
Klassische Strategien neu interpretieren (Teil X): Kann KI den MACD verbessern?

Die sich kreuzenden gleitende Durchschnitte ist wahrscheinlich eine der ältesten existierenden Handelsstrategie. Der MACD (Moving Average Convergence Divergence) ist ein sehr beliebter Indikator, der auf dem Konzept sich kreuzender gleitende Durchschnitte basiert. Es gibt viele neue Mitglieder unserer Gemeinschaft, die sich für die Vorhersagekraft des MACD-Indikators interessieren, um die bestmögliche Handelsstrategie zu entwickeln. Darüber hinaus gibt es erfahrene technische Analysten, die den MACD in ihren Strategien verwenden und sich vielleicht die gleiche Frage stellen. In diesem Artikel finden Sie eine empirische Analyse der Vorhersagekraft des Indikators für das Währungspaar EURUSD. Darüber hinaus vermitteln wir Ihnen Modellierungstechniken, mit denen Sie Ihre technische Analyse durch KI verbessern können.
Überblick über die Handelsstrategie
Der MACD-Indikator wird in erster Linie verwendet, um Markttrends zu erkennen und die Trenddynamik zu messen. Der Indikator wurde in den 1970er Jahren von dem bereits verstorbenen Gerrald Appel entwickelt. Appel war ein Vermögensverwalter für seine Privatkunden, und sein Erfolg beruhte auf seinem Handelsansatz der technischen Analyse. Er erfand den MACD-Indikator vor etwa 50 Jahren.

Abb. 1: Gerald Appel, der Erfinder des MACD-Indikators
Technische Analysten verwenden den Indikator, um auf verschiedene Weise Ein- und Ausstiegspunkte zu identifizieren. Abb. 2 zeigt einen Screenshot des MACD-Indikators, der mit den Standardeinstellungen auf das Paar GBPUSD angewendet wird. Der Indikator ist standardmäßig in Ihrer Installation von MetaTrader 5 enthalten. Die rote Linie, der so genannte MACD-Hauptteil, wird aus der Differenz zwischen zwei gleitenden Durchschnitten, einem schnellen und einem langsamen, berechnet. Wenn die Hauptlinie unter 0 kreuzt, befindet sich der Markt höchstwahrscheinlich in einem Abwärtstrend, und das Gegenteil ist der Fall, wenn die Linie über 0 kreuzt.
Ebenso kann auch die Hauptlinie selbst zur Ermittlung der Marktstärke herangezogen werden. Nur ein steigendes Preisniveau führt zu einer Erhöhung des Wertes der Hauptlinie, und umgekehrt führt ein sinkendes Preisniveau zu einem Rückgang der Hauptlinie. Die Wendepunkte, an denen die Hauptlinie die Form einer Tasse annimmt, werden also durch eine Verschiebung der Marktdynamik verursacht. Um den MACD herum sind verschiedene Handelsstrategien entwickelt worden. Komplexere und ausgefeiltere Strategien versuchen, MACD-Divergenzen zu erkennen.
MACD-Divergenzen treten auf, wenn sich die Kurse in einem starken Trend erholen und neue Extremwerte erreichen. Andererseits befindet sich der MACD-Indikator in einem Trend, der nur noch flacher wird und in scharfem Kontrast zu den starken Kursbewegungen auf dem Chart zu fallen beginnt. In der Regel wird die MACD-Divergenz als frühzeitige Warnung vor einer Trendumkehr interpretiert, die es Händlern ermöglicht, ihre offenen Positionen zurückzunehmen, bevor die Märkte volatiler werden.
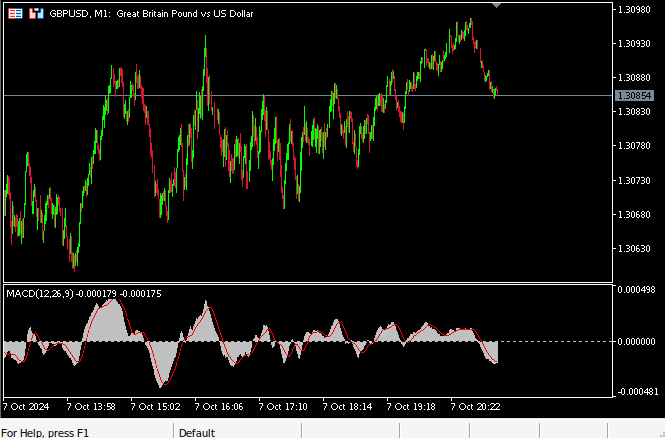
Abb. 2: Der MACD-Indikator mit seinen Standardeinstellungen auf dem M1-Chart des GBPUSD
Es gibt viele Skeptiker, die die Verwendung des MACD-Indikators insgesamt in Frage stellen. Lassen Sie uns damit beginnen, den Elefanten im Raum anzusprechen. Alle technischen Indikatoren sind der Gruppe von nachlaufende Indikatoren zugehörig. Das bedeutet, dass sich die technischen Indikatoren nur ändern, wenn sich die Preisniveaus ändern, sie können sich nicht vor den Preisniveaus ändern. Makroökonomische Indikatoren wie das weltweite Inflationsniveau und geopolitische Nachrichten wie der Ausbruch eines Krieges oder einer Naturkatastrophe können die Angebots- und Nachfrageniveaus ausgleichen. Sie gelten als Frühindikatoren, weil sie sich schnell ändern können, bevor die Preisniveaus diese Änderung widerspiegeln.
Viele Händler sind der Meinung, dass diese verzögerten Signale die Händler höchstwahrscheinlich dazu veranlassen werden, ihre Positionen erst dann einzugehen, wenn die Marktbewegung bereits erschöpft ist. Darüber hinaus ist es üblich, Trendumkehrungen zu beobachten, denen keine MACD-Divergenzen vorausgegangen sind. Im gleichen Sinne kann auch eine MACD-Divergenz beobachtet werden, auf die keine Trendumkehr folgt.
Diese Tatsachen werfen die Frage auf, wie zuverlässig der Indikator ist und ob er wirklich eine nennenswerte Vorhersagekraft hat. Wir wollen prüfen, ob es möglich ist, die dem Indikator innewohnende Verzögerung mit Hilfe von KI zu überwinden. Wenn sich der MACD-Indikator als belastbar erweist, werden wir ein KI-Modell integrieren, das entweder:
- Verwendet die Indikatorwerte zur Prognose zukünftiger Preisniveaus.
- Prognostiziert den MACD-Indikator selbst.
Je nachdem, welcher Modellierungsansatz einen geringeren Fehler ergibt. Andernfalls, wenn unsere Analyse ergibt, dass der MACD im Rahmen unserer derzeitigen Strategie keine Vorhersagekraft besitzt, werden wir uns bei der Vorhersage der Kursniveaus für das Modell mit der besten Leistung entscheiden.
Überblick über die Methodik
Unsere Analyse begann mit einem angepassten Skript, das in MQL5 geschrieben wurde, um genau 100 000 M1-Marktnotierungen für den EURUSD und die entsprechenden MACD-Signal- und Hauptwerte in eine CSV-Datei zu übertragen. Nach unseren Datenvisualisierungen zu urteilen, scheint der MACD-Indikator ein schlechter Indikator für zukünftige Kursniveaus zu sein. Die Änderungen des Preisniveaus sind höchstwahrscheinlich unabhängig vom Wert des Indikators, außerdem haben die Daten durch die Berechnung des Indikators eine nichtlineare und komplexe Struktur, die schwierig zu modellieren sein kann.
Die Daten, die wir von unserem MetaTrader 5 Terminal erhalten haben, wurden in 2 Hälften aufgeteilt. Wir haben die erste Hälfte verwendet, um die Genauigkeit unseres Modells mithilfe einer 5-fachen Kreuzvalidierung zu schätzen. Anschließend erstellten wir 3 identische Deep Neural Network-Modelle und trainierten sie auf 3 verschiedenen Teilmengen unserer Daten:
- Preismodell: Prognostizieren von Preisniveaus mit OHLC-Marktkursen aus MetaTrader 5
- MACD-Modell: Prognostizieren der Werte des MACD-Indikators anhand von OHLC-Kursen und dem MACD-Wert
- Vollständiges Modell: Vorhersage von Kursniveaus anhand von OHLC-Kursen und dem MACD-Indikator
Die zweite Hälfte der Partition wurde zum Testen der Modelle verwendet. Das erste Modell erzielte mit 69 % die höchste Genauigkeit im Test. Unsere Algorithmen zur Auswahl von Merkmalen legten nahe, dass die Marktkurse, die wir aus dem MetaTrader 5 bezogen, informativer waren als die MACD-Werte.
So begannen wir mit der Optimierung des besten Modells, das uns zur Verfügung stand: ein Regressionsmodell, das den zukünftigen Kurs des EURUSD-Paares vorhersagt. Wir sind jedoch schnell auf Probleme gestoßen, weil wir das Rauschen in unseren Trainingsdaten gelernt haben. Es ist uns nicht gelungen, eine einfache lineare Regression in der Testgruppe zu übertreffen. Daher haben wir das überoptimierte Modell durch eine Support Vector Machine (SVM) ersetzt.
Anschließend exportierten wir unser SVM-Modell in das ONNX-Format und erstellten einen Expert Advisor, der einen kombinierten Ansatz zur Vorhersage künftiger EURUSD-Kurse und des MACD-Indikators verwendet.
Abrufen der benötigten Daten
Um den Ball ins Rollen zu bringen, war unsere erste Station die integrierte Entwicklungsumgebung (IDE) MetaEditor. Wir haben das nachstehende Skript erstellt, um unsere Marktdaten vom MetaTrader 5-Terminal abzurufen. Wir haben 100 000 Zeilen historischer M1-Daten angefordert und in das CSV-Format exportiert. Das folgende Skript füllt unsere CSV-Datei mit den Werten für Time, Open, High, Low, Close und den 2 MACD. Ziehen Sie das Skript einfach per Drag & Drop auf ein beliebiges Paar, das Sie analysieren möchten, wenn Sie uns folgen wollen.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int indicator_handler; double indicator_buffer[]; double indicator_buffer_2[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator indicator_handler = iMACD(Symbol(),PERIOD_CURRENT,12,26,9,PRICE_CLOSE); CopyBuffer(indicator_handler,0,0,size,indicator_buffer); CopyBuffer(indicator_handler,1,0,size,indicator_buffer_2); ArraySetAsSeries(indicator_buffer,true); ArraySetAsSeries(indicator_buffer_2,true); //--- File name string file_name = "Market Data " + Symbol() +" MACD " + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MACD Main","MACD Signal"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), indicator_buffer[i], indicator_buffer_2[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Vorverarbeitung von Daten
Nachdem wir unsere Daten in das CSV-Format exportiert haben, können wir die Daten nun in unseren Python-Arbeitsbereich einlesen. Zuerst laden wir die benötigten Bibliotheken.
#Load libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Wir lesen die Daten ein
#Read in the data data = pd.read_csv("Market Data EURUSD MACD .csv")
und legen fest, wie weit wir in die Zukunft vorausschauen sollen.
#Forecast horizon look_ahead = 20
Fügen wir jetzt binäre Ziele hinzu, die anzeigen, ob der aktuelle Messwert größer ist als die 20 vorangegangenen, sowohl für den EURUSD-Schlusskurs als auch für die MACD-Hauptlinie.
#Let's add labels data["Bull Bear"] = np.where(data["Close"] < data["Close"].shift(look_ahead),0,1) data["MACD Bull"] = np.where(data["MACD Main"] < data["MACD Main"].shift(look_ahead),0,1) data = data.loc[20:,:] data
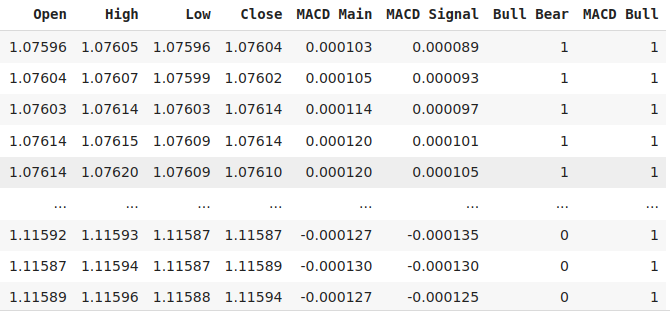
Abb. 3: Einige der Spalten in unserem Datenrahmen
Außerdem müssen wir unsere Zielwerte festlegen.
data["MACD Target"] = data["MACD Main"].shift(-look_ahead) data["Price Target"] = data["Close"].shift(-look_ahead) data["MACD Binary Target"] = np.where(data["MACD Main"] < data["MACD Target"],1,0) data["Price Binary Target"] = np.where(data["Close"] < data["Price Target"],1,0) data = data.iloc[:-20,:]
Explorative Datenanalyse
Streudiagramme helfen uns, die Beziehung zwischen einer abhängigen und einer unabhängigen Variable zu visualisieren. Die nachstehende Grafik zeigt, dass es definitiv eine Beziehung zwischen zukünftigen Kursniveaus und dem aktuellen MACD-Wert gibt. Die Herausforderung besteht darin, dass die Beziehung nicht linear ist und eine komplexe Struktur zu haben scheint. Es ist nicht sofort ersichtlich, welche Veränderungen des MACD-Indikators zu einer steigenden oder fallenden Kursentwicklung führen.
sns.scatterplot(data=data,x="MACD Main",y="MACD Signal",hue="Price Binary Target")
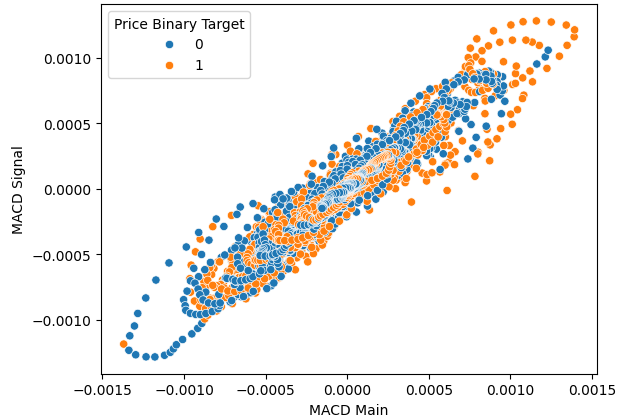
Abb. 4: Visualisierung der Beziehung zwischen dem MACD-Indikator und den Kursniveaus
Eine 3D-Darstellung macht nur noch deutlicher, wie verworren die Beziehung wirklich ist. Es gibt keine definierten Grenzen, sodass wir erwarten, dass die Daten schwer zu klassifizieren sein werden. Die einzigen intelligenten Schlussfolgerungen, die wir aus unserem Diagramm ziehen können, sind, dass sich die Märkte nach dem Durchschreiten extremer Niveaus auf dem MACD schnell wieder in der Mitte zu sammeln scheinen.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["MACD Main"],data["MACD Signal"],data["Close"],c=data["Price Binary Target"]) ax.set_xlabel("MACD Main") ax.set_ylabel("MACD Signal") ax.set_zlabel("EURUSD Close")
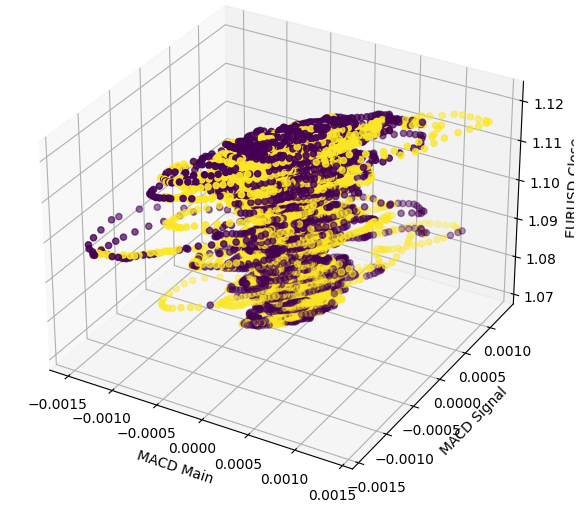
Abb. 5: Visualisierung der Interaktion zwischen dem MACD-Indikator und dem EURUSD-Markt
Mit Hilfe von Violinplots können wir gleichzeitig die Verteilung von Daten visualisieren und zwei Verteilungen vergleichen. Der blaue Umriss stellt eine Zusammenfassung der beobachteten Verteilung zukünftiger Kursniveaus dar, nachdem der MACD angestiegen oder gefallen ist. In der folgenden Abbildung 6 wollten wir herausfinden, ob das Steigen oder Fallen des MACD-Indikators mit unterschiedlichen Verteilungen in Bezug auf künftige Kursbewegungen verbunden ist. Wie wir sehen können, sind die beiden Verteilungen fast identisch. Darüber hinaus hat der Kern jeder Verteilung ein Boxplot. Die Mittelwerte beider Boxplots sind nahezu identisch, unabhängig davon, ob sich der Indikator in einer Hausse- oder Baisse-Phase befindet.
sns.violinplot(data=data,x="MACD Bull",y="Close",hue="Price Binary Target",split=True,fill=False)
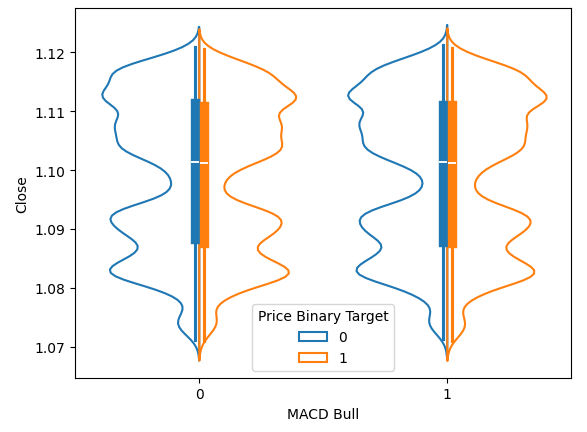
Abb. 6: Die Visualisierung der Auswirkungen des MACD-Indikators auf künftige Kursniveaus
Vorbereiten der Datenmodellierung
Beginnen wir nun mit der Modellierung unserer Daten. Zuallererst müssen wir unsere Bibliotheken importieren.
#Perform train test splits from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.metrics import accuracy_score train,test = train_test_split(data,test_size=0.5,shuffle=False)
Jetzt werden wir die Prädiktoren und das Ziel definieren.
#Let's scale the data ohlc_predictors = ["Open","High","Low","Close","Bull Bear"] macd_predictors = ["MACD Main","MACD Signal","MACD Bull"] all_predictors = ohlc_predictors + macd_predictors cv_predictors = [ohlc_predictors,macd_predictors,all_predictors] #Define the targets cv_targets = ["MACD Binary Target","Price Binary Target","All"]
Skalierung der Daten.
#Scaling the data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train[all_predictors])
train_scaled = pd.DataFrame(scaler.transform(train[all_predictors]),columns=all_predictors)
test_scaled = pd.DataFrame(scaler.transform(test[all_predictors]),columns=all_predictors) Laden wir die benötigten Bibliotheken
#Import the models we will evaluate
from sklearn.neural_network import MLPClassifier,MLPRegressor
from sklearn.linear_model import LinearRegression und jetzt erstellen wir das geteilte Zeitreihenobjekt.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) Die Indizes unseres Datenrahmens werden auf den Satz von Eingaben abgebildet, die wir ausgewertet haben.
err_indexes = ["MACD Train","Price Train","All Train","MACD Test","Price Test","All Test"]
Nun werden wir den Datenrahmen erstellen, der unsere Schätzungen der Genauigkeit des Modells aufzeichnet, wenn wir unsere Eingaben ändern.
#Now let us define a table to store our error levels columns = ["Model Accuracy"] cv_err = pd.DataFrame(columns=columns,index=err_indexes)
Wir setzen alle unsere Indizes zurück
#Reset index
train = train.reset_index(drop=True)
test = test.reset_index(drop=True) und führe eine Kreuzvalidierung des Modells durch. Wir machen das auf der Trainingsmenge, um dann seine Genauigkeit auf der Testmenge zu erfassen, ohne es an die Testmenge anzupassen.
#Initailize the model price_model = MLPClassifier(hidden_layer_sizes=(10,6)) macd_model = MLPClassifier(hidden_layer_sizes=(10,6)) all_model = MLPClassifier(hidden_layer_sizes=(10,6)) price_acc = [] macd_acc = [] all_acc = [] #Cross validate each model twice for j,(train_index,test_index) in enumerate(tscv.split(train_scaled)): #Fit the models price_model.fit(train_scaled.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Binary Target"]) macd_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"MACD Binary Target"]) all_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"Price Binary Target"]) #Store the accuracy price_acc.append(accuracy_score(train.loc[test_index,"Price Binary Target"],price_model.predict(train_scaled.loc[test_index,ohlc_predictors]))) macd_acc.append(accuracy_score(train.loc[test_index,cv_targets[0]],macd_model.predict(train_scaled.loc[test_index,all_predictors]))) all_acc.append(accuracy_score(train.loc[test_index,cv_targets[1]],all_model.predict(train_scaled.loc[test_index,all_predictors]))) #Now we can store our estimates of the model's error cv_err.iloc[0,0] = np.mean(price_acc) cv_err.iloc[1,0] = np.mean(macd_acc) cv_err.iloc[2,0] = np.mean(all_acc) #Estimating test error cv_err.iloc[3,0] = accuracy_score(test[cv_targets[1]],price_model.predict(test_scaled[ohlc_predictors])) cv_err.iloc[4,0] = accuracy_score(test[cv_targets[0]],macd_model.predict(test_scaled[all_predictors])) cv_err.iloc[5,0] = accuracy_score(test[cv_targets[1]],all_model.predict(test_scaled[all_predictors]))
| Eingabe Gruppe | Modell-Genauigkeit |
|---|---|
| MACD Train | 0.507129 |
| OHLC Train | 0.690267 |
| All Train | 0.504577 |
| MACD Test | 0.48669 |
| OHLC Test | 0.684069 |
| Alle Tests | 0.487442 |
Die Bedeutung der Merkmale
Versuchen wir nun, die Wichtigkeit der Merkmale für unser tiefes neuronales Netz zu schätzen. Wir werden die Bedeutung der Permutation für die Interpretation unseres Modells wählen. Die Permutationsbedeutung definiert die Bedeutung jeder Eingabe, indem zunächst die Werte dieser Eingabespalte gemischt werden und dann die Änderungen der Modellgenauigkeit bewertet werden. Der Gedanke dahinter ist, dass wichtige Merkmale einen starken Rückgang des Fehlers bewirken, während unwichtige Merkmale Änderungen in der Genauigkeit des Modells verursachen, die nahe bei 0 liegen.
Es sind jedoch einige Überlegungen anzustellen. Zunächst mischt der Permutations-Bedeutungs-Algorithmus die einzelnen Eingaben des Modells nach dem Zufallsprinzip. Das bedeutet, dass der Algorithmus den Eröffnungskurs nach dem Zufallsprinzip mischen und ihn höher als den Höchstkurs setzen kann. Dies ist in der realen Welt natürlich nicht möglich. Daher sollten wir die Ergebnisse des Algorithmus mit Vorsicht interpretieren. Man könnte sagen, dass der Algorithmus voreingenommen ist, weil er die Bedeutung von Merkmalen unter simulierten Bedingungen bewertet, die möglicherweise nie eintreten werden, wodurch das Modell unnötig benachteiligt wird. Aufgrund der stochastischen Natur der Optimierungsalgorithmen, die zur Anpassung moderner neuronaler Netze verwendet werden, kann das Training derselben neuronalen Netze mit demselben Datensatz jedes Mal zu bemerkenswert unterschiedlichen Erklärungen führen.
#Let us try assess feature importance from sklearn.inspection import permutation_importance from sklearn.linear_model import RidgeClassifier
Wir werden nun unser Permutations-Bedeutungsobjekt an unser trainiertes tiefes neuronales Netzwerkmodell anpassen. Sie haben die Möglichkeit, die zu mischenden Trainings- oder Testdaten zu übergeben. Wir haben uns für die Testdaten entschieden. Anschließend ordneten wir die Daten nach der Reihenfolge des verursachten Genauigkeitsverlusts und stellten die Ergebnisse grafisch dar. Abb. 7 zeigt die beobachteten Werte für die Wichtigkeit von Permutationen. Wir können sehen, dass die Auswirkungen des Umschichtens der Eingaben in Bezug auf den MACD sehr nahe bei 0 liegen, was bedeutet, dass die MACD-Spalten nicht so wichtig für unser Modell sind.
#Let us fit the model model = MLPClassifier(hidden_layer_sizes=(10,6)) model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"]) #Calculate permutation importance scores pi = permutation_importance( model, test_scaled.loc[:,all_predictors], test.loc[:,"Price Binary Target"], n_repeats=10, random_state=42, n_jobs=-1 ) #Sort the importance scores sorted_importances_idx = pi.importances_mean.argsort() importances = pd.DataFrame( pi.importances[sorted_importances_idx].T, columns=test_scaled.columns[sorted_importances_idx], ) #Create the plot ax = importances.plot.box(vert=False, whis=10) ax.set_title("Permutation Importances (test set)") ax.axvline(x=0, color="k", linestyle="--") ax.set_xlabel("Decrease in accuracy score") ax.figure.tight_layout()

Abb. 7: Unsere Permutationsbewertung ergab, dass der Schlusskurs das wichtigste Merkmal ist.
Die Anpassung eines einfacheren Modells könnte uns auch Aufschluss über die Bedeutung der Inputs geben. Der Ridge Classifier ist ein lineares Modell, das seine Koeffizienten in der Richtung, in der es seinen Fehler minimiert, immer näher an 0 heranschiebt. Unter der Annahme, dass Ihre Daten standardisiert und skaliert wurden, haben unwichtige Merkmale daher die kleinsten Ridge-Koeffizienten. Falls es Sie interessiert: Der Ridge-Klassifikator kann dies erreichen, indem er das gewöhnliche lineare Modell um einen Strafterm erweitert, der proportional zur quadrierten Summe der Modellkoeffizienten ist. Dies ist allgemein als L2-Regularisierung bekannt.
#Let us fit the model model = RidgeClassifier() model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"])
Nun wollen wir die Koeffizienten des Modells aufzeichnen.
ridge_importance = pd.DataFrame(model.coef_.tolist(),columns=all_predictors) #Prepare the plot fig,ax = plt.subplots(figsize=(10,5)) sns.barplot(ridge_importance,ax=ax)
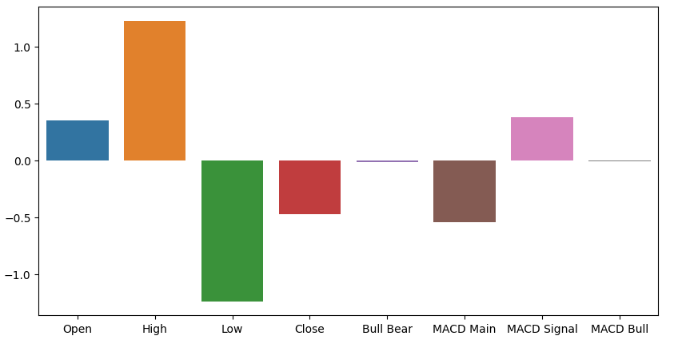
Abb. 8: Unsere Ridge-Koeffizienten deuten darauf hin, dass der hohe und der niedrige Preis die informativsten Merkmale sind, die wir haben
Einstellen der Parameter
Nun werden wir versuchen, unser leistungsstärkstes Modell zu optimieren. Doch wie wir bereits festgestellt haben, war unsere Optimierungsroutine in diesem Zug nicht erfolgreich. Leider liegt dies in der Natur von Optimierungsalgorithmen, wir haben keine Garantie, Lösungen zu finden. Die Optimierung der Parameter bedeutet nicht zwangsläufig, dass das Modell, das Sie am Ende erhalten, besser ist; wir versuchen lediglich, uns den optimalen Modellparametern zu nähern. Laden wir die benötigten Bibliotheken
#Let's tune our model further from sklearn.model_selection import RandomizedSearchCV
Definition des Modells.
#Reinitialize the model model = MLPRegressor(max_iter=200)
Jetzt werden wir das Tuner-Objekt definieren. Das Objekt bewertet unser Modell unter verschiedenen Initialisierungsparametern und gibt ein Objekt zurück, das die besten gefundenen Eingaben enthält.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation" : ["relu","logistic","tanh","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"learning_rate":['constant','adaptive','invscaling'],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"hidden_layer_sizes":[(2,4,8,2),(10,20),(5,10),(2,20),(6,8,10),(1,5),(20,10),(8,4),(2,4,8),(10,5)],
"early_stopping":[True,False],
"warm_start":[True,False],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) Anpassen des „Tuner“-Objekts.
tuner.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) Die besten Parameter, die wir gefunden haben.
tuner.best_params_
'tol': 0.01,
'solver': 'sgd',
'shuffle': False,
'learning_rate_init': 0.01,
'learning_rate': 'constant',
'hidden_layer_sizes': (20, 10),
'early_stopping': True,
'alpha': 1e-07,
'activation': 'identity'}
Tiefergehende Optimierung
Mit Hilfe der SciPy-Bibliothek können wir noch tiefer nach besseren Eingabeeinstellungen suchen. Wir werden die Bibliothek verwenden, um die Ergebnisse der globalen Optimierung der kontinuierlichen Parameter des Modells zu schätzen.#Deeper optimization from scipy.optimize import minimize from sklearn.metrics import mean_squared_error from sklearn.model_selection import TimeSeriesSplit
Wir definieren das Objekt für die Aufteilung der Zeitserie
#Define the time series split object tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)
und erstellen Datenstrukturen, um unsere Genauigkeitsstufen zu speichern.
#Create a dataframe to store our accuracy current_error_rate = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) algorithm_progress = []
Unsere Kostenfunktion, die es zu minimieren gilt, sind die Fehlerwerte des Modells bei den Trainingsdaten.
#Define the objective function def objective(x): #The parameter x represents a new value for our neural network's settings model = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=x[0], tol=x[1], learning_rate_init=x[2] ) #Now we will cross validate the model for i,(train_index,test_index) in enumerate(tscv.split(train)): #Train the model model.fit(train.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Target"]) #Measure the RMSE current_error_rate.iloc[i,0] = mean_squared_error(train.loc[test_index,"Price Target"],model.predict(train.loc[test_index,ohlc_predictors])) #Store the algorithm's progress algorithm_progress.append(current_error_rate.iloc[:,0].mean()) #Return the Mean CV RMSE return(current_error_rate.iloc[:,0].mean())
SciPy erwartet, dass wir es mit Anfangswerten versorgen, um das Optimierungsverfahren zu starten.
#Define the starting point pt = [tuner.best_params_["alpha"],tuner.best_params_["tol"],tuner.best_params_["learning_rate_init"]] bnds = ((10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100))
Wir wollen nun versuchen, das Modell zu optimieren.
#Searching deeper for parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
Es scheint, dass der Algorithmus konvergieren konnte. Das bedeutet, dass er stabile Inputs mit geringer Varianz gefunden hat. Er kam daher zu dem Schluss, dass es keine besseren Lösungen gibt, da sich die Änderungen der Fehlerquoten gegen 0 bewegten.
#The result of our optimization
result success: True
status: 0
fun: 3.730365831424036e-06
x: [ 9.939e-08 9.999e-03 9.999e-03]
nit: 3
jac: [-7.896e+01 -1.133e+02 1.439e+03]
nfev: 100
njev: 25
hess_inv: <3x3 LbfgsInvHessProduct with dtype=float64>
Veranschaulichen wir uns das Verfahren.
#Store the optimal coefficients optimal_weights = result.x optima_y = min(algorithm_progress) optima_x = algorithm_progress.index(optima_y) inputs = np.arange(0,len(algorithm_progress)) #Plot the performance of our optimization procedure plt.scatter(inputs,algorithm_progress) plt.plot(optima_x,optima_y,'ro',color='r') plt.axvline(x=optima_x,ls='--',color='red') plt.axhline(y=optima_y,ls='--',color='red') plt.xlabel("Iterations") plt.ylabel("Training MSE") plt.title("Minimizing Training Error")
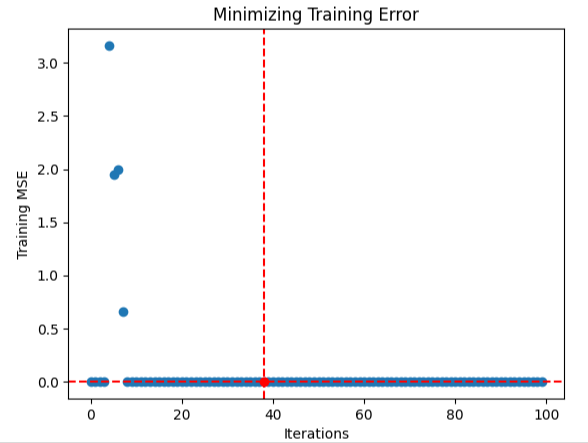
Abb. 9: Visualisierung der Optimierung eines tiefen neuronalen Netzes
Test auf Überanpassung
Überanpassung ist ein unerwünschter Effekt, bei dem unser Modell sinnlose Darstellungen aus den Daten lernt, die wir ihm gegeben haben. Dies ist unerwünscht, da ein Modell in diesem Zustand eine schlechte Genauigkeit aufweist. Wir können feststellen, ob unser Modell überangepasst ist, indem wir es mit schwächeren Lernern und Standardinstanzen eines ähnlichen neuronalen Netzes vergleichen. Wenn unser Modell das Rauschen lernt und das Signal in den Daten nicht erkennen kann, wird es von den schwächeren Lernern übertroffen. Aber selbst wenn unser Modell die schwächeren Lerner übertrifft, besteht immer noch die Möglichkeit, dass es sich zu gut anpasst.
#Testing for overfitting #Benchmark benchmark = LinearRegression() #Default default_nn = MLPRegressor(max_iter=500) #Randomized NN random_search_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=tuner.best_params_["alpha"], tol=tuner.best_params_["tol"], learning_rate_init=tuner.best_params_["learning_rate_init"] ) #LBFGS NN lbfgs_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=result.x[0], tol=result.x[1], learning_rate_init=result.x[2] )
Wir passen die Modelle an und bewerten ihre Genauigkeit. Es ist deutlich zu erkennen, dass das lineare Regressionsmodell alle unsere tiefen neuronalen Netze in den Schatten stellt. Ich beschloss daher, stattdessen eine lineare SVM zu verwenden. Es schnitt besser ab als die neuronalen Netze, aber nicht besser als die lineare Regression.
#Fit the models on the training sets benchmark = LinearRegression() benchmark.fit(((train.loc[:,ohlc_predictors])),train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],benchmark.predict(((test.loc[:,ohlc_predictors])))) #Test the default default_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],default_nn.predict(test.loc[:,ohlc_predictors])) #Test the random search random_search_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],random_search_nn.predict(test.loc[:,ohlc_predictors])) #Test the lbfgs nn lbfgs_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lbfgs_nn.predict(test.loc[:,ohlc_predictors])
| Lineare Regression | Standard NN | Zufällige Suche | LBFGS NN |
|---|---|---|---|
| 2.609826e-07 | 1.996431e-05 | 0.00051 | 0.000398 |
Passen wir unsere LinearSVR an, so ist es wahrscheinlicher, dass sie die nichtlinearen Wechselwirkungen in unseren Daten erfasst.
#From experience, I'll try LSVR from sklearn.svm import LinearSVR
Wir initialisieren das Modell und passen es an alle Daten an, die wir haben. Beachten Sie, dass die Fehlerwerte der SVR besser sind als die des neuronalen Netzes, aber nicht so gut wie die der linearen Regression.
#Initialize the model lsvr = LinearSVR() #Fit the Linear Support Vector lsvr.fit(train.loc[:,["Open","High","Low","Close"]],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lsvr.predict(test.loc[:,["Open","High","Low","Close"]]))
Exportieren nach ONNX
Open Neural Network Exchange (ONNX) ermöglicht es uns, Modelle für maschinelles Lernen in einer Sprache zu erstellen und sie dann mit jeder anderen Sprache, die die ONNX-API unterstützt, zu teilen. Das ONNX-Protokoll verändert rasch die Anzahl der Umgebungen, in denen maschinelles Lernen eingesetzt werden kann. ONNX ermöglicht uns die nahtlose Integration von AI in unseren MQL5 Expert Advisor.
#Let's export the LSVR to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Erstellen wir eine neue Instanz des Modells.
model = LinearSVR()
Passen wir das Modell an alle Daten an, die wir haben.
model.fit(data.loc[:,["Open","High","Low","Close"]],data.loc[:,"Price Target"])
Definieren wir jetzt die Eingabeform des Modells,
#Define the input type initial_types = [("float_input",FloatTensorType([1,4]))]
erstellen eine ONNX-Darstellung des Modells
#Create the ONNX representation onnx_model = convert_sklearn(model,initial_types=initial_types,target_opset=12)
und speichern das ONNX-Modell.
# Save the ONNX model onnx.save_model(onnx_model,"EURUSD SVR M1.onnx")

Abb. 10: Visualisierung unseres ONNX-Modells
Implementierung in MQL5
Wir können nun mit der Umsetzung unserer Strategie in MQL5 beginnen. Wir möchten eine Anwendung entwickeln, die immer dann kauft, wenn der Kurs über dem gleitenden Durchschnitt liegt und die KI einen Kursanstieg vorhersagt.
Um mit unserer Anwendung zu beginnen, werden wir zunächst die gerade erstellte ONNX-Datei in unseren Expert Advisor einbinden.
//+--------------------------------------------------------------+ //| EURUSD AI | //+--------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://metaquotes.com/en/users/gamuchiraindawa" #property version "2.1" #property description "Supports M1" //+--------------------------------------------------------------+ //| Resources we need | //+--------------------------------------------------------------+ #resource "\\Files\\EURUSD SVR M1.onnx" as const uchar onnx_buffer[];
Jetzt müssen wir die Handelsbibliothek laden.
//+--------------------------------------------------------------+ //| Libraries | //+--------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade trade;
Definieren Sie einige Konstanten, die sich nun ändern werden.
//+--------------------------------------------------------------+ //| Constants | //+--------------------------------------------------------------+ const double stop_percent = 1; const int ma_period_shift = 0;
Wir werden dem Nutzer die Kontrolle über die Parameter der technischen Indikatoren und das allgemeine Verhalten des Programms ermöglichen.
//+--------------------------------------------------------------+ //| User inputs | //+--------------------------------------------------------------+ input group "TAs" input double atr_multiple =2.5; //How wide should the stop loss be? input int atr_period = 200; //ATR Period input int ma_period = 1000; //Moving average period input group "Risk" input double risk_percentage= 0.02; //Risk percentage (0.01 - 1) input double profit_target = 1.0; //Profit target
Definieren wir nun alle globalen Variablen, die wir benötigen.
//+--------------------------------------------------------------+ //| Global variables | //+--------------------------------------------------------------+ double position_size = 2; int lot_multiplier = 1; bool buy_break_even_setup = false; bool sell_break_even_setup = false; double up_level = 0.03; double down_level = -0.03; double min_volume,max_volume_increase, volume_step, buy_stop_loss, sell_stop_loss,ask, bid,atr_stop,mid_point,risk_equity; double take_profit = 0; double close_price[3]; double moving_average_low_array[],close_average_reading[],moving_average_high_array[],atr_reading[]; long min_distance,login; int ma_high,ma_low,atr,close_average; bool authorized = false; double tick_value,average_market_move,margin,mid_point_height,channel_width,lot_step; string currency,server; bool all_closed =true; long onnx_model; vectorf onnx_output = vectorf::Zeros(1); ENUM_ACCOUNT_TRADE_MODE account_type;
Unser Experte prüft zunächst, ob der Nutzer den Expertenhandel für das Konto aktiviert hat, dann versucht er, das ONNX-Modell zu laden, und schließlich, wenn dies erfolgreich war, laden wir unsere technischen Indikatoren.
//+------------------------------------------------------------------+ //| On initialization | //+------------------------------------------------------------------+ int OnInit() { //--- Authorization if(!auth()) { return(INIT_FAILED); } //--- Load the ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- Everything went fine else { load(); return(INIT_SUCCEEDED); } }
Wenn unser Advisor nicht nutzt wird, geben wir den dem ONNX-Modell zugewiesenen Speicher frei.
//+------------------------------------------------------------------+ //| On deinitialization | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { OnnxRelease(onnx_model); }Immer wenn wir aktualisierte Kursdaten erhalten, aktualisieren wir unsere globalen Marktvariablen und suchen dann nach Handelssignalen, wenn wir keine offenen Positionen haben. Andernfalls aktualisieren wir unseren nachlaufenden (trailing) Stop-Loss.
//+------------------------------------------------------------------+ //| On every tick | //+------------------------------------------------------------------+ void OnTick() { //On Every Function Call update(); static datetime time_stamp; datetime time = iTime(_Symbol,PERIOD_CURRENT,0); Comment("AI Forecast: ",onnx_output[0]); //On Every Candle if(time_stamp != time) { //Mark the candle time_stamp = time; OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,min_volume,ask,margin); calculate_lot_size(); if(PositionsTotal() == 0) { check_signal(); } } //--- If we have positions, manage them. if(PositionsTotal() > 0) { check_atr_stop(); check_profit(); } } //+------------------------------------------------------------------+ //| Check if we have any valid setups, and execute them | //+------------------------------------------------------------------+ void check_signal(void) { //--- Get a prediction from our model model_predict(); if(onnx_output[0] > iClose(Symbol(),PERIOD_CURRENT,0)) { if(above_channel()) { check_buy(); } } else if(below_channel()) { if(onnx_output[0] < iClose(Symbol(),PERIOD_CURRENT,0)) { check_sell(); } } }
Diese Funktion ist für die Aktualisierung aller unserer globalen Marktvariablen zuständig.
//+------------------------------------------------------------------+ //| Update our global variables | //+------------------------------------------------------------------+ void update(void) { //--- Important details that need to be updated everytick ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); buy_stop_loss = 0; sell_stop_loss = 0; check_price(3); CopyBuffer(ma_high,0,0,1,moving_average_high_array); CopyBuffer(ma_low,0,0,1,moving_average_low_array); CopyBuffer(atr,0,0,1,atr_reading); ArraySetAsSeries(moving_average_high_array,true); ArraySetAsSeries(moving_average_low_array,true); ArraySetAsSeries(atr_reading,true); risk_equity = AccountInfoDouble(ACCOUNT_BALANCE) * risk_percentage; atr_stop = (((min_distance + (atr_reading[0]* 1e5) * atr_multiple) * _Point)); mid_point = (moving_average_high_array[0] + moving_average_low_array[0]) / 2; mid_point_height = close_price[0] - mid_point; channel_width = moving_average_high_array[0] - moving_average_low_array[0]; }
Jetzt müssen wir die Funktion definieren, die sicherstellt, dass unsere Anwendung ausgeführt werden darf. Wenn sie nicht ausgeführt werden darf, gibt die Funktion dem Nutzer Anweisungen, was zu tun ist, und gibt false zurück, wodurch die Initialisierung abgebrochen wird.
//+------------------------------------------------------------------+ //| Check if the EA is allowed to be run | //+------------------------------------------------------------------+ bool auth(void) { if(!TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { Comment("Press Ctrl + E To Give The Robot Permission To Trade And Reload The Program"); return(false); } else if(!MQLInfoInteger(MQL_TRADE_ALLOWED)) { Comment("Reload The Program And Make Sure You Clicked Allow Algo Trading"); return(false); } return(true); }
Während der Initialisierung benötigen wir eine Funktion, die für das Laden aller unserer technischen Indikatoren und das Abrufen wichtiger Marktdetails verantwortlich ist. Die Ladefunktion wird genau das für uns tun, und da sie auf globale Variablen verweist, ist ihr Rückgabetyp ungültig.
//+---------------------------------------------------------------------+ //| Load our needed variables | //+---------------------------------------------------------------------+ void load(void) { //Account Info currency = AccountInfoString(ACCOUNT_CURRENCY); server = AccountInfoString(ACCOUNT_SERVER); login = AccountInfoInteger(ACCOUNT_LOGIN); //Indicators atr = iATR(_Symbol,PERIOD_CURRENT,atr_period); ma_high = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_HIGH); ma_low = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_LOW); //Market Information min_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); max_volume_increase = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MAX) / SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); min_distance = SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL); tick_value = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_VALUE_PROFIT) * min_volume; lot_step = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); average_market_move = NormalizeDouble(10000 * tick_value,_Digits); }
Unser ONNX-Modell hingegen wird durch einen separaten Funktionsaufruf geladen. Die Funktion erstellt unser ONNX-Modell aus dem zuvor definierten Puffer und validiert die Eingabe- und Ausgabeform.
//+------------------------------------------------------------------+ //| Load our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); ulong onnx_input [] = {1,4}; ulong onnx_output[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,onnx_input)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } if(!OnnxSetOutputShape(onnx_model,0,onnx_output)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } return(true); }
Definieren wir nun die Funktion, mit der wir Vorhersagen aus unserem Modell erhalten.
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { vectorf onnx_inputs = {iOpen(Symbol(),PERIOD_CURRENT,0),iHigh(Symbol(),PERIOD_CURRENT,0),iLow(Symbol(),PERIOD_CURRENT,0),iClose(Symbol(),PERIOD_CURRENT,0)}; OnnxRun(onnx_model,ONNX_DEFAULT,onnx_inputs,onnx_output); }
Unser Stop-Loss wird um den ATR-Wert angepasst. Je nachdem, ob es sich bei dem aktuellen Handel um einen Kauf- oder einen Verkaufshandel handelt, ist dies der entscheidende Faktor, der uns dabei hilft, festzustellen, ob wir unseren Stop-Loss nach oben aktualisieren sollten, indem wir den aktuellen ATR-Wert addieren, oder nach unten, indem wir den aktuellen ATR-Wert abziehen. Wir können auch ein Vielfaches des aktuellen ATR-Wertes verwenden, um dem Nutzer eine feinere Kontrolle über sein Risikoniveau zu geben.
//+------------------------------------------------------------------+ //| Update the ATR stop loss | //+------------------------------------------------------------------+ void check_atr_stop() { for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); double type = PositionGetInteger(POSITION_TYPE); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (ask - (atr_stop)); double atr_take_profit = (ask + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } else if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (bid + (atr_stop)); double atr_take_profit = (bid - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } } } }
Schließlich müssen wir 2 Funktionen definieren, die für das Eröffnen von Kauf- und Verkaufspositionen zuständig sind, und ihre komplementären Paare für das Schließen der Position.
//+------------------------------------------------------------------+ //| Open buy positions | //+------------------------------------------------------------------+ void check_buy() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Buy(min_volume * lot_multiplier,_Symbol,ask,buy_stop_loss,0,"BUY"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Open sell positions | //+------------------------------------------------------------------+ void check_sell() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Sell(min_volume * lot_multiplier,_Symbol,bid,sell_stop_loss,0,"SELL"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Close all buy positions | //+------------------------------------------------------------------+ void close_buy() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_BUY) { trade.PositionClose(ticket); } } } } } //+------------------------------------------------------------------+ //| Close all sell positions | //+------------------------------------------------------------------+ void close_sell() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_SELL) { trade.PositionClose(ticket); } } } } }
Lassen Sie uns die letzten 3 Kursniveaus verfolgen.
//+------------------------------------------------------------------+ //| Get the last 3 quotes | //+------------------------------------------------------------------+ void check_price(int candles) { for(int i = 0; i < candles;i++) { close_price[i] = iClose(_Symbol,PERIOD_CURRENT,i); } }
Diese boolesche Prüfung gibt true zurück, wenn wir über dem gleitenden Durchschnitt liegen.
//+------------------------------------------------------------------+ //| Are we completely above the MA? | //+------------------------------------------------------------------+ bool above_channel() { return (((close_price[0] - moving_average_high_array[0] > 0)) && ((close_price[0] - moving_average_low_array[0]) > 0)); }
Prüfen Sie, ob wir unter dem gleitenden Durchschnitt liegen.
//+------------------------------------------------------------------+ //| Are we completely below the MA? | //+------------------------------------------------------------------+ bool below_channel() { return(((close_price[0] - moving_average_high_array[0]) < 0) && ((close_price[0] - moving_average_low_array[0]) < 0)); }
Schließen wir alle Positionen, die wir haben.
//+------------------------------------------------------------------+ //| Close all positions we have | //+------------------------------------------------------------------+ void close_all() { if(PositionsTotal() > 0) { ulong ticket; for(int i =0;i < PositionsTotal();i++) { ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } }
Berechnen wir die optimale Losgröße, damit unsere Marge dem Kapitalbetrag entspricht, den wir zu riskieren bereit sind.
//+------------------------------------------------------------------+ //| Calculate the lot size to be used | //+------------------------------------------------------------------+ void calculate_lot_size() { //--- This is the total percentage of the account we're willing to part with for margin, or to keep a position open in other words. Print("Risk Equity: ",risk_equity); //--- Now that we're ready to part with a discrete amount for margin, how many positions can we afford under the current lot size? //--- By default we always start from minimum lot position_size = risk_equity / margin; //--- We need to keep the number of positions lower than 10 if(position_size > 10) { //--- How many times is it greater than 10? int estimated_lot_size = (int) MathFloor(position_size / 10); position_size = risk_equity / (margin * estimated_lot_size); Print("Position Size After Dividing By margin at new estimated lot size: ",position_size); int estimated_position_size = position_size; //--- Can we increase the lot size this many times? if(estimated_lot_size < max_volume_increase) { Print("Est Lot Size: ",estimated_lot_size," Position Size: ",estimated_position_size); lot_multiplier = estimated_lot_size; position_size = estimated_position_size; } } }
Schließen wir offene Positionen und prüfen, ob wir wieder handeln können.
//--- This function will help us keep track of which side we need to enter the market void close_all_and_enter() { if(PositionSelect(Symbol())) { // Determine the type of position check_signal(); } else { Print("No open position found."); } }
Wenn wir unser Gewinnziel erreicht haben, schließen wir alle Positionen, die wir haben, um den Gewinn zu realisieren, und prüfen dann, ob wir wieder einsteigen können.
//+------------------------------------------------------------------+ //| Chekc if we have reached our profit target | //+------------------------------------------------------------------+ void check_profit() { double current_profit = (AccountInfoDouble(ACCOUNT_EQUITY) - AccountInfoDouble(ACCOUNT_BALANCE)) / PositionsTotal(); if(current_profit > profit_target) { close_all_and_enter(); } if((current_profit * PositionsTotal()) < (risk_equity * -1)) { Comment("We've breached our risk equity, consider closing all positions"); } }
Und schließlich brauchen wir eine Funktion, die alle unrentablen Geschäfte schließt.
//+------------------------------------------------------------------+ //| Close all losing trades | //+------------------------------------------------------------------+ void close_profitable_trades() { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetDouble(POSITION_PROFIT)>profit_target) { ulong ticket; ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } } } //+------------------------------------------------------------------+
Abb. 11: Unser Expert Advisor
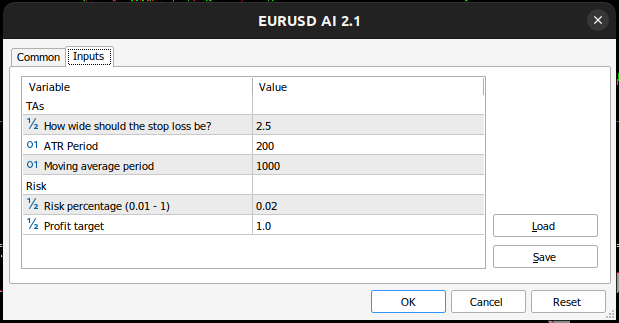
Abb. 12: Die Parameter, die wir zum Testen der Anwendung verwenden
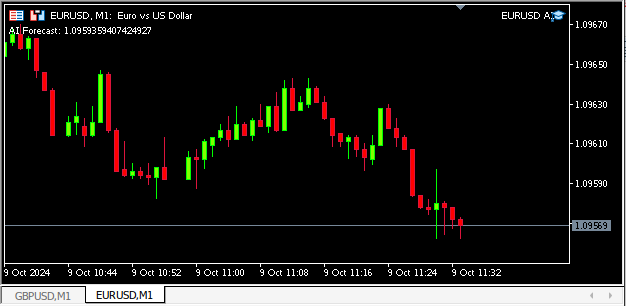
Abb. 13: Unser Programm in Aktion
Schlussfolgerung
Unsere Ergebnisse waren zwar nicht ermutigend, aber sie sind bei weitem nicht schlüssig. Es gibt noch andere Möglichkeiten, den MACD-Indikator zu interpretieren, die eine Bewertung wert sein können. So kreuzt die MACD-Signallinie bei einem Aufwärtstrend oberhalb der Hauptlinie, während sie bei einem Abwärtstrend unter die Hauptlinie fällt. Die Betrachtung des Indikators aus dieser Perspektive könnte zu unterschiedlichen Fehlermetriken führen. Wir können nicht einfach davon ausgehen, dass alle Strategien zur Interpretation des MACD zu einheitlichen Fehlerquoten führen. Es wäre nur vernünftig, die Wirksamkeit verschiedener Strategien auf der Grundlage des MACD zu testen, bevor wir uns ein Urteil über die Wirksamkeit des Indikators bilden können.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16066
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Wie Smart-Money-Konzepte (SMC) zusammen mit dem Fibonacci-Indikator einen optimalen Handelseinstieg signalisieren.
Wie Smart-Money-Konzepte (SMC) zusammen mit dem Fibonacci-Indikator einen optimalen Handelseinstieg signalisieren.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.