
Die Grenzen des maschinellen Lernens überwinden (Teil 4): Überwindung des irreduziblen Fehlers durch mehrere Prognosehorizonte

Maschinelles Lernen ist ein sehr weites Feld, das aus vielen verschiedenen Perspektiven untersucht und interpretiert werden kann. Gerade diese Breite macht es für jeden von uns zu einer großen Herausforderung, sie zu meistern. In unserer Artikelserie haben wir einiges zum maschinellen Lernen aus statistischer Sicht oder aus der Perspektive der linearen Algebra behandelt. Der geometrischen Interpretation von Modellen des maschinellen Lernens wird jedoch nur selten Aufmerksamkeit geschenkt. Traditionell werden Modelle des maschinellen Lernens als Approximation einer Funktion beschrieben, die Eingaben auf Ausgaben abbildet. Aus geometrischer Sicht ist dies jedoch unvollständig.
Was Modelle tatsächlich tun, ist, Bilder des Ziels in den durch die Eingaben definierten Raum einzubetten, sodass sie in Zukunft versuchen können, das Ziel nur mit diesen Eingaben zu beschreiben. Dabei definiert das Modell einen neuen Verteiler aus den Eingabedaten und macht Vorhersagen für diesen neuen Verteiler. Aber das eigentliche Ziel lebt von seiner eigenen Vielfältigkeit. Diese Fehlausrichtung führt zu einer subtilen, aber unvermeidlichen Form des irreduziblen Fehlers: Das Modell ist nie wirklich auf das Ziel ausgerichtet, sondern kann nur auf eine bestimmte Kombination der Eingaben zeigen.
Ein Gedankenexperiment kann helfen. Stellen Sie sich vor, Sie erhalten Aufzeichnungen der Geschwindigkeiten von zwei Autos und sollen beurteilen, welches schneller ist. Das ist einfach – bis Sie feststellen, dass die Geschwindigkeit des einen Autos in Meilen pro Minute und die des anderen in Kilometern pro Stunde gemessen wird. Ihre Urteile werden unzuverlässig, weil die Messungen in unterschiedlichen Einheiten erfolgen. Ebenso werden die Vorhersagen des Modells in einem anderen Koordinatensystem ausgedrückt als dem, in dem das tatsächliche Ziel lebt. Das heißt, dass das Modell seine eigenen Einheiten im laufenden Betrieb erstellen kann.
In Fällen, in denen das Ziel wirklich innerhalb der Spanne der Eingänge liegt, kann der Ausrichtungsfehler fast gleich 0 sein. Im Handel kann es jedoch teuer werden, sie zu ignorieren. Modelle des maschinellen Lernens führen hinter den Kulissen Koordinatentransformationen durch und versetzen uns in ein anderes Koordinatensystem als das des Ziels. Anders als in den Naturwissenschaften haben wir auf den Finanzmärkten keine Garantie, dass unsere Inputs das Ziel perfekt erklären. Hier arbeiten wir teilweise blind.
In unserer Serie über selbstoptimierende Expertenberater haben wir erörtert, wie lineare Regressionsmodelle mithilfe der Matrixfaktorisierung konstruiert werden können, die OpenBLAS-Bibliothek vorgestellt und die Singulärwertzerlegung (SVD) erläutert. Leser, die mit dieser Diskussion nicht vertraut sind, sollten sie nachlesen, da der vorliegende Artikel auf dieser Grundlage aufbaut; ein Link ist hier angegeben.
Die SVD faktorisiert eine Matrix in drei kleinere Matrizen, wie Sie wissen: U, S und VT. Jede hat besondere geometrische Eigenschaften. U und VT sind orthogonale Matrizen, d. h. sie stellen Drehungen oder Spiegelungen der ursprünglichen Daten dar – und entscheidend ist, dass sie Vektoren nicht strecken, sondern nur die Richtung ändern. S, die mittlere Matrix, ist diagonal und skaliert die Datenwerte.
Zusammengenommen kann SVD als eine Abfolge von Rotation, Skalierung und Drehung der Daten verstanden werden. Auf diese Weise betten lineare Regressionsmodelle Bilder des Ziels in den Raum der Eingaben ein. Wenn wir also die lineare Regression auf ihr geometrisches Wesen reduzieren, ist sie nichts anderes als Rotation, Skalierung und nochmals Rotation. Mehr nicht. Das war's. Drehen, Skalieren, Drehen. Wenn man Geometrie studiert, lernt man, sie so zu sehen, aber wenn man das tut, stellt sich eine provokante Frage: Wo findet das ganze „Lernen“ wirklich statt?
Die Antwort ist beunruhigend. Was die Praktiker als „Lernen“ bezeichnen, ist in Wirklichkeit nichts anderes als das Ausrichten von Koordinatensystemen und die Neuskalierung von Achsen, damit das Ziel in den Bereich der Eingaben projiziert werden kann. Wir decken keine versteckten Wahrheiten in den Daten auf. Wir wenden eine Reihe von geometrischen Transformationen an, bis zwei Mannigfaltigkeiten gerade so weit übereinstimmen, dass die Vorhersagen vernünftig aussehen.
Die SVD ist der Prozess, durch den das neue Koordinatensystem erzeugt wird. Bei der linearen Regression werden die Eingabedaten auf eine Reihe von orthogonalen Achsen projiziert, skaliert und zurückgedreht, sodass ein transformierter Raum entsteht, in dem das Ziel so genau wie möglich angenähert werden kann. Das „Lernen“ des Modells besteht eigentlich nur in der Ausrichtung des Ziels auf dieses neue Koordinatensystem.
Auf der Grundlage dieses geometrischen Rahmens können wir Maßnahmen und bereichsgebundene bewährte Praktiken motivieren, die sonst unbegründet erscheinen würden. Die wichtigste Erkenntnis ist, dass wir aufhören müssen, direkte Vergleiche zwischen den Vorhersagen eines Modells und dem tatsächlichen Wert des Ziels anzustellen. Stattdessen sollten wir die Vorhersagen des Modells miteinander vergleichen, und zwar für verschiedene Zeithorizonte.
Nehmen wir zum Beispiel an, das Modell sagt voraus, dass der Schlusskurs einen Schritt voraus bei 5 $ und zehn Schritte voraus bei 15 $ liegen wird. Die Steigung zwischen diesen Prognosen ist positiv, also kaufen wir. Wenn die Steigung negativ ist, verkaufen wir. Wir erwarten nicht mehr, dass die Vorhersagen perfekt mit der Realität übereinstimmen – da dies aufgrund vielfältiger Abweichungen für immer unmöglich sein kann – und handeln stattdessen aufgrund der relativen Steigung der Vorhersagen. Dieses mehrstufige Vorhersageformat ist für den algorithmischen Handel nicht neu. Vielmehr möchte dieser Artikel dem Leser vermitteln, dass mehrstufige Vorhersagen der DeFacto-Goldstandard beim Einsatz von maschinellen Lernmodellen sein sollten.
Dieser Artikel erhebt keinen Anspruch darauf, den geometrischen Fehler zu verringern oder zu beseitigen. Stattdessen lehrt sie uns, wie wir unsere Interaktion mit ihm minimieren können, indem wir uns außerhalb des Bereichs aufhalten, in dem der Fehler dominiert.
Bei unserer Methodik begannen wir mit einem Modell für maschinelles Lernen, das auf neun verschiedene Ziele trainiert wurde. Diese Ziele setzten sich aus dem gleitenden Durchschnitt des Schlusskurses, des Hochs und des Tiefs bei 1, 5 und 10 Tageskerzen in der Zukunft zusammen. Das Kontrollsystem folgte dem klassischen Ansatz: Vorhersage des realen Wertes des Ziels 1 Kerze in der Zukunft, Vergleich mit dem aktuellen Wert des Ziels und entsprechender Handel. Wie der Leser sehen wird, haben wir diese klassische Methode wiederholt übertroffen, indem wir auf direkte Vergleiche verzichtet und stattdessen die eigenen Vorhersagen des Modells über mehrere Zeithorizonte hinweg verglichen haben. Der Grundgedanke ist einfach, aber wirkungsvoll: Die Vorhersagen unseres Modells können für uns profitabler sein, wenn wir sie mit sich selbst vergleichen, als wenn wir sie mit dem tatsächlichen Ziel vergleichen.
Wir haben das Kontrollsystem anhand von 3 Jahren historischer Daten getestet, die von März 2022 bis Mai 2025 reichen. Das Kontrollsystem erzielte in diesem Zeitraum einen Nettogewinn von 71 $. Indem wir lediglich die Art und Weise, wie wir die Vorhersagen des Modells interpretieren, geändert haben, konnten wir den Nettogewinn auf 180 $ steigern, was einer Verbesserung des Gewinns um 153 % entspricht. Unsere Sharpe Ratio stieg von 0,45 auf 2,16 und der Prozentsatz profitabler Handelsgeschäfte von 46% auf 65%, was einer Verbesserung der Handelsgenauigkeit um 41% entspricht.
Das Wichtigste ist, dass alle Verbesserungen, die wir dem Leser jetzt zeigen werden, durchgeführt werden können, ohne dass das Modell, von dem wir abhängig sind, ausgetauscht werden muss, und dass sie auf jedes andere maschinelle Lernmodell, das der Leser bereits kennt, ausgedehnt werden können.
Abrufen der Marktdaten
Wir beginnen mit dem Schreiben eines MQL5-Skripts, um die benötigten historischen Marktdaten abzurufen. Die historischer Marktdaten von Ihrem MetaTrader 5-Terminal abzurufen, ist die beste Vorgehensweise, da sie sicherstellt, dass unsere ONNX-Modelle auf historischen Daten trainiert werden, die mit der endgültigen Einsatzumgebung übereinstimmen. Unser MQL5-Skript holt detaillierte Aufzeichnungen über die vier vorherrschenden Preisniveaus und ihre gleitenden Durchschnitte ab. Wir achten auch auf das Wachstum jedes dieser Preisniveaus im Vergleich zu ihren früheren Niveaus 5 Schritte in der Vergangenheit. Alle diese Daten werden im CSV-Format auf Ihrer Festplatte gespeichert.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 5 //--- Forecast horizon //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Detailed Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA C", "True MA O", "True MA H", "True MA L", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Close 2", "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_reading[i], ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE //+------------------------------------------------------------------+
Analyse der Marktdaten
Wir können nun unsere historischen Marktdaten einlesen. Laden wir zunächst einige Python-Bibliotheken zur Datenmanipulation.
import pandas as pd import numpy as np import matplotlib.pyplot as plt
Nun werden wir 3 eindeutige Zeithorizonte definieren, die wir prognostizieren wollen.
#Define our different forecast horizons H1 = 1 H2 = 5 H3 = 10
Wir werden nun die Marktdaten lesen, die wir von unserem Terminal exportiert haben, und Ziele für die gleitenden Durchschnitte für verschiedene Zeithorizonte erstellen.
#Read in the data data = pd.read_csv('../EURUSD Detailed Market Data As Series Moving Average.csv') #Label the data data['Target 1'] = data['True MA C'].shift(-H1) data['Target 2'] = data['True MA C'].shift(-H2) data['Target 3'] = data['True MA C'].shift(-H3) data['Target 4'] = data['True MA H'].shift(-H1) data['Target 5'] = data['True MA H'].shift(-H2) data['Target 6'] = data['True MA H'].shift(-H3) data['Target 7'] = data['True MA L'].shift(-H1) data['Target 8'] = data['True MA L'].shift(-H2) data['Target 9'] = data['True MA L'].shift(-H3) #Drop missing rows data = data.iloc[:-H3,:]
Wir erstellen eine Trainingspartition
data = data.iloc[:-(365*3),:] data_test = data.iloc[-(365*3):,:]
und trennen die Eingaben und die Ziele.
X = data.iloc[:,1:-9] y = data.iloc[:,-9:]
Wir laden ein beliebiges maschinelles Lernmodell Ihrer Wahl. Für unsere Diskussion werden wir die Sklearn-Bibliothek verwenden und die Prinzipien anhand eines linearen Modells demonstrieren.
from sklearn.linear_model import LinearRegression
Initialisieren des Modells.
model = LinearRegression()
Passen wir das Modell an.
model.fit(X,y)
Ermitteln wir die Vorhersagen des Modells auf der Testmenge, aber passen das Modell nicht auf die Testmenge an. Wie wir sehen können, scheinen die Vorhersagen des Modells gut mit dem Ziel übereinzustimmen, aber wie wir jetzt sehen werden, kann unser Modell noch besser abschneiden.
preds = pd.DataFrame(model.predict(data_test.iloc[:,1:-9])) plt.plot(data_test.iloc[:,-9].reset_index(drop=True),color='black') plt.plot(preds.iloc[:,0],color='red',linestyle=':') plt.grid() plt.title("Out Of Sample Forecasting") plt.ylabel('EUR/USD Exchange Rate') plt.xlabel('Time') plt.legend(['Actual Price','Forecasted Price'])
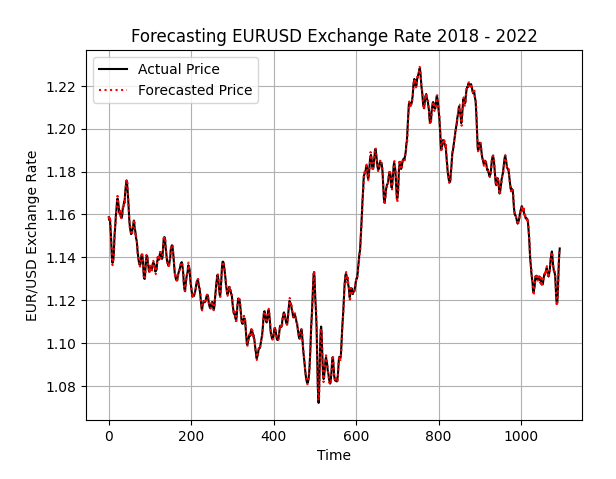
Abbildung 1: Die Vorhersagen des Modells außerhalb der Stichprobe scheinen mit der realen Zielvorgabe übereinzustimmen, aber dieses Leistungsniveau kann noch übertroffen werden
ONNX steht für Open Neural Network Exchange und ermöglicht es uns, Modelle für maschinelles Lernen in einer standardisierten Bibliothek zu erstellen und einzusetzen, die von einer ständig wachsenden Zahl von Programmiersprachen übernommen wird. Wir werden die ONNX-Bibliothek verwenden, um unser maschinelles Lernmodell aus Python zu exportieren und es anschließend in MQL5 zu importieren. ONNX ermöglicht es uns, Modelle für maschinelles Lernen schnell zu entwickeln und einzusetzen.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Wir müssen die Eingangs- und Ausgangsform unserer ONNX-Modelle definieren. Dies ist leicht möglich, da wir zuvor Ein- und Ausgänge getrennt haben. Holen Sie einfach die Anzahl der Spalten in jeder Partition und speichern Sie sie. Pandas macht das Abrufen dieser Informationen durch die Verwendung der shape-Eigenschaft trivial.
initial_types = [("FLOAT INPUT",FloatTensorType([1,X.shape[1]]))] final_types = [("FLOAT OUTPUT",FloatTensorType([y.shape[1],1]))]
Erstellen Sie einen ONNX-Prototyp des maschinellen Lernmodells. Wir werden die Anzahl der Eingänge und Ausgänge angeben, die wir für unser Modell benötigen.
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) Speichern Sie das ONNX-Modell auf der Festplatte.
onnx.save(model_proto,"EURUSD MFH LR D1.onnx")
Festlegung eines grundlegenden Leistungsniveaus
Wir sind nun in der Lage, ein Basisniveau der Leistung festzulegen. Wir beginnen damit, so viele Parameter der Strategie wie möglich festzulegen, um konsistente Tests zu gewährleisten.//+------------------------------------------------------------------+ //| MFH.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define SYSTEM_INPUTS 16 #define SYSTEM_OUTPUTS 9 #define ATR_PERIOD 14 #define ATR_PADDING 1 #define TF_1 PERIOD_D1 #define TF_2 PERIOD_M15 #define MA_PERIOD 5 #define MA_TYPE MODE_SMA #define HORIZON 5
Laden Sie den ONNX-Puffer, den wir aus Python exportiert haben.
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD MFH LR D1.onnx" as const uchar onnx_buffer[];
Wir werden auch auf einige Bibliotheken zurückgreifen, um Routineaufgaben für unseren algorithmischen Handel zu erledigen, wie z. B. die Handelsausführung, die Kerzenbildung und die Handhabung des ONNX-Puffers.
//+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> ONNXFloat *ONNXHandler; Time *TimeHandler; Time *LowerTimeHandler; TradeInfo *TradeHandler; CTrade Trade;
Eine Handvoll globaler Variablen sind notwendig, hauptsächlich für die Handhabung der technischen Indikatoren und die Speicherung der Vorhersagen des ONNX-Modells.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle,fetch,atr_handler; double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],atr[]; double padding; vector model_prediction;
Wenn unsere Anwendung zum ersten Mal geladen wird, werden wir unsere globalen Variablen und nutzerdefinierten Klassen initialisieren und auch Handler für die von uns erstellten technischen Indikatoren speichern.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- fetch = HORIZON * 2; ONNXHandler = new ONNXFloat(onnx_buffer); LowerTimeHandler = new Time(Symbol(),TF_2); TimeHandler = new Time(Symbol(),TF_1); TradeHandler = new TradeInfo(Symbol(),TF_1); ONNXHandler.DefineOnnxInputShape(0,1,SYSTEM_INPUTS); ONNXHandler.DefineOnnxOutputShape(0,1,SYSTEM_OUTPUTS); ma_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_LOW); atr_handler = iATR(Symbol(),TF_1,MA_PERIOD); model_prediction = vector::Zeros(SYSTEM_OUTPUTS); //--- return(INIT_SUCCEEDED); }
Es ist eine gängige Praxis in MQL5, eine gute Speicherverwaltung zu praktizieren und Ressourcen, die nicht mehr benötigt werden, freizugeben.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete ONNXHandler; IndicatorRelease(ma_h_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_l_handle); IndicatorRelease(ma_handle); IndicatorRelease(atr_handler); }
Sobald wir neue Preisniveaus erhalten haben, werden wir unsere technischen Indikatorpuffer und Stop-Loss-Niveaus aktualisieren. Danach werden wir prüfen, ob wir noch offene Positionen haben. Wenn keine offen sind, prüfen wir, ob sich eine Handelsmöglichkeit ergibt, andernfalls verwalten wir die offene Position mit einem Trailing Stop Loss.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Has a new candle formed if(TimeHandler.NewCandle()) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); CopyBuffer(atr_handler,0,0,fetch,atr); ArraySetAsSeries(atr,true); padding = (atr[0] * ATR_PADDING); //--- Obtain a prediction from our model if(PositionsTotal() == 0) { model_predict(); } //--- Manage open positions if(PositionsTotal() >0) { manage_setup(); } } } //+------------------------------------------------------------------+
Unser Trailing-Stop wird durch den ATR-Indikator (Average True Range) definiert. Die ATR misst die Marktvolatilität und hilft uns, unser Risikoniveau dynamisch anzupassen. Wenn der Stop-Loss sicher auf eine profitablere Position aktualisiert werden kann, werden wir dies tun, andernfalls warten wir.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_setup(void) { //--- Select the position by its ticket number if(PositionSelectByTicket(PositionGetTicket(0))) { //--- Store the current tp and sl levels double current_tp,current_sl; current_tp = PositionGetDouble(POSITION_TP); current_sl = PositionGetDouble(POSITION_SL); //--- Before we calculate the new stop loss or take profit double new_sl,new_tp; //--- We first check the position type if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_BUY) { new_sl = TradeHandler.GetBid()-padding; new_tp = TradeHandler.GetBid()+padding; //--- Check if the new stops are more profitable if(new_sl>current_sl) Trade.PositionModify(Symbol(),new_sl,new_tp); } if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_SELL) { new_sl = TradeHandler.GetAsk()+padding; new_tp = TradeHandler.GetAsk()-padding; //--- Check if the new stops are more profitable if(new_sl<current_sl) Trade.PositionModify(Symbol(),new_sl,new_tp); } } }
Wir werden unsere Anwendung zunächst ohne ein Modell des maschinellen Lernens testen, um ein Basisniveau für den Gewinn zu ermitteln. Wir werden eine einfache Ausbruchsstrategie für unsere maschinellen Lernmodelle anwenden, um eine bessere Leistung zu erzielen. Modelle, die unter dieses Leistungsniveau fallen, sind inakzeptabel.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); } } //+------------------------------------------------------------------+
Schließlich müssen Sie alle zuvor erstellten Systemkonstanten zurücksetzen.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_PERIOD #undef MA_TYPE #undef HORIZON #undef TF_1 #undef TF_2 #undef SYSTEM_INPUTS #undef SYSTEM_OUTPUTS #undef ATR_PADDING #undef ATR_PERIOD
Alles in allem sieht unser System so aus.
//+------------------------------------------------------------------+ //| MFH.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define SYSTEM_INPUTS 16 #define SYSTEM_OUTPUTS 9 #define ATR_PERIOD 14 #define ATR_PADDING 1 #define TF_1 PERIOD_D1 #define TF_2 PERIOD_M15 #define MA_PERIOD 5 #define MA_TYPE MODE_SMA #define HORIZON 5 //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD MFH LR D1.onnx" as const uchar onnx_buffer[]; //+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> ONNXFloat *ONNXHandler; Time *TimeHandler; Time *LowerTimeHandler; TradeInfo *TradeHandler; CTrade Trade; //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle,fetch,atr_handler; double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],atr[]; double padding; vector model_prediction; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- fetch = HORIZON * 2; ONNXHandler = new ONNXFloat(onnx_buffer); LowerTimeHandler = new Time(Symbol(),TF_2); TimeHandler = new Time(Symbol(),TF_1); TradeHandler = new TradeInfo(Symbol(),TF_1); ONNXHandler.DefineOnnxInputShape(0,1,SYSTEM_INPUTS); ONNXHandler.DefineOnnxOutputShape(0,1,SYSTEM_OUTPUTS); ma_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(Symbol(),TF_1,MA_PERIOD,0,MA_TYPE,PRICE_LOW); atr_handler = iATR(Symbol(),TF_1,MA_PERIOD); model_prediction = vector::Zeros(SYSTEM_OUTPUTS); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete ONNXHandler; IndicatorRelease(ma_h_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_l_handle); IndicatorRelease(ma_handle); IndicatorRelease(atr_handler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Has a new candle formed if(TimeHandler.NewCandle()) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); CopyBuffer(atr_handler,0,0,fetch,atr); ArraySetAsSeries(atr,true); padding = (atr[0] * ATR_PADDING); } if(LowerTimeHandler.NewCandle()) { //--- Obtain a prediction from our model if(PositionsTotal() == 0) { model_predict(); } //--- Manage open positions if(PositionsTotal() >0) { manage_setup(); } } } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_setup(void) { //--- Select the position by its ticket number if(PositionSelectByTicket(PositionGetTicket(0))) { //--- Store the current tp and sl levels double current_tp,current_sl; current_tp = PositionGetDouble(POSITION_TP); current_sl = PositionGetDouble(POSITION_SL); //--- Before we calculate the new stop loss or take profit double new_sl,new_tp; //--- We first check the position type if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_BUY) { new_sl = TradeHandler.GetBid()-padding; new_tp = TradeHandler.GetBid()+padding; //--- Check if the new stops are more profitable if(new_sl>current_sl) Trade.PositionModify(Symbol(),new_sl,new_tp); } if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_SELL) { new_sl = TradeHandler.GetAsk()+padding; new_tp = TradeHandler.GetAsk()-padding; //--- Check if the new stops are more profitable if(new_sl<current_sl) Trade.PositionModify(Symbol(),new_sl,new_tp); } } } //+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); } } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_PERIOD #undef MA_TYPE #undef HORIZON #undef TF_1 #undef TF_2 #undef SYSTEM_INPUTS #undef SYSTEM_OUTPUTS #undef ATR_PADDING #undef ATR_PERIOD //+------------------------------------------------------------------+
Wir beginnen damit, dass wir zunächst eine angemessene Gewinnerwartung aufstellen. Dieser Schritt ist von wesentlicher Bedeutung, um sicherzustellen, dass wir die Verbesserungen, die unsere Modelle des maschinellen Lernens tatsächlich bewirken, richtig einschätzen können.
Abbildung 2: Auswahl der Backtest-Tage für unser Kontrollsystem
Die detaillierten Ergebnisse des Kontrollsystems werden dem Leser im Folgenden vorgestellt. Wie wir sehen können, war die Mehrheit der von der Strategie platzierten Handelsgeschäfte unprofitabel, jedoch war der Durchschnitt der Handelsgeschäfte mit Gewinn größer als der mit Verlust. Diese asymmetrische Renditestruktur gab uns Vertrauen in das Kontrollsystem.
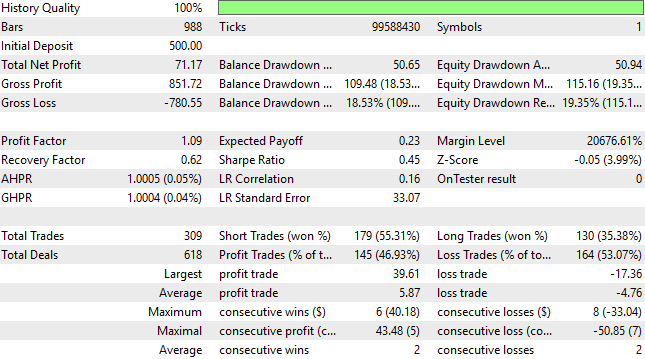
Abbildung 3: Analyse des Gewinns des Kontrollhandelsalgorithmus
Die von der Handelsstrategie erzeugte Kapitalkurve erscheint dagegen extrem volatil und gibt uns wenig Vertrauen, diese Handelsstrategie auch in Zukunft zu verfolgen. Daher werden wir nun versuchen, Modelle des maschinellen Lernens einzusetzen, um die volatilen Schwankungen in unserer derzeit einfachen Handelsstrategie auszugleichen.
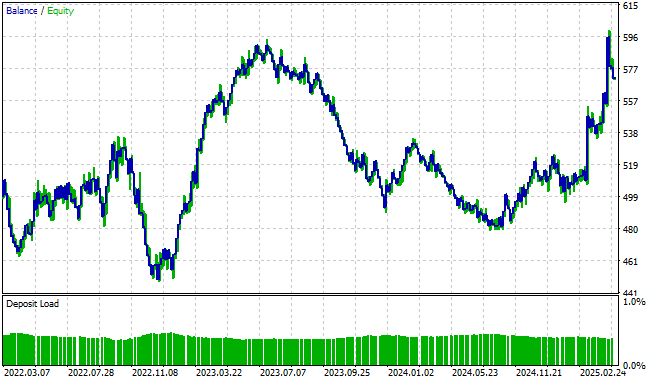
Abbildung 4: Die ursprüngliche Version unserer Handelsstrategie weckt wenig Vertrauen in einen Entwickler
Klassischer Versuch, die Kontrolle zu umgehen
Wir werden nun versuchen, die Kontrollhandelsstrategie mit Hilfe des klassischen Handelskonzepts zu übertreffen. Normalerweise prognostizieren wir in der klassischen Einstellung das Ziel, 1 Kerze in die Zukunft und vergleichen dann den prognostizierten Preis mit dem realen Wert des Preises, um unsere Handelssignale zu erhalten. In diesem Artikel wird versucht, den Leser davon zu überzeugen, dass diese Praxis möglicherweise nicht die bestmögliche für unsere Gemeinschaft ist, und wir werden sehen, warum.
Der größte Teil des Codes der Anwendung wird nicht absichtlich geändert, daher können wir uns ausschließlich auf den Teil des MQL5-Codes konzentrieren, der geändert werden muss, um unsere Ideen zu testen. Wie der Leser unten sehen kann, müssen wir nun die 16 Eingaben abrufen, die für unser ONNX-Modell erforderlich sind, um Vorhersagen zu treffen, und wir müssen sicherstellen, dass jede von ihnen in Float-Datentypen konvertiert wird, bevor wir irgendwelche Berechnungen durchführen. Anschließend erhalten wir eine Vorhersage von unserem ONNX-Modell und vergleichen sie mit dem tatsächlichen Wert des Ziels.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { vectorf model_inputs(SYSTEM_INPUTS); model_inputs[0] = (float) iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = (float) iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = (float) iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = (float) iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = (float) ma_reading[0]; model_inputs[5] = (float) ma_o_reading[0]; model_inputs[6] = (float) ma_h_reading[0]; model_inputs[7] = (float) ma_l_reading[0]; model_inputs[8] = (float)(iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); model_inputs[9] = (float)(iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); model_inputs[10] = (float)(iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); model_inputs[11] = (float)(iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); model_inputs[12] = (float)(ma_reading[0] - ma_reading[(0 + HORIZON)]); model_inputs[13] = (float)(ma_o_reading[0] - ma_o_reading[(0 + HORIZON)]); model_inputs[14] = (float)(ma_h_reading[0] - ma_h_reading[(0 + HORIZON)]); model_inputs[15] = (float)(ma_l_reading[0] - ma_l_reading[(0 + HORIZON)]); //--- Obtain the prediction ONNXHandler.Predict(model_inputs); for(int i=0;i<SYSTEM_OUTPUTS;i++) { model_prediction[i] = ONNXHandler.GetPrediction(i); } if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { if(model_prediction[0]>iClose(Symbol(),TF_2,0)) Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { if(model_prediction[0]<iClose(Symbol(),TF_2,0) Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); } } //+------------------------------------------------------------------+
Wir haben den klassischen maschinellen Lernalgorithmus über denselben Testzeitraum laufen lassen, den wir zur Ermittlung unserer Kontrollrentabilitätswerte verwendet haben.
Abbildung 5: Durchführung des ersten Versuchs, das Kontrollsystem zu übertreffen
Das Rentabilitätsniveau unserer Handelsanwendung hat sich drastisch verschlechtert. Obwohl die Strategie eine hohe Genauigkeit zeigte, da 63 % aller von ihr platzierten Handelsgeschäfte profitabel waren, ist dies kaum beeindruckend, da sie das in dem Kontrollsystem festgelegte Gewinnniveau von 71 $ nicht übertraf.
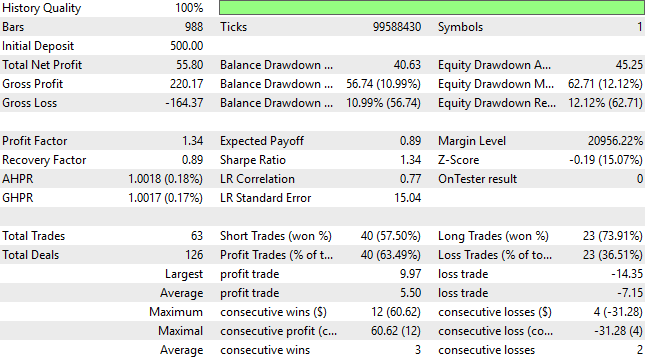
Abbildung 6: Eine detaillierte Analyse unseres ersten Versuchs, das Kontrollsystem zu übertreffen
Die überarbeitete Anwendung, die wir entwickelt haben, erreicht nicht die gleiche Höhe wie die ursprüngliche Version der Handelsstrategie. Fairerweise muss man aber auch erwähnen, dass diese Version unserer Anwendung weit weniger volatil und zuverlässiger zu sein scheint als die ursprüngliche Strategie.
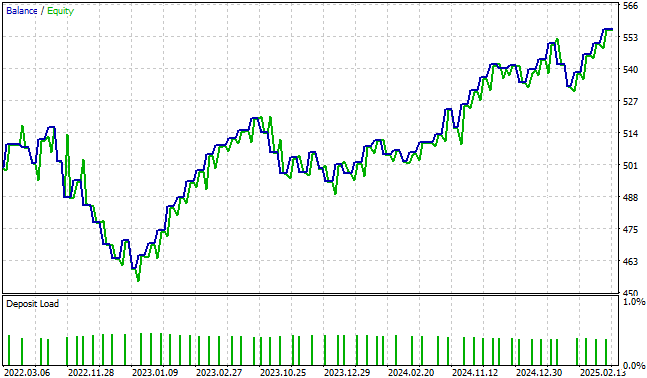
Abbildung 7: Die von der verbesserten Version unserer Handelsanwendung erzeugte Kapitalkurve ist weniger volatil als die ursprüngliche Strategie, erreicht aber auch nicht die gleichen Höhen
Den klassischen Versuch an seine Grenzen bringen
Erinnern Sie sich daran, dass wir das Ziel für 1, 5 und 10 Kerzen in die Zukunft prognostizieren. Wir wollen sehen, ob die Vorhersage für 10 Kerzen informativer ist als die einfache Vorhersage für einen Schritt, mit der wir begonnen haben. Daher werden wir uns wie zuvor nur auf die Teile der Handelsanwendung konzentrieren, die für einen fairen Vergleich geändert werden mussten.
if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { if(model_prediction[ 2 ]>iClose(Symbol(),TF_2,0)) Trade.Buy(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { if(model_prediction[ 2 ]<iClose(Symbol(),TF_2,0)) Trade.Sell(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); }
Wie bei dem Kontrollsystem der Handelsanwendung werden wir das gleiche 3-Jahres-Fenster wählen, um unsere Anwendung zu testen.
Abbildung 8: Denken Sie daran, dass alle Backtests über denselben Zeitraum durchgeführt werden müssen, um sicherzustellen, dass die Strategie die Zeit wirklich besser nutzt.
In den meisten Büchern, in denen Praktiker lernen, wie man Finanzmärkte mithilfe von maschinellem Lernen prognostiziert, wird die Vorhersage eines Schrittes in die Zukunft als Standardverfahren gelehrt. Gewinnbringende menschliche Händler versuchen jedoch selten, jeweils nur eine Kerze zu handeln, und wie wir in diesem Artikel zeigen, scheinen auch unsere Modelle profitabler zu sein, wenn sie über die unmittelbare Kerze hinausblicken dürfen. Der Leser sollte wissen, dass wir in diesem Beitrag zum ersten Mal die Ergebnisse des Kontrollsystems übertreffen.
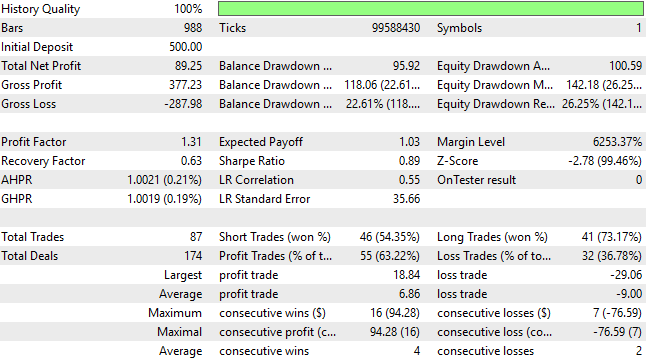
Abbildung 9: Die Vorhersage von 10 Schritten in die Zukunft war für uns profitabler als die Vorhersage von nur einem Schritt in die Zukunft.
Die unerwünschte Volatilität unserer Kapitalkurve wurde natürlich korrigiert. Das ist auf jeden Fall ermutigend, aber wie der Leser bald sehen wird, können wir noch besser abschneiden als das.
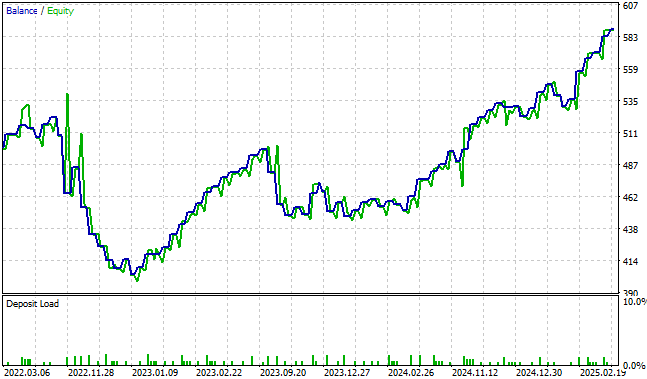
Abbildung 10: Die Kapitalkurve, die durch die zweite Iteration unserer Handelsanwendung erzeugt wird, ist besser als die des Kontrollsystems, aber wir werden dem Leser nun zeigen, wie man dies zu neuen Höhen führen kann
Neuer Raum für Verbesserungen
Wir sind nun bereit, die Vorhersagen unseres Modells in mehreren Zeitschritten in die Zukunft zu vergleichen. Wir vergleichen, wo das Modell den Höchstpreis in 1 und 10 Schritten erwartet, und verwenden dann das erwartete Wachstum dieses Preisniveaus als unser Handelssignal. if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { if(model_prediction[3]<model_prediction[5]) Trade.Buy(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { if(model_prediction[3]>model_prediction[5]) Trade.Sell(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); }
Wir wollen prüfen, ob es sinnvoll ist, die Vorhersagen des Modells über mehrere Zeithorizonte hinweg mit einfacheren direkten Vergleichen zwischen den Vorhersagen des Modells und dem tatsächlichen Wert des Ziels zu vergleichen.
Abbildung 11: Ausführung der dritten Version unserer Handelsanwendung während des dreijährigen Backtestzeitraums
Wie der Leser sehen kann, sprechen die Ergebnisse, die wir erzielt haben, fast für sich selbst. Unsere Anwendung ist jetzt rentabler als jemals zuvor in unserem Entwicklungszyklus. Zur Erinnerung: Wir verwenden dasselbe ONNX-Modell, das wir zuvor exportiert haben. Und daran, dass sich die Grundlagen unserer Handelsbedingungen nicht geändert haben. Vielmehr scheinen wir durch eine sorgfältige Interpretation der Vorhersagen unseres Modells mehr Alpha aus der gleichen Handelsstrategie herauszuholen.
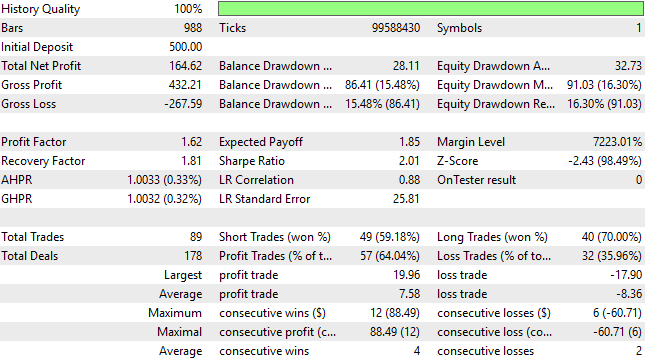
Abbildung 12: Die detaillierten Statistiken, die von der dritten Version unserer Handelsanwendung erstellt wurden, geben uns die Gewissheit, dass wir vernünftige Änderungen an der Anwendung vorgenommen haben
Unsere Kapitalkurve steigt kontinuierlich auf neue Höchststände, die weit über den Bereich des Kontrollsystems unserer Handelsanwendung oder eines der Rentabilitätsniveaus hinausgehen, die wir mit dem klassischen Ansatz des maschinellen Lernens im Finanzbereich ermitteln konnten.
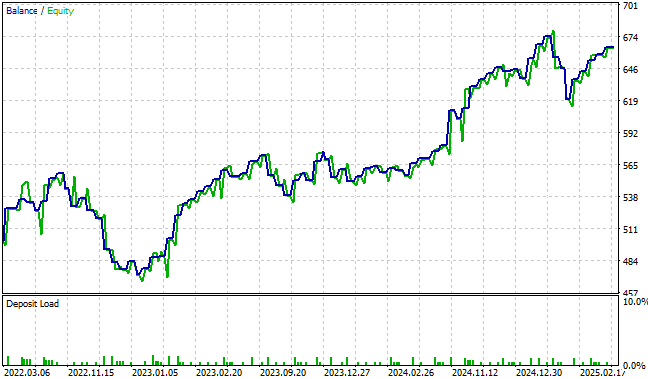
Abbildung 13: Die von der aktuellen Iteration unserer Handelsanwendung erzeugte Kapitalkurve erreicht neue Höchststände, die wir in allen früheren Versionen der Anwendung nicht erreichen konnten.
Letzte Verbesserungen
Als Autor macht es mir Spaß, nach Marktstrukturen zu suchen, die sich leichter vorhersagen lassen als die Preise selbst, aber ebenso informativ sind wie die Kenntnis der künftigen Preisniveaus. Angesichts der Tatsache, dass wir es mit einem Kanal der gleitenden Durchschnitte der Hochs und Tiefs zu tun haben, führte mich meine Intuition zu der Frage, ob das Wachstum in der Mitte zwischen diesen beiden gleitenden Durchschnitten nicht einfacher zu prognostizieren sein könnte. Dies scheint bei dieser Diskussion definitiv der Fall gewesen zu sein.
if(iHigh(Symbol(),TF_2,1)<iOpen(Symbol(),TF_2,0)) { if(((model_prediction[3]+model_prediction[6])/2)<((model_prediction[5]+model_prediction[8])/2)) Trade.Buy(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); Trade.Buy(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetAsk(),TradeHandler.GetBid()-padding,TradeHandler.GetBid()+padding); } if(iLow(Symbol(),TF_2,1)>iOpen(Symbol(),TF_2,0)) { if(((model_prediction[3]+model_prediction[6])/2)>((model_prediction[5]+model_prediction[8])/2)) Trade.Sell(TradeHandler.MinVolume()*2,TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); Trade.Sell(TradeHandler.MinVolume(),TradeHandler.GetSymbol(),TradeHandler.GetBid(),TradeHandler.GetAsk()+padding,TradeHandler.GetAsk()-padding); }
Führen Sie die endgültige Version unserer Anwendung über das gleiche 3-Jahres-Fenster aus, mit dem wir bisher gearbeitet haben.

Abbildung 14: Durchführung der endgültigen Version unserer Handelsanwendung, um zu versuchen, alle vorherigen Iterationen, die wir bisher erstellt haben, zu übertreffen
Wie wir unten sehen können, hat unsere Anwendung durchweg neue Leistungsstufen erreicht, die für uns unerreichbar waren, als wir diese Diskussion begannen. Es scheint, dass die endgültige Version der Anwendung, die wir bisher erstellt haben, die Mühe wert war, die wir in die Erstellung gesteckt haben.
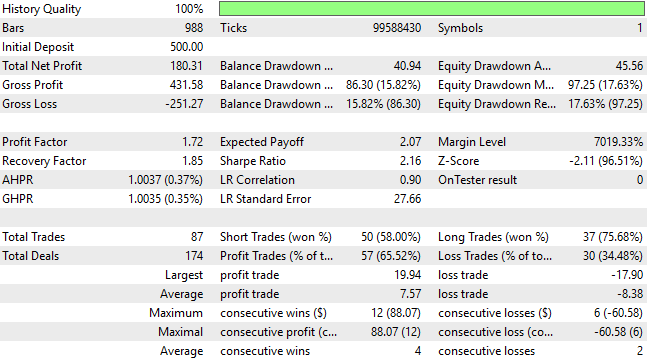
Abbildung 15: Die endgültigen detaillierten Leistungswerte unserer Anwendung übertreffen alle anderen Leistungswerte, die wir zuvor in unserem Ausarbeitung ermittelt haben
Die Volatilität, die wir in unserer Kapitalkurve beobachten, ist fast vollständig unter unserer Kontrolle. Es kann bemerkenswert sein, wie viel Gewinn erzielt werden kann, ohne dass Ihre Handelsstrategien für maschinelles Lernen an Komplexität gewinnen.
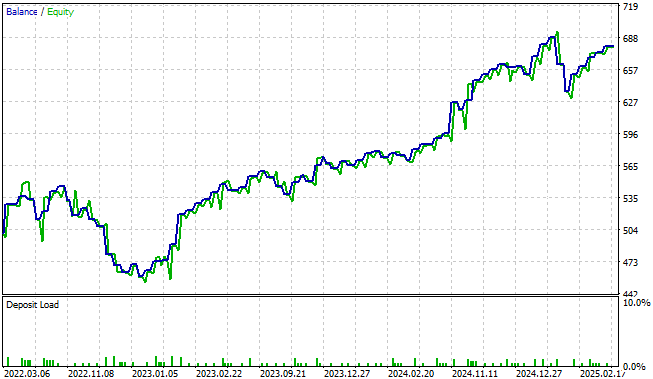
Abbildung 16: Die Visualisierung der Kapitalkurve, die von der endgültigen Version unserer Handelsanwendung erzeugt wird, gibt uns Vertrauen in alle Änderungen, die wir bisher vorgenommen haben
Schlussfolgerung
Die Idee der Vorhersage mehrerer Zeitschritte ist in der algorithmischen Handelswelt nicht neu. Neu ist – und darauf beharrt dieser Artikel – die Perspektive, dass Vorhersagen von mehreren Zeitschritten nicht als eine alternative Technik, sondern vielmehr als ein möglicher Goldstandard für den algorithmischen Handel selbst angesehen werden sollten.
Weiter oben habe ich Ihnen, dem Leser, eine Frage gestellt. Ich habe gezeigt, dass die lineare Regression aus geometrischer Sicht nichts anderes ist als eine Folge von Rotationen und Skalierungen. Dann habe ich gefragt: Wo findet das Lernen wirklich statt?
Den Lesern, die sich immer noch an diese Frage erinnern, muss ich eine mögliche Hypothese anbieten – obwohl ich es stark bevorzuge, dass Sie unbeeinflusst bleiben, um Ihre eigenen zu entdecken.
Das Prinzip, das in diesem Artikel demonstriert wird, ist, dass mathematische Konzepte immer geometrische Entsprechungen haben. Jedes denkbare Modell für maschinelles Lernen kann als koordinierte Akrobatik aus Skalierung, Spiegelung, Projektion, Faltung und Drehung umgedeutet werden, die auf die durch die Daten selbst definierten Mannigfaltigkeiten angewendet wird. Selbst fortgeschrittene neuronale Netze sind nicht geheimnisvoll: Sie sind einfach ausgeklügelte Choreografien geometrischer Transformationen, die Daten immer wieder falten und umformen.
Die Antwort auf die Frage „Wo findet das Lernen statt?“ könnte daher lauten: Lernen findet statt, wenn Informationen in geometrischen Mustern kodiert werden. Der Zyklus von Rotation und Skalierung ist eines der elementarsten dieser Muster. Es ist eine kraftvolle geometrische Struktur in demselben Sinne, wie die drei Grundfarben die Grundlage für alle anderen Farben bilden. In der Geometrie gibt es primäre Transformationen, aus denen alle anderen zusammengesetzt sind.
Die Bildklassifizierungsbranche hat sich bereits auf diese Realität eingestellt. Ihr Erfolg beruht auf langen und detaillierten Vorverarbeitungspipelines – Pipelines, die im Wesentlichen aus einer sorgfältigen Orchestrierung geometrischer Transformationen bestehen. Sie mögen als routinemäßiges Feature-Engineering erscheinen, aber in Wahrheit sind sie die stille Anwendung eben dieser Prinzipien, oft ohne dass man sich ihrer tieferen Bedeutung bewusst ist.
Und so geht der Leser mit wertvollen Erkenntnissen nach Hause: Mehrstufige Prognosen im Handel sind vielleicht eine der am meisten unterschätzten Strategien in unserem Bereich, gerade weil sie weit mehr Arbeit leisten, als ihr wirklich zugetraut wird. Mehrstufige Vorhersagen stellen sicher, dass wir unsere Vergleiche im gleichen Koordinatensystem durchführen. Andernfalls ist der direkte Vergleich der Vorhersagen Ihres Modells mit dem tatsächlichen Wert des Ziels gleichbedeutend mit dem Vergleich zweier Größen, die garantiert nicht in denselben Einheiten vorliegen.
| Dateiname | Beschreibung der Datei |
|---|---|
| Fetch_Data_MA_2.1.mq5 | Das MQL5-Skript, das wir verwendet haben, um historische Daten von unserem MetaTrader 5-Terminal abzurufen. |
| MFH_Baseline.mq5 | Die Basisversion unserer Handelsstrategie, die keine maschinellen Lernmodelle verwendet. |
| MFH_1.1.mq5 | Der erste Versuch, eine Handelsanwendung zu entwickeln, folgte ausschließlich den klassischen Paradigmen des maschinellen Lernens im Finanzbereich. |
| MFH_1.2.mq5 | Der letzte Versuch, den wir unternommen haben, war der Aufbau einer Handelsanwendung unter Verwendung der klassischen Paradigmen des maschinellen Lernens im Finanzbereich. |
| MFH_1.3.mq5 | Der erste Versuch, den wir unternommen haben, bestand darin, keine direkten Vergleiche zwischen dem aktuellen Preis und dem prognostizierten Preis anzustellen. |
| MFH_1.4.mq5 | Die endgültige Version unserer Handelsstrategie, die zu den höchsten Rentabilitätsniveaus führte, haben wir in diesem Artikel vorgestellt. |
| Multiple_Forecast_Horizons.ipynb | Das Jupyter-Notebook, das wir für den Export unseres ONNX-Modells verwendet haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/19383
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
EURUSD MFH LR D1.onnx