SOMFX1Builder
- Utilidades
-
Stanislav Korotky
 Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
New: - Versión: 1.1
- Actualizado: 20 noviembre 2021
Si te gusta el trading por patrones de velas y quieres reforzar este enfoque con tecnologías modernas, este script es para ti. De hecho, forma parte de una caja de herramientas que incluye un motor de red neuronal que implementa un mapa autoorganizado (SOM) para el reconocimiento y la predicción de patrones de velas, y le ofrece una opción para explorar los datos de entrada y los resultantes. La caja de herramientas contiene:
- SOMFX1Builder - este script para el entrenamiento de redes neuronales; construye un archivo con datos generalizados acerca de las figuras de precios más características que pueden ser usadas para la predicción de las siguientes barras, ya sea en una sub-ventana incorporada (usando el indicador SOMFX1), o directamente en el gráfico usando SOMFX1Predictor;
- SOMFX1 - el indicador para la predicción de patrones de precios y el análisis visual de una red neuronal entrenada, los datos de entrada y los resultantes (en una subventana independiente);
- SOMFX1Predictor - otro indicador para la predicción de patrones de precios justo en la ventana principal;
En resumen, todo el proceso de análisis de precios, entrenamiento de la red, reconocimiento de patrones y predicción supone los siguientes pasos:
- Construir una red neuronal mediante SOMFX1Builder;
- Analice el rendimiento de la red neuronal resultante mediante SOMFX1; si no está satisfecho, repita el paso 1 con nuevos ajustes; puede omitir este paso si lo desea;
- Utilice la red neuronal final para la predicción de patrones de precios mediante SOMFX1Predictor.
El paso 1 se describe en detalle a continuación. Puede encontrar más información sobre el análisis visual y la predicción en las páginas web de los indicadores correspondientes.
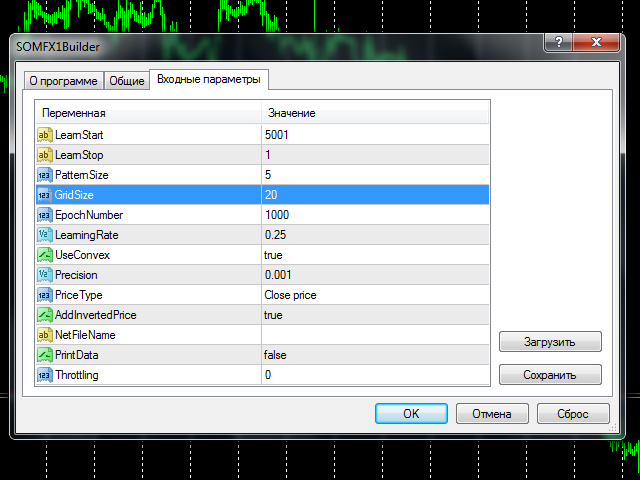
Para comenzar a entrenar debe elegir el número de barras en la historia para entrenar( parámetrosLearnStart y LearnStop ), el número de barras en un solo patrón(PatternSize), el tamaño del mapa(GridSize), el número de ciclos de aprendizaje(EpochNumber). Algunos otros parámetros también pueden afectar al proceso de aprendizaje, puede encontrar todos los detalles más abajo, en la sección "Parámetros".
El aprendizaje puede llevar un tiempo considerable, dependiendo de los parámetros dados. Cuanto mayor sea el número de compases procesados, más tardará en finalizar el proceso. El tamaño del patrón, el tamaño del mapa y el número de épocas funcionan de forma similar. Por ejemplo, el entrenamiento en 5000 barras con el mapa de 10*10 de tamaño puede llevar varios minutos en un PC medio. Todo este tiempo la carga del núcleo de la CPU es máxima, y el terminal puede ralentizarse, si su PC no tiene un par de núcleos. Debería elegir un momento para el entrenamiento en el que no espere una negociación activa, o podría utilizar los fines de semana. Esto es especialmente importante porque el proceso de entrenamiento normalmente necesita cierta optimización y por lo tanto debe repetirse varias veces antes de obtener resultados óptimos. ¿Por qué? Encontrará la respuesta más abajo, en la sección "Elegir los parámetros óptimos".
Antes de empezar a leer las siguientes secciones, puede que le interese leer la sección "Cómo funciona" de la página de SOMFX1 con una visión general de los principios de las redes neuronales.
Parámetros
- LearnStart - número de una barra en la historia, donde comienzan los datos de entrenamiento, o una fecha y hora exacta de la barra (en el formato "AAAA.MM.DD HH:MM"); este parámetro es una cadena, que le permite introducir un número o una fecha; tenga en cuenta que los números de barra cambian cada vez que se forma una nueva barra, por lo que si utilizó el valor 1000 ayer, la barra 1000 de hoy será probablemente otra (excepto en el caso de que utilice barras semanales); durante el proceso de entrenamiento esto no es importante porque todos los datos de entrenamiento se recogen justo antes del inicio y no se cambian después; valor por defecto - 5001;
- LearnStop - número de una barra en la historia, donde los datos de entrenamiento terminan, o una fecha y hora exacta de la barra (en el formato "AAAA.MM.DD HH:MM"); este parámetro también es una cadena; LearnStart debería ser más antiguo que LearnStop; la diferencia entre LearnStart y LearnStop es el número de muestras (vectores de entrada) pasados a la red (más exactamente, es LearnStart-LearnStop-PatternSize); valor por defecto - 1 (excluyendo la última barra, normalmente inacabada);
- PatternSize - número de barras en un único patrón; es la longitud del vector de entrada (muestra de precios); después del entrenamiento, las primeras barras PatternSize-1 se utilizarán para predecir la siguiente barra; por ejemplo, si PatternSize es 5, se extraen patrones de 5 barras del flujo de precios durante el entrenamiento, y luego se utilizarán los inicios de 4 barras para estimar la barra 5 en cada momento; valores permitidos: 3 - 10; valor por defecto - 5;
- GridSize - dimensiones del mapa; es un número de celdas/unidades en los ejes X e Y; el número total de neuronas es GridSize*GridSize (mapa 2D); valores permitidos: 3 - 50, pero atención: los valores superiores a 20 implican un entrenamiento bastante largo con una alta carga de CPU; valor por defecto - 7 (aplicable para las primeras pruebas para acostumbrarse a las herramientas, pero lo más probable es que se requiera un valor mayor para tareas reales);
- EpochNumber - número de ciclos de aprendizaje a ejecutar; valor por defecto - 1000; el proceso de entrenamiento puede terminar antes, si se alcanza la Precisión; en cada época todas las muestras de entrada se introducen en la red;
- LearningRate - velocidad inicial de aprendizaje; valor por defecto - 0.25; puede utilizar el método de prueba y error para encontrar un valor óptimo en el rango 0.1 - 0.5;
- UseConvex - habilita/deshabilita el método de combinación convexa de inicialización de las entradas de las neuronas durante las primeras épocas; habilitarlo supone una mejor separación de patrones y se recomienda; valor por defecto - true;
- Precisión - un número flotante utilizado como umbral para detener el entrenamiento, cuando el error global de la red cambia menos que este número; valor por defecto - 0.001;
- PriceType - tipo de precio a utilizar en los patrones; valor por defecto - precio de cierre;
- AddInvertedPrice - habilita/deshabilita un modo, cuando los movimientos de precios invertidos se añaden a las muestras; esto puede ayudar a eliminar el sesgo de tendencia; valor por defecto - true; esto significa que el número de muestras se hace dos veces mayor:(LearnStart-LearnStop-PatternSize)*2;
- NetFileName - nombre del archivo para guardar la red resultante; valor por defecto - cadena vacía - significa que se construirá automáticamente un nombre de archivo especial; tiene la siguiente estructura: SOM-V-D-SYMBOL-TF-YYYYMMDDHHMM-YYYMMDDHHMM-P.candlemap, donde V - PatternSize, D - GridSize, SYMBOL - símbolo de trabajo actual, TF - timeframe actual, YYYYMMDDHHMM - LearnStart y LearnStop respectivamente; aunque haya especificado LearnStart y LearnStop como números, se transforman automáticamente en fecha y hora; P - PriceType; se recomienda dejar este parámetro en blanco, ya que SOMFX1 y SOMFX1Predictor analizan automáticamente los nombres de archivo autogenerados, por lo que no es necesario especificar manualmente todos los ajustes; de lo contrario, si indica su propio nombre de archivo, todos los ajustes utilizados para entrenar la red deberán duplicarse exactamente en los cuadros de diálogo de SOMFX1 y SOMFX1Predictor, y es importante convertir LearnStart y LearnStop en formato fecha/hora, ya que los números de barra son incoherentes;
- PrintData - activar/desactivar el registro de depuración; por defecto - false;
- Throttling - número de milisegundos para pausar el entrenamiento cada epoch; este parámetro le permite aliviar la carga de la CPU a expensas de un mayor tiempo necesario para que el proceso finalice; puede ayudar si su PC no es lo suficientemente potente y no quiere que el entrenamiento interfiera con otras tareas interactivas que esté realizando; valor por defecto - 0.
Elegir los parámetros óptimos
Las preguntas más importantes que debe plantearse antes de empezar el entrenamiento de la red son:
- ¿Cuántas barras introducir en la red?
- ¿Qué tamaño de patrón elegir?
- ¿Qué tamaño de red elegir?
Todas ellas están estrechamente relacionadas, y la decisión sobre una de las preguntas afecta a las demás.
Al aumentar la profundidad del historial utilizado para el muestreo, cabe esperar una mejor generalización de los patrones por parte de la red. Esto significa que cada patrón descubierto está respaldado por un mayor número de muestras, de modo que la red encuentra regularidades en los precios, no peculiaridades. Por otro lado, alimentar con demasiadas muestras a una red de un tamaño determinado puede provocar el efecto de que la generalización se convierta en promediación, de modo que choque diferentes patrones en una sola neurona. Esto ocurre porque la red tiene una "memoria" limitada, definida por su tamaño. Cuanto mayor es el tamaño, mayor es el número de muestras que puede procesar. Por desgracia, no existe una fórmula exacta para ello. La regla de humb es
donde N es el número de muestras y D son las dimensiones de la red(GridSize).
Por lo tanto, probablemente debería elegir el número de barras en función de su estrategia de negociación preferida. Entonces, teniendo el número, puede calcular el tamaño de red requerido. Por ejemplo, para el marco de tiempo H1, 5760 barras dan un año, lo que parece un horizonte suficientemente bueno para operar en H1, por lo que puede probar el número por defecto 5000. Con este número se puede obtener el tamaño 20 por la fórmula anterior. Tenga en cuenta que si establece AddInvertedPrice en true, el número de muestras aumentará dos veces, por lo que el tamaño también debe ajustarse. Si después de la red de entrenamiento se producen demasiados errores (esto puede validarse utilizando SOMFX1 o SOMFX1Predictor), puede considerar ampliar el tamaño del mapa o reducir el rango de datos de entrenamiento. PriceType también puede ser importante. De todos modos, si tiene conocimiento empírico de que un patrón de vela específico se produce 10 o más veces (en promedio) en un determinado período de tiempo, puede considerar este período como suficiente para el aprendizaje, ya que 10 muestras deberían ser suficientes para la generalización del patrón. Puede utilizar SOMFX1 para investigar cuántas muestras se asignan a cada neurona y cómo se distribuyen las muestras entre las neuronas.
Es posible considerar el problema desde el lado opuesto. El número de unidades de la red es el número máximo de patrones de precios posibles. Supongamos que el número de patrones de velas conocidos es de 50. Entonces el tamaño de la red debería ser de unos 7. El problema aquí es que no hay medios para "decirle" a la red que queremos reconocer exactamente estos 50 patrones y omitir todos los demás: la red aprenderá sobre todos los patrones disponibles en la serie de precios, de modo que los 50 patrones de velas conocidos serán una fracción de todos los patrones que la red intente aprender. Cuál es la fracción es, de nuevo, una cuestión abierta. Por eso suele ser necesario ejecutar el proceso de entrenamiento varias veces con diferentes ajustes y encontrar la mejor configuración.
Si consideramos los patrones clásicos de velas, muchos de ellos se construyen a partir de 3-4-5 velas. Para la red neuronal, 3 ó 4 barras pueden resultar insuficientes para separar correctamente los patrones. Por lo tanto, se recomienda establecer PatternSize en 5 o más. Un tamaño de patrón mayor aumentará los costes de cálculo.
PriceType está implícito para estar cerca, cuando hablamos de patrones de velas convencionales. La red neuronal permite reconocer patrones de precios formados por cualquier otro tipo de precio, como típico, alto o bajo. Es especialmente útil porque las series de precios del precio de cierre son muy irregulares, lo que "cuesta" más "memoria" a la red. En otras palabras, aprender el precio de cierre es mucho más difícil que aprender el precio típico, y requiere un mapa de mayor tamaño en el mismo rango de barras. Por tanto, cambiar el tipo de cercano a típico puede permitir reducir el tamaño del mapa o mejorar la precisión.
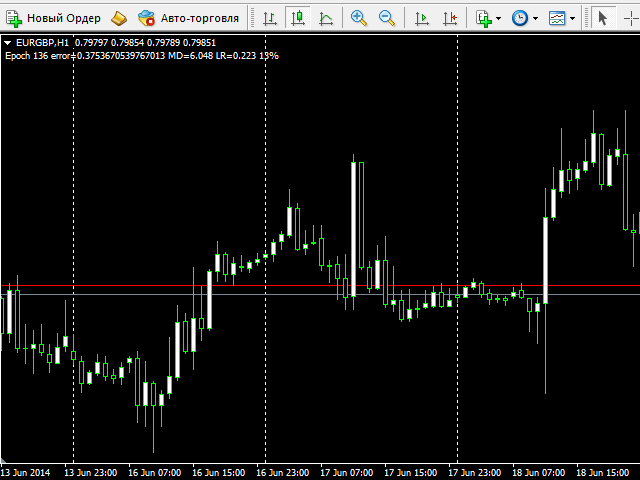
Modus operandi
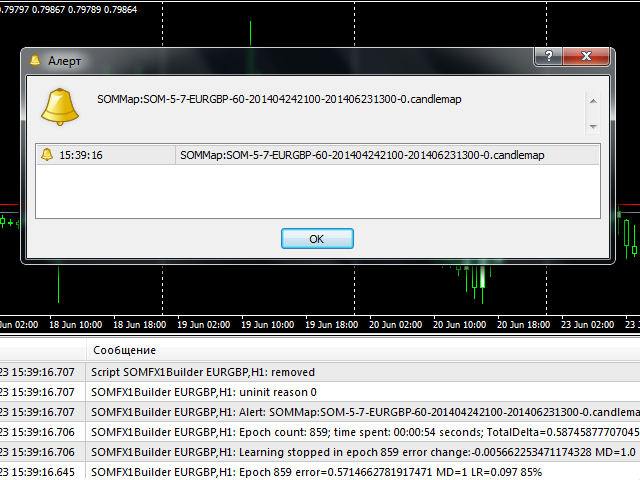
Tras configurar los parámetros y pulsar el botón OK, se inicia el proceso de entrenamiento. Durante el proceso, el script muestra el número de época actual, el error actual, la tasa de aprendizaje y el porcentaje de finalización en el comentario (en la esquina superior izquierda de la ventana). La misma información se imprime en el registro. Cuando el proceso finaliza, se lanza una alerta con el nombre del fichero de la red generada. El archivo se guarda en el subdirectorio Files de su carpeta MQL4. Si se trata de un nombre de archivo generado automáticamente( NetFileName estaba vacío), puede copiar y pegar el nombre de archivo justo desde el diálogo de alerta en el indicador SOMFX1 o SOMFX1Predict (debe pegarse en el parámetro NetFileName similar allí) y ejecutar la red. Si se ha utilizado un nombre de archivo personalizado, deberá copiar todos los parámetros en los indicadores, no sólo el nombre de archivo, sino también la región de aprendizaje, el tamaño del mapa, el tamaño del patrón, etc.
Es importante que el archivo de red no contenga datos de entrada - sólo contiene la red entrenada. La próxima vez que se cargue la red, el indicador SOMFX1 leerá de la configuración todos los parámetros necesarios para extraer de nuevo muestras de precios.
Antes de cada proceso de aprendizaje, la red se inicializa con pesos aleatorios. Esto significa que cada próxima ejecución del script con los mismos ajustes producirá un nuevo mapa que difiere del anterior.
Plazos recomendados: H1 y superiores.
El usuario no ha dejado ningún comentario para su valoración