
Neural Networks in Trading: Hierarchical Skill Discovery for Adaptive Agent Behavior (HiSSD)

Introduction
Cooperative Multi-Agent Reinforcement Learning (MARL) has become increasingly relevant in recent years. The concept has found applications across a wide range of domains, from gaming and autonomous transportation to logistics, social dynamics, and, most importantly, financial markets. Wherever coordinated behavior among multiple strategies or agents is required, traditional methods often fall short. In such scenarios, MARL has demonstrated remarkable performance.
Nevertheless, a number of challenges remain. Developing accurate simulators or maintaining continuous online interaction with the environment requires significant resources. In real-world settings, agents must operate under constantly changing conditions: the number of participants may vary, objectives evolve, and environmental parameters shift over time. As a result, there is growing interest in training systems that can adapt and transfer knowledge from one task to another as efficiently as possible and without incurring additional costs.
The conventional approach is to train agents on one task and then fine-tune them for another. However, this strategy has several drawbacks. First, it requires costly re-interaction with the new environment. Second, a model trained for a fixed number of agents does not scale effectively. Its performance deteriorates when the composition of agents or task parameters changes.
To address these issues, researchers began adopting Transformer-based architectures. They provide greater flexibility: the model is no longer tied to a fixed number of agents and can adapt to new conditions. This laid the foundation for the development of universal cooperative behavioral patterns — skills that can be transferred across tasks and reused in different settings.
Numerous approaches have been proposed for implementing such skills. Some rely on a two-stage training process, where general behavioral patterns are first extracted and then used to learn a policy. Others combine offline and online learning, accelerating adaptation to new environments.
These methods have produced significant improvements, particularly in reducing the cost of transferring models to related tasks. However, they also have limitations. While general-purpose skills are useful, they often overlook task-specific characteristics required for achieving particular objectives. Yet, success frequently lies in precisely those details. Furthermore, many approaches neglect the temporal structure of interactions. Cooperation does not emerge instantaneously — it develops over time. The sequence of actions and the consistency of coordination are both critically important.
To address these issues, the paper "Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation" introduces the HiSSD framework (Hierarchical and Separable Skill Discovery). This novel architecture enables the simultaneous learning of both general and task-specific skills without artificial separation and without rigid constraints. In the hierarchical structure, both categories of knowledge evolve in parallel.
General skills capture universal patterns of cooperation. They enable agents to act cohesively even in unfamiliar environments. These skills form the foundation of agent behavior — a set of responses applicable across a broad range of situations. Task-specific skills, by contrast, are tailored to individual tasks. They enable precise behavioral adjustments based on objectives and environmental conditions.
The core idea behind HiSSD is simultaneous hierarchical learning. This approach provides a deeper understanding of both the temporal aspects of interactions and the context of specific tasks. As a result, it not only improves the quality of agent behavior but also facilitates reliable transfer of learned strategies to new environments.
Experiments conducted by the framework's authors on the popular SMAC and MuJoCo benchmarks confirmed the effectiveness of the approach. Even when faced with previously unseen tasks, agents trained with HiSSD demonstrated strong cooperative behavior. Their strategies proved to be flexible, accurate, and robust.
The HiSSD Algorithm
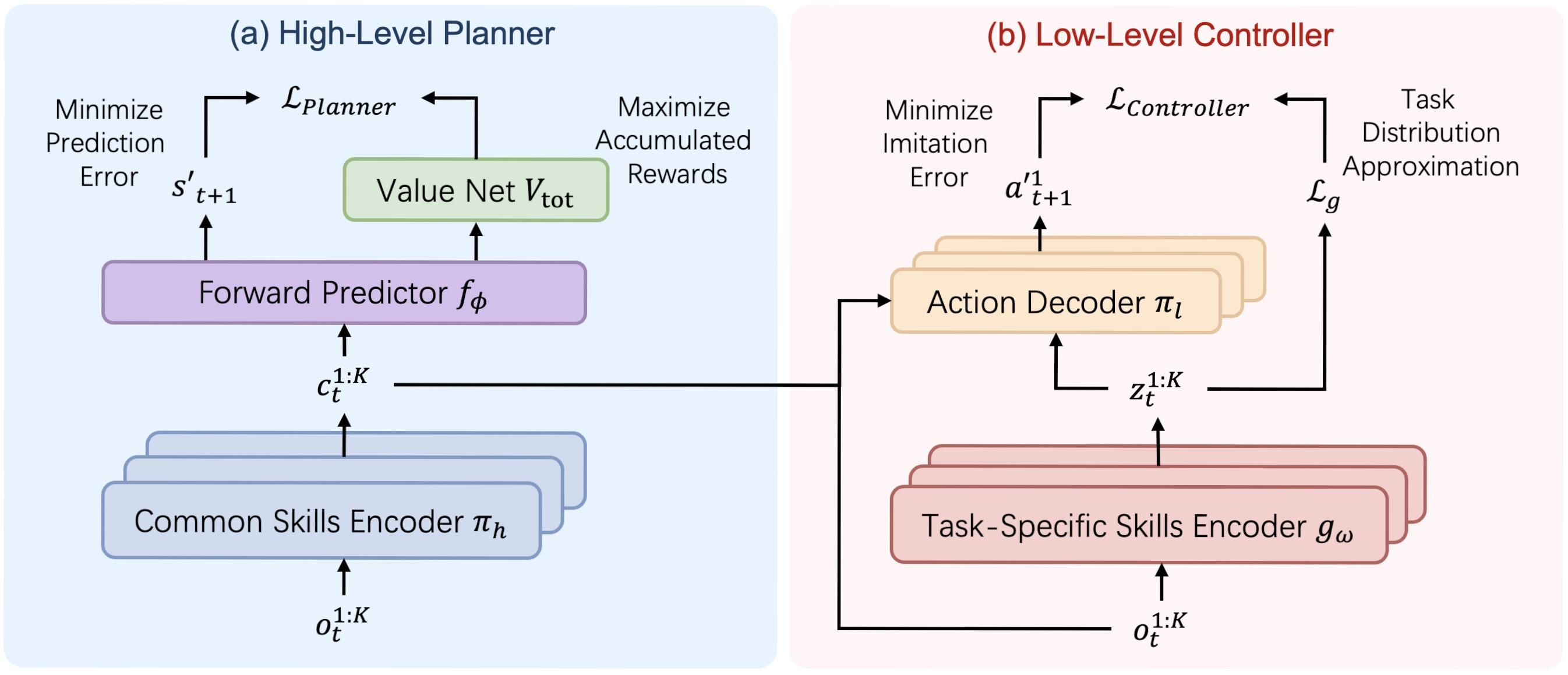
The HiSSD (Hierarchical and Separable Skill Discovery) algorithm is an innovative approach to training agents in multi-agent environments, designed to enable skill transfer across different tasks while maintaining robust behavior in decentralized settings. The central idea of the algorithm is to hierarchically decompose each agent's behavior into two key components: common skills, which are shared across agents and tasks and task-specific skills, which allow behavior to be adapted to a particular role or objective.
One of the key distinctions between HiSSD and many existing approaches is its ability to train all model components simultaneously. Rather than employing sequential or stage-wise training, all modules, including the planner, controller, encoders, and state-value model, are optimized jointly. This synchronized training process reduces inconsistencies between hierarchy levels and promotes more coherent and effective agent behavior.
Training is performed using an offline dataset DT = {Di}, where each Di corresponds to a separate task. At each time step, agent k receives an observation ot,k. Based on this observation, the planner generates a common skill ct,k:
![]()
This skill represents a high-level intention and an overall strategic plan of behavior. Next, the task-specific skill encoder gω generates a task-specific skill zt,k from the same observations:
![]()
The common skill and task-specific skill are then passed to the controller, which combines them with the current observation to determine the agent's action:
![]()
The environmental value model is trained using a modified version of Implicit Q-Learning (IQL) adapted for multi-agent settings. The state value is estimated using the collective reward received by all agents:
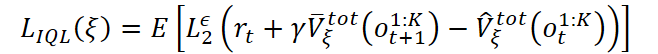
where the truncated squared error is used:
![]()
Based on the model's value estimation, a planner is trained. Its primary objective is to select high-level skills that lead to the most beneficial future states. This is achieved by minimizing a loss function that accounts both for the value of the next state and the likelihood of the predicted state:
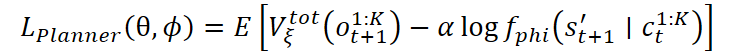
An exponential form of the loss function can also be used:
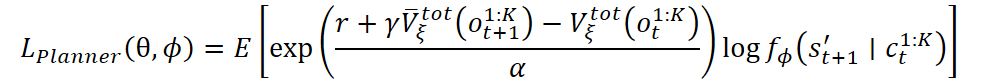
The controller and task-specific skill encoder are trained using a variational autoencoder for behavioral encoding. The core idea is to train the controller to reproduce actions from demonstrations while accounting for the latent structure of the tasks. The loss includes the log-likelihood of the action as well as a regularization term in the form of KL divergence:
![]()
To ensure that the agent's skills are truly differentiated across tasks, contrastive learning is additionally employed. The encoder is trained such that, for each task, the representation gω(q) is closer to positive examples k+ from the same task than to negative examples k- from other tasks:
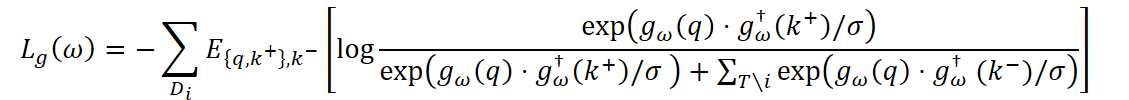
where σ is the temperature coefficient, and gω† denotes an exponentially averaged version of the encoder used to stabilize training.
The final loss function for the controller combines both behavioral and contrastive components.
As a result, HiSSD forms a powerful system in which all levels of behavior — from strategic planning to low-level tactics — are trained in a coordinated manner and operate effectively under decentralized control.
The authors' visualization of the HiSSD framework is shown below.
Implementation in MQL5
After reviewing the theoretical foundations of the HiSSD framework, we now proceed to the practical part of the article, where we implement our interpretation of the proposed methods using MQL5.
Core Principles of the Model Design
Before moving on to the implementation details, it is important to outline several key principles that will form the foundation of our solution.
First, it should be noted that the HiSSD framework is designed for multi-agent learning. This differs from our task, which focuses on learning a trading policy for a single financial instrument. However, this paradigm has significant potential in the context of the multi-task nature of real financial markets. We can extend the proposed hierarchical structure by training multiple independent agents, each analyzing and forecasting a specific subset of market information. To make the final decision-making process more coherent and effective, we introduce a higher-level manager model that aggregates proposals from different agents and selects the optimal strategy. Such multi-task systems are well established in artificial intelligence, and their application to financial markets enables effective handling of diverse factors and risks.
The second important aspect is that, within the HiSSD framework, each agent generates actions based on local observations. However, in financial markets, where price data, trading volumes, and other indicators are highly interdependent, this assumption requires refinement. We can provide each agent with a dedicated univariate sequence extracted from a multimodal time series of raw market data. At the same time, market variables are often correlated. For example, price changes in one asset can influence others. To address this, we introduce a data enrichment mechanism that allows each agent to access shared knowledge about the overall market state, enabling more informed decision-making.
Finally, it is important to emphasize modularity, which lies at the core of the HiSSD framework. This design is particularly well suited for complex, multi-task systems. The architecture can be decomposed into multiple components, each responsible for a separate problem. Modularity not only enables efficient optimization of individual components but also allows the system to adapt flexibly to changing market conditions. In our case, this is especially valuable, as financial markets are highly dynamic, and the ability to quickly modify or improve individual parts of the model can be critical for successful trading.
Skill Encoder
The first module we begin with is the skill encoder. Here, we immediately highlight an important architectural feature of the HiSSD framework: both common and task-specific skills are derived from the same source of information. These are the agent's local observations. In our case, this corresponds to univariate sequences extracted from a multimodal time series representing the state of the environment.
Given this property, we decided to use a unified architectural design for both subtasks. This approach offers several advantages. First, it simplifies model design and debugging. Second, it enables a consistent methodology for evaluating feature quality. Finally, reusing architectural components reduces development overhead and facilitates scaling when extending the model to new tasks or financial instruments.
The skill encoder is implemented within the CNeuronSkillsEncoder object, whose structure is shown below.
class CNeuronSkillsEncoder : public CNeuronSoftMaxOCL { protected: CNeuronCATCH cCrossObservAttention; CNeuronTransposeOCL cTranspose; CNeuronConvOCL cSkillsProjection[2]; CNeuronBaseOCL cPrevSkillsConcat; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronSkillsEncoder(void) {}; ~CNeuronSkillsEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSkillsEncoder; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Within this structure, we observe several internal components, each serving a specific role. Their functionality will be discussed in detail during the implementation of the class methods. For now, what is important is that all the objects are declared as static. This allows us to leave the class's constructor and destructor empty. Initialization of all internal objects is performed in the Init method.
bool CNeuronSkillsEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSoftMaxOCL::Init(numOutputs, myIndex, open_cl, variables * skills, optimization_type, batch)) return false; SetHeads(variables);
The Init method receives a set of constants that uniquely define the architecture of the constructed object. Most of these parameters are already familiar from previous work and will not be described in detail here.
In the method body, we first call the corresponding parent class method, which already implements the minimal required control points as well as initialization of inherited components and interfaces.
As the parent class, we use a SoftMax function layer. This allows us to normalize the outputs of individual agents' skill encoders, bringing them into a comparable scale. The number of skills per agent is defined by the skills parameter. Accordingly, the output vector generated by the module has this length for each agent, where each element represents the importance of a particular skill.
In our setup, the number of agents corresponds to the number of univariate sequences in the multimodal time series. This value is therefore used as the number of SoftMax normalization heads.
After successfully completing the parent initialization, we proceed to initialize newly introduced internal components. The first of these is the information exchange module between univariate sequences. In this experiment, this role is fulfilled by the previously developed CATCH framework component.
int index = 0; if(!cCrossObservAttention.Init(0, index, OpenCL, time_step, variables, window, step, window_key, heads, optimization, iBatch)) return false;
As a reminder, this module aligns univariate sequences in the frequency domain. The spectral decomposition is divided into segments, and analysis is performed within individual frequency bands. This approach allows for a more flexible representation of market signal behavior. Instead of analyzing the entire frequency spectrum as a whole, we focus on specific ranges. This is particularly important in the context of financial markets, where high- and low-frequency fluctuations can convey fundamentally different information: high-frequency components typically reflect short-term volatility and noise, while low-frequency components capture trends and long-term patterns.
This enables the discovery of common patterns — such as synchrony, phase shifts, and correlations — which can then be used as additional information when forming skills.
Importantly, information exchange does not occur directly, but through a masked attention mechanism. This prevents excessive influence between agents and preserves decentralization. As a result, each agent continues to operate on its own univariate sequence while still incorporating global market-level patterns.
The output of the CATCH module is the same multimodal time series, but enriched with cross-channel dependencies.
Next, each agent receives its corresponding univariate sequence. To transform the data into a more suitable representation, a transposition layer is applied.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
After that, independent heads are used to generate each agent's skill vector. Here we use two sequential convolutional layers.
It is important to note that the length of the analyzed sequence may vary significantly. Processing the entire sequence in a single block can therefore be computationally expensive. To address this, the sequence is first split into segments, and dimensionality is adjusted using a convolutional layer.
uint count = (time_step - window + step - 1) / step; if(count <= 1) { window = time_step; count = 1; } //--- index++; if(!cSkillsProjection[0].Init(0, index, OpenCL, window, step, window_key, count, variables, optimization, iBatch)) return false; cSkillsProjection[0].SetActivationFunction(SoftPlus);
The second convolutional layer then aggregates all segments corresponding to a given univariate sequence and produces a single skill vector for each agent. This is indicated by the "1" dimension of the sequence length.
index++; if(!cSkillsProjection[1].Init(0, index, OpenCL, window_key * count, window_key * count, skills, 1, variables, optimization, iBatch)) return false; cSkillsProjection[1].SetActivationFunction(None);
It is important to emphasize that the convolutional layer parameters explicitly define the number of independent univariate sequences processed by the model. This allows each agent to maintain its own convolutional copy with a unique set of weights. At the same time, each agent analyzes its own local portion of the multimodal time series.
In other words, an agent does not simply observe unique data — it focuses on a restricted subset of information. This brings the model closer to real financial markets, where each trader (or agent in our case) operates with different information sources and makes decisions accordingly.
As a result, we obtain not just parallel executors of a single task, but a coordinated set of specialized agents, each learning within its own environment, forming its own market representation, and developing its own behavioral strategy. This design increases system robustness, enhances behavioral diversity, and enables the combination of local strategies to achieve a global objective: efficient and adaptive trading under uncertainty.
Next, we initialize a supplementary object whose size is twice the output tensor. We will discuss its role later during the implementation of the error gradient distribution method.
index++; if(!cPrevSkillsConcat.Init(0, index, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
After initializing all internal objects, the Init method concludes, returning a logical success status to the calling program.
The next stage of development is the implementation of the feed-forward pass algorithms in the feedForward method. As expected, the process is relatively straightforward and linear.
bool CNeuronSkillsEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.FeedForward(NeuronOCL)) return false;
The method receives a pointer to the multimodal input data object, which is immediately passed into the internal cross-channel dependency module.
if(!cTranspose.FeedForward(cCrossObservAttention.AsObject())) return false;
The resulting output is then transposed and forwarded to the skill tensor generation block.
if(!cSkillsProjection[0].FeedForward(cTranspose.AsObject())) return false;
At this point, one important detail must be highlighted. Before calling the second convolutional layer's feed-forward pass, we swap buffer pointers storing intermediate results. This simple operation allows us to preserve previously computed outputs. The importance of this detail will be explained during the implementation of backpropagation.
if(!cSkillsProjection[1].SwapOutputs() || !cSkillsProjection[1].FeedForward(cSkillsProjection[0].AsObject())) return false; //--- return CNeuronSoftMaxOCL::feedForward(cSkillsProjection[1].AsObject()); }
The resulting skill tensor is then mapped into a probability space using the parent class, after which the method completes returning a success flag to the caller.
We then proceed to the implementation of the backpropagation algorithms. This work consists of two stages:
- distribution of error gradients across all components — calcInputGradients
- parameter optimization to minimize the loss — updateInputWeights
We begin with calcInputGradients, which is responsible for propagating gradients through internal modules according to their contribution to the final output. We have already hinted at its structure earlier. Now we finally examine it in detail and explain why it plays a crucial role in training the model.
The method receives a pointer to the input data object used during the feed-forward pass. However, this time, we need to propagate the error gradient back into it according to the influence of the input on the model's final output.
bool CNeuronSkillsEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Naturally, we can only pass data to a valid object. Therefore, at the beginning of the method body, we immediately verify the validity of the received pointer. If the pointer is null or otherwise invalid, the method execution is terminated instantly, as further computations would be meaningless. Such a check is a fundamental safety measure that ensures correct algorithm execution and protects against unpredictable failures during training.
If the validation step is passed successfully, we proceed to the next stage — gradient distribution. At this point, a sequential transfer of information begins across all objects involved in the process. Each of these components is responsible for its own part of the model logic, and our task is to carefully propagate the error gradient into the appropriate modules step by step.
This mechanism is critically important: it provides the model with an internal feedback loop, allowing each block to adjust its parameters according to the final error. It is precisely through this mechanism that the model learns — by discovering optimal parameters that minimize the loss function.
At the first stage, using mechanisms provided by the parent class, we propagate the error gradient received from subsequent layers of the neural architecture into the external interfaces of the object, up to the level of the final skill tensor generation layer of the agents.
if(!CNeuronSoftMaxOCL::calcInputGradients(cSkillsProjection[1].AsObject())) return false;
This process plays a key role in training the model, as it enables the generation of skills that are truly relevant to the task at hand. Through the sequential propagation of gradients, the model receives direct feedback on how correct its previous actions and decisions were.
However, our goal is not only to train agents to generate useful skills, but also to organize their behavior as a coordinated system, ensuring that they can effectively interact by directing their efforts in different directions to achieve maximum overall performance. This is not merely independent training of each agent, but rather the creation of synergy between them.
To implement this approach, we use contrastive learning algorithms, which allow us to introduce diversity into the agents' skill tensors. Importantly, this diversification occurs not only across different agents at a single time step, but also across skills generated at different time steps. This results in a deeper separation in the representation of states.
As a result, each agent is forced not only to recognize the uniqueness of its own skill, but also to take into account the context formed by previous actions. This encourages agents to develop more complex and sequential behavioral strategies, enabling them to adapt to changing conditions and market dynamics.
In the context of financial markets, where conditions can change rapidly, this ability of agents to account for prior actions and state differences becomes particularly important. Skill diversification, combined with historical context, enables the construction of more robust and adaptive strategies capable of operating effectively under high volatility and uncertainty.
The contrastive learning algorithm plays a central role in creating these distinctions, improving the agents' ability to differentiate and interpret diverse situations and make more informed decisions at each step.
During the forward pass, before generating a new skill tensor, we stored the results of the previous forward computation. We now concatenate the outputs from both environment states into a single tensor.
if(!Concat(cSkillsProjection[1].getOutput(), cSkillsProjection[1].getPrevOutput(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
Afterwards, we invoke the diversification method, which is designed to maximally separate individual vectors within the skill subspace.
if(!DiversityLoss(cPrevSkillsConcat.AsObject(), 2 * iHeads, cSkillsProjection[1].GetFilters(), false)) return false;
The resulting error gradients are then split across their corresponding sequences.
if(!DeConcat(cPrevSkillsConcat.getOutput(), cPrevSkillsConcat.getPrevOutput(), cPrevSkillsConcat.getGradient(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
We then add the skill-related error gradients from the current time step to the previously accumulated gradients.
if(!SumAndNormilize(cSkillsProjection[1].getGradient(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].getGradient(), cSkillsProjection[1].GetFilters(), false, 0, 0, 0, 1)) return false;
The rest of the method follows a linear procedure. We propagate the error gradient through the skill generation block.
if(!cSkillsProjection[0].calcHiddenGradients(cSkillsProjection[1].AsObject())) return false;
The resulting values are transposed and passed into the cross-channel dependency analysis module.
if(!cTranspose.calcHiddenGradients(cSkillsProjection[0].AsObject())) return false; if(!cCrossObservAttention.calcHiddenGradients(cTranspose.AsObject())) return false;
Finally, the error gradient is propagated back into the input data object according to its contribution to the final output.
return prevLayer.calcHiddenGradients(cCrossObservAttention.AsObject());
}
The method concludes by returning the logical result of the operation to the calling program.
The parameter update method updateInputWeights is straightforward: it simply invokes the corresponding methods of the internal components. It is worth noting that not all internal modules contain trainable parameters; therefore, only a subset of them participates in this update step.
bool CNeuronSkillsEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.UpdateInputWeights(NeuronOCL)) return false; if(!cSkillsProjection[0].UpdateInputWeights(cTranspose.AsObject())) return false; if(!cSkillsProjection[1].UpdateInputWeights(cSkillsProjection[0].AsObject())) return false; //--- return true; }
A few words should also be said about model saving and restoration. As you may have noticed, the component responsible for concatenating results from two sequential feed-forward passes does not contain trainable parameters. It serves only an auxiliary role, merging outputs from different processing streams. Despite this, the concatenation object does maintain data buffers whose size is twice that of the encoder's output tensor. However, these buffers do not critically affect the model's operation, as they are used only as temporary storage for intermediate computations. Consequently, when saving the trained model, disk space can be reduced by omitting these buffers.
bool CNeuronSkillsEncoder::Save(const int file_handle) { if(!CNeuronSoftMaxOCL::Save(file_handle)) return false; if(!cCrossObservAttention.Save(file_handle)) return false; if(!cTranspose.Save(file_handle)) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!cSkillsProjection[i].Save(file_handle)) return false; //--- return true; }
When restoring the model, the concatenation component can easily be reinitialized based on the known output tensor dimensions of the skill encoder.
bool CNeuronSkillsEncoder::Load(const int file_handle) { if(!CNeuronSoftMaxOCL::Load(file_handle)) return false; if(!LoadInsideLayer(file_handle, cCrossObservAttention.AsObject())) return false; if(!LoadInsideLayer(file_handle, cTranspose.AsObject())) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!LoadInsideLayer(file_handle, cSkillsProjection[i].AsObject())) return false; //--- if(!cPrevSkillsConcat.Init(0, 4, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
With this, we conclude the description of the skill encoder implementation. The full source code of the presented object and its methods is provided in the attachment.
We have made solid progress today; however, the article's scope is nearly exhausted. Therefore, we will take a short break and continue in the next installment.
Conclusion
We have reviewed the theoretical foundations of the HiSSD framework, which represents a powerful and flexible system for training agents in a multi-agent environment. Each agent learns an individual behavioral policy while interacting closely with other participants in the system. This combination of shared and task-specific skill learning enables the development of more adaptive and robust strategies capable of operating effectively under uncertainty and dynamic conditions.
The modular nature of the HiSSD approach, along with the integration of multiple training mechanisms such as contrastive learning and variational behavioral coding, makes it a highly flexible and promising framework for solving problems in multi-agent systems.
In the practical part of the article, we began implementing our interpretation of the proposed approach in MQL5. In particular, we presented an implementation of a universal skill encoder. In the next article, we will continue this work and proceed to testing the effectiveness of the implemented methods on real historical market data.
References
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Other articles from this series
Programs Used in the Article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor for collecting samples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor for collecting samples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor for model training |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor for model testing |
| 5 | Trajectory.mqh | Class library | System state and model architecture description structure |
| 6 | NeuroNet.mqh | Class library | Library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code library | OpenCL program code |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/17729
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article : ‘Applications of Neural Networks in Trading: Hierarchical Skill Discovery (HiSSD) for Adaptive Agent Behaviour’ has been published:
Author: Dmitriy Gizlyk