SOMFX1Builder
- Utilities
-
Stanislav Korotky
 Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
New: - Version: 1.1
- Updated: 20 November 2021
If you like trading by candle patterns and want to reinforce this approach by modern technologies, this script is for you. In fact, it is a part of a toolbox, that includes a neural network engine implementing Self-Organizing Map (SOM) for candle patterns recognition, prediction, and provides you with an option to explore input and resulting data. The toolbox contains:
- SOMFX1Builder - this script for training neural networks; it builds a file with generalized data about most characteristic price figures which can be used for next bars prediction either in a built-in sub-window (using SOMFX1 indicator), or directly on the chart using SOMFX1Predictor;
- SOMFX1 - the indicator for price pattern prediction and visual analysis of a trained neural network, input and resulting data (in a separate sub-window);
- SOMFX1Predictor - another indicator for predicting price patterns just in the main window;
In brief, all the process of price analysis, network training, pattern recognition and prediction supposes the following steps:
- Build a neural network by SOMFX1Builder;
- Analyze the resulting neural network performance by means of SOMFX1; if not satisfied, repeat step 1 with new settings; you may skip this step if you wish;
- Use final neural network for price pattern prediction using SOMFX1Predictor.
The 1-st step is covered in details below. More information about visual analysis and prediction can be found on the web-pages of corresponding indicators.
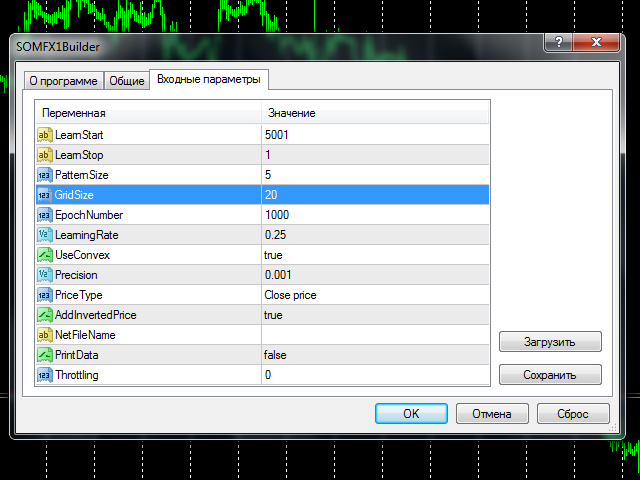
To start training you should choose number of bars in history to train at (LearnStart and LearnStop parameters), number of bars in a single pattern (PatternSize), the size of the map (GridSize), the number of learning cycles (EpochNumber). Some other parameters may also affect learning process, you may find all the details below, in "Parameters" section.
Learning may take considerable time, depending from the given parameters. The larger the number of bars being processed, the longer it takes to finish the process. Pattern size, map size and number of epochs - all work in the similar way. For example, training on 5000 bars with the map 10*10 in size may take several minutes on an average PC. All this time CPU core load is maximum, and terminal may slow down, if your PC doesn't have a couple of cores. You should choose a time for training when you do not expect active trading, or you could use weekends. This is especially important because the training process normally needs some optimization and thus should be repeated several times before you get optimal results. Why? Please find the answer below, in "Choosing optimal parameters" section.
Before you start reading the next sections, it may be worth reading "How it works" section on the SOMFX1 page with an overview of neural network principles.
Parameters
- LearnStart - number of a bar in history, where training data begins, or an exact date and time of the bar (in the format "YYYY.MM.DD HH:MM"); this parameter is a string, whick allows you to enter either a number or a date; note that bar numbers change every time a new bar is formed, so if you used value 1000 yesterday, today's 1000-th bar will be most likely other one (except for the case you use weekly bars); during training process this is not important because all training data is collected just before the start and is not changed afterwards; default value - 5001;
- LearnStop - number of a bar in history, where training data ends, or an exact date and time of the bar (in the format "YYYY.MM.DD HH:MM"); this parameter is also a string; LearnStart should be older than LearnStop; the difference between LearnStart and LearnStop is the number of samples (input vectors) passed to the network (more precisely, it's LearnStart-LearnStop-PatternSize); default value - 1 (excluding the last, usually unfinished bar);
- PatternSize - number of bars in a single pattern; this is the length of input vector (price sample); after the training, the first PatternSize-1 bars will be used to predict the next bar; for example, if PatternSize is 5, 5-bars patterns are extracted from price flow during training, and then 4-bars beginnings will be used to estimate 5-th bar on every moment; allowed values: 3 - 10; default value - 5;
- GridSize - dimentions of the map; this is a number of cells/units on X and Y axes; the total number of neurons are GridSize*GridSize (2D-map); allowed values: 3 - 50, but be warned: the values larger than 20 implies long enough training with high CPU load; default value - 7 (applicable for first tests to get accustomed with the tools, but will most likely require larger value for real tasks);
- EpochNumber - number of learning cycles to run; default value - 1000; the training process may finish earlier, if Precision is reached; in every epoch all input samples are feeded into the network;
- LearningRate - initial learning speed; default value - 0.25; you may use trial and error method to find an optimum value in the range 0.1 - 0.5;
- UseConvex - enable/disable the convex combination method of neurons' inputs initialization during first epochs; enabling it supposes better pattern separation and is recommended; default value - true;
- Precision - a float number used as a threshold to stop training, when overall network error changes less than this number; default value - 0.001;
- PriceType - a price type to use in the patterns; default value - close price;
- AddInvertedPrice - enable/disable a mode, when inverted price movements are added into the samples; this may help to eliminate trend bias; default value - true; this means that number of samples becomes twice larger: (LearnStart-LearnStop-PatternSize)*2;
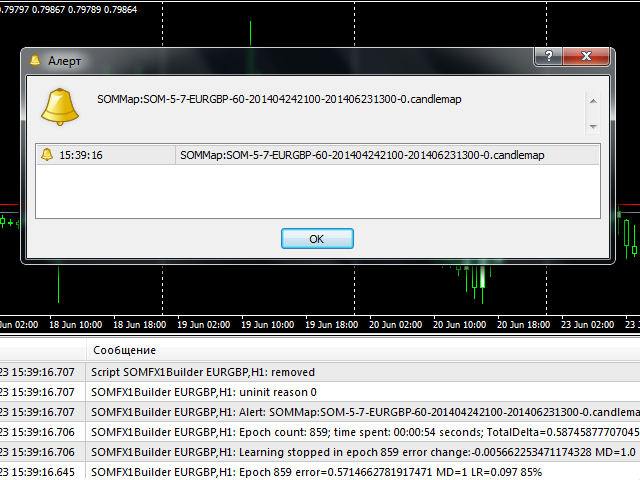
- NetFileName - a name of file to save resulting network; default value - empty string - means that a special filename will be constructed automatically; it has the following strucutre: SOM-V-D-SYMBOL-TF-YYYYMMDDHHMM-YYYYMMDDHHMM-P.candlemap, where V - PatternSize, D - GridSize, SYMBOL - current work symbol, TF - current timeframe, YYYYMMDDHHMM - LearnStart and LearnStop respectively; even if you specified LearnStart and LearnStop as numbers, they are automatically transformed into date and time; P - PriceType; it is recommended to leave this parameter blank, because the autogenerated filenames are parsed by SOMFX1 and SOMFX1Predictor automatically, so you have no need to specify all the settings manually; otherwise, if you give your own filename, all settings used for training the network must be exactly duplicated in SOMFX1 and SOMFX1Predictor dialogs, and it's important to convert LearnStart and LearnStop into date/time format because bar numbers are inconsistent;
- PrintData - enable/disable debug logging; default - false;
- Throttling - number of milliseconds to pause training every epoch; this parameter allows you to ease CPU load in the expense of longer time required for the process to finish; it may help if your PC is not powerful enough and you don't want the training to interfere with other interactive tasks you're performing; default value - 0.
Choosing optimal parameters
Most important questions to answer yourself before you start network training are:
- How many bars to feed into the network?
- Which pattern size to choose?
- Which size of the network to choose?
They all are closely related, and decision on one of the questions affects the others.
By increasing the depth of history used for sampling one could expect better generalization of patterns by the network. This means that every discovered pattern is backed by a larger number of samples, so the network finds regularities in prices, not peculiarities. On the other hand, feeding too many samples to a network of a given size may lead to the effect when generalization becomes averaging, so it clashes different patterns into a single neuron. This happens because network has a limited "memory", defined by its size. The larger the size the larger number of samples can be processed. Unfortunately there is no exact formula for this. The rule of humb is:
where N is the number of samples and D is the network dimensions (GridSize).
So, you should probably choose the number of bars on the basis of your preferred trading strategy. Then, having the number, you can calculate required network size. For example, for H1 timeframe, 5760 bars gives a year, which seems a good enough horizon for trading on H1, so you may try the default 5000 number. With this number one can get the size 20 by the formula above. Please note that setting AddInvertedPrice to true will increase the number of samples twice, so the size must be adjusted as well. If after the training network produces too many errors (this can be validated by using SOMFX1 or SOMFX1Predictor) you may consider either to enlarge the size of the map or to reduce the range of training data. PriceType may also be important. Anyway, if you have empirical knowledge that specific candle pattern occurs 10 or more times (in average) on some period of time, you may consider this period as sufficient for learning, because 10 samples should be enough for pattern generalization. You can use SOMFX1 for investigation how many samples mapped into every neuron and how evenly samples are distributed among neurons.
It's possible to consider the problem from the opposite side. Number of units in the network is the maximal number of possible price patterns. Let us assume that the number of known candle patterns is 50. Then the size of the network should be about 7. The problem here is that there are no means to "tell" the network that we want to recognize exactly these 50 patterns and omit all the others: the network will learn on all patterns available in the price series, so that the 50 known candle patterns will be a fraction of all patterns the network tries to learn. What is the fraction is - again - an open question. This is why it is usually required to run training process several times with different settings and find the best configuration.
If we consider classical candle patterns, many of them are built from 3-4-5 candles. For the neural network 3 or 4 bars may prove to be insufficient patterm size for proper pattern separation. So it is recommended to set PatternSize to 5 or more. Larger pattern size will increase computation costs.
PriceType is implied to be close, when we talk about conventional candle patterns. The neural network allows for recognition of price patterns formed by any other price type, such as typical, high or low. It is especially useful because price series of the close price are very raggy, which "costs" more "memory" for the network. In other words - learning close is much more difficult than learning typical price, and requires larger map size on the same bar range. So, changing the type from close to typical may allow one to reduce the map size or improve accuracy.
Modus operandi
After setting the parameters and pressing OK button the training process starts. During the process the script outputs current epoch number, current error, learning rate and percentage of completion in the comment (in the left upper corner of the window). The same information is printed into the log. When the process finished, an alert is fired with the filename of the generated network. The file is saved in the Files subdirectory of your MQL4 folder. If it's an automatically generated filename (NetFileName was empty), you can copy and paste the filename just from the alert dialog into SOMFX1 or SOMFX1Predict indicator (should be pasted into similar NetFileName parameter there) and run the network. If a custom filename was used, then you should copy all parameters into the indicators - not only the filename but learning region, map size, pattern size, etc.
It's important that the network file does not contain input data - it holds the trained network only. When the network is loaded next time, a SOMFX1 indicator reads from settings all required parameters to extract price samples anew.
Before every learning process the network is initialized by random weights. This means that every next run of the script with the same settings will produce a new map which differs from previous one.
Recommended timeframes: H1 and above.
User didn't leave any comment to the rating