
Erstellung einer Strategie der Rückkehr zum Mittelwert auf der Grundlage von maschinellem Lernen
Einführung
In diesem Artikel wird ein weiterer origineller Ansatz zur Entwicklung von Handelssystemen auf der Grundlage des maschinellen Lernens vorgeschlagen. Im vorangegangenen Artikel habe ich bereits die Möglichkeiten der Anwendung von Clustering auf das Problem des Kausalschlusses betrachtet. In diesem Artikel wird das Clustering verwendet, um Finanzzeitreihen in verschiedene Modi mit einzigartigen Eigenschaften zu unterteilen, und dann werden Handelssysteme für jeden dieser Modi entwickelt und getestet.
Darüber hinaus werden wir uns verschiedene Möglichkeiten zur Kennzeichnung von Beispielen für die Rückkehr zum Mittelwert ansehen und sie am Währungspaar EURGBP testen, das als flach gilt, was bedeutet, dass diese Strategien in vollem Umfang auf es anwendbar sein sollten.
Dieser Artikel ermöglicht es Ihnen, verschiedene Machine-Learning-Modelle in Python zu trainieren und sie in Handelssysteme für das MetaTrader 5-Handelsterminal umzuwandeln.
Vorbereiten der erforderlichen Pakete
Das Modelltraining wird in Python durchgeführt. Stellen Sie daher sicher, dass Sie die folgenden Pakete installiert haben:
import math import pandas as pd import pickle from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester from bots.botlibs.export_lib import export_model_to_ONNX
Die letzten 3 Module wurden von mir geschrieben. Sie sind am Ende des Artikels beigefügt. Jedes dieser Pakete kann andere Pakete importieren, wie Scipy, Numpy, Sklearn, Numba, die ebenfalls installiert werden sollten. Sie sind weithin bekannt und öffentlich verfügbar, sodass es keine Probleme geben sollte, sie zu installieren.
Wenn Sie eine saubere Version von Python haben, finden Sie unten eine Liste der Pakete, die Sie installieren müssen:
pip install numpy pip install pandas pip install scipy pip install scikit-learn pip install catboost pip install numba
Möglicherweise müssen Sie auch absolute Importpfade für die am Ende des Artikels enthaltenen Bibliotheken verwenden, abhängig von Ihrer Entwicklungsumgebung und deren Standort.
Der Code ist so konzipiert, dass er nicht stark von der Version des Python-Interpreters oder eines bestimmten Pakets abhängt, aber es ist besser, die neuesten stabilen Versionen zu verwenden.
Wie lassen sich Beispiele der Strategien für die Rückkehr zum Mittelwert kennzeichnen?
Erinnern wir uns daran, wie wir die Kennzeichnungen in früheren Artikeln markiert haben. Wir haben eine Schleife erstellt, in der die Dauer jedes einzelnen Handels zufällig festgelegt wurde, zum Beispiel von 1 bis 15 Balken. Je nachdem, ob der Markt innerhalb der Anzahl der Balken, die seit der Eröffnung des virtuellen Handels vergangen sind, gestiegen oder gefallen ist, wurde dann eine Kauf- oder Verkaufsmarke gesetzt. Die Funktion gab einen Datenrahmen mit Merkmalen und gekennzeichneten Tags zurück, und der Datensatz war bereits vollständig für das anschließende Training eines maschinellen Lernmodells vorbereitet.
def get_labels(dataset, markup, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + markup) < curr_pr: labels.append(1.0) elif (future_pr - markup) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Diese Art der Kennzeichnung hat jedoch einen entscheidenden Nachteil – sie ist zufällig. Indem wir die Daten auf diese Weise kennzeichnen, machen wir keine Vorgaben darüber, welche Muster das maschinelle Lernmodell annähern soll. Daher wird das Ergebnis einer solchen Kennzeichnung und Ausbildung auch weitgehend zufällig sein. Wir haben versucht, dieses Problem durch mehrere Brute-Force-Trainingsläufe zu beheben und die Algorithmusarchitekturen komplexer zu gestalten, aber die Kennzeichnung selbst war immer noch bedeutungslos. Aufgrund von Zufallsstichproben konnten nur einige Modelle den OOS-Test (Out-of-Sample-Test) bestehen.
In diesem Artikel schlage ich einen neuen Ansatz für die Handelskennzeichnung vor, der auf der Filterung der ursprünglichen Zeitreihen basiert. Schauen wir uns diese Kennzeichnung anhand eines Beispiels an.
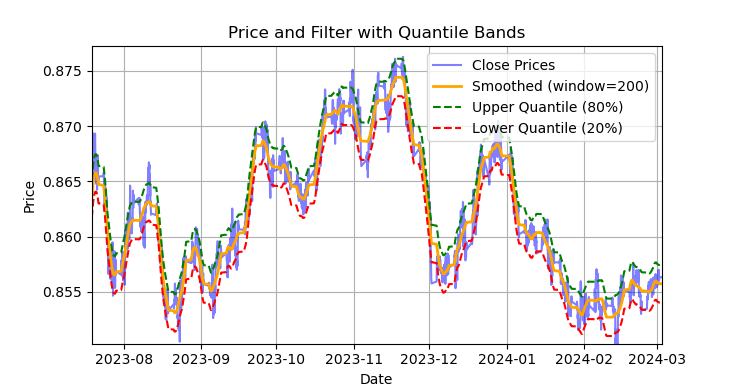
Abb. 1. Darstellung des Savitzky-Golay-Filters und der Banden (Quantile)
Abb. 1 zeigt die Glättungslinie des Savitzky-Golay-Filters und die 20- und 80-Quantil-Bänder, die ein wenig an die Bollinger-Bänder erinnern. Der Hauptunterschied zwischen dem Savitzky-Golay-Filter und einem regulären gleitenden Durchschnitt besteht darin, dass er nicht relativ zu den Preisen nachhängt. Aufgrund dieser Eigenschaft glättet der Filter die Preise gut, und das verbleibende „Rauschen“ sind Abweichungen von den Mittelwerten (den Werten des Filters selbst), die zur Entwicklung einer Mean-Reversion-Strategie genutzt werden können. Wenn sich das obere und das untere Band kreuzen, wird ein Verkaufs- oder Kaufsignal gebildet. Wenn der Kurs die obere Linie überschreitet, ist dies ein Verkaufssignal. Wenn der Kurs die untere Linie überschreitet, ist dies ein Kaufsignal.
Der Savitzky-Golay-Filter ist ein digitaler Filter, der zur Glättung von Daten und zur Unterdrückung von Rauschen verwendet wird, wobei wichtige Signalmerkmale wie Spitzen und Trends erhalten bleiben. Sie wurde von Abraham Savitzky und Marcel J. Е. Golay im Jahr 1964 vorgeschlagen. Dieser Filter wird häufig in der Signalverarbeitung und Datenanalyse eingesetzt.
Der Savitzky-Golay-Filter arbeitet durch lokale Annäherung der Daten mit einem Polynom niedrigen Grades (quadratisch, kubisch oder quartisch) nach der Methode der kleinsten Quadrate. Für jeden Datenpunkt wird eine Nachbarschaft (ein Fenster) ausgewählt, und die Daten innerhalb dieses Fensters werden durch das Polynom approximiert. Nach der Annäherung wird der Wert in der Mitte des Fensters durch den mit dem Polynom berechneten Wert ersetzt. So können wir das Rauschen glätten und gleichzeitig die Signalform beibehalten.
Nachfolgend finden Sie den Code für die Erstellung und visuelle Auswertung des Filters.
def plot_close_filter_quantiles(dataset, rolling=200, quantiles=[0.2, 0.8], polyorder=3): # Calculate smoothed prices smoothed = savgol_filter(dataset['close'], window_length=rolling, polyorder=polyorder) # Calculate difference between prices and filter lvl = dataset['close'] - smoothed # Get quantile values q_low, q_high = lvl.quantile(quantiles).tolist() # Calculate bands based on quantiles upper_band = smoothed + q_high # Upper band lower_band = smoothed + q_low # Lower band # Create plot plt.figure(figsize=(14, 7)) plt.plot(dataset.index, dataset['close'], label='Close Prices', color='blue', alpha=0.5) plt.plot(dataset.index, smoothed, label=f'Smoothed (window={rolling})', color='orange', linewidth=2) plt.plot(dataset.index, upper_band, label=f'Upper Quantile ({quantiles[1]*100:.0f}%)', color='green', linestyle='--') plt.plot(dataset.index, lower_band, label=f'Lower Quantile ({quantiles[0]*100:.0f}%)', color='red', linestyle='--') # Configure display plt.title('Price and Filter with Quantile Bands') plt.xlabel('Date') plt.ylabel('Price') plt.legend() plt.grid(True) plt.show()
Es wäre also ein Fehler, diesen Filter online auf nicht-stationäre Zeitreihen anzuwenden, da die letzten Werte neu gezeichnet werden können, aber er eignet sich sehr gut für die Markierung von Handelsgeschäften auf bestehenden Daten.
Schreiben wir nun den Code, der die Kennzeichnung der Trainingsbeispiele mit dem Savitzky-Golay-Filter implementiert. Die Funktion zur Kennzeichnung befindet sich zusammen mit anderen ähnlichen Funktionen im Python-Modul labeling_lib.py, das dann in unser Projekt importiert wird.
@njit def calculate_labels_filter(close, lvl, q): labels = np.empty(len(close), dtype=np.float64) for i in range(len(close)): curr_lvl = lvl[i] if curr_lvl > q[1]: labels[i] = 1.0 elif curr_lvl < q[0]: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_filter(dataset, rolling=200, quantiles=[.45, .55], polyorder=3) -> pd.DataFrame: """ Generates labels for a financial dataset based on price deviation from a Savitzky-Golay filter. This function applies a Savitzky-Golay filter to the closing prices to generate a smoothed price trend. It then calculates trading signals (buy/sell) based on the deviation of the actual price from this smoothed trend. Buy signals are generated when the price is significantly below the smoothed trend, anticipating a potential price reversal. Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. rolling (int, optional): Window size for the Savitzky-Golay filter. Defaults to 200. quantiles (list, optional): Quantiles to define the "reversion zone". Defaults to [.45, .55]. polyorder (int, optional): Polynomial order for the Savitzky-Golay filter. Defaults to 3. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (no signal) are removed. - Rows with missing values (NaN) are removed. - The temporary 'lvl' column is removed. """ # Calculate smoothed prices using the Savitzky-Golay filter smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) # Calculate the difference between the actual closing prices and the smoothed prices diff = dataset['close'] - smoothed_prices dataset['lvl'] = diff # Add the difference as a new column 'lvl' to the DataFrame # Remove any rows with NaN values dataset = dataset.dropna() # Calculate the quantiles of the 'lvl' column (price deviation) q = dataset['lvl'].quantile(quantiles).to_list() # Extract the closing prices and the calculated 'lvl' values as NumPy arrays close = dataset['close'].values lvl = dataset['lvl'].values # Calculate buy/sell labels using the 'calculate_labels_filter' function labels = calculate_labels_filter(close, lvl, q) # Trim the dataset to match the length of the calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new 'labels' column to the DataFrame dataset['labels'] = labels # Remove any rows with NaN values dataset = dataset.dropna() # Remove rows where the 'labels' column has a value of 2.0 (no signals) dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Return the modified DataFrame with the 'lvl' column removed return dataset.drop(columns=['lvl'])
Um die Kennzeichnung zu beschleunigen, verwenden wir das im vorherigen Artikel beschriebene Numba-Paket.
Die Funktion get_labels_filter() akzeptiert den Originaldatensatz mit den Preisen und den daraus konstruierten Merkmalen, die Länge des Approximationsfensters für den Filter, die Grenzen der unteren und oberen Quantile und den Grad des Polynoms. Das Ergebnis dieser Funktion ist das Hinzufügen von Kauf- oder Verkaufsmarken zum ursprünglichen Datensatz, der dann als Trainingsdatensatz verwendet werden kann.
Die Verlaufsschleife ist in einer separaten Funktion namens calc_labels_filter implementiert, die umfangreiche Berechnungen unter Verwendung des Numba-Pakets durchführt.
Diese Art der Kennzeichnung hat ihre eigenen Merkmale:
- Nicht alle gekennzeichneten Abschlüsse sind gewinnbringend, da weitere Kursänderungen nach dem Überschreiten der Bänder nicht immer in die entgegengesetzte Richtung gehen. Dies kann dazu führen, dass die Beispiele fälschlicherweise als Kauf oder Verkauf gekennzeichnet werden.
- Dieser Nachteil wird theoretisch durch die Tatsache kompensiert, dass die Kennzeichnung einheitlich und nicht zufällig erfolgt und daher falsch gekennzeichnete Beispiele als Trainingsfehler oder Fehler des Handelssystems als Ganzes betrachtet werden können, was zu einer geringeren Überanpassung am Ausgang führen kann.
Die vollständige Beschreibung der Logik für die Kennzeichnung von Handelsgeschäften wird im Folgenden dargelegt:
Funktion calculate_labels_filter
Eingangsdaten:
- close – Array von Schlusskursen
- lvl – Reihe von Preisabweichungen vom geglätteten Trend
- q – Array von Quantilen, die Signalbereiche definieren
Logik:
1. Initialisierung: Erstellen wir ein leeres Array ‘labels‘ mit der gleichen Länge wie ‘close‘, um die Signale zu speichern.
2. Die Schleife durch die Preise: Für jeden Kurs in close[i] und die entsprechende Abweichung in lvl[i]:
- Verkaufssignal: Wenn die Abweichung lvl[i] das obere Quantil q[1] übersteigt, befindet sich der Kurs deutlich über dem geglätteten Trend, was das Verkaufssignal anzeigt (labels[i] = 1,0).
- Kaufsignal: Ist die Abweichung lvl[i] kleiner als das untere Quantil q[0], liegt der Kurs deutlich unter dem geglätteten Trend, was ein Kaufsignal bedeutet (labels[i] = 0,0).
- Kein Signal: In anderen Fällen (Abweichung liegt zwischen den Quantilen) wird kein Signal erzeugt (labels[i] = 2,0).
3. Zurückgegebenes Ergebnis: Rückgabe des Arrays ‘labels‘ mit Signalen.
Funktion get_labels_filter
Eingangsdaten:
- dataset – DataFrame mit Finanzdaten, die die Spalte ‘close‘ (Schlusskurse) enthalten
- rolling – Fenstergröße für die Glättung des Savitzky-Golay-Filters
- Quantile – Quantile zur Bestimmung von Signalbereichen
- polyorder – Ordnung des Polynoms für die Savitzky-Golay-Glättung
Logik:
1. Preisglättung:
- Berechnung der geglätteten Preise unter Anwendung des Savitzky-Golay-Filters auf die Schlusskurse (dataset['close']).
2. Berechnung der Abweichung:
- Wir berechnen die Differenz (Diff) zwischen den tatsächlichen Schlusskursen und den geglätteten Kursen.
- Wir fügen auch die Differenz als neue Spalte ‘lvl‘ zum DataFrame hinzu.
3. Beseitigung von Lücken:
- Zeilen mit fehlenden Werten (NaN) aus DataFrame entfernen.
4. Berechnung der Quantile:
- Berechnen der Quantile für die Spalte ‘lvl‘, die zur Bestimmung der Signalbereiche verwendet werden.
5. Signalberechnung:
- Aufrufen der Funktion calculate_labels_filter auf und Übergabe der Schlusskurse, Abweichungen und Quantile.
- Abrufen des Arrays 'labels' mit Signalen.
6. DataFrame-Behandlung:
- Abschneiden des DataFrame auf die Länge des Arrays 'labels'.
- Fügen wir das Array 'labels' als neue Spalte 'labels' zum DataFrame hinzu.
- Zeichenketten entfernen, bei denen 'labels' gleich 2.0 ist (kein Signal).
- Entfernen der temporären Spalte ‘lvl‘.
7. Zurückgegebenes Ergebnis: Rückgabe eines modifizierten DataFrame mit den Kauf- und Verkaufssignalen in der Spalte ‘labels‘.
Wir werden die obige Kennzeichnungsmethode als Standard betrachten, anhand dessen die Grundprinzipien der Mean-Reversion-Strategie aufgezeigt werden. Dies ist eine Arbeitsmethode, die angewendet werden kann. Wir können es verallgemeinern und modifizieren, um mehrere Filter unterzubringen und die variable Varianz der Abweichungen vom Mittelwert zu berücksichtigen. Nachstehend finden Sie die Funktion get_labels_multiple_filters, mit der solche Änderungen umgesetzt werden.
@njit def calc_labels_multiple_filters(close, lvls, qs): labels = np.empty(len(close), dtype=np.float64) for i in range(len(close)): label_found = False for j in range(len(lvls)): curr_lvl = lvls[j][i] curr_q_low = qs[j][0][i] curr_q_high = qs[j][1][i] if curr_lvl > curr_q_high: labels[i] = 1.0 label_found = True break elif curr_lvl < curr_q_low: labels[i] = 0.0 label_found = True break if not label_found: labels[i] = 2.0 return labels def get_labels_multiple_filters(dataset, rolling_periods=[200, 400, 600], quantiles=[.45, .55], window=100, polyorder=3) -> pd.DataFrame: """ Generates trading signals (buy/sell) based on price deviation from multiple smoothed price trends calculated using a Savitzky-Golay filter with different rolling periods and rolling quantiles. This function applies a Savitzky-Golay filter to the closing prices for each specified 'rolling_period'. It then calculates the price deviation from these smoothed trends and determines dynamic "reversion zones" using rolling quantiles. Buy signals are generated when the price is within these reversion zones across multiple timeframes. Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. rolling_periods (list, optional): List of rolling window sizes for the Savitzky-Golay filter. Defaults to [200, 400, 600]. quantiles (list, optional): Quantiles to define the "reversion zone". Defaults to [.05, .95]. window (int, optional): Window size for calculating rolling quantiles. Defaults to 100. polyorder (int, optional): Polynomial order for the Savitzky-Golay filter. Defaults to 3. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (no signal) are removed. - Rows with missing values (NaN) are removed. """ # Create a copy of the dataset to avoid modifying the original dataset = dataset.copy() # Lists to store price deviation levels and quantiles for each rolling period all_levels = [] all_quantiles = [] # Calculate smoothed price trends and rolling quantiles for each rolling period for rolling in rolling_periods: # Calculate smoothed prices using the Savitzky-Golay filter smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) # Calculate the price deviation from the smoothed prices diff = dataset['close'] - smoothed_prices # Create a temporary DataFrame to calculate rolling quantiles temp_df = pd.DataFrame({'diff': diff}) # Calculate rolling quantiles for the price deviation q_low = temp_df['diff'].rolling(window=window).quantile(quantiles[0]) q_high = temp_df['diff'].rolling(window=window).quantile(quantiles[1]) # Store the price deviation and quantiles for the current rolling period all_levels.append(diff) all_quantiles.append([q_low.values, q_high.values]) # Convert lists to NumPy arrays for faster calculations (potentially using Numba) lvls_array = np.array(all_levels) qs_array = np.array(all_quantiles) # Calculate buy/sell labels using the 'calc_labels_multiple_filters' function labels = calc_labels_multiple_filters(dataset['close'].values, lvls_array, qs_array) # Add the calculated labels to the DataFrame dataset['labels'] = labels # Remove rows with NaN values and no signals (labels == 2.0) dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Return the DataFrame with the new 'labels' column return dataset
Diese Funktion kann eine unbegrenzte Anzahl von Glättungsparametern für den Savitzky-Golay-Filter akzeptieren. Dies kann einen zusätzlichen Vorteil darstellen, da die Kennzeichnung mehrere Filter mit unterschiedlichen Zeiträumen umfasst. Zur Bildung eines Signals reicht es aus, dass bei mindestens einem der Filter Abweichungen vom Mittelwert im Abstand der Quantilsgrenzen ausgelöst werden.
So können wir eine hierarchische Struktur für die Kennzeichnung von Handelsgeschäften aufbauen. So wird zum Beispiel zuerst die Bedingung für den Hochpassfilter, dann für den Mittelpassfilter und schließlich für den Tiefpassfilter geprüft. Tiefpassfiltersignale können als zuverlässiger angesehen werden, sodass vorherige Signale durch ein Tiefpassfiltersignal überschrieben werden, wenn ein solches auftritt. Wenn der Tiefpassfilter jedoch kein Signal erzeugt, werden die Handelsgeschäfte weiterhin auf der Grundlage der Signale der vorherigen Filter markiert. Dies trägt dazu bei, die Anzahl der gekennzeichneten Beispiele zu erhöhen, und ermöglicht höhere Eingabeschwellen (Quantile), da es die Chance erhöht, dass mindestens ein Signal in einer Reihe von Filtern auftaucht.
Quantilberechnungen werden jetzt in einem gleitenden Fenster mit einer konfigurierbaren Periode durchgeführt, wodurch die variable Varianz der Abweichungen vom Mittelwert für genauere Signale berücksichtigt werden kann.
Schließlich können wir den Fall asymmetrischer Abschlüsse betrachten, indem wir davon ausgehen, dass Filter mit unterschiedlichen Glättungsperioden erforderlich sein können, um Kauf- und Verkaufsaufträge aufgrund des verzerrten Durchschnitts der Notierungen zu markieren. Dieser Ansatz wird durch die Funktion get_labels_filter_bidirectional umgesetzt.
@njit def calc_labels_bidirectional(close, lvl1, lvl2, q1, q2): labels = np.empty(len(close), dtype=np.float64) for i in range(len(close)): curr_lvl1 = lvl1[i] curr_lvl2 = lvl2[i] if curr_lvl1 > q1[1]: labels[i] = 1.0 elif curr_lvl2 < q2[0]: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_filter_bidirectional(dataset, rolling1=200, rolling2=200, quantiles=[.45, .55], polyorder=3) -> pd.DataFrame: """ Generates trading labels based on price deviation from two Savitzky-Golay filters applied in opposite directions (forward and reversed) to the closing price data. This function calculates trading signals (buy/sell) based on the price's position relative to smoothed price trends generated by two Savitzky-Golay filters with potentially different window sizes (`rolling1`, `rolling2`). Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. rolling1 (int, optional): Window size for the first Savitzky-Golay filter. Defaults to 200. rolling2 (int, optional): Window size for the second Savitzky-Golay filter. Defaults to 200. quantiles (list, optional): Quantiles to define the "reversion zones". Defaults to [.45, .55]. polyorder (int, optional): Polynomial order for both Savitzky-Golay filters. Defaults to 3. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (no signal) are removed. - Rows with missing values (NaN) are removed. - Temporary 'lvl1' and 'lvl2' columns are removed. """ # Apply the first Savitzky-Golay filter (forward direction) smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling1, polyorder=polyorder) # Apply the second Savitzky-Golay filter (could be in reverse direction if rolling2 is negative) smoothed_prices2 = savgol_filter(dataset['close'].values, window_length=rolling2, polyorder=polyorder) # Calculate price deviations from both smoothed price series diff1 = dataset['close'] - smoothed_prices diff2 = dataset['close'] - smoothed_prices2 # Add price deviations as new columns to the DataFrame dataset['lvl1'] = diff1 dataset['lvl2'] = diff2 # Remove rows with NaN values dataset = dataset.dropna() # Calculate quantiles for the "reversion zones" for both price deviation series q1 = dataset['lvl1'].quantile(quantiles).to_list() q2 = dataset['lvl2'].quantile(quantiles).to_list() # Extract relevant data for label calculation close = dataset['close'].values lvl1 = dataset['lvl1'].values lvl2 = dataset['lvl2'].values # Calculate buy/sell labels using the 'calc_labels_bidirectional' function labels = calc_labels_bidirectional(close, lvl1, lvl2, q1, q2) # Process the dataset and labels dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Remove bad signals (if any) # Return the DataFrame with temporary columns removed return dataset.drop(columns=['lvl1', 'lvl2'])
Diese Funktion akzeptiert rollierende1 und rollierende2 Glättungsperioden, die den Kauf- und Verkaufsgeschäften entsprechen. Durch Variation dieser Parameter kann man versuchen, eine bessere Kennzeichnungs- und Generalisierungsfähigkeit bei neuen Daten zu erreichen. Wenn zum Beispiel ein Währungspaar in einem Aufwärtstrend ist und es vorzuziehen ist, Kaufgeschäfte zu eröffnen, dann können Sie die Länge des roling1-Fensters für die Markierung von Verkaufsgeschäften erhöhen, und es wird weniger von ihnen geben, oder sie werden nur in den Momenten wirklich starker Trendumkehrungen auftreten. Bei Kaufgeschäften können wir die Länge des roling2-Fensters verringern, sodass es mehr Kaufgeschäfte als Verkaufsgeschäfte geben wird.
Kennzeichnung mit einer Beschränkung auf profitable Geschäfte und Filterauswahl
Es wurde bereits erwähnt, dass die vorgeschlagenen Handelsmarker das Vorhandensein von gekennzeichneten, aber offensichtlich unrentablen Geschäften zulassen. Dies ist kein Fehler, sondern eher eine Funktion.
Wir können Prüfungen hinzufügen, um sicherzustellen, dass nur profitable Geschäfte gekennzeichnet werden. Dies kann nützlich sein, wenn die Saldenkurve einer idealen geraden Linie ohne signifikante Absenkungen angenähert werden soll.
Außerdem wurde nur ein einziger Savitzky-Golay-Filter verwendet, aber ich möchte ihre Vielfalt durch Hinzufügen eines einfachen gleitenden Durchschnitts und eines Splines (Kurve) als Filter erhöhen.
Schauen wir uns die Optionen für solche Handelsmustertücher an. Wir werden die Funktion get_labels_mean_reversion als Grundlage verwenden, die Einschränkungen bei der Rentabilität und der Filterauswahl vorsieht.
@njit def calculate_labels_mean_reversion(close, lvl, markup, min_l, max_l, q): labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): rand = random.randint(min_l, max_l) curr_pr = close[i] curr_lvl = lvl[i] future_pr = close[i + rand] if curr_lvl > q[1] and (future_pr + markup) < curr_pr: labels[i] = 1.0 elif curr_lvl < q[0] and (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_mean_reversion(dataset, markup, min_l=1, max_l=15, rolling=0.5, quantiles=[.45, .55], method='spline', shift=0) -> pd.DataFrame: """ Generates labels for a financial dataset based on mean reversion principles. This function calculates trading signals (buy/sell) based on the deviation of the price from a chosen moving average or smoothing method. It identifies potential buy opportunities when the price deviates significantly below its smoothed trend, anticipating a reversion to the mean. Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. markup (float): The percentage markup used to determine buy signals. min_l (int, optional): Minimum number of consecutive days the markup must hold. Defaults to 1. max_l (int, optional): Maximum number of consecutive days the markup is considered. Defaults to 15. rolling (float, optional): Rolling window size for smoothing/averaging. If method='spline', this controls the spline smoothing factor. Defaults to 0.5. quantiles (list, optional): Quantiles to define the "reversion zone". Defaults to [.45, .55]. method (str, optional): Method for calculating the price deviation: - 'mean': Deviation from the rolling mean. - 'spline': Deviation from a smoothed spline. - 'savgol': Deviation from a Savitzky-Golay filter. Defaults to 'spline'. shift (int, optional): Shift the smoothed price data forward (positive) or backward (negative). Useful for creating a lag/lead effect. Defaults to 0. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (no signal) are removed. - Rows with missing values (NaN) are removed. - The temporary 'lvl' column is removed. """ # Calculate the price deviation ('lvl') based on the chosen method if method == 'mean': dataset['lvl'] = (dataset['close'] - dataset['close'].rolling(rolling).mean()) elif method == 'spline': x = np.array(range(dataset.shape[0])) y = dataset['close'].values spl = UnivariateSpline(x, y, k=3, s=rolling) yHat = spl(np.linspace(min(x), max(x), num=x.shape[0])) yHat_shifted = np.roll(yHat, shift=shift) # Apply the shift dataset['lvl'] = dataset['close'] - yHat_shifted dataset = dataset.dropna() # Remove NaN values potentially introduced by spline/shift elif method == 'savgol': smoothed_prices = savgol_filter(dataset['close'].values, window_length=int(rolling), polyorder=3) dataset['lvl'] = dataset['close'] - smoothed_prices dataset = dataset.dropna() # Remove NaN values before proceeding q = dataset['lvl'].quantile(quantiles).to_list() # Calculate quantiles for the 'reversion zone' # Prepare data for label calculation close = dataset['close'].values lvl = dataset['lvl'].values # Calculate buy/sell labels labels = calculate_labels_mean_reversion(close, lvl, markup, min_l, max_l, q) # Process the dataset and labels dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Remove sell signals (if any) return dataset.drop(columns=['lvl']) # Remove the temporary 'lvl' column
Ich habe den Code der Funktion get_labels, die zu Beginn des Abschnitts besprochen und in früheren Artikeln verwendet wurde, zur Überprüfung der Rentabilität von Geschäften und als Grundlage verwendet. Nach diesem Prinzip werden Geschäfte ausgewählt, die die Kennzeichnung durch einen Filter durchlaufen haben. Nur die Handelsgeschäfte, die für eine bestimmte Anzahl von Schritten im Voraus profitabel sind, werden ausgewählt; andernfalls werden sie als 2,0 gekennzeichnet und dann aus dem Datensatz entfernt. Außerdem habe ich zwei neue Filter hinzugefügt: gleitender Durchschnitt und Spline.
Während der einfache gleitende Durchschnitt im Handel weithin bekannt ist, ist die Methode zur Konstruktion eines Splines nicht jedem geläufig und sollte erklärt werden.
Splines sind ein flexibles Werkzeug zur Annäherung von Funktionen. Anstatt ein komplexes Polynom für die gesamte Funktion zu konstruieren, unterteilen Splines den Bereich in Intervalle und konstruieren für jedes Intervall ein eigenes Polynom. Diese Polynome gehen an den Grenzen der Intervalle fließend ineinander über, sodass eine kontinuierliche und glatte Kurve entsteht.
Es gibt verschiedene Arten von Splines, die jedoch alle nach einem ähnlichen Prinzip aufgebaut sind:
- Bereichsaufteilung: Das ursprüngliche Intervall, auf dem die Funktion definiert ist, wird durch Punkte, die als Knoten bezeichnet werden, in Teilintervalle unterteilt.
- Auswählen des Polynomgrades: Bestimmt den Grad des Polynoms, das für jedes Teilintervall verwendet wird.
- Polynomielle Konstruktion: Für jedes Teilintervall wird ein Polynom des gewählten Grades konstruiert, das durch die Datenpunkte in diesem Intervall verläuft.
- Gewährleistung der Glätte: Die Verhältnisse der Polynome werden so gewählt, dass die Glätte des Splines an den Grenzen der Intervalle gewährleistet ist. Dies bedeutet in der Regel, dass die Werte benachbarter Polynome und ihrer Ableitungen an den Knoten übereinstimmen sollten.
Splines können bei der Analyse von Finanzzeitreihen nützlich sein:
- Interpolation und Glättung von Daten: Mit Splines können wir das Rauschen in Ihren Daten glätten und die Werte einer Zeitreihe an Punkten schätzen, an denen Messungen fehlen.
- Trend-Simulation: Mit Hilfe von Splines können langfristige Trends in Daten modelliert und von kurzfristigen Schwankungen getrennt werden.
- Vorhersage: Einige Arten von Splines können für die Vorhersage zukünftiger Werte einer Zeitreihe verwendet werden.
- Abgeleitete Schätzungen: Mit Hilfe von Splines können wir die Ableitungen einer Zeitreihe schätzen, was für die Analyse der Preisänderungsrate nützlich sein kann.
In unserem Fall werden wir die Zeitreihe mit einem Spline und einem gleitenden Durchschnitt glätten, so wie es bei der Verwendung des Savitzky-Golay-Filters geschehen ist. Wir können die Kennzeichnung mit jedem Filter separat durchführen und dann die Ergebnisse vergleichen und den besten Filter für eine bestimmte Situation auswählen.
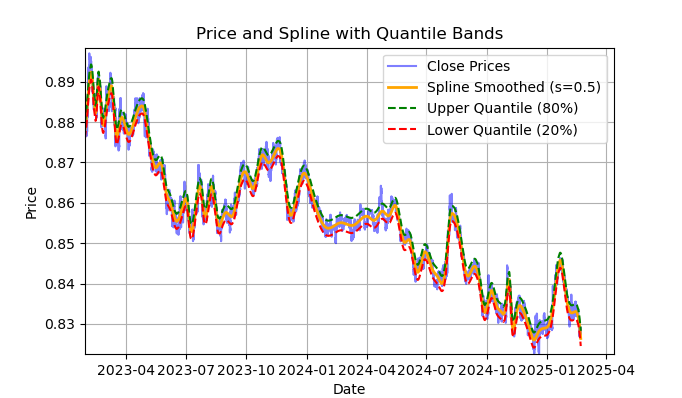
Abb. 2. Anzeige der Spline-Filter und Banden (Quantile)
Abb. 2 zeigt die Glättungslinie des Spline-Filters und die 20- und 80-Quantilbänder. Der Hauptunterschied zwischen dem Spline-Filter und dem Savitzky-Golay-Filter besteht darin, dass er die Reihen mit Hilfe von stückweise linearen oder nichtlinearen Funktionen glättet, abhängig vom Glättungsfaktor s, der am besten im Bereich von 0,1;1 eingestellt wird, und vom Grad des Polynoms, der normalerweise im Bereich von 1 bis 3 liegt. Wenn wir diese Parameter variieren, können wir die Unterschiede in der resultierenden Glättung visuell beurteilen. Im Code ist der Grad des Polynoms k=3 festgelegt, er kann aber auch geändert werden.
Der Code zur Konstruktion und visuellen Auswertung eines Splines sieht folgendermaßen aus:
import pandas as pd from scipy.interpolate import UnivariateSpline import matplotlib.pyplot as plt def plot_close_filter_quantiles(dataset, rolling=200, quantiles=[0.2, 0.8]): """ Plots close prices with spline smoothing and quantile bands. Args: dataset (pd.DataFrame): DataFrame with 'close' column and datetime index. rolling (int, optional): Rolling window size for spline smoothing. Defaults to 200. quantiles (list, optional): Quantiles for band calculation. Defaults to [0.2, 0.8]. s (float, optional): Smoothing factor for UnivariateSpline. Adjusts the spline stiffness. Defaults to 1000. """ # Create spline smoothing # Convert datetime index to numerical values (Unix timestamps) numerical_index = pd.to_numeric(dataset.index) # Create spline smoothing using the numerical index spline = UnivariateSpline(numerical_index, dataset['close'], k=3, s=rolling) smoothed = spline(numerical_index) # Calculate difference between prices and filter lvl = dataset['close'] - smoothed # Get quantile values q_low, q_high = lvl.quantile(quantiles).tolist() # Calculate bands based on quantiles upper_band = smoothed + q_high lower_band = smoothed + q_low # Create plot plt.figure(figsize=(14, 7)) plt.plot(dataset.index, dataset['close'], label='Close Prices', color='blue', alpha=0.5) plt.plot(dataset.index, smoothed, label=f'Spline Smoothed (s={rolling})', color='orange', linewidth=2) plt.plot(dataset.index, upper_band, label=f'Upper Quantile ({quantiles[1]*100:.0f}%)', color='green', linestyle='--') plt.plot(dataset.index, lower_band, label=f'Lower Quantile ({quantiles[0]*100:.0f}%)', color='red', linestyle='--') # Configure display plt.title('Price and Spline with Quantile Bands') plt.xlabel('Date') plt.ylabel('Price') plt.legend() plt.grid(True) plt.show()
Eine ausführliche Beschreibung der gesamten Funktion calculate_labels_mean_reversion für ein umfassendes Verständnis des Codes für die Handelskennzeichnung finden Sie weiter unten.
calculate_labels_mean_reversion Funktion:
Eingangsdaten:
- close – Array von Schlusskursen
- lvl – Array der Preisabweichungen von der geglätteten Reihe
- markup – in %
- min_l – Mindestanzahl der Kerzen zur Prüfung der Bedingung
- max_l – maximale Anzahl von Kerzen zur Prüfung der Bedingung
- eine Reihe von Quantilen, die Signalbereiche definieren
Logik:
1. Initialisierung: Erstellen wir ein leeres Array 'labels' der Länge len(close) – max_l, um die Signale zu speichern. Die Länge wurde gekürzt, um den zukünftigen Preiswerten Rechnung zu tragen.
2. Die Schleife durch die Preise: Für jeden Kurs close[i] mit Index i von 0 bis len(close) – max_l – 1:
- Definieren der Zufallszahl 'rand' zwischen min_l und max_l.
- Ermittelt den aktuellen Preis curr_pr, die aktuelle Abweichung curr_lvl und den zukünftigen Preis future_pr für 'rand'-Kerzen im Voraus.
- Verkaufssignal: Wenn curr_lvl größer ist als das (q[1]) obere Quantil und der zukünftige Preis future_pr unter Berücksichtigung des ‘Aufschlags‘ kleiner ist als der aktuelle Preis, setzen wir labels[i] = 1,0.
- Singal kaufen: Wenn curr_lvl kleiner ist als das untere Quantil (q[0]) und der zukünftige Preis future_pr abzüglich des Aufschlags größer ist als der aktuelle Preis, wird labels[i] = 0,0 gesetzt.
- Kein Signal: In anderen Fällen setzen wir labels[i] = 2.0.
3. Zurückgegebenes Ergebnis: Rückgabe des Arrays ‘labels‘ mit Signalen.
Funktion get_labels_mean_reversion:
Eingangsdaten:
- dataset – DataFrame mit Finanzdaten, die die Spalte ‘close‘ enthalten
- markup – in %
- min_l – Mindestanzahl der Kerzen zur Prüfung der Bedingung
- max_l – maximale Anzahl von Kerzen zur Prüfung der Bedingung
- rolling – Glättungsparameter (Fenstergröße oder Verhältnis)
- quantiles – Quantile zur Bestimmung von Signalbereichen
- method – Glättungsmethode ('mean', 'spline', 'savgol')
- shift – Verschiebung der geglätteten Reihe
Logik:
1. Berechnung der Abweichung: Berechnen wir die Abweichungen von der geglätteten Preisreihe (close) in Abhängigkeit von der gewählten ‘Methode‘:
- mean – Abweichung vom gleitenden Durchschnitt
- spline – Abweichung von der spline-geglätteten Kurve
- savgol – Abweichung vom geglätteten Savitzky-Golay-Filter
2. Beseitigung von Lücken: Zeilen mit Lücken (NaN) aus dem Datensatz entfernen.
3. Berechnung der Quantile: Berechnung von q-Quantilen für lvl-Abweichungen.
4. Aufbereitung der Daten: Extrahieren von Arrays mit Schlusskursen und Niveauabweichungen aus dem ‘dataset‘.
5. Signalberechnung:
- Rufen wir die Funktion calculate_labels_mean_reversion mit den vorbereiteten Daten auf, um das Array 'labels' mit den Signalen zu erhalten.
6. DataFrame-Behandlung:
- ‘dataset‘ bis zu ‘labels‘ abschneiden.
- Fügen wir ‘labels‘ als neue Spalte ‘labels‘ zu ‘dataset‘ hinzu.
- Zeilen mit Lücken (NaN) aus dem ‘dataset‘ entfernen.
- Zeichenketten entfernen, bei denen 'labels' gleich 2.0 ist (kein Signal).
- Entfernen der Spalte lvl.
Zur Abwechslung wollen wir eine Version desselben Samplers implementieren, die die Bedingungen für mehrere Filter mit unterschiedlichen Perioden prüft, und nicht nur für einen. Wenn alle Bedingungen für alle Filter erfüllt sind und sie die gleiche Richtung haben (Kauf oder Verkauf) und die Transaktion über einen Zeitraum von n Bars in die Zukunft profitabel ist, dann erfüllt sie die Etikettierungsbedingungen; andernfalls wird sie ignoriert und aus der Trainingsstichprobe entfernt.
@njit def calculate_labels_mean_reversion_multi(close_data, lvl_data, q, markup, min_l, max_l, windows): labels = [] for i in range(len(close_data) - max_l): rand = random.randint(min_l, max_l) curr_pr = close_data[i] future_pr = close_data[i + rand] buy_condition = True sell_condition = True qq = 0 for rolling in windows: curr_lvl = lvl_data[i, qq] if not (curr_lvl >= q[qq][1]): sell_condition = False if not (curr_lvl <= q[qq][0]): buy_condition = False qq+=1 if sell_condition and (future_pr + markup) < curr_pr: labels.append(1.0) elif buy_condition and (future_pr - markup) > curr_pr: labels.append(0.0) else: labels.append(2.0) return labels def get_labels_mean_reversion_multi(dataset, markup, min_l=1, max_l=15, windows=[0.2, 0.3, 0.5], quantiles=[.45, .55]): """ Generates labels for a financial dataset based on mean reversion principles using multiple smoothing windows. This function calculates trading signals (buy/sell) based on the deviation of the price from smoothed price trends calculated using multiple spline smoothing factors (windows). It identifies potential buy opportunities when the price deviates significantly below its smoothed trends across multiple timeframes. Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. markup (float): The percentage markup used to determine buy signals. min_l (int, optional): Minimum number of consecutive days the markup must hold. Defaults to 1. max_l (int, optional): Maximum number of consecutive days the markup is considered. Defaults to 15. windows (list, optional): List of smoothing factors (rolling window equivalents) for spline calculations. Defaults to [0.2, 0.3, 0.5]. quantiles (list, optional): Quantiles to define the "reversion zone". Defaults to [.45, .55]. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (sell signal) are removed. - Rows with missing values (NaN) are removed. """ q = [] # Initialize an empty list to store quantiles for each window lvl_data = np.empty((dataset.shape[0], len(windows))) # Initialize a 2D array to store price deviation data # Calculate price deviation from smoothed trends for each window for i, rolling in enumerate(windows): x = np.array(range(dataset.shape[0])) # Create an array of x-values (time index) y = dataset['close'].values # Extract closing prices spl = UnivariateSpline(x, y, k=3, s=rolling) # Create a spline smoothing function yHat = spl(np.linspace(min(x), max(x), num=x.shape[0])) # Generate smoothed price data lvl_data[:, i] = dataset['close'] - yHat # Calculate price deviation from smoothed prices q.append(np.quantile(lvl_data[:, i], quantiles).tolist()) # Calculate and store quantiles dataset = dataset.dropna() # Remove NaN values before proceeding close_data = dataset['close'].values # Extract closing prices # Calculate buy/hold labels using multiple price deviation series labels = calculate_labels_mean_reversion_multi(close_data, lvl_data, q, markup, min_l, max_l, windows) # Process the dataset and labels dataset = dataset.iloc[:len(labels)].copy() # Trim the dataset to match label length dataset['labels'] = labels # Add the calculated labels as a new column dataset = dataset.dropna() # Remove rows with NaN values dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Remove sell signals (if any) return dataset
Abschließend wollen wir eine weitere Funktion zur Kennzeichnung von Handelsgeschäften mit einer Rückkehr zum Mittelwert schreiben, die Quantile in einem gleitenden Fenster einer bestimmten Periode berechnet, anstatt über die gesamte Beobachtungshistorie. Dies wird dazu beitragen, die Auswirkungen der variablen Volatilität der Preisabweichung vom Mittelwert zu glätten.
@njit def calculate_labels_mean_reversion_v(close_data, lvl_data, volatility_group, quantile_groups, markup, min_l, max_l): labels = [] for i in range(len(close_data) - max_l): rand = random.randint(min_l, max_l) curr_pr = close_data[i] curr_lvl = lvl_data[i] curr_vol_group = volatility_group[i] future_pr = close_data[i + rand] q = quantile_groups[curr_vol_group] if curr_lvl > q[1] and (future_pr + markup) < curr_pr: labels.append(1.0) elif curr_lvl < q[0] and (future_pr - markup) > curr_pr: labels.append(0.0) else: labels.append(2.0) return labels def get_labels_mean_reversion_v(dataset, markup, min_l=1, max_l=15, rolling=0.5, quantiles=[.45, .55], method='spline', shift=1, volatility_window=20) -> pd.DataFrame: """ Generates trading labels based on mean reversion principles, incorporating volatility-based adjustments to identify buy opportunities. This function calculates trading signals (buy/sell), taking into account the volatility of the asset. It groups the data into volatility bands and calculates quantiles for each band. This allows for more dynamic "reversion zones" that adjust to changing market conditions. Args: dataset (pd.DataFrame): DataFrame containing financial data with a 'close' column. markup (float): The percentage markup used to determine buy signals. min_l (int, optional): Minimum number of consecutive days the markup must hold. Defaults to 1. max_l (int, optional): Maximum number of consecutive days the markup is considered. Defaults to 15. rolling (float, optional): Rolling window size or spline smoothing factor (see 'method'). Defaults to 0.5. quantiles (list, optional): Quantiles to define the "reversion zone". Defaults to [.45, .55]. method (str, optional): Method for calculating the price deviation: - 'mean': Deviation from the rolling mean. - 'spline': Deviation from a smoothed spline. - 'savgol': Deviation from a Savitzky-Golay filter. Defaults to 'spline'. shift (int, optional): Shift the smoothed price data (lag/lead effect). Defaults to 1. volatility_window (int, optional): Window size for calculating volatility. Defaults to 20. Returns: pd.DataFrame: The original DataFrame with a new 'labels' column and filtered rows: - 'labels' column: - 0: Buy - 1: Sell - Rows where 'labels' is 2 (no signal) are removed. - Rows with missing values (NaN) are removed. - Temporary 'lvl', 'volatility', 'volatility_group' columns are removed. """ # Calculate Volatility dataset['volatility'] = dataset['close'].pct_change().rolling(window=volatility_window).std() # Divide into 20 groups by volatility dataset['volatility_group'] = pd.qcut(dataset['volatility'], q=20, labels=False) # Calculate price deviation ('lvl') based on the chosen method if method == 'mean': dataset['lvl'] = (dataset['close'] - dataset['close'].rolling(rolling).mean()) elif method == 'spline': x = np.array(range(dataset.shape[0])) y = dataset['close'].values spl = UnivariateSpline(x, y, k=3, s=rolling) yHat = spl(np.linspace(min(x), max(x), num=x.shape[0])) yHat_shifted = np.roll(yHat, shift=shift) # Apply the shift dataset['lvl'] = dataset['close'] - yHat_shifted dataset = dataset.dropna() elif method == 'savgol': smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=5) dataset['lvl'] = dataset['close'] - smoothed_prices dataset = dataset.dropna() # Calculate quantiles for each volatility group quantile_groups = {} for group in range(20): group_data = dataset[dataset['volatility_group'] == group]['lvl'] quantile_groups[group] = group_data.quantile(quantiles).to_list() # Prepare data for label calculation (potentially using Numba) close_data = dataset['close'].values lvl_data = dataset['lvl'].values volatility_group = dataset['volatility_group'].values # Calculate buy/sell labels labels = calculate_labels_mean_reversion_v(close_data, lvl_data, volatility_group, quantile_groups, markup, min_l, max_l) # Process dataset and labels dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) # Remove sell signals # Remove temporary columns and return return dataset.drop(columns=['lvl', 'volatility', 'volatility_group'])
Wir haben also bereits eine Reihe von Handelsmarkern, mit denen wir experimentieren können. Es können Ansätze kombiniert und neue Ansätze geschaffen werden.
Die vollständige Liste der oben beschriebenen Handelsmuster aus der Bibliothek labeling_lib.py ist nachstehend aufgeführt. Darauf aufbauend können wir alte ändern und neue erstellen, je nachdem, wie gut wir die Marktmuster verstehen und welche Strategie wir daraus ableiten wollen. Das Modul enthält auch andere nutzerdefinierte Handels-Sampler, die jedoch nichts mit Mean-Reversion-Strategien zu tun haben und daher in diesem Artikel nicht beschrieben werden.
# FILTERING BASED LABELING W/O RESTRICTIONS def get_labels_filter(dataset, rolling=200, quantiles=[.45, .55], polyorder=3) -> pd.DataFrame def get_labels_multiple_filters(dataset, rolling_periods=[200, 400, 600], quantiles=[.45, .55], window=100, polyorder=3) -> pd.DataFrame def get_labels_filter_bidirectional(dataset, rolling1=200, rolling2=200, quantiles=[.45, .55], polyorder=3) -> pd.DataFrame: # MEAN REVERSION WITH RESTRICTIONS BASED LABELING def get_labels_mean_reversion(dataset, markup, min_l=1, max_l=15, rolling=0.5, quantiles=[.45, .55], method='spline', shift=0) -> pd.DataFrame def get_labels_mean_reversion_multi(dataset, markup, min_l=1, max_l=15, windows=[0.2, 0.3, 0.5], quantiles=[.45, .55]) -> pd.DataFrame def get_labels_mean_reversion_v(dataset, markup, min_l=1, max_l=15, rolling=0.5, quantiles=[.45, .55], method='spline', shift=1, volatility_window=20) -> pd.DataFrame:
Es ist nun an der Zeit, zum zweiten Teil des Artikels überzugehen, nämlich dem Clustern von Marktmodi und der anschließenden Kombination beider Ansätze, um Handelssysteme auf der Grundlage der Rückkehr zum Mittelwert zu entwickeln.
Was ist zu clustern und warum ist es notwendig?
Bevor wir etwas clustern, müssen wir entscheiden, warum wir das überhaupt tun müssen. Stellen wir uns ein Kurs-Chart vor, das einen Trend, eine flache Kurve, Perioden mit hoher und niedriger Volatilität, verschiedene Muster und andere Merkmale aufweist. Das heißt, das Preis-Chart ist nicht etwas Einheitliches, in dem die gleichen Muster vorhanden sind. Man könnte sogar sagen, dass es in verschiedenen Zeitabschnitten unterschiedliche Muster gibt oder geben kann, die in anderen Zeitintervallen verschwinden.
Das Clustering ermöglicht es uns, die ursprüngliche Zeitreihe anhand bestimmter Merkmale in mehrere Zustände zu unterteilen, sodass jeder dieser Zustände ähnliche Beobachtungen beschreibt. Dies kann den Aufbau eines Handelssystems erleichtern, da das Training auf homogeneren, ähnlichen Daten erfolgt. Zumindest kann man sich das so vorstellen. Natürlich wird das Handelssystem nicht mehr über den gesamten historischen Zeitraum arbeiten, sondern über einen ausgewählten Teil davon, der aus verschiedenen Zeitpunkten besteht, deren Werte in ein bestimmtes Cluster fallen.
Nach der Clusterbildung können nur ausgewählte Beispiele etikettiert werden, d. h. es werden ihnen eindeutige Klassenkennzeichnungen zugewiesen, um das endgültige Modell zu erstellen. Wenn ein Cluster homogene Daten mit ähnlichen Beobachtungen enthält, sollte seine Kennzeichnung homogener und damit vorhersehbarer werden. Wir können mehrere Datencluster nehmen, jeden von ihnen separat gekennzeichnet, dann Modelle für maschinelles Lernen auf den Daten aus jedem Cluster trainieren und sie auf den Trainings- und Testdaten testen. Wenn ein Cluster gefunden wird, der es dem Modell ermöglicht, gut zu lernen, d. h. zu verallgemeinern und Vorhersagen für neue Daten zu treffen, kann die Aufgabe der Entwicklung eines Handelssystems als praktisch abgeschlossen betrachtet werden.
Clustering von Finanzzeitreihen zur Ermittlung von Marktmodi
Bevor Sie diesen Abschnitt lesen, sollten Sie sich mit den verschiedenen Arten von Clustering-Algorithmen vertraut machen, die im vorherigen Artikel beschrieben wurden. Sie enthält auch eine vergleichende Tabelle verschiedener Clustering-Algorithmen und ihrer Testergebnisse. Für diesen Artikel habe ich den konventionellen k-means Clustering-Algorithmus als den schnellsten und effizientesten gewählt.
Bei der Erstellung von Merkmalen mit der Funktion get_features müssen wir die Möglichkeit vorsehen, dass im Datensatz genau die Merkmale vorhanden sind, nach denen das Clustering durchgeführt werden soll. Ich schlage vor, von drei grundlegenden Optionen auszugehen. Wenn Sie andere Merkmale kennen, die Ihrer Meinung nach Marktregime gut beschreiben, können Sie sie gerne verwenden. Dazu muss ihre Berechnung in die Funktion zur Feature-Erzeugung aufgenommen werden, und sie müssen „meta_feature“-Symbole in ihrem Namen enthalten, um sie weiter von den Hauptfeatures zu trennen.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).skew() count += 1 # for i in hyper_params['periods_meta']: # pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() # count += 1 # for i in hyper_params['periods_meta']: # pFixed[str(count)+'meta_feature'] = pFixedC - pFixedC.rolling(i).mean() # count += 1 return pFixed.dropna()
In der ersten Schleife werden alle in der Liste ‘periods‘ angegebenen Merkmale berechnet. Dies sind die wichtigsten Merkmale, die zum Trainieren des Hauptmodells für maschinelles Lernen verwendet werden, das Kauf- oder Verkaufstransaktionen vorhersagt. In diesem Fall handelt es sich um einfache gleitende Durchschnitte mit unterschiedlichen Zeiträumen.
In der zweiten Schleife werden die in der Liste ‘periods_meta‘ angegebenen Merkmale berechnet. Dies sind genau die Merkmale, die zur Clusterbildung von Marktregimen beitragen werden. Standardmäßig wird das Clustering auf der Grundlage der Schiefe der Kurse im gleitenden Fenster berechnet. Die auskommentierten Felder entsprechen der Berechnung von Merkmalen auf der Grundlage der Standardabweichung im gleitenden Fenster oder auf der Grundlage von Preisinkrementen. Die Auswahl der Merkmale erfolgt empirisch, durch eine Enumeration verschiedener Optionen. Experimente haben gezeigt, dass das auf Schiefe (Asymmetrie) basierende Clustern die Daten gut trennt, daher wird sie in diesem Artikel verwendet.
Schiefe (oder Asymmetrie) in Verteilungen ist ein Merkmal, das das Ausmaß beschreibt, in dem eine Datenverteilung nicht symmetrisch um ihren Mittelwert ist. Die Schiefe misst, wie stark eine Verteilung von der Symmetrie abweicht (z. B. eine Normalverteilung). Die Schiefe wird anhand des Verhältnisses der Asymmetrie (Schiefe) gemessen. Mit dem Skew Clustering können Datengruppen mit ähnlichen Verteilungsmerkmalen identifiziert werden, was bei der Ermittlung dieser Modi hilfreich ist. So kann eine positive Steigung auf Perioden mit seltenen, aber starken Preissprüngen (z. B. während Krisen) hindeuten, während eine negative Steigung Perioden mit gleichmäßigeren Veränderungen anzeigen kann.
Nachdem die Merkmale gebildet wurden, wird der endgültige Datensatz an die Funktion übergeben, die das Clustering durchführt. Die Funktion fügt auch eine neue Spalte „clusters“ hinzu, die die Clusternummern enthält.
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
Um ein „Peeken“ zu verhindern, werden die Daten vor und nach den in den Algorithmuseinstellungen angegebenen Daten abgeschnitten, sodass das Clustering nur mit den Daten durchgeführt wird, die für das Modelltraining verwendet werden. Der Code enthält auch eine Auswahl von Merkmalen für das Clustering, die mit dem Schlüsselwort ‘meta_feature‘ im Namen der Merkmalsspalte ausgewählt werden.
Alle Hyperparameter des Algorithmus werden in einem Wörterbuch gespeichert, dessen Daten zur Erstellung von Merkmalen, zur Auswahl des Trainingszeitraums usw. verwendet werden.
hyper_params = {
'symbol': 'EURGBP_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
# 'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files (x86)/RoboForex MT4 Terminal/MQL4/Include/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.02000,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [10],
'backward': datetime(2000, 1, 1),
'forward': datetime(2021, 1, 1),
'n_clusters': 10,
'rolling': 200,
} - Der Name der Datei auf der Festplatte, die die Symbolanführungszeichen enthält
- Exportpfad für den Export von trainierten Modellen in das #include-Verzeichnis des MetaTrader 5 Terminals
- Modell-ID, um sie nach dem Export zu unterscheiden, wenn mehrere Modelle exportiert werden müssen
- Aufschlag, der dem durchschnittlichen Spread und der Provision in Punkten Rechnung tragen sollte. Für eine genauere Kennzeichnung von Handelsgeschäften und anschließende Tests in der Vergangenheit.
- Stopp-Loss unterstützt durch den schnellen Custom-Tester
- Take-Profit
- Liste der Zeiträume für die Berechnung der Hauptmerkmale. Jedes einzelne Element der Liste stellt einen Zeitraum für ein separates Merkmal dar. Je mehr Elemente, desto mehr Funktionen.
- Liste der Zeiträume für Merkmale, die am Clustering teilnehmen.
- Anfangsdatum des Modelltraining
- Enddatum der Modelltraining
- Die Anzahl der Cluster (Modi), in die die Daten unterteilt werden
- Parameter des rollenden Fensters für die Filterglättung
Fassen wir nun alles zusammen, betrachten wir die Hauptschleife der Modelltraining und analysieren wir alle Phasen der Vorverarbeitung und des Trainings selbst.
# LEARNING LOOP dataset = get_features(get_prices()) models = [] for i in range(1): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_filter(clustered_data, rolling=hyper_params['rolling'], quantiles=[0.45, 0.55], polyorder=3 ) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1)))
Zunächst wird ein Datensatz erstellt, der Preise und Merkmale enthält. Das Erstellen von Merkmalen wurde oben beschrieben. Dann wird die Liste ‘Modelle‘ erstellt, in der die bereits trainierten Modelle gespeichert werden. Als Nächstes haben wir die Wahl, wie viele Trainingsiterationen in der Schleife durchgeführt werden sollen. Die Standardeinstellung ist eine Iteration. Wenn Sie mehrere Modelle trainieren müssen, geben Sie deren Anzahl im range()-Iterator an.
Anschließend wird der ursprüngliche Datensatz geclustert, und jedem Beispiel wird eine Clusternummer zugewiesen. Wenn in den Hyperparametern 10 n_clusters angegeben sind, wird dieser Parameter an die Funktion übergeben, und die Clusterbildung erfolgt in 10 Clustern. Experimente haben gezeigt, dass 10 Cluster die optimale Anzahl von Marktmodi sind, aber natürlich kann man mit diesem Parameter experimentieren.
Anschließend wird die endgültige Anzahl der Cluster bestimmt, ihre laufenden Nummern werden in aufsteigender Reihenfolge sortiert, und dann werden für jede Clusternummer nur die Zeilen aus dem Datensatz ausgewählt, die ihr entsprechen. Wir sind nicht an Clustern interessiert, die zu wenige Beobachtungen haben, daher prüfen wir, ob es mindestens 500 Beispiele gibt.
Der nächste Schritt ist der Aufruf der Funktion für die Kennzeichnung der Handelsgeschäfte für den aktuell ausgewählten Cluster. In diesem Fall habe ich die allererste Kennzeichnungsfunktion get_labels_filter genommen, mit der dieser Artikel begann. Nachdem die Handelsgeschäfte etikettiert sind, werden die Daten in zwei Datensätze aufgeteilt. Der erste Datensatz enthält die Hauptmerkmale und Kennzeichnungen und der zweite die Meta-Merkmale, die für das Clustering verwendet werden, sowie die Labels 0 und 1. Eine Eins bedeutet, dass die Daten dem ausgewählten Cluster entsprechen, und Nullen bedeuten, dass es sich um einen anderen als den ausgewählten Cluster handelt. Schließlich wollen wir, dass das Handelssystem nur in einem bestimmten Marktmodus handelt.
Das erste Modell lernt also, die Richtung des Handels vorherzusagen, und das zweite Modell wird vorhersagen, wann sie eröffnet werden können und wann sie nicht eröffnet werden sollten.
Sehen wir uns nun die Funktion fit_final_models selbst an, die zwei Datensätze für zwei endgültige Modelle nimmt und den CatBoost-Algorithmus darauf trainiert.
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=False, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=30, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=500, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=25, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Ausbildungsstufen:
1. Aufbereitung der Daten:
- Aus den ‘geclusterten‘ und ‘Meta‘-Eingabedatenrahmen werden (X, X_meta)-Merkmale und (y, y_meta)-Kennzeichnungen extrahiert.
- Die Kennzeichnung der Datentypen werden in int16 konvertiert. Dies ist für eine nahtlose Konvertierung des Modells in das ONNX-Format erforderlich.
- Die Daten werden mit train_test_split in Trainings- und Testsätze aufgeteilt.
2. Training des Hauptmodells:
- Das CatBoostClassifier-Objekt wird mit den angegebenen Hyperparametern erstellt.
- Das Modell wird anhand der Trainingsdaten (train_X, train_y) trainiert, wobei der Validierungssatz (test_X, test_y) für den Frühstopp verwendet wird.
3. Meta-Modell-Training:
- Es wird ein CatBoostClassifier-Objekt für das Metamodell mit den angegebenen Hyperparametern erstellt.
- Das Metamodell wird in ähnlicher Weise wie das Hauptmodell trainiert, wobei die entsprechenden Trainings- und Testdaten verwendet werden.
4. Bewertung des Modells:
- Die trainierten Modelle (model, meta_model) werden zusammen mit den Parametern stop_loss und take_profit an die Funktion test_model übergeben, um ihre Leistung zu bewerten.
- Der zurückgegebene R2-Wert stellt die Leistungskennzahl des Modells dar.
5. Behandlung von R2 und Rückgabe des Ergebnisses:
- Wenn R2 gleich NaN ist, wird er durch -1,0 ersetzt.
- Der Wert von R2 wird auf dem Bildschirm angezeigt.
- Die Funktion gibt die Liste mit R2 und den trainierten Modellen (model, meta_model) zurück.
Für jeden Cluster werden zwei trainierte Klassifizierungsmodelle ausgegeben, die für den abschließenden visuellen Test und den Export in das MetaTrader 5-Terminal bereit sind. Es sei daran erinnert, dass bei jeder Trainingsiteration so viele Modellpaare erstellt werden, wie es in den Hyperparametern angegebene Cluster gibt. Diese Zahl sollte mit der Anzahl der Iterationen multipliziert werden, um eine Vorstellung davon zu bekommen, wie viele Paare von Modellen insgesamt produziert werden sollen. Wenn z. B. 10 Cluster und 10 Iterationen angegeben sind, werden 100 Modellpaare ausgegeben, wobei diejenigen ausgeschlossen werden, die die Filterung für die Mindestanzahl von Beispielen nicht bestanden haben.
Modelle trainieren und testen. Testen des Algorithmus
Um den Algorithmus bequemer nutzen zu können, ist es ratsam, ihn in der interaktiven Python-Umgebung String für String auszuführen. Dann können wir die Hyperparameter ändern und mit verschiedenen Samplern experimentieren. Oder wir können den gesamten Code in das .ipynb-Format übertragen, um ihn in IPython auf einem Laptop auszuführen. Wenn Sie das gesamte Skript ausführen wollen, müssen Sie es noch bearbeiten, um die Parameter anzupassen.
Ich schlage vor, jede der Kennzeichnungsfunktionen zu testen, indem Sie 10 Iterationen für jede durchführen. Die übrigen Parameter sind die gleichen wie im beigefügten Skript angegeben.
Sobald die Trainingsschleife gestartet ist, werden die Trainingsergebnisse für jede Iteration für jeden Datencluster angezeigt.
R2: 0.9815970951474068 Iteration: 9, Cluster: 5 R2: 0.9914890771969395 Iteration: 9, Cluster: 6 R2: 0.9450681335265942 Iteration: 9, Cluster: 7 R2: 0.9631330369697314 Iteration: 9, Cluster: 8 R2: 0.9680380185183347 Iteration: 9, Cluster: 9 R2: 0.8203651933893291
Wir können dann alle Ergebnisse in aufsteigender R^2-Reihenfolge sortieren, um das beste Ergebnis auszuwählen. Wir können die Saldenkurve auch visuell im Prüfgerät auswerten.
models.sort(key=lambda x: x[0]) test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], plt=True)
Das hervorgehobene bedeutet, dass das erste Modell vom Ende her (d. h. das mit dem höchsten R^2) getestet wird. Um das vorletzte Modell zu testen, muss -2 eingestellt werden, usw. Der Tester zeigt ein Saldenkurve (blau) und ein Währungspaar-Diagramm (orange) sowie eine vertikale Linie an, die den Trainingszeitraum von den neuen Daten trennt. Alle Modelle werden von Anfang 2010 bis Anfang 2021 trainiert, dies ist in den Hyperparametern festgelegt. Sie können die Trainings- und Testintervalle nach eigenem Ermessen ändern. Der Testzeitraum für alle Modelle in diesem Artikel erstreckt sich von Anfang 2021 bis Anfang 2025.
Testen verschiedener Probenehmer für den Handel
- get_labels_filter(dataset, rolling=200, quantiles=[.45, .55], polyorder=3)
Nachfolgend ist das beste Ergebnis für die Markierung get_labels_filter aufgeführt.
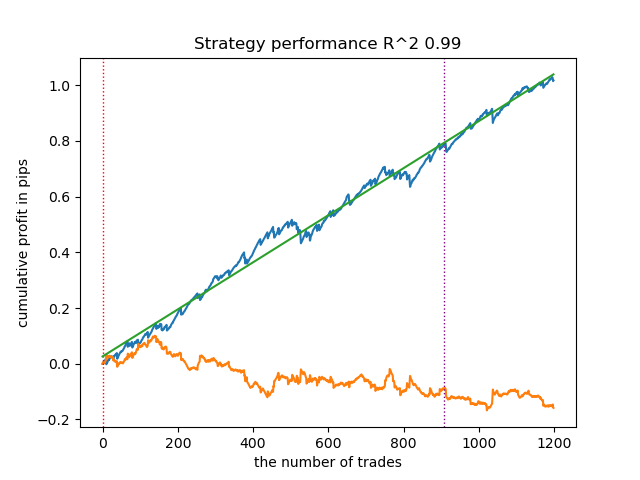
Der Basismarker leistete gute Arbeit bei der Kennzeichnung der Trades, und alle Modelle erwiesen sich bei den neuen Daten als profitabel. Machen wir das Gleiche für die übrigen Marker und sehen wir uns die Ergebnisse an.
- get_labels_multiple_filters(dataset,rolling_periods=[50,100,200],quantiles=[.45,.55],window=100,polyorder=3)
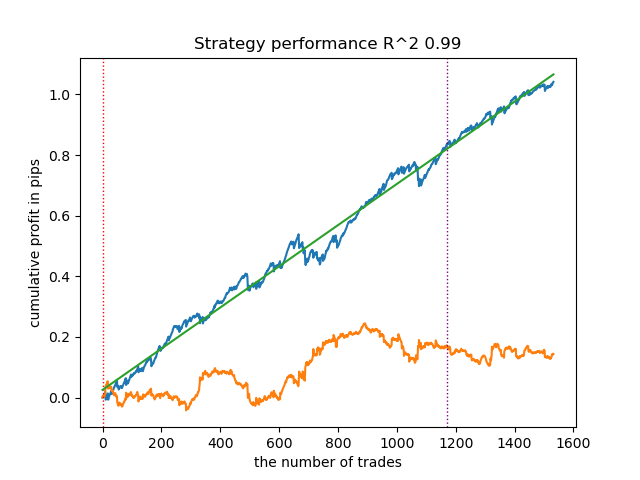
Modelle, die mit den Daten dieses Markers trainiert wurden, zeigen häufig einen Anstieg der Anzahl der Abschlüsse im Vergleich zur Basislinie. Ich habe hier nicht mit den Einstellungen experimentiert, weil der Artikel sonst zu lang geworden wäre.
- get_labels_filter_bidirectional(dataset, rolling1=50, rolling2=200, quantiles=[.45, .55], polyorder=3)
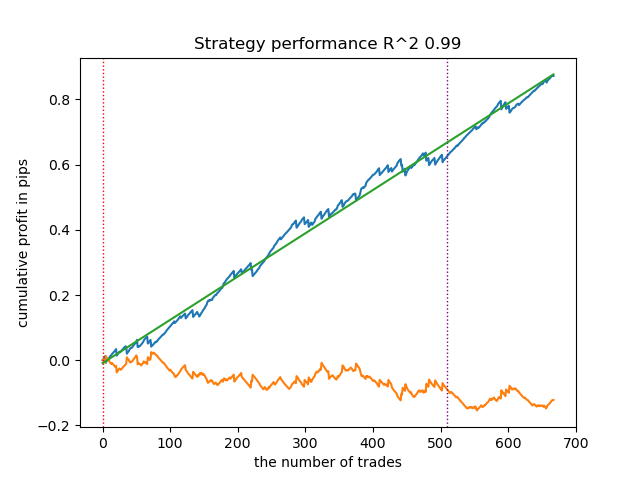
Dieser asymmetrische Marker hat seine Effizienz auch bei neuen Daten bewiesen. Durch die getrennte Auswahl verschiedener Glättungsparameter für Kauf- und Verkaufstransaktionen können Sie optimale Ergebnisse erzielen.
Kommen wir nun zu den Markern mit Beschränkungen für rein profitable Geschäfte. Es ist klar, dass die vorherigen Marker auch während des Trainingszeitraums keine glatte Saldenkurve liefern, aber sie erfassen die allgemeinen Muster gut. Schauen wir uns an, was sich ändert, wenn wir die Verlustgeschäfte aus dem Trainingsdatensatz entfernen.
- get_labels_mean_reversion(dataset, markup, min_l=1, max_l=15, rolling=0.5, quantiles=[.45, .55], method='spline', shift=0)
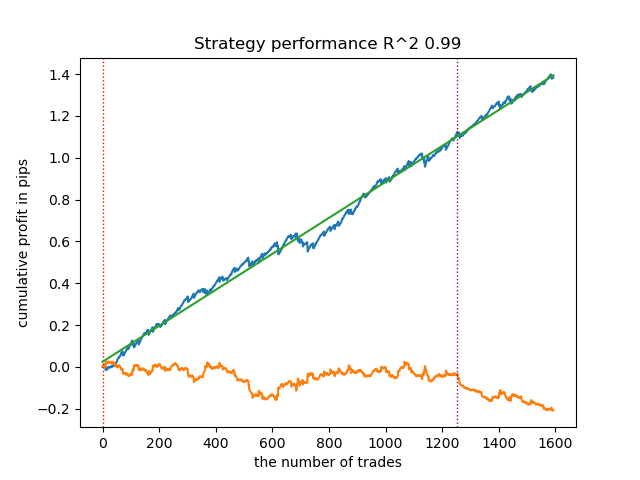
Ich habe diesen Marker mit einem Spline als Filter und einem festen Glättungsfaktor von 0,5 getestet. Der Artikel enthält keine Tests für den Savitzky-Golay-Filter und den einfachen gleitenden Durchschnitt. Es zeigt sich jedoch, dass glattere Kurven erreicht werden können, wenn eine Rentabilitätsbeschränkung für Handelsgeschäfte verwendet wird.
- get_labels_mean_reversion_multi(dataset, markup, min_l=1, max_l=15, windows=[0.2, 0.3, 0.5], quantiles=[.45, .55])
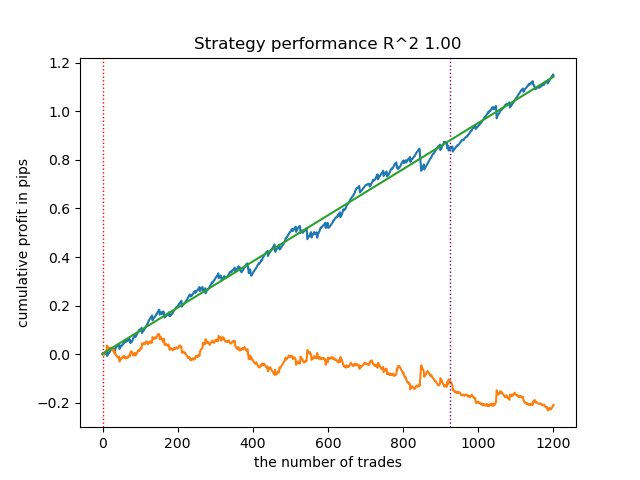
Dieser Sampler ist auch in der Lage, qualitativ hochwertige Samples zu liefern, dank derer das Modell auch bei neuen Daten gewinnbringend handelt.
- get_labels_mean_reversion_v(dataset, markup, min_l=1, max_l=15, rolling=0.2, quantiles=[.45, .55], method='spline', shift=0, volatility_window=20)
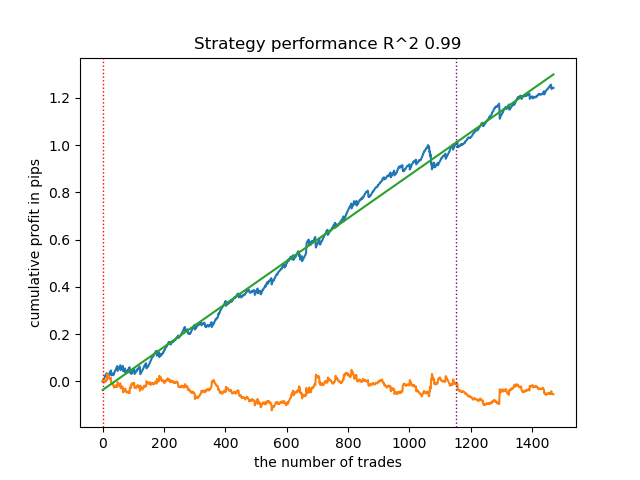
Dieser Algorithmus ist auch in der Lage, eine akzeptable Kennzeichnung und gute Ausgabemodelle zu zeigen.
Schlussfolgerungen zu Deal Markern:
- Wenn Sie nicht wissen, wo Sie anfangen sollen, und Ihnen alles zu kompliziert erscheint, verwenden Sie die einfachste Probenahme, die ein akzeptables Ergebnis liefern kann.
- Wenn Sie nicht sofort schöne Bilder erhalten, denken Sie daran, dass es bei der Kennzeichnung der Handelsgeschäfte und beim Training der Modelle Zufallskomponenten gibt. Führen Sie den Algorithmus einfach ein paar Mal aus.
- Alle Probenahmen mit Grundeinstellungen können akzeptable Ergebnisse liefern. Für weitere Feinabstimmungen müssen Sie sich auf einen dieser Bereiche konzentrieren und die Parameter auswählen.
Schlussfolgerungen zum Clustering:
- Hinter den Kulissen wurden mehrere Tests mit Samplern ohne Clustering und mit Clustering ohne Sampler durchgeführt. Ich habe festgestellt, dass diese Algorithmen einzeln nicht so gut funktionieren wie im Tandem.
- Es ist nicht notwendig, zu viele Merkmale zu erstellen, anhand derer die Clusterbildung durchgeführt wird. Dies verkompliziert das Modell und macht es weniger robust gegenüber neuen Daten.
- Die optimale Anzahl von Clustern liegt im Bereich von 5-10. Eine zu geringe Anzahl von Clustern führt zu einer schlechten Verallgemeinerungsfähigkeit und schlechten Ergebnissen bei neuen Daten, während eine zu große Anzahl von Clustern zu einem starken Rückgang der Anzahl von Transaktionen führt.
Der Einfachheit halber sollten Sie den gewünschten Deal-Marker im Code auskommentieren.
# LEARNING LOOP dataset = get_features(get_prices()) models = [] for i in range(10): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_filter(clustered_data, rolling=hyper_params['rolling'], quantiles=[0.45, 0.55], polyorder=3 ) # clustered_data = get_labels_multiple_filters(clustered_data, # rolling_periods=[50, 100, 200], # quantiles=[.45, .55], # window=100, # polyorder=3) # clustered_data = get_labels_filter_bidirectional(clustered_data, # rolling1=50, # rolling2=200, # quantiles=[.45, .55], # polyorder=3) # clustered_data = get_labels_mean_reversion(clustered_data, # markup = hyper_params['markup'], # min_l=1, max_l=15, # rolling=0.5, # quantiles=[.45, .55], # method='spline', shift=0) # clustered_data = get_labels_mean_reversion_multi(clustered_data, # markup = hyper_params['markup'], # min_l=1, max_l=15, # windows=[0.2, 0.3, 0.5], # quantiles=[.45, .55]) # clustered_data = get_labels_mean_reversion_v(clustered_data, # markup = hyper_params['markup'], # min_l=1, max_l=15, # rolling=0.2, # quantiles=[.45, .55], # method='spline', # shift=0, # volatility_window=100) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) # TESTING & EXPORT models.sort(key=lambda x: x[0]) test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], plt=True)
Exportieren trainierter Modelle in MetaTrader 5
Der vorletzte Schritt beinhaltet den Export der trainierten Modelle und der Header-Datei in das ONNX-Format. Das Modul export_lib.py, das unten angehängt ist, enthält die Funktion export_model_to_ONNX(**kwargs). Schauen wir uns das genauer an.
def export_model_to_ONNX(**kwargs): model = kwargs.get('model') symbol = kwargs.get('symbol') periods = kwargs.get('periods') periods_meta = kwargs.get('periods_meta') model_number = kwargs.get('model_number') export_path = kwargs.get('export_path') model[1].save_model( export_path +'catmodel ' + symbol + ' ' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'main model', 'onnx_graph_name': 'CatBoostModel_main' }, pool=None) model[2].save_model( export_path + 'catmodel_m ' + symbol + ' ' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'meta model', 'onnx_graph_name': 'CatBoostModel_meta' }, pool=None) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel_' + symbol + '_' + str(model_number) + '[]' code += '\n' code += '#resource "catmodel_m '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel2_' + symbol + '_' + str(model_number) + '[]' code += '\n\n' code += 'int Periods' + symbol + '_' + str(model_number) + '[' + str(len(periods)) + \ '] = {' + ','.join(map(str, periods)) + '};' code += '\n' code += 'int Periods_m' + symbol + '_' + str(model_number) + '[' + str(len(periods_meta)) + \ '] = {' + ','.join(map(str, periods_meta)) + '};' code += '\n\n' # get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(symbol) + ' ONNX include' + ' ' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
Die Funktion sollte eine Liste von Argumenten erhalten, wie z.B.:
- model = models[-1] – eine Liste von zwei trainierten Modellen, die mit Modellen aus verschiedenen Trainingsiterationen vorbelegt wurde. Ähnlich wie beim Tester entspricht der Index -1 dem Modell mit dem höchsten R^2, der Index -2 dem zweitbesten Modell, usw. Wenn Ihnen ein bestimmtes Modell bei der visuellen Prüfung gefällt, verwenden Sie beim Exportieren denselben Index.
- symbol = hyper_params['symbol '] – Name des Symbols, z. B. EURGBP_H1, der in den Hyperparametern angegeben ist. Dieser Name wird beim Exportieren von Modellen hinzugefügt, um Modelle für verschiedene Symbole zu unterscheiden.
- periods = hyper_params['periods'] – eine Liste von Perioden der Merkmale des Hauptmodells.
- periods_meta = hyper_params['periods_meta'] – eine Liste von Perioden von Merkmalen eines zusätzlichen Modells, das den aktuellen Marktmodus bestimmt.
- model_number = hyper_params['model_number'] – Modellnummer, wenn Sie viele Modelle exportieren und nicht wollen, dass sie überschrieben werden. Zu den Modellnamen hinzugefügt.
-
export_path = hyper_params['export_path'] – Pfad zum ‘include‘-Ordner des Terminals oder dessen Unterverzeichnis zum Speichern von Dateien auf der Festplatte.
Die Funktion speichert beide Modelle im .onnx-Format und erzeugt eine Header-Datei, über die diese Modelle aufgerufen und Features für sie berechnet werden. Es ist zu beachten, dass die Berechnung der Merkmale direkt im Terminal erfolgt, sodass sichergestellt werden muss, dass sie mit ihrer Berechnung im Python-Skript identisch ist. Aus dem Code können Sie ersehen, dass die Funktion fill_arrays die gleitenden Durchschnitte für das erste Modell und die Funktion fill_arrays_m die Preisschiefe für das zweite Modell berechnet. Wenn Sie die Merkmale im Python-Skript ändern, dann ändern Sie deren Berechnung in dieser Funktion oder in der Header-Datei selbst.
Ein Beispiel für den Aufruf der Funktion selbst, um Modelle auf der Festplatte zu speichern, wird unten gezeigt.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Aufbau eines Handelsroboters, der ONNX-Modelle zur Ausführung von Handelsoperationen verwendet
Gehen wir davon aus, dass wir mit dem nutzerdefinierten Tester ein optisch ansprechendes Modell trainiert und ausgewählt haben, zum Beispiel das folgende:
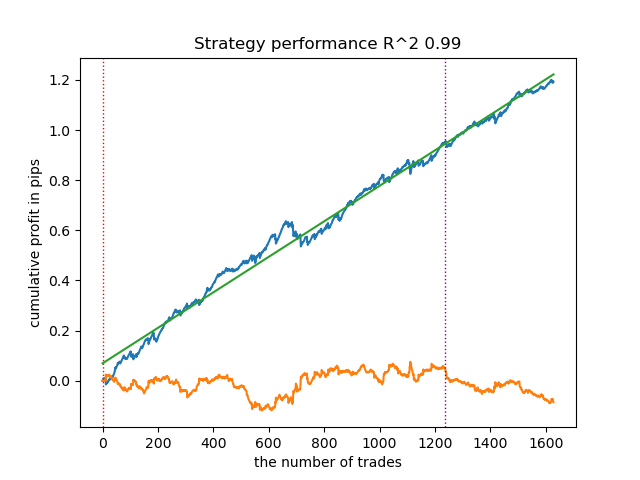
Nun müssen wir die Exportfunktion im Terminal aufrufen.
Nach dem Exportieren des Modells erscheinen 3 Dateien im Ordner include/mean reversion/ des MetaTrader 5 Terminals (in meinem Fall wird ein Unterverzeichnis verwendet, um Verwechslungen mit anderen Modellen zu vermeiden):
- catmodel EURGBP_H1 0.onnx – Hauptmodell, das Kauf- und Verkaufssignale liefert.
- catmodel_m EURGBP_H1 0.onnx – zusätzliches Modell, das den Handel erlaubt oder verbietet.
- EURGBP_H1 ONNX include 0.mqh – Header-Datei, die diese Modelle importiert und die Merkmale berechnet.
Die Namen der ONNX-Modelle beginnen immer mit dem Wort „catmodel“, das für catboost model steht, gefolgt vom Symbolnamen und dem Zeitrahmen. Das zusätzliche Modell ist mit dem Suffix _m gekennzeichnet, das für ‘Metamodell‘ steht. Der Name der Header-Datei beginnt immer mit dem Markensymbol und endet mit der Modellnummer, die beim Export angegeben wird, damit sich neu exportierte Modelle nicht gegenseitig überschreiben, sofern dies nicht erforderlich ist.
Schauen wir uns den Inhalt der .mqh-Datei an.
#include <Math\Stat\Math.mqh> #resource "catmodel EURGBP_H1 0.onnx" as uchar ExtModel_EURGBP_H1_0[] #resource "catmodel_m EURGBP_H1 0.onnx" as uchar ExtModel2_EURGBP_H1_0[] int PeriodsEURGBP_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mEURGBP_H1_0[1] = {10}; void fill_araysEURGBP_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsEURGBP_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsEURGBP_H1_0[i],pr); ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mEURGBP_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mEURGBP_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mEURGBP_H1_0[i],pr); ret[0] = MathSkewness(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Zunächst wird eine Bibliothek mathematischer Berechnungen angeschlossen, die für die Berechnung von Mittelwert und Schiefe und möglicherweise auch für andere Momente von Verteilungen und andere mathematische Berechnungen benötigt werden, wenn die Berechnung von Merkmalen geändert werden muss. Als Nächstes laden wir unsere beiden ONNX-Modelle als Ressourcen, die für die Generierung von Handelssignalen verwendet werden sollen. Danach werden Arrays mit Perioden für die Berechnung von Merkmalen deklariert, die die Eingabedaten für das Haupt- und das Metamodell darstellen werden.
Die beiden anderen Funktionen füllen die Arrays mit Merkmalswerten. Ich möchte Sie daran erinnern, dass diese Dateien beim Exportieren von Modellen aus einem Python-Skript erstellt werden und nicht jedes Mal von Grund auf neu geschrieben werden müssen. Es genügt, eine Verbindung zu einem Trading EA herzustellen. Das ist sehr praktisch, wenn man das Modell nach einiger Zeit neu trainieren möchte. Dann exportiert man es einfach in das Terminal, überschreibt das Modell mit einem neueren und kompiliert den Bot neu, ohne Änderungen am Code vorzunehmen. Die schiere Menge des Codes kann zunächst abschreckend wirken, aber in der Praxis ist das Training so einfach wie das Ausführen des Skripts und das anschließende Kompilieren des Bots, was nur ein paar Minuten dauern kann.
Nun müssen wir einen Handels-EA erstellen, mit dem sich diese Header-Datei verbinden und ONNX-Modelle initialisieren wird.
#include <Mean reversion/EURGBP_H1 ONNX include 0.mqh> #include <Trade\Trade.mqh> #include <Trade\AccountInfo.mqh> #property strict #property copyright "Copyright 2025, Dmitrievsky max." #property link "https://www.mql5.com/ru/users/dmitrievsky" #property version "1.0" CTrade mytrade; CPositionInfo myposition; input bool Allow_Buy = true; //Allow BUY input bool Allow_Sell = true; //Allow SELL double main_threshold = 0.5; double meta_threshold = 0.5; sinput double MaximumRisk=0.001; //Progressive lot coefficient sinput double ManualLot=0.01; //Fixed lot, set 0 if progressive sinput ulong OrderMagic = 57633493; //Orders magic input int max_orders = 3; //Max positions number input int orders_time_delay = 5; //Time delay between positions input int max_spread = 20; //Max spread input int stoploss = 2000; //Stop loss input int takeprofit = 200; //Take profit input string comment = "mean reversion bot"; static datetime last_time = 0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) const long ExtInputShape [] = {1, ArraySize(PeriodsEURGBP_H1_0)}; const long ExtInputShape2 [] = {1, ArraySize(Periods_mEURGBP_H1_0)}; long ExtHandle = INVALID_HANDLE, ExtHandle2 = INVALID_HANDLE; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { mytrade.SetExpertMagicNumber(OrderMagic); ExtHandle = OnnxCreateFromBuffer(ExtModel_EURGBP_H1_0, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2_EURGBP_H1_0, ONNX_DEFAULT); if(ExtHandle == INVALID_HANDLE || ExtHandle2 == INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape 1 failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape2)) { Print("OnnxSetInputShape 2 failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); } const long output_shape[] = {1}; if(!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("OnnxSetOutputShape 1 error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetOutputShape(ExtHandle2, 0, output_shape)) { Print("OnnxSetOutputShape 2 error ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(ExtHandle); OnnxRelease(ExtHandle2); }
Das Wichtigste ist die korrekte Initialisierung der Dimensionen der Eingabefelder für jedes Modell. Sie ist gleich der Größe des Arrays in der Header-Datei, das die Periodenwerte für die Merkmalsberechnung enthält. Es gibt so viele Zeichen, wie es Periodenwerte gibt.
Die Output-Dimension ist bei beiden Modellen gleich eins.
const long ExtInputShape [] = {1, ArraySize(PeriodsEURGBP_H1_0)}; const long ExtInputShape2 [] = {1, ArraySize(Periods_mEURGBP_H1_0)};
Dann weisen wir den Modellen Handles zu.
ExtHandle = OnnxCreateFromBuffer(ExtModel_EURGBP_H1_0, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2_EURGBP_H1_0, ONNX_DEFAULT);
Und wir setzen die richtigen Dimensionen der Ein- und Ausgänge im Körper der Bot-Initialisierungsfunktion.
if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape 1 failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape2)) { Print("OnnxSetInputShape 2 failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); }
Nach dem Löschen des Bots aus der Chart werden auch die Modelle gelöscht.
Der Bot handelt bei der Eröffnung jeder neuen Kerze, um die Berechnungen zu beschleunigen. Nun müssen wir uns ansehen, wie wir Signale von unseren Modellen erhalten.
void OnTick() { if(!isNewBar()) return; double features[], features_m[]; fill_araysEURGBP_H1_0(features); fill_arays_mEURGBP_H1_0(features_m); double f[ArraySize(PeriodsEURGBP_H1_0)], f_m[ArraySize(Periods_mEURGBP_H1_0)]; for(int i = 0; i < ArraySize(PeriodsEURGBP_H1_0); i++) { f[i] = features[i]; } for(int i = 0; i < ArraySize(Periods_mEURGBP_H1_0); i++) { f_m[i] = features_m[i]; } static vector out(1), out_meta(1); struct output { long label[]; float proba[]; }; output out2[], out2_meta[]; OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f_m, out_meta, out2_meta); double sig = out2[0].proba[1]; double meta_sig = out2_meta[0].proba[1];
Die Reihenfolge des Empfangs von Signalen aus ONNX-Modellen:
- Die Arrays features und features_m werden erstellt.
- Sie werden durch die entsprechenden fill_arrays-Funktionen mit Merkmalswerten gefüllt.
- Die Reihenfolge der Elemente in diesen Arrays ist im Vergleich zu der Reihenfolge, in der das Modell sie erhalten soll, invertiert. Aus diesem Grund werden die Arrays f und f_m erstellt und die Daten in der richtigen Reihenfolge umgeschrieben.
- Die Vektoren out und out_meta werden erstellt, die den Modellen die Dimensionen der Ausgabevektoren mitteilen.
- Die Ausgabestruktur wird für die Annahme von vorhergesagten 0;1-Kennzeichnungen und Wahrscheinlichkeiten erstellt. Wahrscheinlichkeiten werden in Signalberechnungen verwendet.
- Die Instanzen out2 und out2_meta der Ausgabestruktur werden erstellt, um Signale zu empfangen.
- Die Modelle werden mit den Merkmalen und Abmessungen der Ausgangswerte eingeführt. Sie geben Prognosen ab.
- Vorhersagen (Wahrscheinlichkeiten) werden aus Instanzen von Strukturen extrahiert.
Abschließend bleibt die Logik der Positionseröffnung auf der Grundlage der empfangenen Signale zu betrachten. Schließsignale funktionieren nach der umgekehrten Logik.
// OPEN POSITIONS BY SIGNALS if((Ask-Bid < max_spread*_Point) && meta_sig > meta_threshold && AllowTrade(OrderMagic)) if(countOrders(OrderMagic) < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(), ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 1-main_threshold && Allow_Buy) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_BUY, l, Ask, stop, take, comment); Sleep(50); } while(res == -1); } else { if(sig > main_threshold && Allow_Sell) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_SELL, l, Bid, stop, take, comment); Sleep(50); } while(res == -1); } } }
Zunächst wird das Signal des zweiten Modells überprüft. Wenn die Wahrscheinlichkeit größer als 0,5 ist, ist die Eröffnung von Handelsgeschäften erlaubt (der Markt befindet sich im erforderlichen Modus). Anschließend werden die Bedingungen mit dem Hauptmodell abgeglichen, das die Wahrscheinlichkeit eines Kaufs oder Verkaufs vorhersagt. Die Wahrscheinlichkeit < 0,5 bedeutet einen Kauf, während die Wahrscheinlichkeit > 0,5 einen Verkauf bedeutet. Die Positionen werden je nach den Bedingungen eröffnet.
Jetzt können wir den Bot kompilieren und ihn im Strategietester testen.
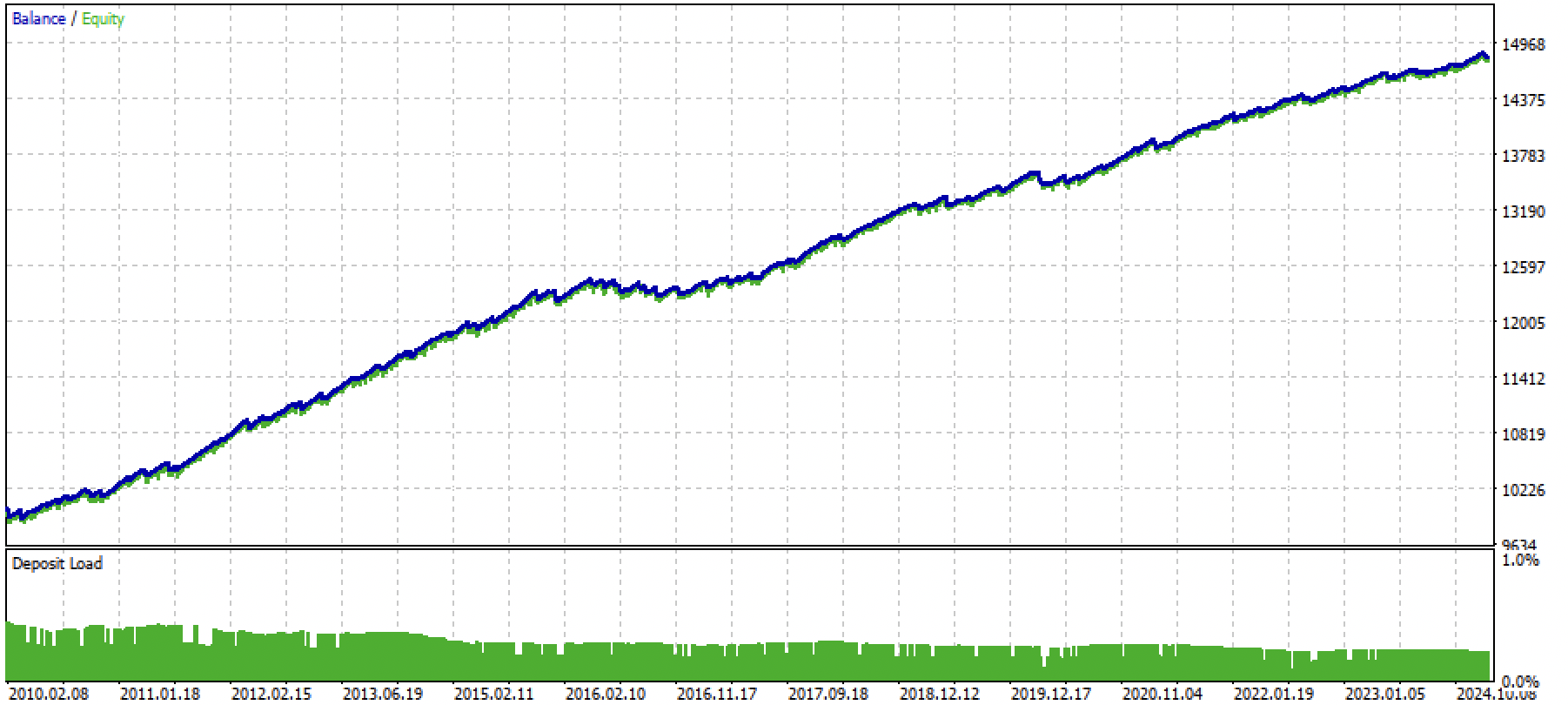
Abb. 3. Testen des trainierten Modells mit der Strategie Rückkehr zum Mittelwert
Schlussfolgerung
Dieser Artikel zeigt alle Schritte auf, die zur Entwicklung der Strategie der Rückkehr zum Mittelwert mit Hilfe von maschinellem Lernen erforderlich sind. Es wird ein umfassender Ansatz skizziert: von der Kennzeichnung des Handels und der Identifizierung der Marktordnung bis hin zum Modelltraining und der Erstellung eines vollwertigen Handelsroboters.
Der Artikel enthält alle erforderlichen Codes für unabhängige Experimente.
Python files.zip enthält die folgenden Dateien für die Entwicklung in der Python-Umgebung:
| Dateiname | Beschreibung |
|---|---|
| mean reversion.py | Das Hauptskript für das Training von Modellen |
| labeling_lib.py | Modul mit Deal-Markern |
| tester_lib.py | Nutzerdefinierter Strategietester auf der Grundlage von maschinellem Lernen |
| export_lib.py | Die Bibliothek für den Export von Modellen zum MetaTrader 5 Terminal im ONNX-Format |
| EURGBP_H1.csv | Die Datei mit den vom MetaTrader 5-Terminal exportierten Kursen |
MQL5 files.zip enthält Dateien für das MetaTrader 5-Terminal:
| Dateiname | Beschreibung |
|---|---|
| mean reversion.ex5 | Der zusammengestellte Bot aus dem Artikel |
| mean reversion.mq5 | Der Quellcode des Bot aus dem Artikel |
| folder Include//Mean reversion | Die ONNX-Modelle und die Header-Datei für die Verbindung mit dem Bot |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16457
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Überprüft, alles funktioniert bei mir. Beigefügt sind die Dateien der trainierten Modelle aus dem Artikel und der aktualisierte Bot oben.
Es ist wünschenswert, die Modelle anschließend neu zu trainieren, da dem Artikel Demomodelle beigefügt sind. Wenn Sie das Python-Skript verstehen.
Ja, in dieser Version kompiliert der Bot selbst und funktioniert korrekt. Aber die Modelle müssen neu trainiert werden. Und das sollte, so wie ich es verstehe, regelmäßig geschehen.
Ich komme langsam mit Python zurecht, aber ich habe noch nicht alles verstanden. Ich habe die Hauptversion von Rutop auf meinem Laptop ausgerollt und auf die aktuelle Version aktualisiert. Ich habe alle notwendigen Pakete installiert (pandas, numba, numpy, catboost, scipy, scikit-learn). Quotes heruntergeladen. Ich habe die Datei mit den Kursen und allen Skripten in den Ordner Files im Hauptkatalog von MT5 gelegt. Ich habe die Pfade in den Code des Modell-Trainingsskripts geschrieben. Aber etwas geht nicht zum Ergebnis.
Ich korrigiere den Skriptcode in MetaEditore. Ich versuche, das Skript von dort aus zu starten. Der Prozess stürzt mit einem Fehler ab (er findet das Bots-Paket Python nicht, und der Versuch, es nach dem Schema der Installation anderer Pakete zu installieren, endet ebenfalls mit einem Fehler). Derselbe Fehler tritt auf, wenn ich das Skript über die Python-Konsole ausführe.
Können Sie mir einen Tipp geben, in welche Richtung ich das Thema vertiefen kann?
Guten Tag!
Ja, in dieser Version kompiliert der Bot selbst und funktioniert korrekt. Aber die Modelle müssen neu trainiert werden. Und das sollte, so wie ich es verstehe, regelmäßig geschehen.
Ich komme mit Python gut zurecht, aber noch funktioniert nicht alles. Ich habe die Hauptversion von Rutop auf meinem Laptop installiert und sie auf die aktuelle Version aktualisiert. Ich habe alle notwendigen Pakete installiert (pandas, numba, numpy, catboost, scipy, scikit-learn). Quotes heruntergeladen. Ich habe die Datei mit den Kursen und allen Skripten in den Ordner Files im Hauptkatalog von MT5 gelegt. Ich habe die Pfade in den Code des Modell-Trainingsskripts geschrieben. Aber etwas geht nicht zum Ergebnis.
Ich korrigiere den Skriptcode in MetaEditore. Ich versuche, das Skript von dort aus zu starten. Der Prozess stürzt mit einem Fehler ab (er findet das Bots-Paket Python nicht, und der Versuch, es nach dem Schema der Installation anderer Pakete zu installieren, endet ebenfalls mit einem Fehler). Der gleiche Fehler tritt auf, wenn ich das Skript über die Python-Konsole ausführe.
Können Sie mir einen Tipp geben, in welche Richtung ich das Thema bearbeiten soll?
Bots ist nur das Stammverzeichnis (Ordner), in dem sich die Module aus dem Artikel befinden. Wenn das Skript sie beim Importieren von Modulen (zusätzliche Dateien) nicht sieht, dann schreiben Sie die vollständigen Pfade zu den Dateien.
Oder legen Sie alle diese Dateien in denselben Ordner wie das Hauptskript und tun Sie stattdessen dies:
Das kann passieren, wenn Sie bei der Installation von Python den PYTHONPATH nicht vorgeschrieben haben. Suchen Sie im Internet, um herauszufinden, wie Sie ihn für Ihr System vorgeben können. Das heißt, Python sieht die Dateien auf der Diskette nicht.
Oder lesen Sie einen Grundkurs über den Import von Modulen im Internet.
Bots ist lediglich ein Stammverzeichnis (Ordner), in dem sich die Module aus dem Artikel befinden. Wenn das Skript sie beim Importieren von Modulen (zusätzlichen Dateien) nicht sieht, schreiben Sie die vollständigen Pfade zu den Dateien.
Oder legen Sie alle diese Dateien in denselben Ordner wie das Hauptskript und tun Sie stattdessen dies:
Das kann passieren, wenn Sie bei der Installation von Python den PYTHONPATH nicht vorgeschrieben haben. Suchen Sie im Internet, um herauszufinden, wie Sie ihn für Ihr System vorgeben können. Das heißt, Python sieht die Dateien auf der Diskette nicht.
Oder lesen Sie einen Grundkurs über den Import von Modulen im Internet.
Guten Tag, Maxim. Ich danke dir. Fast alles ist gelöst. Die letzte Frage.
Es gibt kommentierte Zeilen (154-182) im Hauptskript für das Training von Modellen. Soweit ich weiß, handelt es sich dabei um alternative Deal Sampler (Markups). Aber ich kann sie nicht ausprobieren. Wenn eine der Markierungen unkommentiert ist (bedingt, Zeilen 154-158) und die ursprüngliche auskommentiert ist (Zeilen 149-153), startet das Skript nicht.
Woran kann das liegen, wo kann ich suchen?
Danke )
Guten Tag, Maxim. Ich danke Ihnen. Fast alles ist gelöst. Die letzte Frage.
Es gibt kommentierte Zeilen (154-182) im Hauptskript für das Training der Modelle. Soweit ich weiß, handelt es sich dabei um alternative Deal Sampler (Markups). Aber ich kann sie nicht ausprobieren. Wenn eine der Markierungen unkommentiert ist (bedingt, Zeilen 154-158) und die ursprüngliche kommentiert ist (Zeilen 149-153), startet das Skript nicht.
Woran kann das liegen, wo kann ich nachschauen?
Danke )
Hallo, Sie brauchen Protokolle dessen, was der Python-Interpreter schreibt.
Guten Tag, Maxim. Ich danke Ihnen. Fast alles ist gelöst. Die letzte Frage.
Es gibt kommentierte Zeilen (154-182) im Hauptskript für das Training der Modelle. Soweit ich weiß, handelt es sich dabei um alternative Deal Sampler (Markups). Aber ich kann sie nicht ausprobieren. Wenn eine der Markierungen unkommentiert ist (bedingt, Zeilen 154-158) und die ursprüngliche kommentiert ist (Zeilen 149-153), startet das Skript nicht.
Woran kann das liegen, wo kann ich nachschauen?
Danke )
Prüfen Sie, ob der unkommentierte Text in der gleichen Zeile steht
Es sollte keine Unterstreichung vorhanden sein, wie im Screenshot unten