
Redes neuronales: así de sencillo (Parte 67): Utilizamos la experiencia adquirida para afrontar nuevos retos

Introducción
El aprendizaje por refuerzo se basa en maximizar las recompensas que obtenemos del entorno cuando interactuamos con él. Obviamente, en el proceso de entrenamiento será necesaria una interacción constante con el entorno, aunque con frecuencia se dan situaciones diferentes. Y para algunas tareas, pueden encontrarse distintas restricciones en dicha interacción con el entorno. En tales situaciones, los algoritmos de aprendizaje por refuerzo offline acuden en nuestra ayuda. Estos permiten entrenar los modelos a partir de un archivo limitado de trayectorias recogidas por la interacción previa con el entorno durante su periodo de disponibilidad.
Obviamente, el aprendizaje por refuerzo offline no está exento de inconvenientes. En concreto, el problema del aprendizaje sobre el entorno se agrava aún más por las limitaciones de la muestra de entrenamiento, que sencillamente no puede abarcar toda la diversidad del entorno. Esto resulta especialmente grave en entornos estocásticos complejos. En el artículo anterior nos familiarizamos con una de las soluciones a este problema (el método ExORL).
No obstante, a veces las limitaciones de las interacciones del entorno pueden ser de una importancia crítica. El proceso de exploración del entorno puede ir acompañado de recompensas positivas y negativas. Las recompensas negativas pueden resultar muy indeseables e ir acompañadas de pérdidas económicas o de algún otro tipo de pérdida no deseada que no podamos permitirnos. Pero las tareas rara vez "nacen de la nada": la mayoría de las veces, estamos optimizando un proceso existente. Y en nuestra "era de la tecnología de la información" casi siempre podemos encontrar experiencia en la interacción con el entorno objeto de estudio en el proceso de resolución de problemas como el que nos ocupa. Es posible usar datos de interacción con el entorno del mundo real que puedan cubrir hasta cierto punto el espacio de acciones y estados requerido. En el artículo "Real World Offline Reinforcement Learning with Realistic Data Source" se describen experimentos que utilizan estas experiencias para resolver nuevos problemas de control de robots reales. En su trabajo, los autores de este artículo proponen un nuevo marco de entrenamiento de modelos Real-ORL.
1. El marco Real-ORL
El aprendizaje por refuerzo offline (ORL) modela el entorno del proceso de toma de decisiones de Márkov. Esto supone el acceso a un conjunto de datos previamente generados en forma de trayectorias recogidas usando una política o mezcla de políticas de comportamiento. El objetivo de ORL es utilizar un conjunto de datos offline para entrenar casi la política π óptima. En general, no tenemos posibilidad de entrenar una política π* óptima debido a que la exploración es insuficiente y el conjunto de datos de entrenamiento es limitado. En este caso, nuestro objetivo será encontrar la mejor política que sea factible entrenar con el conjunto de datos disponible.
La mayoría de los algoritmos de aprendizaje por refuerzo offline incluyen alguna forma de regularización o conservadurismo que puede adoptar, entre otras, las siguientes formas:
- Regularización del gradiente de políticas;
- Programación dinámica aproximada;
- Entrenamiento usando un modelo de entorno.
Los autores del marco Real-ORL no ofrecen nuevos algoritmos de entrenamiento de modelos. En su artículo, investigan una serie de algoritmos ORL previamente representativos y evalúan su rendimiento con un robot físico en escenarios de uso realistas. Los autores del marco señalan que los algoritmos de aprendizaje analizados en el artículo están orientados sobre todo a la simulación, utilizando conjuntos de datos ideales, así como muestras independientes y simultáneas. Sin embargo, este planteamiento resulta incorrecto en el mundo estocástico real, donde las acciones van acompañadas de retrasos operativos, lo que generalmente limita el uso de políticas entrenadas con robots físicos. Al fin y al cabo, no está claro si los resultados de las pruebas comparativas simuladas o de la evaluación limitada de los equipos pueden generalizarse a los procesos del mundo real. El artículo "Real World Offline Reinforcement Learning with Realistic Data Source" pretende llenar este vacío. En él se presentan estudios empíricos de varios algoritmos de aprendizaje por refuerzo offline en tareas de aprendizaje del mundo real, centrándose en la generalización más allá del dominio de la muestra de entrenamiento.
A su vez, el aprendizaje por imitación ofrece un enfoque alternativo al aprendizaje de políticas de control para robótica. A diferencia del RL, que entrena las políticas optimizando las recompensas, el aprendizaje por imitación pretende repetir las demostraciones del experto, y en la mayoría de los casos explota enfoques de aprendizaje supervisado que excluyen la función de recompensa del proceso de aprendizaje. También resulta interesante la combinación del aprendizaje por refuerzo y el aprendizaje por imitación.
En su trabajo, los autores del marco Real-ORL usan un conjunto de datos offline formado por trayectorias de una política manual heurística. Las trayectorias se recogieron bajo la supervisión del experto y representan un conjunto de datos de calidad razonablemente alta. Los autores del método consideran el aprendizaje por imitación offline (la clonación de comportamientos, en particular) como el algoritmo de básico en su estudio empírico.
Con el fin de maximizar la objetividad de la evaluación de los métodos de entrenamiento, el artículo considera cuatro tareas de manipulación clásicas, que constituyen un conjunto de retos de manipulación habituales. Cada tarea se modela como un MDP con una única función de recompensa, y cada uno de los métodos de entrenamiento analizados se aplicará para resolver los 4 problemas, lo que pone a todos los algoritmos en condiciones de absoluta igualdad.
Como ya hemos mencionado, los datos de entrenamiento se recogen usando políticas desarrolladas bajo la supervisión de un experto. Básicamente, se han recogido las trayectorias exitosas en las cuatro tareas. Los autores del marco consideran que la recogida de trayectorias subóptimas o las trayectorias expertas distorsionadas por diversos ruidos no es algo aceptable en la robótica, ya que un comportamiento distorsionado o aleatorio resulta inseguro y perjudicial para el estado técnico del equipo. Al mismo tiempo, el uso de datos recogidos de diferentes tareas ofrece un entorno más realista para aplicar el aprendizaje por refuerzo offline en robots reales por tres razones:
- La recopilación de datos "aleatorios/de investigación" en un robot real de forma autónoma exigiría amplias restricciones de seguridad, supervisión y acompañamiento experto.
- Contratar a expertos para que registren esos datos aleatorios en grandes cantidades tiene menos sentido que usarlos para recopilar trayectorias significativas sobre un problema del mundo real.
- Desarrollar estrategias específicas para cada tarea y someter a pruebas de estrés la capacidad de ORL basándose en un conjunto de datos tan sólido resulta más viable que utilizar un conjunto de datos comprometido.
Los autores del marco Real-ORL, para evitar sesgos a favor de la tarea (o algoritmo), han congelado de antemano el conjunto de datos recogidos.
Para entrenar las políticas de los agentes en todas las tareas, los autores de Real-ORL dividen cada tarea en pasos más sencillos etiquetados con subobjetivos. El agente realiza pequeños pasos hacia los subobjetivos hasta que se cumplen algunos criterios específicos de la tarea. Las políticas entrenadas de este modo no han alcanzado los resultados teóricamente máximos posibles debido al ruido del controlador y al error de seguimiento. No obstante, completan la tarea con un alto porcentaje de éxito y tienen un rendimiento comparable al de las demostraciones humanas.
Los autores de Real-ORL han realizado experimentos utilizando más de 3 000 trayectorias de entrenamiento, más de 3 500 trayectorias de evaluación y un gasto superior a las 270 horas-hombre. Como resultado de la investigación, han llegado a las siguientes conclusiones:
- Para tareas fuera del dominio de aplicación, los algoritmos de aprendizaje por refuerzo podrían generalizarse a dominios de tareas con pocos datos y también a tareas dinámicas.
- El cambio en el rendimiento de ORL tras utilizar datos heterogéneos tiende a variar según los agentes, el diseño de la tarea y las características de los datos.
- Ciertas trayectorias heterogéneas e independientes de la tarea pueden ofrecer un soporte de datos superpuesto y posibilitar un mejor aprendizaje, permitiendo a los agentes ORL mejorar su rendimiento.
- El mejor agente para cada problema es el algoritmo ORL o la paridad entre ORL y BC. Las evaluaciones del artículo indican que, incluso en un régimen de datos ajeno al dominio de aplicación más realista para el mundo real, el aprendizaje por refuerzo offline resulta un enfoque eficaz.
A continuación le mostramos una visualización personalizada del marco Real-ORL.
2. Implementación usando MQL5
El artículo"Real World Offline Reinforcement Learning with Realistic Data Source" valida empíricamente la eficacia de los métodos de aprendizaje por refuerzo offline para resolver problemas reales. Pero lo que más llama la atención es el uso de datos sobre la resolución de problemas similares o parecidos para construir una política de Agente propia. En este caso, el único criterio para los datos es el entorno. Es decir, los datos deberán recopilarse como resultado de la interacción con el entorno que estamos analizando.
¿Y qué nos da eso? Como mínimo, obtendremos información abundante sobre el estudio del entorno, en nuestro caso los mercados financieros. Ya hemos hablado muchas veces de uno de los principales problemas del aprendizaje por refuerzo: la exploración del entorno. Y al mismo tiempo, siempre teníamos ante nosotros una enorme cantidad de información que no aprovechábamos, estamos hablando de las señales. En la siguiente captura de pantalla, hemos eliminado deliberadamente los autores y el nombre de las señales. En nuestro experimento, el único criterio para las señales será la presencia de transacciones en el segmento histórico del periodo de estudio para el instrumento financiero que nos interesa.

Entrenaremos los modelos en el marco temporal de los 7 primeros meses de 2023 del instrumento EURUSD. Seleccionaremos las señales según los criterios que siguen: pueden ser señales de pago o gratuitas. Tenga en cuenta que en las señales de pago una parte de la historia está oculta, pero son las últimas transacciones las que se ocultan. No obstante, nos interesa la historia que se encuentra al descubierto.
En la pestaña "Cuenta", comprobaremos si hay alguna transacción en el periodo de interés.
Y en la pestaña "Estadísticas" comprobaremos la disponibilidad de transacciones sobre el instrumento financiero que nos interesa. Dicho esto, no buscaremos señales que solo funcionen en el instrumento de interés. Más adelante eliminaremos las transacciones innecesarias.
Estoy de acuerdo en que se trata de un análisis bastante aproximado e indirecto, y que no garantiza la presencia de transacciones sobre el instrumento financiero analizado en el periodo histórico que nos interesa, pero la probabilidad de su presencia es bastante alta. Este tipo de análisis es bastante sencillo y fácil de hacer.
Así, cuando encontremos una señal adecuada, iremos a la pestaña "Historia de transacciones" de la señal y descargaremos un archivo csv con la historia de transacciones.

Tenga en cuenta que los archivos descargados deberán guardarse en la carpeta común de MetaTrader 5 "...\AppData\Roaming\ MetaQuotes\ Terminal\ Common\ Files\". Para facilitar su uso, hemos creado el subdirectorio "Señales" y hemos renombrado los archivos de todas las señales a "SignalX.csv", donde X será el número de serie de la historia de señales guardada.
Aquí conviene señalar que el marco Real-ORL considerado implica el uso de trayectorias seleccionadas como cierta experiencia de interacción con el entorno, y de ningún modo promete la clonación completa de las trayectorias. Por lo tanto, al seleccionar las trayectorias, no comprobaremos la correlación (ni ningún otro análisis estadístico) de las transacciones con los indicadores que estamos utilizando. Por la misma razón, no debemos esperar que el modelo entrenado repita completamente las acciones de la señal más rentable o de cualquier otra de las utilizadas.
De este modo hemos seleccionado 20 señales. Sin embargo, en su forma pura, no podemos usar los archivos csv resultantes para entrenar nuestros modelos. Debemos cotejar las transacciones con los datos históricos de los movimientos de los precios y las lecturas de los indicadores en el momento de las transacciones y recopilar las trayectorias conocidas para cada una de las señales utilizadas. Implementaremos esta funcionalidad en el asesor "...\RealORL\ResearchRealORL.mq5", pero antes haremos un pequeño trabajo preparatorio.
Para registrar cada operación de la historia de transacciones de la señal, crearemos la clase CDeal. Esta clase está destinada exclusivamente al uso interno, y para eliminar operaciones innecesarias, omitiremos los envoltorios de acceso a variables de clase. Declararemos todas las variables públicamente.
class CDeal : public CObject { public: datetime OpenTime; datetime CloseTime; ENUM_POSITION_TYPE Type; double Volume; double OpenPrice; double StopLos; double TakeProfit; double point; //--- CDeal(void); ~CDeal(void) {}; //--- vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
Las variables de clase son comparables a los campos de transacción en MetaTrader 5. Solo hemos omitido la variable del nombre del instrumento, ya que se supone que trabaja con un único instrumento financiero. Sin embargo, si estamos creando un modelo multidivisa, sería conveniente añadir el nombre del instrumento.
Y otro momento interesante: en la transacción especificaremos el stop loss y el take profit en forma de precio, mientras que el modelo generará la acción del Agente en unidades relativas. Para poder convertir los datos, almacenaremos el tamaño de un punto del instrumento en la variable de point.
En el constructor de la clase, rellenaremos las variables con valores iniciales, mientras que dejaremos el destructor de la clase vacío.
void CDeal::CDeal(void) : OpenTime(0), CloseTime(0), Type(POSITION_TYPE_BUY), Volume(0), OpenPrice(0), StopLos(0), TakeProfit(0), point(1e-5) { }
Para convertir una transacción en el vector de acciones del Agente, crearemos un método Action, en cuyos parámetros transmitiremos la fecha y hora de apertura de la barra actual y los precios bid y ask, así como el intervalo del marco temporal analizado en segundos. Permítame recordarle que estamos analizando el mercado y realizando todas las operaciones comerciales en la apertura de cada barra.
Aquí vale la pena señalar que el momento de las operaciones comerciales en la historia de las señales que hemos recopilado puede diferir de la hora de apertura de la barra del marco temporal utilizado. Y si bien podemos cerrar una posición por Stop Loss o Take Profit dentro de la barra, podremos abrir una posición solo en la apertura de la misma. Por lo tanto, aquí haremos una suposición e introduciremos una pequeña corrección en el precio y en el momento de apertura de la posición: abriremos una posición en la apertura de una barra si en la historia de la señal se abre antes de su cierre.
Siguiendo la lógica anterior, en el código del método, si la hora actual es menor que la hora de apertura de la posición corregida o mayor que la hora de cierre de la posición corregida, el método retornará un vector de acción del Agente nulo.
vector<float> CDeal::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); if((OpenTime - period_seconds) > current || CloseTime <= current) return result;
Observe que primero crearemos el vector de resultados nulo y solo después realizaremos el control del tiempo y devolveremos el resultado. Este enfoque nos permitirá seguir operando con el vector nulo de resultados ya generado. Por ello, cuando tengamos que rellenar el vector de acciones, solo rellenaremos los elementos distintos de cero.
El vector de acción se rellenará en el cuerpo del operador de selección de switch en función del tipo de posición. En el caso de una posición larga, escribiremos el volumen de la transacción en el elemento con un índice "0". A continuación, comprobaremos las diferencias entre el take profit y el stop loss respecto a "0" y, de ser necesario, convertiremos el precio en un valor relativo. Luego escribiremos los valores obtenidos en los elementos con los índices "1" y "2", respectivamente.
switch(Type) { case POSITION_TYPE_BUY: result[0] = float(Volume); if(TakeProfit > 0) result[1] = float((TakeProfit - ask) / (MaxTP * point)); if(StopLos > 0) result[2] = float((ask - StopLos) / (MaxSL * point)); break;
Para la posición corta se realizarán operaciones similares, pero desplazando los índices de los elementos del vector en 3.
case POSITION_TYPE_SELL: result[3] = float(Volume); if(TakeProfit > 0) result[4] = float((bid - TakeProfit) / (MaxTP * point)); if(StopLos > 0) result[5] = float((StopLos - bid) / (MaxSL * point)); break; }
Luego retornaremos el vector generado al programa que ha realizado la llamada.
//--- return result; }
Y combinaremos todas las transacciones de una señal en la clase CDeals. Esta clase contendrá un array dinámico de objetos, al que añadiremos ejemplares de la clase CDeal creada anteriormente, y 2 métodos:
- LoadDeals - carga las transacciones del archivo csv de la historia;
- Action - formación del vector de acción del Agente.
class CDeals { protected: CArrayObj Deals; public: CDeals(void) { Deals.Clear(); } ~CDeals(void) { Deals.Clear(); } //--- bool LoadDeals(string file_name, string symbol, double point); vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
En el constructor y el destructor de la clase, borraremos el array dinámico de transacciones.
Le propongo empezar cargando la historia de transacciones del archivo cvs LoadDeals. En los parámetros del método transmitiremos el nombre del archivo, el nombre del instrumento analizado y el tamaño del punto. Hemos puesto deliberadamente el nombre del instrumento en los parámetros, ya que a menudo existen diferencias en los nombres de los instrumentos financieros en los distintos brókeres. Como consecuencia, incluso cuando el asesor se inicia en el gráfico del instrumento analizado, su nombre puede diferir del unificado en el archivo de la historia de la señal.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
En el cuerpo del método, comprobaremos primero el nombre del archivo y su presencia en la carpeta compartida del terminal. Si falta el archivo requerido, informaremos al usuario y finalizaremos el método con el resultado false.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
El siguiente paso consistirá en comprobar el nombre del instrumento financiero especificado. Y en su defecto, anotaremos el nombre del instrumento gráfico sobre el que se ejecutará el asesor.
if(symbol == NULL) { symbol = _Symbol; point = _Point; }
Una vez hayamos pasado con éxito el bloque de control, abriremos el archivo especificado en los parámetros del método y comprobaremos inmediatamente el resultado de la operación según el valor del manejador obtenido. Si por alguna razón no se ha podido abrir el archivo, informaremos al usuario sobre el error y finalizaremos el método con un resultado negativo.
ResetLastError(); int handle = FileOpen(file_name, FILE_READ | FILE_ANSI | FILE_CSV | FILE_COMMON, short(';'), CP_ACP); if(handle == INVALID_HANDLE) { PrintFormat("Error of open file %s: %d", file_name, GetLastError()); return false; }
Con esto finaliza el trabajo preparatorio, así que podemos comenzar a organizar el ciclo de lectura de datos. Antes de cada iteración del ciclo, comprobaremos si se ha llegado al final del archivo.
FileSeek(handle, 0, SEEK_SET); while(!FileIsEnding(handle)) { string s = FileReadString(handle); datetime open_time = StringToTime(s); string type = FileReadString(handle); double volume = StringToDouble(FileReadString(handle)); string deal_symbol = FileReadString(handle); double open_price = StringToDouble(FileReadString(handle)); volume = MathMin(volume, StringToDouble(FileReadString(handle))); datetime close_time = StringToTime(FileReadString(handle)); double close_price = StringToDouble(FileReadString(handle)); s = FileReadString(handle); s = FileReadString(handle); s = FileReadString(handle);
En el cuerpo del ciclo, primero leeremos toda la información sobre una transacción y la escribiremos en variables locales. Según la estructura del archivo, los 3 últimos elementos contendrán la comisión, el swap y el beneficio de la transacción. No utilizaremos estos datos en nuestra trayectoria, ya que la hora y el precio de apertura podrían ser diferentes de los de la historia, y junto con ellos, los valores de los beneficios serían diferentes. Además, la comisión y los swaps dependen de la configuración del bróker.
A continuación, comprobaremos si el instrumento financiero de la operación comercial coincide con el analizado, transmitido en los parámetros. Si los instrumentos no coinciden, pasaremos a la siguiente iteración del ciclo.
if(StringFind(deal_symbol, symbol, 0) < 0) continue;
Si la operación se realiza sobre el instrumento financiero que nos interesa, crearemos un ejemplar del objeto de descripción de la operación,
ResetLastError(); CDeal *deal = new CDeal(); if(!deal) { PrintFormat("Error of create new deal object: %d", GetLastError()); return false; }
y lo rellenaremos, pero aquí hay un matiz a considerar. Podemos almacenar sin problemas:
- el tipo de posición;
- las horas de apertura y cierre;
- el precio de apertura;
- el volumen de las transacciones;
- el tamaño de 1 punto.
Sin embargo, los precios de stop loss y take profit no se especificarán en la historia de transacciones. En su lugar, solo se indicará el precio real de cierre de la posición. Aquí utilizaremos una lógica bastante simple:
- Primero introduciremos la suposición de que la posición se ha cerrado por Stop Loss o Take Profit.
- En este caso, si la posición se ha cerrado con ganancias, se habrá cerrado por take profit. De lo contrario, el cierre se habrá producido por stop loss. En el campo correspondiente, especificaremos el precio de cierre.
- El campo opuesto permanecerá vacío.
deal.OpenTime = open_time; deal.CloseTime = close_time; deal.OpenPrice = open_price; deal.Volume = volume; deal.point = point; if(type == "Sell") { deal.Type = POSITION_TYPE_SELL; if(close_price < open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } } else { deal.Type = POSITION_TYPE_BUY; if(close_price > open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } }
Entiendo perfectamente los riesgos de negociar sin un stop loss, pero espero minimizarlos durante el entrenamiento previo del modelo.
Ahora añadiremos la descripción de la transacción creada a un array dinámico y pasaremos a la siguiente iteración del ciclo.
ResetLastError(); if(!Deals.Add(deal)) { PrintFormat("Error of add new deal: %d", GetLastError()); return false; } }
Tras llegar al final del archivo, cerraremos el archivo y finalizaremos el método con el resultado true.
FileClose(handle); //--- return true; }
El algoritmo del método de entrenamiento del vector de acción del Agente será bastante sencillo. Simplemente iteraremos un ciclo a través de todo el array de transacciones y llamaremos a los métodos con el mismo nombre de cada transacción.
vector<float> CDeals::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); for(int i = 0; i < Deals.Total(); i++) { CDeal *deal = Deals.At(i); if(!deal) continue; vector<float> action = deal.Action(current, ask, bid, period_seconds);
Pero aquí también tenemos algunas sutilezas. Supongamos que varias posiciones, incluidas las multidireccionales, pueden abrirse simultáneamente en la historia de señales. Por lo tanto, deberemos sumar los vectores obtenidos de todas las transacciones del archivo. Pero solo podremos sumar volúmenes. La simple adición de niveles de stop loss y take profit no será correcta. Y aquí deberemos recordar que como stop loss y take profit en el vector de acción del Agente se especificará el desplazamiento en unidades relativas desde el precio actual. Considerando esto, al sumar los vectores para los niveles de stop loss y take profit, tomaremos la desviación máxima. Los volúmenes no cerrados a tiempo serán cerrados por el asesor en la apertura de una nueva vela, ya que en este caso se esperará una disminución del volumen total de la posición total.
result[0] += action[0]; result[3] += action[3]; result[1] = MathMax(result[1], action[1]); result[2] = MathMax(result[2], action[2]); result[4] = MathMax(result[4], action[4]); result[5] = MathMax(result[5], action[5]); } //--- return result; }
Luego transmitiremos el vector final de acciones del Agente al programa que realiza la llamada y luego finalizaremos el método.
Aquí termina el trabajo preparatorio, así que podemos pasar a trabajar en el asesor "...\RealORL\ResearchRealORL.mq5". Aquí debemos decir que el asesor ha sido creado sobre la base de los asesores revisados anteriormente "...\...\Research.mq5" y ha heredado su patrón de construcción, y además se han heredado todos los parámetros externos.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = -10000; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int Agent = 1;
Al mismo tiempo, este asesor no utiliza ningún modelo, ya que nosotros mismos hemos tomado la decisión sobre las transacciones comerciales, y hemos utilizado la historia de transacciones de la señal. Por lo tanto, eliminaremos todos los objetos modelo y añadiremos un objeto del array de transacciones de la señal CDeals.
SState sState; STrajectory Base; STrajectory Buffer[]; STrajectory Frame[1]; CDeals Deals; //--- float dError; datetime dtStudied; //--- CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- double PrevBalance = 0; double PrevEquity = 0;
Del mismo modo, en el método de inicialización del asesor, en lugar de cargar un modelo preentrenado, cargaremos la historia de operaciones comerciales.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load history if(!Deals.LoadDeals(SignalFile(Agent), "EURUSD", SymbolInfoDouble(_Symbol, SYMBOL_POINT))) return INIT_FAILED; //--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Tenga en cuenta que al cargar los datos de las transacciones de la señal, especificaremos SignalFile(Agent) en lugar del nombre del archivo. Aquí utilizaremos una macrosustitución, y para ello hemos creado previamente nombres de archivo de señal unificados "SeñalX.csv". La macrosustitución nos retornará el nombre unificado del archivo de la historia de la señal con el valor del parámetro externo Agent como identificador.
#define SignalFile(agent) StringFormat("Signals\\Signal%d.csv",agent)
Esto nos permitirá ejecutar "...\RealORL\ResearchRealORL.mq5" en el modo de optimización del Simulador de Estrategias de MetaTrader 5. Y la optimización mediante el parámetro Agent permitirá que cada pasada opere con su propio archivo de historia de señales. De este modo, podremos procesar varios archivos de señales en paralelo y recoger de ellos las trayectorias de interacción con el entorno.
La interacción con el entorno se ejecutará en el método OnTick. Aquí comprobaremos primero la aparición del nuevo evento de apertura de la barra, como de costumbre.
void OnTick() { //--- if(!IsNewBar()) return;
Y, de ser necesario, descargaremos los datos históricos de los movimientos de precio. Y también actualizaremos los búferes de objetos de trabajo con indicadores.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
La ausencia de modelos para la toma de decisiones implicará que no es necesario llenar los búferes de datos. Sin embargo, deberemos rellenar la estructura de estados con los datos necesarios para almacenar la información en la trayectoria de interacción con el entorno. En primer lugar, recopilaremos los datos sobre el movimiento de los precios y el rendimiento de los indicadores.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
A continuación, introduciremos la información sobre el estado de la cuenta y las posiciones abiertas. Aquí también especificaremos la hora de apertura de la barra actual. Tenga en cuenta que en esta fase solo almacenaremos un único valor de tiempo sin crear armónicos de marca temporal. Esto permitirá reducir la cantidad de datos almacenados sin perder información.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Ahora completaremos directamente los elementos del impacto del cambio de balance y equidad en el vector de recompensa.
sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(1.0 - sState.account[1] / PrevBalance);
Y guardaremos los valores de balance y equidad que necesitaremos en la siguiente barra para calcular la recompensa.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
En lugar de pasar directamente por el agente, consultaremos el vector de acciones de la historia de transacciones de la señal.
vector<float> temp = Deals.Action(TimeCurrent(), SymbolInfoDouble(_Symbol, SYMBOL_ASK), SymbolInfoDouble(_Symbol, SYMBOL_BID), PeriodSeconds(TimeFrame) );
El procesamiento y la descodificación del vector de acción se realizan según el algoritmo que hemos elaborado anteriormente. En primer lugar, excluiremos los volúmenes multidireccionales.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
A continuación, ajustaremos la posición larga. Pero antes no permitíamos abrir una posición sin especificar un stop loss o un take profit, y ahora es una medida forzada. Por consiguiente, realizaremos ajustes en la verificación del cierre de las posiciones abiertas anteriormente y la especificación de los precios de stop loss / take profit.
//--- buy control if(temp[0] < min_lot || (temp[1] > 0 && (temp[1] * MaxTP * Symb.Point()) <= stops) || (temp[2] > 0 && (temp[2] * MaxSL * Symb.Point()) <= stops)) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = (temp[1] > 0 ? NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double buy_sl = (temp[2] > 0 ? NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Realizaremos ajustes similares en el bloque de ajuste de posiciones cortas.
//--- sell control if(temp[3] < min_lot || (temp[4] > 0 && (temp[4] * MaxTP * Symb.Point()) <= stops) || (temp[5] > 0 && (temp[5] * MaxSL * Symb.Point()) <= stops)) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = (temp[4] > 0 ? NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double sell_sl = (temp[5] > 0 ? NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Al final del método, rellenaremos el vector de recompensa, copiaremos el vector de acción y pasaremos la estructura para que se añada a la trayectoria.
if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
Con esto terminaremos la revisión de los métodos del asesor "...\RealORL\ResearchRealORL.mq5", ya que el resto de los métodos han sido trasladados sin cambios. El código completo del asesor, así como todos los programas utilizados en el artículo, se encontrarán en el archivo adjunto.
Los autores del método Real-ORL no ofrecen un nuevo método para enseñar la política del Actor. Y para nuestro experimento no hemos hecho ningún cambio ni en el algoritmo de aprendizaje de políticas ni en la arquitectura del modelo. Daremos este paso deliberadamente para que las condiciones sean comparables a las del entrenamiento del modelo del artículo anterior, lo que finalmente nos permitirá evaluar el impacto del marco Real-ORL directamente en el resultado del entrenamiento de políticas.
3. Simulación
El trabajo anterior se ha realizado para recopilar información comercial de varias señales y preparar un asesor para convertir la información recopilada en trayectorias de interacción con el entorno. Ahora procederemos a probar el trabajo realizado y a evaluar el impacto de las trayectorias seleccionadas en los resultados del entrenamiento del modelo. En este artículo, entrenaremos modelos completamente nuevos inicializados con parámetros aleatorios. Recordemos que en el artículo anterior optimizamos modelos previamente entrenados.
En primer lugar, ejecutamos el asesor para convertir la historia de señales en trayectorias "...\RealORL\ResearchRealORL.mq5". Luego ejecutaremos el asesor en el modo de optimización completa.
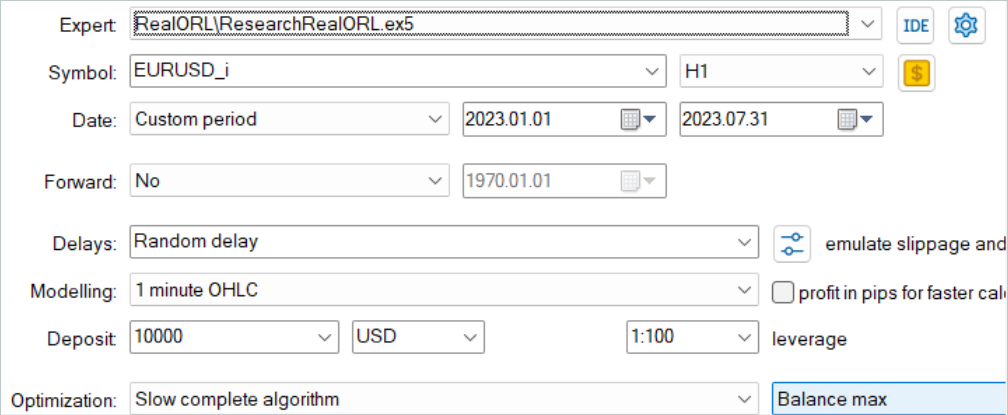
Realizaremos la optimización en un solo parámetro del Agente. En el rango de parámetros, especificaremos el primer y último identificador de los archivos de señal en incrementos de "1".
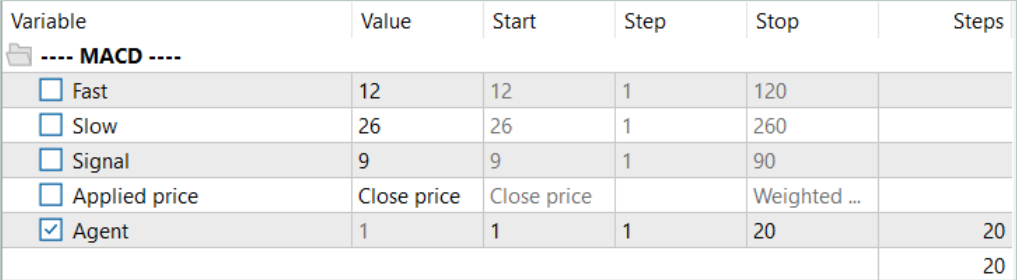
Debemos decir que las trayectorias resultantes son bastante interesantes.
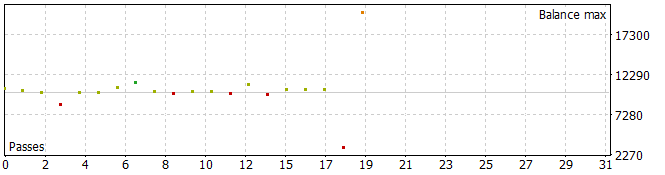
Cinco de las pasadas durante el periodo analizado han cerrado con pérdidas, mientras que una ha duplicado su balance.
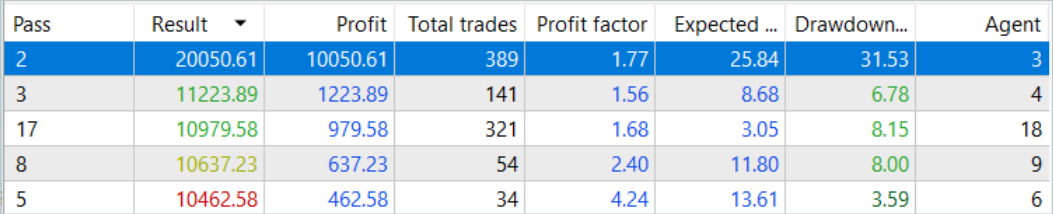
Una sola pasada de la trayectoria más rentable ha mostrado una caída bastante profunda el 7.02.2023 y el 25.07.2023. No vamos a discutir la estrategia utilizada por el autor de la señal, ya que no estoy familiarizado con ella. Además, es muy posible que la reducción se deba a una apertura anticipada de la posición, provocada por el desplazamiento del punto de apertura de la posición al inicio de la barra del marco temporal analizado. Y, obviamente, el uso de los stop loss que hayamos reducido deliberadamente a cero provocará el bloqueo de las pérdidas en tales situaciones.
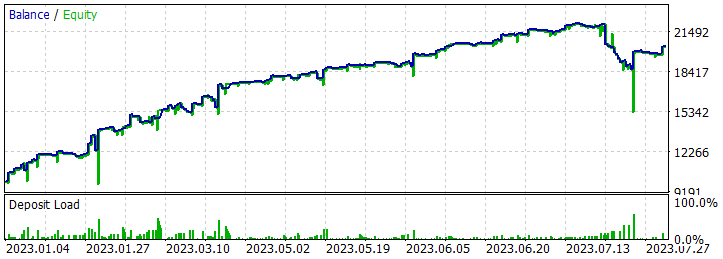
Tras guardar las trayectorias, procederemos al entrenamiento del modelo. Para ello, ejecutaremos el asesor "...\RealORL\Study.mq5".
El entrenamiento inicial se ha realizado únicamente con datos de trayectoria recogidos a partir del rendimiento de la señal, y debo decir que no ha habido ningún milagro. El rendimiento del modelo tras el entrenamiento inicial distaba mucho de los resultados deseados. La política entrenada ha generado pérdidas tanto para el periodo de entrenamiento de los 7 primeros meses de 2023 como para el intervalo histórico de prueba de agosto de 2023. Pero, sinceramente, yo no iría tan lejos como para decir que el marco Real-ORL propuesto resulta ineficaz. Las 20 trayectorias seleccionadas distan mucho de las 3 000 utilizadas por los autores del marco. Y ciertamente 20 trayectorias no abarcan ni siquiera una pequeña parte de la variedad de acciones posibles de un agente.
Antes de continuar con el entrenamiento, hemos rellenado el búfer de trayectorias de entrenamiento utilizando el asesor "...\RealORL\Research.mq5". Recordemos que este asesor realiza pasadas con tomas de decisiones basadas en la política pre-entrenada del Agente. Y la exploración del entorno se realiza debido a la estocasticidad del estado latente y las políticas del Agente. Las 2 estocasticidades crean una gran variedad de acciones del Agente, permitiéndole explorar el entorno. A medida que se entrene la política del Agente, ambas estocasticidades disminuirán, debido a la varianza decreciente de cada parámetro. Esto hará que las acciones del Agente sean más predecibles e informadas.
Vamos a añadir 200 nuevas trayectorias al búfer y repetir el proceso de entrenamiento del modelo.
Esta vez, el proceso de entrenamiento de la política del Agente ha sido bastante largo. Hemos tenido que actualizar muchas veces el búfer de reproducción de experiencias utilizando el asesor "...\RealORL\Research.mq5" antes de conseguir una política rentable. Sin embargo, debemos señalar que, en el proceso de actualización del búfer de reproducción de experiencias una vez que está completamente lleno, hemos sustituido las trayectorias con máxima pérdida (mínima ganancia) por otras más rentables. En consecuencia, solo se han sustituido las trayectorias recogidas con el asesor "...\RealORL\Research.mq5". Las trayectorias de las señales, debido a su rendimiento global, han permanecido permanentemente en el búfer de reproducción de experiencias.
Como ya hemos dicho, el largo entrenamiento ha dado lugar a una política capaz de generar beneficios en la muestra de entrenamiento. Además, la política resultante es capaz de generalizar las lecciones aprendidas a los nuevos datos. Prueba de ello es la obtención de beneficios con datos históricos fuera del periodo de estudio.


En los datos históricos de la muestra de prueba, el Agente ha realizado 131 transacciones, de las cuales el 48,85% se han cerrado con beneficios. La operación rentable máxima es casi un 10% inferior a la pérdida máxima (379,89 frente a 398,49, respectivamente). Al mismo tiempo, la media de transacciones rentables es un 40% superior a la media de pérdidas. Como resultado, el factor de beneficio para el periodo de prueba ha sido de 1,34 y el factor de recuperación de 0,94.
También cabe destacar la casi paridad entre las transacciones largas (70) y cortas (61). Esto demuestra la capacidad del Agente para destacar tendencias localizadas en lugar de limitarse a seguir una tendencia global.
Conclusión
En este artículo, se nos presenta el marco Real-ORL, que nos ha llegado de la robótica. Los autores del marco realizan en su trabajo una investigación empírica bastante amplia usando un robot real, lo cual les permite extraer las siguientes conclusiones:
- Para tareas fuera del dominio de aplicación, los algoritmos de aprendizaje por refuerzo podrían generalizarse a dominios de tareas con pocos datos y también a tareas dinámicas.
- El cambio en el rendimiento de ORL tras utilizar datos heterogéneos tiende a variar según los agentes, el diseño de la tarea y las características de los datos.
- Ciertas trayectorias heterogéneas e independientes de la tarea pueden ofrecer un soporte de datos superpuesto y posibilitar un mejor aprendizaje, permitiendo a los agentes ORL mejorar su rendimiento.
- El mejor agente para cada problema es el algoritmo ORL o la paridad entre ORL y BC. Las evaluaciones del artículo indican que, incluso en un régimen de datos ajeno al dominio de aplicación más realista para el mundo real, el aprendizaje por refuerzo offline resulta un enfoque eficaz.
En nuestro artículo, consideramos la posibilidad de utilizar el marco propuesto para su uso en el ámbito de los mercados financieros. Concretamente, los enfoques propuestos por los autores del marco Real-ORL permiten explotar la historia de una amplia gama de señales diferentes en el mercado para entrenar modelos. Sin embargo, necesitaremos un gran número de trayectorias para maximizar la representación de la diversidad del entorno. Y, por tanto, deberemos trabajar para recoger el mayor número posible de trayectorias diversas. Utilizar solo 20 trayectorias en este artículo puede considerarse probablemente un error. Los autores de Real-ORL han utilizado más de 3 000 trayectorias en su trabajo.
Mi opinión personal es que el método puede y debe utilizarse para el entrenamiento inicial del modelo y tiene una ventaja sobre la recogida de trayectorias aleatorias. No obstante, utilizar solo datos de trayectoria "congelados" no es suficiente para construir una política de Agente óptima. Es difícil esperar resultados serios del pequeño número de trayectorias que hemos seleccionado. Pero los autores del método tampoco han obtenido en su trabajo los máximos resultados teóricamente posibles. Además, la información sobre las señales es limitada y no permite considerar todos los riesgos. Por ejemplo, no hay información sobre el stop loss y el take profit en las señales. Su ausencia impide evaluar y controlar plenamente los riesgos. Por lo tanto, un modelo entrenado con trayectorias de señales necesitará un ajuste fino posterior en trayectorias adicionales ya obtenidas con la política preentrenada.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | ResearchExORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método ExORL |
| 4 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13854
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 5): Bandas de Bollinger en el Canal de Keltner - Señales de Indicador
Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 5): Bandas de Bollinger en el Canal de Keltner - Señales de Indicador
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Si conoces el tema, escribe un artículo sobre el uso de Google Colab + Tensor Flow. Puedo dar una tarea real de comercio y calcular las entradas.
No sé cuánto está en el tema de este sitio?
Hola @Dmitriy Gizlyk
En primer lugar me quito el sombrero ante tus esfuerzos en esta maravillosa serie sobre IA y ML.
He pasado por todos los artículos de 1 a 30 en una fila en un solo día. La mayoría de los archivos que proporcionaste funcionaron sin ningún problema.
Sin embargo, he saltado al artículo 67 y trató de ejecutar 'ResearchRealORL'. Estoy recibiendo los siguientes errores.
¿Podría ayudarme en qué me equivoco?
Saludos y muchas gracias por todos sus esfuerzos para enseñarnos ML en MQL5.
你好@Dimitri吉兹利克
首先,向您为创建这个关于 AI 和 ML 的精彩系列文章所做的努力致敬。
我在一天内连续浏览了从 1 到 30 的所有文章。您提供的大多数文件都可以正常工作。
但是,我转到了第 67 条并尝试运行 "ResearchRealORL"。我收到以下错误。
你能帮我解决我错的地方吗?
衷心感谢您在MQL5中教我们ML的所有努力。
Estoy ejecutando el código en Neural networks made easy (Part 67): Using past experience to solve new tasks
Tengo el mismo problema con respecto a lo siguiente.
2024.04.21 18:00:01.131 Core 4 pass 0 tested with error "OnInit returned non-zero code 1" in 0:00:00.152
Parece que está relacionado con el comando 'FileIsExist'.
Pero, no puedo resolver este problema.
¿Sabéis cómo resolverlo?