
开发多币种 EA 交易(第 6 部分):自动选择实例组
概述
在上一篇文章中,我们实现了选择策略选项的功能 - 固定仓位大小和可变仓位大小。这样,我们就可以根据最大回撤率对策略的工作结果进行归一化处理,并将最大回撤率在规定范围内的策略合并为一组。为了演示,我们从单个策略实例的优化结果中手动选择了几个最有吸引力的输入参数组合,并尝试将它们组合成一组,甚至是三组三策略的组合。我们在后一种情况下取得了最好的结果。
但是,如果我们需要增加分组策略的数量和不同分组组合的数量,那么日常手工操作的工作量就会大大增加。
首先,我们需要在每个交易品种上采用不同的优化标准,优化策略的单个实例。此外,对于每个交易品种,可能有必要针对不同的时间框架分别进行优化。对于我们的特定模型策略,我们还可以按已下订单的类型(止损、限价或市场仓位)进行单独优化。
其次,有必要从结果参数集(约 2 到 5 万个)中选出少量(10 到 20 个)最佳参数。但是,它们不仅要独当一面,在小组合作时也要做到最好。逐个选择和添加策略实例也需要时间和耐心。
第三,将获得的组合并为更高的组,进行标准化。如果手动操作,只能承受两到三个级别。更多的分组级别似乎就太费力了。
因此,让我们尝试将 EA 开发的这一阶段自动化。
绘制路径图
遗憾的是,我们不太可能同时完成所有工作。相反,当前任务的复杂性可能会导致人们根本不愿意着手解决这一问题。因此,让我们至少从一个侧面来探讨这个问题。阻碍我们开始实施的主要困难是由此产生的问题:"这会给我们带来任何好处吗?能否在不降低质量(最好是提高质量)的情况下用自动选择代替手动选择?整个过程会不会比人工筛选还要长?
在找到答案之前,我们很难着手解决问题。因此,让我们这样做吧:我们当前的首要任务是测试 "自动分组选择可能有用" 这一假设。为了测试它,我们将在一个交易品种上获取一个实例的优化结果集,并手动选择一个好的归一化组。这将是我们比较结果的基线。然后,使用最少的成本,编写最简单的自动化程序,让我们来选择一个组。然后,我们将把自动选择的组的结果与手动选择的组的结果进行比较。如果比较结果显示出自动化的潜力,那么就有可能进一步、更美观、更正确地实施自动化。
准备初始数据
让我们下载实施前几部分时获得的 SimpleVolumesExpertSingle.mq5 EA 优化结果,并导出为 XML。
图 1.导出优化结果以便进一步处理
为了简化进一步的使用,我们将添加额外的列,其中包含不参与优化的参数值。我们需要添加交易品种、时间框架、最大订单数(maxCountOfOrders ),更重要的是添加拟合余额(fittedBalance)。我们将根据已知的净值最大相对回撤率计算后者的值。
如果我们使用 100,000 美元的初始余额,那么绝对回撤约为 100,000 *(relDDpercent / 100)。这个值应该是 fittedBalance 的 10%,因此我们可以得到:
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
我们将用常数 PERIOD_H1 表示代码中指定的时间范围值,其数值为 16385。
添加后,我们会得到一个数据表,并将其保存为 CSV 格式。转换后的表格第一行如下所示:
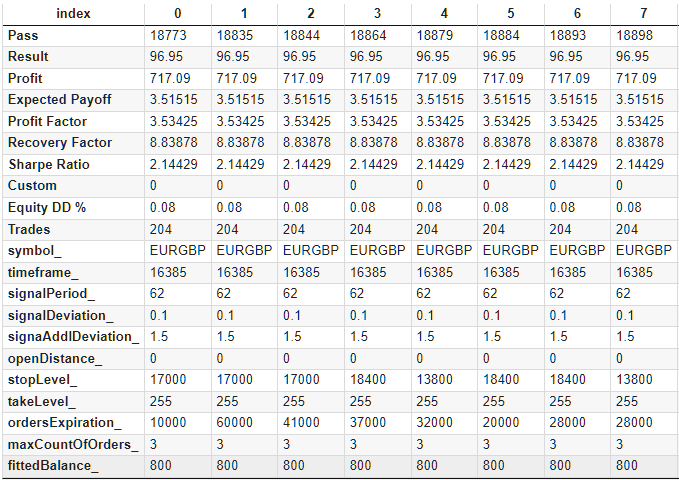
图 2.优化结果补充表
这项工作可以委托给计算机来完成,例如,可以使用 TesterCache 库,或在优化过程中采用其他方法来存储有关每次通过的数据。但我想以最小的工作量完成这项工作。因此,我将暂时手动完成这项工作。
该表包含利润小于零的记录(18,000 行中约有 1000 行)。我们肯定对这些结果不感兴趣,所以让我们立即删除它们。
在此之后,初始数据就可以用于构建基线版本,并随后用于选择可与基线版本竞争的策略组。
基线
准备基本版本是一个简单而单调的过程。首先,我们应该按照 "质量" 的递减顺序对我们的策略进行某种排序。让我们用下面的方法来评估质量。突出显示该表中包含各种性能指标的列集:利润、预期回报、利润因子、恢复因子、夏普比率、净值 DD %和交易次数。每个参数都要进行最小-最大缩放,从而得出 [0; 1] 范围内的结果。获取后缀为"_s"的其他列,并用它们计算每一行的总和,如下所示:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
并将其添加为新的表格列。按降序排序。
然后,我们将开始向下排列名单,把我们喜欢的候选者加入到组中,并立即检查它们的合作情况。我们将尝试添加参数和结果尽可能不同的参数集。
例如,在各组参数中,有一些参数仅在 SL 级别上有所不同。但如果在测试期间从未触发过这一级别,那么不同级别的测试结果将是一样的。因此,这种组合不能合并,因为它们的开仓和平仓时间会重合,因此最大回撤时间也会重合。我们要选择在不同时间发生回撤的样本。这将使我们能够提高盈利能力,因为仓位量可以减少,而不是与策略数量成比例地减少,而是减少次数。
让我们用这种方法选出 16 个标准化策略实例。
我们还将使用固定余额进行交易。为此,请设置 FixedBalance = 10000。在这种情况下,标准化策略的单个最大回撤为 1000。让我们来看看测试结果:
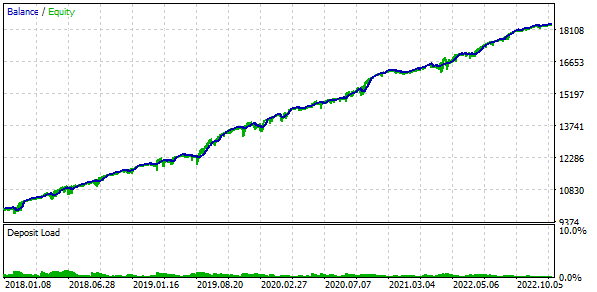
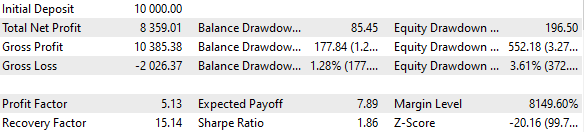
图 3.基础情况结果
事实证明,如果我们将 16 个策略组合起来,并将每个策略的仓位规模缩小 16 倍,那么最大回撤额就只有 552 美元,而不是 1000 美元。为了将这组策略转化为标准化组,我们进行了计算,以便应用等于 1000 / 552 = 1.81 的回撤因子Scale 来维持 10% 的回撤。
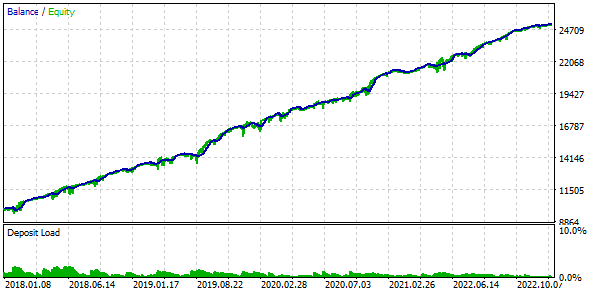

图 4. 标准化基础组的基本情况结果(Scale=1.81)
为了记住需要使用 FixedBalance= 10,000 和 Scale = 1.81,请将这些数字设置为相应输入的默认值。我们得到以下代码:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" input double expectedDrawdown_ = 10; // - Maximum risk (%) input double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.81; // - Group scaling multiplier input group "::: Other parameters" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Create and fill the array of all selected strategy instances CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Add a group of selected strategies to the strategies expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
将其保存在当前文件夹的 BaselineExpert.mq5 文件中。
用于比较的基本版本已经准备就绪,现在让我们来实现将策略实例选择到组中的自动化。
完善策略
我们需要替换为策略构造函数参数的输入参数组合目前存储在 CSV 文件中。这就意味着,从这里读取时,我们将接收到字符串类型的值。如果该策略有一个构造函数,它只接受一个字符串,并从中提取所有必要的参数,那就更方便了。例如,我计划使用 Input_Struct 库来实现这种向构造函数传递参数的方法。但现在,为了简单起见,让我们添加该类型的第二个构造函数:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Load the indicator to get tick volumes m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Set the size of the tick volume receiving array and the required addressing ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
该构造函数假定所有参数的值都按正确顺序排列在一个字符串中,并用逗号分隔。这样一个字符串作为构造函数的唯一参数传递,用逗号分割成若干部分,每部分在转换为适当的数据类型后,被分配给所需的类属性。
让我们将更改保存到当前文件夹中的 SimpleVolumesStrategy.mqh 文件。
完善 EA
让我们以 SimpleVolumesExpert.mq5 EA 为例。我们将在其基础上创建一个新的 EA,该 EA 将从我们之前用于手动选择的 CSV 文件中优化选择多个策略实例。
首先,让我们添加一组输入参数,以便加载策略实例参数列表并将它们选入组中。为简单起见,我们将把同时包含在一组中的策略数量限制为 8 个,并提供设置小于 8 个策略的功能。
input group "::: Selection for the group" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // File with strategy parameters (*.csv) sinput int count_ = 8; // Number of strategies in the group (1 .. 8) input int i0_ = 0; // Strategy index #1 input int i1_ = 1; // Strategy index #2 input int i2_ = 2; // Strategy index #3 input int i3_ = 3; // Strategy index #4 input int i4_ = 4; // Strategy index #5 input int i5_ = 5; // Strategy index #6 input int i6_ = 6; // Strategy index #7 input int i7_ = 7; // Strategy index #8
如果 count_ 小于 8,则枚举时只使用其中指定的定义策略索引的参数数。
接下来,我们遇到了一个问题。如果我们将包含 Params_SV_EURGBP_H1.csv 策略参数的文件放在终端数据目录下,那么只有在终端图表上启动 EA 时才会从该目录下读取参数。如果我们在测试器中运行,这个文件将不会被检测到,因为测试器使用自己的数据目录。当然,我们可以找到测试器数据目录的位置,然后将文件复制到那里,但这样做很不方便,也不能解决下一个问题。
下一个问题是,在运行优化时(这正是我们开发此 EA 的目的),数据文件将无法提供给本地网络中的代理集群,更不用说 MQL5 云网络代理了。
解决上述问题的临时办法是在 EA 源代码中包含数据文件的内容。但我们仍将尝试提供使用外部 CSV 文件的功能。为此,我们需要使用 MQL5 语言中的工具,如 tester_file 预处理器指令和 OnTesterInit() 事件处理函数。我们还将利用本地计算机上所有终端和测试代理的共同数据文件夹。
如《MQL5 参考》所述,tester_file 指令允许指定测试器的文件名。这意味着,即使测试器运行在远程服务器上,该文件也会被发送到远程服务器,并被放置在测试代理数据目录中。这似乎正是我们所需要的。但事实并非如此!该文件名应为常量,并应在编译时定义。因此,不可能用任意文件名来替代它,因为只有在开始优化时才会在 EA 输入参数中传递任意文件名。
我们必须采用以下变通方法。我们将选择一些固定的文件名,并将其设置在 EA 中。例如,它可以根据 EA 本身的名称来构建。我们将在 tester_file 指令中指定这个常量名称:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
接下来,我们将为策略参数集数组添加一个全局变量(字符串型)。我们将从文件中读取数据到这个数组中。
string params[]; // Array of strategy parameter sets as strings
让我们编写一个从文件加载数据的函数,其工作原理如下。首先,检查终端共享数据文件夹或数据文件夹中是否存在指定名称的文件。如果存在,我们就将其复制到数据文件夹中选定固定名称的文件中。接下来,打开具有固定读取名称的文件,并从中读取数据。
//+------------------------------------------------------------------+ //| Load strategy parameter sets from a CSV file | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Check if the file exists in the shared folder and in the data folder if(FileIsExist(fileName, FILE_COMMON)) { // If it is in the shared folder, then copy it to the data folder with a fixed name res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // If it is in the data folder, then copy it here, but with a fixed name res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // If there is a file with a fixed name, that is good as well if(FileIsExist(PARAMS_FILE)) { res = true; } // If the file is found, then if(res) { // Open it int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // If opened successfully if(f != INVALID_HANDLE) { FileReadString(f); // Ignore data column headers // For all further file strings while(!FileIsEnding(f)) { // Read the string and extract the part containing the strategy inputs string s = CSVStringGet(FileReadString(f), 10, 21); // Add this part to the array of strategy parameter sets APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
因此,如果在远程测试代理上执行该代码,那么启动优化的主 EA 实例中带有固定名称的文件将被传递到其数据文件夹中。要实现这一点,需要在 OnTesterInit() 事件处理函数中添加调用此加载函数。
在同一个处理函数中,我们将设置参数集索引迭代的范围值,这样就不必在优化参数设置窗口中手动设置了。如果我们需要从小于 8 的集合中选择一个组,那么我们也会在这里自动禁止枚举不必要的索引。
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
作为优化标准,选择在最大回撤为初始固定余额 10%的情况下可获得的最大利润。为此,请在 EA 中添加 OnTester() 处理函数,我们将在其中计算参数值:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
通过计算该参数,我们可以立即一次性获得有关信息,即如果我们考虑到在该次交易中实现的最大回撤,设置缩放系数使回撤达到 10%,可以获得多少利润。
在OnInit()EA 初始化处理函数中,我们还需要先加载策略参数集。然后,我们从输入参数中提取索引,检查其中是否有重复的索引。如果情况并非如此,则不会启动带有此类输入参数的通过。如果一切正常,则从策略参数集数组中提取具有指定索引的参数集,并将其添加到 EA 中。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Form the string from the parameter set indices separated by commas string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Turn the string into the array string indexes[]; StringSplit(strIndexes, ',', indexes); // Leave only the specified number of instances in it ArrayResize(indexes, count_); // Multiplicity for parameter set indices CHashSet<string> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Create and fill the array of all strategy instances CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Create and add selected groups of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
我们还需要在 EA 中至少添加 OnTesterDeinit() 空处理函数。这是具有 OnTesterInit() 处理函数的 EA 的编译器要求。
我们将把获得的代码保存在当前文件夹下的 OptGroupExpert.mq5 文件中。
简单组合
通过指定路径来创建包含交易策略参数集的 CSV 文件,从而启动对已实施 EA 的优化。我们将使用一种遗传算法,最大化用户标准,即按 10% 回撤率归一化的利润。我们使用相同的测试期进行优化 - 从 2018 年到 2022 年(含 2022 年)。
使用本地网络上的 13 个测试代理,完成超过 10,000 次运行的标准遗传优化块大约需要 9 个小时。令人惊讶的是,结果实际上优于基线集。这就是优化结果表顶部的样子:
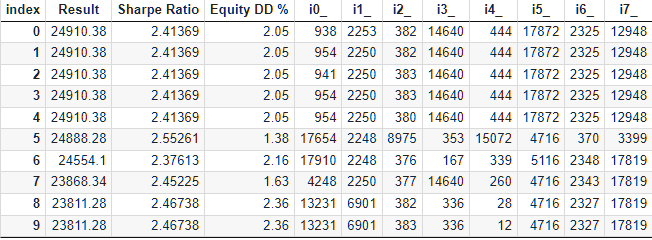
图 6.自动遴选小组的优化结果
让我们仔细看看最佳结果。要获得计算利润,除了指定表格第一行中的所有指数外,我们还需要将 scale_ 参数设置为指定的 10% 回撤(10,000 美元中的 1000 美元)与按净值计算的最大回撤之比。在表格中,我们用百分比来表示。不过,为了更准确地计算,最好是取绝对值而不是相对值。
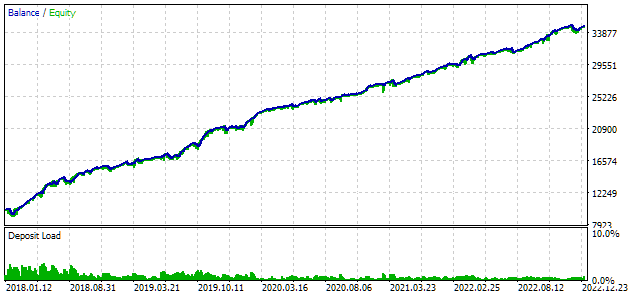
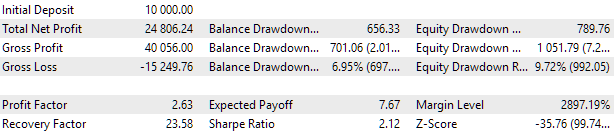
图 7.最佳组的测试结果
利润结果与计算结果略有不同,但差异很小,可以忽略不计。但很明显,自动选择找到的组别比人工选择的组别更好:利润是 24 800 美元,而不是 15 200 美元,好了一倍半多。这一过程不需要任何人工干预。这已经是一个非常令人鼓舞的结果。我们可以松一口气,并以更大的热情继续朝着这个方向努力。
让我们看看,在筛选过程中,我们是否有什么可以改进的地方,而无需花费大量精力。从表列出的各组策略选择结果中,我们可以清楚地看到,前五组的结果是相同的,它们之间的差异仅仅体现在参数集的一两个指标上。出现这种情况的原因是,在我们的原始文件中,有几组策略参数也给出了相同的结果,但在一些不太重要的参数上却存在差异。因此,如果给出相同结果的两组不同数据分为两组,那么这两组可能会产生相同的结果。
这也意味着在优化过程中,可以将多组“相同”的策略参数合并为一组。这导致我们为减少回撤而努力实现的组别多样性下降。让我们试着摆脱这种 "完全相同" 的组合最终被归为一组的优化通过。
聚类的组合
为了去除这些组,我们将把原始 CSV 文件中的所有策略参数集分成几个组。每个组都包含一组参数,这些参数给出完全相同或相似的结果。在聚类方面,我们将使用现成的 k-means 聚类算法。我们将把以下列作为聚类的输入数据:signalPeriod_、signalDeviation_、signaAddlDeviation_、openDistance_、stopLevel_和takeLevel_。让我们尝试使用以下 Python 代码将所有参数集分成 64 个群集:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False)
现在,我们的参数集文件中又多了一列群集编号。要使用该文件,让我们在 OptGroupExpert.mq5 的基础上创建一个新的 EA,并对其进行一些小的添加。
让我们添加另一个集合,并将初始化时包含所选参数集的群集数填入其中。只有当这组参数集的所有群集数都不同时,我们才会启动这样的运行。由于从文件中读取的字符串末尾包含一个与策略参数无关的群集编号,因此我们需要在将其传递给策略构造函数之前,将其从参数字符串中删除。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Multiplicities for parameter and cluster set indices CHashSet<string> setIndexes; CHashSet<string> setClusters; // Add all indices and clusters to the multiplicities FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique || setClusters.Count() != count_ // not all clusters are unique ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Remove the cluster number from the parameter set string string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Add a strategy with a set of parameters with a given index APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Form and add a group of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
将此代码保存在当前文件夹下的 OptGroupClusterExpert.mq5 文件中。
这种优化安排也暴露出自身的不足。如果遗传算法的初始种群中出现了太多至少有两个相同参数集指数的个体,就会导致种群迅速退化,优化算法过早终止。但是,如果再进行一次运行,我们可能会更幸运一些,然后优化就会到达终点,并找到相当好的结果。
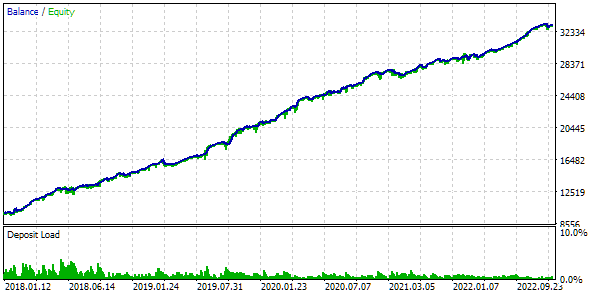
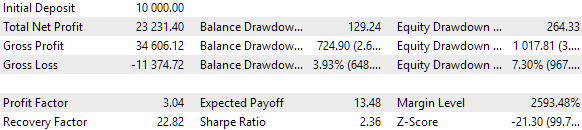
图 8.最佳分组聚类测试结果
通过混合输入参数集或减少组内策略的数量,可以提高防止种群退化的概率。无论如何,与不进行聚类的优化相比,用于优化的时间减少了一倍半到两倍。
群集中的一个实例
还有另一种防止种群退化的方法:在文件中只留下属于特定群集的一个集合。我们可以使用以下 Python 代码生成包含此类数据的文件:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
对于这个包含数据的 CSV 文件,我们可以使用本文中编写的两个 EA 中的任何一个进行优化。
如果发现剩下的数据集太少,那么我们可以增加群集数量,或者从一个群集中抽取几个数据集。
让我们看看该 EA 的优化结果:
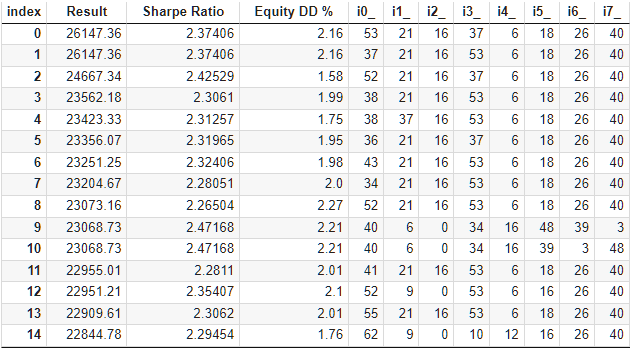
图 9.按 64 个组进行自动筛选的优化结果
它们与前两种方法大致相同。其中一个组的发现超过了之前发现的所有组。虽然这更多的是运气问题,而不是设定上限的优越性。以下是最佳小组的单个通过成绩:
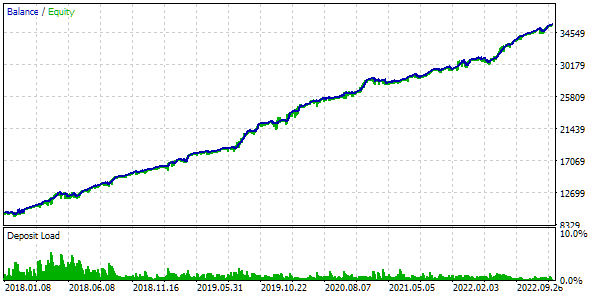
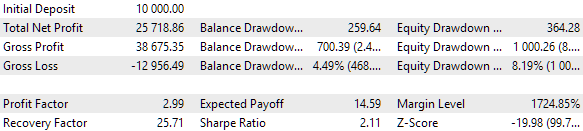
图 10.群集中一组最佳组的测试结果
从结果表中可以看出,各组之间有明显的重复,区别仅在于策略参数集的索引顺序不同。
要避免这种情况,可以在 EA 中增加一个条件检查,即输入参数中的索引组合必须构成一个递增序列。但是,由于种群的退化速度非常快,这又给遗传优化的使用带来了问题。要进行完整的枚举,即使从 64 个集合中选择一组 8 个集合,也会产生过多的通过。有必要以某种方式改变将 EA 的迭代输入转换为策略参数集索引的方法。但这些已经是未来的计划。
值得注意的是,当使用群集中的一个数据集时,在优化的最初几分钟就能发现与人工选择结果(利润约为 15,000 美元)相当的结果。然而,为了获得最佳结果,我们需要等到优化工作接近尾声的时候。
结论
让我们看看有什么收获。我们已经证实,与人工选择相比,自动选择参数组可产生更好的盈利结果。这个过程本身需要更多时间,但这次不需要人的参与,这是非常好的。此外,如果有必要,我们还可以通过使用更多的测试代理来大幅降低成本。
现在我们可以继续前进了。如果我们有能力选择策略实例组,那么我们就可以考虑从获得的优秀组中自动创建组。就 EA 代码而言,区别仅在于如何正确读取参数,并在 EA 中添加不同的策略组。在这里,我们可以考虑采用统一的格式,将策略和组的优化参数集存储在数据库中,而不是单独的文件中。
如果能在进行参数优化的测试期间之外,看看我们的优秀小组在测试期的表现,那就更好了。这也许就是我将在下一篇文章中尝试做的事情。
感谢您的关注!期待很快与您见面!
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/14478
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
维克托,谢谢你的反馈!
我也不知道 Excel 中有什么特殊函数,我是这样做的:
谢谢尤里。
但您在书中写到,要在利润、预期回报、利润因子、恢复因子、夏普比率、净值 DD %、交易等 列中添加_s。我应该按照什么顺序添加才能使其生效?是在原始列之后添加每一列,还是全部添加到表格末尾?您能否像编辑表格一样截图显示列名,或者附上一个已编辑的小文件作为示例。
另外,在优化智能交易系统时,您是设置了一个复杂的标准,还是只设置了平衡最大值?我试过了,我在通道中发现的交易次数不是很多,5 年来大约有 100-180 次交易。
请告诉我,如果我想让您的智能交易系统读取信号,并在给定时间框架内的新条形图开盘时打开交易,而不是像现在这样每隔一格就进行一次交易。我应该在哪里添加检查新条形图的功能?
加法的顺序只对如何更快地完成加法有影响。对我来说,在表格末尾添加这些列(AC:AI 列),然后在几个新列(AJ: AP)中 计算偏差,然后在 AQ 中求和 AJ:AP,然后在 AR 中找到最大缩放因子 Scale,并在 AS 中计算比率 Res = AR/AQ,这样 会更快。要按其排序,您必须将 AS 中的值复制到新的 AT 列中。我附上了一个示例。
我从复杂标准开始优化,然后再优化所有其他标准。交易数量 可以不同,包括相对较小的交易。这取决于 SL 和 TP 水平的大小。
在下一篇文章中,我计划向大家介绍检查新栏的功能,以及如何在此应用。
在下一篇文章中,我计划向大家介绍检查新条形图的功能,以及如何在此应用。
尤里,谢谢你提供的示例表,我知道它来自上一篇文章 (7),它也会很有用,但我要求你提供这篇文章 (6) 中表格的示例,你将其输入OptGroupClusterExpert.mq5 Expert Advisor 的输入中。据我所知,该表名为 Params_SV_EURGBP_H1-with_cluster.csv 和 Params_SV_EURGBP_H1.csv。这就是我向您提出的要求。请附上这些表格作为示例。
关于下一篇文章让我们拭目以待:)如果能为每个策略添加时间过滤器(指定交易期的开始和结束时间)和一些指标过滤器(2-3个)就更好了。)
维克多,是的,的确,我在前面的表格示例中有点超前了。
我附上了Params_SV_EURGBP_H1.xlsx 的示例,因为 CSV 文件不再包含公式。您需要将其保存为 CSV 格式,如果 Excel 使用"; "作为分隔符,您需要在整个 CSV 文件中将"; "替换为","。Params_SV_EURGBP_H1-with_cluster.csv 文件是使用文章中提供的Params_SV_EURGBP_H1.csv 的 Python 代码自动获取的。
至于添加时间过滤器 和附加指标:所使用的架构允许这样做--您可以创建新的交易策略类(CVirtualStrategy 的后续类),并添加任何所需的过滤器和指标。我自己不打算使用时间过滤器,因为我从未通过引入时间限制来提高交易结果。我不打算在一个策略中使用很多指标,因为对输入信号进行强过滤对我来说并不那么重要。例如,可以通过将各使用一个不同指标的策略实例组合在一起来间接获得。
新文章 开发多币种 EA 交易(第 6 部分):自动选择实例组已发布:
作者:Yuriy Bykov