
Neural Networks in Trading: A Multi-Agent System with Conceptual Reinforcement (Final Part)

Introduction
In the previous article, we explored the theoretical aspects of the FinCon framework, developed as a tool for analysis and automation in the financial domain. Its goal is to assist in decision-making in financial markets by leveraging big data processing, natural language processing (NLP), and portfolio management techniques. The core idea of the system lies in the use of a multi-agent architecture, where each module performs specific tasks while interacting with others to achieve shared objectives.
A key component of this architecture is the Manager Agent, which coordinates the work of Analyst Agents. The Manager aggregates the results produced by the analysts, performs risk control, and refines the investment strategy. FinCon employs specialized Analyst Agents, each responsible for different aspects of data processing and analysis, market forecasting, and risk evaluation. This division of labor reduces informational redundancy and accelerates data processing.
The framework implements a two-tier risk management architecture:
- The first level operates in real time, minimizing short-term losses.
- The second level evaluates system actions based on completed episodes, identifying errors and improving strategies.
One of FinCon's key features is the use of Conceptual Verbal Reinforcement Feedback (CVRF). This mechanism assesses both the performance of Analyst Agents and the trading decisions made by the Manager. It enables the system to learn from its own experience, refining its behavioral policies by focusing on the most influential market factors.
The framework also includes a three-tier memory system:
- Working memory temporarily stores data required for ongoing operations.
- Procedural memory retains proven methods and algorithms for reuse.
- Episodic memory records key events and their outcomes, allowing the system to analyze past experiences and apply lessons to future decisions.
The original visualization of the FinCon framework is provided below.

In the previous article, we began implementing our own interpretation of the approaches proposed by the framework authors. Within the object CNeuronMemoryDistil, we built algorithms for the three-layer memory system. Today, we continue this work.
The Analyst Agent Object
We begin by constructing the Analyst Agent module. The FinCon authors designed a universal agent module that can operate across diverse domains, independent of task specifics. This flexibility is achieved through an architecture built around a pre-trained large language model (LLM) functioning on a question–answer (QA) principle. The agent's behavior depends on the question or task it receives.
Although our models do not employ an LLM, we can still create a universal object adaptable for various specialized Analyst Agents. This approach ensures the system's flexibility and modularity.
According to the authors, FinCon agents integrate several key modules that together support their functionality.
Configuration and profiling module plays an important role in defining the types of tasks the agent tasks. It not only sets trading objectives, including details about economic sectors and performance metrics, but also distributes roles and responsibilities among agents. The module forms a foundational textual framework used to generate functional queries to the memory database.
Additionally, the configuration and profiling module enables agents to adapt to different economic sectors by identifying the most relevant metrics for each current task. The information it generates becomes the foundation for coherent interaction among all other system components.
The perception module manages the agent's interaction with its environment. It regulates the perception of market information by filtering data and identifying meaningful patterns. This allows the agent to adapt to changing conditions while maintaining accuracy and efficiency in its forecasts.
The memory module is a critical component, ensuring data storage and processing required for decision-making. It consists of three key parts: working memory, procedural memory, and episodic memory. Working memory enables the agent to perform ongoing tasks, monitor market changes, and adjust its actions. Procedural memory records all steps taken by the agent, including results and conclusions. Episodic memory stores data on completed tasks and contributes to forming long-term strategies.
In the previous work, we already developed the memory module and can now use that ready-made solution. Notably, the original FinCon framework granted access to episodic memory only to the Manager. In our implementation, however, all agents will utilize the three-tier memory structure. Each agent will have its own memory module, naturally limiting access to data relevant only to its specific tasks. This design allows each agent to consider not only recent changes but also their broader temporal context.
The configuration and profiling module's functionality assumes the presence of a dedicated external object that generates tasks according to each agent's specialization and available input data. In our implementation, we assume uniform input data. This means that with a fixed agent role, identical queries will be generated at each step. However, during model training, these queries can be adjusted to better align with the agent's current role and skills.
This reasoning leads us to the idea of creating a trainable query tensor within the agent module itself. This approach eliminates the need for an additional external information stream. The initial values of this tensor are randomly initialized during object creation. These parameters form the agent's "innate cognitive abilities". These serve as a unique foundation for its future learning.
As training progresses, the agent gradually develops a role that best matches its inherent capabilities defined at initialization. This allows the agent to organically adapt to its tasks while efficiently leveraging its "innate" characteristics, creating a strong basis for further development. The trainable query tensor becomes a key tool for identifying and reinforcing the most suitable developmental trajectory. This design ensures coherence between the agent's initial random state and its target role, reducing training costs and improving overall model efficiency.
The main goal of the perception module is to identify methods that extract the most relevant patterns from the data stream for the agent's tasks. To implement this functionality, we can use cross-attention mechanisms. These enable the model to "highlight" the most relevant information, ensuring effective filtering and data processing.
After constructing the agent's internal modules, the next important step is to analyze its output. A central question lies in the specificity of results. On one hand, such specificity depends on the agent's task, which seems to contradict the concept of a universal agent. On the other hand, diverse outputs complicate result processing, making standardization essential.
In our implementation, each agent produces a tensor representing a proposed trading decision as output. The original FinCon framework grants the Manager exclusive authority to generate trading decisions. However, there is no restriction on agents submitting their own proposals. This approach allows us to create a unified data structure for representing agent outputs, regardless of their specific roles. Such standardization simplifies result processing and enhances the overall system's efficiency.
All of the above concepts are implemented within the CNeuronFinConAgent object. Its structure is presented below.
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In the presented structure, we can observe a familiar set of overridable methods, as well as several objects that will be used to organize the approaches described above. We will examine the specific purpose of each of these components as we proceed with implementing the algorithms for the object methods.
It is also important to note that the cross-attention object is used as the parent class. The inherited methods and objects from this class will likewise be utilized to organize the operation of the module we are creating.
All internal objects are declared as static, simplifying the class structure and allowing both the constructor and destructor to remain empty. The initialization of internal and inherited objects is handled within the Init method. This method takes a set of constants that clearly and unambiguously define the architecture of the object being created.
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
Within the body of the method, we (as always) begin by calling the parent class method of the same name, which already organizes the initialization of inherited objects and the interfaces for data exchange with external components.
As mentioned earlier, the cross-attention object was chosen as the parent class. Such objects are designed to process two data streams, which may seem questionable in the context of FinCon agents, as they initially operate with a single information stream specific to their assigned task. However, agents also receive data from the memory module. This introduces a second data stream. Moreover, a critical aspect of an agent's operation is its sequential analysis - its ability to reflect on its own actions and make adjustments in response to changing market conditions. This reflective process effectively creates a third stream of information.
In our implementation, the reflection functionality will be organized using mechanisms inherited from the parent class. The cross-attention approach is expected to be effective for adjusting the tensor of previous results in the context of evolving market conditions. Thus, the parent object's primary data stream will consist of the result tensor parameters, while the second stream will contain information about the current environmental state.
Recall that at the agent’s output, we expect a tensor of recommended trading operations.
Next, we initialize two attention modules. These modules separately store the dynamics of market conditions and the sequence of trading decisions proposed by the agent. This structure allows us to better assess the effectiveness of the behavioral policy being applied within the context of the current market dynamics.
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
The profiling module is constructed from two sequential fully connected layers. The first layer contains a single element with a fixed value of 1, while the second layer generates a tensor of a specified size. In our implementation, the length of the generated vector is ten times greater than that of a single element's description in the input sequence. This can be interpreted as representing the agent's role through a ten-element sequence.
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
The perception module, as previously discussed, is represented by an internal cross-attention object. It analyzes the received input data in the context of the agent specialization.
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
After successfully initializing all internal and inherited objects, we return a logical result to the calling program and complete the method execution.
The next stage of development involves implementing the feed-forward pass algorithm within the feedForward method. Here, we must organize the information flow between the objects initialized earlier.
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
The method parameters include a pointer to the input data object, which contains descriptions of the environmental state. It is important to recall that each agent analyzes incoming information according to its specific role. Therefore, we first generate a tensor describing the assigned task.
Note that the agent role tensor is generated only during training. In testing and production modes, the agent's specialization remains constant, and regenerating this tensor on each iteration is unnecessary.
Next, we use the internal cross-attention object to extract patterns relevant to solving the agent's assigned task.
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
The obtained values are then passed to the environment state memory module, enriching the current state with information about preceding market dynamics. This approach provides a deeper contextual understanding.
Similarly, we add the results from the previous feedforward pass to the agent action memory module.
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
As a result, the two memory modules output tensors describing the agent's most recent actions and the corresponding environmental changes. These data are passed to the parent class method of the same name, which adjusts the tensor of recommended trading operations in light of current market dynamics.
Before this step, however, it is necessary to swap the pointers to the data buffers, thereby preserving the previous result tensor. This ensures the correct execution of backpropagation operations during model training.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
The logical result of these operations is returned to the calling program, and the method concludes.
After completing the feedforward algorithm, we proceed to organize the information flow for the backpropagation pass. As is well known, during gradient propagation, the data flow mirrors the structure of the feedforward phase but moves in the opposite direction. Thanks to the identical routing of the forward and backward passes, the model can efficiently account for the influence of each parameter on the final result.
The gradient distribution operations are implemented in the calcInputGradients method. This method receives a pointer to the input data object, but this time we must pass error gradient values reflecting the influence of the input data on the model's final outcome.
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Within the method, we first check the validity of the received pointer, since if it is invalid, further operations are meaningless.
The actual gradient distribution process begins with a call to the parent class method having the same name. It propagates the error gradients to the attention modules.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
Through the trading operation proposal memory module, we then pass the error gradient back to our current object. Because its previous feedforward results were used as input for that memory module. However, the result buffer now contains different values obtained from the latest feedforward operation. Moreover, we want to preserve the current values of the gradient buffer. To achieve this, we first restore the results of the previous feedforward pass by swapping the result buffer pointers. Next, we substitute the gradient buffer pointer with a free data buffer. Only after completing this preparatory work do we proceed to distribute the error gradients.
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
It is important to note that we do not recursively propagate gradients to earlier passes. Therefore, the gradient obtained from these operations is not reused. Nonetheless, these steps are necessary to ensure proper distribution of gradients among the internal objects of the memory module. After completing these actions, we restore the original buffer pointers.
We then distribute the error gradient along the environment state memory module pipeline. Here, the gradient is first propagated to the perception module, which, as noted earlier, is implemented using a cross-attention block.
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
Then we distribute the obtained error gradients between the input data and the MLP responsible for generating the agent role tensor, according to their respective influence on the model's performance.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
We do not propagate gradients through the MLP that generates the agent role tensor, since its first layer contains a fixed value.
After completing all required operations, the method returns a logical success flag to the calling program and terminates execution.
This concludes our examination of the algorithms used to construct the methods of the universal Analyst Agent object. You can find the complete code of this class and all its methods in the attachment.
The Manager Object
The next stage of our work involves constructing the Manager Agent object. Here, a slight conceptual dissonance arises. On the one hand, we have discussed building a universal agent that can also function as a manager. On the other hand, the manager's role is to consolidate results and coordinate the actions of all agents. This means it must receive information from multiple sources.
The following implementation can be viewed in different ways. For example, as an adaptation of the previously built universal agent to perform managerial functions. Indeed, the universal agent class serves here as the parent class for the new object - its structure is presented below.
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
To minimize external data flows, we integrated all agents within the manager object itself. In this configuration, the manager can be perceived as a self-contained FinCon framework. However, that is more a matter of interpretation. Let's focus on developing the functional capabilities of this new object.
In the structure of the new object, we again see a familiar set of overridable methods and several internal objects, whose roles we will explore while designing the algorithms for the class methods.
All internal objects are declared as static, allowing us to keep the class constructor and destructor empty. Initialization of all declared and inherited objects is performed in the Init method.
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
In the method body, as usual, we call the relevant method of the parent class. But in this case there is a nuance. The initial data for the manager are the results of the agents' work. Therefore, the input window for the manager corresponds to the dimension of a single agent's result vector, while the sequence length equals the total number of internal agents, including the risk assessment agent.
It should be noted that our manager works with two types of Analyst Agents. each analyzing the current environment from different perspectives. To obtain the second projection of input data, we employ a matrix transposition object.
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Next, we organize two consecutive initialization loops for the Analyst Agents.
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
Then we add a Risk Control Agent. Its inputs are represented by a vector describing the current account state, and this is explicitly specified in the initialization parameters.
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
Additionally, we require an object to concatenate the results from all internal agents. This combined output will then serve as input for the Manager Agent, whose functionality we inherit from the parent class.
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
It is worth emphasizing that the account state information is obtained through an auxiliary data stream, represented by a dedicated data buffer. However, for proper functioning of the initialized Risk Control Agent, a neural layer object containing this input data is required. Therefore, we create an internal object to which the information from the secondary data stream is transferred.
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
After completing all required operations, the method returns a logical success flag to the calling program and terminates execution.
We now proceed to construct the feed-forward algorithm within the feedForward method. In this case, we are working with two input data streams. The primary stream provides a tensor describing the analyzed environmental state, while the secondary stream carries the financial results of the model’s operation in the form of an account state vector.
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
Inside the method, we first perform a brief preprocessing step, during which the result buffer pointer of the secondary input data object (account state) is replaced with the corresponding buffer from the appropriate data stream. We also transpose the tensor of input data from the primary stream.
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
After completing these preparatory steps, we pass the resulting data to the Analyst Agents for analysis and proposal generation.
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
The outputs of the agents are then concatenated into a single object.
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
The concatenated results are then passed to the Manager, responsible for making the final trading decision based on all agents' recommendations.
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
The logical result is returned to the calling program.
This completes our discussion of the algorithms used to construct the Manager methods. The backpropagation methods are left for independent study. The full implementation of the class and all its methods can be found in the attached materials.
Model Architecture
A few words should be said about the architecture of the trainable model. In preparing this article, only a single model was trained, the Trading Decision Agent. This should not be confused with the agents of the FinCon framework itself.
The architecture of the trained model was carried over almost unchanged from previous works dedicated to the FinAgent method. Only one neural layer was replaced, enabling integration of the approaches implemented in the FinCon framework.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
The complete model architecture code is included in the attachment. It also contains programs used for training and testing. Since these scripts were transferred without modification from earlier works, we will not analyze them in detail here.
Testing
The last two articles have been devoted to the FinCon framework, in which we examined its core principles in depth. Our interpretation of the framework methods was implemented in MQL5, and it is now time to assess the effectiveness of these implementations on real historical data.
It should be noted that the implementation presented here differs significantly from the original one, which naturally affects the results. Therefore, we can speak only about evaluating the efficiency of the implemented approaches, not about reproducing the original results.
For model training, we used H1 EURUSD data from 2024. The parameters of the analyzed indicators were left unchanged to focus exclusively on evaluating the algorithmic performance.
The training dataset was formed from multiple runs of several models with randomly initialized parameters. In addition, we included successful runs derived from available market signal data using the Real-ORL method. This enriched the dataset with positive examples and expanded the coverage of possible market scenarios.
During training, we used an algorithm that generates "near-perfect" target actions for the Agent. This enables model training without the need for continuous dataset updates. However, we recommend periodic data updates, which can further improve learning outcomes by expanding state-space coverage.
The final testing was conducted using available data from January 2025, with all other parameters unchanged. The results are presented below.
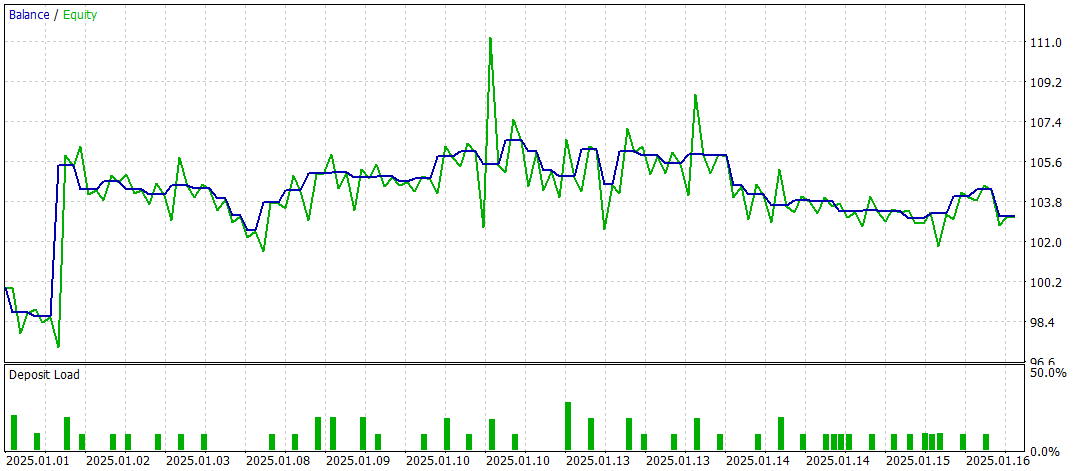
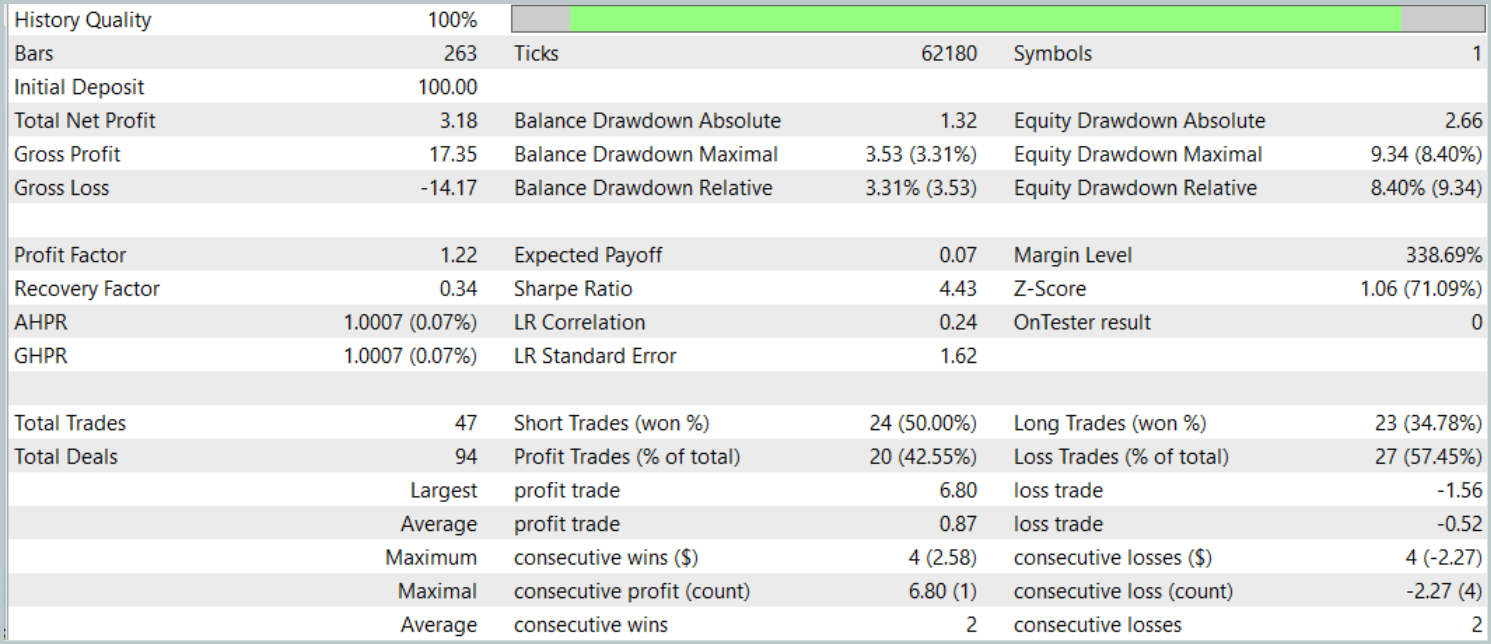
The test results offer a mixed assessment of the model's effectiveness. During the testing period, the model achieved a profit across 47 trading operations, but only 42% of those trades were successful. Moreover, most of the balance growth resulted from a single profitable trade, while the balance curve remained in a narrow range for the rest of the time. This suggests that the model requires further optimization.
Conclusion
In this article, we examined the main components and functional capabilities of the FinCon framework, as well as its advantages in automating and optimizing trading decision-making. In the practical section, we implemented the proposed methods in MQL5. We built and trained a model using real historical data, and evaluated its performance. The testing results, however, indicate that, while the model demonstrates potential, it still requires further refinement and optimization to achieve more stable and consistently high performance.
References
- FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- Other articles from this series
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor for collecting samples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor for collecting samples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Model training EA |
| 4 | Test.mq5 | Expert Advisor | Model Testing Expert Advisor |
| 5 | Trajectory.mqh | Class library | System state and model architecture description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code library | OpenCL program code |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/16937
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use