
Neural Networks in Trading: Actor—Director—Critic

Introduction
Reinforcement Learning (RL) remains one of the most promising and rapidly advancing fields in modern machine learning. Its uniqueness lies in the ability of an Agent to learn through interaction with its environment, developing optimal behavioral strategies based on accumulated experience. Particularly successful has been its integration with deep neural networks, commonly referred to as Deep Reinforcement Learning (Deep RL), which has driven significant progress in autonomous systems for robotics, game playing, industrial process control, and financial markets.
Financial environments are characterized by high stochasticity, continuous change, and substantial risk, making them an ideal testing ground for Deep RL methods. In such settings, an Agent must rapidly adapt to fluctuations in prices, trading volumes, and market volatility while making decisions under uncertainty. However, the practical deployment of RL in trading strategies, especially in high-frequency trading and portfolio management, faces several challenges. One of the most significant is poor sample efficiency, meaning that uninformative actions and erroneous strategies carry an exceptionally high cost.
In classical Model-Free RL algorithms, where no explicit model of the environment is used, the Agent receives information solely from observed experience. It learns through trial and error: taking actions, receiving rewards, and updating its estimates. However, a large proportion of these interactions are only weakly informative. In financial markets, this means substantial transaction costs, capital losses, and a long path toward a robust strategy. Consequently, improving sample efficiency and accelerating learning convergence remain critical objectives.
One of the most robust and widely adopted architectures is the Actor–Critic framework, which combines two models:
- Actor — learns the policy,
- Critic — evaluates actions through the Value Function.
In financial applications, the Actor–Critic architecture is commonly used to build Agents capable of forecasting short-term returns while managing long-term risk. For example, in portfolio rebalancing tasks, the Critic learns to estimate expected returns, while the Actor selects asset weights that maximize portfolio value. However, even this advanced architecture has limitations. During the early stages of training, the Critic's estimates may be highly inaccurate, causing the Actor to receive misleading signals. As a result, the Agent may repeatedly explore action-space regions that are likely to be unprofitable.
To address this limitation, the paper "Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework" introduced a new framework: Actor—Director—Critic (ADC). In addition to the Actor and Critic, the architecture incorporates a third component — the Director. Its role is to act as a classifier capable of distinguishing high-quality actions from poor ones even before the Critic has learned to provide reliable evaluations. Unlike the Critic, the Director performs a classification rather than an evaluation function. It determines whether a particular action should be used to train the policy or whether it is inherently low-quality and should be excluded from further consideration.
The introduction of the Director offers several advantages. First, selectivity is critically important during the early stages of training, where ineffective actions should be avoided whenever possible. Second, in environments with high transaction costs and market volatility, every unsuccessful action can be expensive for the Agent. Under such conditions, the Director serves as an initial guidance mechanism for the Actor, enabling it to focus on potentially effective actions. This approach reduces exploration entropy and accelerates the formation of productive strategies.
The Director is trained using two empirical data subsets: one containing highly profitable state–action–reward tuples and another containing low-performing examples. Once trained, the Director performs binary classification on newly generated actions, filtering out potentially ineffective choices and thereby reinforcing the signals provided by the Critic. The Director's influence is controlled through a decay coefficient: initially, it exerts substantial influence over the Actor, but as the Critic's accuracy improves, the Director's weight gradually decreases. This mechanism preserves both flexibility and stability throughout optimization.
In addition to the structural improvements introduced by the ADC architecture, the authors address another fundamental problem: Overestimation Bias. In RL, overestimation occurs when inflated value estimates are used as learning targets, leading to exaggerated reward expectations and unstable training. The primary causes of overestimation are:
- Maximization Bias, arising from the tendency to select overestimated value-function outputs;
- Bootstrapping Errors, where predicted future rewards are used to update current-state estimates.
One of the most well-known approaches to mitigating overestimation is the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. TD3 employs two independent Q-functions and uses the minimum of their estimates for updates. Nevertheless, the method remains susceptible to instability because its target networks are updated with delay, and their estimates can still be noisy.
The ADC framework proposes a modification of this approach. Each Q-function is assigned two target networks that are updated alternately at different intervals. When computing the target value, the framework uses the average estimate produced by the two target models. This approach reduces estimation variance, minimizes overestimation bias, and improves training stability. Such improvements are particularly important in financial applications, where errors in the Q-function may directly translate into capital losses.
By combining the Actor–Director–Critic architecture with an enhanced dual-estimation mechanism, ADC produces a powerful, adaptive, and robust framework. Its application to algorithmic trading, asset management, and automated hedging has the potential to significantly improve trading performance, accelerate Agent training, and reduce risk through intelligent action selection from the earliest stages of learning.
The ADC Algorithm
Across a wide range of reinforcement learning tasks, the Actor–Critic architecture has established itself as a reliable and effective solution. Its elegance, clarity, and ability to produce high-quality policies have made it a foundation for subsequent developments in reinforcement learning. However, as environments have become increasingly complex, particularly those involving continuous Agent's action spaces and sparse feedback, more powerful and flexible architectural solutions have become necessary. The Actor–Director–Critic (ADC) framework emerged as a response to these challenges, incorporating principles of strategic planning, heuristic guidance, and deep action evaluation.
The architecture is built upon three interconnected components: the Actor, the Critic, and the Director. Together, they form a coordinated system in which each component reinforces the others, creating conditions for faster and more stable Agent learning.
The Critic serves as the analytical core of the system. Its primary role is to evaluate the long-term utility of the Agent's actions by approximating the value function Q(s, a), which represents the expected cumulative reward under the current policy. The Critic is trained by minimizing the error between predicted and target values:
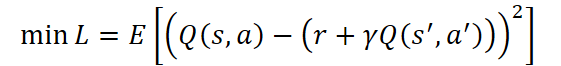
Where:
- r is the reward received from the environment for the Agent's most recent action;
- γ ∈ [0,1) is the discount factor;
- s' and a' denote the subsequent state and action, respectively.
However, relying exclusively on the Critic's estimates, particularly during the early stages of training, can be risky, since its predictions are often unstable. To compensate for this uncertainty and guide the Agent toward sensible decisions, the architecture introduces the Director, which functions as a mentor-like component. The Director acts as a binary classifier that distinguishes potentially beneficial actions from undesirable ones. The Director is trained using pre-labeled datasets of positive actions ah and negative actions al according to the following objective function:
![]()
where function D(s, a) estimates the probability that action a in the state s is appropriate. In this way, the Director filters actions and guides the Actor's learning process, particularly during the initial stages when the Critic's estimates may not yet be reliable.
The Actor, in turn, represents the Agent's behavioral policy. It is implemented as a parameterized function μθ(s), that outputs an action a deemed optimal under the current policy after analyzing the current state s. In the ADC framework, the Actor is trained not only using feedback from the Critic but also with guidance from the Director. This enables more confident progression toward optimal strategies. The Actor's objective function combines these two sources of information:
![]()
As a result, the Actor seeks actions that are both endorsed by the Director and assigned high expected value by the Critic.
To improve training stability and mitigate overestimation bias, the ADC framework employs an enhanced dual-estimation mechanism. Two independent Critics are maintained, each accompanied by two target networks with frozen parameters. During Critic training, the target value is computed as the average prediction of the corresponding target networks for the next state–action pair, helping stabilize the learning process. During Actor training, the minimum estimate from the two Critics is used, preventing action overvaluation and encouraging the development of a more conservative yet reliable policy.
The Critics' target models are updated alternately by copying the parameters of their corresponding trainable models at predefined intervals. This approach promotes long-term training stability and prevents abrupt fluctuations in target values.
It is also important to note that the Critic's parameters are optimized at every training iteration. In contrast, policy updates for the Actor are performed with a delay, providing additional training stability. This delayed-update mechanism allows the Critic sufficient time to accurately evaluate the current policy and offer more reliable guidance for its adjustment.
Furthermore, stochastic smoothing techniques are employed to improve the Agent's behavioral diversity and robustness, including:
- adding Gaussian noise to the Agent's actions:
![]()
- adding limited noise to target actions:
![]()
The final parameter optimization function for the Actor integrates signals from both the Critic and the Director:
![]()
The Actor–Director–Critic framework opens new avenues for the development of intelligent Agents capable not only of learning from experience but also of using guidance in a similar way to human learning.
The authors' visualization of the Actor–Director–Critic framework is presented below.

Implementation in MQL5
After reviewing the theoretical aspects of the Actor–Director–Critic framework, we now move on to the practical part of this article, where we present our interpretation of implementing the proposed methods using MQL5.
As you may have noticed, the considered framework does not require the introduction of entirely new modules as separate objects. This aspect significantly distinguishes this work from previous approaches. In this implementation, we focus on constructing the architecture of trainable models from previously developed modules, as well as on designing the training process in accordance with the proposed methodology.
Architecture of Trainable Models
When beginning the construction of the trainable model architecture, it is important to note that the ADC framework proposed by the authors is applicable to a broad range of architectural designs. In the original paper, experimental results are presented using an extension of the TD3 framework. In our work, however, we go further and apply the proposed ideas to a more complex architectural solution — HiSSD, which was introduced in a previous study. Moreover, we do not limit ourselves to simply adding two new models (the Critic and the Director), but also introduce modifications to previously developed components.
As before, the architecture of all trainable models is defined within the CreateDescriptions method. In the parameters of this method, we add two dynamic arrays to store the architectures of the newly introduced models.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
In the body of the method, we check the received pointers and, if necessary, create new instances of dynamic array objects. This prevents critical errors during subsequent access to these arrays.
The first model we describe is the high-level planner, which partially functions as an encoder of the environment state.
As a reminder, this model receives as input a tensor describing the environment state. It generates a matrix of general skills in the model's latent state and predicts future environment states over a given planning horizon. Importantly, only the common skill representation is used for forecasting future states. This encourages the model to construct a highly informative latent skill tensor.
The first layer remains a fully connected layer with a size sufficient to encode the full input state tensor of the environment.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
The model receives raw, unprocessed data directly from the MetaTrader 5 terminal. This may include sequences of price quotes as well as technical indicator data ranging from simple moving averages to complex oscillators.
Although these data are highly valuable, they are extremely heterogeneous in nature. Their ranges, statistical distributions, and noise characteristics may differ significantly. Without proper preprocessing, such heterogeneity leads to a substantial degradation in model training performance. Therefore, the next step is to bring the data into a comparable representation space, typically using batch normalization, which helps mitigate the value distributional imbalance.
However, in this implementation we take a different approach. To improve model robustness and generalization capability, we enhance this stage by introducing controlled noise into the normalized data. This acts as a form of regularization, preventing overfitting and improving adaptability under real market turbulence.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Only after this step do we use a universal skill-generation module, whose purpose is to construct a tensor of informative common skills for each agent. This tensor represents a condensed abstraction of key features capable of characterizing the agent's behavior and objectives in the current market context. In highly volatile and unpredictable financial environments, such an abstraction increases the robustness of the strategy by reducing sensitivity to short-term noise and outliers.
It is important to understand that this skill tensor will later be used as part of the input data for the Agent's policy generation. Its presence significantly improves the model's selective capacity, enabling it to more accurately distinguish between potentially profitable and unprofitable actions. In this way, we reinterpret the data in terms of tasks and competencies. We move away from the classical "state → action" formulation toward an interpretable transition: "context → skill → action".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
To further improve agent's actions taking into account the dynamics of changes in the common skill tensor, we introduce an LSTM recurrent block. This component plays a key role in capturing the temporal structure of observed market data. Financial markets, as is well known, exhibit strong dependence on past states, and a significant portion of market logic is embedded in temporal patterns.
This is precisely where LSTM (Long Short-Term Memory) becomes an indispensable tool. Its internal memory mechanism allows it to retain and update information about key market transitions and structural patterns without losing context over long time dependencies. As a result, the model learns not only to recognize current market conditions but also to anticipate potential reversals or continuations based on the complex structure of historical observations.
Placing the LSTM block after the skill-generation layer is a deliberate architectural choice. First, the model extracts an abstract representation of the current state and agent objectives in the form of a skill tensor. Then, the LSTM tracks the evolution of these skills over time. This enables the agent to perceive not only a static snapshot of the market but also the dynamics of its strategic profile — for example, how dominant trends evolve, how support and resistance levels form, and how volatility behaves over time.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = prev_out; // Common Skkills descr.layers = prev_count; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Next, we sequentially add two convolutional layers, each playing a specific role in processing the multidimensional time series received from previous layers. These convolutional layers function as a form of MLP with independent forecasting heads, designed for autonomous analysis and prediction of the evolution of unitary components of complex market sequences over a specified forecasting horizon.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
The predicted univariate sequences are then transposed into a full multidimensional time-series representation.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Importantly, after this entire cascade of feature transformations, we restore the predicted values back to the original data scale and distribution using inverse normalization. This step is necessary to ensure that model outputs remain meaningful and interpretable within a trading context.
Inverse normalization preserves the connection between the "model world" and the real market space, where every value has a precise quantitative interpretation.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
It should be emphasized that the latent representation produced by the general skill-generation block is not the final output of the pipeline. Rather, it serves as a valuable intermediate abstraction that will be reused multiple times across different components of the Actor–Director–Critic framework. For this reason, we store the recurrent LSTM representation in a local variable, ensuring its availability for subsequent operations.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
Next, we describe the architecture of the low-level Controller. This module analyzes the same environment state and produces a tensor of specific skills. Therefore, we can reuse the first two layers of the previous model — input processing and normalization — without modification.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
The Controller then operates as a low-level module responsible for constructing a tensor of task-specific skills. Unlike the previously described common skill-generation module, which operates in a strategic context, the Controller functions at a tactical level, analyzing the current environment state.
The Controller does not merely react to the environment; it actively interprets the complex market structure, extracting what can be described as the agent's short-term "intuition". Based on this analysis, it produces a tensor of task-specific skills reflecting immediate preferences and the actions the agent should take in a given situation.
Finally, three information streams are merged:
- the latent representation of common (high-level) skills;
- the tensor of task-specific (low-level) skills;
- the normalized representation of the current environment state.
The resulting combined tensor serves as the basis for generating the agent's action matrix. This structure provides strong model adaptability: strategic objectives are aligned with tactical realities. Behavioral patterns become more flexible and yet they remain consistent with the overall trading policy.
It is important to emphasize that the Controller is not merely a predictive action module, but rather a semantic bridge between high-level intentions and concrete market context. It enables the agent to adapt to continuously changing market conditions while preserving the strategic direction of its behavior.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.layers, // Variables NSkills, // Task Skills latent.count, // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Next we proceed to the architecture of the high-level Actor model, which is responsible for producing the final trading decision. Its task is to interpret the action matrix proposed by the Controller at the previous stage. In other words, the Actor serves as the final decision-making entity, determining which specific behavior will be executed in the current market context based on a set of alternative tactical scenarios.
The Actor's architecture is fully inherited from our previous work. We made a deliberate design choice not to add noise to actions generated from the matrix of alternative strategies. Unlike many reinforcement learning problems where noise injection promotes exploration and diversity, in financial markets even minimal distortion of the final action may lead to catastrophic consequences. A slight deviation in position sizing, a marginal shift in trade levels, or, even worse, a misinterpretation of market dynamics can all result in significant losses and, consequently, a reduction in system reliability.
We introduced only a minor adjustment to the probability prediction model for directional market movement, related to relocating the latent state of the environment encoder from the general skill generation module to the recurrent block. This small but important modification is aimed at improving the model's ability to capture temporal dependencies and adapt dynamically to changing market conditions.
Since the goal of this section is to keep the exposition concise, we do not provide a full and detailed description of these architectures here. However, interested readers may refer to the attachments for complete implementation details.
Almost all of the models described above form a hierarchical structure of the Actor within the Actor–Director–Critic framework. The next key component is the Director, a specialized model whose primary task is the contextual classification of Actor-generated actions into profitable and unprofitable ones.
The role of the Director is difficult to overestimate: it acts as a strategic quality filter, discarding potentially loss-making decisions before they are executed and lead to financial damage. In highly volatile financial markets, where every mistake is costly, such an early evaluation mechanism becomes especially critical.
A distinctive feature of the proposed approach is that the Director does not merely classify actions, but also generates additional supervisory learning signals. This accelerates the Actor's adaptation process, as it allows the policy to incorporate the Director's feedback without requiring repeated accumulation of negative experience. This mechanism is particularly effective in settings where the cost of errors is high and learning time is limited.
In traditional implementations, the Director receives as input the environment state tensor, directly reflecting the Agent's observations. In our implementation, however, the Director operates on a common skill matrix — an informative latent representation produced by the skill generation module at the output of the LSTM block, which has been pre-trained to extract behavioral patterns from multivariate time series. This representation already accounts for environmental dynamics, filters out irrelevant signals, and concentrates the most meaningful aspects of the current context. As a result, the Director operates in a compressed and more stable feature space, significantly improving classification accuracy, decision stability, and real-time adaptability under live market conditions.
In the main information stream, the Director receives the Agent's action tensor as input, which is normalized immediately.
//--- Director director.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = NActions; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
The direct analysis of Actor-proposed actions in the context of current market conditions — encoded in the common skill matrix — is performed using a cross-attention module. This is where semantic alignment takes place between what the agent intends to do and what is actually justified by the current market dynamics.
The cross-attention mechanism enables the Director to identify relationships between components of the action tensor and features of the common skill matrix. This is especially important in highly volatile markets, where simple linear dependencies no longer hold. Cross-attention effectively allows the model to focus on those aspects of the Actor's behavior that are most critical in a given situation.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {3, // Inputs window latent.count // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {NActions/3, // Inputs units latent.layers // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
The output of the cross-attention module is a semantically enriched representation of the Actor's action, already adapted to the current market context. This representation reflects not only the Agent's intention, but also its appropriateness under current conditions, taking into account all discovered patterns and interactions between actions and general skills.
This context-enriched representation becomes the basis for the final processing stage — classification of the action in terms of potential profitability.
The classification procedure is implemented using a sequence of three fully connected neural layers, each equipped with its own activation function to introduce the necessary nonlinearity into the data transformation. This cascade enables the model to flexibly approximate complex decision boundaries, producing a more accurate separation between profitable and unprofitable actions.
In the final layer, a sigmoid activation function is used, allowing the model's output to be interpreted as a probabilistic estimate of class membership. Thus, the model does not merely produce a binary decision, but also provides a confidence measure for its classification.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 1; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
It should be noted that the Critic model in this implementation adopts a similar architectural design. As in the case of the Director, a cross-attention module is used, allowing the Critic to align Actor-proposed actions with the current environmental context represented by the common skill matrix. This results in a more accurate evaluation of action outcomes, taking into account the complex dependencies between agent behavior and the latent market dynamics.
However, there is a fundamental difference in the final stage of the Critic's architecture. Unlike the Director, which uses a sigmoid function for probabilistic interpretation, the Critic's output layer contains no activation function. This design choice is motivated by the nature of the target variable — the expected cumulative reward — which can span a wide and effectively unbounded range.
In other words, the Critic outputs a scalar estimate of the utility of the proposed action in the current context, expressed in units of expected return. Applying a bounded activation function would distort this quantity by clipping potentially important deviations. Therefore, the final value is produced directly, allowing the model to freely represent learned expectations of the environment.
However, this is only a minor architectural adjustment. For this reason, we omit a detailed discussion of the Critic architecture in this article. A full architectural description of all models is provided in the attachment and available for independent study.
Unfortunately, after this detailed exploration of architectural design choices, we have essentially exhausted the scope of this article. We will take a brief pause here, and in the next article we will discuss the training process of the models and evaluate the effectiveness of the proposed solution on real historical data.
Conclusion
In this work, we introduced a new Actor–Director–Critic framework designed for solving problems using deep learning and neural networks. One of the key contributions of this framework is the introduction of the Director model, which classifies Actor actions in the context of the current environment state, significantly improving the efficiency and stability of the training process.
In the practical section of the article, we examined in detail the architectural design of the trainable models that form the basis of the Actor–Director–Critic framework. We described the principles behind the use of various modules and highlighted key design decisions underlying each component of the system.
In the next article, we will focus on the training process of these models and evaluate their performance on real historical market data.
References
- Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework
- Other articles from this series
Programs Used in the Article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor for collecting samples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor for collecting samples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor for offline model training |
| 4 | StudyOnline.mq5 | Expert Advisor | Expert Advisor for online model training |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor for model testing |
| 5 | Trajectory.mqh | Class library | System state and model architecture description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code library | OpenCL program code |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/17796
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use