
Developing a multi-currency Expert Advisor (Part 11): Automating the optimization (first steps)
Introduction
In the previous article, we have laid the foundation for easy usage of the results obtained from optimization to build a ready-made EA with multiple instances of trading strategies working together. Now we do not have to manually enter the parameters of all used instances in the code or in the EA inputs. We only need to save the initialization string in a certain format to a file, or insert it as text into the source code so that the EA can use it.
So far, the initialization string has been generated manually. Now, finally, the time has come to start implementing the automatic formation of the EA initialization string based on the obtained optimization results. Most probably, we will not have a fully automated solution within the scope of this article, but at least we are going to make significant progress in the intended direction.
Setting a task
In general terms, our objectives can be formulated as follows: we want to get an EA that runs in the terminal and performs EA optimization with one instance of a trading strategy on several symbols and timeframes. Let these be EURGBP, EURUSD and GBPUSD, as well as timeframes H1, M30 and M15. We need to be able to select from the results of each optimization pass stored in the database those that will relate to a specific symbol and timeframe (and later to some other combinations of test parameters).
We will select a few best results according to different criteria from each group of results for one symbol-timeframe combination. We will place all selected instances into one (for now) instance group. Then we need to determine the group multiplier. A separate EA will do this in the future, but for now we can do this manually.
We form an initialization string to be used in the final EA based on the selected group and multiplier.
Concepts
Let's introduce several additional concepts for further use:
- Universal EA is an Expert Advisor receiving the initialization string making it ready to work on a trading account. We can make it read the initialization string from a file with the name specified in the inputs, or get it from the database by the project name and version.
- Optimizing EA is an EA who will be responsible for performing all actions to optimize projects. When running on a chart, it will search the database for information about the necessary optimization actions and perform them sequentially. The end result of its work will be a saved initialization string for the universal EA.
- Stage EAs are the EAs directly optimized in the tester. There will be several of them, depending on the number of stages implemented. The optimizing EA will launch these EAs for optimization and track its completion.
In this article, we will limit ourselves to one stage optimizing the parameters of a single trading strategy instance. The second stage will involve combining a few best instances into one group and normalizing it. We will perform this manually for now.
As a universal EA, we will make an EA that can build an initialization string itself, selecting information about good examples of trading strategies from the database.
Information about the necessary optimization actions in the database should be stored in a convenient form. We should be able to create this kind of information relatively easily. Let's leave aside for now the question of how this information will get into the database. We can implement a user-friendly interface later. Currently, the main thing is to understand the structure of this information and create a corresponding table structure for it in the database.
Let's start by identifying more general entities, and gradually move down to simpler entities. In the end, we should come to the previously created entity, which represents information about a single tester pass.
Project
The Project entity is at the top level. This is a composite entity: one project will consist of several stages. The Stage entity will be considered below. A project is characterized by a name and a version. It may also have some description. A project can be in several states: "created", "queued for run", "running" and "completed". It would also be logical to store the initialization string for the universal EA, obtained as a result of the project execution, in this entity.
For the convenience of using information from the database in MQL5 programs, we will implement a simple ORM in the future, that is, we will create classes in MQL5 that represent all the entities that we will store in the database.
The class objects for the "Project" entity will store the following in the database:
- id_project – project ID.
- name – project name used in the universal EA to search for the initialization string.
- version – project version to be defined, for example, by the versions of the trading strategy instances.
- description – project description, arbitrary text containing some important details. It may be empty.
- params – initialization string for the universal EA to be filled upon the project completion. It has has an empty value initially.
- status – project status (Created, Queued, Processing, Done). Initially, the project is created with the Created status.
The list of fields may be expanded later.
When a project is ready to run, it is moved to the Queued state. For now, we will carry out this transition manually. Our optimization EA will search for projects with this status and move them to the Processing status.
At the start and completion of any stage, we will check the need to update the project status. If the first stage is started, the project goes into the Processing state. When the last stage is completed, the project goes into the Done state. At this point, the params field value will be filled so that we receive an initialization string that can be passed to the universal EA upon the project completion.
Stage
As already mentioned, the implementation of each project is divided into several stages. The main characteristic of the stage is the EA that will be launched within the framework of this stage for optimization in the tester (stage EA). A test interval will also be set for the stage. This interval will be the same for all optimizations performed at this stage. We should also provide for the storage of other information about optimization (initial deposit, tick simulation mode, etc.).
A stage can have a parent (previous) stage specified. In this case, the execution of the stage will begin only after the completion of the parent stage.
Objects of this class will store the following in the database:
- id_stage – stage ID.
- id_project – project ID the stage belongs to.
- id_parent_stage – parent (previous) stage ID.
- name – stage name.
- expert – name of the EA launched for optimization at this stage.
- from_date – optimization period start date.
- to_date – optimization period end date.
- forward_date – optimization forward period start date. It may be empty, so that forward mode is not used.
- other fields with optimization parameters (initial deposit, tick simulation mode, etc.), which will have default values that do not require changes in most cases
- status – stage status, which can take three possible values: Queued, Processing, Done. Initially, a stage is created with the Queued status.
Each stage, in turn, consists of one or several jobs. When the first job starts, the stage goes into the Processing state. When all jobs are completed, the stage goes into the Done state.
Job
The implementation of each stage consists of the sequential execution of all the jobs included in it. The main characteristics of the job are the symbol, timeframe and inputs of the EA, which is optimized at the stage containing this job.
Objects of this class will store the following in the database:
- id_job – job ID.
- id_stage – ID of the stage the job belongs to.
- symbol – test symbol (trading instrument).
- period – test timeframe.
- tester_inputs – settings of the EA optimization inputs.
- status – job status (Queued, Processing or Done). Initially, a job is created with the Queued status.
Each job will consist of one or more optimization tasks. When the first optimization task starts, the job goes into the Processing state. When all optimization tasks are completed, the job goes into the Done state.
Optimization task
The execution of each task consists of the sequential execution of all the tasks included in it. The main characteristic of the problem is the optimization criterion. The rest of the settings for the tester will be inherited by the task from the job.
Objects of this type will store the following in the database:
- id_task – task ID.
- id_job – job ID, within which the job is performed.
- optimization_criterion – optimization criterion for a given task.
- start_date – optimization task start time.
- finish_date – optimization task end time.
- status – optimization task status (Queued, Processing, Done). Initially, an optimization task is created with the Queued status.
Each task will consist of several optimization passes. When the first optimization pass starts, the optimization task goes into the Processing state. When all optimization passes are completed, the optimization task goes into the Done state.
Optimization pass
We have already considered it in one of the previous articles where we added auto saving of the results of all passes during optimization in the strategy tester. Now we will add a new field that contains the task ID, within which this pass was performed.
Objects of this type will store the following in the database:
- id_pass – pass ID.
- id_task – ID of the task, within which the pass is performed.
- pass result fields – group of fields for all available statistics on the pass (pass number, number of transactions, profit factor, etc.).
- params – initialization string with parameters of the strategy instances used in the pass.
- inputs – pass inputs values.
- pass_date - pass end time.
Compared to the previous implementation, we change the composition of the stored information about the parameters of the strategies used in each pass. More generally, we will need to store information about a group of strategies. Therefore, we will make it so that a group of strategies containing one strategy will be saved for a single strategy as well.
There will be no status field for the pass, since entries are added to the table only after the pass has been completed, not before it has started. Therefore, the very presence of an entry already means that the pass is complete.
Since our database has already significantly enriched its structure, we will make changes to the program code responsible for creating and working with the database.
Creating and managing the database
During the development, we will have to repeatedly re-create the database with an updated structure. Therefore, we will make a simple auxiliary script that will perform a single action - re-create the database and fill it with the necessary initial data. We will consider the initial data to be filled into the empty database later.
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
Save the code in the CleanDatabase.mq5 file of the current folder.
Previously, the CDatabase::Create() table creation method contained an array of strings with SQL queries that re-created one table. Now we have more tables, so storing SQL queries directly in the source code becomes inconvenient. Let's relocate the text of all SQL requests into a separate file, from which they will be loaded for execution inside the Create() method.
To do this, we will need a method that will read all requests from the file by its name and execute them:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
Now let's make changes to the Create() method. The file with the database structure and initial data will have a fixed name: the .schema.sql string is added to the database name:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
Now we can use any SQLite database environment to create all the tables in it and populate them with initial data. After that, we can export the resulting database as a set of SQL queries to a file and use this file in our MQL5 programs.
The last change we need to make to the CDatabase class at this stage is associated with the emerging need to execute requests not only for inserting data, but also for retrieving data from the tables. In the future, all code responsible for obtaining data should be distributed among separate classes that work with individual entities stored in the database. But until we have these classes, we will have to make do with temporary workarounds.
Reading data using the tools provided by MQL5 is a more complex task than adding it. To obtain request result rows, we need to create a new data type (structure) in MQL5, designed to obtain data for this specific request. Then we need to send a request and get the result handle. Using this handle, we can then, in a loop, receive one string at a time from the request results into a variable of the same previously created structure.
So, within the CDababase class, writing a generic method that reads the results of arbitrary requests that retrieve data from the tables is not easy to implement. Therefore, let's give it to the higher level instead. To do this, we only need to provide the database connection handle, stored in the s_db field, to the higher level:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
Save the obtained code in the Database.mqh file of the current folder.
Optimizing EA
Now we can start creating the optimizing EA. First of all, we will need the library to work with the tester by fxsaber, or rather this include file:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
Our optimizing EA will perform the main work periodically - according to a timer. Therefore, we will create a timer and immediately launch its handler for execution in the initialization function. Since optimization tasks typically take tens of minutes, triggering the timer every five seconds seems quite sufficient:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
In the timer handler, we will check whether the tester is currently not in use. If it is indeed not in use, then we need to perform actions to complete current task if any. After that, get the optimization ID and inputs from the database for the next task and launch it by calling the StartTask() function:
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
In the task launch function, use the MTTESTER class methods to load the inputs into the tester and launch the tester in the optimization mode. Also, update the information in the database, saving the start time of the current task and its status:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
The function of receiving the next task from the database is also quite simple. In essence, we arrange the execution of one SQL query in it and receive its results. Note that this function returns the ID of the next task as a result, and it writes the string with the optimization inputs to the setting variable passed to the function as an argument by reference:
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
For the sake of simplicity, the values of some optimization inputs are specified directly in the code. For example, the deposit of USD 10,000, leverage of 1:200, USD, and so on will always be used. Later, the values of these parameters can also be taken from the database if necessary.
The TotalTasks() function code, which returns the number of tasks in the queue, is very similar to the code of the previous function, so we will not provide it here.
Save the resulting code in the Optimization.mq5 file of the current folder. Now we need to make a few more small edits to the previously created files to get a minimally self-sufficient system.
СVirtualStrategy and СSimpleVolumesStrategy
In these classes, we will remove the ability to set the value of the normalized balance of the strategy and make it always have an initial value equal to 10,000. It will now change only when a strategy is included in a group with a given normalizing factor. Even if we want to run one instance of the strategy, we will have to add it alone to the group.
So let's set a new value in the CVirtualStrategy class object constructor:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
Now remove the reading of the last parameter from the initialization string in the CSimpleVolumesStrategy class constructor:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
Save the changes implemented to the VirtualStrategy.mqh and CSimpleVolumesStrategy.mqh files in the current folder.
СVirtualStrategyGroup
In this class, we added a new method that returns the initialization string of the current group with a different substituted value of the normalizing factor. This value will be determined only after the tester has completed its run, so we cannot immediately create a group with the correct multiplier. Basically, we just substitute the number passed as an argument into the initialization string before the closing parenthesis:
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }Save the changes made to the VirtualStrategyGroup.mqh files in the current folder.
CTesterHandler
In the class for storing the results of optimization passes, add the s_idTask static property, to which we will assign the current optimization task ID. In the method for processing incoming data frames, we will add it to the set of values passed to the SQL query for saving the results to the database:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
Save the obtained code in the TesterHandler.mqh file of the current folder.
СVirtualAdvisor
Finally, it is time for the last edit. In the EA class, we will add auto normalization of a strategy or a group of strategies that were used in the EA during a given optimization pass. To do this, we re-create the group of used strategies from the EA initialization string and then form the initialization string of this group with another normalizing multiplier calculated just based on the results of the current drawdown of the pass:
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
Save the changes in the VirtualAdvisor.mqh file of the current folder.
Optimization start
Everything is ready to start optimization. In the database, we created a total of 81 tasks (3 symbols * 3 timeframes * 9 criteria). At first, we chose a short optimization interval only 5 months long, and few possible combinations of optimized parameters, since we were more interested in the auto test performance, rather than the results themselves in the form of found combinations of inputs of working strategy instances. After performing several test runs and correcting minor flaws, we got what we wanted. The passes table was filled with pass results containing filled initialization strings of normalized groups with a single strategy instance.
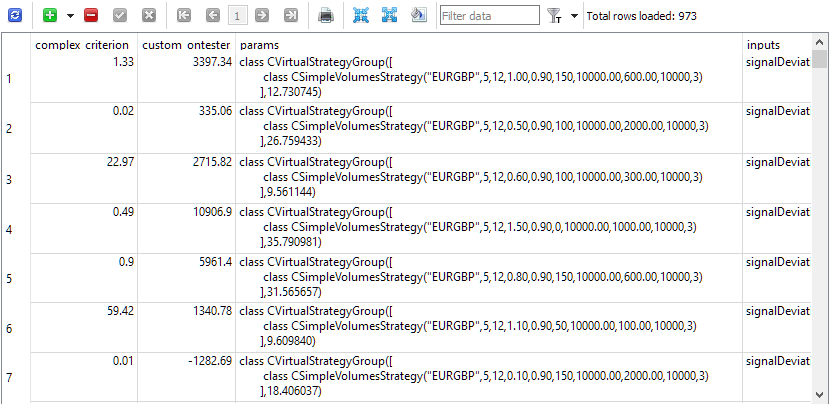
Fig. 1. 'Passes' with pass results
Once the structure has proven its worth, we can give it a more complex task. Let's run the same 81 tasks over a longer interval and with many more parameter combinations. In this case, we will have to wait for some time: 20 agents perform one optimization task for about an hour. So, if we work around the clock, it will take about 3 days to complete all the tasks.
After that, we will manually select the best passes from the thousands of passes received, forming a corresponding SQL query that selects such passes. For now, selection will only be based on the Sharpe ratio exceeding 5. Next, we will create a new EA, which will play the role of a universal EA at this stage. Its main part is the initialization function. In this function, we extract the parameters of the selected best passes from the database, form an initialization string for the EA based on them and create it.
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
For optimization, we chose an interval that includes two full years: 2021 and 2022. Let's have a look at the universal EA results on this interval. To match the maximum drawdown to 10%, we will select a suitable value for the scale_ multiplier. The test results of the universal EA on the interval are as follows:
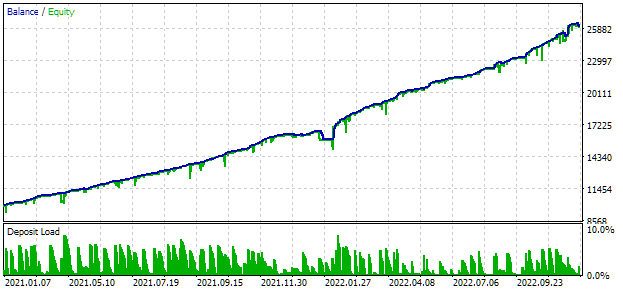
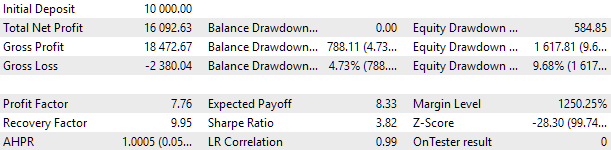
Fig. 2. Universal EA test results for 2021-2022 (scale_ = 2)
About a thousand strategy instances were involved in the EA operation. These results should be treated as intermediary once, since we have not yet performed many of the previously discussed actions aimed at improving the result. In particular, the number of instances of EURUSD strategies turned out to be significantly greater than for EURGBP, which is why the multicurrency advantages have not yet been used to the fullest extent. So, there is hope that we still have some potential for improvement. I will work on implementing this potential in the coming articles.
Conclusion
We have made another important step towards the intended goal. We have gained the ability to automate the optimization of trading strategy instances on different symbols, timeframes and other parameters. Now we do not have to track the end of one running optimization process in order to change the parameters and run the next one.
Saving all results in the database allows us not to worry about a possible restart of the optimizing EA. If for some reason, the optimizing EA operation was interrupted, then at the next launch it will be resumed starting with the next task in the queue. We also have a complete picture of all test passes during the optimization process.
However, there is still a lot of room for further work. We have not yet implemented updating stage and project states. Currently, we only have updating task states. Optimization of projects consisting of several stages has not been considered yet as well. It is also unclear how to best implement intermediate handling of data stages if it requires, for example, data clustering. I will try to cover all this in the following articles.
Thank you for your attention! See you soon!
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/14741
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.
 HTTP and Connexus (Part 2): Understanding HTTP Architecture and Library Design
HTTP and Connexus (Part 2): Understanding HTTP Architecture and Library Design
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Yes, I didn't expect it to be so simple myself. At first I studied Validate, I thought I would have to write something of my own based on it, but then I realised that I could do with a simpler implementation.
Thanks again for a great library!
Hi Yuriy,
I am trying to reblicate Part 11. I have created a SQL with CleanDatabase that created it in User\Roaming\AppData... However when I tried to use the Optimizer, I received the error: IPC server not started. Can you , or anyone, provide an easy reference to starting it?
Also, I use the /portable switch on Terminal and MetaEditor with all my MQL installations located in in C:\"Forex Program Files" will this cause any problems?
During my MQ4 development and teesting EAs, I created directories for all pairs I was interested in testing. I used the JOIN command to redirect the appropriate subdirectories of each test directory to my common directory for starting the probrams and receiving quote data to insure all separate tests were using the same data and executable. In addition, each test wrote s CVS file for each run and I used a version of the File functions to to read the CVS files from each Files directory and consolidate them into a common CVS file. If this is any interest for you in your use of CVS files in lieu of the SQL access, let me know.
In the interim, I am going to download Part 20 and muddle through the examples.
CapeCoddah