SOMFX1Builder
- Utilitys
-
Stanislav Korotky
 Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
Trading is just my hobby. I'm working in IT industry. So developement of experts, indicators, and script is not a problem at all to me. Wide range of technologies are used: MQL4, MQL5, system and applied programming, web-services, neural networks and more.
New: - Version: 1.1
- Aktualisiert: 20 November 2021
Wenn Sie gerne mit Kerzenmustern handeln und diesen Ansatz durch moderne Technologien verstärken möchten, ist dieses Skript genau das Richtige für Sie. Es ist Teil einer Toolbox, die eine neuronale Netzwerk-Engine enthält, die eine selbstorganisierende Karte (SOM) für die Erkennung und Vorhersage von Kerzenmustern implementiert und Ihnen die Möglichkeit bietet, Eingabe- und Ergebnisdaten zu untersuchen. Die Toolbox enthält:
- SOMFX1Builder - dieses Skript für das Training neuronaler Netze; es erstellt eine Datei mit verallgemeinerten Daten über die meisten charakteristischen Preisfiguren, die für die Vorhersage der nächsten Takte entweder in einem eingebauten Unterfenster (unter Verwendung des SOMFX1-Indikators) oder direkt auf dem Chart unter Verwendung des SOMFX1Predictor verwendet werden können;
- SOMFX1 - der Indikator für die Vorhersage von Kursmustern und die visuelle Analyse eines trainierten neuronalen Netzes, der Eingabe- und Ergebnisdaten (in einem separaten Unterfenster);
- SOMFX1Predictor - ein weiterer Indikator für die Vorhersage von Kursmustern nur im Hauptfenster;
Kurz gesagt, der gesamte Prozess der Preisanalyse, des Netzwerktrainings, der Mustererkennung und der Vorhersage geht von den folgenden Schritten aus:
- Aufbau eines neuronalen Netzes mit SOMFX1Builder;
- Analysieren Sie die Leistung des resultierenden neuronalen Netzes mit Hilfe von SOMFX1; wenn Sie nicht zufrieden sind, wiederholen Sie Schritt 1 mit neuen Einstellungen; Sie können diesen Schritt auch überspringen;
- Verwenden Sie das endgültige neuronale Netz für die Vorhersage von Kursmustern mit SOMFX1Predictor.
Der 1. Schritt wird weiter unten im Detail beschrieben. Weitere Informationen zur visuellen Analyse und Vorhersage finden Sie auf den Webseiten der entsprechenden Indikatoren.
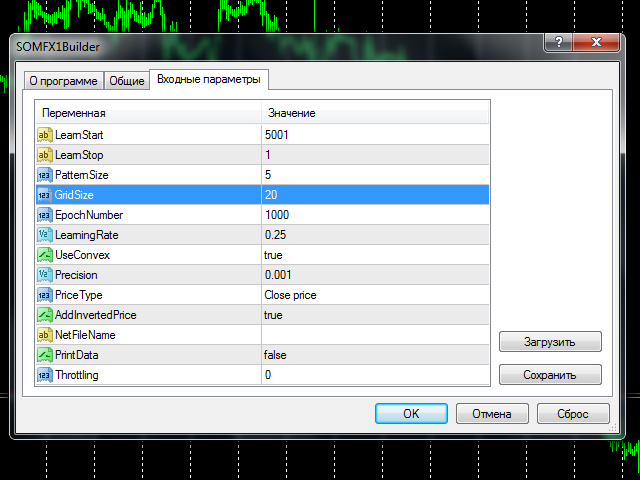
Um mit dem Training zu beginnen, sollten Sie die Anzahl der zu trainierenden Balken in der Geschichte( ParameterLearnStart und LearnStop ), die Anzahl der Balken in einem einzelnen Muster(PatternSize), die Größe der Karte(GridSize) und die Anzahl der Lernzyklen(EpochNumber) wählen. Einige andere Parameter können sich ebenfalls auf den Lernprozess auswirken, alle Details finden Sie unten im Abschnitt "Parameter".
Der Lernprozess kann je nach den angegebenen Parametern beträchtliche Zeit in Anspruch nehmen. Je größer die Anzahl der zu verarbeitenden Takte ist, desto länger dauert es, den Prozess zu beenden. Die Größe des Musters, die Größe der Karte und die Anzahl der Epochen funktionieren alle auf ähnliche Weise. Beispielsweise kann das Training für 5000 Balken mit einer 10*10 großen Karte auf einem durchschnittlichen PC mehrere Minuten dauern. Während dieser ganzen Zeit ist die CPU-Kernbelastung maximal, und das Terminal kann sich verlangsamen, wenn Ihr PC nicht über mehrere Kerne verfügt. Sie sollten eine Zeit für das Training wählen, zu der Sie keinen aktiven Handel erwarten, oder Sie könnten die Wochenenden nutzen. Dies ist besonders wichtig, da der Trainingsprozess normalerweise etwas optimiert werden muss und daher mehrmals wiederholt werden sollte, bevor Sie optimale Ergebnisse erzielen. Und warum? Die Antwort finden Sie weiter unten im Abschnitt "Auswahl der optimalen Parameter".
Bevor Sie mit dem Lesen der nächsten Abschnitte beginnen, lohnt es sich vielleicht, den Abschnitt "Wie es funktioniert" auf der SOMFX1-Seite zu lesen, der einen Überblick über die Prinzipien neuronaler Netze gibt.
Parameter
- LearnStart - Nummer eines Balkens in der Historie, an dem die Trainingsdaten beginnen, oder ein genaues Datum und eine genaue Uhrzeit des Balkens (im Format "JJJJ.MM.DD HH:MM"); dieser Parameter ist eine Zeichenkette, die es Ihnen ermöglicht, entweder eine Zahl oder ein Datum einzugeben; beachten Sie, dass sich die Balken-Nummern jedes Mal ändern, wenn ein neuer Balken gebildet wird; wenn Sie also gestern den Wert 1000 verwendet haben, wird der 1000-te Balken von heute höchstwahrscheinlich ein anderer sein (außer in dem Fall, dass Sie wöchentliche Balken verwenden); während des Trainingsprozesses ist dies nicht wichtig, da alle Trainingsdaten kurz vor dem Start gesammelt werden und danach nicht mehr geändert werden; Standardwert - 5001;
- LearnStop - Nummer des Balkens in der Historie, an dem die Trainingsdaten enden, oder das genaue Datum und die Uhrzeit des Balkens (im Format "JJJJ.MM.DD HH:MM"); dieser Parameter ist ebenfalls ein String; LearnStart sollte älter sein als LearnStop; der Unterschied zwischen LearnStart und LearnStop ist die Anzahl der Samples (Eingangsvektoren), die an das Netzwerk übergeben werden (genauer gesagt ist es LearnStart-LearnStop-PatternSize); Standardwert - 1 (mit Ausnahme des letzten, normalerweise unvollendeten Balkens);
- PatternSize - Anzahl der Balken in einem einzelnen Muster; dies ist die Länge des Eingangsvektors (Preisbeispiel); nach dem Training werden die ersten Balken von PatternSize-1 verwendet, um den nächsten Balken vorherzusagen; wenn PatternSize z.B. 5 ist, werden 5-Balken-Muster aus dem Preisfluss während des Trainings extrahiert, und dann werden 4-Balken-Anfänge verwendet, um den 5ten Balken zu jedem Zeitpunkt zu schätzen; erlaubte Werte: 3 - 10; Standardwert - 5;
- GridSize - Abmessungen der Karte; dies ist eine Anzahl von Zellen/Einheiten auf der X- und Y-Achse; die Gesamtzahl der Neuronen ist GridSize*GridSize (2D-Karte); erlaubte Werte: 3 - 50, aber Achtung: Werte über 20 bedeuten langes Training mit hoher CPU-Last; Standardwert - 7 (geeignet für erste Tests, um sich mit den Werkzeugen vertraut zu machen, aber für reale Aufgaben werden wahrscheinlich größere Werte benötigt);
- EpochNumber - Anzahl der auszuführenden Lernzyklen; Standardwert - 1000; der Trainingsprozess kann früher beendet werden, wenn die Präzision erreicht ist; in jeder Epoche werden alle Eingabeproben in das Netz eingespeist;
- LearningRate - anfängliche Lerngeschwindigkeit; Standardwert - 0.25; Sie können die Trial-and-Error-Methode verwenden, um einen optimalen Wert im Bereich von 0.1 - 0.5 zu finden;
- UseConvex - aktiviert/deaktiviert die konvexe Kombinationsmethode für die Initialisierung der Neuronen-Eingänge während der ersten Epochen; die Aktivierung dieser Methode führt zu einer besseren Mustertrennung und wird empfohlen; Standardwert - true;
- Precision - eine Fließkommazahl, die als Schwellenwert verwendet wird, um das Training zu stoppen, wenn der Gesamtfehler des Netzwerks kleiner als diese Zahl ist; Standardwert - 0,001;
- PriceType - ein Preistyp, der in den Mustern verwendet werden soll; Standardwert - Schlusskurs;
- AddInvertedPrice - aktiviert/deaktiviert einen Modus, in dem invertierte Preisbewegungen zu den Mustern hinzugefügt werden; dies kann helfen, Trendverzerrungen zu eliminieren; Standardwert - true; dies bedeutet, dass die Anzahl der Muster doppelt so groß wird:(LearnStart-LearnStop-PatternSize)*2;
- NetFileName - Name der Datei, in der das resultierende Netzwerk gespeichert werden soll; Standardwert - leerer String - bedeutet, dass ein spezieller Dateiname automatisch erstellt wird; er hat die folgende Struktur: SOM-V-D-SYMBOL-TF-YYYYMMDDHHMM-YYYYMMDDHHMM-P.candlemap, wobei V - PatternSize, D - GridSize, SYMBOL - aktuelles Arbeitssymbol, TF - aktueller Zeitrahmen, YYYYMMDDHHMM - LearnStart bzw. LearnStop; auch wenn Sie LearnStart und LearnStop als Zahlen angegeben haben, werden sie automatisch in Datum und Uhrzeit umgewandelt; P - PriceType; es wird empfohlen, diesen Parameter leer zu lassen, da die automatisch generierten Dateinamen von SOMFX1 und SOMFX1Predictor automatisch geparst werden, so dass Sie nicht alle Einstellungen manuell angeben müssen; andernfalls, wenn Sie Ihren eigenen Dateinamen angeben, müssen alle Einstellungen, die für das Training des Netzwerks verwendet werden, in den Dialogen von SOMFX1 und SOMFX1Predictor exakt dupliziert werden, und es ist wichtig, LearnStart und LearnStop in das Datums-/Zeitformat umzuwandeln, da Bar-Nummern inkonsistent sind;
- PrintData - Aktivieren/Deaktivieren der Debug-Protokollierung; Standard - false;
- Throttling - Anzahl der Millisekunden, um das Training in jeder Epoche zu unterbrechen; mit diesem Parameter können Sie die CPU-Belastung auf Kosten einer längeren Dauer des Prozesses verringern; dies kann hilfreich sein, wenn Ihr PC nicht leistungsfähig genug ist und Sie nicht wollen, dass das Training andere interaktive Aufgaben beeinträchtigt; Standardwert - 0.
Auswahl der optimalen Parameter
Die wichtigsten Fragen, die Sie sich selbst beantworten müssen, bevor Sie mit dem Netzwerktraining beginnen, sind:
- Wie viele Balken sollen in das Netz eingespeist werden?
- Welche Mustergröße ist zu wählen?
- Welche Größe des Netzes soll gewählt werden?
Alle diese Fragen sind eng miteinander verknüpft, und die Entscheidung über eine der Fragen hat Auswirkungen auf die anderen.
Wenn man die Tiefe der für das Sampling verwendeten Historie erhöht, kann man eine bessere Verallgemeinerung der Muster durch das Netz erwarten. Das bedeutet, dass jedes entdeckte Muster durch eine größere Anzahl von Stichproben gestützt wird, so dass das Netz Regelmäßigkeiten in den Preisen findet und keine Besonderheiten. Andererseits kann die Einspeisung von zu vielen Stichproben in ein Netz einer bestimmten Größe dazu führen, dass die Generalisierung zu einer Mittelwertbildung wird, so dass verschiedene Muster in einem einzigen Neuron zusammenkommen. Dies geschieht, weil ein Netzwerk einen begrenzten "Speicher" hat, der durch seine Größe definiert ist. Je größer die Größe, desto mehr Muster können verarbeitet werden. Leider gibt es dafür keine genaue Formel. Die Humb'sche Regel lautet:
wobei N die Anzahl der Stichproben und D die Netzgröße(GridSize) ist.
Sie sollten also die Anzahl der Balken auf der Grundlage der von Ihnen bevorzugten Handelsstrategie wählen. Mit dieser Zahl können Sie dann die erforderliche Netzwerkgröße berechnen. Für den H1-Zeitrahmen beispielsweise ergeben 5760 Balken ein Jahr, was für den H1-Handel ein ausreichender Zeithorizont zu sein scheint, so dass Sie die Standardzahl 5000 verwenden können. Mit dieser Zahl kann man die Größe 20 durch die obige Formel erhalten. Bitte beachten Sie, dass die Einstellung von AddInvertedPrice auf true die Anzahl der Stichproben verdoppelt, so dass die Größe ebenfalls angepasst werden muss. Wenn das Trainingsnetz zu viele Fehler produziert (dies kann mit SOMFX1 oder SOMFX1Predictor überprüft werden), können Sie entweder die Größe der Karte vergrößern oder den Bereich der Trainingsdaten reduzieren. Auch der Preistyp kann wichtig sein. Wie auch immer, wenn Sie empirisch wissen, dass ein bestimmtes Kerzenmuster 10 oder mehr Mal (im Durchschnitt) in einem bestimmten Zeitraum auftritt, können Sie diesen Zeitraum als ausreichend für das Lernen betrachten, da 10 Stichproben für die Verallgemeinerung des Musters ausreichend sein sollten. Sie können SOMFX1 verwenden, um zu untersuchen, wie viele Stichproben auf jedes Neuron abgebildet werden und wie gleichmäßig die Stichproben auf die Neuronen verteilt sind.
Man kann das Problem auch von der anderen Seite her betrachten. Die Anzahl der Einheiten im Netzwerk ist die maximale Anzahl der möglichen Preismuster. Nehmen wir an, dass die Anzahl der bekannten Kerzenmuster 50 beträgt. Dann sollte die Größe des Netzes etwa 7 betragen. Das Problem hierbei ist, dass es keine Möglichkeit gibt, dem Netz zu "sagen", dass wir genau diese 50 Muster erkennen und alle anderen auslassen wollen: Das Netz wird auf alle in der Preisreihe verfügbaren Muster lernen, so dass die 50 bekannten Kerzenmuster einen Bruchteil aller Muster ausmachen, die das Netz zu lernen versucht. Wie hoch dieser Bruchteil ist, ist - wieder einmal - eine offene Frage. Aus diesem Grund ist es in der Regel erforderlich, den Trainingsprozess mehrmals mit verschiedenen Einstellungen durchzuführen und die beste Konfiguration zu finden.
Wenn wir klassische Kerzenmuster betrachten, bestehen viele von ihnen aus 3-4-5 Kerzen. Für das neuronale Netzwerk können sich 3 oder 4 Takte als unzureichende Mustergröße für eine korrekte Mustertrennung erweisen. Es wird daher empfohlen, PatternSize auf 5 oder mehr zu setzen. Eine größere Mustergröße erhöht die Berechnungskosten.
PriceType wird als naheliegend angesehen, wenn es sich um herkömmliche Kerzenmuster handelt. Das neuronale Netz ermöglicht die Erkennung von Preismustern, die durch einen anderen Preistyp gebildet werden, wie z. B. typisch, hoch oder niedrig. Dies ist besonders nützlich, weil die Preisreihen des Schlusskurses sehr lumpig sind, was dem Netz mehr "Speicher" kostet. Mit anderen Worten: Das Erlernen des Schlusskurses ist viel schwieriger als das Erlernen des typischen Preises und erfordert eine größere Kartengröße für denselben Balkenbereich. Wenn man also den Typ von "nahe" zu "typisch" ändert, kann man die Größe der Karte verringern oder die Genauigkeit verbessern.
Arbeitsweise
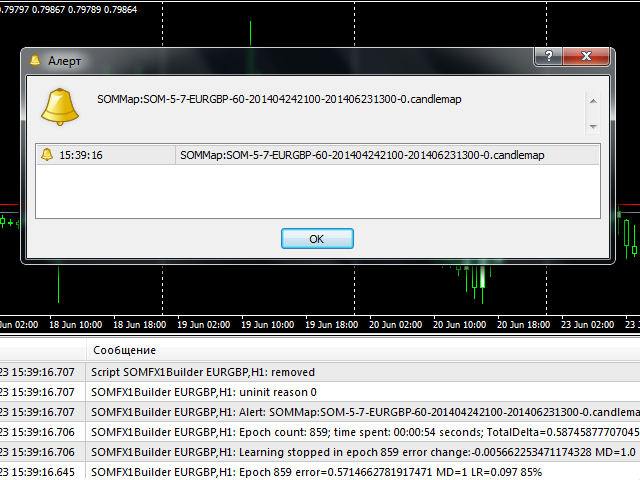
Nach dem Einstellen der Parameter und dem Drücken der Schaltfläche OK beginnt der Trainingsprozess. Während des Prozesses gibt das Skript die aktuelle Epochenzahl, den aktuellen Fehler, die Lernrate und den Prozentsatz der Fertigstellung im Kommentar (in der linken oberen Ecke des Fensters) aus. Die gleichen Informationen werden auch im Protokoll ausgedruckt. Wenn der Prozess abgeschlossen ist, wird eine Warnung mit dem Dateinamen des erzeugten Netzes ausgegeben. Die Datei wird im Unterverzeichnis Files Ihres MQL4-Ordners gespeichert. Wenn es sich um einen automatisch generierten Dateinamen handelt(NetFileName war leer), können Sie den Dateinamen einfach aus dem Warndialog in den SOMFX1- oder SOMFX1Predict-Indikator kopieren und einfügen (sollte dort in den ähnlichen NetFileName-Parameter eingefügt werden) und das Netzwerk ausführen. Wenn ein benutzerdefinierter Dateiname verwendet wurde, sollten Sie alle Parameter in die Indikatoren kopieren - nicht nur den Dateinamen, sondern auch Lernbereich, Kartengröße, Mustergröße usw.
Es ist wichtig, dass die Netzdatei keine Eingabedaten enthält - sie enthält nur das trainierte Netz. Wenn das Netzwerk das nächste Mal geladen wird, liest ein SOMFX1-Indikator alle erforderlichen Parameter aus den Einstellungen aus, um die Kursmuster neu zu extrahieren.
Vor jedem Lernprozess wird das Netzwerk mit Zufallsgewichten initialisiert. Das bedeutet, dass jeder nächste Durchlauf des Skripts mit den gleichen Einstellungen eine neue Karte erzeugt, die sich von der vorherigen unterscheidet.
Empfohlene Zeitrahmen: H1 und darüber.
Der Benutzer hat keinen Kommentar hinterlassen