
Del básico al intermedio: Plantilla y Typename (V)

Introducción
En el artículo anterior Del básico al intermedio: Plantilla y Typename (IV), expliqué cómo podríamos crear una plantilla para generalizar un tipo de modelado de la manera más didáctica y simple posible. De esta manera, creamos lo que podría considerarse una sobrecarga de tipos de datos. Al final del artículo, presenté un concepto que puede resultar muy difícil de entender para muchos: la transferencia de datos dentro de una función o procedimiento que también se implementa como plantilla. Justamente, por el hecho de que lo presentado exige una explicación mejor, dejé esto para hacerlo en este artículo. Además, necesitamos hablar de otro tema relacionado con esto, en el que el uso de plantillas puede marcar la diferencia entre implementar o no algo.
Así pues, para comenzar adecuadamente este artículo, vamos a iniciar un nuevo tema para explicar por qué funciona el último código que se mostraba en el artículo anterior.
Expandimos la mente
En el artículo anterior, implementamos algo con una apariencia bastante inusual. Creo que muchos de ustedes aún no habían visto nada parecido. Para poder explicar adecuadamente su significado, necesitamos revisar el código utilizado. Puede observarse justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 <T> &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
Código 01
Muy bien, dado que ya habrás experimentado lo que se vio en el artículo anterior, este código 01 debe haber llamado tu atención. Esto se debe precisamente a la forma en que se está declarando el procedimiento de la línea 35. Es cierto que para entender qué se necesita declarar, pero sobre todo por qué se hace como se hace en este código 01.
En primer lugar, debemos comprender que este procedimiento de la línea 35 será sobrecargado por el compilador. Esto ocurre durante el proceso de creación del código ejecutable. Pues, bien, como se dijo en el artículo anterior, lancé el desafío de crear un código que realizara el mismo trabajo que el código 01, pero sin hacer uso de la sobrecarga vía plantilla. Esto es para el procedimiento implementado en la línea 35. El objetivo de este ejercicio es dejar claro por qué el procedimiento necesita ser declarado de esa manera.
Como en teoría este ejercicio es sencillo, pero en la práctica puede resultar un poco complicado, vamos a hacerlo juntos. Así, podrás entender por qué la declaración debe hacerse de esa manera, como se puede ver en el código 01.
No voy a modificar todo el código, solo el procedimiento. Así, podemos centrarnos en el fragmento que se muestra a continuación.
. . . 33. //+------------------------------------------------------------------+ 34. void Swap(un_01 <ulong> &arg) 35. { 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. arg.u8_bits[i] = arg.u8_bits[j]; 40. arg.u8_bits[j] = tmp; 41. } 42. } 43. //+------------------------------------------------------------------+ 44. void Swap(un_01 <ushort> &arg) 45. { 46. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 47. { 48. tmp = arg.u8_bits[i]; 49. arg.u8_bits[i] = arg.u8_bits[j]; 50. arg.u8_bits[j] = tmp; 51. } 52. } 53. //+------------------------------------------------------------------+
Fragmento 01
Este fragmento sustituye al procedimiento de la línea 35. Pero presta atención: lo que contiene este fragmento 01 es EXACTAMENTE lo que el compilador creará cuando traduzca y realice la sobrecarga del procedimiento visto en el código 01. Por tanto, en este fragmento 01 solo se cubren los tipos ulong y ushort, a diferencia de lo que se ve en el código 01, donde se cubren todos los tipos primarios.
Pero entonces, ¿por qué necesitamos expresar las cosas de esta manera, como se observa en el fragmento 01? El motivo, creo yo, ahora está mucho más claro. Si has entendido lo que se explicó en el artículo anterior, habrás percibido el motivo por el que las líneas 14 y 24 del código 01 se declaran de esa forma. Y, por el mismo motivo, también necesitamos que las líneas 34 y 44, vistas en este fragmento 01, se declaren de una forma semejante.
Recuerda el siguiente hecho, que vimos en los primeros artículos cuando hablamos del paso de valor o por referencia: al declarar una variable, debemos indicar su tipo y darle un nombre. Y, dentro de la declaración de una función o procedimiento, estamos declarando una variable que puede ser o no una constante, dependiendo de cada caso específico.
Vale, en cuanto a la declaración de las variables para tratar un procedimiento, la cosa aparentemente es simple. Pero aún tengo una duda. Cuando hablaste sobre variables especiales, dijiste que una función sería uno de estos tipos de variables. Sin embargo, en este tipo de situaciones, como la que estamos tratando ahora, ¿cómo podríamos utilizar una función para cubrir el código e implementar lo que necesitamos?
Bien, esta es, de hecho, una excelente pregunta, querido lector. Esto se debe a que, para poder devolver valores, necesitamos utilizar una declaración diferente a la que hacemos cuando usamos procedimientos. Sin embargo, el concepto adoptado es bastante similar a lo que se ha visto hasta el momento. Recuerda que, cuando retornamos algo, ese retorno es un tipo de variable, como si estuviéramos declarando una variable cuyo nombre es el de la función. Por tanto, podemos aplicar el concepto básico y crear nuestro código de forma adecuada.
Así pues, antes de ver la forma generalizada, veremos una manera parecida a la que se puede observar en el fragmento 01. No obstante, dado que las funciones tienen como objetivo trabajar de forma diferente a los procedimientos, también vamos a modificar el código 01. Esto es lo que se ve a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. un_01 <ulong> Swap(const un_01 <ulong> &arg) 33. { 34. un_01 <ulong> local; 35. 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. local.u8_bits[i] = arg.u8_bits[j]; 40. local.u8_bits[j] = tmp; 41. } 42. 43. return local; 44. } 45. //+------------------------------------------------------------------+ 46. un_01 <ushort> Swap(const un_01 <ushort> &arg) 47. { 48. un_01 <ushort> local; 49. 50. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 51. { 52. tmp = arg.u8_bits[i]; 53. local.u8_bits[i] = arg.u8_bits[j]; 54. local.u8_bits[j] = tmp; 55. } 56. 57. return local; 58. } 59. //+------------------------------------------------------------------+
Código 02
Observa que este código 02 es ligeramente distinto al código 01. Sin embargo, a pesar de estas pequeñas diferencias, produce el mismo resultado. Es decir, cuando compiles este código 02 y lo ejecutes en el terminal de MetaTrader 5, obtendrás lo que se ve en la imagen de abajo.
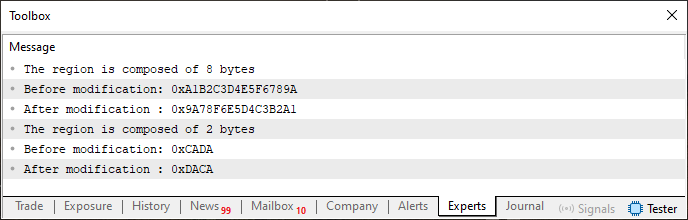
Imagen 01
Observa que se trata del mismo tipo de respuesta que se obtendría al ejecutar el código 01, incluso después de haberlo modificado para hacer uso del fragmento 01. Pero, al igual que el fragmento 01, este código 02 limita las opciones de tipos de datos que el compilador podrá utilizar cuando intentemos utilizar la unión un_01.
Aquí, en este código 02, tenemos la misma limitación. Sin embargo, quiero que observes cómo se tradujo el fragmento 01 para poder utilizar funciones en lugar de procedimientos. Observa también las líneas 19 y 28 de este código 02, pues es ahí donde hacemos uso de la variable especial Swap, que, en realidad, es una función con el noble objetivo de ser utilizada como variable de solo lectura.
Es genial, ¿no crees? Pero, del mismo modo que el fragmento 01 muestra lo que hace el procedimiento del código 01, podemos transformar estas funciones del código 02 en una plantilla. De esta manera, el código mantendría el mismo comportamiento y libertad de elección de tipos que el código 01. Para ello, basta con transformar los puntos comunes de las funciones del código 02 en un punto donde el compilador pueda actuar de alguna forma. Así, el compilador podrá cambiar el tipo de dato siempre que sea necesario. Entendiendo este concepto, podemos transcribir el código 02 al código 03, que se encuentra justo a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. template <typename T> 33. un_01 <T> Swap(const un_01 <T> &arg) 34. { 35. un_01 <T> local; 36. 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. local.u8_bits[i] = arg.u8_bits[j]; 41. local.u8_bits[j] = tmp; 42. } 43. 44. return local; 45. } 46. //+------------------------------------------------------------------+
Código 03
Y este código 03 es una mejora del código 02, ya que ahora podemos utilizar cualquier tipo de dato y el compilador podrá entenderlo y crear todas las sobrecargas necesarias para crear nuestra aplicación con éxito.
Con esto, lo que antes parecería algo extremadamente complejo y difícil de entender pasó a ser simple y trivial, siendo que cualquier principiante ahora puede lidiar con el uso de plantillas. ¿Notaron cómo, a veces, creemos que algo es complicado, pero, si entendemos de hecho los conceptos adoptados, conseguimos implementar cualquier cosa con facilidad? Y es por eso que te estoy diciendo que practiques lo que se está mostrando. No para memorizar formas de codificar las cosas, sino para entender cómo los conceptos están siendo explorados y aplicados en cada situación específica.
Bueno, de hecho, esta es la parte que muchos podrían considerar de nivel intermedio o avanzado. Pero, en mi opinión, lo que se ha mostrado aquí es solo lo básico. Sin embargo, aún necesitamos hablar un poco más sobre lo que estamos haciendo aquí, ya que hasta ahora no se ha mencionado por qué siempre utilizamos la palabra reservada typename.
No obstante, esta explicación exige que pasemos a un nuevo tema, para que todo esté debidamente separado y podamos estudiarlo con calma y atención. Así que vamos a crear un nuevo tema.
Typename. ¿Para qué sirve de hecho?
Una duda que es muy justa y que, de hecho, merece una explicación adecuada es: ¿Qué sería typename? ¿Y para qué nos serviría en un código real? Bien, mi querido lector, entender esto puede ayudarte a implementar algunos tipos de código bastante interesantes. Aunque, en la mayoría de los casos, typename se utiliza solo con fines muy específicos y orientados a algún tipo de actividad de testeo.
Rara vez, al menos hasta donde yo sé, se utilizará typename para otra cosa que no sea verificar y asegurar que una función o procedimiento sobrecargado por el compilador no se salga de control. Esto se debe a que no es raro que implementemos una plantilla y, al utilizar dicha función o procedimiento, obtengamos resultados incoherentes precisamente porque tal o cual tipo no se implementa correctamente.
En otras ocasiones, podemos desear que, al utilizar un tipo de dato, la función o el procedimiento sobrecargado por el compilador tenga un determinado comportamiento, y que en otro tipo de dato el comportamiento sea distinto. Esto se aplica a la misma función o procedimiento. Puede parecer un tanto confuso hablar de esto, sin embargo, en la práctica, a veces es necesario. Entonces, entender cómo funciona typename te ayudará a lidiar con este tipo de situaciones.
Para demostrarlo, vamos a intentar crear una aplicación que sea, al menos, divertida. Demostrar cómo trabajar con typename es algo muy específico que puede resultar aburrido. Pero vamos a ver si conseguimos que resulte menos aburrido. Para ello, vamos a utilizar el código que se ve justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = arg.u8_bits[i]; 43. local.u8_bits[i] = arg.u8_bits[j]; 44. local.u8_bits[j] = tmp; 45. } 46. 47. return local; 48. } 49. //+------------------------------------------------------------------+
Código 04
En este código 04, vamos a jugar con todo lo visto y explicado hasta ahora. El objetivo es entender cómo se puede utilizar typename en un código real. El objetivo es reflejar toda la información presente en la memoria, es decir, en una variable, de forma que la mitad derecha vaya a la izquierda y la mitad izquierda cambie de lugar con la derecha. Así de simple.
Al observar el código 04, se puede apreciar que es prácticamente una modificación de lo que hemos visto hasta ahora. Y esto se está haciendo de manera completamente intencionada, ya que así podemos centrarnos en lo que realmente es novedad y necesita ser comprendido.
Al ejecutar este código 04 en MetaTrader 5, obtenemos la respuesta que se muestra justo debajo.
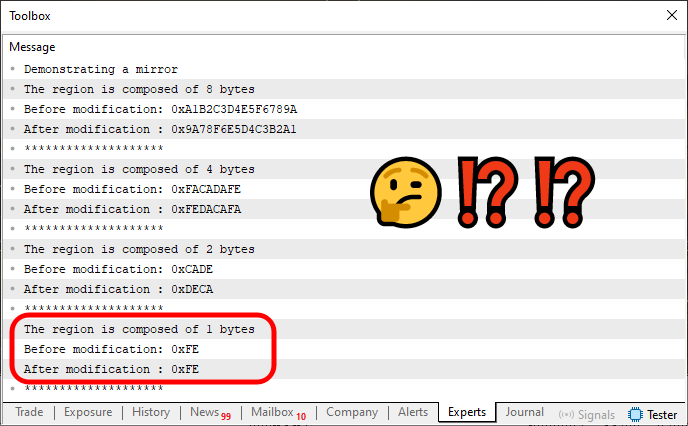
Imagen 02
Observa que estoy destacando uno de los valores. El motivo es simple: NO SE ESTÁ REFLEJANDO, ya que el lado derecho NO ESTÁ siendo intercambiado con el izquierdo. Sin embargo, para todos los demás valores, el reflejo sí se produce. Por tanto, el problema radica en que, al utilizar un tipo de dato de un byte, perdemos la capacidad de reflejar el lado derecho en el izquierdo y viceversa.
Sin embargo, sabemos que en MQL5 solo tenemos un tipo que escapa, o mejor dicho, que cumple el criterio de un byte. Este es el tipo uchar, cuando no tenemos un valor con signo, y el tipo char, cuando tenemos un valor con signo. No obstante, implementar una llamada sobrecargada para tratar con estos tipos resulta un tanto inconveniente. Esto se debe a que perdemos la isonomía de la operación si hacemos este tipo de enfoque. Lo ideal es continuar utilizando la función Mirror, que se implementa en la línea 36, para conseguirlo.
Bien, pero ahora viene la pregunta clave: ¿cómo podemos indicarle al compilador cómo manejar el tipo uchar o char para lograr el reflejo de los valores?
Bien, mi querido lector, existen muchas formas de hacerlo. Una de las más prácticas y sencillas sería leer bit a bit, alternando entre los bits de la derecha y los de la izquierda. Así, no necesitaríamos utilizar una sobrecarga de funciones o procedimientos como haríamos normalmente. Sin embargo, ese no es el objetivo, así que te dejo como tarea intentar implementar este tipo de solución, en la que hacemos el reflejo intercambiando bit a bit los valores presentes en la información de entrada. Esto te ayudará a fijar mejor algunos conceptos e incluso a pensar como un programador.
Pero, ¿y para nosotros ahora? ¿Cómo podemos resolver esto? Bien, mi querido lector, esta es la parte en la que las cosas se vuelven interesantes. Esto es posible porque typename puede decirnos literalmente el nombre del tipo de dato que está llegando. En otras palabras, podemos preguntarle a typename cuál es el tipo de dato que estamos recibiendo o que está siendo utilizado por una variable. Para que esto sea más digerible y para que entiendas lo que vamos a hacer, vamos a crear una pequeña modificación en el código 04. Puedes verla en el código de abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Código 05
Al ejecutar este código 05, verás algo muy parecido a la imagen que aparece justo debajo.
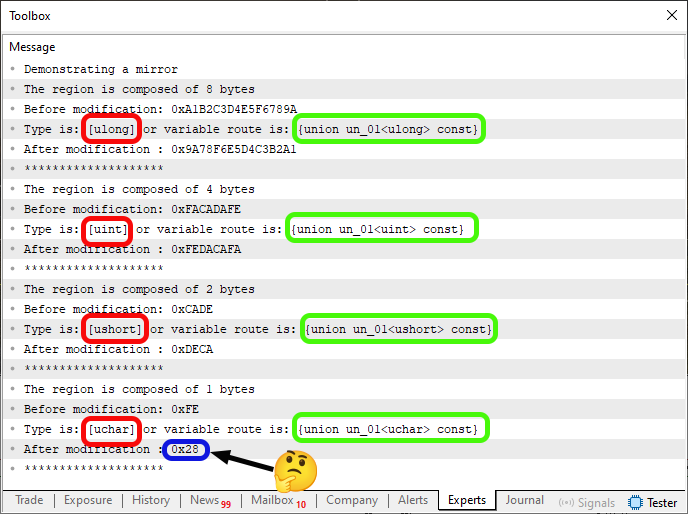
Imagen 03
Aquí, en esta imagen 03 surgió algo que no entendí, ya que NO TIENE ningún sentido que haya aparecido. Tanto es así que está resaltado en AZUL. Es EXTRAÑO. Pero ese no es el punto. Lo que realmente nos interesa son las partes de esta imagen 03 que están destacadas en rojo y verde. ¿De dónde vinieron estas informaciones? Bien, mi querido lector, estas informaciones se imprimieron debido a la línea 40 del código 05. Ahora, presta atención, pues esto es muy importante y debes comprenderlo bien. De lo contrario, podrías tener problemas en el futuro al intentar utilizar las informaciones destacadas en rojo y verde en la imagen 03.
TODAS LAS MARCAS EN ROJO se refieren a la petición al compilador de que nos diga CUÁL ES EL TIPO PRIMITIVO de dato que está utilizando la función. Las MARCAS EN VERDE se refieren a la respuesta del compilador a nuestra solicitud para que nos informe del TIPO DE DATO QUE ESTÁ SIENDO UTILIZADO POR LA VARIABLE. Nota que existe una diferencia muy sutil en nuestra pregunta. Sin embargo, la respuesta puede ser completamente diferente.
Normalmente, y muy probablemente, verás a muchos programadores pidiendo al compilador que diga cuál es el tipo de dato de la variable. Sin embargo, esto no siempre nos dará la respuesta correcta, o mejor dicho, la respuesta que esperamos obtener. Esto se debe a que puede que nos encontremos en una situación muy parecida a la que se muestra justo arriba, donde el tipo de dato primitivo es uno y el tipo de dato utilizado por la variable es un tipo más complejo, pero relacionado de alguna manera con el tipo de dato primitivo.
Sin embargo, no es necesario que te desesperes pensando en cómo vas a verificar esto. En el anexo encontrarás estos códigos, para que puedas estudiarlos y practicar con calma. Pero, volviendo a nuestra cuestión, lo que nos interesa es la información destacada en rojo en la imagen 03. Y nota que todas se escriben de la misma forma en que las declaramos durante la fase de implementación del código. Sin embargo, quiero llamar tu atención, querido y estimado lector, sobre el hecho de que estos valores son cadenas. Es decir, podemos compararlas con otras cadenas durante la fase de ejecución del código. Y precisamente esta es la parte que nos interesa.
Perfecto, ahora ya tenemos un punto de apoyo. Aún queda por hacer una pequeña prueba para aislar los tipos uchar o char, que son los que tienen un único byte, y así poder reflejar adecuadamente los valores. Para ello, necesitaremos implementar una pequeña modificación. Pero esta vez vamos a regresar al código original, es decir, al código 04, para realizar la modificación necesaria. Dicha modificación puede observarse en el código de abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 41. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Código 06
Ahora presta atención, querido lector. Lo que estoy haciendo aquí se puede hacer de diversas maneras. Cada una tiene sus ventajas y desventajas, y puede ser más o menos fácil de entender qué se está haciendo y cómo ocurrirán las cosas. Si no entiendes muy bien este código 06, no te preocupes. Tendrás acceso a él en el anexo y podrás modificarlo para entender lo que ocurre.
Sin embargo, antes de hacer esto, es bueno que primero comprendas lo que he implementado y cuál será el resultado final cuando se ejecute este código. De lo contrario, podrías modificar algo y obtener un resultado diferente al esperado, y pensar que todo funciona correctamente.
Entonces vamos a ello. Primero, veremos cuál es el resultado de la ejecución en el terminal de MetaTrader 5, que se puede observar en la imagen de abajo.
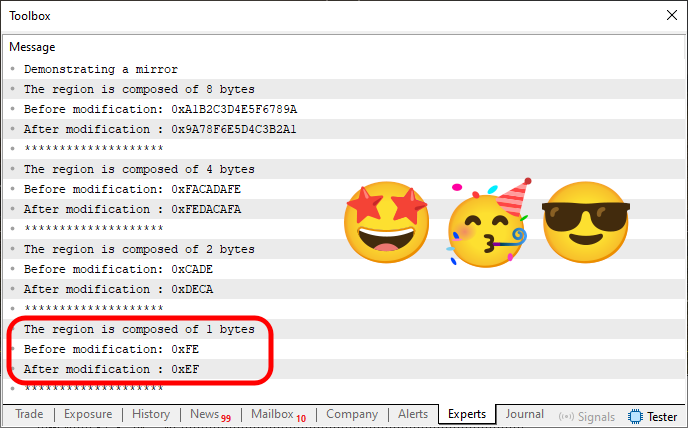
Imagen 04
Simplemente maravilloso. El código consiguió cumplir su objetivo, que era reflejar los valores de cada variable de forma que la mitad de la derecha se intercambiara con la de la izquierda, tal y como se había estimado. Pero fíjate que, para hacer esto basándose en el código 04, todo lo que se añadió al código 06 fue la línea 40. Claro que necesitamos hacer un pequeño ajuste en la línea 41, pero no es esa la parte a la que quiero llamar tu atención, sino a la función que estoy usando para probar si usaremos un método u otro para hacer el reflejo.
La función StringFind de la biblioteca estándar de MQL5 nos permitirá buscar un fragmento específico dentro de la cadena que devuelve typename. Esto es importante para nosotros porque, INDEPENDIENTEMENTE de si usamos el tipo de la variable o el tipo primitivo que el compilador utilizó, podremos obtener la incidencia del fragmento buscado. Pero el motivo por el que estoy utilizando precisamente esta función es que StringFind nos dará un resultado tanto cuando uchar se devuelva como cuando se devuelva char. Esto se debe a que la diferencia entre ambas es precisamente la u que está presente en uchar, pero no en char. De cualquier forma, tendremos la prueba en marcha y un resultado que se reportará.
Sin embargo, cada caso es un caso. Dependiendo de lo que quieras construir en tu código, esta pequeña diferencia entre los nombres de los tipos, con la misma anchura de bytes, puede afectar al resultado final. Esto se debe a que, en un caso, podemos tener valores negativos y, en otro, no. Aunque la resolución explícita del tipo puede aplicarse para corregir este tipo de inconvenientes, es bueno estar atento cuando se vaya a implementar un código en el que se quiera usar una información que el compilador haya podido crear.
Ahora viene la parte graciosa. Tal vez hayas notado que el resultado de la imagen 04 es correcto. Pero aun así, el resultado de la imagen 03 debe tenerse en cuenta. No sé exactamente por qué el compilador decidió gastarnos una broma pesada. Esto se debe a que, si modificamos el código 06 de modo que visualicemos el mismo tipo de información que el código 05 estaría imprimiendo, el resultado es correcto. Sin embargo, algo RARO ocurrió cuando fui a compilar el código 05, que fatalmente estaba generando un resultado extraño, como se puede ver en la imagen 03.
Para comprobarlo, el código modificado al que me refiero se encuentra justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 42. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 43. { 44. tmp = arg.u8_bits[i]; 45. local.u8_bits[i] = arg.u8_bits[j]; 46. local.u8_bits[j] = tmp; 47. } 48. 49. return local; 50. } 51. //+------------------------------------------------------------------+
Código 07
Observa que este código 07 es una combinación de los códigos 05 y 06. Al ejecutarlo, se mostrará lo que se ve en la imagen de abajo.
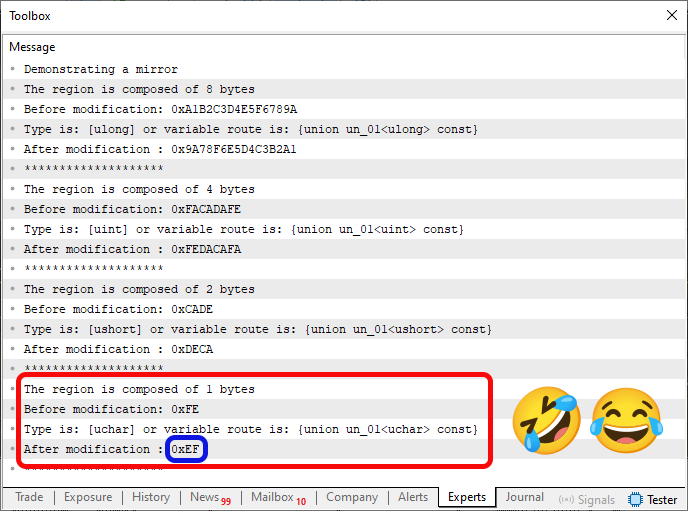
Imagen 05
¿Es una broma o no? ver quién entiende qué pudo pasar cuando se compiló el código 05 o durante su ejecución. Menos mal que estamos aquí haciendo cosas que no requieren precisión y en las que se pueden tolerar pequeños deslices. Pero, aun así, no deja de ser gracioso.
Consideraciones finales
En este artículo finalizamos la explicación y el entrenamiento necesarios para que tú, mi querido y estimado lector que estás comenzando en el campo de la programación, puedas aprender qué es la sobrecarga de funciones o procedimientos. El objetivo es que una misma función o procedimiento pueda utilizar el mismo nombre, pero con datos de tipos diferentes.
Empezamos con casos sencillos, como el que se vio en Del básico al intermedio: Sobrecarga, y fuimos pasando a casos cada vez más elaborados, construyendo así plantillas de funciones y procedimientos. Sin embargo, como este tipo de concepto va más allá de las funciones y los procedimientos, adoptamos el mecanismo de creación de plantillas para ahorrar tiempo de programación. Al utilizar plantillas en nuestras implementaciones, en realidad estamos delegando la creación de la sobrecarga de funciones y procedimientos al compilador para simplificar nuestra labor como programadores.
Sin embargo, podemos ampliar el concepto de plantilla a otros escenarios, como la creación y manipulación de tipos complejos de datos. En este caso, al haber hablado solo de uniones, restringimos todos los conceptos y aplicaciones a este tipo de modelado. Así, se hizo posible experimentar con la sobrecarga de tipos. Esto nos permitió hacer aún más cosas con mucho menos código, ya que la responsabilidad de ajustar y mantener todo dentro de los estándares pasó a ser del compilador. A nosotros nos quedó la responsabilidad de indicar al compilador qué tipo de dato primitivo se debe utilizar.
Sin embargo, las posibilidades podrían ampliarse aún más, permitiéndonos manipular de manera controlada las cosas cuando uno u otro tipo primitivo de dato se utilice en nuestro código. Para realizar este control, pasamos a utilizar typename, que nos permite saber el nombre del tipo utilizado, ya sea por el compilador o por la variable que queremos manipular.
Sé que muchos de ustedes, sobre todo los principiantes, pueden encontrar todo esto muy complicado y confuso. Sin embargo, conviene recordar que aún estamos en el nivel que considero el más básico y simple posible. Por eso, te aconsejo, querido y estimado lector, que estudies y practiques lo que se ha mostrado. Enfócate principalmente en estudiar cada punto que se ha explicado en estos artículos hasta el momento, pues de aquí en adelante la cosa solo tiende a volverse cada día más complicada e interesante. Y para aquellos a los que de verdad les gusta programar, estamos a punto de entrar en un nuevo parque de atracciones llamado MQL5.
Entonces, nos vemos en el próximo artículo, donde abordaremos un tema aún más interesante y divertido.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15671
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso