Discusión sobre el artículo "Aplicando el método de Montecarlo al aprendizaje por refuerzo"
Me gustaría contribuir a las observaciones:
Beneficios de esta versión:
*************************************
1. A diferencia de las versiones anteriores, esta versión no opera todo el tiempo. Opera selectivamente cuando la señal es buena. Esto es una gran ventaja para satisfacer sus necesidades. Por lo demás, es una buena cosa))) ..
2. Se puede optimizar de forma rápida y sencilla.
3. El tamaño del modelo entrenador es pequeño, por lo que podemos entrenar big data
Las desventajas de esta versión:
*******************************************
1. Muchas veces tarda mucho tiempo en futuras pasadas, por lo que tenemos que detener manualmente el proceso de optimización.
2. 2. Por algunas razones no es tan fácil ejecutar las pruebas. Tengo que reiniciar mi terminal MT5 y aún así a veces no funciona.
Mis sugerencias de mejora:
*************************************
1. 1. Trate de utilizar al menos 4 a 5 funciones de entrada para la formación, tales como abrir, cerrar, alta, baja.
2.Trate de utilizar "MathMoments ()" funciones correctamente cuando se optimiza en la obtención de señales de trading:
h ttps:// www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3. 3. Intente realizar un entrenamiento iterativo diario o semanal.
Se trata de un resultado aleatorio.
4. Pruebe con varios periodos de tiempo.
¿Cómo podemos hacerlo mejor? :))))

- www.mql5.com
El método de Montecarlo es sin duda un método eficaz para estudiar los procesos aleatorios. Sin embargo, la aplicación de este método (así como de cualquier otro) debe tener en cuenta la naturaleza del proceso (para nosotros se trata de los mercados financieros).
El problema de la analítica moderna es que, hasta ahora, ni el AT tradicional ni otros métodos han sido capaces de revelar la estructura elemental de los movimientos de los precios del mercado (como un átomo en física), y las estructuras disponibles (patrones de AT, ondas de Elliott y otros) no son elementales, ya que no son continuas para el análisis (aparecen de forma ambigua o rara vez). Por lo tanto, el uso de métodos modernos es casi una búsqueda ciega del llamado "mejor modelo" por el método de la fuerza bruta (en este caso por el método de Monte Carlo).
Pero esto es un problema para la industria analítica en su conjunto. Y el autor, en el marco del método, mostró soluciones originales - ¡gracias por el trabajo!
Respeto al autor, para otro artículo interesante, para un enfoque abierto y constructivo a la MO, a pesar de la secreta, ratón jugueteo de otros participantes del tema y el zugunder de la administración:)
Específicamente sobre el tema - No entiendo muy bien el punto de Monte Carlo de tiro para encontrar objetivos, porque son casi inequívocamente determinista y se puede encontrar un orden de magnitud más rápido, de acuerdo a los vértices del zigzag o los valores de los mismos rendimientos.
En mi opinión, sería más racional aplicar este método a un problema mucho más incierto y multidimensional, como la selección y clasificación de predictores. Lo ideal sería que, al resolver este problema, los predictores se evaluaran en un complejo, y que la búsqueda y el entrenamiento alternativo de cada uno por separado descritos en el artículo se parecieran a un sistema de ecuaciones con una incógnita.
Respeto al autor, para otro artículo interesante, para un enfoque abierto y constructivo a la MO, a pesar de la secreta, ratón jugueteo de otros participantes del tema y la administración zugunder:)
Específicamente sobre el tema - No entiendo muy bien el punto de Monte Carlo de tiro para encontrar objetivos, porque son casi inequívocamente determinista y se puede encontrar un orden de magnitud más rápido, de acuerdo con los vértices del zigzag o los valores de los mismos rendimientos.
En mi opinión, sería más racional aplicar este método a un problema mucho más incierto y multidimensional, como la selección y clasificación de predictores. Idealmente, a la hora de resolver este problema, los predictores deberían evaluarse en un complejo, y la búsqueda y entrenamiento alternativo sobre cada uno por separado descrita en el artículo se parece a componer sistemas de ecuaciones con una incógnita.
Respeto al autor, para otro artículo interesante, para un enfoque abierto y constructivo a la MO, a pesar de la secreta, ratón jugueteo de otros participantes del tema y la administración zugunder:)
Específicamente sobre el tema - No entiendo muy bien el punto de Monte Carlo de tiro para encontrar objetivos, porque son casi inequívocamente determinista y se puede encontrar un orden de magnitud más rápido, de acuerdo con los vértices del zigzag o los valores de los mismos rendimientos.
En mi opinión, sería más racional aplicar este método a un problema mucho más incierto y multidimensional, como la selección y clasificación de predictores. Idealmente, a la hora de resolver este problema, los predictores deberían evaluarse en un complejo, y la búsqueda y el entrenamiento alternativo de cada uno por separado descritos en el artículo parecen sistemas de ecuaciones con una sola incógnita.
En cuanto a "inequívocamente determinista", es incorrecto, porque las cifras de AT y los "rendimientos" son cosas muy ambiguas y poco fiables de analizar.
Por ello, el autor no los utiliza, sino que experimenta con el método de Montecarlo.
Hola Maxim.
Una pregunta.
"shift_probab" y "regularización" Los valores utilizados son sólo para la optimización y NO en el curso del comercio en vivo. ¿Estoy en lo cierto?
¿O es necesario establecer los valores optimizados shift_probab y regularización en el gráfico después de cada optimización se ha completado para el comercio en vivo?
Gracias.
Hola, a través de Monte Carlo hay una enumeración aleatoria de objetivos, de acuerdo con todos los cánones de RL. Es decir, hay muchas estrategias (pasos), el agente busca la óptima, a través del mínimo error en el oos. La construcción de nuevas características también se implementa en una de las bibliotecas a través de MSUA (ver codobase). Este trabajo sólo implementa una búsqueda por fuerza bruta de las fichas existentes, sin construir otras nuevas. Véase el método de eliminación recursiva. Es decir, tanto las fichas como los objetivos se eliminan recursivamente. Más adelante puedo sugerir otras variantes, en realidad hay muchas. Pero las pruebas comparativas llevan mucho tiempo.
Hola, por supuesto, la selección aleatoria de acciones es el canon de la RL, es más, puede ser necesaria porque diferentes acciones del agente pueden cambiar el entorno, lo que genera un número de variantes que tiende a infinito, y por supuesto Monte Carlo bien puede aplicarse para optimizar la secuencia de dichas acciones.
Pero en nuestro caso, el entorno - cotizaciones del mercado no dependen de las acciones del agente, especialmente en la implementación considerada, donde se utilizan datos históricos, conocidos de antemano, y por tanto la elección de la secuencia de acciones (trades) del agente se puede realizar sin métodos estocásticos.
P.D. por ejemplo, es posible encontrar la secuencia objetivo de operaciones con el máximo beneficio posible mediante las cotizaciones https://www.mql5.com/es/code/9234.

- www.mql5.com
Hola Maxim.
Una pregunta.
"shift_probab" y "regularización" Los valores utilizados son sólo para la optimización y NO en el curso del comercio en vivo. ¿Estoy en lo cierto?
¿O es necesario establecer los valores optimizados shift_probab y regularización en el gráfico después de cada optimización se ha completado para el comercio en vivo?
Gracias.
Hola, por supuesto, la selección aleatoria de acciones es la canónica de la RL, es más, puede ser necesaria porque diferentes acciones del agente pueden cambiar el entorno, lo que genera un número de opciones tendente a infinito, y por supuesto Monte Carlo bien puede aplicarse para optimizar la secuencia de dichas acciones.
Pero en nuestro caso, el entorno - cotizaciones del mercado no dependen de las acciones del agente, especialmente en la implementación considerada, donde se utilizan datos históricos, conocidos de antemano, y por tanto la elección de la secuencia de acciones (trades) del agente puede realizarse sin métodos estocásticos.
P.D. por ejemplo, es posible encontrar la secuencia objetivo de operaciones con el máximo beneficio posible mediante las cotizaciones https://www.mql5.com/es/code/9234.
Lo de ser "inequívocamente determinista" es erróneo, ya que las cifras de AT y los "rendimientos" son cosas muy ambiguas y poco fiables de analizar.
Por lo tanto, el autor no las utiliza, sino que experimenta con el método Monte Carlo.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Aplicando el método de Montecarlo al aprendizaje por refuerzo:
Aplicación de Reinforcement learning para el desarrollo de expertos autodidactas. En el artículo anterior ya nos familiarizamos con el algoritmo de Random Decision Forest y escribimos un sencillo experto autodidacta basado en Reinforcement learning (aprendizaje por refuerzo). Se destacaron las principales ventajas de este enfoque, tales como la sencillez de escritura del algoritmo comercial y la alta velocidad de entrenamiento. El aprendizaje por refuerzo (en lo sucesivo AR) se implementa fácilmente en cualquier experto comercial y aumenta su velocidad de optimización.
Después de detener la optimización, solo tenemos que activar el modo de simulación única (puesto que el mejor modelo se guarda en el archivo y se carga solo él):
Vamos a retroceder en la historia hasta hace dos meses y mirar cómo funciona el modelo en los cuatro meses completos:
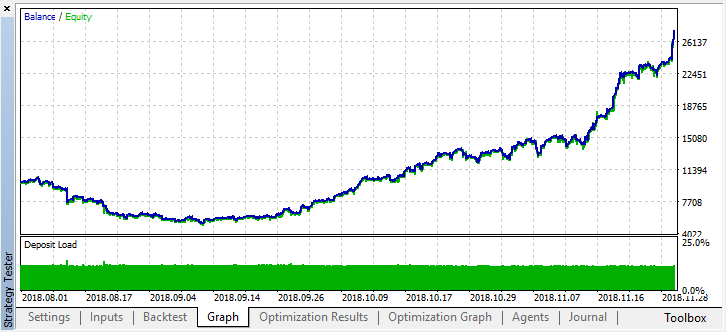
Podemos ver que el modelo obtenido ha aguantado dos meses más (septiembre casi al completo), pero en agosto se ha roto.Autor: Maxim Dmitrievsky