の規模が損失を出した取引を上回ったため、合計利益が達成されました。取引の平均利益は平均損失の2倍を上回ります。取引ごとの最大利益は最大損失のほぼ3.5倍です。その結果、利益率は1よりわずかに高くなります。
EAは新しいデータでも利益を示しました。訓練期間後1か月で、モデルはほぼ20%の利益を受け取ることができました。これは訓練セットでの結果よりも高くなります。ただし、結果の統計は訓練セットのデータと同等です。テスト中におこなわれた取引は4件のみで、利益を上げて終了したのはそのうちの1件だけでした。しかし、この取引での利益は、損失が最も大きかった取引の12.8倍です。


訓練サンプルとその後の期間の結果を比較すると、新しいデータで収益性の波の始まりが観察されており、その後、予見可能な将来に低下が続く可能性があると想定できます。
全体として、このモデルは利益を生み出すことができますが、追加の最適化が必要です。
結論
この記事では、エージェントをより効率的に訓練できる報酬関数分解アプローチを紹介しました。報酬の分解により、ユーザーはエージェントによる決定に対するさまざまなコンポーネントの影響を分析できます。
MQL5を使用してアルゴリズムを実装し、報酬関数の分解を SAC+DICE メソッドに統合しました。
実装されたアルゴリズムをテストしているときに、訓練セット内と訓練セット外の両方で利益を生み出すことができるモデルを取得することができました。これは、アルゴリズムの一般化能力を示しています。
しかし、得られた結果は私たちが望むものとは程遠いものでした。同時に、報酬関数を分解することで、訓練結果に対する報酬関数の個々のコンポーネントの影響を分析することが可能になります。個々のコンポーネントを含めたり除外したりして、訓練結果への影響を評価することを試してみることをお勧めします。
リンク
- Conflict-Averse Gradient Descent for Multi-task Learning
- Value Function Decomposition for Iterative Design of Reinforcement Learning Agents
- ニューラルネットワークが簡単に(第52回):楽観的な研究と分布修正
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | Net_SAC_D_DICE.mqh | クラスライブラリ | モデルクラス |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13098
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ドミトリーに感謝します。テストできるnn EAを見つけたいと思って、あなたのセラープロフィールを クリックしました。
私はnnに関するudemyのMQL5コースを受講しました。私はあなたの一連の記事から始めています。