
Neural Networks in Trading: LSTM Optimization for Multivariate Time Series Forecasting (Final Part)

Introduction
In the previous article, we examined the theoretical foundations of the DA-CG-LSTM framework, specifically designed to address complex forecasting tasks involving dynamic multivariate time series.
Modern financial markets are complex dynamic systems in which numerous factors interact continuously: macroeconomic indicators, news events, interest rate changes, the behavior of major market participants, and many other, often latent, variables. Time series representing price and trading volume dynamics serve as the primary source of information about these processes. However, analyzing such data requires a model capable of simultaneously capturing both long-term trends and short-term fluctuations, while also distinguishing truly significant signals from background noise.
Traditional time series analysis methods often prove insufficiently flexible and lack sensitivity to the wide variety of market factors involved. Their limited ability to selectively focus on key features and time intervals results in a deterioration of forecasting accuracy under highly volatile market conditions. These limitations became the starting point for the development of the DA-CG-LSTM framework — an architecture that combines a dual attention mechanism with a modified recurrent block structure.
One of DA-CG-LSTM's key strengths is its flexibility in processing multimodal data. In real-world trading scenarios, it is essential to analyze not only price levels but also derived indicators and external economic events. The framework under consideration can dynamically adapt to changes in feature importance at each time step, automatically reallocating attention toward the most relevant sources of information. As a result, the model can effectively identify complex relationships among numerous features and adjust its forecasts according to the current market context.
Particularly valuable is the dual-stage attention mechanism implemented in the architecture. At the first level, the model focuses on features, determining which characteristics currently have the greatest influence on market dynamics. At the second level, attention shifts to temporal intervals. The model evaluates which segments of historical data are most informative for forecasting the most probable movement. This two-stage process enables deep information filtering, allowing the system to disregard secondary data and concentrate on genuinely significant signals, whether they involve major trend shifts or localized anomalies.
Another important advantage of DA-CG-LSTM is its high robustness to noisy data, which is critical for deployment in real market environments. Financial time series typically contain numerous random fluctuations caused not by underlying market mechanisms but by various external or internal stochastic factors. The modified CG-LSTM block within the framework acts as an adaptive filter capable of dynamically reducing the influence of noisy features. Through its internal mechanisms for managing feature and time-step weights, the model focuses on identifying stable, recurring price behavior patterns, thereby significantly improving forecasting performance.
Another distinctive characteristic of DA-CG-LSTM is its ability to process long time series efficiently without losing sensitivity to short-term changes. In conventional recurrent networks, increasing the length of the analyzed sequence often leads to gradient vanishing and a decline in the quality of long-range dependency modeling. In the architecture proposed by the framework's authors, this issue is addressed through an early-stage information filtering process based on primary attention and a specialized memory organization in the CG-LSTM block. This allows the model to maintain focus on long-term trends while also responding rapidly to short-term fluctuations, such as news releases or intraday volatility spikes.
As a result, the DA-CG-LSTM framework successfully combines adaptability to multidimensional data, deep information filtering capabilities, noise robustness, and good trainability over long temporal horizons. These qualities make it a powerful tool for building modern time series forecasting systems.
The DA-CG-LSTM algorithm is based on the sequential processing of data through several key modules.
At the first stage, the original representation of a multivariate time series passes through a primary attention module that weights the importance of individual features at each time step. This allows the model to compress and emphasize the most relevant information while eliminating unnecessary informational noise.
At the next stage, the data is passed to a secondary attention module, where the focus shifts to temporal intervals. The model evaluates which segments of historical data play a decisive role in generating future predictions.
The processed data is then fed into a modified CG-LSTM block, where features are aggregated according to their intrinsic importance and interactions. The CG-LSTM block differs from a conventional LSTM in that it incorporates additional control mechanisms that influence memory cell operations based on the significance of both features and time intervals. This enables more accurate modeling of complex multidimensional dependencies among market factors.
The final aggregated representation, formed through the two attention levels and the CG-LSTM block, is then used to predict the target variable — for example, the future price of an asset or the direction of its movement.
This multi-stage architecture enables the model to simultaneously capture both short-term and long-term dependencies, minimize the impact of noise, and adaptively modify its data processing strategy according to the current market context.
The authors' visualization of the DA-CG-LSTM framework is shown below.

In this article, we will take the next step in developing our own implementation of the approaches proposed by the authors of the DA-CG-LSTM framework using MQL5. The primary focus will be on designing the model architectures.
Model Architecture
As previously noted, the DA-CG-LSTM framework is built around two fundamental components: attention modules and the modified CG-LSTM recurrent block. Together, these elements form a robust architecture that provides the model with the flexibility, noise resilience, and ability to capture complex multi-level temporal dependencies required for financial market applications. Under conditions of high volatility and market uncertainty, such properties are not merely desirable — they are essential for building reliable trading systems.
In the practical section of the previous article, we thoroughly examined the process of implementing the CG-LSTM block in MQL5. The resulting component successfully performs three critical functions: feature filtering to eliminate unnecessary noise, efficient management of the model's internal state to preserve long-term information, and data aggregation across multiple temporal scales. Its ability to suppress unstructured noise while maintaining stable learning dynamics enables the construction of models that preserve forecasting accuracy over extended historical periods.
To identify and analyze relationships among features and temporal sequences, the authors of DA-CG-LSTM proposed an enhanced version of the linear attention mechanism. In our implementation, we decided to use the previously developed CNeuronLinearAttention object, created during the development of the Hidformer framework. Although the architectural details of the two solutions differ, their underlying concept remains the same.
Given these considerations, we chose to use the existing attention module without introducing additional modifications. This significantly accelerated the development process and minimized the risks associated with integrating new, insufficiently tested solutions. As a result, we now have a complete set of components required to build the DA-CG-LSTM framework.
The next logical step is to design the architecture of trainable models based on these components. Here, we moved beyond the traditional task of forecasting future time series values. In financial markets, it is important not only to predict price dynamics but also to use those predictions effectively when making trading decisions, optimizing both risk and potential returns.
To achieve this goal, we incorporated the best ideas from the HiSSD architecture, which has demonstrated high effectiveness in noise suppression and the processing of complex nonlinear dependencies. The DA-CG-LSTM structure was integrated into the encoder by constructing a latent space of global and local agent skills that describe the state of the market environment. This latent space serves as the foundation for subsequent stages of analysis and decision-making.
On top of this base structure, we implemented an Actor-Director-Critic reinforcement learning framework. This integration enables the system not only to generate forecasts but also to strategically select actions that maximize expected returns.
The architecture of the trainable models is defined in the CreateDescriptions method. Its parameters receive pointers to six dynamic array objects, each corresponding to a separate level of the overall model architecture:
- Environment State Encoder — responsible for constructing the latent space of agents' global skills. It generalizes information about the current market state, uncovering hidden relationships among the factors that influence market dynamics.
- Low-Level Controller — generates agents' local skills based on the analyzed environmental features. By interpreting them in the context of global skills, the controller synthesizes a tensor of possible actions representing the most promising trading scenarios while accounting for both short-term and long-term market trends.
- Actor — receives the action tensor from the controller and, evaluating it in the context of the current account state, risk level, and predefined strategic objectives, generates the final trading decision aimed at maximizing profit while controlling acceptable losses.
- Probabilistic Trend Forecasting Model — contributes to the formation of more informative global agent skills by enriching them with a probabilistic representation of the expected market direction. This enables the model to account for the probabilistic nature of market processes and construct more robust strategies.
- Director — performs preliminary action filtering, reducing the likelihood of decisions associated with excessively high risk. It guides the Actor's policy toward more conservative and reliable scenarios that are consistent with current market conditions.
- Critic — evaluates the effectiveness of selected strategies over the future time horizon and adjusts agent behavior to maximize cumulative long-term profit while maintaining a reasonable level of risk.
The CreateDescriptions method performs strict validation of all incoming pointers. When necessary, new instances of descriptive objects are created, ensuring the integrity and correctness of the model architecture throughout every stage of its construction.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Let us begin by describing the architecture of the environment state encoder. As in our previous work, the raw input data is fed into a fully connected layer with sufficient dimensionality. This layer serves as a gateway to the model, accepting raw input data without any preliminary manual preprocessing.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
The information source consists of data obtained directly from the trading terminal: price quotes, trading volumes, market sentiment indicators, and other relevant parameters. We deliberately omitted any preprocessing performed outside the model. This strategy undoubtedly complicates the training process, as it imposes substantially higher requirements on the model's ability to self-learn and filter out noise. However, this approach ultimately yields much greater robustness during real-world deployment.
It is important to understand that a trained model will deliver reliable and reproducible results only if the data it receives during live operation follows a distribution similar to that used during training. Manual preprocessing performed outside the model increases the risk of unpredictable deviations. Even minor changes to filters or their parameters can radically alter the nature of the input data. Therefore, data preprocessing must become an integral part of the model architecture itself.
To minimize these risks and improve training quality, we integrated the initial data processing stage directly into the encoder structure. This function is performed by a batch normalization layer with a controlled noise injection mechanism CNeuronBatchNormWithNoise. Batch normalization brings heterogeneous multimodal data onto a common scale, improving training stability and accelerating model convergence. In addition, a small amount of noise-based augmentation enhances the model's generalization capability, reducing the risk of overfitting when working with limited datasets.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
The normalized data is then passed to a linear attention module responsible for analyzing interdependencies among individual features within each time step.
At this stage, particular emphasis is placed on correctly interpreting the internal structure of the data. Although the model processes a time series, at each individual time step it deals with the same fixed set of features describing the state of the environment.
Given the repetitive nature of the data structure at every temporal slice, we decided to use a single shared matrix of trainable parameters to analyze all time steps. In other words, the model applies a common, universal attention mechanism across the entire time series. This allows us to achieve several critically important effects:
- improved consistency in feature interpretation across different time intervals;
- a significant reduction in the number of trainable parameters, which is especially important when training data is limited;
- enhanced generalization capability by minimizing overfitting;
- faster training through computational optimization.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.layers = 1; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
After analyzing feature interdependencies at each time step, the next important stage is temporal analysis of the input data. To accomplish this, we first transpose the original tensor, allowing each individual feature to be treated as a sequence of observations over time.
The transposed tensor is then passed to a second linear attention module specifically designed to analyze temporal dynamics.
It should be noted that, after transposition, we effectively obtain a collection of univariate time series, each representing the evolution of a single feature over time. These features may belong to different data modalities. Importantly, different modalities may exhibit distinct response patterns to identical market events. Therefore, at this stage, we adopt a more flexible approach: each univariate sequence is assigned its own trainable parameter matrix. This mechanism allows us to:
- account for the specific characteristics of each modality when interpreting its temporal dynamics;
- identify unique response patterns of different features to the same market triggers;
- increase the model's sensitivity to weak but important signals within individual data channels;
- avoid mixing information originating from fundamentally different types of features.
Such an architecture is particularly effective in financial markets, where heterogeneous data sources may react to fundamental or technical events with different speeds, amplitudes, and directional biases.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; descr.count = 1; descr.window = HistoryBars; descr.layers = BarDescr; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
After passing through the two attention layers, the analyzed data acquires a substantially richer representation. It now contains information about both the internal relationships among features and the characteristic temporal dependencies inherent to each modality. However, in order to build an effective decision-making strategy for financial markets, these data must be aggregated into a more compact and meaningful representation.
The internally enriched data is passed to the CG-LSTM block, where the univariate sequences formed in the previous stage are analyzed independently. It is worth noting that this approach differs significantly from the original design proposed by the authors of the DA-CG-LSTM framework. In the classical DA-CG-LSTM architecture, recurrent cells process multimodal representations corresponding to individual time steps. This approach allows complex cross-modal dependencies to be captured.
In our project, however, we deliberately chose an alternative strategy. We further develop the ideas introduced in the HiSSD architecture, where special emphasis is placed on independently forecasting univariate sequences associated with individual agents. This approach allows us to capture modality-specific behavioral patterns more flexibly and accurately, while minimizing the impact of potential cross-modal noise originating from different data sources.
This data processing scheme in CG-LSTM provides:
- more explicit specialization of hidden states for specific aspects of the data;
- improved model robustness to changes in the structure of market information;
- enhanced interpretability of global skills, since each skill vector is associated with a specific modality of the analyzed data.
When designing the recurrent block, we made an important architectural decision: the hidden state dimension of each CG-LSTM element was set equal to the size of an individual agent's global skill vector. This allows each univariate sequence to generate a fixed-size output representation that encodes the most important aspects of its long-term behavior. These representations subsequently become the foundation for further decision-making processes.
It is important to emphasize that the global skill matrix is constructed in a fully trainable manner. The model independently determines which aspects of feature behavior are most significant for successful operation under real-world trading conditions.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGLSTMOCL; descr.count = NSkills; // Common Skkills descr.window = HistoryBars; // Sequence descr.layers = BarDescr; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
We should also recall that the high-level planner of the HiSSD framework learns to construct global skills by encoding a latent state for the purpose of accurately predicting the next system state. Similarly, the primary objective of the DA-CG-LSTM framework is to forecast multimodal time series as accurately as possible. Its entire architecture is built around this goal: a sophisticated attention mechanism, powerful recurrent blocks, and a decoder are all designed to extract hidden patterns and improve forecasting performance.
However, we adopt a fundamentally different approach and intentionally repurpose the architecture for another task: learning a maximally informative latent representation — the so-called global agent skills. Our priority is not to precisely predict every subsequent time series value, but rather to create an internal market representation that will serve as a robust foundation for learning an optimal agent policy.
Within this context, we deliberately abandoned the complex architecture of the original DA-CG-LSTM decoder. Its deep latent-space analysis mechanisms could potentially distort or reinterpret the global skills, making them less suitable for agent control tasks.
Instead, we selected a minimalist decoder consisting of two consecutive convolutional layers. This design provides straightforward processing of hidden representations, minimal interference with the structure of global skills, high interpretability of the results, and independent processing of univariate feature sequences.
This approach preserves the integrity and value of the learned latent space, paving the way for more effective training of the Actor's policy.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; int prev_out = descr.window_out = 4 * NForecast; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
To correctly align the forecasted values with the actual data, at the final stage of decoder processing we transpose the output tensor back to its original structure.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
However, even after restoring its shape, the forecast values remain in normalized form. Therefore, the next important step is inverse transformation: the statistical parameters of the original feature distribution, recorded during batch normalization, are restored.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
We now proceed to the architecture of the low-level controller. This model plays a key role in constructing local agent strategies based on the analysis of the environment at each specific point in time.
The controller receives raw environmental data as input, similarly to the global skill encoder. In fact, its architecture is based on the same underlying structure: initial data normalization with random noise injection, a two-stage analysis process implemented through linear attention modules, and a CG-LSTM recurrent block for sequential processing.
The fundamental difference between global and local skills lies not in their construction mechanism, but in the tasks agents are required to solve during training. In the case of global skills, the emphasis is placed on creating a generalized latent space capable of integrating long-term dependencies and key market characteristics. Local skills, on the other hand, are oriented toward rapid adaptation to the current market state and the generation of specific trading actions for each individual time step.
Therefore, we simply replicate the architecture of the skill encoder.
//--- Task task.Clear(); //--- Task Encoder for(int i = 0; i <= LatentLayer; i++) if(!task.Add(encoder.At(i))) return false;
After generating the local skills, the next step is to enrich them with the contextual information contained in the agents' global skills. To accomplish this, we employ a two-layer cross-attention block.
The agents' local skills act as Queries, while the global skills of all agents serve as Keys and Values. The key principle here is that each agent's local skills are interpreted not in isolation, but within the broader context of the entire system's latent space. This enables more informed decision-making.
A distinctive feature of this block is its two-stage cross-attention mechanism. At the first stage, a standard Cross-Attention operation is performed. Local queries extract the most relevant fragments of global information. This enables agents to flexibly adapt their short-term behavior in accordance with both the current state of the environment and the strategic trends encoded in the global skills.
At the second stage, integration is further strengthened through an additional attention layer that uncovers deeper and more complex relationships between short-term objectives and long-term strategic guidance.
It is precisely this integration of local and global contexts that enables the model to generate more balanced and well-founded trading decisions, increasing the agents' resilience to false signals and short-term market noise.
//--- layer LatentLayer+1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {NSkills, NSkills}; // WIndow if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {BarDescr, BarDescr}; // Units if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; descr.window_out = 32; descr.layers = 2; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!task.Add(descr)) { delete descr; return false; }
The local skills, enriched with global context, are then passed to the decision-making block. Here, two consecutive convolutional layers play a central role. This architecture enables the efficient parallel execution of independent MLPs for each individual agent.
Each agent interprets its own local latent space and makes decisions without directly interfering with the operation of other agents. The convolutional structure provides high computational efficiency by allowing all agents to be processed simultaneously, while each agent operates with its own dedicated parameter matrix.
The sequence of two convolutional layers adds further architectural flexibility: the first layer performs initial feature aggregation and transformation, while the second layer refines the local representations and generates the final action tensor. This approach improves both the adaptability and robustness of agent behavior under highly volatile financial market conditions.
//--- layer LatentLayer+2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; prev_out = descr.window_out = 4 * NActions; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!task.Add(descr)) { delete descr; return false; } //--- layer LatentLayer+3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NActions; descr.layers = prev_count; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
The architectures of the high-level Actor, Director, and Critic models have been fully carried over from our previous work. Their detailed descriptions can be found at this link. So, we will not dwell on them now. A complete description of all model architectures is provided in the attachment.
Model Training
The model training process is organized into three stages: dataset generation, offline training of all model components, and subsequent online fine-tuning. This approach combines the fundamental stability acquired from historical data with flexible adaptation to current market conditions.
All programs used during training were carried over unchanged from our previous work; therefore, we will not discuss their algorithms in detail. Instead, we will revisit only the fundamental principles of the process.
Model training begins with the creation of a training dataset. For this purpose, we use the Research.mq5 Expert Advisor, which we run in the MetaTrader 5 Strategy Tester to collect historical data for the EURUSD currency pair on the one-minute timeframe throughout the entire year of 2024. To minimize computational load, each run is limited to one month of historical data, while behavioral diversity among agents is achieved through randomized policies. After each candle closes, market states, indicator values, account metrics, and agent actions are recorded, forming complete trajectories for the experience replay buffer.
The collected data serves as the foundation for offline training of all components, which is performed using the Study.mq5 Expert Advisor. Trajectories and starting points are randomly sampled from the replay buffer to construct training batches of sequential states. To accelerate convergence, a near-perfect trajectory technique is employed, enabling the encoder to predict several steps ahead. During this stage, the Skill Encoders, Actor, Director, and Critic are trained, establishing the agent's baseline behavioral policy.
After completing offline training, we proceed to the online fine-tuning stage. Here we use the StudyOnline.mq5 Expert Advisor. The primary focus is on training the Actor under the supervision of the Director and Critic. After each new candle closes, the system analyzes the environment state, updates action evaluations, and adjusts the model parameters. Periodic soft updates of the target models help maintain a balance between strategic stability and adaptability.
This multi-stage approach, combining offline knowledge accumulation with online adaptation, provides high efficiency and robustness when operating under real market conditions.
Testing
An objective evaluation of the implemented solutions and the resulting trading policy can only be obtained using data that was not involved in the training process. For this purpose, a test period spanning January to March 2025 was selected. Using historical data outside the training set eliminates the risk of overfitting and gives the results genuine practical significance.
All other experimental parameters (the market environment, timeframe, and terminal settings) were left unchanged. This ensured that the evaluation measured only the quality of the learned strategy, without interference from external factors.
The testing results are presented below and clearly demonstrate the agent's behavioral model under real-world conditions.


During the testing period, the model executed 37 trades. Slightly more than 40% of them were closed profitably. Nevertheless, the model was able to generate an overall profit because the average winning trade was more than twice the size of the average losing trade. The profit factor reached 1.67.
Conclusion
In this work, we examined the theoretical foundations of the DA-CG-LSTM framework, which differs from conventional models through the introduction of innovative components such as CG-LSTM and a dual attention mechanism. These elements enable more accurate extraction of temporal dependencies and allow the model to capture both short-term fluctuations and long-term trends.
In the practical section, we presented a modified architecture adapted for training trading agents. Simplifying the decoder in favor of convolutional blocks allowed the training process to focus on extracting global skills, a key factor in building a robust and adaptive trading strategy.
The effectiveness of the implemented approaches was evaluated using a test dataset outside the training period. Although the proportion of profitable trades was slightly above 40%, the ratio between average gains and average losses was sufficient to produce an overall positive outcome.
It should be emphasized that the models described in this work remain exploratory in nature. Before being deployed in live trading environments, they must be trained on more representative datasets and subjected to comprehensive testing under a wide range of market conditions.
References
- A Dual-Staged Attention Based Conversion-Gated Long Short Term Memory for Multivariable Time Series Prediction
- Other articles from this series
Programs Used in the Article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor for collecting samples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor for collecting samples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor for offline model training |
| 4 | StudyOnline.mq5 | Expert Advisor | Expert Advisor for online model training |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor for model testing |
| 5 | Trajectory.mqh | Class library | System state and model architecture description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code library | OpenCL program code |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/17939
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
|
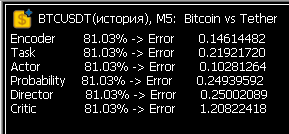
I ran a 1-month, 5-minute run in Research, which produced a 300MB DACGLSTM.bd file. I launched Study. The error rates are alarming. Or is this normal for the very first run?
After the Study, the .nnw neural network files appeared. I ran another round of data collection, but by the very next month, Research had stopped executing trades...
Hurrah! After a few weeks of running around in circles, the error values in Study have finally returned to normal! Now the neural network is actually learning.
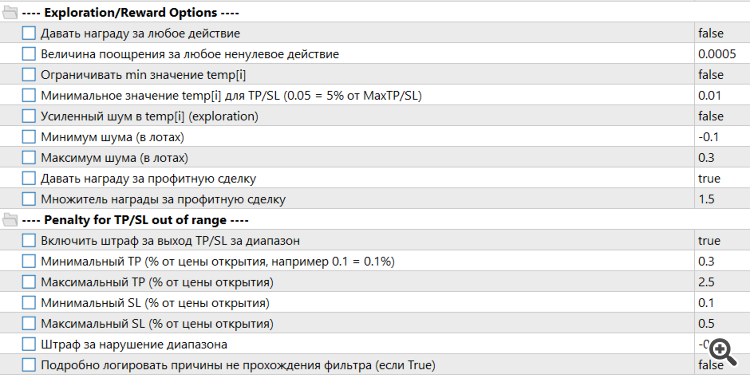
I had to expand the reward and penalty algorithm
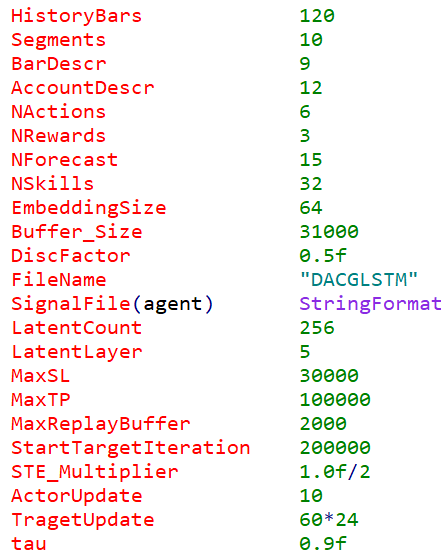
and also make significant adjustments to the Trajectory’s input parameters
Hooray! After a few weeks of running around in circles, the error values in Study have finally stabilised! Now the neural network is actually learning.
Now comes the interesting bit – how it will trade on the new data… I’m working with wooden models – they’re easier to understand. But on the new data, the trading is almost random, as there are no significant features.
Now comes the interesting bit – how it will trade on the new data… I’m working with wooden models – they’re easier to understand. But with the new data, trading is almost random, as there are no significant features.
I’ve still got a way to go before I can trade for real.) After a few rounds of Research-Study, trades start closing very quickly. The neural network is learning to survive, not to make a profit. And the shorter the trade, the more it seems to the network that it’s incurring a smaller penalty. The dance with the tambourines continues. I need to set up the reward and penalty algorithm correctly, and that seems to be the hardest bit. For now, I’m just trying to impose strict limits. For example, not allowing stop-losses or take-profits to be set below a threshold value. I’m also trying to limit the minimum trade duration so they don’t close almost immediately after opening. I use either LLM, Grok or ChatGPT 4.1, but they sometimes act so daft it’s beyond belief. Still, little by little, we’re making progress. A lot of time is spent on training cycles. It would be great to join forces with someone else; it’s a very promising area.