Diskussion zum Artikel "Algorithmische Handelsstrategien: KI und ihr Weg zu den goldenen Zinnen"
Nachdem ich den Artikel gelesen hatte, kam mir die Idee, mit dem Clustering-Prozess selbst zu spielen.
Ich habe eine Variante geschrieben, die das Clustering in einem gleitenden Fenster statt auf dem gesamten Datensatz durchführt. Dies kann die Partitionierung von Clustern unter Berücksichtigung der zeitlichen Struktur von BP verbessern.
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # Zuerst erstellen wir globale Referenzschwerpunkte. global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # Clustering in einem gleitenden Fenster anwenden for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # KMeans in das aktuelle Fenster einlernen local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # Anpassen der lokalen Zentren an die globalen Zentren # um die Konsistenz der Cluster-Labels zu gewährleisten centroid_mapping = {} for local_idx in range(n_clusters): # Suche nach dem nächstgelegenen globalen Schwerpunkt zu diesem lokalen Schwerpunkt distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 +1, um mit der Nummerierung bei 1 zu beginnen # Die Beschriftungen für das aktuelle Fenster abrufen local_labels = local_kmeans.predict(window_data) # Lokale Bezeichnungen in konsistente globale Bezeichnungen umwandeln for j in range(window_size): if i+j < len(clusters): # Prüfung auf Überschreitung der Grenzen clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
Fügen Sie diese Funktion in den Code ein und ersetzen Sie clustering durch sliding_window_clustering.
Es scheint die Ergebnisse zu verbessern.
Dennoch ist es manchmal nützlich, Artikel zu schreiben.
Vielen Dank für den Artikel Dmitrievsky. Es sieht so aus, als ob der hochgeladene EA und seine Include-Datei nicht miteinander übereinstimmen. Es bezieht sich auf die mpq-Datei im Ordner "Trend Following", aber die Beispieldateien waren in "Mean Reversion".
Und die Funktion get_features in der "kausalen eine Richtung.py" sind nicht das gleiche wie das, was in dem Artikel erscheint. Außerdem ist die mqh-Datei, die von "causal one direction.py" beim Exportieren von .onnx erzeugt wird , nicht dieselbe wie die in MQL5_files.zip angebotene.
Ich wäre Ihnen sehr dankbar, wenn Sie die notwendige Klarstellung vornehmen könnten.
Paul

Vielen Dank für den Artikel Dmitrievsky. Es sieht so aus, als ob der hochgeladene EA und seine Include-Datei nicht miteinander übereinstimmen. Es bezieht sich auf die mpq-Datei im Ordner "Trend Following", aber die Beispieldateien waren in "Mean Reversion".
Und die Funktion get_features in der "kausalen eine Richtung.py" sind nicht das gleiche wie das, was in dem Artikel erscheint. Außerdem ist die mqh-Datei, die von "causal one direction.py" beim Exportieren von .onnx erzeugt wird , nicht die gleiche wie die in MQL5_files.zip angebotene.
Ich wäre Ihnen sehr dankbar, wenn Sie die notwendige Klarstellung vornehmen könnten.
Paul
Die Archive wurden aktualisiert und eine neue Clustermethode hinzugefügt.
Jetzt stimmen alle Pfade und Funktionen überein.
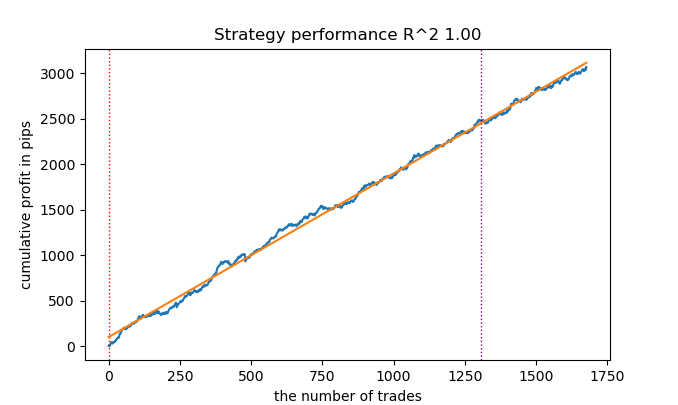
So haben Sie R2 ist ein modifizierter Index, dessen Effizienz auf dem Gewinn in Pips basiert. Was ist mit dem Drawdown und anderen Leistungsindikatoren? Wenn wir ein Modell erhalten, das mehr als 90 % beim Training und mindestens 85 % beim Test erzielt, dann wird Ihr Index beeindruckende Zahlen liefern. Egal, wie oft ich den Tester auf MT5 laufen lasse, ich habe noch nie einen Gewinn in der Historie erhalten. Das Depot ist aufgebraucht. Dies ist trotz der Tatsache, dass Ihr Tester auf Python gibt 0,97-0,98
Ich verstehe nicht, was das mit CV zu tun hat.
Alle diese Strategien haben eine geringe Beweiskraft, weil sie nur auf der Geschichte der nicht-stationären Kurse basieren. Aber man kann Trends aufspüren.- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Algorithmische Handelsstrategien: KI und ihr Weg zu den goldenen Zinnen :
Die Entwicklung des Verständnisses der Fähigkeiten von Methoden des maschinellen Lernens im Handel hat zur Entwicklung verschiedener Algorithmen geführt. Sie sind gleich gut in der gleichen Aufgabe, aber grundlegend verschieden. In diesem Artikel wird erneut ein unidirektionales Handelssystem für Gold betrachtet, allerdings unter Verwendung eines Clustering-Algorithmus.
Wenn man diesen wichtigen Ansatz zur Analyse und Prognose von Zeitreihen aus verschiedenen Blickwinkeln betrachtet, kann man seine Vor- und Nachteile im Vergleich zu anderen Methoden zur Erstellung von Handelssystemen, die ausschließlich auf der Analyse und Prognose von Finanzzeitreihen beruhen, bestimmen. In einigen Fällen sind diese Algorithmen sehr effektiv und übertreffen die klassischen Ansätze sowohl in Bezug auf die Geschwindigkeit der Erstellung als auch auf die Qualität der resultierenden Handelssysteme.
In diesem Artikel konzentrieren wir uns auf den unidirektionalen Handel, bei dem der Algorithmus nur kauft oder verkauft. Als Basisalgorithmen werden CatBoost- und K-Means-Algorithmen verwendet. CatBoost ist ein Basismodell, das die Funktionen eines binären Klassifizierers für die Klassifizierung von Handelsgeschäften übernimmt. K-Means wird hingegen in der Vorverarbeitungsphase zur Bestimmung der Marktarten verwendet.
Autor: dmitrievsky