
Neuronale Netze leicht gemacht (Teil 48): Methoden zur Verringerung der Überschätzung von Q-Funktionswerten

Einführung
Im vorigen Artikel habe ich die Deep Deterministic Policy Gradient (DDPG)-Methode besprochen, die für das Training von Modellen in einem kontinuierlichen Aktionsraum entwickelt wurde. Dies ermöglicht es uns, unser Modelltraining auf die nächste Stufe zu heben. Unser letzter Agent ist daher nicht nur in der Lage, die kommende Richtung der Kursbewegung vorherzusagen, sondern erfüllt auch Funktionen des Kapital- und Risikomanagements. Sie gibt die optimale Größe der zu eröffnenden Position an sowie die Level von Stop-Loss und Take-Profit.
Allerdings hat die DDPG auch ihre Nachteile. Wie bei anderen Anhängern des Q-Learnings besteht auch hier das Problem, dass die Werte der Q-Funktion überschätzt werden. Während des Trainings können sich die Fehler häufen, was letztlich dazu führt, dass der Agent eine suboptimale Strategie erlernt.
Wie Sie sich vielleicht erinnern, lernt das Modell des Critic (Kritiker) in DDPG die Q-Funktion (Vorhersage der erwarteten Belohnung) auf der Grundlage der Ergebnisse der Interaktion mit der Umgebung, während das Agenten-Modell darauf trainiert wird, die erwartete Belohnung zu maximieren, und zwar nur auf der Grundlage der Ergebnisse der Bewertung der Aktionen durch den Critic. Folglich hat die Qualität der Ausbildung des Critics großen Einfluss auf die Verhaltensstrategie des Agenten und seine Fähigkeit, optimale Entscheidungen zu treffen.
1. Ansätze zum Abbau von Überbewertungen
Das Problem der Überschätzung der Q-Funktionswerte tritt beim Training verschiedener Modelle mit der DQN-Methode und ihren Ableitungen häufig auf. Sie ist sowohl für Modelle mit diskreten Aktionen als auch für die Lösung von Problemen in einem kontinuierlichen Raum von Aktionen charakteristisch. Die Ursachen dieses Phänomens und die Methoden zur Bekämpfung seiner Folgen können in jedem einzelnen Fall spezifisch sein. Daher ist ein integrierter Ansatz zur Lösung dieses Problems wichtig. Ein solcher Ansatz wurde in dem im Februar 2018 veröffentlichten Artikel „Addressing Function Approximation Error in Actor-Critic Methods“ vorgestellt. Es wird ein Algorithmus mit der Bezeichnung Twin Delayed Deep Deterministic policy gradient (TD3) vorgeschlagen. Der Algorithmus ist eine logische Fortsetzung von DDPG und führt einige Verbesserungen ein, die die Qualität der Modellschulung erhöhen.
Zunächst fügen die Autoren einen zweiten Critic (Kritiker) hinzu. Die Idee ist nicht neu und wurde bereits für diskrete Aktionsraummodelle verwendet. Die Autoren der Methode haben jedoch ihr Verständnis, ihre Vision und ihren Ansatz für die Verwendung des zweiten Critics eingebracht.
Die Idee ist, dass beide Critic mit zufälligen Parametern initialisiert und parallel mit denselben Daten trainiert werden. Sie werden mit unterschiedlichen Anfangsparametern initialisiert und beginnen ihr Training in unterschiedlichen Zuständen. Aber beide Critics sind auf die gleichen Daten trainiert, daher sollten sie sich auf das gleiche (wünschenswerte globale) Minimum zubewegen. Es ist ganz natürlich, dass die Ergebnisse ihrer Prognosen während des Trainings konvergieren. Sie werden jedoch aufgrund des Einflusses verschiedener Faktoren nicht identisch sein. Bei jedem von ihnen besteht das Problem der Überschätzung der Q-Funktion. Aber zu einem bestimmten Zeitpunkt wird ein Modell die Q-Funktion überbewerten, während das zweite sie unterbewerten wird. Selbst wenn beide Modelle die Q-Funktion überbewerten, ist der Fehler des einen Modells geringer als der des zweiten. Auf der Grundlage dieser Annahmen schlagen die Autoren der Methode vor, die minimale Vorhersage zu verwenden, um beide Critics zu trainieren. Auf diese Weise minimieren wir die Auswirkungen einer Überschätzung der Q-Funktion und die Ansammlung von Fehlern während des Lernprozesses.
Mathematisch kann diese Methode wie folgt dargestellt werden:
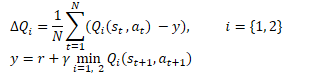
Ähnlich wie bei DDPG empfehlen die Autoren von TD3 eine sanfte Aktualisierung der Zielmodelle. Anhand von praktischen Beispielen zeigen die Autoren, dass die sanfte Aktualisierung von Zielmodellen zu einem stabileren Q-Funktions-Lernprozess mit geringerer Varianz der Ergebnisse führt. Gleichzeitig führt die Verwendung von stabileren (weniger aktualisierten) Zielen im Trainingsprozess zu einer Verringerung der Häufung des Fehlers bei der Neubewertung der Q-Funktion.
Die Ergebnisse der Experimente veranlassten die Autoren der Methode, die Politik des Actors (Akteur) seltener zu aktualisieren.
Wie Sie wissen, ist das Training neuronaler Netze ein iterativer Prozess, bei dem Fehler schrittweise reduziert werden. Die Trainingsgeschwindigkeit wird durch die Trainingskoeffizienten und den Algorithmus zur Aktualisierung der Parameter bestimmt. Dieser Ansatz ermöglicht die Mittelung des Fehlers in der Trainingsstichprobe und die Erstellung eines Modells, das dem untersuchten Prozess so nahe wie möglich kommt.
Die Ergebnisse des Actor-Modells sind Teil der Trainingsmenge des Critics. Eine seltene Aktualisierung der Actor-Politik ermöglicht es uns, die Stochastizität der Trainingsstichprobe für den Critic zu reduzieren und dadurch die Stabilität des Trainings zu erhöhen.
Das Training des Actors mit Daten aus der Auswertung der Ergebnisse eines genaueren Critic ermöglicht es uns, die Qualität der Arbeit des Actors zu verbessern und unnötige Aktualisierungsvorgänge mit fehlerhaften Ergebnissen zu vermeiden.
Darüber hinaus schlugen die Autoren des TD3-Algorithmus vor, den Trainingsprozess um eine Glättung der Zielfunktion zu ergänzen. Die Verwendung des Teilprozesses basiert auf der Annahme, dass ähnliche Handlungen zu ähnlichen Ergebnissen führen. Wir gehen davon aus, dass zwei leicht unterschiedliche Handlungen zum gleichen Ergebnis führen. Daher wird das Hinzufügen von einem geringfügigem Rauschen zu den Aktionen des Agenten die Belohnung durch die Umgebung nicht verändern. Dies ermöglicht es uns jedoch, dem Lernprozess des Critics eine gewisse Stochastik hinzuzufügen und seine Bewertungen in einem bestimmten Umfeld von Zielwerten zu glätten.
![]()
Diese Methode ermöglicht es, eine Art Regularisierung in das Training des Critics einzuführen und Spitzen zu glätten, die zu einer Überschätzung der Q-Funktionswerte führen.
Der Twin Delayed Deep Deterministic policy gradient (TD3) führt also 3 wesentliche Ergänzungen zum DDPG-Algorithmus ein:
- Paralleles Training von 2 Critics
- Verzögerung bei der Aktualisierung der Actor-Parametern
- Glättung der Zielfunktion.
Wie Sie sehen können, beziehen sich alle 3 Ergänzungen nur auf die Anordnung des Trainings und haben keinen Einfluss auf die Architektur der Modelle.
2. Implementierung mittels MQL5
Im praktischen Teil des Artikels werden wir die Implementierung des TD3-Algorithmus mit MQL5 betrachten. In dieser Implementierung verwenden wir nur 2 der 3 Zusätze. Aufgrund der Stochastizität des Finanzmarktes selbst habe ich auf eine Glättung der Zielfunktion verzichtet. Es ist unwahrscheinlich, dass wir in der gesamten Trainingsmenge 2 völlig identische Zustände finden.
Wir kehren auch zu der Erfahrung zurück, dass 3 EAs verwendet werden:
- Research — Sammeln von Beispielen Datenbank
- Study — Modellausbildung
- Test — Überprüfung der erzielten Ergebnisse.
Darüber hinaus nehmen wir Änderungen an der Interpretation der Modellergebnisse sowie am Handelsalgorithmus des EA vor.
2.1. Änderung des Handelsalgorithmus
Lassen Sie uns zunächst über die Änderung des Handelsalgorithmus sprechen. Ich habe beschlossen, von der ständigen Eröffnung neuer Positionen nach dem Prinzip „Open and Forget“ (eine Position wird auf der Grundlage der Ergebnisse einer Analyse der aktuellen Marktsituation eröffnet und nach einem Stop-Loss oder Take-Profit geschlossen) abzurücken. Stattdessen werden wir eine Position eröffnen und halten. Gleichzeitig schließen wir Ergänzungen und eine teilweise Schließung der Position nicht aus.
In diesem Paradigma ändern wir die Interpretation der Modellsignale. Wie zuvor liefert der Agent 6 Werte: Positionsgröße, Stop-Loss und Take-Profit in 2 Handelsrichtungen. Aber jetzt werden wir das erhaltene Volumen mit der aktuellen Position vergleichen und, falls nötig, die Position aufstocken oder teilweise schließen. Wir werden die Mittel mit Standardmitteln aufstocken. Um Positionen teilweise zu schließen, erstellen wir die Funktion ClosePartial.
Wir können einen Teil einer Position mit Standardmitteln schließen. Wir gehen jedoch davon aus, dass es mehrere Positionen gibt, die aufgrund von Aufstockungen eröffnet wurden. Daher besteht die Aufgabe der erstellten Funktion darin, Positionen nach dem FIFO-Verfahren (First In - First Out) für das Gesamtvolumen zu schließen.
In den Parametern erhält die Funktion die Positionsart und das Abschlussvolumen. Im Hauptteil der Funktion wird sofort das empfangene Volumen der Schlie?positionen überprüft, und wenn ein falscher Wert empfangen wird, wird die Funktion abgebrochen.
Als Nächstes führen wir einen Suchzyklus für alle offenen Stellen durch. In der Schleife überprüfen wir das Instrument und den Typ der offenen Position. Wenn wir die gewünschte Position gefunden haben, überprüfen wir ihr Volumen. Hier gibt es 2 Möglichkeiten:
- Das Positionsvolumen ist kleiner oder gleich dem Schließvolumen - wir schließen die Position vollständig und reduzieren das Schließvolumen um das Positionsvolumen.
- Das Positionsvolumen ist größer als das Schlie?volumen - wir schließen die Position teilweise und setzen das Schlie?volumen auf Null zurück.
Der Zyklus wird so lange wiederholt, bis alle offenen Positionen durchsucht sind oder bis das Volumen bis zum Abschluss größer als „0“ ist.
bool ClosePartial(ENUM_POSITION_TYPE type, double value) { if(value <= 0) return true; //--- for(int i = 0; (i < PositionsTotal() && value > 0); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; double pvalue = PositionGetDouble(POSITION_VOLUME); if(pvalue <= value) { if(Trade.PositionClose(PositionGetInteger(POSITION_TICKET))) { value -= pvalue; i--; } } else { if(Trade.PositionClosePartial(PositionGetInteger(POSITION_TICKET), value)) value = 0; } } //--- return (value <= 0); }
Wir haben uns für die Positionsgröße entschieden. Lassen Sie uns nun über die Level von Stop-Loss- und Take-Profit sprechen. Aus Erfahrung wissen wir, dass eine Verschiebung des Stop-Loss, wenn sich der Kurs gegen eine Position bewegt, eine schlechte Praxis ist, die nur zu einer Erhöhung des Risikos und der Verlustakkumulation führt. Daher werden wir Stop-Loss nur in Richtung eines Handels nachziehen. Take-Profit kann in beide Richtungen verschoben werden. Die Logik hier ist einfach. Wir hätten den Take-Profit zunächst konservativer ansetzen können, aber die Marktentwicklung deutet auf eine stärkere Bewegung hin. Daher können wir den Stop-Loss nachziehen und trotzdem die erwartete Gewinnspanne erhöhen. Wenn wir die erwartete Marktbewegung nicht erreichen, können wir die Gewinnschwelle senken. Wir nehmen nur das, was der Markt hergibt.
Um die beschriebene Funktionalität zu implementieren, erstellen wir die Funktion TrailPosition. In den Funktionsparametern geben wir den Positionstyp, den Kurs von Stop-Loss- und den Take-Profit an. Bitte beachten Sie, dass wir genau die Preise der Handelsniveaus angeben, und nicht Einrückungen in Punkten vom aktuellen Preis.
Wir überprüfen die angegebenen Ebenen im Funktionskörper nicht. Wir werden dies dem Nutzer überlassen und einen Hinweis auf die Notwendigkeit einer solchen Kontrolle auf der Seite des Hauptprogramms anbringen.
Als Nächstes führen wir einen Suchzyklus für alle offenen Stellen durch. Ähnlich wie bei der Funktion des teilweisen Schließens einer Position wird im Hauptteil der Schleife das Instrument und der Typ der offenen Position überprüft.
Wenn wir die gewünschte Position gefunden haben, speichern wir den aktuellen Stop-Loss und Take-Profit der Position in lokalen Variablen. Gleichzeitig setzen wir das Flag für die Positionsänderung auf „false“.
Danach überprüfen wir die Abweichung der Handelsniveaus der offenen Position von den in den Parametern ermittelten Werten. Die Prüfung, ob eine Änderung erforderlich ist, hängt von der Art der offenen Stelle ab. Daher führen wir diese Kontrolle im Körper der 'switch'-Anweisung mit einer Prüfung der Positionsart durch. Wenn es notwendig ist, mindestens eine der Handelsebenen zu ändern, ersetzen wir den entsprechenden Wert in der lokalen Variablen und ändern das Flag der Positionsänderung auf „true“.
Am Ende der Schleifenoperationen überprüfen wir den Wert des Positionsänderungs-Flags und aktualisieren gegebenenfalls seine Handelsstufen. Das Ergebnis der Operation wird in einer lokalen Variablen gespeichert.
Nachdem alle offenen Positionen durchsucht wurden, wird die Funktion beendet und das logische Ergebnis der durchgeführten Operationen an das aufrufende Programm zurückgegeben.
bool TrailPosition(ENUM_POSITION_TYPE type, double sl, double tp) { int total = PositionsTotal(); bool result = true; //--- for(int i = 0; i <total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; bool modify = false; double psl = PositionGetDouble(POSITION_SL); double ptp = PositionGetDouble(POSITION_TP); switch(type) { case POSITION_TYPE_BUY: if((sl - psl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; case POSITION_TYPE_SELL: if((psl - sl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; } if(modify) result = (Trade.PositionModify(PositionGetInteger(POSITION_TICKET), psl, ptp) && result); } //--- return result; }
Wenn wir über Veränderungen in der Interpretation der Signale des Akteurs sprechen, lohnt es sich, einen weiteren Punkt zu beachten. Zuvor haben wir LReLU als Aktivierungsfunktion für die Ausgabe des Akteurs verwendet. Dies ermöglicht es uns, bei den oberen Werten unbegrenzte Ergebnisse zu erzielen. Sie ermöglicht es uns auch, ein negatives Ergebnis anzuzeigen, das wir als No-Deal-Signal betrachten. Im Paradigma der aktuellen Interpretation von Actor-Signalen haben wir beschlossen, die Aktivierungsfunktion zu einem Sigmoid mit einem Bereich von 0 bis 1 zu ändern. Als Handelsvolumen sind wir mit diesen Werten durchaus zufrieden. Dasselbe kann man nicht über die Handelsstufen sagen. Um die Werte der Handelsniveaus zu entschlüsseln, führen wir 2 Konstanten ein, die die maximale Größe des Abstands des Stop-Loss‘ und des Take-Profits vom Preis bestimmen. Multipliziert man diese Konstanten mit den entsprechenden Daten des Actors, so erhält man die Handelsstufen in Punkten vom aktuellen Kurs.
#define MaxSL 1000 #define MaxTP 1000
In allen anderen Aspekten ist die Architektur unserer Modelle gleich geblieben. Deshalb werde ich sie hier nicht beschreiben. Sie finden sie in der Anlage. Die Beschreibung der Modellarchitektur befindet sich wie immer in „TD3\Trajectory.mqh“, in der Funktion CreateDescriptions.
2.2. Aufbau eines EAs, der eine Beispieldatenbank erstellt
Nachdem wir nun die Prinzipien der Entschlüsselung von Actor-Signalen und die Grundlagen des Handelsalgorithmus festgelegt haben, können wir direkt mit der Arbeit an unseren Modell-Trainings-EAs beginnen.
Zunächst erstellen wir den EA „TD3\Research.mq5“, um eine Trainingsstichprobe von Beispielen zu erstellen. Die Umgebungsverträglichkeitsprüfung wurde auf der Grundlage von zuvor überprüften ähnlichen Umgebungsverträglichkeitsprüfungen erstellt. In diesem Artikel werden wir nur die Methode OnTick betrachten, die den oben beschriebenen Handelsalgorithmus implementiert. Ansonsten unterscheidet sich die neue EA-Version nicht wesentlich von den früheren Versionen.
Zu Beginn der Methode wird wie zuvor das Ereignis der Eröffnung einer neuen Kerze überprüft. Dann laden wir die historischen Daten der Preisbewegung des Symbols und die Parameter der analysierten Indikatoren herunter.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Wir übergeben die heruntergeladenen Daten an einen Puffer, der den aktuellen Zustand der Umgebung beschreibt.
MqlDateTime sTime; float atr = 0; State.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign); }
Der nächste Schritt besteht darin, einen Vektor zu erstellen, der den Kontostand abbildet.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance));
Wie wir sehen, ist die Aufbereitung der Ausgangsdaten ähnlich wie bei den zuvor besprochenen Ratgebern.
Als Nächstes übertragen wir die vorbereiteten Daten an den Eingang des Actorsmodells und führen einen Vorwärtsdurchlauf durch.
if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) return;
Wir speichern die Daten, die wir benötigen, beim nächsten Balken und erhalten das Ergebnis der Arbeit des Actors.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp;
Bitte beachten Sie, dass wir in diesem EA nur das Actorsmodell verwenden. Schließlich ist es der Actor, der die Handlung entsprechend der gelernten Politik (Strategie) ausführt. Beim Training des Modells werden wir Critic-Modelle verwenden.
Um die Untersuchung der Umgebung zu maximieren, fügen wir den Ergebnissen des Akteurs ein wenig Rauschen hinzu.
Hier müssen wir uns daran erinnern, dass wir 2 Modi zum Starten des EA haben. In der Anfangsphase starten wir den EA ohne ein vortrainiertes Modell und initialisieren unseren Actor mit zufälligen Parametern. In diesem Modus müssen wir keine Rauschen hinzufügen, um die Umgebung zu erkunden. Schließlich wird ein ungeübtes Modell auch ohne Rauschen chaotische Werte liefern. Wenn wir jedoch ein vortrainiertes Modell laden, ermöglicht uns das Hinzufügen von Rauschen, die Umgebung der Entscheidungen des Akteurs zu erkunden.
Wir begrenzen die erhaltenen Werte auf den Bereich der akzeptablen Werte des Sigmoids, das wir als Aktivierungsfunktion am Ausgang des Actor-Modells verwenden.
if(AddSmooth) { int err = 0; for(ulong i = 0; i < temp.Size(); i++) temp[i] += (float)(temp[i] * Math::MathRandomNormal(0, 0.3, err)); temp.Clip(0.0f, 1.0f); }
Als Nächstes gehen wir zur Entschlüsselung des Ergebnisvektors des Akteurs über. Zunächst werden wir die wichtigsten Konstanten in lokalen Variablen speichern: das Mindestpositionsvolumen, den Schritt der Änderung des Positionsvolumens und die Mindesteinrückungen der Handelsstufen.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point();
Zunächst entschlüsseln wir die Indikatoren für Kaufpositionen. Das erste Element des Vektors wird mit dem Positionsvolumen identifiziert. Sie sollte größer oder gleich dem Mindestpositionsvolumen sein. Das zweite und dritte Element sind die Werte von Take-Profit bzw. Stop-Loss. Wir passen diese Elemente um die Konstanten für die maximale Gewinnmitnahme und den Stop-Loss an und multiplizieren sie außerdem mit dem Wert eines einzelnen Symbolpunkts. Das Ergebnis sollte ein Wert sein, der größer ist als die minimale Einrückung der Handelsstufen. Wenn mindestens ein Parameter die Bedingungen nicht erfüllt, schließen wir alle offenen Positionen in dieser Richtung.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Wenn die Ergebnisse des Akteurs uns empfehlen, eine Kaufposition zu eröffnen oder zu halten, normalisieren wir die Positionsgröße entsprechend den Anforderungen des Brokers für das analysierte Symbol. Wandeln wir die Handelsniveaus in konkrete Kurswerte um. Dann rufen wir die oben beschriebene Funktion zur Änderung offener Positionen auf, wobei wir die Positionsart POSITION_TYPE_BUY und die daraus resultierenden Kurswerte der Handelsstufen angeben.
else { double buy_lot = min_lot+MathRound((double)(temp[0]-min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Als nächstes gleichen wir die Größe der offenen Positionen mit den Empfehlungen des Akteurs ab. Wenn das Volumen der offenen Positionen größer ist als empfohlen, dann rufen wir die Funktion der teilweisen Schließung von Positionen auf. In den Parametern dieser Funktion geben wir die Positionsart POSITION_TYPE_BUY und die Differenz zwischen offenem und empfohlenem Volumen als Größe der zu schließenden Positionen an.
Wenn eine Aufstockung empfohlen wird, dann eröffnen wir eine zusätzliche Position für das fehlende Volumen. Gleichzeitig geben wir die empfohlenen Level für Stop-Loss- und Take-Profit an.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Die Parameter einer Verkaufsposition werden auf ähnliche Weise entschlüsselt.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot+MathRound((double)(temp[3]-min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Am Ende der Methode fügen wir die Daten dem Trajektorien-Array hinzu, um sie anschließend in der Beispieldatenbank zu speichern. Hier erzeugen wir zunächst eine Belohnung aus der Umgebung. Als Belohnung verwenden wir die relative Veränderung des Saldos, die wir zuvor im ersten Element des Vektors zur Beschreibung des Kontostands erfasst haben. Falls erforderlich, fügen wir dieser Belohnung eine Strafe für den Mangel an offenen Positionen hinzu.
Wir fügen der Zustandsbeschreibungsstruktur Vektoren für den aktuellen Zustand der Umgebung und die Ergebnisse des Actors hinzu. Wir haben die Daten zur Beschreibung des Kontozustands bereits eingegeben. Aufruf der Methode zum Hinzufügen des aktuellen Zustands zum Trajektorien-Array.
//--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; State.GetData(sState.state); if(!Base.Add(sState, reward)) ExpertRemove(); }
Andere EA-Funktionen wurden praktisch ohne Änderungen übernommen. Sie finden sie in der Anlage. Wir gehen nun zur nächsten Phase unserer Arbeit über.
2.3. Erstellen eines EAs für das Modelltraining
Das Modell wird in dem EA „TD3\Study.mq5“ trainiert. In diesem EA arrangieren wir den gesamten TD3-Algorithmus mit dem Training des Actors und 2 Critics.
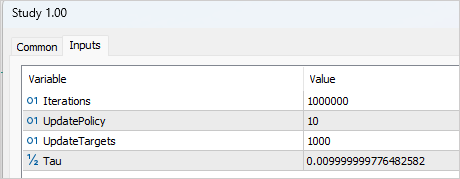
Um den Ausbildungsprozess zu gestalten, müssen mehrere externe Variablen hinzugefügt werden, die uns bei der Verwaltung der Ausbildung helfen. Wie üblich geben wir hier die Anzahl der Iterationen zur Aktualisierung der Modellparameter an. Im Zusammenhang mit der TD3-Methode bezieht sich dies auf das Training von Critic-Modellen.
input int Iterations = 1000000;
Um die Häufigkeit der Aktualisierungen der Actors anzugeben, erstellen wir die Variable UpdatePolicy, in der wir angeben, wie viele Aktualisierungen von Critic auf eine Aktualisierung der Actors entfallen.
input int UpdatePolicy = 3;
Darüber hinaus werden wir die Aktualisierungshäufigkeit der Zielmodelle und das Aktualisierungsverhältnis festlegen.
input int UpdateTargets = 100; input float Tau = 0.01f;
Im Bereich der globalen Variablen werden wir 6 Instanzen der Klasse des neuronalen Netzes deklarieren: Akteur, 2 Critic und Zielmodelle.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetActor; CNet TargetCritic1; CNet TargetCritic2;
Die Methode zur Initialisierung des EA ist fast identisch mit ähnlichen EAs aus früheren Artikeln, wobei die unterschiedliche Anzahl trainierter Modelle berücksichtigt wird. Sie finden sie in der Anlage.
Bei der Deinitialisierungsmethode werden jedoch die Zielmodelle aktualisiert und gespeichert, nicht die trainierten Modelle (wie zuvor). Zielmodelle sind eher statisch und weniger fehleranfällig.
void OnDeinit(const int reason) { //--- TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetActor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", TargetCritic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", TargetCritic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
Das Modelltraining wird in der Funktion Trainieren durchgeführt. Wir speichern im Funktionskörper die Anzahl der geladenen Trajektorien der Trainingsstichprobe in einer lokalen Variablen und ordnen den Trainingszyklus entsprechend der im externen Parameter angegebenen Anzahl von Iterationen an.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Im Schleifenkörper wählen wir nach dem Zufallsprinzip eine Trajektorie und einen Zustand aus der gewählten Trajektorie aus.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Zunächst führen wir einen Vorwärtsdurchlauf an den Zielmodellen durch, der es uns ermöglicht, den Vorhersagewert des nachfolgenden Zustands zu erhalten.
Theoretisch könnten wir die Modelle auch ohne die Zielfunktion trainieren. Schließlich könnten wir den Wert des nachfolgenden Zustands anhand der akkumulierten tatsächlichen nachfolgenden Belohnung bestimmen. Dieser Ansatz könnte geeignet sein, wenn es sich um den Endzustand der Umgebung handelt. Aber wir trainieren das Modell für die Finanzmärkte, die über den vorhersehbaren Zeithorizont unendlich sind. Daher haben ähnliche Zustände wie vor 1 oder 3 Monaten für uns den gleichen Wert, da wir diese Erfahrung auch in Zukunft nutzen wollen. Daher wird ein gut trainiertes Critic-Modell unabhängig von der Tiefe des Verlaufs vergleichbare Ergebnisse liefern.
Kehren wir zu unserem EA zurück. Wir übertragen Daten aus der Beispieldatenbank in Puffer, die den Zustand der Umgebung beschreiben, und bilden einen Vektor, der den Zustand des Kontos beschreibt. Bitte beachten Sie, dass wir die Daten nicht für den ausgewählten, sondern für den nachfolgenden Zustand erfassen.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Dann veranlassen wir einen direkten Durchlauf durch das Ziel-Actorsmodell.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!TargetActor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Als Nächstes führen wir einen direkten Durchlauf von 2 Ziel-Critic-Modellen durch. Die Quelldaten für beide Modelle sind das Zielmodell des Actors.
if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Aus den gewonnenen Daten lassen sich Zielwerte für das Training der Critic-Modelle ableiten.
Ich möchte Sie daran erinnern, dass jeder Critic nur einen Wert der vorausgesagten Aktionskosten unter den aktuellen Bedingungen liefert. Daher wird unser Zielwert auch eine Zahl sein.
Gemäß dem TD3-Algorithmus nehmen wir den Mindestwert aus den 2 Zielergebnissen der Critic-Modelle. Wir multiplizieren den resultierenden Wert mit dem Abzinsungsfaktor und addieren die tatsächliche Belohnung für die durchgeführte Aktion aus der Beispieldatenbank.
TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = DiscFactor * MathMin(reward, Result[0]) + (Buffer[tr].Revards[i] - Buffer[tr].Revards[i + 1]);
An diesem Punkt haben wir einen Zielwert für Critic. Der TD3-Algorithmus liefert nur einen Zielwert für 2 Critic-Modelle. Doch bevor wir zurückgehen, müssen wir einen Blick auf Critic werfen. Hier gibt es eine Nuance. Wie Sie wissen, sieht die Critic-Architektur keine primäre Datenverarbeitungseinheit vor. Diese Funktion wird vom Actor ausgeführt, und wir übertragen den latenten Zustand des Actors an den Critic als Ausgangsdaten zur Beschreibung des Zustands der Umgebung. Daher nehmen wir zunächst die Ausgangsdaten aus der Beispieldatenbank und führen einen Vorwärtsdurchlauf durch das Actorsmodell durch.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Dabei ist zu bedenken, dass der Actor höchstwahrscheinlich Aktionen zurückliefert, die sich von den in der Datenbank gespeicherten Beispielen während des Trainings unterscheiden. Die Belohnung entspricht jedoch nicht der gespeicherten Handlung. Daher entladen wir den latenten Zustand des Akteurs. Wir laden die perfekte Aktion aus der Beispieldatenbank. Und mit diesen Daten führen wir einen direkten Durchlauf der beiden Critics durch.
if(!Critic1.feedForward(Result,1,false, GetPointer(Actions)) || !Critic2.feedForward(Result,1,false, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Hier sollten wir noch eine Sache beachten. Theoretisch könnten wir den latenten Zustand des Actors in der Phase der Erfassung der Beispieldatenbank speichern und nun einfach die gespeicherten Daten verwenden. Allerdings ändern sich die Parameter aller neuronalen Schichten während des Modelltrainings. Folglich ändert sich auch der Datenvorverarbeitungsblock beim Training des Actors. Infolgedessen ändert sich die latente Darstellung desselben Umgebungszustands. Wenn wir den Critic mit falschen Ausgangsdaten trainieren, werden wir beim Training des Actor zu einem unvorhersehbaren Ergebnis kommen. Das wollen wir natürlich vermeiden. Um Critics zu trainieren, verwenden wir daher eine korrekte latente Repräsentation des Umgebungszustands zusammen mit abgeschlossenen Aktionen aus der Beispieldatenbank und der entsprechenden Belohnung.
Als Nächstes füllen wir den Zielwertpuffer und führen einen Rückwärtsdurchlauf durch beide Critics durch.
Result.Clear(); Result.Add(reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Kommen wir nun zum Training des Actors. Wie bereits im theoretischen Teil dieses Artikels erwähnt, werden die Parameter der Actore weniger häufig aktualisiert. Daher prüfen wir zunächst, ob dieses Verfahren in der aktuellen Iteration erforderlich ist.
//--- Policy study if(iter > 0 && (iter % UpdatePolicy) == 0) {
Wenn der Zeitpunkt gekommen ist, die Parameter des Akteurs zu aktualisieren, wählen wir nach dem Zufallsprinzip neue Ausgangsdaten aus, um die Objektivität zu wahren.
tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Als Nächstes führen wir einen Vorwärtsdurchlauf des Actors durch.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Dann führen wir einen Vorwärtsdurchlauf von einem Critic durch. Bitte beachten Sie, dass wir hier keine Daten aus der Beispieldatenbank verwenden. Der Vorwärtsdurchgang des Critics wird vollständig auf den neuen Ergebnissen des Actors durchgeführt, da es für uns wichtig ist, die aktuelle Modellpolitik zu bewerten.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Zur Aktualisierung der Actors-Parameter habe ich Critic1 verwendet. Nach meinen Beobachtungen ist die Wahl des Modells Critic in diesem Fall nicht so wichtig. Trotz der unterschiedlichen Bewertungen gaben beide Critic während des Tests identische Fehlergradientenwerte an den Actor zurück.
Das Training des Actors zielt darauf ab, die erwartete Belohnung zu maximieren. Wir nehmen das aktuelle Ergebnis der Handlungsbewertung des Critics und fügen ihm eine kleine positive Konstante hinzu. Wenn ich eine negative Bewertung der Maßnahmen erhielt, habe ich meine positive Konstante als Zielwert verwendet. Auf diese Weise versuchte ich, meinen Ausstieg aus dem Bereich der negativen Bewertungen zu beschleunigen.
Critic1.getResults(Result); float forecast = Result[0]; Result.Update(0, (forecast > 0 ? forecast + PoliticAdjust : PoliticAdjust));
Bei der Aktualisierung der Actor-Parameter wird das Critic-Modell nur als eine Art Verlustfunktion verwendet. Er erzeugt nur am Ausgang des Akteurs einen Fehlergradienten. In diesem Fall ändern sich die kritischen Parameter nicht. Zu diesem Zweck deaktivieren wir den Trainingsmodus des Critic vor dem Rückwärtsdurchgang. Nachdem wir den Fehlergradienten an den Actor übertragen haben, schalten wir den Critic wieder in den Trainingsmodus.
Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { Critic1.TrainMode(true); PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Critic1.TrainMode(true); }
Nachdem wir den Fehlergradienten vom Critic erhalten haben, führen wir einen Rückwärtsdurchlauf des Actor durch.
In dieser Phase haben wir die Schulung der Q-Funktion durch die Critic und die Vermittlung der Politik an die Actors organisiert. Alles, was wir tun müssen, ist eine sanfte Aktualisierung der Zielmodelle zu implementieren. Dies wurde in dem vorangegangenen Artikel ausführlich beschrieben. Hier wird lediglich geprüft, wann die Modelle aktualisiert werden und die entsprechenden Methoden für jedes Zielmodell aufgerufen.
//--- Update Target Nets if(iter > 0 && (iter % UpdateTargets) == 0) { TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Am Ende der Schleifeniteration informieren wir den Nutzer über das Training und zeigen die aktuellen Fehler der beiden Critic an. Wir zeigen keine Indikatoren für die Qualität des Actor-Trainings an, da der Fehler für dieses Modell nicht berechnet wird.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss der Schleifeniterationen löschen wir den Kommentarbereich und leiten den EA-Abschaltprozess ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Auf die Beschreibung des Algorithmus zum Testen des trainierten Modells „TD3\Test.mq5“ soll hier nicht näher eingegangen werden. Sein Code wiederholt fast vollständig den des EAs, der die Beispiel-Datenbank aufbaut. Ich habe nur die Hinzufügung von Rauschen zu den Ergebnissen der Arbeit des Akteurs ausgeschlossen, da wir die Qualität der Ausbildung des Modells bewerten wollen, was die Untersuchung der Umgebung ausschließt. Gleichzeitig habe ich den Block für die Erfassung der Trajektorie und die Aufzeichnung in der Beispieldatenbank belassen. So können wir erfolgreiche und erfolglose Durchgänge speichern. Dies ermöglicht es uns anschließend, beim nächsten Start des Trainingsprozesses eine Fehlerkorrektur vorzunehmen.
Den vollständigen Code aller verwendeten Programme finden Sie im Anhang.
3. Test
Gehen wir nun zum Training und zum Testen der erzielten Ergebnisse über. Wie üblich wurden die Modelle auf historischen Daten von EURUSD H1 von Januar bis Mai 2023 trainiert. Die Indikatorparameter und alle Hyperparameter wurden auf ihre Standardwerte gesetzt.
Das Training war ziemlich langwierig und iterativ. In der ersten Phase wurde eine Datenbank mit 200 Trajektorien erstellt. Für den ersten Trainingsprozess wurden 1.000.000 Iterationen durchgeführt. Die Politik des Actors wurde einmal nach jeweils 10 Iterationen der Aktualisierung der Parameter für die Critic aktualisiert. Eine sanfte Aktualisierung der Zielmodelle wurde nach jeweils 1.000 Iterationen der Aktualisierung des Critics durchgeführt.
Danach wurden der Beispieldatenbank weitere 50 Trajektorien hinzugefügt, und die zweite Stufe des Modelltrainings wurde eingeleitet. Gleichzeitig wurde die Anzahl der Iterationen vor der Aktualisierung des Actors- und des Zielmodells auf 3 bzw. 100 reduziert.
Nach etwa 5 Trainingszyklen (bei jedem Zyklus wurden 50 Trajektorien hinzugefügt) entstand ein Modell, das in der Lage war, auf Basis der Trainingsdaten Gewinne zu erzielen. Nach 5 Monaten der Trainingsstichprobe konnte das Modell, fast 10 % des Einkommens generieren. Dies ist nicht das beste Ergebnis. Es wurden 58 Transaktionen durchgeführt. Der Anteil der gewinnbringenden Transaktionen lag bei mageren 40 %. Gewinnfaktor - 1,05, Erholungsfaktor - 1,50. Der Gewinn wurde aufgrund der Größe der profitablen Positionen erzielt. Der durchschnittliche Gewinn aus einem Handel beträgt das 1,6-fache des durchschnittlichen Verlustes. Der maximale Gewinn beträgt das 3,5-fache des maximalen Verlustes aus einer Handelsoperation.
Es ist bemerkenswert, dass der Drawdown des Saldos fast 32 % beträgt, während das Kapital kaum 6 % überschreitet. Wie Sie auf dem Diagramm sehen können, beobachten wir Drawdowns in der Bilanz mit einer flachen oder sogar wachsenden Equity-Kurve. Dieser Effekt erklärt sich durch die gleichzeitige Öffnung von multidirektionalen Positionen. Wenn der Stop-Loss einer Verlustposition ausgelöst wird, kommt es zu einem Drawdown im Saldo. Gleichzeitig akkumuliert eine offene Position in der entgegengesetzten Richtung Gewinne, die sich in der Equity-Kurve widerspiegeln.


Wie wir uns erinnern, zeigte das Modell im vorangegangenen Artikel ein aussagekräftigeres Ergebnis mit dem Trainingsset, konnte es aber mit neuen Daten nicht wiederholen. Jetzt ist die Situation umgekehrt. Wir haben keine übermäßigen Gewinne mit dem Trainingsset erhalten, aber das Modell hat stabile Ergebnisse außerhalb des Trainingssets gezeigt. Beim Testen des Modells mit nachfolgenden Daten, die nicht im Trainingsset enthalten sind, sehen wir eine „kleinere Kopie“ des vorherigen Tests. Das Modell erhielt 2,5 % Gewinn in 1 Monat. Gewinnfaktor - 1,07, Erholungsfaktor - 1,16. Nur 27 % der gewinnbringenden Handelsgeschäfte, aber der durchschnittliche gewinnbringende Handel ist fast dreimal so hoch wie der durchschnittliche Verlusthandel. Der Drawdown von 32 % des Saldos und nur 2 % des Kapitals.


Schlussfolgerung
In diesem Artikel haben wir uns mit dem Algorithmus Twin Delayed Deep Deterministic policy gradient (TD3) vertraut gemacht. Die Autoren der Methode schlagen mehrere wichtige Verbesserungen des DDPG-Algorithmus vor, die die Effizienz der Methode und die Stabilität der Modellbildung erhöhen können.
Im Rahmen dieses Artikels haben wir diese Methode mit MQL5 implementiert und an historischen Daten getestet. Im Laufe des Trainingsprozesses wurde ein Modell entwickelt, das in der Lage war, nicht nur mit den Trainingsdaten, sondern auch mit den Erfahrungen aus den neuen Daten Gewinne zu erzielen. Es ist erwähnenswert, dass das Modell mit den neuen Daten Ergebnisse erzielte, die mit den Ergebnissen des Trainingssatzes vergleichbar sind. Die Ergebnisse sind nicht genau so, wie wir sie uns wünschen. Es gibt Dinge, an denen noch gearbeitet werden muss. Eines ist jedoch sicher: Der TD3-Algorithmus ermöglicht das Training eines Modells, das auch bei neuen Daten zuverlässig funktioniert.
Im Allgemeinen können wir den Algorithmus für weitere Forschungen zum Aufbau eines Modells für den realen Handel verwenden.
Liste der Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12892
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Entwicklung eines Wiedergabesystems — Marktsimulation (Teil 10): Nur echte Daten für das Replay verwenden
Entwicklung eines Wiedergabesystems — Marktsimulation (Teil 10): Nur echte Daten für das Replay verwenden
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Vielen Dank, Dimitry, für diese wunderbare Serie!
Beim Kompilieren von Trajectory.mqh ist ein Fehler in Zeile 274 "int total = ArraySize(Buffer);" aufgetreten und der Fehler lautet 'Buffer - undeclared identifier'. Ich habe in Ihrem vorherigen Artikel gesucht, aber in diesem Teil (48) ist die Funktion SaveTotalBase() das erste Mal, dass sie im Quellcode erwähnt wird. habe ich etwas verpasst?
Vielen Dank, Dimitry, für diese wunderbare Serie!
Beim Kompilieren von Trajectory.mqh ist ein Fehler in Zeile 274 "int total = ArraySize(Buffer);" aufgetreten und der Fehler lautet 'Buffer - undeclared identifier'. Ich habe in Ihrem vorherigen Artikel gesucht, aber in diesem Teil (48) ist die Funktion SaveTotalBase() das erste Mal, dass sie im Quellcode erwähnt wird. habe ich etwas verpasst?
Hallo, Sie brauchen Trajectory.mqh nicht zu kompilieren. Es ist nur eine Bibliothek zur Verwendung in anderen EA.