
Hidden-Markov-Modelle in Handelssystemen mit maschinellem Lernen
Inhalt
- Einführung
- Algorithmen in der Bibliothek hmmlearn
- Die Klasse hmm.GaussianHMM
- Die Klasse hmm.GMMHMM
- Die Klasse vhmm.VariationalGaussianHMM
- Vergleich der Leistung der Modelle
- Methoden zur Bestimmung von Prior-Matrizen
- Identifizierung von Marktregimen mit HMM
- Erstellen von Prior-Matrizen
- Exportieren von Modellen in MetaTrader 5
- Schlussfolgerung
Einführung
Hidden-Markov-Modelle (HMMs) sind eine leistungsstarke Klasse probabilistischer Modelle, die für die Analyse sequenzieller Daten entwickelt wurden, bei denen beobachtete Ereignisse von einer Sequenz unbeobachteter (versteckter) Zustände abhängen, die einen Markov-Prozess bilden. HMMs sind doppelt stochastische Modelle, die durch eine endliche Menge verborgener Zustände und eine Folge beobachtbarer Ereignisse gekennzeichnet sind, deren Wahrscheinlichkeit vom aktuellen verborgenen Zustand abhängt. Zu den wichtigsten Annahmen von HMMs gehören die Markov-Eigenschaft für verborgene Zustände, was bedeutet, dass die Wahrscheinlichkeit des Übergangs zum nächsten Zustand nur vom aktuellen Zustand abhängt, und die Unabhängigkeit der Beobachtungen bei Kenntnis des aktuellen verborgenen Zustands.
Hidden-Markov-Modelle finden in verschiedenen Bereichen breite Anwendung, u. a. in der Sprach- und Bilderkennung, der Verarbeitung natürlicher Sprache (z. B. Part-of-Speech-Tagging), der Bioinformatik (DNA- und Proteinsequenzanalyse) und der Zeitreihenanalyse (Prognosen, Erkennung von Anomalien). Die Fähigkeit, Systeme zu modellieren, deren interne Struktur nicht direkt beobachtbar ist, aber beobachtbare Ergebnisse beeinflusst, macht HMM zu einem wertvollen Werkzeug für die Analyse komplexer zeitabhängiger Zusammenhänge. Die Beobachtungen in solchen Modellen sind nur ein indirektes Spiegelbild der verborgenen Prozesse, und das Verständnis dieser Prozesse kann wichtige Informationen über die Dynamik des Systems liefern.
Die Bibliothek hmmlearn ist eine Python-Bibliothek für unüberwachtes Lernen mit Hidden-Markov-Modellen. Sie wurde entwickelt, um einfache und effiziente Werkzeuge für die Arbeit mit HMMs bereitzustellen, die der API von scikit-learn folgen, die Integration in bestehende Projekte erleichtern und den Trainingsprozess vereinfachen. Hmmlearn basiert auf den grundlegenden wissenschaftlichen Python-Bibliotheken, wie NumPy, SciPy und Matplotlib.
Zu den wichtigsten Funktionen von hmmlearn gehören die Implementierung verschiedener HMM-Modelle mit unterschiedlichen Emissionsverteilungen, das Training von Modellparametern aus beobachteten Daten, die Bestimmung der wahrscheinlichsten verborgenen Zustandssequenzen, die Erzeugung von Stichproben aus trainierten Modellen und die Möglichkeit, trainierte Modelle zu speichern und zu laden. Die Vielfalt der implementierten Modelle ermöglicht es den Nutzern, je nach Art ihrer Daten die geeignete Emissionsverteilung auszuwählen. Der Datentyp (kontinuierlich, diskret, Zähler) bestimmt, welche Wahrscheinlichkeitsverteilung den Prozess der Erzeugung von Beobachtungen in jedem verborgenen Zustand am besten beschreibt.
Algorithmen in der Bibliothek hmmlearn
Die Bibliothek hmmlearn implementiert die folgenden Haupt-HMM-Modelle:
- hmm.CategoricalHMM – für die Modellierung von Sequenzen kategorischer (diskreter) Beobachtungen.
- hmm.GaussianHMM – zur Modellierung von Sequenzen kontinuierlicher Beobachtungen unter der Annahme einer Gauß-Verteilung in jedem verborgenen Zustand.
- hmm.GMMHMM – für die Modellierung von Sequenzen kontinuierlicher Beobachtungen, bei denen die Emissionen aus jedem verborgenen Zustand durch eine Mischung von Gauß-Verteilungen beschrieben werden.
- hmm.MultinomialHMM – für die Modellierung von Sequenzen diskreter Beobachtungen, bei denen jeder Zustand eine Wahrscheinlichkeitsverteilung über eine feste Menge von Symbolen hat.
- hmm.PoissonHMM – für die Modellierung von Datensequenzen, die Ereigniszähler darstellen, wobei die Emissionen aus jedem verborgenen Zustand einer Poisson-Verteilung folgen.
- vhmm.VariationalCategoricalHMM – Variationsversion von CategoricalHMM, die Variationsinferenzmethoden zum Lernen verwendet.
- vhmm.VariationalGaussianHMM – Variationsversion des GaussianHMM für kontinuierliche Beobachtungen, die nach einer multivariaten Normalverteilung verteilt sind und mittels Variationsinferenz trainiert werden.
Wir interessieren uns für die Algorithmen, die mit kontinuierlichen Daten arbeiten, daher werden nur diese berücksichtigt.
Die Klasse hmm.GaussianHMM
Die Klasse hmm.GaussianHMM in der Bibliothek hmmlearn implementiert ein Hidden-Markov-Modell mit Gaußschen Emissionen. Dieses Modell wird verwendet, wenn die beobachteten Variablen kontinuierlich sind und angenommen wird, dass sie in jedem verborgenen Zustand einer multivariaten Normalverteilung (Gauß) folgen.
Gaußsche HMM werden häufig zur Modellierung verschiedener Zeitreihen verwendet, z. B. für Finanzdaten (z. B. Aktienkurse), Messwerte verschiedener Sensoren und andere kontinuierliche Prozesse, bei denen die beobachteten Werte durch eine Gaußsche Verteilung in jedem der verborgenen Zustände beschrieben werden können.
Der Konstruktor der Klasse hmm.GaussianHMM akzeptiert folgende Parameter:
- n_components (int, Standardwert ist 1): definiert die Anzahl der verborgenen Zustände im Modell. Jedem Zustand wird eine eigene Gaußsche Verteilung zugeordnet.
- covariance_type ({„spherical“, „diag“, „full“, „tied“}, Standardwert ist „diag“): legt den Typ der für jeden Zustand verwendeten Kovarianzmatrix fest. Die Wahl des Kovarianztyps wirkt sich direkt auf die Komplexität des Modells und die Anzahl der geschätzten Parameter aus.
- spherical – jeder Zustand verwendet die gleiche Varianz für alle Merkmale. Die Kovarianzmatrix ist ein Vielfaches der Identitätsmatrix.
- diag – jeder Zustand verwendet eine diagonale Kovarianzmatrix, wobei davon ausgegangen wird, dass die Merkmale innerhalb eines Zustands statistisch unabhängig sind, aber unterschiedliche Varianzen haben können.
- full – jeder Zustand verwendet eine vollständige (nicht eingeschränkte) Kovarianzmatrix, die es uns ermöglicht, Korrelationen zwischen Merkmalen innerhalb jedes Zustands zu modellieren. Diese Option ist am flexibelsten, erfordert jedoch mehr Daten für eine zuverlässige Parameterschätzung und kann zu Überanpassung führen.
- tied – alle verborgenen Zustände haben die gleiche vollständige Kovarianzmatrix. Dies ermöglicht die Berücksichtigung von Korrelationen zwischen Merkmalen, setzt aber voraus, dass die Struktur dieser Korrelationen in allen Zuständen gleich ist.
- min_covar (float, Standardwert ist 1e-3): legt den Mindestwert für die Diagonalelemente der Kovarianzmatrix fest, um zu verhindern, dass sie während des Trainings entartet (z.B. Varianz Null) und um eine Überanpassung zu vermeiden.
- startprob_prior (array, form (n_components,), optional): Parameter der Dirichlet-A-priori-Verteilung für die Startwahrscheinlichkeiten startprob_, die die Wahrscheinlichkeit bestimmen, mit der eine Beobachtungssequenz in jedem der verborgenen Zustände beginnt.
- transmat_prior (array, form (n_components, n_components), optional): Parameter des Dirichlet-Priors für jede Zeile der transmat_-Übergangsmatrix, die die Übergangswahrscheinlichkeit zwischen verborgenen Zuständen bestimmt.
- means_prior (array, form (n_components,), optional): der Mittelwert der Prior-Normalverteilung für die Mittelwerte (means_) der einzelnen verborgenen Zustände.
- means_weight (array, form (n_components,), optional): Gewicht (oder Präzision, inverse Varianz) der normalen Prior-Verteilung für die Mittelwerte (means_) jedes versteckten Zustands.
- covars_prior (array, form (n_components,), optional): Parameter der prior-Verteilung für die covars_ Kovarianzmatrix. Der Typ dieser Verteilung hängt von dem Parameter covariance_type ab. Bei „spherical“ und „diag“ handelt es sich um Parameter der inversen Gamma-Verteilung, bei „full“ und „tied“ um Parameter der inversen Wishart-Verteilung.
- covars_weight (array, form (n_components,), optional): Gewicht der Prior-Verteilungsparameter für die covars_-Kovarianzmatrix. Ähnlich wie bei covars_prior hängt die Interpretation von covariance_type ab (Skalierungsparameter für inverse Gamma- oder inverse Wishart-Verteilungen).
- algorithm ({„viterbi“, „map“}, optional): der Algorithmus, der für die Dekodierung verwendet wird, d. h. für die Suche nach der wahrscheinlichsten Folge von verborgenen Zuständen, die der beobachteten Folge entsprechen. „viterbi“ implementiert den Viterbi-Algorithmus, während „map“ (maximale a-posteriori-Schätzung) eine Glättung (vorwärts-rückwärts) durchführt, um den wahrscheinlichsten Zustand zu jedem Zeitpunkt zu finden.
- random_state (RandomState oder int, optional): Zufallszahlengenerator-Objekt oder Integer-Seed zur zufälligen Initialisierung der Modellparameter, um reproduzierbare Ergebnisse zu gewährleisten.
- n_iter (int, optional): maximale Anzahl der Iterationen, die der Expectation-Maximization-Algorithmus (EM) beim Training des Modells durchführt. Der Standardwert ist 10.
- tol (float, optional): Konvergenzschwelle des EM-Algorithmus. Wenn die Änderung der logarithmischen Wahrscheinlichkeit zwischen zwei aufeinanderfolgenden Iterationen kleiner als dieser Wert wird, wird das Training abgebrochen. 0,01 ist die Standardeinstellung.
- verbose (bool, optional): wenn auf True gesetzt, werden die Konvergenzdaten bei jeder Iteration in den Standardfehler geschrieben. Die Konvergenz kann auch über das Attribut monitor_ überwacht werden.
- params (string, optional): gibt an, welche Modellparameter während des Trainings aktualisiert werden sollen. Kann eine Kombination von Symbolen enthalten: „s“ für Anfangswahrscheinlichkeiten (startprob_), „t“ für Übergangswahrscheinlichkeiten (transmat_), „m“ für Mittelwerte (means_), und „c“ für Kovarianzen (covars_). Standardwert ist „stmc“ (alle Parameter werden aktualisiert).
- init_params (string, optional): gibt an, welche Modellparameter vor Beginn des Trainings initialisiert werden. Die Symbole haben die gleiche Bedeutung wie in „params“. Standard ist „stmc“ (alle Parameter sind initialisiert).
- implementation (string, optional): legt die Implementierung des zu verwendenden Vorwärts-Rückwärts-Algorithmus fest: logarithmisch (“log“) oder mit „scaling“. Standardmäßig wird aus Gründen der Abwärtskompatibilität „log“ verwendet, die Implementierung von „scaling“ ist jedoch in der Regel schneller.
Die GaussianHMM-Parameter werden vor dem Training des Modells mithilfe des EM-Algorithmus initialisiert. Die Initialisierungsparameter definieren den Anfangszustand des Modells. Der Parameter init_params steuert, welche Parameter initialisiert werden sollen. Wenn ein Parameter nicht in init_params enthalten ist, wird davon ausgegangen, dass sein Wert bereits manuell festgelegt wurde.
Die Anfangswerte der Parameter können zufällig initialisiert oder auf der Grundlage der bereitgestellten Daten berechnet werden. Die korrekte Initialisierung der Parameter kann die Konvergenzrate des EM-Algorithmus und die Qualität des endgültigen Modells erheblich beeinflussen, da der EM-Algorithmus in lokalen Optima stecken bleiben kann.
Die Optimierung der Gaußschen HMM-Parameter erfolgt mit dem iterativen Algorithmus der Erwartungsmaximierung (EM). Dieser Algorithmus besteht aus zwei Hauptschritten, die iterativ durchgeführt werden, bis Konvergenz erreicht ist:
- E-Schritt (Expectation): In diesem Schritt werden angesichts der aktuellen Schätzungen der Modellparameter und der beobachteten Datenfolge die posterioren Wahrscheinlichkeiten (dass sich das System zu jedem Zeitpunkt in einem bestimmten verborgenen Zustand befand) berechnet. Dies geschieht in der Regel mit dem Vorwärts-Rückwärts-Algorithmus.
- M-Schritt (Maximierung): In diesem Schritt werden die Modellparameter (Anfangswahrscheinlichkeiten, Übergangswahrscheinlichkeiten zwischen den Zuständen, Mittelwerte und Kovarianzen für jeden Zustand) so aktualisiert, dass die erwartete logarithmische Wahrscheinlichkeit der beobachteten Daten unter Berücksichtigung der im E-Schritt berechneten posterioren Wahrscheinlichkeiten maximiert wird.
Der Prozess wird so lange wiederholt, bis Konvergenz erreicht ist, was entweder durch das Erreichen der durch den Parameter n_iter festgelegten maximalen Anzahl von Iterationen oder dadurch bestimmt wird, dass die Änderung der logarithmischen Wahrscheinlichkeit zwischen aufeinander folgenden Iterationen kleiner als der durch tol festgelegte Schwellenwert wird. Der EM-Algorithmus garantiert, dass die logarithmische Wahrscheinlichkeit bei jeder Iteration zunimmt (oder erhalten bleibt); er garantiert jedoch nicht, dass das globale Maximum gefunden wird, und das Ergebnis kann von den anfänglichen Parametereinstellungen abhängen.
Die Wahl des Parameters covariance_type wirkt sich direkt auf die Struktur der Kovarianzmatrix aus, die zur Modellierung der Emissionen in jedem verborgenen Zustand verwendet wird.
- Bei der Auswahl „spherical“ wird eine isotrope Kovarianz angenommen, d. h. die Varianz aller Merkmale in einem bestimmten Zustand ist gleich, und die Kovarianzmatrix ist proportional zur Identitätsmatrix.
- „diag“ weist auf die Verwendung einer diagonalen Kovarianzmatrix hin, was bedeutet, dass die Merkmale in jedem Zustand als statistisch unabhängig betrachtet werden, obwohl sie unterschiedliche Varianzen haben können.
- „full“ ermöglicht die Verwendung der vollständigen Kovarianzmatrix, wobei die Korrelationen zwischen den verschiedenen Merkmalen innerhalb jedes verborgenen Zustands berücksichtigt werden.
- „tied“ bedeutet, dass alle verborgenen Zustände dieselbe vollständige Kovarianzmatrix haben. Die Wahl des Kovarianztyps sollte auf Annahmen über die Struktur der Daten in jedem verborgenen Zustand beruhen. Komplexere Kovarianztypen, wie z. B. „full“, können Daten mit komplexen Abhängigkeiten zwischen Merkmalen besser anpassen, erfordern jedoch mehr Parameter zur Schätzung, was zu einer Überanpassung führen kann, wenn die Daten unzureichend sind.
Die Flexibilität, die durch die verschiedenen Parameter von hmm.GaussianHMM gegeben ist, ermöglicht es den Forschern, das Modell an die spezifischen Merkmale von Finanzzeitreihen anzupassen. Insbesondere der Parameter „covariance_type“ erlaubt es uns, verschiedene Annahmen über die Beziehungen zwischen den Merkmalen in jedem verborgenen Zustand zu treffen.
Bei der Abstimmung der hmm.GaussianHMM-Parameter für Finanzzeitreihen sollten deren spezifische Merkmale wie Volatilität, Preisschocks und mögliche Abweichungen der Verteilungen von der Normalverteilung berücksichtigt werden. Die Anzahl der verborgenen Zustände (n_components) sollte auf der Grundlage der erwarteten Anzahl von Marktregimen gewählt werden. Dies kann auf der Grundlage von Expertenwissen oder anhand von Modellauswahlkriterien wie AIC oder BIC bestimmt werden.
Es wird empfohlen, mit einer kleinen Anzahl von Zuständen (z. B. 2 oder 3) zu beginnen und diese je nach Bedarf zu erhöhen, wobei das Risiko einer Überanpassung zu kontrollieren ist. Für univariate Finanzzeitreihen (z. B. Renditen) können die Kovarianzarten „diag“ oder „spherical“ ausreichend sein. Bei multivariaten Reihen (z. B. Renditen mehrerer Vermögenswerte oder Merkmale wie Preis und Volumen) ermöglicht die Option „full“ die Modellierung von Korrelationen, erhöht jedoch die Komplexität des Modells. Beim Kovarianztyp „tied“ wird für alle Bedingungen die gleiche Korrelationsstruktur angenommen.
Der Parameter min_covar trägt dazu bei, eine Überanpassung zu verhindern, indem er sicherstellt, dass die Varianzen nicht zu klein werden. Der Standardwert von 1e-3 ist oft ein guter Ausgangspunkt. Die Erstellung informativer Prior-Verteilungen (z. B. unter Verwendung von startprob_prior und transmat_prior, um Vorannahmen über Anfangszustandswahrscheinlichkeiten und Übergangstendenzen widerzuspiegeln) kann nützlich sein, insbesondere wenn die Daten begrenzt sind. So könnte man zum Beispiel Stabilität in Marktregimen erwarten, die in der Prior-Verteilung für die Übergangsmatrix kodiert werden kann.
Die Parameter n_iter und tol steuern die maximale Anzahl der Iterationen und die Konvergenzschwelle des EM-Algorithmus. Ein größerer Wert von n_iter kann zu einer besseren Konvergenz führen, erhöht aber auch die Trainingszeit. Ein kleinerer Wert von tol führt zu strengeren Konvergenzkriterien.
Die Vorverarbeitung von Finanzdaten ist von entscheidender Bedeutung. Es wird empfohlen, Renditen (prozentuale Veränderungen) anstelle von Preisen zu verwenden und möglicherweise technische Indikatoren wie gleitende Durchschnitte, Volatilitätsmaße (z. B. ATR) und Volumenindikatoren als Indikatoren einzubeziehen. Eine Normalisierung oder Standardisierung der Merkmale wird ebenfalls empfohlen. Finanzielle Zeitreihen sind häufig nicht stationär. Es sollte in Erwägung gezogen werden, die Daten zu differenzieren oder ein gleitendes Fenster für die Parameterschätzung zu verwenden, um sich an die veränderte Marktdynamik anzupassen.
Um die optimale Kombination von Hyperparametern für einen bestimmten Finanzdatensatz zu finden, sollten Methoden wie die Gittersuche oder die Bayes'sche Optimierung (z. B. mit Optuna) verwendet werden. Die nicht-stationäre Natur von Finanzzeitreihen erfordert eine sorgfältige Vorverarbeitung und möglicherweise den Einsatz adaptiver Methoden, wie z. B. das Lernen mit gleitenden Fenstern. Die Abstimmung der Hyperparameter ist ebenfalls von entscheidender Bedeutung, um sicherzustellen, dass das GaussianHMM-Modell die zugrundeliegende Marktdynamik effektiv erfasst, ohne sich zu sehr an historische Daten anzupassen.
Die Klasse hmm.GMMHMM
Die Klasse hmm.GMMHMM ist für die Arbeit mit kontinuierlichen Emissionen konzipiert, die am besten durch eine Mischung aus mehreren Gauß-Verteilungen dargestellt werden. Auf diese Weise lassen sich komplexere Emissionsmuster modellieren als mit einer einzelnen Gauß-Verteilung, was insbesondere bei Daten mit ausgeprägten Clustern innerhalb jedes verborgenen Zustands nützlich ist.
hmm.GMMHMM kann nützlich sein, wenn die Verteilung der Finanzdaten innerhalb eines bestimmten Regimes multimodal ist oder signifikant von der Gaußschen Verteilung abweicht. Beispielsweise können Renditen in einem Regime mit hoher Volatilität je nach Richtung der Preisbewegung unterschiedliche Merkmale aufweisen. hmm.GMMHMM erweitert hmm.GaussianHMM, indem jeder verborgene Zustand mit einer Mischung von Gauß-Verteilungen assoziiert werden kann. Dies ist besonders für Finanzzeitreihen von Vorteil, die unter verschiedenen Marktregimen ein komplexeres und nicht normalverteiltes Verhalten aufweisen können.
- Der Konstruktor der Klasse hmm.GMMHMM enthält alle Parameter der Klasse hmm.GaussianHMM und fügt außerdem den Parameter n_mix (ganze Zahl, Standardwert 1) hinzu, der die Anzahl der Mischungskomponenten in jedem Zustand sowie die zu den Mischungsgewichten gehörenden Prior-Verteilungen
- Der Parameter covariance_type in GMMHMM hat eine etwas andere „tied“-Option: alle Mischungskomponenten jedes Zustands haben dieselbe vollständige Kovarianzmatrix.
- Die Parameter params und init_params enthalten auch das Symbol „w“ zur Steuerung der GMM-Mischungsgewichte.
- Der Hauptunterschied bei den Parametern liegt in n_mix und den zugehörigen Prior-Verteilungen für die Mischungsgewichte, was eine flexiblere Modellierung der Emissionswahrscheinlichkeiten in jedem verborgenen Zustand ermöglicht. Die subtilere „tied“-Option für die Kovarianz in GMMHMM bietet ebenfalls eine zusätzliche Möglichkeit, das Modell zu beschränken.
Bei der Festlegung der hmm.GMMHMM-Parameter für Finanzzeitreihen ist die Wahl der Anzahl der Mischungskomponenten (n_mix) ein entscheidender Schritt. Die Anzahl der Mischungskomponenten sollte die Verteilung der Finanzdaten in jedem verborgenen Zustand bestmöglich darstellen. Dies erfordert in der Regel einige Experimente. Es wird empfohlen, mit einer kleinen Anzahl von Komponenten (z. B. 2 oder 3) zu beginnen und diese zu erhöhen, wenn das Modell nicht gut genug passt, aber eine Überanpassung sollte vermieden werden.
Informationskriterien wie AIC oder BIC können verwendet werden, um den optimalen Wert von n_mix zu bestimmen. Andere Parameter können ähnlich wie die hmm.GaussianHMM-Parameter konfiguriert werden, wobei die spezifischen Merkmale der Finanzdaten berücksichtigt werden. Die Wahl von covariance_type wirkt sich zum Beispiel darauf aus, wie die Varianz innerhalb jeder Mischungskomponente modelliert wird. Die Auswahl der optimalen Anzahl von Mischungskomponenten (n_mix) ist ein wichtiger Schritt für den effektiven Einsatz von hmm.GMMHMM für finanzielle Zeitreihen. Dabei gilt es, die Fähigkeit des Modells, komplexe Datenverteilungen zu erfassen, gegen das Risiko einer Überanpassung abzuwägen, was die Anwendung von Methoden wie Kreuzvalidierung oder Informationskriterien erfordern kann, um robuste Schätzungen zu erhalten.
Die Klasse vhmm.VariationalGaussianHMM
Die Klasse vhmm.VariationalGaussianHMM ist ein Hidden-Markov-Modell mit multivariaten Gauß-Emissionen, das mithilfe von Variationsinferenz anstelle des in hmm.GaussianHMM verwendeten Erwartungsmaximierungsalgorithmus (EM) trainiert wird.
Ziel der Variationsinferenz ist es, die Parameter einer Verteilung zu finden, die der wahren Posterior-Verteilung der latenten Variablen und Modellparameter am nächsten kommt. Im Gegensatz zur EM, die Punktschätzungen der Parameter liefert, liefert die Variationsinferenz Posteriorverteilungen für die Modellparameter, die für die Schätzung der Unsicherheit nützlich sein können.
Der Hauptunterschied von vhmm.VariationalGaussianHMM liegt in der Verwendung der Variationsinferenz für das Training. Dieser Bayes'sche Ansatz hat Vorteile gegenüber der Maximum-Likelihood-Schätzung in hmm.GaussianHMM, insbesondere durch die Bereitstellung eines Maßes für die Unsicherheit durch die Posteriorverteilungen der Modellparameter.
- Der Konstruktor der Klasse vhmm.VariationalGaussianHMM enthält n_components, covariance_type, algorithm, random_state, n_iter, tol, verbose, params, init_params und Implementierungsparameter, ähnlich denen von hmm.GaussianHMM.
- Die wichtigsten zusätzlichen Parameter in Bezug auf die Prior-Verteilungen sind startprob_prior, transmat_prior, means_prior, beta_prior, dof_prior und scale_prior. Wenn diese Parameter auf None gesetzt sind, werden die Standard-Prior-Verteilungen verwendet. Der Parameter beta_prior bezieht sich auf die Genauigkeit der Prior-Normalverteilung für die Mittelwerte. Die Parameter dof_prior und scale_prior legen die Prior-Verteilung für die Kovarianzmatrix fest (inverse Wishart- oder inverse Gamma-Verteilung, je nach Kovarianz-Typ).
- Die Initialisierung von vhmm.VariationalGaussianHMM erfordert die Angabe von Prior-Verteilungen für alle Modellparameter. Diese Prior-Verteilungen spielen beim Training eine wichtige Rolle, insbesondere wenn die Daten begrenzt sind, und ermöglichen die Einbeziehung von Vorwissen oder Überzeugungen über die Parameter.
Bei der Abstimmung der Parameter von vhmm.VariationalGaussianHMM für Finanzzeitreihen ist die Wahl der Prior-Verteilungen wichtig. Prior-Verteilungen wirken als eine Form der Regularisierung und verhindern, dass sich das Modell zu sehr an die Trainingsdaten anpasst. Sie erlauben auch die Einbeziehung von vorhandenem Wissen oder Überzeugungen bezüglich der Modellparameter.
Wenn beispielsweise Grund zu der Annahme besteht, dass die Anfangsverteilung der Zustände (startprob_) relativ gleichmäßig sein sollte, kann man einen Dirichlet-Prior mit symmetrischen Parametern nahe bei 1 verwenden. In ähnlicher Weise können Überzeugungen über Übergangswahrscheinlichkeiten (transmat_), Mittelwerte (means_prior) oder Kovarianzen (scale_prior, dof_prior) durch die Wahl geeigneter priorer Verteilungen kodiert werden.
Die Wahl der prioren Verteilungen beeinflusst die resultierenden posterioren Verteilungen der Modellparameter nach dem Training auf den Daten. Informative Prior-Verteilungen (z. B. mit einer geringen Varianz um einen bestimmten Wert) haben einen stärkeren Einfluss, da sie die posteriore Verteilung in Richtung der Prior-Verteilung beeinflussen. Uninformative oder schwache Prior-Verteilungen (z. B. solche mit großen Varianzen oder gleichmäßigen Verteilungen) haben weniger Einfluss, sodass die Daten die posteriore Verteilung dominieren.
Vergleich der Leistung von Modellen für finanzielle Zeitreihen
Das Modell hmm.GaussianHMM ist ein Basismodell, das davon ausgeht, dass die beobachteten Finanzdaten in jedem verborgenen Zustand gaußverteilt sind. Seine Stärken liegen in der Einfachheit und Recheneffizienz, wodurch es sich für große Datensätze und Fälle eignet, in denen kein Grund zu der Annahme besteht, dass die Verteilungen erheblich von der Normalverteilung abweichen.
Sein Schwachpunkt ist jedoch die Annahme von Normalverteilungen, die für viele Finanzzeitreihen, die durch Schiefe, Kurtosis und dicke Schwänze gekennzeichnet sind, möglicherweise nicht zutreffen. In Szenarien, in denen die Finanzdaten in jedem Regime relativ gut durch eine Normalverteilung approximiert werden, kann hmm.GaussianHMM gute Ergebnisse erbringen, z. B. bei der Modellierung wichtiger Marktregime auf täglichen oder wöchentlichen Daten. Es kann auch bei der Modellierung von Daten mit hoher Frequenz oder von Daten mit Spitzen und nicht-normalen Verteilungen schlechter abschneiden.
Das Modell hmm.GMMHMM erweitert die Möglichkeiten von hmm.GaussianHMM, indem es die Verwendung einer Mischung von Gaußschen Verteilungen zur Modellierung der Emissionen in jedem verborgenen Zustand ermöglicht. Seine Stärke liegt in der Fähigkeit, komplexere multimodale Verteilungen zu modellieren, wodurch es sich besser für Finanzdaten eignet, die innerhalb eines einzigen Marktregimes unterschiedliche Teilmuster aufweisen können. In Zeiten hoher Volatilität können sich die Renditen beispielsweise je nach Marktrichtung unterschiedlich verhalten.
Der Schwachpunkt von hmm.GMMHMM ist die steigende Anzahl von Parametern, die zu einer Überanpassung führen kann, insbesondere bei begrenzten Daten. Außerdem kann das Training im Vergleich zu hmm.GaussianHMM rechenintensiver sein.
hmm.GMMHMM kann bei der Modellierung von Finanzzeitreihen, bei denen die Verteilungen mit mehreren Modi nicht normalverteilt oder multimodal sind, wie z. B. bei der Analyse von Intraday- oder Volatilitätsdaten, bessere Ergebnisse liefern. Bei der Modellierung einfacher Regime mit annähernd normaler Verteilung oder bei sehr kleinen Datensätzen, bei denen das Risiko einer Überanpassung hoch ist, kann sie schlechter abschneiden.
Das vhmm.VariationalGaussianHMM-Modell verwendet zum Lernen Variationsinferenz, einen Bayes'schen Ansatz. Seine Stärke ist die Fähigkeit, posteriore Parameterverteilungen zu liefern, die eine Bewertung der Modellunsicherheit ermöglichen. Der Bayes'sche Ansatz kann auch nützlich sein, wenn die Daten begrenzt sind, dank der Verwendung von Prior-Verteilungen, die das Modell regulieren und Vorwissen einbeziehen können.
Ein Schwachpunkt von vhmm.VariationalGaussianHMM ist die Schwierigkeit, Prior-Verteilungen anzupassen, was die Ergebnisse erheblich beeinflussen kann. Außerdem handelt es sich bei der Variationsinferenz um eine Näherungsmethode, und die resultierende Posterior-Verteilung kann von der wahren Posterior-Verteilung abweichen.
vhmm.VariationalGaussianHMM kann bei der Modellierung von Finanzzeitreihen besser abschneiden, wenn die Unsicherheit der Parameter wichtig ist oder wenn nur begrenzte Daten zur Verfügung stehen und Vorwissen verwendet werden muss. Sie kann schlechter abschneiden, wenn die Prior-Verteilungen schlecht gewählt sind oder wenn eine sehr hohe Genauigkeit der Parameterschätzung erforderlich ist, die die Maximum-Likelihood-Methode bei ausreichenden Daten liefern kann.
Die Wahl des Modells wird von Faktoren wie der Menge der verfügbaren Daten, der Komplexität der Marktdynamik und den Anforderungen an die Interpretierbarkeit des Modells beeinflusst. Für große Datensätze und relativ einfache Marktdynamik kann hmm.GaussianHMM aufgrund seiner Einfachheit und Berechnungseffizienz ausreichend und vorzuziehen sein. Für komplexere Dynamiken oder nicht-normale Verteilungen kann hmm.GMMHMM erforderlich sein. Wenn die Bewertung der Unsicherheit wichtig ist oder nur wenige Daten verfügbar sind, sollte vhmm.VariationalGaussianHMM in Betracht gezogen werden.
Schlussfolgerung und Empfehlungen
Bei finanziellen Zeitreihen hängt das potenziell beste oder schlechteste Modell von dem spezifischen Problem und den Merkmalen der Daten ab.
Im Allgemeinen ist hmm.GaussianHMM eine einfache und effiziente Wahl, wenn Finanzdaten unter Marktregimen durch eine Gauß-Verteilung vernünftig approximiert werden können. Wenn die Verteilungen komplexer oder multimodal sind, kann hmm.GMMHMM eine bessere Anpassung bieten, erfordert jedoch eine sorgfältigere Abstimmung und ist möglicherweise anfälliger für eine Überanpassung. vhmm.VariationalGaussianHMM bietet einen Bayes'schen Ansatz mit der Möglichkeit, die Unsicherheit zu schätzen, was in bestimmten Szenarien nützlich sein kann, jedoch das Verständnis und die richtige Auswahl der Prior-Verteilungen erfordert.
Es ist wichtig zu betonen, dass die Wahl des Modells nicht allein aus theoretischen Gründen getroffen werden kann. Empirische Validierung und Backtesting auf realen Finanzdaten sind notwendige Schritte, um festzustellen, welches Modell für ein bestimmtes Problem am besten geeignet ist. Verschiedene Leistungsmetriken wie Log-Likelihood, Vorhersagegenauigkeit und finanzspezifische Metriken (z. B. MAPE, R^2) sollten verwendet werden, um die Leistung von Modellen zu vergleichen und das am besten geeignete Modell zur Lösung eines bestimmten Finanzzeitreihenanalyseproblems auszuwählen.
Methoden zur Bestimmung von Prior-Kovarianzmatrizen für Zeitreihen in der hmmlearn-Bibliothek
Ein gängiger Typ von HMM ist das Gaußsche Emissionsmodell, bei dem davon ausgegangen wird, dass die beobachteten Daten in jedem verborgenen Zustand nach einer multivariaten Normalverteilung verteilt sind. Die Parameter dieser Verteilung sind der Vektor der Mittelwerte und die Kovarianzmatrix, die die Form, die Ausrichtung und den Grad der Abhängigkeit zwischen den Komponenten der beobachteten Daten bestimmt.
Beim Training von Gauß-HMMs, insbesondere bei der Verwendung von Bayes'schen Ansätzen wie der Variationsinferenz, spielt die Definition von Prior-Kovarianzmatrizen eine wichtige Rolle. Die Vorkenntnis der Kovarianzstruktur einer Zeitreihe kann das Modelltraining erheblich erleichtern, insbesondere in Situationen, in denen die Datenverfügbarkeit begrenzt ist. Falsch spezifiziertes Vorwissen kann zu suboptimalen Ergebnissen, Konvergenzproblemen bei Lernalgorithmen oder einer Überanpassung des Modells führen.
Die Python-Bibliothek hmmlearn bietet die Klassen hmm.GaussianHMM (und hmm.GMMHMM) und vhmm.VariationalGaussianHMM für die Arbeit mit HMMs mit Gaußschen Emissionen. Die Klasse hmm.GaussianHMM implementiert das Modelltraining mit dem klassischen Expectation-Maximization (EM)-Algorithmus, während vhmm.VariationalGaussianHMM einen Bayes'schen Ansatz auf der Grundlage von Variationsinferenz bietet.
Beide Klassen bieten Parameter zur Beeinflussung des Trainings und der Initialisierung, einschließlich der Möglichkeit, Prior-Verteilungen für die Kovarianzmatrizen anzugeben. Mit dem Parameter covariance_type können Sie den Typ der Kovarianzmatrix auswählen (spherical, diagonal, full, oder tied), während Sie mit den Parametern covars_prior und covars_weight in hmm.GaussianHMM sowie scale_prior und dof_prior in vhmm.VariationalGaussianHMM Prior-Verteilungen für die Kovarianzen angeben können. Die korrekte Verwendung dieser Parameter erfordert ein Verständnis der verschiedenen Methoden zur Bestimmung von Prior-Kovarianzmatrizen für Zeitreihen.
Methoden zur Bestimmung von Prior-Kovarianzmatrizen für Zeitreihen
Es gibt mehrere Ansätze zur Bestimmung von Prior-Kovarianzmatrizen für Zeitreihen, die jeweils auf unterschiedlichen Annahmen über die Daten und die verfügbaren Prior-Informationen beruhen.
Empirische Bewertung. Eine der direktesten Methoden ist die direkte Schätzung der Kovarianzmatrix aus zuvor erfassten Zeitreihendaten. Die Stichproben-Kovarianzmatrix spiegelt die Kovarianz zwischen den verschiedenen Komponenten der Zeitreihe wider, wobei jedes Element (i, j) der Matrix die Stichproben-Kovarianz zwischen der i-ten und j-ten Komponente darstellt und die Diagonalelemente die Stichprobenvarianzen repräsentieren.
Für eine Zeitreihe X der Länge T und der Dimension p kann die Stichproben-Kovarianzmatrix Σ̂ anhand der Standardgleichung berechnet werden. Die Anwendung der empirischen Schätzung auf Zeitreihen hat jedoch ihre Grenzen.
Zunächst wird davon ausgegangen, dass die Zeitreihe stationär ist, d. h. ihre statistischen Eigenschaften wie Mittelwert und Kovarianz ändern sich im Laufe der Zeit nicht.
Zweitens ist für eine zuverlässige Schätzung eine ausreichende Datenmenge im Vergleich zur Dimensionalität der Zeitreihe erforderlich.
Drittens kann bei einem im Vergleich zur Dimensionalität geringen Stichprobenumfang das Problem der Singularität der Kovarianzmatrix auftreten, was sie für die Verwendung in einigen Algorithmen ungeeignet macht.
Trotz dieser Einschränkungen kann die empirische Schätzung als angemessener Ausgangspunkt dienen, wenn genügend stationäre Daten verfügbar sind.
Methoden der Schrumpfung. In Situationen, in denen die empirische Schätzung der Kovarianzmatrix aufgrund des begrenzten Datenvolumens oder der hohen Dimensionalität unzuverlässig sein kann, können Schrumpfungsmethoden verwendet werden. Bei diesen Methoden wird die Kovarianzmatrix der Stichprobe mit einer Zielmatrix kombiniert, wobei ein Schrumpfungsfaktor verwendet wird, um das Gewicht jeder Matrix zu bestimmen.
Die Zielmatrix kann z. B. die Identitätsmatrix (unter der Annahme der Unabhängigkeit der Komponenten), eine Diagonalmatrix (unter der Annahme, dass keine Korrelation zwischen den Komponenten besteht) oder eine Matrix mit konstanter Varianz sein. Die Gleichung für die lineare Kompression lautet Rα = (1 – α)S + αT, wobei S die Kovarianzmatrix der Probe, T die Zielmatrix und α ∈ der Schrumpfungskoeffizient ist.
Schrumpfungsmethoden sind besonders nützlich, wenn die Datenmenge begrenzt ist, da sie den Schätzfehler der Kovarianzmatrix verringern, ihre Robustheit verbessern und eine Überanpassung des Modells verhindern. Die Auswahl der Zielstruktur erfordert einige Vorabinformationen über die Art der Abhängigkeiten in den Daten.
Verwendung informativer Prior-Verteilungen. Wenn es ein Vorwissen über den Themenbereich oder die Kovarianzstruktur der Zeitreihe gibt, kann dieses Wissen formal in das Modell einbezogen werden, indem informative Vorverteilungen verwendet werden.
Für Kovarianzmatrizen wird häufig die Inverse Wishart-Verteilung verwendet, die die konjugierte Prior-Verteilung für Kovarianzmatrizen in der multivariaten Normalverteilung ist. Die Parameter der inversen Wishart-Verteilung sind die Skalenmatrix und die Freiheitsgrade.
Die Wahl der Parameter der Prior-Verteilung sollte die bestehenden Vorannahmen über die Kovarianzstruktur widerspiegeln. Informative Prior-Verteilungen können auf der Grundlage früherer Forschungen, von Expertenwissen oder der Analyse ähnlicher Zeitreihen erstellt werden. Die Verwendung solcher Prior-Informationen kann das Modelltraining erheblich verbessern, vor allem wenn sie durch fundiertes Vorwissen unterstützt werden.
Uninformative Prior-Verteilungen. In Fällen, in denen es keine festen Vorannahmen über die Kovarianzstruktur der Zeitreihe gibt, können uninformative Prior-Verteilungen verwendet werden. Das Ziel solcher Prior-Informationen ist es, ihren Einfluss auf die Posterior-Verteilung zu minimieren, sodass die Daten die Trainingsergebnisse weitgehend bestimmen.
Ein Beispiel für eine nicht-informative Prior-Verteilung für eine Kovarianzmatrix ist die Jeffreys-Verteilung. Für Korrelationsmatrizen wird häufig der LKJ-Prior verwendet, der eine gleichmäßige Verteilung über den Raum der Korrelationsmatrizen gewährleistet oder unterschiedliche Konzentrationsgrade um die Nullkorrelation herum zulässt. Es ist jedoch zu beachten, dass die Definition eines wirklich uninformativen Priors schwierig sein kann, und dass selbst schwach informative Prior-Daten die Ergebnisse beeinflussen können, insbesondere bei begrenzten Daten.
Strukturelle Annahmen über Zeitreihen. Wenn eine Zeitreihe bekannte Autokorrelationseigenschaften aufweist, kann dieses Wissen genutzt werden, um eine Prior-Kovarianzmatrix zu erstellen. Zum Beispiel kann die Analyse der Autokorrelationsfunktion (ACF) und der partiellen Autokorrelationsfunktion (PACF) dabei helfen, die Ordnung der autoregressiven (AR) oder gleitenden Durchschnittsprozesse (MA) zu identifizieren, die die Zeitreihe beschreiben können.
Auf der Grundlage der Parameter dieser Modelle ist es möglich, eine Prior-Kovarianzmatrix zu konstruieren, die bekannte Zeitabhängigkeiten widerspiegelt. Beim AR(1)-Prozess zum Beispiel hängt die Struktur der Kovarianzmatrix vom Autokorrelationsparameter ab. Dieser Ansatz geht davon aus, dass die Zeitreihe durch ein Zeitreihenmodell angemessen beschrieben werden kann und dass die Parameter dieses Modells auf der Grundlage früherer Daten geschätzt werden können.
Anwendung von Methoden zur Bestimmung von Prior-Kovarianzmatrizen in hmmlearn
Die Bibliothek hmmlearn bietet verschiedene Optionen zur Definition von Prior-Kovarianzmatrizen unter Verwendung der Klassen hmm.GaussianHMM und vhmm.VariationalGaussianHMM.
Eine empirische Schätzung der Kovarianzmatrix, die aus vorläufigen Daten gewonnen wurde, kann zur direkten Initialisierung des Attributs covars_ sowohl in den Klassen hmm.GaussianHMM als auch vhmm.VariationalGaussianHMM verwendet werden. In ähnlicher Weise können die Ergebnisse der Anwendung von Schrumpfungsmethoden auf die empirische Kovarianzmatrix zur Initialisierung von covars_ verwendet werden.
Um informative Prior-Verteilungen zu spezifizieren, bietet die Klasse hmm.GaussianHMM die Parameter covars_prior und covars_weight. Diese Parameter steuern die Parameter der Prior-Verteilung für die Kovarianzmatrix covars_. Die Art der Prior-Verteilung hängt von dem Wert des Parameters covariance_type ab. Wenn covariance_type auf „spherical“ oder „diag“ gesetzt ist, wird die inverse Gamma-Verteilung verwendet. Wenn covariance_type auf „full“ oder „tied“ gesetzt ist, wird die inverse Wishart-Verteilung verwendet.
Der Parameter covars_prior wird als Formparameter für die inverse Gamma-Verteilung interpretiert und ist mit den Freiheitsgraden der inversen Wishart-Verteilung verknüpft. Der Parameter covars_weight ist ein Skalierungsparameter für die inverse Gamma-Verteilung und ist mit der Skalierungsmatrix für die inverse Wishart-Verteilung verwandt.
Die Klasse vhmm.VariationalGaussianHMM ermöglicht auch die Angabe informativer Prior-Verteilungen auf Kovarianzmatrizen unter Verwendung der Parameter scale_prior und dof_prior. Der Parameter dof_prior gibt die Freiheitsgrade für die Wishart-Verteilung (für „full“ und „tied“) oder die inverse Gamma-Verteilung (für „spherical“ und „diag“) an. Der Parameter scale_prior gibt die Skalenmatrix für die Wishart-Verteilung (für „full“ und „tied“) oder den Skalenparameter für die inverse Gamma-Verteilung (für „spherical“ und „diag“) an. Diese Parameter bestimmen die Vorannahmen über die Kovarianzstruktur in einem Bayes'schen Modell, das mittels Variationsinferenz implementiert wird.
Um nicht-informative Prior-Verteilungen zu spezifizieren, kann man die entsprechenden Parameter covars_prior, covars_weight, scale_prior und dof_prior verwenden und ihre Werte so einstellen, dass die Prior-Verteilung schwach oder diffus ist. So können zum Beispiel sehr kleine Werte für Parameter, die sich auf die Genauigkeit oder den inversen Maßstab beziehen, oder sehr große Werte für Parameter, die sich auf den Maßstab beziehen, angegeben werden.
Schließlich können strukturelle Annahmen über die Zeitreihen berücksichtigt werden, indem eine geeignete Kovarianzmatrix auf der Grundlage der Autokorrelationsanalyse konstruiert und diese Matrix zur Initialisierung des Attributs covars_ in beiden hmmlearn-Klassen verwendet wird.
Identifizierung von Marktregimen mittels HMM: Eintauchen in die Praxis
Bevor Sie diesen Abschnitt lesen, empfehle ich Ihnen, die beiden vorhergehenden Artikel zu lesen:
- Erforschung des maschinellen Lernens im unidirektionalen Trendhandel am Beispiel von Gold
-
Algorithmische Handelsstrategien: KI und ihr Weg zu den goldenen Zinnen
Diese Artikel beschreiben das Grundprinzip des Aufbaus von Handelssystemen. Anstelle von Kausalschlüssen oder Clustern von Marktregimen werden wir jedoch Hidden-Markov-Modelle verwenden, um Marktregime zu identifizieren. Auf diese Weise können Sie diese Ansätze testen und miteinander vergleichen und sich eine eigene Meinung über ihre Effizienz bilden.
Bevor Sie beginnen, stellen Sie sicher, dass Sie die erforderlichen Pakete installiert haben:
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from hmmlearn import hmm, vhmm from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX
Der Algorithmus identifiziert Marktregime durch das Training von Hidden-Markov-Modellen nach dem gleichen Prinzip wie in den Artikeln über das Clustering von Marktregimen beschrieben. Daher betreffen die Änderungen im Code nur die Identifizierung der Marktregime.
Im Folgenden finden Sie die Funktion, die die Marktregime definiert:
def markov_regime_switching(dataset, n_regimes: int, model_type="GMMHMM") -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Create and train the HMM model if model_type == "HMM": model = hmm.GaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) elif model_type == "GMMHMM": model = hmm.GMMHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, n_mix=3, ) elif model_type == "VARHMM": model = vhmm.VariationalGaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data
Der Code enthält 3 Modelle, die im theoretischen Teil beschrieben werden und Standardparameter haben. Zunächst müssen wir uns vergewissern, dass sie überhaupt funktionieren, und dann können wir die Parameter einstellen. Sie können beim Aufruf der Funktion eines der Modelle auswählen und sofort die Qualität des Clusterings testen.
Der Trainingszyklus bleibt derselbe, abgesehen von der Funktion der Ermittlung von Marktregimen:
for i in range(1): data = markov_regime_switching(dataset, n_regimes=hyper_params['n_clusters'], model_type="HMM") sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_one_direction(clustered_data, markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1)))
Die Trainingshyperparameter werden wie folgt festgelegt:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 5,
}
- Die Periode von Merkmalen, für die das Training der versteckten Markov-Modelle durchgeführt wird, ist gleich fünf.
- Kaufrichtung für Gold
- Die geschätzte Zahl der Regime beträgt fünf.
Alle Modelle werden auf Standardabweichungen in einem gleitenden Fenster (Volatilität) als Merkmale getestet:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Trainingsergebnisse mit Standardparametern
- Der GaussianHMM-Algorithmus mit den Standardparametern hat gezeigt, dass er in der Lage ist, versteckte Zustände (Regimes) zu finden, was zu einer akzeptablen Saldenkurve bei den Testdaten führte.
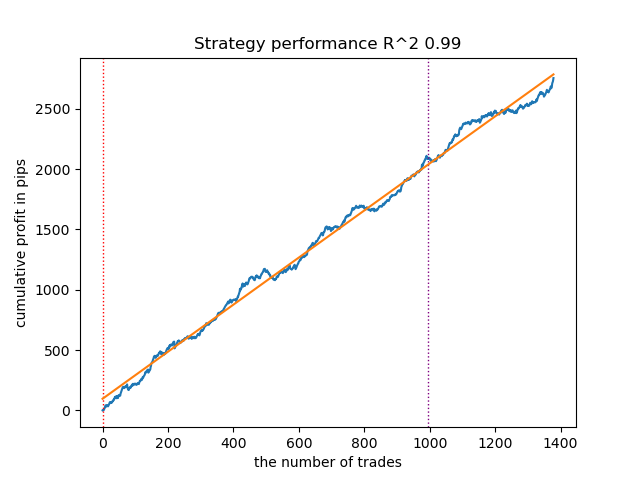
Abb. 1. Testen von GaussianHMM mit Standardeinstellungen
- Der GMMHMM-Algorithmus schnitt ebenfalls gut ab, wobei keine nennenswerten Veränderungen in der Qualität der Modelle zu beobachten waren.
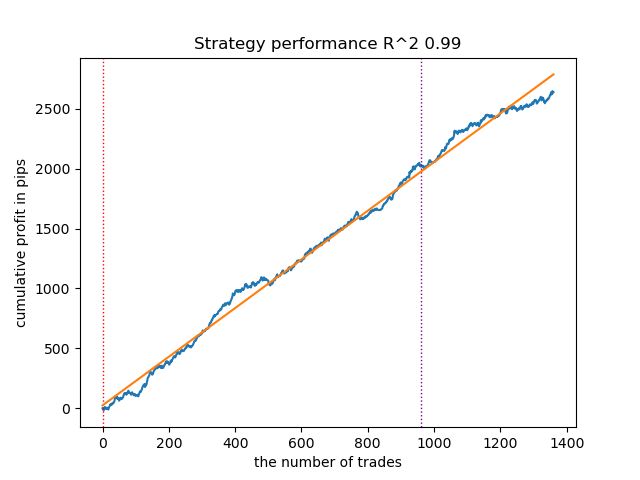
Abb. 2. Testen von GMMHMM mit Standardeinstellungen
- Der VariationalGaussianHMM-Algorithmus mag wie ein Ausreißer erscheinen, aber nach ein paar erneuten Trainings kann er bessere Kurven erzeugen.
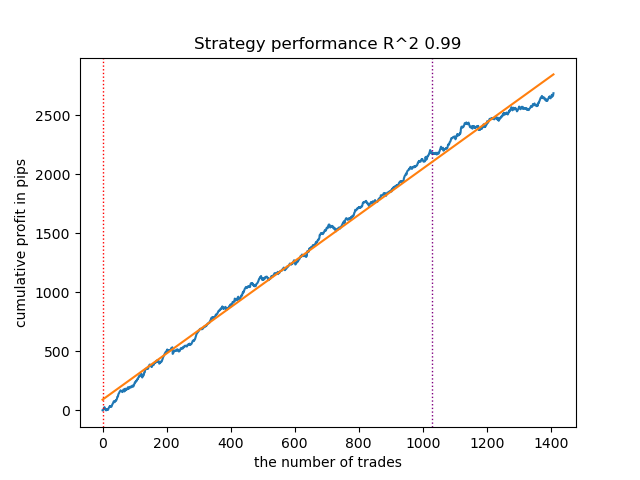
Abb. 3. Testen des VariationalGaussianHMM mit Standardeinstellungen
Insgesamt haben sich alle Algorithmen als praktisch einsetzbar erwiesen, sodass wir mit der Abstimmung ihrer Parameter fortfahren können.
Erhöhung der Anzahl der Trainingsiterationen (n_iter = 100)
Mit einer Erhöhung der Anzahl der Iterationen des Trainings der Markov-Modelle verbesserten sich die Ergebnisse auf neuen Daten für alle Modifikationen des Algorithmus etwas. Dies ist offenbar darauf zurückzuführen, dass die Algorithmen bessere lokale Optima gefunden haben. Insgesamt wurden in diesem Stadium keine signifikanten Unterschiede in der Qualität der resultierenden Modelle für die verschiedenen Algorithmen festgestellt. Aber GaussianHMM ließ sich aufgrund seiner Einfachheit etwas schneller trainieren.
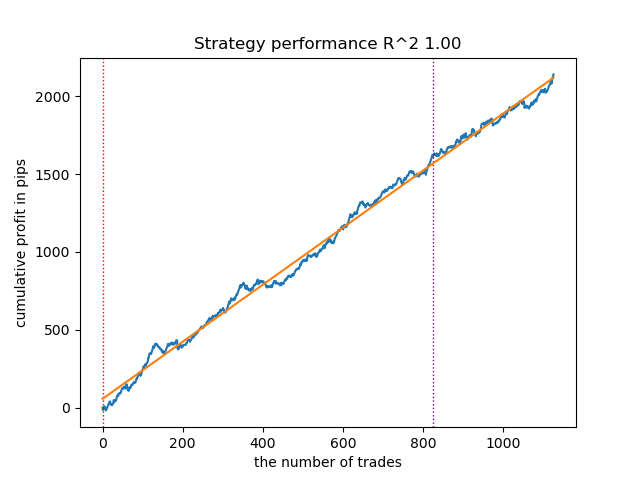
Abb. 4. Testen von GaussianHMM mit n_iter = 100
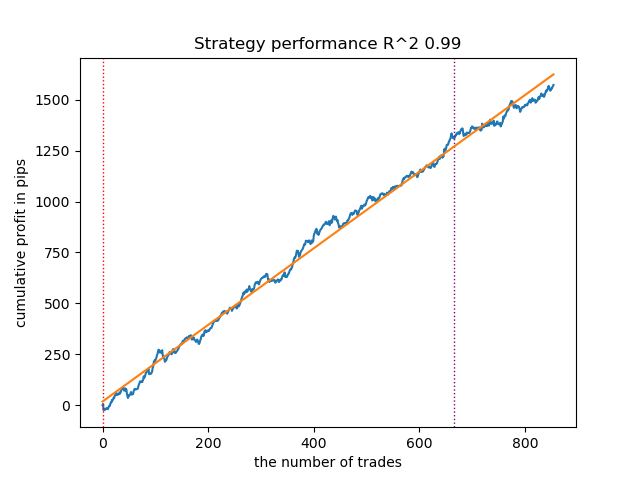
Abb. 5. Prüfung von GMMHMM mit n_iter = 100
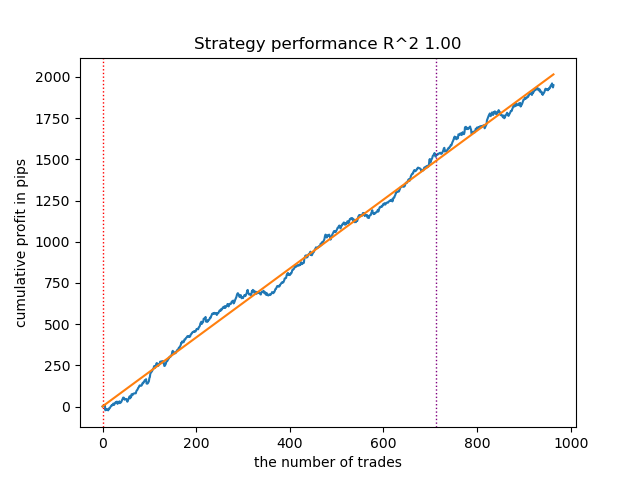
Abb. 6. Testen des VariationalGaussianHMM mit n_iter = 100
Verringerung der Zahl der Marktregimes auf drei
Die Anzahl der Iterationen beeinflusst die Qualität der Modelle. Lassen wir diesen Parameter auf 100 Iterationen stehen. Versuchen wir, die Anzahl der Regimes (verborgene Zustände der Modelle) auf drei zu reduzieren und die Ergebnisse zu betrachten.
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 3,
} GaussianHMM, GMMHMM und VariationalGaussianHMM zeigten gute Ergebnisse bei der Identifizierung der drei Marktregime, wobei letzteres mehrere Trainingsneustarts erforderte.
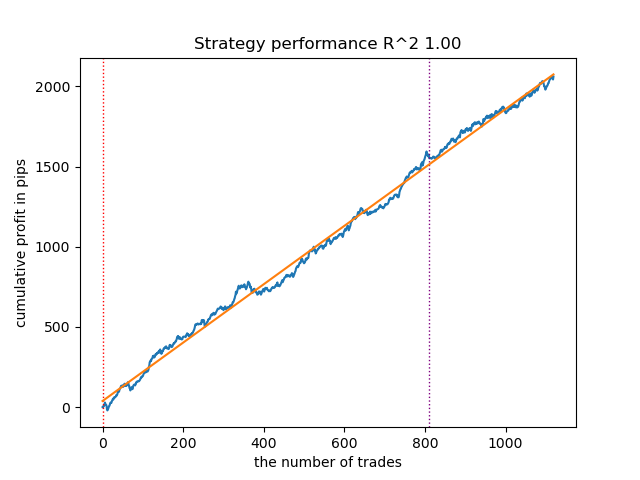
Abb. 7. Testen von VariationalHMM mit n_iter = 100 und drei Regimen
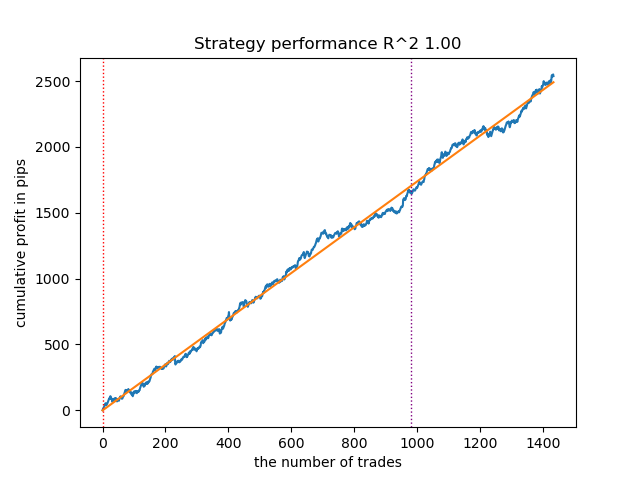
Abb. 8. Testen von GMMHMM mit n_iter = 100 und drei Regimen
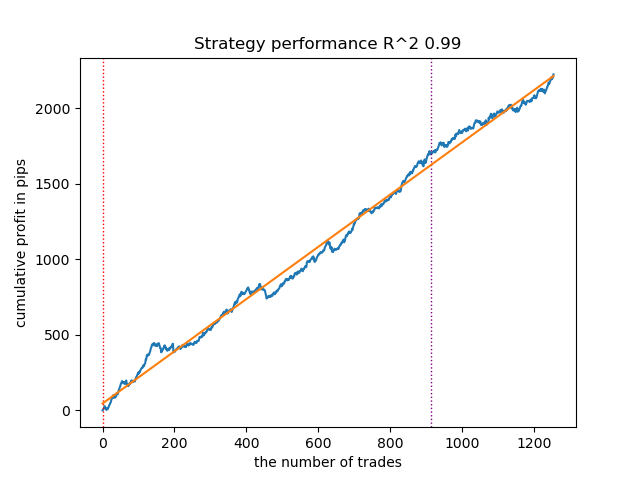
Abb. 9. Testen von VariationalGaussianHMM mit n_iter = 100 und drei Regimen
Erstellung von Prior-Kovarianzmatrizen für Hidden-Markov-Modelle
Im theoretischen Teil des Artikels wurden fünf Methoden zur Bestimmung von Prior-Kovarianzmatrizen für Zeitreihen betrachtet. Die erste und die letzte Methode sind für uns am besten geeignet. Rufen wir sie in Erinnerung:
- Empirische Bewertung. Eine der direktesten Methoden ist die direkte Schätzung der Kovarianzmatrix aus zuvor erfassten Zeitreihendaten. Die Stichproben-Kovarianzmatrix spiegelt die Kovarianz zwischen den verschiedenen Komponenten der Zeitreihe wider, wobei jedes Element (i, j) der Matrix die Stichproben-Kovarianz zwischen der i-ten und j-ten Komponente darstellt und die Diagonalelemente die Stichprobenvarianzen repräsentieren. Für die Zeitreihe X der Länge T und der Dimension p kann die Stichproben-Kovarianzmatrix Σ̂ anhand der Standardgleichung berechnet werden. Die Anwendung der empirischen Schätzung auf Zeitreihen hat jedoch ihre Grenzen. Zunächst wird davon ausgegangen, dass die Zeitreihe stationär ist, d. h. ihre statistischen Eigenschaften wie Mittelwert und Kovarianz ändern sich im Laufe der Zeit nicht. Zweitens ist für eine zuverlässige Schätzung eine ausreichende Datenmenge im Vergleich zur Dimensionalität der Zeitreihe erforderlich. Drittens kann die Kovarianzmatrix, wenn der Stichprobenumfang im Vergleich zur Dimensionalität klein ist, unter Singularität leiden, sodass sie für die Verwendung in einigen Algorithmen ungeeignet ist. Trotz dieser Einschränkungen kann eine empirische Schätzung als vernünftiger Ausgangspunkt dienen, wenn genügend stationäre Daten verfügbar sind.
- Strukturelle Annahmen über Zeitreihen. Wenn eine Zeitreihe bekannte Autokorrelationseigenschaften aufweist, kann dieses Wissen genutzt werden, um eine Prior-Kovarianzmatrix zu erstellen. Zum Beispiel kann die Analyse der Autokorrelationsfunktion (ACF) und der partiellen Autokorrelationsfunktion (PACF) dabei helfen, die Ordnung der autoregressiven (AR) oder gleitenden Durchschnittsprozesse (MA) zu identifizieren, die die Zeitreihe beschreiben können. Auf der Grundlage der Parameter dieser Modelle ist es möglich, eine Prior-Kovarianzmatrix zu konstruieren, die bekannte Zeitabhängigkeiten widerspiegelt. Beim AR(1)-Prozess zum Beispiel hängt die Struktur der Kovarianzmatrix vom Autokorrelationsparameter ab. Dieser Ansatz geht davon aus, dass die Zeitreihe durch ein Zeitreihenmodell angemessen beschrieben werden kann und dass die Parameter dieses Modells auf der Grundlage früherer Daten geschätzt werden können.
Wir können jedoch nicht mit Sicherheit sagen, dass Finanzzeitreihen durch solche einfachen Modelle angemessen beschrieben werden können. Experimente haben gezeigt, dass solche Prior-Verteilungen die Ergebnisse bei der Bestimmung verborgener Markov-Zustände nicht immer verbessern. Darüber hinaus habe ich mit dem Pre-Clustering mittels k-means experimentiert, um die Übergangsmatrizen mit den erhaltenen Werten zu initialisieren. Dies führte zu Hidden-Markov-Modellen, die ähnliche Ergebnisse lieferten wie in der vorangegangenen Arbeit, in der ein Clustering von Marktregimen durchgeführt wurde, ohne dass sich die Saldenkurve mit den neuen Daten wesentlich verbesserte.
Erstellen von Prior-Verteilung auf Basis von Clustern
Das Trainingsskript stellt eine experimentelle Funktion für die Vorberechnung von Prioren durch Clustering und das anschließende Training von Hidden-Markov-Modellen dar.
def markov_regime_switching_prior(dataset, n_regimes: int, model_type="HMM", n_iter=100) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Calculate priors from meta_features using k-means clustering from sklearn.cluster import KMeans # Use k-means to cluster the data into n_regimes groups kmeans = KMeans(n_clusters=n_regimes, n_init=10) cluster_labels = kmeans.fit_predict(X_scaled) # Calculate cluster-specific means and covariances to use as priors prior_means = kmeans.cluster_centers_ # Shape: (n_regimes, n_features) # Calculate empirical covariance for each cluster from sklearn.covariance import empirical_covariance prior_covs = [] for i in range(n_regimes): cluster_data = X_scaled[cluster_labels == i] if len(cluster_data) > 1: # Need at least 2 points for covariance cluster_cov = empirical_covariance(cluster_data) prior_covs.append(cluster_cov) else: # Fallback to overall covariance if cluster is too small prior_covs.append(empirical_covariance(X_scaled)) prior_covs = np.array(prior_covs) # Shape: (n_regimes, n_features, n_features) # Calculate initial state distribution from cluster proportions initial_probs = np.bincount(cluster_labels, minlength=n_regimes) / len(cluster_labels) # Calculate transition matrix based on cluster sequences trans_mat = np.zeros((n_regimes, n_regimes)) for t in range(1, len(cluster_labels)): trans_mat[cluster_labels[t-1], cluster_labels[t]] += 1 # Normalize rows to get probabilities row_sums = trans_mat.sum(axis=1, keepdims=True) # Avoid division by zero row_sums[row_sums == 0] = 1 trans_mat = trans_mat / row_sums # Initialize model parameters based on model type if model_type == "HMM": model_params = { 'n_components': n_regimes, 'covariance_type': "full", 'n_iter': n_iter, 'init_params': '' # Don't use default initialization } from hmmlearn import hmm model = hmm.GaussianHMM(**model_params) # Set the model parameters directly with our k-means derived priors model.startprob_ = initial_probs model.transmat_ = trans_mat model.means_ = prior_means model.covars_ = prior_covs # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data return data
Die Erstellung von Prior-Verteilungen am Beispiel des GaussianHMM-Modells sieht folgendermaßen aus:
- Normalisierung der Daten. Meta-Merkmale werden mit StandardScaler skaliert, um den Einfluss der Skalierung auf die Clustering-Ergebnisse zu eliminieren.
- K-means-Clustering. Damit werden die Anfangsparameter der verborgenen Zustände (Regime) festgelegt. Die Daten werden durch Clustering in n_regimes Clusters aufgeteilt. Die erhaltenen Cluster-Labels cluster_labels werden zur Berechnung der Mittelwerte prior_means (Clusterzentren) und der Kovarianzmatrizen prior_covs – der empirischen Kovarianz innerhalb von Clustern oder der Gesamtkovarianz, wenn der Cluster zu klein ist – verwendet.
- Berechnung der Anfangswahrscheinlichkeiten. Anfangsverteilung initial_probs: der Anteil der Punkte in jedem Cluster. Wenn zum Beispiel 30 % der Daten zu Cluster 0 gehören, dann ist initial_probs[0] = 0,3.
- Übergangsmatrix. Anschließend wird berechnet, wie häufig ein Cluster in der Zeitreihe auf einen anderen folgt.
- Anschließend wird das Hidden-Markov-Modell mit diesen Prioren initialisiert und trainiert.
Die übrigen Methoden gehen von noch schwächeren Abhängigkeiten aus und wurden daher gar nicht berücksichtigt. Dies ist wahrscheinlich keine vollständige Liste der möglichen Methoden zur Bestimmung von Priors. Andere Methoden können verwendet werden, sollten aber auf einem Expertenurteil beruhen.
Testen von Hidden-Markov-Modellen mit Prior-Verteilungen
Es wurde festgestellt, dass die Streuung der Ergebnisse abnahm. Die Wahrscheinlichkeit, dass Modelle in lokalen Minima stecken bleiben, wurde geringer, aber ihre Vielfalt nahm ab. Außerdem erfordert die Identifizierung von Marktregimen mithilfe von Hidden-Markov-Modellen in der Regel weniger Regime (Cluster) als k-means.
Die Ergebnisse der Tests dreier Modelle mit gegebenen Prior-Verteilungen sind nachstehend aufgeführt:
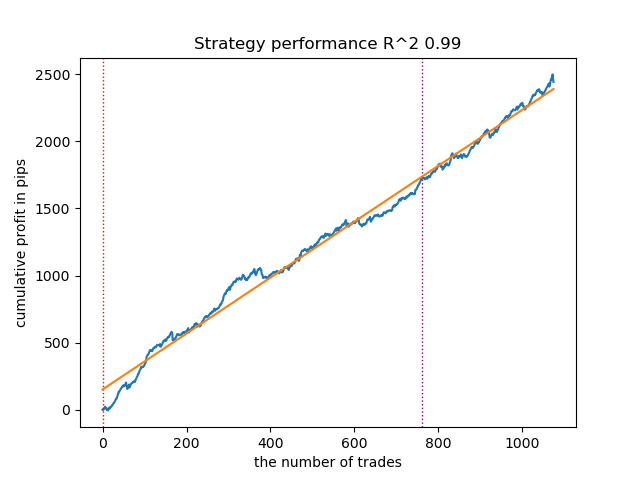
Abb. 10. Testen von GaussianHMM mit Prior-Verteilungen
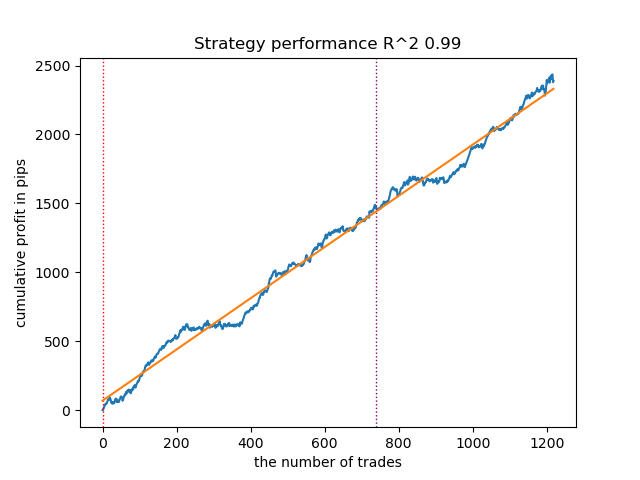
Abb. 11. Testen von GMMHMM mit Prior-Verteilungen
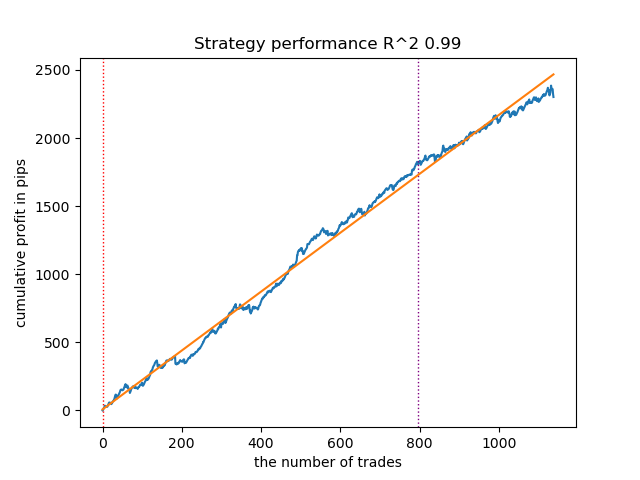
Abb. 12. Testen von VariationalGaussianHMM mit Prior-Verteilungen
Exportieren von Modellen und Kompilieren eines Bots für Meta Trader 5
Der Export von Modellen erfolgt auf genau dieselbe Weise, wie in früheren Artikeln vorgeschlagen. Das Modul mit dem Export ist in dem beigefügten Archiv enthalten.
Nehmen wir an, dass wir ein Modell mithilfe eines nutzerdefinierten Strategietesters ausgewählt haben.
# TESTING & EXPORT models.sort(key=lambda x: x[0]) test_model_one_direction(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True)
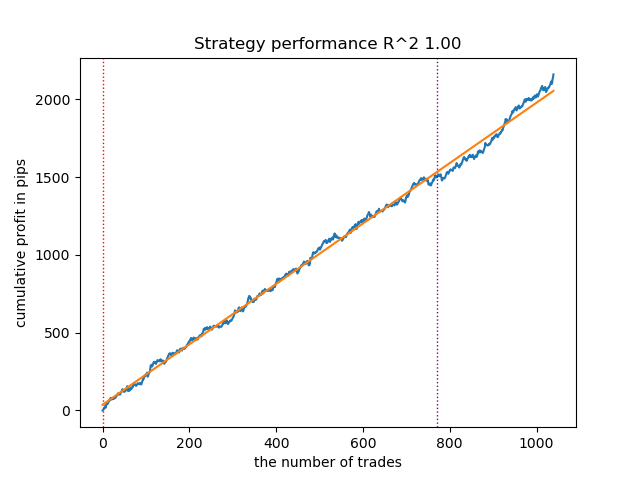
Abb. 13. Testen des besten Modells mit einem nutzerdefinierten Strategietester
Nun müssen Sie die Exportfunktion aufrufen, die die Modelle im Terminalordner speichert.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Dann sollten wir den am Ende des Artikels angehängten Bot kompilieren und ihn im MetaTrader 5 Tester testen.
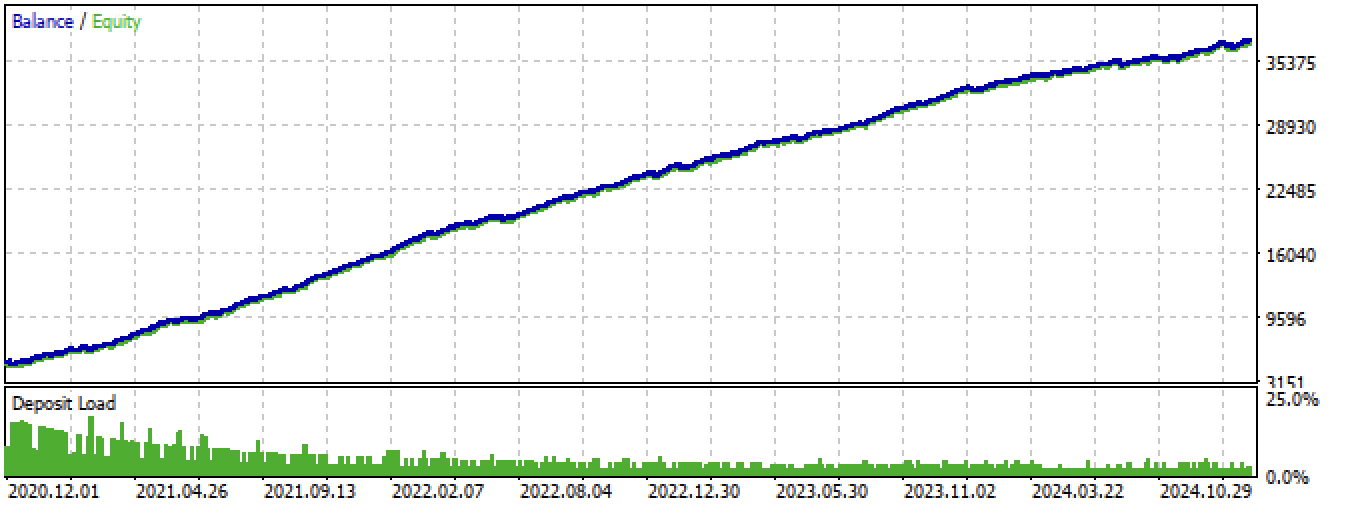
Abb. 14. Testen des besten Modells im Meta Trader 5 Terminal für den gesamten Zeitraum
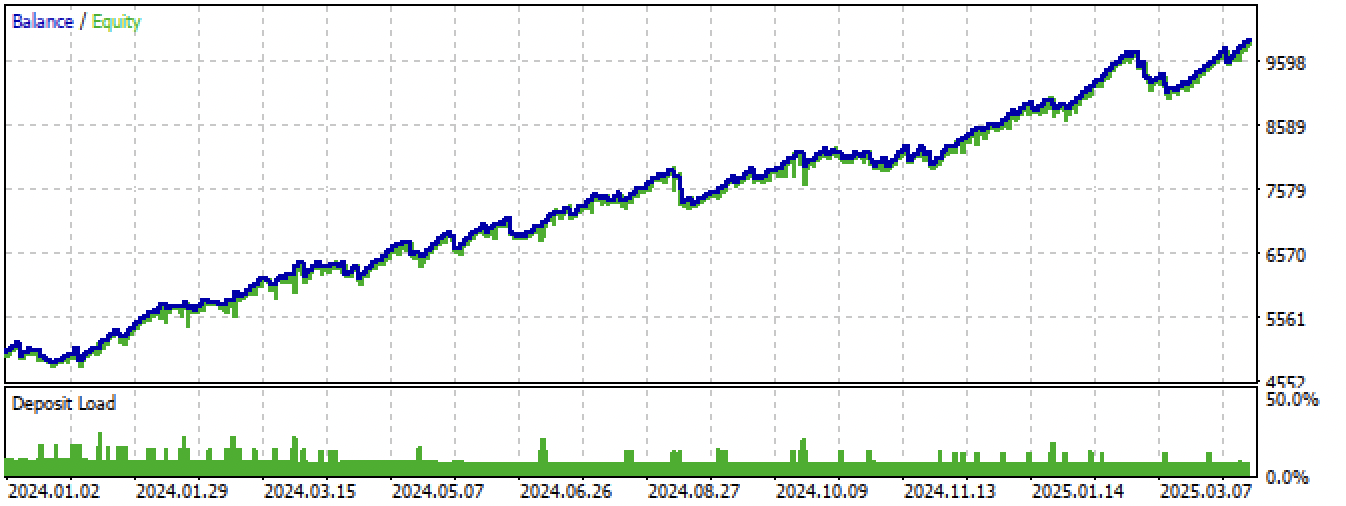
Abb. 15. Testen des besten Modells im Meta Trader 5 Terminal mit neuen Daten
Schlussfolgerung
Hidden-Markov-Modelle sind eine interessante Methode zur Identifizierung von Marktregimen. Doch wie alle Modelle des maschinellen Lernens neigen sie bei nicht-stationären Zeitreihen zur Überanpassung.
Eine qualitativ hochwertige Zuordnung von Prior-Matrizen ermöglicht es uns, stabilere Marktregime zu finden, die auch bei neuen Daten wirksam bleiben. In der Regel werden weniger Marktregime benötigt als im Falle der Clusterbildung. Wurden im ersten Fall 10 Cluster benötigt, so reicht es im zweiten Fall manchmal aus, 3-5 versteckte Zustände zu setzen.
Ich habe keine großen Unterschiede in der Leistung der drei Algorithmen gefunden, sie zeigen alle ungefähr die gleichen Ergebnisse. Daher können wir GaussianHMM verwenden, da es das einfachste und schnellste ist. GMMHMM kann theoretisch zu glatteren Saldenkurven führen, da eine Mischung von Verteilungen vorliegt, was zur Identifizierung von Teilmustern in jedem Marktregime beiträgt, aber dies kann zu einer größeren Überanpassung führen. VariationalGaussianHMM erfordert eine sorgfältigere Priorisierung, während seine Parameter schwieriger zu definieren und zu interpretieren sind.
Ein weiterer nützlicher Ansatz könnte die Kreuzvalidierung von Modellen durch die Schätzung der Parameter von multimodale Verteilungen bei verschiedenen Folds sein, doch wurde dieser Ansatz in dieser Arbeit nicht berücksichtigt.
Das Archiv Python files.zip enthält die folgenden Dateien für die Entwicklung in der Python-Umgebung:
| Dateiname | Beschreibung |
|---|---|
| one direction HMM.py | Das Hauptskript für das Training von Modellen |
| labeling_lib.py | Aktualisiertes Modul mit Handelskennzeichnung |
| tester_lib.py | Aktualisierter nutzerdefinierter Strategietester basierend auf maschinellem Lernen |
| export_lib.py | Modul zum Exportieren von Modellen auf das Terminal |
| XAUUSD_H1.csv | Die Datei mit den vom MetaTrader 5-Terminal exportierten Kursen |
Das Archiv MQL5 files.zip enthält Dateien für das MetaTrader 5-Terminal:
| Dateiname | Beschreibung |
|---|---|
| one direction HMM.ex5 | Der zusammengestellte Bot aus dem Artikel |
| one direction HMM.mq5 | Der Quellcode des Bot aus dem Artikel |
| Include//Trend following folder | Die ONNX-Modelle und die Header-Datei für die Verbindung mit dem Bot |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17917
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Затем, следует скомпилировать приложенного в конце статьи бота и протестировать его в тестере MetaTrader 5.
Abb. 14. Test des besten Modells im MetaTrader 5 Terminal für den gesamten Zeitraum
Das Archiv MQL5 files.zip enthält Dateien für das MetaTrader 5-Terminal
Bitte machen Sie es zu einem Standard, die entsprechenden tst-Dateien der Backtest-Ergebnisse in den Artikeln zu veröffentlichen. Ich danke Ihnen dafür.
Bitte machen Sie es zum Standard, die entsprechenden tst-Dateien der Backtest-Ergebnisse auch in Artikeln zu veröffentlichen. Ich danke Ihnen.