Discussing the article: "Developing a multi-currency Expert Advisor (Part 19): Creating stages implemented in Python"
Hello,
we start Python by executing shell command in this code:
//+------------------------------------------------------------------+ //| Start a task| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is an EA optimisation task if(m_type == TASK_TYPE_EX5) { // Start a new optimisation task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If it is task for executing Python-program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call function from operation system (Windows) for executing shell command ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Where:
- m_pythonPath is a path to Python on current computer;
- m_setting is string with the name of executed Python-program and its command-line arguments
hello
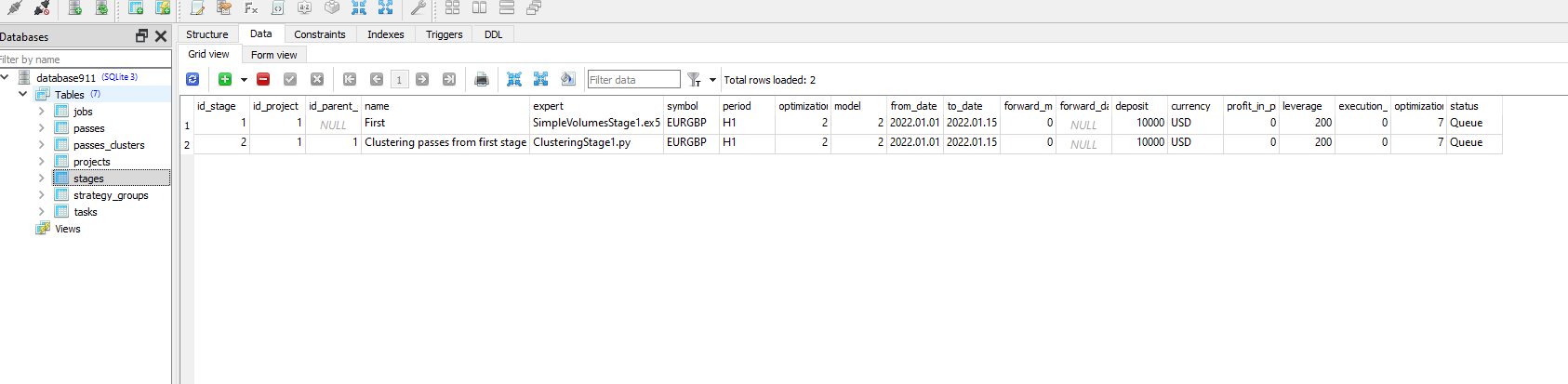
first i optimize satge 1 and complete
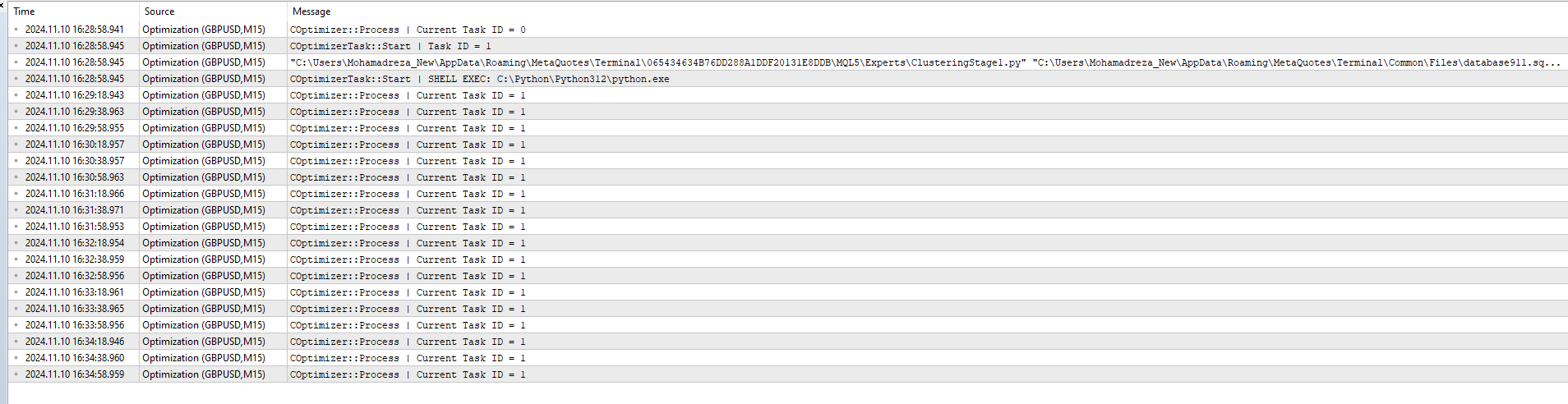
then I added ClusteringStage1.py and task and job to database and Optimize Again But did not work just this message :
2024.11.10 16:35:18.952 Optimisation ( GBPUSD , M15) COptimizer::Process | Current Task ID = 1
{kind=link}
Hello
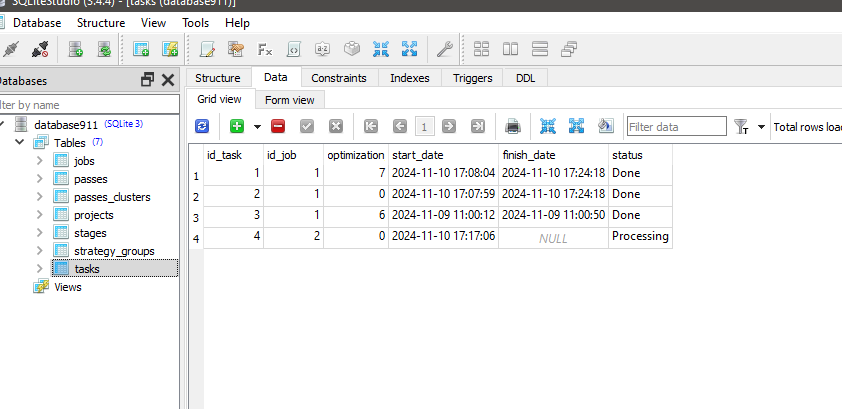
It seems that running Python-program doesn't change status for task with id_task=1.
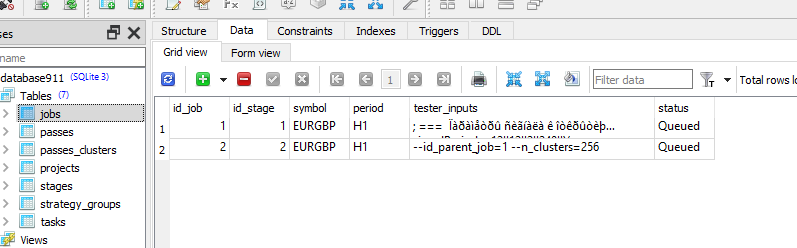
Check that in job for this task you have correct values in [tester_inputs] column. There are:
--id_parent_job=1 --n_clusters=256
where 1 is id_job for job of first stage. In your case it may be other number value.
You can also try to run Python-program with actually parameters manually from command line and then you'll be able to see possible error-messages from it
Hello
It seems that running Python-program doesn't change status for task with id_task =1.
Check that in job for this task you have correct values in [tester_inputs] column. There are:
where 1 is id_job for job of first stage. In your case it may be other number value.
You can also try to run Python-program with actually parameters manually from command line and then you'll be able to see possible error-messages from it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
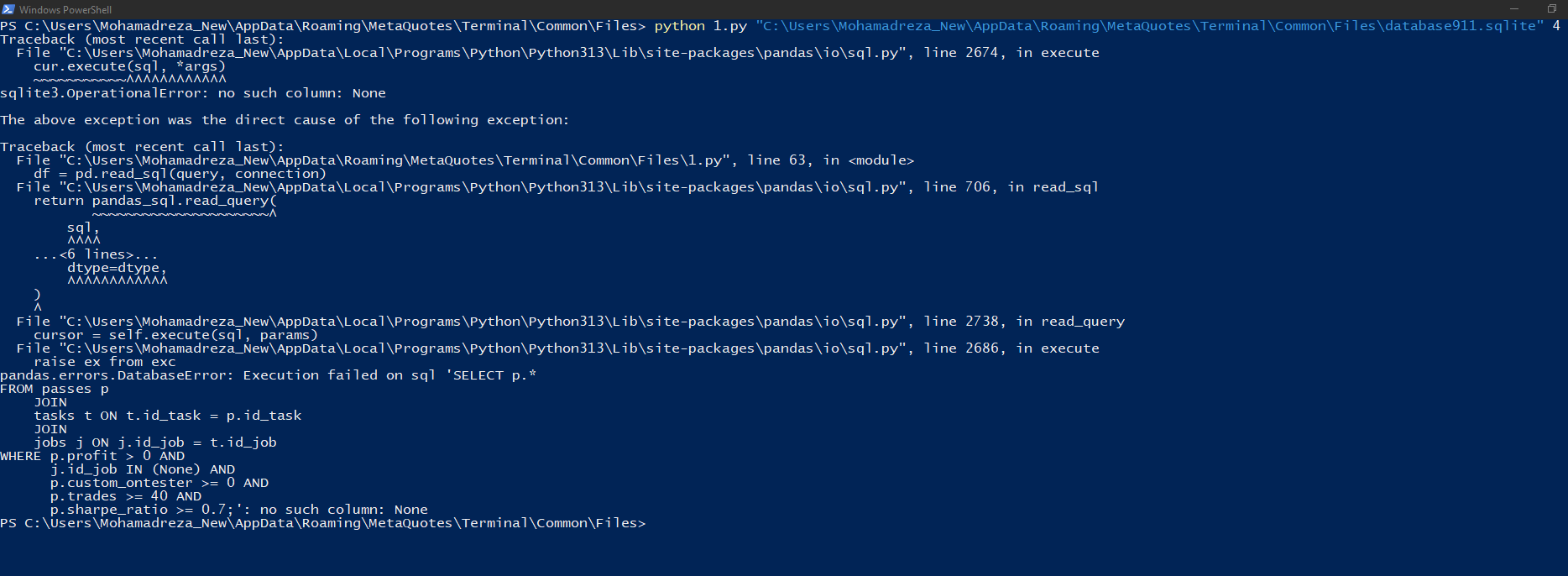
i run in powershell and see this
Try running it like this:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
We need to set the arguments: db_path, id_task. Then we have got error message as you posted:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
We need also set two arguments: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
What will you get?
I run this
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
and get this error
ValueError: n_samples=150 should be >= n_clusters=256.
then i change n_clusters=150 and run
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
and i think worked. but in database not any change
after that i try optimize with n_samples=150 but dont worked
Interesting article! I'll read the whole series, then.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Why did they abandon the functionality of the AlgLib library?
#include <Math\Alglib\alglib.mqh> Minus only in speed, but mainly because python parallelises calculations on all cores.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Developing a multi-currency Expert Advisor (Part 19): Creating stages implemented in Python.
To perform clustering, we used a ready-made library scikit-learn for Python, or, more precisely, the implementation of the K-Means algorithm. This is not the only clustering algorithm, but considering other possible ones, comparing and choosing the best one, as applied to this problem, was beyond the acceptable limits. Therefore, essentially the first algorithm that came to hand was taken, and the results obtained using it turned out to be quite good.
However, using this particular implementation made it necessary to run a small Python program. This was not too much of a hassle when we were doing most of the operations manually. But now that we have made significant progress in automating the entire process of testing and selecting good groups of individual trading strategy instances, having even a simple manual operation in the middle of a pipeline of sequentially executed optimization tasks looks bad.
To fix this, we can take two paths. The first one is to find a ready-made MQL5 implementation of the clustering algorithm or implement it on our own. The second one involves adding the ability to launch not only EAs written in MQL5, but also Python programs at the required stages of the automatic optimization.
Author: Yuriy Bykov