
Del básico al intermedio: Struct (II)

En el artículo anterior, "Del básico al intermedio: Struct (I)", empezamos a tratar un tema que, en mi opinión, es muy importante comprenderlo bien, ya que nos permite hacer muchas cosas de forma mucho más sencilla. Sin embargo, la verdadera importancia de comprender todos los detalles involucrados cuando el tema son las estructuras radica precisamente en el hecho de que se encuentran a medio camino entre la programación orientada a objetos y la programación convencional.
Pero como este tema está empezando, todavía tenemos mucho de qué hablar antes de poder decir: «Sí, ya sé cómo trabajar con estructuras».
Cómo usar estructuras en funciones y procedimientos
Una de las cosas que hace que muchos principiantes se pierdan al trabajar con estructuras es la cuestión de si deben o no pasar valores usando estructuras. Pues bien. De hecho, esta es una cuestión bastante intrigante que, en algunos momentos, termina generando más dudas que cualquier otra cosa. La razón, para aquellos que creen que es algo fácil de resolver, es precisamente el hecho de que podemos pasar variables por referencia, ya sea a una función o a un procedimiento. En estos casos, debemos tener cuidado al trabajar con estructuras.
Yo, que soy de la vieja escuela, viví una época en la que no podíamos transferir datos mediante estructuras en el lenguaje C de forma directa. Hoy en día ya es posible hacerlo, pero hubo un tiempo en el que necesitábamos utilizar otros mecanismos para efectuar dichas transferencias. En este tipo de escenarios, las posibilidades de error aumentan a medida que se añaden más variables a la estructura. Pero eso es pasado. Hoy en día tenemos mecanismos más seguros para realizar el mismo tipo de transferencia. No obstante, esto no te impide utilizar antiguas técnicas de implementación de código, en las que la seguridad no es el foco principal, sino la velocidad de procesamiento de la información.
Sin embargo, aunque es posible hacer estas cosas, NO VOY a explicar cómo implementarlas, ya que son muy difíciles y conllevan un alto riesgo de cometer errores. Por esta razón, vamos a aprender a hacer las cosas de la forma correcta. En primer lugar, querido lector, debes comprender que no siempre es necesario pasar una estructura entre rutinas diferentes. Es decir, una función o procedimiento no tiene por qué saber si está trabajando con una estructura de datos o con valores discretos.
En cierto modo, cuando utilizamos los mecanismos ya mostrados y explicados en otros artículos, podemos hacer que el código sea mucho más flexible y fácil de usar. Por esta razón, al pasar a utilizar estructuras, podemos terminar limitando ciertas actividades de una rutina determinada.
Para entenderlo, veamos un primer código muy sencillo, que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. MqlDateTime dt; 07. 08. TimeToStruct(TimeLocal(), dt); 09. 10. Print(DateToString(dt.day, dt.mon, dt.year)); 11. Print(DateToString(3, 15, 2024)); 12. } 13. //+------------------------------------------------------------------+ 14. string DateToString(int day, int month, int year) 15. { 16. if ((day < 1) || (day > 31) || (month < 1) || (month > 12)) 17. return "ERROR..."; 18. 19. return StringFormat("%02d/%02d/%d", day, month, year); 20. } 21. //+------------------------------------------------------------------+
Código 01
Al ejecutarse, este código 01 producirá el resultado que se puede observar a continuación.
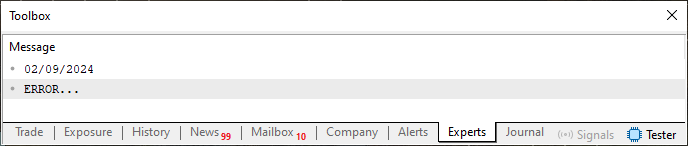
Imagen 01
Observa que en este código 01 no utilizamos nada muy complejo ni difícil de entender. Sin embargo, cuando ejecutes este código, el resultado que obtengas será con toda seguridad diferente al que se muestra en la imagen 01. Y el motivo es simple: el uso de la función TimeLocal. Esta función de la biblioteca estándar de MQL5 tiene como objetivo capturar el valor actual del reloj y devolverlo en formato datetime. Este formato, que ocupa ocho bytes, contiene información sobre la hora y la fecha actuales del lugar donde se está ejecutando MetaTrader 5, y se contabiliza en segundos. Pero esto no nos importa, no hasta el punto de necesitar entrar en más detalles. Sin embargo, el mismo valor que TimeLocal devuelve se utiliza por la función TimeToStruct para rellenar la estructura MqlDateTime. Y es aquí donde realmente queremos llegar. La estructura MqlDateTime se declara como se muestra a continuación.
struct MqlDateTime { int year; int mon; int day; int hour; int min; int sec; int day_of_week; int day_of_year; };
Declaración MqlDateTime
Ahora presta atención a lo que voy a explicar, pues es importante para entender lo que estamos haciendo en el código 01. La función TimeToStruct descompone el valor de 64 bits, conocido como datetime, en valores para asignar un valor adecuado a cada una de las variables de la estructura mostrada en la declaración anterior. Existen otras formas de hacerlo. Sin embargo, esa no es la cuestión que estamos tratando aquí. Lo importante es que, una vez asignados los valores, podemos utilizarlos como se muestra en la línea 10 del código 01. Pero ten en cuenta que esto solo ha sido posible porque en la función de la línea 14 estamos utilizando argumentos de tipo primitivo para recibir los datos. Esto nos permite prescindir de valores innecesarios y utilizar únicamente los que necesitamos.
Sin embargo, este mismo enfoque también nos permite hacer uso de lo que se ve en la línea 11. Pero, debido a la prueba de la línea 16, terminamos haciendo que la rutina de la línea 14 devuelva un error, ya que NO TENEMOS la posibilidad de un año con quince meses.
Es a este tipo de cosas a las que me refería, ya que este enfoque que se muestra aquí, en el código 01, se podría implementar de diversas maneras, como se observa en el código 02 más abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. MqlDateTime dt; 07. 08. TimeToStruct(TimeLocal(), dt); 09. 10. Print(DateToString(dt)); 11. dt.day = 3; 12. dt.mon = 15; 13. dt.year = 2024; 14. Print(DateToString(dt)); 15. } 16. //+------------------------------------------------------------------+ 17. string DateToString(MqlDateTime &arg) 18. { 19. if ((arg.day < 1) || (arg.day > 31) || (arg.mon < 1) || (arg.mon > 12)) 20. return "ERROR..."; 21. 22. return StringFormat("%02d/%02d/%d", arg.day, arg.mon, arg.year); 23. } 24. //+------------------------------------------------------------------+
Código 02
En este caso, obtendríamos el mismo resultado que se observa en la imagen 01. Sin embargo, sería mucho más fácil entender el motivo del error, ya que al observar la línea doce de este código 02 se percibe claramente lo que está mal. No obstante, fíjate en que en la línea 17 fue necesario pasar la estructura por referencia, lo cual puede ser un problema, aunque también se soluciona fácilmente, ya que solo necesitamos hacer que el argumento recibido se vea como una constante. Cómo hacer esto ya se explicó en otros artículos. En cualquier caso, la función tiene ahora muchos más privilegios que antes, ya que puede visualizar más datos de los necesarios para su funcionamiento. Por este motivo, no existe una respuesta clara sobre cómo utilizar las estructuras en funciones o procedimientos, ya que puedes estar pasando mucha más información de la necesaria.
Este concepto, que es el del conocimiento mínimo que una función o procedimiento debe tener sobre otros datos, se utiliza y menciona mucho más cuando se habla de clases y objetos. Esto se debe a que en la programación orientada a objetos este concepto está mucho más presente de lo que puedes imaginar, querido lector. Pero esto es un tema para tratar en el futuro. Por ahora, necesitas entender que, cuanto menos tenga que saber una rutina (ya sea un procedimiento o una función), mejor. Así necesitamos declarar y transmitir menos información, lo que agiliza la implementación y futuras correcciones y mejoras en el código.
Vale, pero estos dos códigos que acabamos de ver están relacionados con un tipo de actividad concreto. Sin embargo, es posible que necesites crear estructuras personalizadas, aunque MQL5 ya nos proporciona doce tipos diferentes de estructuras previamente definidas. En otro momento, abordaremos cada una de estas estructuras, aunque ya hemos hablado un poco sobre una de ellas: MqlDateTime. Pero eso fue solo una breve presentación de lo que realmente podemos y vamos a hacer más adelante.
Muy bien, pero ahora es posible que te preguntes cómo implementar algo que vaya a utilizar una estructura que hayas creado. Para responder a esta pregunta de manera adecuada, vamos a crear un nuevo tema, ya que no quiero mezclar las cosas. Aunque la respuesta tenga alguna relación con este tema, no quiero mezclar las cosas.
Trabajo con estructuras personalizadas
Aunque la respuesta a la pregunta del final del tema anterior tenga mucho que ver con el tema, quiero separar las cosas para que el material sea lo más didáctico posible. Esto se debe a que, cuando usamos una de las doce estructuras previamente definidas en MQL5, podemos implementar las cosas de una manera determinada. Sin embargo, cuando vamos a implementar algo haciendo uso de alguna estructura que hayamos creado, muchas veces necesitamos hacerlo de otra manera. Esto se debe a cuestiones que se explicaron en el artículo y el tema anteriores. Pero existe otra cuestión que abordaremos pronto.
Pero, antes de eso, vamos a entender una cosa:
Una estructura es un tipo especial de dato que puede contener cualquier tipo de información.
Esta frase es muy importante y debes comprenderla correctamente. Cuando comprendes qué es realmente una estructura, te resulta más fácil entender cómo implementarla y utilizarla en tus códigos. Entonces, querido lector, entiende que una estructura no es diferente de un tipo uchar, double u otro cualquiera. Al igual que estos tipos permiten colocar y trabajar con valores contenidos en ellos, podemos hacer lo mismo con las estructuras. Algo similar a lo que se mostró con las uniones, que en este caso no serían un tipo especial de dato, sino un conjunto de datos que comparten una región común de memoria.
Para reforzar la idea de que una estructura es un tipo especial de dato, pensemos en registros de inscripción. En un registro de inscripción podemos incluir diversa información, como por ejemplo: nombre, apellidos, dirección, profesión, contactos, etc. En fin, todos estos datos podrían organizarse de manera que tuvieran el mismo formato de registro de inscripción, lo que permitiría manipularlos de forma muy sencilla.
Básicamente, hay dos maneras de hacerlo. La primera es crear una serie de variables para contener la información que queremos y necesitamos mantener en el registro. Estas variables estarían dispersas por todo el código. Sería más o menos como podemos ver justo abajo. Por supuesto, esto es solo un ejemplo hipotético.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. string Name, 07. Surname, 08. Address, 09. Position; 10. double Remuneration; 11. datetime Birth, 12. Hiring; 13. . . . Registration routines . . .
Código 03
A menos que estés creando una aplicación cuyo propósito sea manejar solo un registro, es difícil que un código real tenga una apariencia como la del código 03. Sin embargo, es posible que tengas un código con esa apariencia siempre y cuando los registros se almacenen en disco. Pero en este punto surgen algunos problemas, entre ellos el orden en que las variables necesitan ser almacenadas. No obstante, este problema no es el que nos interesa en este momento, sino otro: lidiar con el cruce o las relaciones entre datos de diferentes registros.
De acuerdo, ¿cómo podrías lidiar con esto? En la práctica, lo más común sería crear arrays. Como ya hemos hablado de los arrays, seguramente pensarías en crear algo como lo que se muestra justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. #define def_Number_of_Records 10 07. 08. string Name[def_Number_of_Records], 09. Surname[def_Number_of_Records], 10. Address[def_Number_of_Records], 11. Position[def_Number_of_Records]; 12. double Remuneration[def_Number_of_Records]; 13. datetime Birth[def_Number_of_Records], 14. Hiring[def_Number_of_Records]; 15. . . . Registration routines . . .
Código 04
Como puedes ver, ahora podemos trabajar con varios registros a la vez. Sin embargo, aunque esta técnica funciona, es bastante rudimentaria. El motivo es que, si necesitamos añadir algún campo más o eliminar uno, tendremos mucho trabajo para una edición sencilla. Y eso que estoy hablando solo en términos de aplicación, no de uso. Sin embargo, al observar este código 04 y teniendo en cuenta lo que se ha mostrado hasta ahora sobre estructuras, pensarás: «¿No podríamos incluir todo lo visto en el código 04 dentro de una estructura?». Y es precisamente en este punto donde la cosa empieza a tener sentido, porque toda la complicación que hemos visto en los demás códigos se reduce a lo que se muestra justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. #define def_Number_of_Records 10 07. 08. struct st_Register 09. { 10. string Name, 11. Surname, 12. Address, 13. Position; 14. double Remuneration; 15. datetime Birth, 16. Hiring; 17. }; 18. 19. st_Register Record[def_Number_of_Records]; 20. . . . Registration routines . . .
Código 05
Fíjate en cómo fue surgiendo todo de forma natural. No fue necesario crear una serie de aplicaciones para que la idea tomara forma y pasara a tener sentido. Sin embargo —y ahora viene lo divertido—, la estructura declarada en la línea ocho de este código 05 solo será accesible dentro del procedimiento OnStart o donde haya sido declarada. En este caso, debes tener en cuenta que la estructura st_Register no se puede utilizar para pasar algo a una función o procedimiento, como se hacía en el código 02, por lo que es necesario adoptar un enfoque similar al del código 01 para poder utilizar cualquier información de la estructura declarada en la línea ocho del código 05.
Esto, en algunos casos, puede ser problemático. Sin embargo, en otros casos, puede ser justo lo que necesitamos. En cualquier caso, en general, las estructuras, a diferencia de las uniones, se declaran con un ámbito global, precisamente para permitirnos transferir datos de manera más cómoda y práctica.
Quien ya haya estudiado, aunque sea de manera muy superficial, lenguajes como Python o JavaScript, sabrá que es muy común usar algo como lo que se ve justo debajo.
cmd_entry.pack(fill='x', side='left' , expand=1)
En esta línea de código, que puede ser tanto de Python como de JavaScript, tenemos algo que no tiene el menor sentido para quien utiliza MQL5, C o C++. Esto se debe a que, cuando se observa algún valor asignado a una variable en una llamada, se está asignando un valor a una variable presente en el código, ya sea global o local. Sin embargo, de cualquier manera, si buscas esa variable, se encontrará en uno de esos ámbitos. Esto hablando en términos de MQL5, C o C++.
Sin embargo, si vemos este mismo fragmento en un código Python o JavaScript, no estamos asignando un valor a una variable. Sé que esto parece completamente ilógico. Sin embargo, estamos asignando un valor a algo similar a una estructura. Precisamente por este motivo, podemos asignar valores a cualquier elemento sin necesidad de seguir un orden previamente establecido, cosa que sí sería obligatoria en MQL5, por ejemplo.
Sin embargo, si miramos este mismo código, que podría estar escrito en Python o JavaScript, como una estructura similar a la de MQL5, todo pasaría a tener sentido. Esto convertiría el traspaso de valores entre funciones y procedimientos en algo mucho más simple y agradable, sobre todo si hay muchos argumentos que transferir.
Ahora presta atención, pues esto puede marcar la diferencia en la forma en que vas a abordar diferentes problemas. En algunos artículos anteriores, hablamos sobre la posibilidad de crear sobrecarga de funciones y procedimientos. Esto nos permite trabajar con diferentes tipos y cantidades de argumentos en una función o procedimiento. Sin embargo, si en algunos de estos momentos utilizáramos estructuras para pasar esos valores, algunos casos en los que sería necesaria la sobrecarga ya no lo serían. Esto se debe a que podemos pasar un número arbitrario de argumentos simplemente porque estén en una estructura.
Te ha entrado la curiosidad, ¿verdad? Pues no hay una forma perfecta y definitiva de hacer nada. Sin embargo, hay maneras que pueden ser más o menos interesantes, dependiendo, claro, de cada caso concreto.
Entonces hagamos lo siguiente: Supongamos entonces que el código 05 utiliza diversas funciones y procedimientos y que necesitamos transmitir más o menos argumentos en cada uno de ellos. Podrías utilizar el enfoque del código 01 para tener un control sobre cada argumento, pero tendrías el inconveniente de que necesitarías usar la sobrecarga en varios momentos. No obstante, también podrías adoptar el enfoque del código 02, aunque, en este caso, el inconveniente sería el riesgo de que se modificara algún valor sin que te dieras cuenta. Sin embargo, existe una solución que, en muchos casos, se adoptaría de hecho. Esta solución consiste precisamente en usar una función cuando se quiere modificar algo y un procedimiento cuando solo se quiere consultar.
En cualquier caso, la estructura declarada en la línea ocho del código 05 debería salir del ámbito local y adoptarse en el global, como se puede ver en el código hipotético de abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Register 05. { 06. string Name, 07. Surname, 08. Address, 09. Position; 10. double Remuneration; 11. datetime Birth, 12. Hiring; 13. }; 14. //+------------------------------------------------------------------+ 15. void OnStart(void) 16. { 17. st_Register Record[10]; 18. uchar Counter = 0, 19. Index; 20. 21. Index = Counter; 22. Counter += (NewRecord(Record[Counter], "Daniel", "Jose", "Brasil", "1971/03/30") ? 1 : 0); 23. Record[Index] = UpdatePosition(Record[Index], "Chief Programmer"); 24. Index = Counter; 25. Counter += (NewRecord(Record[Counter], "Edimarcos", "Alcantra", "Brasil", "1974/12/07") ? 1 : 0); 26. Record[Index] = UpdatePosition(Record[Index], "Programmer"); 27. Index = Counter; 28. Counter += (NewRecord(Record[Counter], "Carlos", "Almeida", "Brasil", "1985/11/15") ? 1 : 0); 29. Record[Index] = UpdatePosition(Record[Index], "Junior Programmer"); 30. Index = Counter; 31. Counter += (NewRecord(Record[Counter], "Yara", "Alves", "Brasil", "1978/07/25") ? 1 : 0); 32. Record[Index] = UpdatePosition(Record[Index], "Accounting"); 33. 34. Print("Number of records: ", Counter); 35. ViewRecord(Record[3]); 36. } 37. //+------------------------------------------------------------------+ 38. bool NewRecord(st_Register &arg, const string Name, const string Surname, const string Address, const string Birth) 39. { 40. arg.Name = Name; 41. arg.Surname = Surname; 42. arg.Address = Address; 43. arg.Birth = StringToTime(Birth); 44. arg.Hiring = TimeLocal(); 45. 46. return true; 47. } 48. //+------------------------------------------------------------------+ 49. st_Register UpdatePosition(const st_Register &arg, const string NewPosition) 50. { 51. st_Register info = arg; 52. 53. info.Position = NewPosition; 54. 55. return info; 56. } 57. //+------------------------------------------------------------------+ 58. void ViewRecord(const st_Register &arg) 59. { 60. PrintFormat("Collaborator: %s, %s\nPosition: %s\nBirth in: %s", 61. arg.Surname, 62. arg.Name, 63. arg.Position, 64. TimeToString(arg.Birth, TIME_DATE)); 65. } 66. //+------------------------------------------------------------------+
Código 06
Sé que este código 06 es algo bastante subjetivo, ya que muchos consideran que es poco probable que llegue a crearse. Pero, aunque se trate solo de un ejemplo hipotético, contiene muchos elementos y cuestiones que verás en el mundo real. Cuando se ejecute, generará lo que se muestra en la imagen de abajo.
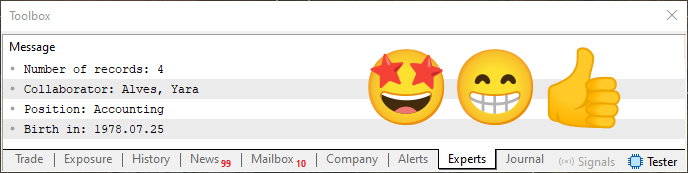
Imagen 03
Ahora, observa que aquí se están realizando diversas cosas. Y, aunque para algunos este código pueda parecer muy complicado y difícil de entender, para quien ha estudiado y practicado lo que se ha mostrado en los artículos, este código es bastante simple, claro y directo. Pero como aquí tenemos algunos elementos que pueden resultar extraños, como las fechas de nacimiento, voy a dar una explicación rápida sobre lo que ocurre.
En la línea cuatro, declaramos nuestra estructura de datos. Observa que está declarada en ámbito global. Por esta razón, podrá utilizarse en varios puntos fuera del bloque de código principal, es decir, del procedimiento OnStart. Ahora, dentro de este bloque principal, tenemos la declaración de la línea 17, cuyo objetivo es crear una lista de información. Es decir, nuestra estructura se tratará como si fuera un tipo de variable especial. A continuación, entre las líneas 21 y 32, podemos añadir registros a nuestra lista de información. Recuerda que cada valor dentro del array sería como si fuera un elemento completamente distinto. Sin embargo, como estamos estructurando todo en un único bloque (la estructura declarada en la línea cuatro), da la impresión de que cada elemento estaría físicamente ligado a los demás, creando así una hoja de registro.
En cada llamada entre las líneas 21 y 32, intentamos añadir un nuevo registro a nuestro array. Esto se realiza a través de la llamada a la línea 38. Observa que le estamos dando a la función de la línea 38 los privilegios mínimos necesarios. Es decir, solo le facilitamos algunos datos, mientras que otros pueden asignarse directamente desde la propia rutina, como ocurre en la línea 44, donde obtenemos la fecha actual y la utilizamos para informar sobre el momento de la contratación. En la práctica, esto se hace muchas veces, ya que, cuando se registra a un nuevo colaborador, es cuando se le contrata. Por esta razón, podemos permitir que la función de la línea 38 asigne un valor a la estructura de retorno, valor que no se transmite como argumento de la propia llamada.
Naturalmente, en un código real existe una serie de pruebas para garantizar que no se produzcan errores durante la fase de registro. Sin embargo, como este código es solo didáctico, tales pruebas resultan completamente innecesarias.
Muy bien, como cada registro necesita otros datos que no se están pasando directamente como argumentos a la función NewRecord, presente en la línea 38, usamos la línea 49 para actualizar o asignar algún valor específico al registro ya creado. En un código real, se realizarían varias pruebas aquí.
Sin embargo, el objetivo de esta función de la línea 49 es precisamente mostrar cómo se puede devolver un valor, que en este caso sería la propia estructura generada dentro de la función. Esta práctica nos permite tener un mayor control sobre cuándo y dónde vamos a cambiar los valores de una estructura.
Observa que, a diferencia de lo que ocurría en la línea 38, donde la estructura de entrada se modificaba de manera permanente, aquí, en la línea 49, modificamos la estructura y se la devolvemos al autor de la llamada. Será responsabilidad del autor de la llamada encontrar el lugar adecuado para utilizar lo que fue devuelto por la función. Y sí, mi querido lector, puedes utilizar este retorno de diversas maneras, como se verá más adelante.
En cualquier caso, al final tenemos un pequeño procedimiento para visualizar algún registro. Así obtenemos lo que se puede ver en la imagen 03.
Ahora bien, ¿sería posible crear el mismo código 06 de modo que el trabajo se realice de una forma un poco diferente? Sí, y es precisamente esto lo que podemos ver en el código de abajo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. struct st_Register 005. { 006. uchar ID; 007. string Name, 008. Surname, 009. Address, 010. Position; 011. double Remuneration; 012. datetime Birth, 013. Hiring; 014. }gl_Record[10]; 015. //+------------------------------------------------------------------+ 016. void OnStart(void) 017. { 018. uchar Index; 019. 020. ZeroMemory(gl_Record); 021. 022. NewCollaborator("Daniel", "Jose", "Brasil", "1971/03/30", "Chief Programmer"); 023. NewCollaborator("Edimarcos", "Alcantra", "Brasil", "1974/12/07", "Programmer"); 024. NewCollaborator("Carlos", "Almeida", "Brasil", "1985/11/15", "Junior Programmer"); 025. 026. Index = GetNumberRecord(); 027. 028. if (NewRecord(gl_Record[Index], "Yara", "Alves", "Brasil", "1978/07/25")) 029. { 030. gl_Record[Index].ID = Index + 1; 031. gl_Record[Index] = UpdatePosition(gl_Record[Index], "Accounting"); 032. } 033. 034. Print("Number of records: ", GetNumberRecord()); 035. Print("--------------------"); 036. 037. for(uchar c = 1; ViewRecord(c); c++) 038. Print("********************"); 039. } 040. //+------------------------------------------------------------------+ 041. bool NewCollaborator(const string Name, const string Surname, const string Address, const string Birth, const string Position) 042. { 043. st_Register info; 044. uchar Index = 0; 045. 046. if (!NewRecord(info, Name, Surname, Address, Birth)) 047. return false; 048. 049. info = UpdatePosition(info, Position); 050. 051. while (gl_Record[Index].ID) 052. { 053. if (Index >= gl_Record.Size()) return false; 054. Index++; 055. } 056. 057. info.ID = Index + 1; 058. gl_Record[Index] = info; 059. 060. return true; 061. } 062. //+------------------------------------------------------------------+ 063. bool NewRecord(st_Register &arg, const string Name, const string Surname, const string Address, const string Birth) 064. { 065. arg.Name = Name; 066. arg.Surname = Surname; 067. arg.Address = Address; 068. arg.Birth = StringToTime(Birth); 069. arg.Hiring = TimeLocal(); 070. 071. return true; 072. } 073. //+------------------------------------------------------------------+ 074. st_Register UpdatePosition(const st_Register &arg, const string NewPosition) 075. { 076. st_Register info = arg; 077. 078. info.Position = NewPosition; 079. 080. return info; 081. } 082. //+------------------------------------------------------------------+ 083. uchar GetNumberRecord(void) 084. { 085. uchar counter = 0; 086. 087. for (uchar c = 0; c < gl_Record.Size(); counter += (gl_Record[c].ID ? 1 : 0), c++); 088. 089. return counter; 090. } 091. //+------------------------------------------------------------------+ 092. bool ViewRecord(const uchar ID) 093. { 094. st_Register info; 095. 096. ZeroMemory(info); 097. 098. for (uchar c = 0; (c < gl_Record.Size()) && (!info.ID); c++) 099. info = (gl_Record[c].ID == ID ? gl_Record[c] : info); 100. 101. if (info.ID) 102. PrintFormat("Collaborator: %s, %s\nPosition: %s\nBirth in: %s", 103. info.Surname, 104. info.Name, 105. info.Position, 106. TimeToString(info.Birth, TIME_DATE)); 107. else 108. Print("Record ID [", ID ,"] not found."); 109. 110. return (bool) info.ID; 111. } 112. //+------------------------------------------------------------------+
Código 07
Vale, ahora sí que tenemos algo realmente complicado entre manos. Este código 07 es bastante más complejo. Porque no entiendo nada de lo que se está haciendo aquí. (RISAS). Bien, mi querido lector, en el fondo, este código 07 es muy simple. Para ser completamente honesto, en mi opinión, este código 07 es más simple que el código 06, a pesar de que hacen básicamente lo mismo. Sin embargo, entiendo que alguien pueda pensar que este código 07 es más complicado.
En primer lugar, porque ahora tenemos una declaración de variable global en la línea 14, lo que complica mucho las cosas. Pero antes de hablar un poco más sobre lo que hace este código 07, veamos el resultado de su ejecución. Puede observarse en la imagen siguiente.
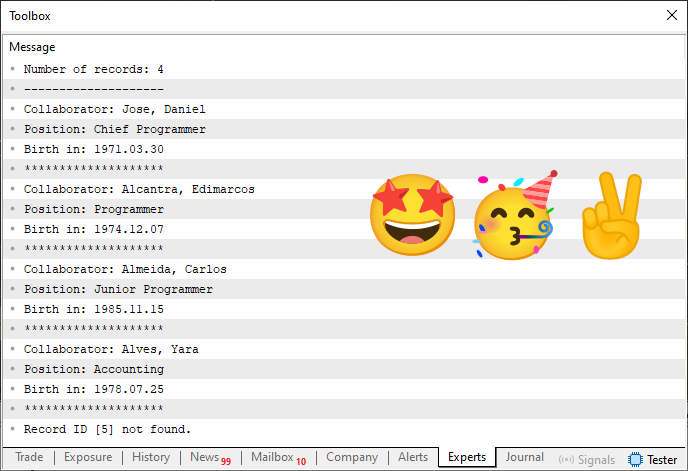
Imagen 04
Observa que todos los registros que estamos realizando dentro del bloque principal aparecen en esta imagen, lo que es perfecto, ya que indica que el código 07 está funcionando correctamente. Pero, ¿cómo se ha hecho esto, si ahora aparecen cosas diferentes? Bien, mi querido lector, como se dijo en el artículo anterior, las estructuras son un paso intermedio entre la programación convencional y la programación orientada a objetos. Sin embargo, aún estamos al principio de lo que realmente se puede hacer con las estructuras.
Sin embargo, observa que ahora estamos usando las líneas del 22 al 32 para incluir nuevos registros en el sistema. Mas, la forma en que se crean los registros entre las líneas 22 y 24 es más fácil de entender al principio, diferente de lo que ocurre entre las líneas 26 y 32. Allí estamos haciendo el mismo trabajo que realiza la función de la línea 41, solo que de manera completamente manual. El simple hecho de hacerlo así hace que el código sea más arriesgado. Esto se debe a que, si cometes algún error, puedes pasar horas intentando resolver el problema.
Pero quiero que estudies este código 07 para que lo comprendas de manera práctica. Compara el nivel de dificultad para obtener un resultado con el código 06 con la dificultad para obtener el mismo resultado con el código 07. Entender esto te ayudará a comprender mejor lo que se verá en el próximo artículo.
Sin embargo, la parte más compleja de este código es, tal vez, la función de la línea 92, que vamos a analizar. En primer lugar, en la línea 94, declaramos una estructura temporal. En la línea 96, limpiamos la región de memoria donde se colocará la estructura. Así, podemos utilizar las pruebas dentro del bucle visto en la línea 98 para saber cuándo se ha encontrado la ID buscada.
De este modo, en la línea 101 podremos verificar si hay algo que deba imprimirse en el terminal de MetaTrader 5. Si se ha encontrado la ID, imprimiremos el contenido de la estructura de registro. En caso contrario, se imprimirá el mensaje de la línea 108.
No obstante, como el valor de retorno de esta función debe ser de tipo booleano y la ID es un valor numérico, le indicamos al compilador que somos conscientes de este hecho. Así, en la línea 110, usamos una conversión explícita de tipo para devolver al llamante si hemos tenido éxito o no en la búsqueda de la ID requerida. Este retorno es importante para que el bucle de la línea 37 sepa cuándo debe detenerse.
Consideraciones finales
En este artículo, hemos visto cómo utilizar estructuras en códigos bastante simples. Aunque todo aquí tiene como objetivo la didáctica, pudimos construir algo que se parece mucho a una base de datos. Es muy cierto que una base de datos real necesitaría incluir diversas pruebas para evitar fallos. Sin embargo, creo que se alcanzó el objetivo principal, que era mostrar cómo concebir el concepto de estructuras.
Es decir, una estructura es una variable especial. Por tanto, querido lector, te recomiendo que estudies y practiques con los códigos que encontrarás en el anexo. Aunque no se haya hecho una explicación minuciosa de cada línea de código, imagino que no será necesario, ya que todo el contenido es fácil de entender para quien ha estudiado y practicado lo que se muestra en los artículos.
En el próximo artículo, veremos cómo podemos utilizar las estructuras de una manera aún más práctica e interesante para hacer el trabajo de codificación más sencillo.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15731
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso