
Data Science und ML (Teil 48): Sind Transformer für das Trading wirklich relevant?

Inhalt
- Was ist ein Transformer-Modell?
- Hintergrund
- Architektur des Transformer-Modells
- Temporal Fusion Transformer (TFT)-Modell
- Aufbereitung der Daten für das TFT-Modell
- Training des Temporal Fusion Transformer
- Suche nach den besten Parametern für das TFT-Modell
- Einen Handelsroboter auf Basis des TFT-Modells erstellen
- Fazit
Was ist ein Transformer-Modell?
Beim Deep Learning ist ein Transformer eine künstliche neuronale Netzarchitektur, die auf dem Mechanismus der Multi-Head-Attention basiert. Diese Architektur wurde erstmals 2017 in dem von acht Google-Forschern verfassten Papier „Attention Is All You Need“ vorgestellt. In dem Papier wurde ein neues Modell vorgestellt, das auf dem ursprünglich von Bahdanau et al. 2014 vorgeschlagenen Attention-Mechanismus aufbaut und weithin als grundlegender Beitrag zur modernen künstlichen Intelligenz angesehen wird.
Transformer haben in verschiedenen Bereichen bemerkenswerte Erfolge erzielt. Im Rahmen der Verarbeitung natürlicher Sprache (NLP) haben sie ihre Fähigkeiten bei der Sprachübersetzung, der Sentimentanalyse und der Textzusammenfassung unter Beweis gestellt. Auch für Bildverarbeitungsaufgaben wurden Transformer erfolgreich angepasst und etwa für Bildklassifikation und Objekterkennung eingesetzt. Darüber hinaus erstreckt sich ihre Effektivität auch auf die Zeitreihenanalyse, wo sie aufgrund ihrer einzigartigen Fähigkeit, langfristige Abhängigkeiten zu erfassen, für die Vorhersage sequenzieller Daten geeignet sind, was sich bei Aufgaben wie der Vorhersage von Aktienkursen oder der Vorhersage von Wettermustern zeigt.
Der in diesem Artikel verwendete Begriff Transformer bezieht sich auf eine Familie von Architekturen, die auf Attention basieren, und nicht auf ein einzelnes festes Modell.
Transformer sind eine Familie neuronaler Netzarchitekturen, die auf Attention-Mechanismen statt auf Rekurrenz basieren. Im Gegensatz zu klassischen Sequenzmodellen kann jedes Element einer Sequenz direkt auf alle anderen Elemente Bezug nehmen, was eine effiziente Modellierung weitreichender Abhängigkeiten und parallele Berechnungen während des Trainings ermöglicht.
Ursprünglich für die Verarbeitung natürlicher Sprache entwickelt, wurden Transformer-Varianten seitdem an Bildverarbeitungs- und Zeitreihenaufgaben angepasst, oft mit architektonischen Änderungen, um domänenspezifischen Einschränkungen wie bekannten zukünftigen Eingaben, Prognosen mit mehreren Horizonten und begrenzter Datenverfügbarkeit Rechnung zu tragen.
Hintergrund
Im Bereich der Verarbeitung natürlicher Sprache (NLP) sind sequenzielle Modelle wie RNNs und LSTMs weit verbreitet. Diese Modelle haben sich bei Aufgaben wie maschineller Übersetzung und Sprachmodellierung als sehr leistungsfähig erwiesen. Bei der Verarbeitung sequenzieller Eingaben sind ihnen jedoch strukturelle Grenzen gesetzt.
Die wichtigsten Einschränkungen sind die folgenden:

Struktur eines bestehenden sequenziellen Modells
Lange Berechnungszeit
Herkömmliche sequenzielle Modelle nutzen in der Regel Informationen aus früheren Zeitschritten als Eingabe, um den aktuellen Zeitschritt zu interpretieren. Wie in dem in Abbildung 1 dargestellten Beispiel wird durch die sequentielle Abhängigkeit eine Struktur geschaffen, bei der latente Merkmale schrittweise verarbeitet werden. Folglich skaliert die Berechnungszeit linear mit der Eingabelänge, was mit zunehmender Länge der Sequenzen immer ineffizienter wird.
Schwierigkeit bei der Erfassung langfristiger Abhängigkeiten
Aufgrund ihres sequentiellen Charakters haben Modelle rekurrenter neuronaler Netze (RNN) Schwierigkeiten, Abhängigkeiten zwischen entfernten Elementen in einer Sequenz zu erfassen. Obwohl Architekturen wie LSTM und GRU eingeführt wurden, um dieses Problem zu lösen, beruhen sie immer noch auf versteckten Zustandsdarstellungen fester Größe, was ihre Fähigkeit, extrem lange Sequenzen effektiv zu verarbeiten, einschränkt.
Die Entwickler von Google schlugen ein Transformer-Modell vor, das vollständig auf Rekurrenz verzichtet und sich stattdessen auf einen Attention-Mechanismus stützt, um globale Abhängigkeiten zwischen Eingabe- und Ausgabeelementen herzustellen. Diese Architektur sollte die genannten Einschränkungen wirksam adressieren und die Skalierbarkeit und Effizienz des Modells verbessern, obwohl moderne Varianten sie für bestimmte Bereiche wie Zeitreihen wieder einführen könnten.
Architektur des Transformer-Modells
![]()
Mechanismus der Self-Attention
Im Gegensatz zu herkömmlichen rekurrenten neuronalen Netzen (RNNs) und neuronalen Netzen mit Langzeitgedächtnis (LSTMs) stützen sich Transformer auf einen Mechanismus der Self-Attention, der es dem Modell ermöglicht, die Relevanz verschiedener Teile der Eingabesequenz für die Vorhersage zu gewichten.
Parallelisierung
Transformer ermöglichen eine Parallelisierung während des Trainings, obwohl einige Varianten während der Inferenz sequenziell bleiben, was sie effizienter macht als sequenzielle Modelle wie RNNs. Dies führt zu schnelleren Trainingszeiten.
Encoder-Decoder-Struktur
Das Modell besteht aus einem Encoder und einem Decoder. Der Encoder verarbeitet die Eingabesequenz und erfasst die Kontextinformationen, während der Decoder die Ausgabesequenz erzeugt.
Multi-Head Attention
Der Mechanismus der Self-Attention wird durch mehrere Köpfe erweitert, sodass sich das Modell gleichzeitig auf verschiedene Aspekte der Eingabesequenz konzentrieren kann. Dies verbessert die Fähigkeit, komplexe Zusammenhänge zu erfassen.
Im Gegensatz zu versteckten Zuständen fester Größe ermöglicht Attention dem Modell, relevante Informationen von jedem Punkt der Sequenz dynamisch auszuwählen.
Positionelle Kodierung
Transformer verstehen von Natur aus nicht die Reihenfolge der Eingangssequenz. Um dieses Problem zu lösen, werden den Eingabeeinbettungen Positionskodierungen hinzugefügt, die Informationen über die Positionen der Token in der Sequenz liefern.
Auch hier bezieht sich der in diesem Artikel mehrfach verwendete Begriff Transformer nicht auf ein einziges Modell; die Architektur kann sich bei verschiedenen Transformer-Modellen erheblich unterscheiden. Zum Beispiel:
| Modell | Architektur | Primäre Verwendung / Anwendungsbereich |
|---|---|---|
| Original-Transformer | Encoder-Decoder. | Maschinelle Übersetzung, Sequenz-zu-Sequenz-Aufgaben. |
| BERT (bidirektionale Encoder-Repräsentationen aus Transformer-Modellen) | Nur Encoder. | Textverständnis (Klassifizierung, NER, Einbettung) |
| GPT (Generative Pre-trained Transformer) | Nur Decoder. | Textgenerierung, Sprachmodellierung, Codegenerierung. |
| ViT (Der Visionstransformer) | Nur Encoder. | Bildklassifizierung, Lernen von Bilddarstellungen. |
| TFT (Temporal Fusion Transformer) | Hybrid (LSTM + Attention ) | Zeitreihenprognosen, Finanz- und Unternehmensdaten. |
Weitere Informationen über den Aufbau von Transformer und mehr finden Sie im Referenzteil am Ende dieses Artikels.
Unter den Transformer-Varianten eignet sich der Temporal Fusion Transformer (TFT) besonders für Zeitreihenprognosen. In diesem Artikel werden wir erörtern, was ein solches System ist, wie man es erstellt und wie man es für Marktprognosen nutzen kann.
Das TFT-Modell
Per Definition;
Ein Temporal Fusion Transformer (TFT) ist ein hochmodernes, auf Attention basierendes Deep-Learning-Modell, das für die Prognose von Zeitreihen mit mehreren Horizonten entwickelt wurde.
Es wurde von Google und Forschern der Universität Oxford im Jahr 2021 vorgestellt und soll durch die Kombination von LSTM-basierten (Long Short-Term Memory) Encoder-Decoder-Komponenten mit Mechanismen der Self-Attention leistungsstarke, interpretierbare Vorhersagen liefern.
Weitere Informationen über die Theorie und den Aufbau des Systems finden Sie in diesem Artikel: https://medium.com/dataness-ai/understanding-temporal-fusion-transformer-9a7a4fcde74b
Wir wollen dieses Modell mithilfe des Frameworks von PyTorch-Forecasting umsetzen.
Wir beginnen mit der Installation aller in diesem Projekt verwendeten Abhängigkeiten (die Datei requirements.txt befindet sich in der angehängten Zip-Datei am Ende dieses Artikels) in Ihrer virtuellen Python-Umgebung.
pip install -r requirements.txt
Aufbereitung der Daten für das TFT-Modell
Wir beginnen mit dem Import von Daten aus dem MetaTrader 5 Terminal.
import MetaTrader5 as mt5 # Get rates from the MetaTrader5 app if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() symbol = "EURUSD" rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M15, 0, 10000) rates_df = pd.DataFrame(rates) rates_df["time"] = pd.to_datetime(rates_df["time"], unit="s") data = pd.concat([rates_df, get_features(rates_df)], axis=1)
Feature Engineering
Wir können nicht alle verfügbaren Merkmale verwenden; lassen wir also die weg, die wir für unnötig halten.
rates_df.drop(columns=[ "spread", "real_volume" ], inplace=True)
Die nach diesem Schritt verbleibenden Merkmale sind ebenfalls nicht ausreichend, fügen wir unserem DataFrame daher weitere Merkmale hinzu.
Nachfolgend finden Sie eine einfache Klasse zur Erzeugung verschiedener Merkmale (Feature Engineering neuer Variablen):
features.py
- Datums- und zeitbasierte Funktionen
features.py
import pandas as pd from ta.trend import sma_indicator, ema_indicator, macd_diff, macd_signal from ta.momentum import stochrsi_k, stochrsi_d, rsi from ta.volatility import bollinger_hband, bollinger_lband class FeatureEngineer: # date/time features @staticmethod def hour(date_series: pd.Series) -> pd.Series: return date_series.dt.hour @staticmethod def dayofweek(date_series: pd.Series) -> pd.Series: return date_series.dt.dayofweek @staticmethod def dayofmonth(date_series: pd.Series) -> pd.Series: return date_series.dt.day @staticmethod def month(date_series: pd.Series) -> pd.Series: return date_series.dt.month
- Trendfolgeindikatoren
# trend following indicators @staticmethod def sma(price: pd.Series, window: int=20) -> pd.Series: return sma_indicator(price, window) @staticmethod def ema(price: pd.Series, window: int=20) -> pd.Series: return ema_indicator(price, window) @staticmethod def macd_diff(price: pd.Series, window_slow: int=26, window_fast: int=12, window_signal: int=9) -> pd.Series: return macd_diff(price, window_slow=window_slow, window_fast=window_fast, window_sign=window_signal) @staticmethod def macd_signal(price: pd.Series, window_slow: int=26, window_fast: int=12, window_signal: int=9) -> pd.Series: return macd_signal(price, window_slow=window_slow, window_fast=window_fast, window_sign=window_signal
- Momentum-Indikatoren
# momentum indicators @staticmethod def rsi(price: pd.Series, window: int=14) -> pd.Series: return rsi(price, window) @staticmethod def stochrsi_k(price: pd.Series, window: int=14, smooth1: int=3, smooth2: int=3) -> pd.Series: return stochrsi_k(price, window=window, smooth1=smooth1, smooth2=smooth2) @staticmethod def stochrsi_d(price: pd.Series, window: int=14, smooth1: int=3, smooth2: int=3) -> pd.Series: return stochrsi_d(price, window=window, smooth1=smooth1, smooth2=
- Volatilitätsindikatoren
# volatility indicators @staticmethod def bollinger_hband(price: pd.Series, window: int=20, window_dev: int=2) -> pd.Series: return bollinger_hband(price, window=window, window_dev=window_dev) @staticmethod def bollinger_lband(price: pd.Series, window: int=20, window_dev: int=2) -> pd.Series: return bollinger_lband(price, window=window, window_dev=window_dev)
Wir rufen die Methoden dieser Klasse mit einer einzigen statischen Funktion namens get_all aus derselben Klasse auf.
@staticmethod def get_all(data: pd.DataFrame) -> pd.DataFrame: return pd.DataFrame({ "hour": FeatureEngineer.hour(data["time"]), "dayofweek": FeatureEngineer.dayofweek(data["time"]), "dayofmonth": FeatureEngineer.dayofmonth(data["time"]), "month": FeatureEngineer.month(data["time"]), "sma_20": FeatureEngineer.sma(data["close"]), "ema_20": FeatureEngineer.ema(data["close"]), "macd_diff": FeatureEngineer.macd_diff(data["close"]), "macd_signal": FeatureEngineer.macd_signal(data["close"]), "rsi": FeatureEngineer.rsi(data["close"]), "stochrsi_k": FeatureEngineer.stochrsi_k(data["close"]), "stochrsi_d": FeatureEngineer.stochrsi_d(data["close"]), "bollinger_hband": FeatureEngineer.bollinger_hband(data["close"]), "bollinger_lband": FeatureEngineer.bollinger_lband(data["close"]), })
Wir verwenden diese Klasse, um ein neues Pandas-DataFrame mit zusätzlichen Merkmalen zu erhalten.
new_features = features.FeatureEngineer.get_all(rates_df)
Ausgabe:
(.env) C:\Users\Omega Joctan\OneDrive\mql5 articles\Data Science and ML\Part 48\TFT>python train.py hour dayofweek dayofmonth month sma_20 ema_20 macd_diff macd_signal rsi stochrsi_k stochrsi_d bollinger_hband bollinger_lband 0 20 3 21 8 NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 20 3 21 8 NaN NaN NaN NaN NaN NaN NaN NaN NaN 2 20 3 21 8 NaN NaN NaN NaN NaN NaN NaN NaN NaN 3 20 3 21 8 NaN NaN NaN NaN NaN NaN NaN NaN NaN 4 21 3 21 8 NaN NaN NaN NaN NaN NaN NaN NaN NaN ... ... ... ... ... ... ... ... ... ... ... ... ... ... 9985 20 4 16 1 1.160491 1.160265 -0.000107 -0.000404 41.591063 0.303937 0.316652 1.162598 1.158383 9986 20 4 16 1 1.160384 1.160213 -0.000068 -0.000421 43.685146 0.499779 0.367431 1.162418 1.158349 9987 20 4 16 1 1.160269 1.160151 -0.000047 -0.000433 42.436779 0.698607 0.500775 1.162214 1.158323 9988 21 4 16 1 1.160154 1.160067 -0.000046 -0.000444 40.194753 0.774743 0.657710 1.162051 1.158257 9989 21 4 16 1 1.160052 1.160010 -0.000026 -0.000450 42.452830 0.687333 0.720228 1.161864 1.158240 [9990 rows x 13 columns]
Anschließend führen wir beide DataFrames zu einem größeren Datensatz zusammen, den wir für das endgültige Modelltraining verwenden werden.
data = pd.concat([rates_df, new_features], axis=1) # concatenate dataframes
Ausgabe:
time open high low close tick_volume ... macd_signal rsi stochrsi_k stochrsi_d bollinger_hband bollinger_lband 0 2025-08-21 20:00:00 1.16112 1.16171 1.16112 1.16170 642 ... NaN NaN NaN NaN NaN NaN 1 2025-08-21 20:15:00 1.16170 1.16173 1.16126 1.16136 557 ... NaN NaN NaN NaN NaN NaN 2 2025-08-21 20:30:00 1.16136 1.16167 1.16129 1.16158 414 ... NaN NaN NaN NaN NaN NaN 3 2025-08-21 20:45:00 1.16158 1.16187 1.16149 1.16151 513 ... NaN NaN NaN NaN NaN NaN 4 2025-08-21 21:00:00 1.16151 1.16152 1.16103 1.16106 473 ... NaN NaN NaN NaN NaN NaN ... ... ... ... ... ... ... ... ... ... ... ... ... ... 9985 2026-01-16 20:15:00 1.15911 1.15954 1.15905 1.15951 407 ... -0.000404 41.591063 0.303937 0.316652 1.162598 1.158383 9986 2026-01-16 20:30:00 1.15951 1.15973 1.15936 1.15972 289 ... -0.000421 43.685146 0.499779 0.367431 1.162418 1.158349 9987 2026-01-16 20:45:00 1.15972 1.15994 1.15955 1.15956 447 ... -0.000433 42.436779 0.698607 0.500775 1.162214 1.158323 9988 2026-01-16 21:00:00 1.15956 1.15967 1.15921 1.15927 457 ... -0.000444 40.194753 0.774743 0.657710 1.162051 1.158257 9989 2026-01-16 21:15:00 1.15927 1.15958 1.15915 1.15947 290 ... -0.000450 42.452830 0.687333 0.720228 1.161864 1.158240 [9990 rows x 19 columns]
Die Zielvariable definieren
Ein typisches überwachtes maschinelles Lernen erfordert eine Zielvariable; eine Variable, die ein Modell mithilfe anderer Merkmale (Prädiktoren) vorhersagen muss.
Da es sich um ein Zeitreihenproblem handelt, verwenden wir die Renditen als Zielvariable.
data["returns"] = data["close"].pct_change()
Erstellen eines Zeitreihen-Dataset-Objekts
Für PyTorch-Forecasting müssen die Daten für ein Modell in einem Objekt namens TimeSeriesDataset gespeichert werden.
Wir benötigen eine Spalte namens time_idx im DataFrame, bevor wir ihn dem TimeSeriesDataset-Objekt zuweisen.
data["time_idx"] = data.index data.drop(columns=["time"], inplace=True)
time_idx (str) – Ganzzahlige Spalte, die den Zeitindex innerhalb der Daten angibt. Diese Spalte dient zur Bestimmung der Reihenfolge der Datenpunkte. Wenn es keine fehlenden Beobachtungen gibt, sollte der Zeitindex bei jeder nachfolgenden Stichprobe um +1 steigen. Die erste time_idx für jede Reihe muss nicht unbedingt 0 sein, sondern kann einen beliebigen Wert annehmen.
Sobald die Spalte time_idx in einen DataFrame eingefügt wird, muss die ursprüngliche Spalte, die die Zeit (datetime) enthält, gelöscht werden (TFT verwendet datetime-Variablen nicht direkt).
data.drop(columns=["time"], inplace=True)
max_prediction_length = 6 max_encoder_length = 24 training_cutoff = data["time_idx"].max() - max_prediction_length training = TimeSeriesDataSet( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], min_encoder_length=max_encoder_length // 2, # keep encoder length long (as it is in the validation set) max_encoder_length=max_encoder_length, min_prediction_length=1, max_prediction_length=max_prediction_length, static_categoricals=["symbol"], # time_varying_known_categoricals=[], time_varying_known_reals=[ "hour", "dayofweek", "dayofmonth", "month", "time_idx", "stochrsi_k", "stochrsi_d", "rsi", "macd_diff", ], time_varying_unknown_categoricals=[], time_varying_unknown_reals=[ "open", "high", "low", "close", "tick_volume", "ema_20", "sma_20", "bollinger_hband", "bollinger_lband" ], target_normalizer=GroupNormalizer( groups=["symbol"], transformation="softplus" ), # use softplus and normalize by group add_target_scales=True, add_encoder_length=True, )
Dieses Objekt nimmt viele Variablen auf, von denen die folgende Tabelle einige beschreibt: Mehr dazu hier.
| Variable | Beschreibung |
|---|---|
| max_encoder_length | Wie weit das Modell in die Vergangenheit schauen darf. |
| max_prediction_length | Wie weit in die Zukunft soll das Modell voraussagen. |
| time_varying_known_reals | Hierbei handelt es sich um eine Liste kontinuierlicher Variablen, die sich im Laufe der Zeit ändern und für die Zukunft bekannt sind. Wir haben stationäre Indikatoren ausgewählt, die wir in unserem DataFrame neben den Zeitmerkmalen haben. |
| time_varying_unknown_reals | Dies sollte eine Liste kontinuierlicher Variablen sein, die in der Zukunft nicht bekannt sind und sich im Laufe der Zeit ändern. Zielvariablen sollten hier aufgenommen werden, wenn sie real sind. Hierfür haben wir Merkmale wie Eröffnung, Höchststand, Tiefststand, Schlussstand usw. ausgewählt. Bei den Merkmalen sind wir uns nicht sicher, wie sie in Zukunft bewertet werden. |
| group_ids | Eine Liste von Spaltennamen, die eine Zeitreiheninstanz innerhalb der Daten identifizieren; das bedeutet, dass die group_ids eine Stichprobe zusammen mit der time_idx identifizieren. Wenn Sie nur eine Zeitreihe haben, setzen Sie dies auf den Namen der Spalte, die konstant ist. Da wir nur ein Symbol in unserem Pandas DataFrame gesammelt haben, ist die einzige Gruppe, die wir zuweisen, das aktuelle Symbol. data["symbol"] = "EURUSD"Gruppen können Zeitreihendaten von verschiedenen Instrumenten (Symbolen) und Zeitrahmen darstellen. |
Wir erstellen die Validierungsdaten, indem wir das Trainingsobjekt nachbilden.
# (predict=True) which means to predict the last max_prediction_length points in time for each series validation = TimeSeriesDataSet.from_dataset( training, data, predict=True, stop_randomization=True )
Schließlich erstellen wir PyTorch-Datenlader sowohl für die Trainings- als auch für die Validierungsdaten (Datenlader eignen sich zum Einspeisen von Daten in die Modelle).
batch_size = 128 # set this between 32 to 128 train_dataloader = training.to_dataloader( train=True, batch_size=batch_size, num_workers=0 ) val_dataloader = validation.to_dataloader( train=False, batch_size=batch_size * 10, num_workers=0 )
Training des TFT-Modells
Wir trainieren unser Modell mit PyTorch Lightning, unten ist ein Lightning-Trainer für die Trainingsaufgabe.
pl.seed_everything(42) # random seed for reproducibility lr_logger = LearningRateMonitor() # log the learning rate logger = TensorBoardLogger("lightning_logs") # logging results to a tensorboard # configure network and trainer early_stop_callback = EarlyStopping( monitor="val_loss", min_delta=1e-4, patience=10, verbose=False, mode="min" ) trainer = pl.Trainer( max_epochs=50, accelerator="cpu", enable_model_summary=True, gradient_clip_val=0.1, limit_train_batches=50, # comment in for training, running validation every 30 batches # fast_dev_run=True, # comment in to check that networkor dataset has no serious bugs callbacks=[lr_logger, early_stop_callback], logger=logger, )
Da wir keine Möglichkeit haben, die richtige Lernrate für unser Modell zu kennen, müssen wir eine finden.
Wir erstellen eine Instanz des TFT-Modells, die für die Ermittlung der besten Lernrate verwendet wird.
tft = TemporalFusionTransformer.from_dataset( training, # not meaningful for finding the learning rate but otherwise very important learning_rate=0.03, hidden_size=8, # most important hyperparameter apart from learning rate # number of attention heads. Set to up to 4 for large datasets attention_head_size=2, dropout=0.1, # between 0.1 and 0.3 are good values hidden_continuous_size=8, # set to <= hidden_size loss=metrics.QuantileLoss(), optimizer="ranger", # reduce learning rate if no improvement in validation loss after x epochs # reduce_on_plateau_patience=1000, )
Suche nach einer optimalen Lernrate.
res = Tuner(trainer).lr_find( tft, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, max_lr=10.0, min_lr=1e-6, ) optimal_lr = res.suggestion() print(f"suggested learning rate: {optimal_lr}") fig = res.plot(show=False, suggest=True) plots_path = os.path.join(outputs_dir, "Plots") os.makedirs(plots_path, exist_ok=True) fig.savefig(os.path.join(plots_path, "lr_finder.png"))
Ausgabe:
Finding best initial lr: 91%|█████████████████████████████████████████████████████████████████████████████████████████████▋ | 91/100 [00:41<00:04, 2.20it/s] LR finder stopped early after 91 steps due to diverging loss. Restoring states from the checkpoint path at C:\Users\Omega Joctan\OneDrive\mql5 articles\Data Science and ML\Part 48\TFT\.lr_find_6df0be87-4347-4325-98f1-3a2b5a244c46.ckpt Restored all states from the checkpoint at C:\Users\Omega Joctan\OneDrive\mql5 articles\Data Science and ML\Part 48\TFT\.lr_find_6df0be87-4347-4325-98f1-3a2b5a244c46.ckpt Learning rate set to 1.3182567385564071e-05 suggested learning rate: 1.3182567385564071e-05
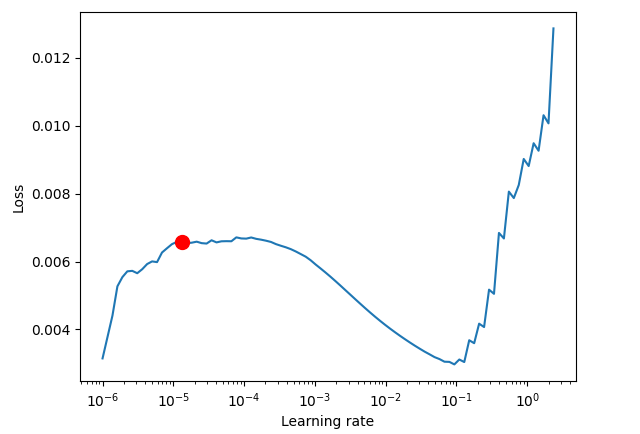
Sobald eine geeignete Lernrate ermittelt wurde, erstellen wir eine neue Modellinstanz und trainieren sie mit einem solchen Lernratenwert.
tft = TemporalFusionTransformer.from_dataset( training, learning_rate=optimal_lr, hidden_size=16, attention_head_size=2, dropout=0.1, hidden_continuous_size=8, loss=metrics.QuantileLoss(), log_interval=10, # uncomment for learning rate finder and otherwise, e.g., to 10 for logging every 10 batches optimizer="ranger", reduce_on_plateau_patience=4, ) print(f"Number of parameters in network: {tft.size() / 1e3:.1f}k") trainer.fit( tft, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, ) tft_predictions = tft.predict(val_dataloader, return_y=True) print("TFT MAE: ", metrics.MAE()(tft_predictions.output, tft_predictions.y))
Ausgabe:
Epoch 4: 100%|██████████████████████████████████████████| 50/50 [01:04<00:00, 0.77it/s, v_num=1, train_loss_step=0.000846, val_loss=0.0013, train_loss_epoch=0.00092]`Trainer.fit` stopped: `max_epochs=5` reached. Epoch 4: 100%|██████████████████████████████████████████| 50/50 [01:05<00:00, 0.77it/s, v_num=1, train_loss_step=0.000846, val_loss=0.0013, train_loss_epoch=0.00092] 💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry. GPU available: False, used: False TPU available: False, using: 0 TPU cores TFT MAPE: tensor(1.2644)+
Vergleichen wir nun die Vorhersagen des Modells mit den tatsächlichen Werten, um einen Eindruck davon zu bekommen, wo die Vorhersagen des Modells im Vergleich zu den tatsächlichen (ursprünglichen) Werten stehen.
best_model_path = trainer.checkpoint_callback.best_model_path best_tft = TemporalFusionTransformer.load_from_checkpoint(best_model_path) # raw predictions are a dictionary from which all kinds of information, including quantiles, can be extracted raw_predictions = best_tft.predict( val_dataloader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu") ) n = raw_predictions.output.prediction.shape[0] print(f"Plotting {n} predictions...") for idx in range(n): fig = best_tft.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) fig.savefig(os.path.join(plots_path, f"tft_prediction_{idx}.png")) plt.close(fig=fig)
Ausgabe:
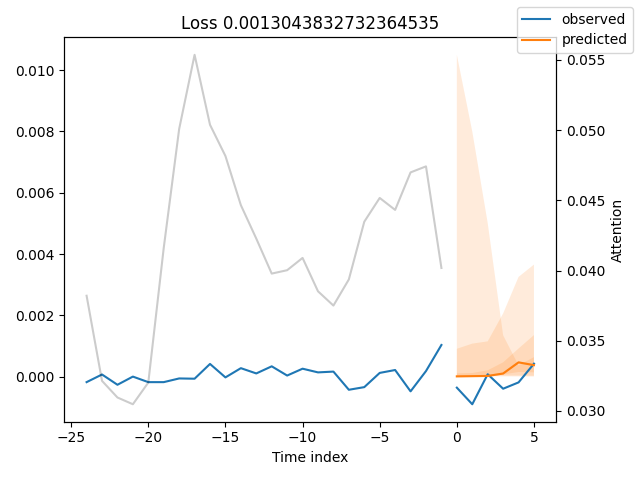
Die vorhergesagten Werte scheinen den Originalwerten sehr nahe zu kommen.
Die MAE-Kennzahl ist ohne Vergleichswert nur begrenzt aussagekräftig. Wir müssen wissen, wo unser Modell im Vergleich zu anderen steht. Das wollen wir mit dem Baseline-Modell herausfinden.
Ein Baseline-Modell
Es handelt sich um ein Modell, das den letzten bekannten Zielwert für eine Vorhersage verwendet. Es dient als einfache Vergleichsbasis, die wir übertreffen wollen.
baseline_predictions = Baseline().predict(val_dataloader, return_y=True) print("Baseline model MAE: ",metrics.MAE()(baseline_predictions.output, baseline_predictions.y))
Nachdem das Skript noch einmal ausgeführt wurde, war das TFT-Modell doppelt so genau wie ein Baseline-Modell.
TFT MAE: tensor(0.0002) Baseline model MAE: tensor(0.0004)
Suche nach den besten Parametern für das TFT-Modell
Da es sich bei einem Transformer-Modell um ein auf einem neuronalen Netz basierendes Modell handelt (mit einer LSTM-Komponente im Kern), sind sie wie alle anderen neuronalen Netzmodelle empfindlich gegenüber Hyperparametern.
Um das Beste aus ihnen herauszuholen, brauchen wir den richtigen Satz von Hyperparametern für ein bestimmtes Problem, das das Modell zu lösen versucht.
In der Dokumentation heißt es dazu:
Die Hyperparameter-Abstimmung mit Optuna ist direkt in das PyTorch Forecasting integriert. Wir können die Funktion optimize_hyperparameters() verwenden, um die Hyperparameter des TFT zu optimieren.
Zum Beispiel:
import pickle from pytorch_forecasting.models.temporal_fusion_transformer.tuning import optimize_hyperparameters # create study study = optimize_hyperparameters( train_dataloader, val_dataloader, model_path="optuna_test", n_trials=200, max_epochs=50, gradient_clip_val_range=(0.01, 1.0), hidden_size_range=(8, 128), hidden_continuous_size_range=(8, 128), attention_head_size_range=(1, 4), learning_rate_range=(0.001, 0.1), dropout_range=(0.1, 0.3), trainer_kwargs=dict(limit_train_batches=30), reduce_on_plateau_patience=4, use_learning_rate_finder=False, # use Optuna to find ideal learning rate or use in-built learning rate finder ) # save study results - also we can resume tuning at a later point in time with open("test_study.pkl", "wb") as fout: pickle.dump(study, fout) # show best hyperparameters print(study.best_trial.params)
Im Gegensatz zu anderen Python-Frameworks für maschinelles Lernen, wie scikit-learn und Keras, erfordern PyTorch-Module ein wenig manuelle Programmierung, was oft dazu führt, dass zusätzlicher Code für alles geschrieben werden muss. Dies kann zu einer mühsamen und fehleranfälligen Programmierarbeit führen.
Um uns das Leben zu erleichtern, verpacken wir den gesamten Code, den wir brauchen, in eine einzige Klasse.
model.py
class TFTModel: def __init__(self, training: TimeSeriesDataSet, train_dataloader: DataLoader, val_dataloader: DataLoader, parameters: dict, loss: metrics=metrics.QuantileLoss(), trainer_max_epochs = 10): """ Initialize the Temporal Fusion Transformer model with training and validation data. Args: training (TimeSeriesDataSet): The training dataset loader containing time series data for model training. parameters (dict): A dictionary containing hyperparameters for the model configuration: - learning_rate (float, optional): Learning rate for the optimizer. Default is 0.03. - hidden_size (int, optional): Size of hidden layers. Most important hyperparameter apart from learning rate. Default is 8. - attention_head_size (int, optional): Number of attention heads. Set to up to 4 for large datasets. Default is 2. - dropout (float, optional): Dropout rate for regularization. Values between 0.1 and 0.3 are recommended. Default is 0.1. - hidden_continuous_size (int, optional): Size of continuous hidden layers. Should be set to <= hidden_size. Default is 8. loss (metrics): Loss function to be used for model training, e.g., QuantileLoss. Attributes: model (TemporalFusionTransformer): The initialized Temporal Fusion Transformer model with a given loss function and Ranger optimizer. trainer: PyTorch Lightning trainer instance configured for model training. """ # configure network and trainer pl.seed_everything(42) self.train_dataloader = train_dataloader self.val_dataloader = val_dataloader self.training = training self.loss = loss self.model = self._create_model(parameters=parameters) self.trainer = self._create_trainer(max_epochs=trainer_max_epochs) def _create_model(self, parameters: dict) -> TemporalFusionTransformer: return TemporalFusionTransformer.from_dataset( self.training, # not meaningful for finding the learning rate but otherwise very important learning_rate=parameters.get("learning_rate", 0.03), hidden_size=parameters.get("hidden_size", 8), # most important hyperparameter apart from learning rate # number of attention heads. Set to up to 4 for large datasets attention_head_size=parameters.get("attention_head_size", 2), dropout=parameters.get("dropout", 0.1), # between 0.1 and 0.3 are good values hidden_continuous_size=parameters.get("hidden_continuous_size", 8), # set to <= hidden_size loss=self.loss, optimizer="ranger", # reduce learning rate if no improvement in validation loss after x epochs # reduce_on_plateau_patience=1000, ) def _create_trainer(self, max_epochs: int=50, grad_clip_val=0.1, limit_train_batches: int=50) -> pl.Trainer: lr_logger = LearningRateMonitor() # log the learning rate logger = TensorBoardLogger("lightning_logs") # logging results to a tensorboard # configure network and trainer early_stop_callback = EarlyStopping( monitor="val_loss", min_delta=1e-4, patience=10, verbose=False, mode="min" ) return pl.Trainer( max_epochs=max_epochs, accelerator="cpu", enable_model_summary=True, gradient_clip_val=grad_clip_val, limit_train_batches=limit_train_batches, # comment in for training, running validation every 30 batches # fast_dev_run=True, # comment in to check that networkor dataset has no serious bugs callbacks=[lr_logger, early_stop_callback], logger=logger, ) def find_optimal_lr(self, plot_output_dir: str, max_lr: float=10.0, min_lr: float=1e-6, show_plot: bool=False, save_plot: bool=True) -> float: """find an optimal learning rate""" res = Tuner(self.trainer).lr_find( self.model, train_dataloaders=self.train_dataloader, val_dataloaders=self.val_dataloader, max_lr=max_lr, min_lr=min_lr, ) optimal_lr = res.suggestion() # ---- optional, saving the plot ---- fig = res.plot(show=show_plot, suggest=True) if save_plot: try: fig.savefig(os.path.join(plot_output_dir, "lr_finder.png")) except Exception as e: print("Error saving learning rate finder plot: ", e) return optimal_lr def load_best_model(self) -> bool: """Load the best model checkpoint after training.""" model = None try: best_model_path = self.trainer.checkpoint_callback.best_model_path model = TemporalFusionTransformer.load_from_checkpoint(best_model_path) except Exception as e: print("Error loading best model checkpoint: ", e) return False self.model = model return True def fit(self): self.trainer.fit( self.model, train_dataloaders=self.train_dataloader, val_dataloaders=self.val_dataloader, ) def predict(self, x: TimeSeriesDataSet, return_x: Optional[bool]=False, mode: Optional[str]="prediction", return_y: bool=True): try: tft_predictions = self.model.predict(x, mode=mode, return_x=return_x, return_y=return_y) except Exception as e: print(f"Failed to predict: {e}") return None return tft_predictions @staticmethod def find_optimal_parameters(train_dataloader: TimeSeriesDataSet, val_dataloader: TimeSeriesDataSet, max_epochs: int=50, n_trials: int=100, use_learning_rate_finder: bool=False, model_path: str="optuna_test", best_params_path: str="best_params.pkl", timeout: int=300) -> dict: """ Find optimal hyperparameters for a Temporal Fusion Transformer model using Optuna. Best parameters are saved for potential later usage Args: train_dataloader (TimeSeriesDataSet): Training dataset loader containing time series data. val_dataloader (TimeSeriesDataSet): Validation dataset loader for evaluating model performance. max_epochs (int, optional): Maximum number of training epochs per trial. Defaults to 50. n_trials (int, optional): Number of optimization trials to run. Defaults to 100. use_learning_rate_finder (bool, optional): Whether to use built-in learning rate finder instead of Optuna-based learning rate optimization. Defaults to False. model_path (str, optional): Directory path to save model checkpoints during optimization. Defaults to "optuna_test". best_params_path (str, optional): File path to save the best hyperparameters. Defaults to "best_params.pkl". timeout (int, optional): Maximum time in seconds to run the optimization study. Defaults to 300. Returns: dict: Dictionary containing the best hyperparameters found during optimization. """ # create study study = optimize_hyperparameters( train_dataloader, val_dataloader, model_path=model_path, n_trials=n_trials, max_epochs=max_epochs, gradient_clip_val_range=(0.01, 1.0), hidden_size_range=(8, 128), hidden_continuous_size_range=(8, 128), attention_head_size_range=(1, 4), learning_rate_range=(0.001, 0.1), dropout_range=(0.1, 0.3), trainer_kwargs=dict(limit_train_batches=30), reduce_on_plateau_patience=4, use_learning_rate_finder=use_learning_rate_finder, # use Optuna to find ideal learning rate or use in-built learning rate finder timeout=timeout, # stop study after given seconds ) # save study results - also we can resume tuning at a later point in time best_params = study.best_trial.params try: with open(best_params_path, "wb") as fout: pickle.dump(best_params, fout) print("Best parameters saved to: ", best_params_path) except Exception as e: print("Error saving best parameters: ", e) # return best hyperparameters return best_params def plot_raw_predictions(self, raw_predictions, plots_path: str, show=False): n = raw_predictions.output.prediction.shape[0] print(f"Plotting {n} predictions...") for idx in range(n): fig = self.model.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) if show: plt.show(fig=fig) fig.savefig(os.path.join(plots_path, f"tft_prediction_{idx}.png")) plt.close(fig=fig)
Eine Klasse gibt uns einen saubereren Ansatz für die Handhabung eines wiederverwendbaren Trainers, das Training des Modells, die Suche nach den besten Parametern, usw.
Da die Funktion find_optimal_parameters eine statische Methode innerhalb einer Klasse TFTModel ist, können wir sie vor einem Klassenkonstruktor einsetzen und die besten Parameter ermitteln, bevor wir sie wieder einer Klasseninstanz zuweisen.
Zum Beispiel:
best_params = model.TFTModel.find_optimal_parameters(train_dataloader=train_dataloader, val_dataloader=val_dataloader, timeout=optuna_timeout, best_params_path=best_params_path ) print("Best hyperparameters found: ", best_params) tft_model = model.TFTModel( training=training, train_dataloader=train_dataloader, val_dataloader=val_dataloader, parameters=best_params, trainer_max_epochs=max_training_epochs )
Einen Handelsroboter auf Basis des TFT-Modells erstellen
Um einen funktionierenden Handelsroboter zu erstellen, müssen wir die Vorhersagen des Modells anhand der neuesten Marktdaten während der Inferenz des Modells erhalten.
Da das TFT während der Inferenz dieselben Merkmale erwartet (einschließlich der Zielvariablen), benötigen wir eine globale Funktion für die Datenerfassung und das Feature Engineering.
bot.py
def prepare_data(rates_df: pd.DataFrame) -> pd.DataFrame: rates_df["time"] = pd.to_datetime(rates_df["time"], unit="s") # convert time in seconds to datetime features_df = features.FeatureEngineer.get_all(rates_df) data = pd.concat([rates_df, features_df], axis=1) # concatenate dataframes # making the target variable data["returns"] = data["close"].pct_change() data["symbol"] = "EURUSD" # assigning symbol name as a group # drop NANs if any data.dropna(inplace=True) # assigning a time index data = data.reset_index(drop=True) data["time_idx"] = data.index # let's keep track of unused features unused_features = ["time", "spread", "real_volume"] return data.drop(columns=unused_features)
Die obige Funktion nimmt einen rohen DataFrame aus MetaTrader 5, erstellt neue Merkmale, einschließlich der Zielvariablen, der Gruppe, zu der ein bestimmter DataFrame gehört, und des Zeitindexes, und gibt schließlich alle erforderlichen Merkmale zurück.
Wir brauchen auch eine Funktion zum Trainieren des Modells; sie sollte eine Referenz auf das trainierte TFTModel in einer globalen Variablen speichern.
bot.py
def train_model(start_bar: int=100, num_bars: int=1000, symbol: int = "EURUSD", timeframe: int=mt5.TIMEFRAME_M15, max_prediction_length: int = 6, max_encoder_length: int = 24, load_best_parameters = False): # we extract training data from MetaTrader 5 try: rates = mt5.copy_rates_from_pos(symbol, timeframe, start_bar, num_bars) except Exception as e: print("Error retrieving data from MetaTrader 5: ", e) return data = prepare_data(rates_df=pd.DataFrame(rates)) # ------------ preparing training data and data loaders ------------ training_cutoff = data["time_idx"].max() - max_prediction_length training = TimeSeriesDataSet( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], min_encoder_length=max_encoder_length // 2, # keep encoder length long (as it is in the validation set) max_encoder_length=max_encoder_length, min_prediction_length=1, max_prediction_length=max_prediction_length, static_categoricals=["symbol"], # time_varying_known_categoricals=[], time_varying_known_reals=[ "hour", "dayofweek", "dayofmonth", "month", "time_idx", "stochrsi_k", "stochrsi_d", "rsi", "macd_diff", ], time_varying_unknown_categoricals=[], time_varying_unknown_reals=[ "open", "high", "low", "close", "tick_volume", "ema_20", "sma_20", "bollinger_hband", "bollinger_lband" ], target_normalizer=GroupNormalizer( groups=["symbol"], transformation="softplus" ), # use softplus and normalize by group add_relative_time_idx=True, add_target_scales=True, add_encoder_length=True, ) # create validation set (predict=True) which means to predict the last max_prediction_length points in time # for each series validation = TimeSeriesDataSet.from_dataset( training, data, predict=True, stop_randomization=True ) # create dataloaders for model batch_size = 128 # set this between 32 to 128 train_dataloader = training.to_dataloader( train=True, batch_size=batch_size, num_workers=4, persistent_workers=True ) val_dataloader = validation.to_dataloader( train=False, batch_size=batch_size * 10, num_workers=4, persistent_workers=True ) best_params_path = os.path.join(outputs_dir, "best_params.pkl") if load_best_parameters: try: with open(best_params_path, "rb") as fin: best_params = pickle.load(fin) except Exception as e: print("Error loading best parameters: ", e) print("Finding optimal parameters instead...") best_params = model.TFTModel.find_optimal_parameters(train_dataloader=train_dataloader, val_dataloader=val_dataloader, timeout=optuna_timeout, best_params_path=best_params_path, ) else: best_params = model.TFTModel.find_optimal_parameters(train_dataloader=train_dataloader, val_dataloader=val_dataloader, timeout=optuna_timeout, best_params_path=best_params_path ) print("Best hyperparameters found: ", best_params) global trained_model trained_model = model.TFTModel( training=training, train_dataloader=train_dataloader, val_dataloader=val_dataloader, parameters=best_params, trainer_max_epochs=max_training_epochs ) trained_model.load_best_model() trained_model.fit()
Alle Handelsoperationen werden innerhalb einer Funktion namens trading_function ausgeführt.
def trading_function(): global trained_model if trained_model is None: train_model(symbol=symbol, timeframe=timeframe, max_encoder_length=lookback_window, max_prediction_length=lookahead_window, load_best_parameters=True) # get a trained model instance return # ---------- get data for model's inference ------- rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 100) rates_df = pd.DataFrame(rates) if rates_df.empty: return data = prepare_data(rates_df=rates_df) predicted_returns = trained_model.predict(x=data, return_x=False, return_y=False) print(f"predicted returns: {np.array(predicted_returns)}") next_return = np.array(predicted_returns).ravel()[-1] print(f"next_return: {next_return:.2f}") # ------------- some trading strategy ---------------- tick_info = mt5.symbol_info_tick(symbol) if tick_info is None: print("Failed to get tick information. Error = ",mt5.last_error()) return symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get information for {symbol}") return lotsize = symbol_info.volume_min if next_return > 0: if not pos_exists(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_BUY): m_trade.buy(volume=lotsize, symbol=symbol, price=tick_info.ask) close_by_type(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_SELL) # close a different type else: if not pos_exists(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_SELL): m_trade.sell(volume=lotsize, symbol=symbol, price=tick_info.bid) close_by_type(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_BUY) # close a different type
Als erstes wird in der obigen Funktion geprüft, ob ein gültiges Modell in der globalen Variable trained_model vorhanden ist; ist dies nicht der Fall, wird das Modell zum ersten Mal mit der Funktion train_model trainiert.
Die angewandte Handelsstrategie ist elementar: Wenn der letzte prognostizierte Renditewert in der Reihe positiv ist, werten wir das als Kaufsignal und eröffnen einen Handel; andernfalls ist es ein Verkaufssignal, und wir eröffnen einen Verkaufshandel. Alle gegenläufigen Geschäfte zum Signal werden mit einer Funktion close_by_type beendet.
Schließlich legen wir fest, wie oft wir nach Handelssignalen suchen und entsprechende Handelsaktionen durchführen wollen, ganz zu schweigen davon, wann und wie oft das Modell neu trainiert wird (um es mit neuen Marktinformationen auf dem Laufenden zu halten).
bot.py
timeframe = mt5.TIMEFRAME_M15 symbol = "EURUSD" magic_number = 20012026 slippage = 100 lookback_window = 24 lookahead_window = 6 if __name__ == "__main__": mt5_exe_path = r"C:\Program Files\MetaTrader 5 IC Markets Global\terminal64.exe" if not mt5.initialize(mt5_exe_path): print("initialize() failed, error code =", mt5.last_error()) quit() m_trade = CTrade(magic_number=magic_number, filling_type_symbol=symbol, deviation_points=slippage, mt5_instance=mt5) def trading_function(): global trained_model if trained_model is None: train_model(symbol=symbol, timeframe=timeframe, max_encoder_length=lookback_window, max_prediction_length=lookahead_window, load_best_parameters=True) # get a trained model instance return # ---------- get data for model's inference ------- rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 100) rates_df = pd.DataFrame(rates) if rates_df.empty: return data = prepare_data(rates_df=rates_df) predicted_returns = trained_model.predict(x=data, return_x=False, return_y=False) print(f"predicted returns: {np.array(predicted_returns)}") next_return = np.array(predicted_returns).ravel()[-1] print(f"next_return: {next_return:.2f}") # ------------- some trading strategy ---------------- tick_info = mt5.symbol_info_tick(symbol) if tick_info is None: print("Failed to get tick information. Error = ",mt5.last_error()) return symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get information for {symbol}") return lotsize = symbol_info.volume_min if next_return > 0: if not pos_exists(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_BUY): m_trade.buy(volume=lotsize, symbol=symbol, price=tick_info.ask) close_by_type(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_SELL) # close a different type else: if not pos_exists(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_SELL): m_trade.sell(volume=lotsize, symbol=symbol, price=tick_info.bid) close_by_type(symbol=symbol, magic=magic_number, type=mt5.POSITION_TYPE_BUY) # close a different type schedule.every(15).minutes.do(trading_function) # check for signals after 15 minutes (according to the timeframe) schedule.every(lookback_window*15).minutes.do(train_model, max_encoder_length=lookback_window, max_prediction_length=lookahead_window) while True: schedule.run_pending() time.sleep(1)
Fazit
Das TFT-Modell ermöglicht Mehrhorizont-Prognosen, was sich für Bestätigungen über mehrere Prognosefenster hinweg als nützlich erweisen kann. Es unterstützt mehrere Datengruppen, bei denen es sich um Daten aus verschiedenen Instrumenten und Zeiträumen handeln kann, wodurch das Modell nützliche Muster über verschiedene Instrumente und Zeithorizonte hinweg erfassen kann Darüber hinaus verfügt dieses Modell über verschiedene Interpretationsmethoden, wie z. B. die Gegenüberstellung der Vorhersagen des Modells mit den tatsächlichen Werten und die Wichtigkeit der einzelnen Merkmale, die uns helfen, die Entscheidungslogik des Modells besser nachzuvollziehen.
Man kann mit Fug und Recht behaupten, dass das TFT ein geeignetes Modell für die Erstellung von Prognosen für Zeitreihendaten ist.
Allerdings handelt es sich um eines dieser komplizierten Modelle, da im Kern eine LSTM-Komponente verwendet wird. Dieses Modell ist sehr rechenintensiv (Sie benötigen auf jeden Fall eine GPU, wenn Sie mit einem größeren Datensatz damit spielen möchten) und benötigt viel Zeit zum Trainieren auf einer CPU. Außerdem sind viele Stichproben in einem Datensatz erforderlich, um eine gute Verallgemeinerung zu erreichen, und trotzdem kann es sein, dass eher Rauschen als Signale erfasst werden. Um dieses Problem zu lösen, verwenden die Entwickler die vom Modell bereitgestellten Quantile.
So gut Transformer auch in anderen Bereichen sind, so wenig ist über ihre Leistung im Finanzbereich bekannt, der weitaus komplexer ist als andere Bereiche und dessen Vorhersage schwierig ist; dieser einzigartige Artikel zeigt die Möglichkeit des Einsatzes von TFT in diesem Bereich auf und bietet einen Ausgangspunkt für weitere Untersuchungen.
Bitte zögern Sie nicht, Ihre Gedanken und Meinungen im Diskussionsteil dieses Artikels mitzuteilen.
Tabelle der Anhänge
| Dateiname | Beschreibung und Verwendung |
|---|---|
| train.py | Es ist eine Spielwiese für den Großteil des in diesem Artikel verwendeten Codes und demonstriert den Prozess des Trainings und der Evaluierung des TFT-Modells. |
| features.py | Ein Modul, das eine Klasse enthält, die für das Feature-Engineering zuständig ist (Erstellung weiterer Merkmale, z. B. Indikatoren aus OHLC-Werten). |
| model.py | Enthält die Klasse TFTModel, die alle nützlichen Methoden für den Einsatz des Temporal Fusion Transformer-Modells zusammenfasst. |
| bot.py | Ein fertiger Handelsroboter, der das TFT-Modell für seine Handelsentscheidungen verwendet. |
| error_description.py | Es verfügt über Funktionen, die MetaTrader 5-Fehlercodes in menschenlesbare Meldungen (Fehler) interpretieren. |
| Trade/Trade.py | Ein ähnliches Verzeichnis wie MQL5/Include/Trade. Dieser Pfad enthält Python-Module, die den Standard-Klassenbibliotheken ähneln. |
| requirements.txt | Enthält alle Python-Abhängigkeiten und ihre Version(en), die in diesem Projekt verwendet werden. Die in diesem Projekt verwendete Python-Version ist 3.11.1 |
Referenzen
- https://pytorch-forecasting.readthedocs.io/de/stable/tutorials/stallion.html
- https://medium.com/@ejcacciatore/the-transformer-revolution-in-financial-markets-technical-insights-applications-and-caveats-34806db92e8e
- https://dl.acm.org/doi/fullHtml/10.1145/3674029.3674037
- https://arxiv.org/pdf/1912.09363
- https://medium.com/dataness-ai/understanding-temporal-fusion-transformer-9a7a4fcde74b
- https://en.wikipedia.org/wiki/Transformer_(deep_learning)
- https://medium.com/@kdk199604/kdks-review-attention-is-all-you-need-what-makes-the-transformer-so-revolutionary-c91f135583b0
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18885
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.