
Нейросети в трейдинге: Многоагентная система с концептуальным подтверждением (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическим аспектами фреймворка FinCon, который был разработан в качестве инструмента для анализа и автоматизации в финансовой сфере. Его цель — помочь в принятии решений на финансовых рынках, используя методы обработки больших данных, анализа текстовой информации (NLP) и управления портфелем. Основная идея системы заключается в использовании многоагентной архитектуры, где каждый модуль выполняет определённые задачи, взаимодействуя с другими для достижения общих целей.
Ключевым элементом архитектуры является Агент-Менеджер, который координирует работу Агентов-Аналитиков. Менеджер объединяет результаты работы аналитиков, осуществляет контроль рисков и уточняет инвестиционную стратегию. В FinCon используются специализированные Аналитики, между которыми распределяются функции обработки и анализа данных, прогнозирования рыночной динамики и оценки рисков. Разделение задач между агентами позволяет снизить избыточность информации и ускоряет процесс обработки.
В фреймворке реализована двухуровневая архитектура управления рисками:
- Первый уровень работает в реальном времени, минимизируя краткосрочные потери.
- Второй уровень анализирует действия системы на основе завершённых эпизодов, помогая выявлять ошибки и улучшать стратегии.
Одной из ключевых функций FinCon является использование концептуального вербального подкрепления (CVRF). Этот механизм оценивает результаты работы Аналитиков и торговые решения, принятые Менеджером. Это позволяет системе учиться на собственном опыте и совершенствовать используемую политику поведения, фокусируясь на наиболее значимых рыночных факторах.
Фреймворк также включает трёхуровневую систему памяти:
- Рабочая память отвечает за временное хранение данных для выполнения текущих операций.
- Процедурная память сохраняет проверенные методы и алгоритмы, которые могут использоваться повторно.
- Эпизодическая память фиксирует ключевые события и их результаты, что позволяет анализировать прошлый опыт и применять его в будущем.
Авторская визуализация фреймворка FinCon представлена ниже.

В предыдущей статье была начата работа по реализации собственного видения подходов, предложенных авторами фреймворка. В рамках объекта CNeuronMemoryDistil были построены алгоритмы функционирования трехуровневой системы памяти. И сегодня мы продолжим эту работу.
Объект Агента-Аналитика
Сегодня мы начнем работу с построения модуля Агента-Аналитика. Авторы фреймворка FinCon разработали универсальный модуль агента, который может работать в самых разных областях, независимо от специфики выполняемых задач. Это стало возможным благодаря использованию архитектуры на основе предварительно обученной большой языковой модели (LLM), которая функционирует по принципу «вопрос-ответ» (QA). Специфика работы агента зависит от поставленного перед ним вопроса или задачи.
Хотя в наших моделях не используется LLM, это не мешает нам создать универсальный объект, который в дальнейшем может быть адаптирован для выполнения функций агентов-аналитиков с различной специализацией. Такой подход обеспечит гибкость и модульность системы.
Согласно описанию, данному в авторской работе, агенты фреймворка FinCon включают несколько ключевых модулей, которые интегрируются для поддержки их функциональности.
Модуль общей конфигурации и профилирования играет важную роль в определении типов решаемых задач. Он не только устанавливает цели торговли, включая подробности о секторах экономики и показателях эффективности, но и распределяет роли и обязанности между агентами. Этот модуль формирует базовую текстовую основу, которая используется для генерации запросов, связанных с функциональностью агента, к базе данных памяти.
Кроме того, модуль общей конфигурации и профилирования помогает агентам адаптироваться к разным секторам экономики, определяя наиболее важные метрики для текущей задачи. Информация, генерируемая этим модулем, становится основой для корректного взаимодействия всех остальных компонентов системы.
Модуль восприятия отвечает за организацию взаимодействия агента с окружающей средой. Он регулирует восприятие рыночной информации, фильтруя данные и выделяя значимые паттерны. Благодаря этому, агент может адаптироваться к изменяющимся условиям, оставаясь эффективным и точным в своих прогнозах.
Модуль памяти является критически важным компонентом, так как он обеспечивает хранение и обработку данных, необходимых для принятия решений. Он состоит из трех ключевых компонентов: рабочей памяти, процедурной памяти и эпизодической памяти. Рабочая память позволяет агенту выполнять текущие задачи, наблюдая за изменениями на рынке и адаптируя свои действия. Процедурная память фиксирует все шаги, предпринятые агентом в процессе работы, включая результаты и выводы. Эпизодическая память, в свою очередь, хранит данные о завершенных задачах и помогает формировать долгосрочные стратегии.
В предыдущей работе мы уже разработали модуль памяти и теперь можем использовать готовое решение. Здесь стоит сказать, что авторы фреймворка дали доступ к эпизодической памяти только менеджеру. Мы же в своей реализации будем использовать трехуровневую организацию памяти для всех агентов. Только каждый агент получит свой модуль памяти, что естественным образом ограничит доступ только к данным, релевантным для решения поставленной задачи. Такой подход позволит агенту учитывать не только последние изменения, но и их контекст в рамках более широкой временной перспективы.
Функционал модуля общей конфигурации и профилирования подразумевает наличие специального объекта, который находится вне агента и генерирует задачи с учетом специфики каждого агента и имеющихся исходных данных. В рамках нашей реализации мы предполагаем использование однотипных исходных данных. Это значит, что при фиксированной роли агента, на каждом шаге его работы будут генерироваться одинаковые запросы. Тем не менее, в процессе обучения модели такие запросы могут корректироваться, чтобы агент получал более точные задачи в соответствии с его текущей ролью и навыками.
Эти размышления подводят нас к идее создания обучаемого тензора запросов внутри самого модуля агента. Такой подход позволит исключить необходимость в дополнительном потоке внешней информации к агенту. При этом начальные значения такого тензора задаются случайным образом во время инициализации объекта. Эти параметры формируют "врожденные когнитивные" способности агента, создавая уникальную базу для его будущего обучения.
В процессе обучения агент постепенно приобретает роль, которая наилучшим образом соответствует его индивидуальным способностям, сформированным на этапе инициализации. Это позволяет агенту не только органично адаптироваться к поставленным задачам, но и эффективно использовать свои "врожденные" особенности, создавая прочную основу для дальнейшего развития. Обучаемый тензор запросов становится ключевым инструментом для выявления и усиления наиболее подходящего направления развития агента. Такой подход обеспечивает согласованность между случайно заданным начальным состоянием и целевой ролью агента, что, в свою очередь, способствует снижению затрат на обучение модели, повышая её общую эффективность.
Основная цель модуля восприятия — определить подходы, которые помогут выделить из общего потока информации паттерны, наиболее полезные для выполнения задач агента. Для реализации этой функции мы можем использовать механизмы кросс-внимания. Они позволят «подсветить» наиболее релевантные данные, обеспечивая эффективную фильтрацию и обработку информации.
После рассмотрения вопросов построения внутренних модулей агента, стоит остановиться на анализе результатов его работы. Одним из ключевых вопросов здесь является специфика получаемых результатов. С одной стороны, такая специфика обусловлена задачами, поставленными перед агентом, что несколько противоречит концепции универсального агента. С другой стороны, разнообразие результатов усложняет их обработку, что делает задачу стандартизации крайне актуальной.
В рамках данной реализации, на выходе каждого агента мы генерируем тензор предстоящего торгового решения. Конечно, мы помним, что авторами фреймворка предоставлено уникальное право генерации торгового решения только менеджеру. Но никто не запрещает каждому агенту дать свои предложения. Это позволяет нам создать унифицированную структуру данных, которая может использоваться для описания результатов работы агента, независимо от его конкретной роли. Такая стандартизация упрощает обработку результатов и способствует улучшению общей эффективности системы.
Все описанные выше подходы будут реализованы в рамках объекта CNeuronFinConAgent, структура которого представлена ниже.
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В представленной структуре можно наблюдать уже знакомый набор переопределяемых методов и несколько объектов, которые мы будем использовать для организации описанных выше подходов. С более детальной информацией о назначении каждого из них мы познакомимся в процессе реализации алгоритмов методов данного объекта.
Так же следует обратить внимание на использование именно объекта кросс-внимания в качестве родительского класса. Унаследованные таким образом методы и объекты мы тоже будем использовать для организации работы создаваемого модуля.
Все внутренние объекты объявлены статично, что упрощает структуру класса, позволяя оставить пустыми конструктор и деструктор. Инициализация всех внутренних и унаследованных объектов осуществляется в методе Init. Указанный метод принимает ряд констант, которые дают возможность чётко и однозначно определить архитектуру создаваемого объекта.
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
В теле метода мы, как всегда, сначала вызываем одноименный метод родительского класса, в котором уже организован процесс инициализации унаследованных объектов и интерфейсов обмена данных с внешними объектами.
Как упоминалось ранее, в качестве родительского класса был выбран объект кросс-внимания. Такие объекты предназначены для работы с двумя потоками данных, что может вызвать вопросы в контексте работы агентов FinCon. Ведь они изначально взаимодействуют с унитарным потоком информации, необходимым для решения конкретной задачи. Однако следует учитывать, что агенты дополнительно получают информацию из модуля памяти. Это вводит второй поток данных. Более того, важным аспектом работы агента является его последовательность и способность анализировать свои действия, внося коррективы в ответ на изменяющиеся рыночные условия. Такой процесс рефлексии формирует третий поток информации.
В рамках нашей реализации, функционал рефлексии будет организован с использованием механизмов, унаследованных от родительского класса. Ожидается, что подходы кросс-внимания окажутся эффективными для корректировки тензора предыдущих результатов в контексте изменения рыночной обстановки. Таким образом, основной поток данных для родительского объекта будет представлен параметрами тензора результатов, а второй поток — информацией о текущем состоянии окружающей среды.
Напомню, что на выходе агента мы ожидаем тензор рекомендуемых торговых операций.
Далее мы инициализируем два модуля внимания. В них мы отдельно сохраняем динамику рыночной ситуации и последовательность торговых решений, предложенных данным агентом. Это позволит нам лучше оценить эффективность используемой политики поведения в контексте текущей динамики рынка.
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
Модуль профилирования мы построим из двух последовательных полносвязных слоев. Первый слой содержит один элемент с фиксированным значением "1", а второй слой генерирует тензор заданного размера. В нашей реализации длина генерируемого вектора в 10 раз превышает длину описания одного элемента исходной последовательности. Это можно сравнить с описанием роли агента последовательностью из 10 элементов.
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
Роль модуля восприятия, как и обсуждалось ранее, выполняет внутренний объект кросс-внимания. Он должен провести анализ полученных исходных данных в контексте специфики агента.
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
А после успешной инициализации всех внутренних и унаследованных объектов мы возвращаем логический результат выполнения операций вызывающей программе и завершаем работу метода.
Следующим этапом нашей работы является построение алгоритма прямого прохода в рамках метода feedForward. Здесь нам предстоит организовать информационные потоки между инициализированными выше объектами.
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
В параметрах метода мы получаем указатель на объект исходных данных, который содержит описания состояния окружающей среды. И здесь следует вспомнить, что каждый агент анализирует полученную информацию с учетом своей специфики. Поэтому мы сначала генерируем тензор описания поставленной задачи.
Обратите внимание, что тензор роли агента генерируется только в процессе обучения. Ведь в режиме тестирования и промышленной эксплуатации модели, специализация агента остается неизменной, и повторная генерация данного тензора на каждой итерации не требуется.
Затем, мы воспользуемся внутренним объектом кросс-внимания для выделения паттернов, релевантных для решения поставленной перед агентом задачи.
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
Полученные значения мы передаем в модуль памяти состояний окружающей среды, с целью обогащения текущего состояния информацией о предшествующей динамике. Такой подход обеспечивает более глубокое понимания контекста.
Аналогичным образом мы добавляем результаты предыдущего прямого прохода в модуль памяти действий агента.
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
Таким образом, на выходе двух модулей памяти формируются тензоры описания последних действия агента и соответствующих изменений в состоянии окружающей среды. Эти данные передаются в одноименный метод родительского класса, который корректирует тензор рекомендуемых торговых операций с учетом текущей динамики рынка.
Однако перед этим, необходимо выполнить перестановку указателей на буферы данных, что позволит сохранить предыдущий тензор результатов, обеспечивая корректное выполнение операций обратного прохода во время обучения модели.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
Логический результат выполнения операций возвращаем вызывающей программе и завершаем работу метода.
После завершения реализации алгоритма прямого прохода, приступаем к организации информационных потоков для обратного прохода. Как известно, поток данных при распространении градиента ошибки повторяет структуру информационных потоков прямого прохода, но направлен в обратную сторону. Благодаря идентичности маршрутов прямого и обратного проходов, модель эффективно учитывает влияние каждого параметра на итоговый результат.
Операции распределения градиента ошибки реализованы в методе calcInputGradients. В параметрах метода мы получаем указатель на объект исходных данных, только теперь нам предстоит передать в него значения градиентов ошибки, соответствующие влиянию исходных данных на конечный результат работы модели.
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сразу проверяем актуальность полученного указателя, так как в противном случае все дальнейшие операции не имеют смысла.
Непосредственно операции распределения градиента ошибки начинаются с вызова одноименного метода родительского класса. Он передаст погрешности на модули внимания.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
По магистрали модуля памяти предложений торговых операций нам предстоит передать градиент ошибки на наш текущий объект. Ведь результаты его предыдущего прямого прохода использовались в качестве исходных данных для этого модуля памяти. Только в буфере результатов находятся уже другие значения, полученные при выполнении операций последнего прямого прохода. Кроме того, мы бы хотели сохранить текущие значения буфера градиентов ошибки. Поэтому, мы сначала вернем в буфер результатов предусмотрительно сохраненные результаты предыдущего прямого прохода, путем подмены указателей на объект буфера. А вместо указателя на буфер градиентов ошибки, подставим свободный буфер данных. И только после успешного выполнения подготовительных работ, осуществляем распределение градиентов ошибки.
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Здесь стоит обратить внимание, что мы не распространяем рекуррентно градиент ошибки на предыдущие проходы. И в таком случае нами не используется, полученный после выполнения указанных операций, градиент ошибки. Однако осуществление данных операций обусловлено необходимостью распределения градиентов ошибки между внутренними объектами модуля памяти. А после успешного выполнения указанных действий, мы возвращаем указатели на буферы данных в исходное состояние.
Далее нам предстоит распределить градиент ошибки по магистрали модуля памяти состояний окружающей среды. Здесь мы сначала спустим его до уровня модуля восприятия, роль которого выполняет блок кросс-внимания.
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
А затем распределим полученные погрешности между исходными данными и MLP генерации тензора описания роли агента в соответствии с их влиянием на результат работы модели.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
По MLP генерации тензора описания роли агента мы не распределяем градиент ошибки, так как её первый слой содержит фиксированное значение.
Поэтому, после выполнения всех необходимых операций, метод возвращает логический результат их успешности вызывающей программе и завершает свою работу.
На этом мы завершаем рассмотрение алгоритмов построения методов объекта универсального Агента-Аналитика. С полным кодом представленного класса и всех его методов вы можете самостоятельно ознакомиться во вложении.
Объект Менеджера
Следующим этапом нашей работы является построение объекта Агента-Менеджера. И здесь возникает небольшой диссонанс. С одной стороны, мы говорили о построении универсального агента, который может быть использован и в качестве менеджера. С другой стороны, менеджер объединяет результаты и координирует работу всех агентов. А значит, получает информацию из нескольких источников.
К описанной далее работе можно относится по-разному. В том числе и как к адаптации созданного выше универсального агента к решению задач менеджера. Ведь именно класс универсального агента мы использовали в качестве родительского при построении нового объекта, структура которого представлена ниже.
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
С целью минимизации потоков внешней информации, мы перенесли все агенты внутрь нашего менеджера. И в таком виде его можно воспринимать, как организацию целостного фреймворка FinCon. Однако, это скорее вопрос субъективного восприятия, мы же сосредоточимся на разработке функциональных возможностей нового объекта.
В представленной выше структуре нового объекта можно увидеть уже знакомый набор переопределяемых методов и несколько внутренних объектов, функционал которых мы рассмотрим в процессе создания алгоритмов этих методов нового класса.
Все внутренние объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех объявленных и унаследованных объектов осуществляется в методе Init. В параметрах данного метода мы получаем ряд констант, которые позволяю однозначно идентифицировать архитектуру создаваемого объекта.
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
В теле метода мы, как обычно, сразу вызываем одноименный метод родительского класса. Но в данном случае есть нюанс. Исходными данными для менеджера являются результаты работы агентов. Поэтому, в качестве окна исходных данных мы указываем размерность вектора результатов одного агента, а размер последовательности равен количеству внутренних агентов, включая агента оценки рисков.
Следует отметить, что наш менеджер будет работать с двумя типами агентов-аналитиков. Они будут анализировать текущее состояние окружающей среды в двух проекциях. И для получения второй проекции исходных данных мы воспользуемся объектом транспонирования матрицы.
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Далее мы организуем два последовательных цикла инициализация агентов-аналитиков.
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
И добавим агента контроля рисков. Для него исходными данными будет служить вектор описания текущего состояния счета, что и отражается в параметрах при вызове метода инициализации объекта.
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
Кроме того, нам потребуется объект конкатенации результатов работы всех внутренних агентов. Именно с этим объектом будет работать наш Агент-Менеджер, функционал которого мы унаследовали от родительского класса.
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
Здесь стоит обратить внимание, что информацию о состоянии счета мы планируем получать по вспомогательному информационному потоку, который представлен буфером данных. Однако, для корректной работы инициализированного агента по контролю рисков необходимо наличие объекта нейронного слоя, содержащего исходные данные. Поэтому мы создаем внутренний объект, в который будем переносить информацию, полученную по второму информационному потоку.
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
После завершения всех вышеописанных операций, метод возвращает логический результат, указывающий на успешность их выполнения, и завершает свою работу.
Далее мы переходим к построению алгоритма прямого прохода в рамках метода feedForward. В данном случае мы работаем с двумя информационными потоками исходных данных. По основной магистрали планируется получение тензора описания анализируемого состояния окружающей среды, а по второму — финансовый результат работы модели в виде вектора состояния счета.
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
В теле метода мы сначала проводим небольшую подготовительную работу, во время которой указатель на буфер результатов внутреннего объекта исходных данных второй магистрали (состояния счета) заменяется полученным буфером соответствующего информационного потока. Кроме того, мы осуществляем транспонирование тензора исходных данных основного информационного потока.
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
После выполнения подготовительных работ, мы передаем полученные данные агентам-аналитикам для анализа и генерации предложений.
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
Результаты их работы конкатенируются в единый объект.
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
А уже объединенные результаты работы всех агентов передаются менеджеру для принятия итогового решения по выполняемым торговым операциям.
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
Логический результат выполнения операций мы возвращаем вызывающей программе и завершаем работу метода.
На этом мы завершаем рассмотрение алгоритмов построения методов нашего Менеджера. Методы обратного прохода я предлагаю оставить для самостоятельного изучения. Полный код представленного класса и всех его методов вы можете найти во вложении.
Архитектура модели
Несколько слов об архитектуре обучаемой модели. В рамках подготовки данной статьи была обучена только одна модель Агента принятия торговых решений. Прошу не путать с агентами фреймворка FinCon.
Архитектура обучаемой модели практически без изменений перенесена из предыдущих работ, посвященных методу FinAgent. Был заменён лишь один нейронный слой, что позволило интегрировать реализованные подходы фреймворка FinCon.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полный код архитектуры обучаемой модели вы найдете во вложении к статье. Там же представлены программы, используемые в процессе обучения и тестирования модели. Все они были перенесены без изменений из предыдущих работ, поэтому мы не будем сейчас останавливаться на их рассмотрении.
Тестирование
Последние две статьи были посвящены фреймворку FinCon. В них мы подробно рассмотрели основные принципы его работы. Наше видение подходов, предложенных авторами фреймворка, было реализовано средствами MQL5, и теперь пришло время оценить эффективность реализованных подходов на реальных исторических данных.
Следует отметить, что представленная в данной работе реализация значительно отличается от оригинальной, что несомненно скажется на полученных результатах. Поэтому мы можем говорить только об оценке эффективности реализованных подходов.
Для обучения модели мы использовали данные валютной пары EURUSD за 2024 год на таймфрейме H1. Параметры анализируемых индикаторов были оставлены без изменений, что позволило сосредоточиться на анализе эффективности самих алгоритмов.
Обучающая выборка была сформирована на основе проходов нескольких моделей со случайно инициализированными параметрами. Кроме того, мы добавили успешные проходы, созданные по доступным данным рыночных сигналов с использованием метода Real-ORL. Это позволило расширить охват возможных рыночных ситуаций и наполнить обучающую выборку положительными примерами.
В процессе обучения применялся алгоритм, позволяющий формировать "почти идеальные" целевые действия для обучения Агента. Такой подход дает возможность обучать модель без постоянного обновления обучающей выборки. Однако, мы рекомендуем регулярное обновление данных, что может дополнительно улучшить результаты обучения, расширив охват состояний.
Итоговое тестирование проводилось на доступных данных за Январь 2025 года с сохранением прочих параметров. Результаты тестирования представлены ниже.
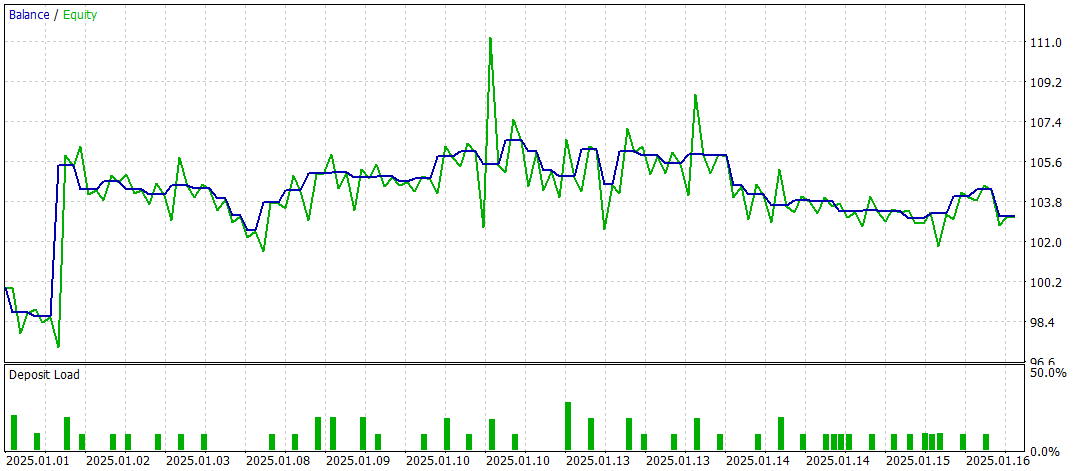
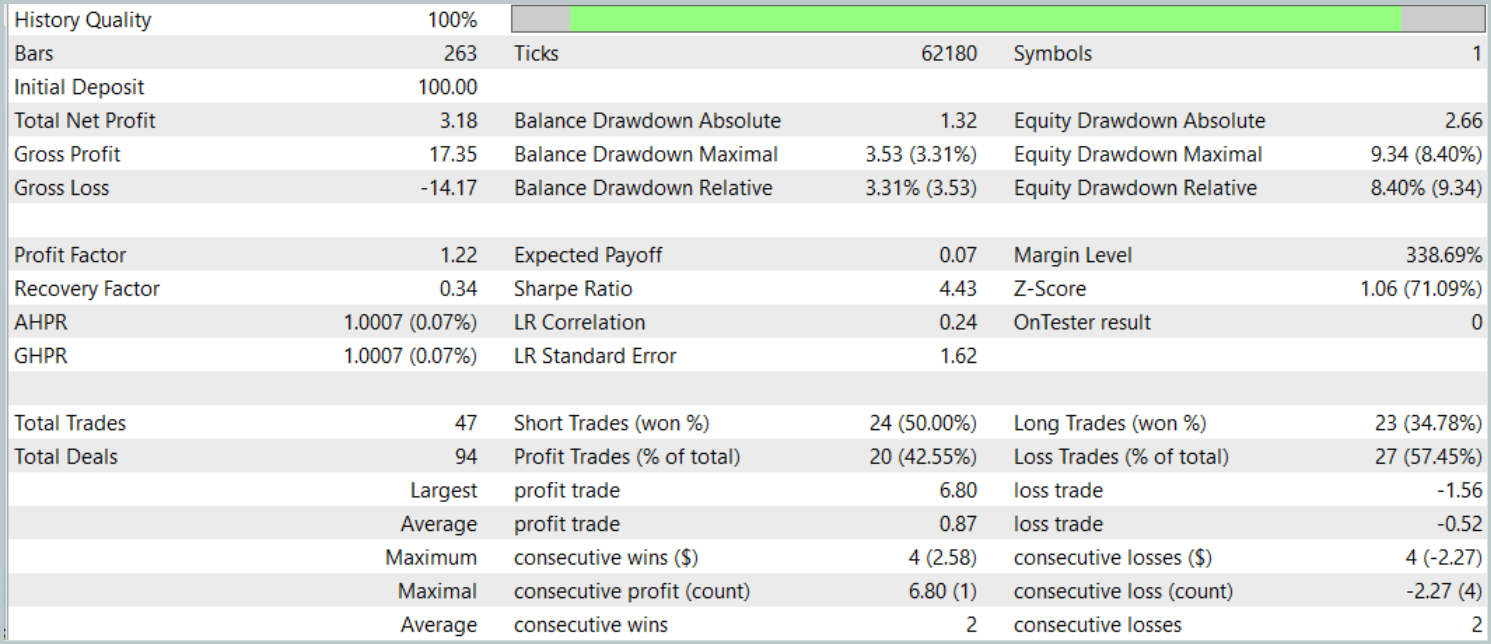
Результаты тестирования дают неоднозначное представление об эффективности модели. За период тестирования удалось получить прибыль, проведя 47 торговых операций, но только 42% из них оказались успешными. Более того, существенный прирост баланса был достигнут благодаря лишь одной успешной сделке, тогда как остальное время линия баланса оставалась в узком диапазоне. Это указывает на необходимость дальнейшей оптимизации модели.
Заключение
В данной статье мы рассмотрели основные компоненты и функциональные возможности фреймворка FinCon, а также его преимущества в автоматизации и оптимизации принятия торговых решений. В практической части были реализованы предложенные подходы средствами MQL5. Мы построили и обучили модель на реальных исторических данных. Однако, результаты тестирования показывают, что модель требует дальнейшей оптимизации для достижения более стабильных и высоких результатов.
Ссылки
- FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 От начального до среднего уровня: Переменные (I)
От начального до среднего уровня: Переменные (I)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования