
Reimaginando las estrategias clásicas en MQL5 (Parte X): ¿Puede la IA impulsar el MACD?

El cruce de medias móviles es probablemente una de las estrategias de trading más antiguas que existen. La convergencia/divergencia de la media móvil (Moving Average Convergence Divergence, MACD) es un indicador muy popular que se basa en el concepto de cruces de medias móviles. Hay muchos miembros nuevos en nuestra comunidad que pueden sentir curiosidad por conocer el poder predictivo del indicador MACD, en su búsqueda por crear la mejor estrategia de trading posible. Además, hay analistas técnicos experimentados que utilizan el MACD en sus estrategias y que pueden tener la misma pregunta en mente. Este artículo le presentará un análisis empírico del poder predictivo del indicador sobre el par EURUSD. Además, le proporcionaremos técnicas de modelización que podrá utilizar para mejorar su análisis técnico con IA.
Resumen de la estrategia comercial
El indicador MACD se utiliza principalmente para identificar las tendencias del mercado y medir el impulso de las mismas. El indicador fue creado en la década de 1970 por el difunto Gerrald Appel. Appel era gestor financiero para sus clientes privados, y su éxito se basaba en su enfoque técnico del análisis bursátil. Él inventó el indicador MACD hace aproximadamente 50 años.

Figura 1: Gerald Appel, creador del indicador MACD.
Los analistas técnicos utilizan el indicador para identificar los puntos de entrada y salida de diversas maneras. La figura 2 a continuación es una captura de pantalla del indicador MACD aplicado al par GBPUSD utilizando su configuración predeterminada. El indicador está incluido de forma predeterminada en la instalación de MetaTrader 5. La línea roja, denominada MACD principal, se calcula mediante la diferencia entre dos medias móviles, una rápida y otra lenta. Siempre que la línea principal cruza por debajo de 0, es muy probable que el mercado se encuentre en una tendencia bajista, y lo contrario ocurre cuando la línea cruza por encima de 0.
Del mismo modo, la línea principal también se puede utilizar para identificar la fortaleza del mercado. Solo la apreciación de los niveles de precios provocará un aumento del valor de la línea principal y, por el contrario, la depreciación de los niveles de precios provocará una caída de la línea principal. Por lo tanto, los puntos de inflexión, en los que la línea principal forma una figura parecida a una copa, se crean por un cambio en el impulso del mercado. Se han implementado diversas estrategias de trading en torno al MACD. Las estrategias más elaboradas y sofisticadas buscan identificar la divergencia del MACD.
La divergencia MACD se produce cuando los niveles de precios suben en una tendencia fuerte, rompiendo nuevos niveles extremos. Por otro lado, el indicador MACD muestra una tendencia que se vuelve cada vez más plana y comienza a caer, en marcado contraste con la fuerte acción del precio que se observa en el gráfico. Por lo general, la divergencia del MACD se interpreta como una señal temprana de inversión de tendencia, lo que permite a los operadores cerrar sus posiciones abiertas antes de que los mercados se vuelvan más volátiles.
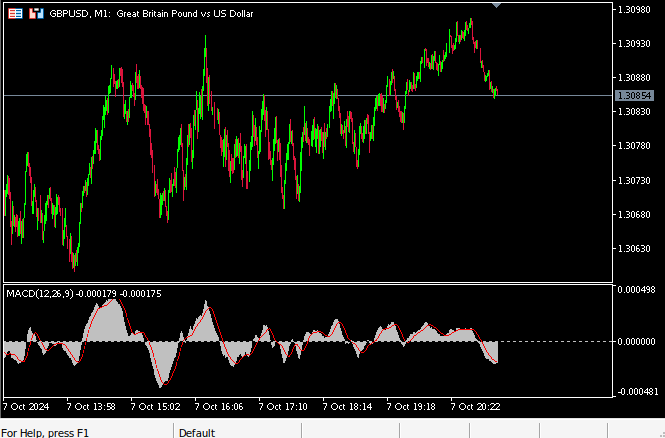
Figura 2: El indicador MACD con su configuración predeterminada en el gráfico M1 del GBPUSD.
Hay muchos escépticos que cuestionan el uso del indicador MACD en su conjunto. Empecemos por abordar el tema que todos tenemos en mente. Todos los indicadores técnicos se agrupan como indicadores rezagados. Esto significa que los indicadores técnicos solo cambian después de que cambian los niveles de precios, no pueden cambiar antes de los niveles de precios. Los indicadores macroeconómicos, como los niveles de inflación mundial, y las noticias geopolíticas, como el estallido de una guerra o un desastre natural, pueden afectar los niveles de oferta y demanda. Se consideran indicadores adelantados porque pueden cambiar rápidamente antes de que los niveles de precios reflejen ese cambio.
Muchos operadores opinan que estas señales rezagadas probablemente harán que los operadores entren en sus posiciones cuando el movimiento del mercado ya se haya agotado. Además, es habitual observar reversiones de tendencia que no han sido precedidas por divergencias del MACD. Y en el mismo sentido, también es posible observar una divergencia del MACD que no fue seguida por un cambio de tendencia.
Estos hechos nos llevan a cuestionar la fiabilidad del indicador y si realmente tiene algún poder predictivo digno de mérito. Deseamos evaluar si es posible superar el retraso inherente al indicador utilizando inteligencia artificial. Si el indicador MACD resulta ser resistente, integraremos un modelo de IA que:
- Utiliza los valores del indicador para pronosticar los niveles de precios futuros.
- Pronostica el indicador MACD en sí mismo.
Dependiendo del enfoque de modelado se obtiene un error menor. De lo contrario, si nuestro análisis sugiere que el MACD podría no tener capacidad predictiva en nuestra estrategia actual, optaremos por el modelo con mejor rendimiento a la hora de pronosticar los niveles de precios.
Resumen de la metodología
Nuestro análisis comenzó con un script personalizado escrito en MQL5 para obtener exactamente 100.000 filas de cotizaciones de mercado M1 sobre el EURUSD y sus correspondientes señales MACD y valores principales en un archivo CSV. A juzgar por nuestras visualizaciones de datos, el indicador MACD parece ser un mal separador de los niveles de precios futuros. Los cambios en los niveles de precios probablemente sean independientes del valor del indicador. Además, el cálculo del indicador dio a los datos una estructura no lineal y compleja que puede ser difícil de modelar.
Los datos que obtuvimos de nuestra terminal MetaTrader 5 se dividieron en dos mitades. Utilizamos la primera mitad para estimar la precisión de nuestro modelo mediante validación cruzada de 5 veces. Posteriormente, creamos tres modelos idénticos de redes neuronales profundas y los entrenamos con tres subconjuntos diferentes de nuestros datos:
- Modelo de precios: Previsión de los niveles de precios utilizando las cotizaciones de mercado OHLC de MetaTrader 5.
- Modelo MACD: Pronosticar los valores del indicador MACD utilizando cotizaciones OHLC y la lectura MACD.
- Modelo completo: Previsión de los niveles de precios utilizando cotizaciones OHLC y el indicador MACD.
La segunda mitad de la partición se utilizó para probar los modelos. El primer modelo obtuvo la mayor precisión en la prueba, con un 69%. Nuestros algoritmos de selección de características sugirieron que las cotizaciones de mercado que obtuvimos de MetaTrader 5 eran más informativas que los valores MACD.
Así, comenzamos a optimizar el mejor modelo que teníamos, un modelo de regresión que pronosticaba el precio futuro del par EURUSD. Sin embargo, rápidamente nos encontramos con problemas porque nuestro modelo aprendió el ruido presente en nuestros datos de entrenamiento. No logramos superar una regresión lineal simple en el conjunto de pruebas. Por lo tanto, sustituimos el modelo sobreoptimizado por una máquina de vectores de soporte (Support Vector Machine, SVM).
Posteriormente, exportamos nuestro modelo SVM al formato ONNX y creamos un asesor experto utilizando un enfoque combinado de previsión de los niveles futuros del precio del EURUSD y el indicador MACD.
Obtención de los datos que necesitamos
Para empezar, nuestra primera parada fue el entorno de desarrollo integrado (IDE) MetaEditor. Hemos creado el script que se describe a continuación para obtener nuestros datos de mercado desde el terminal MetaTrader 5. Solicitamos 100.000 filas de datos históricos M1 y los exportamos a formato CSV. El siguiente script rellenará nuestro archivo CSV con los valores de hora, apertura, máximo, mínimo, cierre (Time, Open, High, Low, Close), y los dos valores MACD. Simplemente arrastre y suelte el script sobre cualquier par que desee analizar, si desea seguirnos.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int indicator_handler; double indicator_buffer[]; double indicator_buffer_2[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator indicator_handler = iMACD(Symbol(),PERIOD_CURRENT,12,26,9,PRICE_CLOSE); CopyBuffer(indicator_handler,0,0,size,indicator_buffer); CopyBuffer(indicator_handler,1,0,size,indicator_buffer_2); ArraySetAsSeries(indicator_buffer,true); ArraySetAsSeries(indicator_buffer_2,true); //--- File name string file_name = "Market Data " + Symbol() +" MACD " + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MACD Main","MACD Signal"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), indicator_buffer[i], indicator_buffer_2[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Preprocesamiento de datos
Ahora que hemos exportado nuestros datos en formato CSV, leamos los datos en nuestro espacio de trabajo de Python. Primero cargaremos las bibliotecas que necesitamos.
#Load libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Leer los datos.
#Read in the data data = pd.read_csv("Market Data EURUSD MACD .csv")
Define hasta qué punto en el futuro debemos pronosticar.
#Forecast horizon look_ahead = 20
Agreguemos objetivos binarios a la bandera si la lectura actual es mayor que las 20 instancias anteriores, tanto para el precio de cierre del EURUSD como para la línea principal del MACD.
#Let's add labels data["Bull Bear"] = np.where(data["Close"] < data["Close"].shift(look_ahead),0,1) data["MACD Bull"] = np.where(data["MACD Main"] < data["MACD Main"].shift(look_ahead),0,1) data = data.loc[20:,:] data
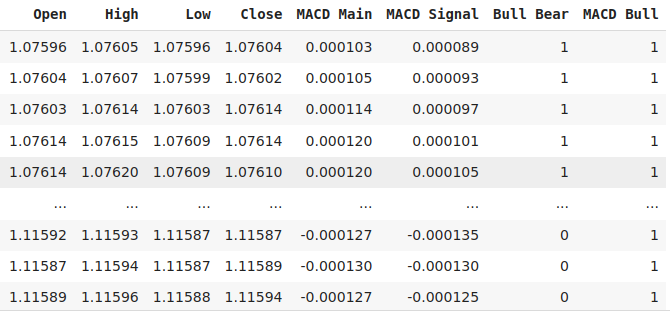
Figura 3: Algunas de las columnas de nuestro marco de datos.
Además, necesitamos definir nuestros valores objetivo.
data["MACD Target"] = data["MACD Main"].shift(-look_ahead) data["Price Target"] = data["Close"].shift(-look_ahead) data["MACD Binary Target"] = np.where(data["MACD Main"] < data["MACD Target"],1,0) data["Price Binary Target"] = np.where(data["Close"] < data["Price Target"],1,0) data = data.iloc[:-20,:]
Análisis exploratorio de datos
Los gráficos de dispersión nos ayudan a visualizar la relación entre una variable dependiente y una independiente. El gráfico a continuación nos muestra que definitivamente existe una relación entre los niveles de precios futuros y la lectura MACD actual, el desafío es que la relación no es lineal y parece tener una estructura compleja. No es inmediatamente obvio qué cambios en el indicador MACD resultan en un desempeño del precio alcista o bajista.
sns.scatterplot(data=data,x="MACD Main",y="MACD Signal",hue="Price Binary Target")
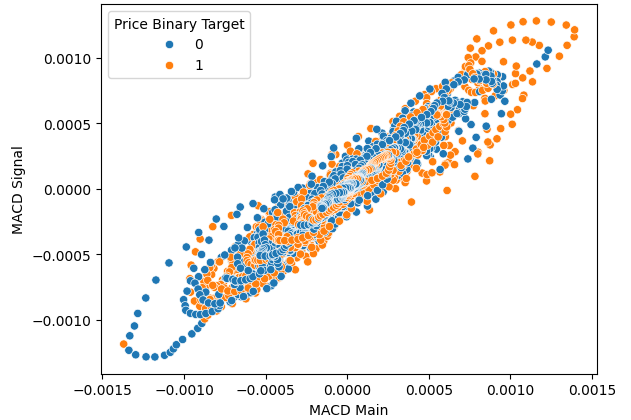
Figura 4: Visualización de la relación entre el indicador MACD y los niveles de precios.
Realizar un gráfico 3D solo demuestra aún más cuán complicada es realmente la relación. No hay límites definidos, por lo que esperaríamos que los datos fueran difíciles de clasificar. La única deducción inteligente que podemos extraer de nuestro gráfico es que los mercados parecen agruparse rápidamente hacia el centro después de atravesar niveles extremos en el MACD.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["MACD Main"],data["MACD Signal"],data["Close"],c=data["Price Binary Target"]) ax.set_xlabel("MACD Main") ax.set_ylabel("MACD Signal") ax.set_zlabel("EURUSD Close")
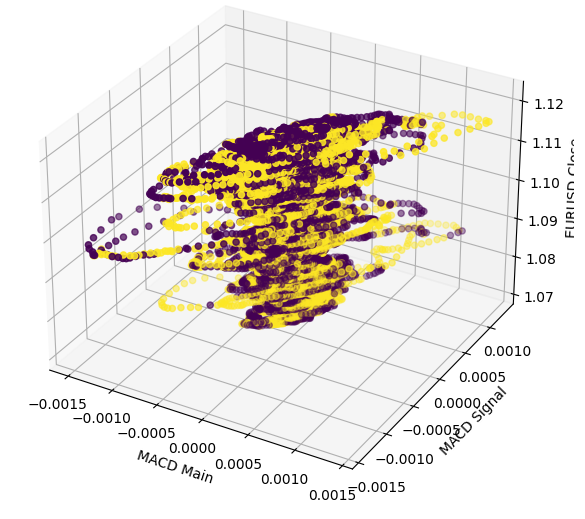
Figura 5: Visualización de la interacción entre el indicador MACD y el mercado EURUSD.
Los gráficos de violín nos permiten, simultáneamente, visualizar la distribución de datos y comparar 2 distribuciones. El contorno azul representa un resumen de la distribución observada de los niveles de precios futuros después de que el MACD haya subido o bajado. En la figura 6 a continuación, queríamos comprender si el aumento o la caída del indicador MACD está asociado con diferentes distribuciones con respecto a los movimientos de precios futuros. Como podemos ver, las dos distribuciones parecen casi idénticas. Además, el núcleo de cada distribución tiene un diagrama de caja. Los valores medios de ambos diagramas de caja parecen casi iguales, independientemente de si el indicador estaba en un estado alcista o bajista.
sns.violinplot(data=data,x="MACD Bull",y="Close",hue="Price Binary Target",split=True,fill=False)
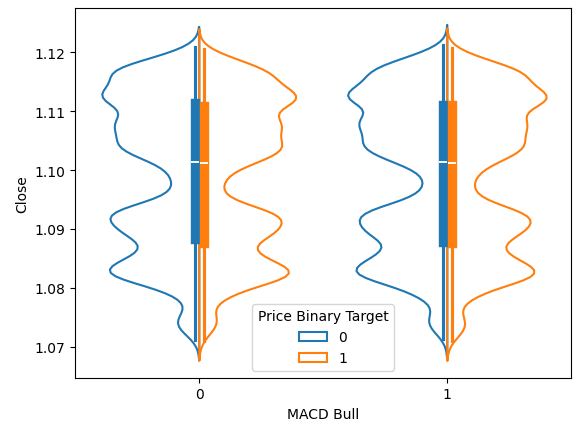
Figura 6: Visualización del efecto del indicador MACD en los niveles de precios futuros.
Preparación para modelar los datos
Ahora comencemos a modelar nuestros datos, primero y principal necesitamos importar nuestras bibliotecas.
#Perform train test splits from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.metrics import accuracy_score train,test = train_test_split(data,test_size=0.5,shuffle=False)
Ahora definiremos los predictores y el objetivo.
#Let's scale the data ohlc_predictors = ["Open","High","Low","Close","Bull Bear"] macd_predictors = ["MACD Main","MACD Signal","MACD Bull"] all_predictors = ohlc_predictors + macd_predictors cv_predictors = [ohlc_predictors,macd_predictors,all_predictors] #Define the targets cv_targets = ["MACD Binary Target","Price Binary Target","All"]
Escalando los datos.
#Scaling the data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train[all_predictors])
train_scaled = pd.DataFrame(scaler.transform(train[all_predictors]),columns=all_predictors)
test_scaled = pd.DataFrame(scaler.transform(test[all_predictors]),columns=all_predictors) Carguemos las librerías que necesitamos.
#Import the models we will evaluate
from sklearn.neural_network import MLPClassifier,MLPRegressor
from sklearn.linear_model import LinearRegression Crear el objeto de división de series de tiempo.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) Los índices de nuestro marco de datos se asignarán al conjunto de entradas que estábamos evaluando.
err_indexes = ["MACD Train","Price Train","All Train","MACD Test","Price Test","All Test"]
Ahora crearemos el marco de datos que registrará nuestras estimaciones de la precisión del modelo a medida que cambiamos nuestras entradas.
#Now let us define a table to store our error levels columns = ["Model Accuracy"] cv_err = pd.DataFrame(columns=columns,index=err_indexes)
Restablecer todos nuestros índices.
#Reset index
train = train.reset_index(drop=True)
test = test.reset_index(drop=True) Validemos de forma cruzada el modelo. Validaremos de forma cruzada el modelo en el conjunto de entrenamiento y luego registraremos su precisión en el conjunto de prueba sin ajustarlo a él.
#Initailize the model price_model = MLPClassifier(hidden_layer_sizes=(10,6)) macd_model = MLPClassifier(hidden_layer_sizes=(10,6)) all_model = MLPClassifier(hidden_layer_sizes=(10,6)) price_acc = [] macd_acc = [] all_acc = [] #Cross validate each model twice for j,(train_index,test_index) in enumerate(tscv.split(train_scaled)): #Fit the models price_model.fit(train_scaled.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Binary Target"]) macd_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"MACD Binary Target"]) all_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"Price Binary Target"]) #Store the accuracy price_acc.append(accuracy_score(train.loc[test_index,"Price Binary Target"],price_model.predict(train_scaled.loc[test_index,ohlc_predictors]))) macd_acc.append(accuracy_score(train.loc[test_index,cv_targets[0]],macd_model.predict(train_scaled.loc[test_index,all_predictors]))) all_acc.append(accuracy_score(train.loc[test_index,cv_targets[1]],all_model.predict(train_scaled.loc[test_index,all_predictors]))) #Now we can store our estimates of the model's error cv_err.iloc[0,0] = np.mean(price_acc) cv_err.iloc[1,0] = np.mean(macd_acc) cv_err.iloc[2,0] = np.mean(all_acc) #Estimating test error cv_err.iloc[3,0] = accuracy_score(test[cv_targets[1]],price_model.predict(test_scaled[ohlc_predictors])) cv_err.iloc[4,0] = accuracy_score(test[cv_targets[0]],macd_model.predict(test_scaled[all_predictors])) cv_err.iloc[5,0] = accuracy_score(test[cv_targets[1]],all_model.predict(test_scaled[all_predictors]))
| Grupo de entradas | Precisión del modelo |
|---|---|
| Entrenamiento MACD | 0.507129 |
| Entrenamiento OHLC | 0.690267 |
| Todo el entrenamiento | 0.504577 |
| Prueba MACD | 0.48669 |
| Prueba OHLC | 0.684069 |
| Todas las pruebas | 0.487442 |
Importancia de las características
Intentemos ahora estimar los niveles de importancia de las características para nuestra red neuronal profunda. Seleccionaremos la importancia de la permutación para interpretar nuestro modelo. La importancia de la permutación define la importancia de cada entrada mezclando primero los valores de esa columna de entrada y luego evaluando los cambios en la precisión del modelo. La idea es que las características importantes causarán grandes caídas en el error, mientras que las características no importantes causarán cambios en la precisión del modelo cercanos a cero.
Sin embargo, hay algunas consideraciones que deben hacerse. En primer lugar, el algoritmo de importancia de permutación baraja aleatoriamente cada una de las entradas del modelo. Esto significa que el algoritmo puede mezclar aleatoriamente el precio de apertura y establecerlo más alto que el precio alto. Obviamente esto no es posible en el mundo real. Por lo tanto, debemos interpretar los resultados del algoritmo con cautela. Se podría decir que el algoritmo es parcial porque evalúa la importancia de las características en condiciones simuladas que potencialmente nunca podrían ocurrir, penalizando innecesariamente el modelo. Además, debido a la naturaleza estocástica de los algoritmos de optimización utilizados para ajustar las redes neuronales modernas, entrenar las mismas redes neuronales con el mismo conjunto de datos podría generar explicaciones notablemente diferentes cada vez.
#Let us try assess feature importance from sklearn.inspection import permutation_importance from sklearn.linear_model import RidgeClassifier
Ahora ajustaremos nuestro objeto de importancia de permutación en nuestro modelo de red neuronal profunda entrenado. Tienes la opción de pasar los datos de entrenamiento o de prueba para que se barajen, nosotros elegimos los datos de prueba. Luego, organizamos los datos según el orden de caída en la precisión ocasionada y graficamos los resultados. La figura 7 a continuación muestra los puntajes de importancia de permutación observados. Podemos ver que los efectos de mezclar las entradas relacionadas con el MACD aparecen muy cerca de 0, lo que implica que las columnas del MACD no son tan importantes para nuestro modelo.
#Let us fit the model model = MLPClassifier(hidden_layer_sizes=(10,6)) model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"]) #Calculate permutation importance scores pi = permutation_importance( model, test_scaled.loc[:,all_predictors], test.loc[:,"Price Binary Target"], n_repeats=10, random_state=42, n_jobs=-1 ) #Sort the importance scores sorted_importances_idx = pi.importances_mean.argsort() importances = pd.DataFrame( pi.importances[sorted_importances_idx].T, columns=test_scaled.columns[sorted_importances_idx], ) #Create the plot ax = importances.plot.box(vert=False, whis=10) ax.set_title("Permutation Importances (test set)") ax.axvline(x=0, color="k", linestyle="--") ax.set_xlabel("Decrease in accuracy score") ax.figure.tight_layout()
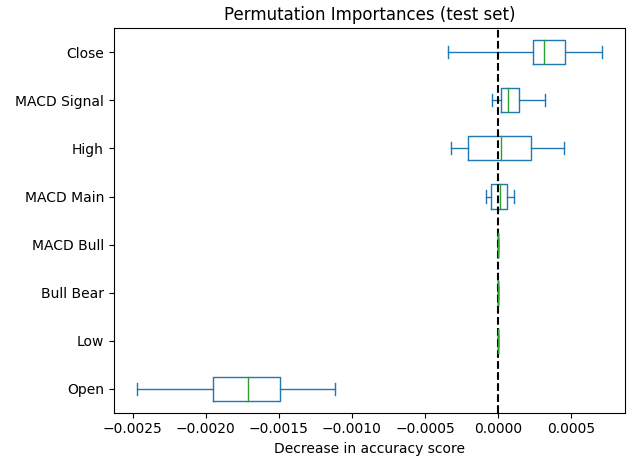
Figura 7: Nuestras puntuaciones de importancia de permutación clasificaron el precio de cierre como la característica más importante.
Ajustar un modelo más simple también podría darnos una idea de los niveles de importancia de las entradas. El clasificador de cresta es un modelo lineal que acerca sus coeficientes cada vez más a 0 en la dirección que minimiza su error. Por lo tanto, asumiendo que sus datos han sido estandarizados y escalados, las características sin importancia tendrán los coeficientes de cresta más pequeños. Si tenía curiosidad, el clasificador de cresta puede lograr esto extendiendo el modelo lineal ordinario para incluir un término de penalización proporcional a la suma al cuadrado de los coeficientes del modelo. Esto se conoce comúnmente como regularización L2.
#Let us fit the model model = RidgeClassifier() model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"])
Ahora grafiquemos los coeficientes del modelo.
ridge_importance = pd.DataFrame(model.coef_.tolist(),columns=all_predictors) #Prepare the plot fig,ax = plt.subplots(figsize=(10,5)) sns.barplot(ridge_importance,ax=ax)
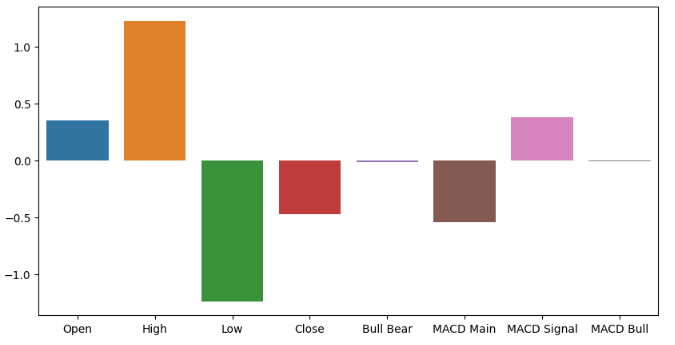
Figura 8: Nuestros coeficientes de cresta nos sugieren que el precio alto y el precio bajo son las características más informativas que tenemos.
Ajuste de parámetros
Ahora intentaremos optimizar nuestro modelo con mejor rendimiento. Sin embargo, como dijimos anteriormente, nuestra rutina de optimización no tuvo éxito en este turno. Desafortunadamente, esto es inherente a la naturaleza de los algoritmos de optimización, no tenemos garantía de encontrar soluciones. Realizar la optimización de parámetros no significa necesariamente que el modelo obtenido al final será mejor, solo estamos intentando aproximar los parámetros óptimos del modelo. Carguemos las librerías que necesitamos.
#Let's tune our model further from sklearn.model_selection import RandomizedSearchCV
Definiendo el modelo.
#Reinitialize the model model = MLPRegressor(max_iter=200)
Ahora definiremos el objeto sintonizador. El objeto evaluará nuestro modelo bajo diferentes parámetros de inicialización y devolverá un objeto que contiene las entradas con mejor rendimiento encontradas.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation" : ["relu","logistic","tanh","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"learning_rate":['constant','adaptive','invscaling'],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"hidden_layer_sizes":[(2,4,8,2),(10,20),(5,10),(2,20),(6,8,10),(1,5),(20,10),(8,4),(2,4,8),(10,5)],
"early_stopping":[True,False],
"warm_start":[True,False],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) Ajuste del objeto sintonizador.
tuner.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) Los mejores parámetros que encontramos.
tuner.best_params_
'tol': 0.01,
'solver': 'sgd',
'shuffle': False,
'learning_rate_init': 0.01,
'learning_rate': 'constant',
'hidden_layer_sizes': (20, 10),
'early_stopping': True,
'alpha': 1e-07,
'activation': 'identity'}
Optimización más profunda
Podemos buscar aún más a fondo para obtener mejores configuraciones de entrada empleando la biblioteca SciPy. La usaremos para estimar los resultados de la optimización global sobre los parámetros continuos del modelo.#Deeper optimization from scipy.optimize import minimize from sklearn.metrics import mean_squared_error from sklearn.model_selection import TimeSeriesSplit
Define el objeto de división de series de tiempo.
#Define the time series split object tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)
Crear estructuras de datos para almacenar nuestros niveles de precisión.
#Create a dataframe to store our accuracy current_error_rate = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) algorithm_progress = []
Nuestra función de costo a minimizar serán los niveles de error del modelo en los datos de entrenamiento.
#Define the objective function def objective(x): #The parameter x represents a new value for our neural network's settings model = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=x[0], tol=x[1], learning_rate_init=x[2] ) #Now we will cross validate the model for i,(train_index,test_index) in enumerate(tscv.split(train)): #Train the model model.fit(train.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Target"]) #Measure the RMSE current_error_rate.iloc[i,0] = mean_squared_error(train.loc[test_index,"Price Target"],model.predict(train.loc[test_index,ohlc_predictors])) #Store the algorithm's progress algorithm_progress.append(current_error_rate.iloc[:,0].mean()) #Return the Mean CV RMSE return(current_error_rate.iloc[:,0].mean())
SciPy espera que le proporcionemos valores iniciales para iniciar el procedimiento de optimización.
#Define the starting point pt = [tuner.best_params_["alpha"],tuner.best_params_["tol"],tuner.best_params_["learning_rate_init"]] bnds = ((10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100))
Intentemos ahora optimizar el modelo.
#Searching deeper for parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
Parece que el algoritmo logró converger. Esto significa que encontró entradas estables que tenían poca variación. Por lo tanto, concluyó que no existen soluciones mejores porque los cambios en los niveles de error se acercaban a 0.
#The result of our optimization
result success: True
status: 0
fun: 3.730365831424036e-06
x: [ 9.939e-08 9.999e-03 9.999e-03]
nit: 3
jac: [-7.896e+01 -1.133e+02 1.439e+03]
nfev: 100
njev: 25
hess_inv: <3x3 LbfgsInvHessProduct with dtype=float64>
Visualicemos el procedimiento.
#Store the optimal coefficients optimal_weights = result.x optima_y = min(algorithm_progress) optima_x = algorithm_progress.index(optima_y) inputs = np.arange(0,len(algorithm_progress)) #Plot the performance of our optimization procedure plt.scatter(inputs,algorithm_progress) plt.plot(optima_x,optima_y,'ro',color='r') plt.axvline(x=optima_x,ls='--',color='red') plt.axhline(y=optima_y,ls='--',color='red') plt.xlabel("Iterations") plt.ylabel("Training MSE") plt.title("Minimizing Training Error")
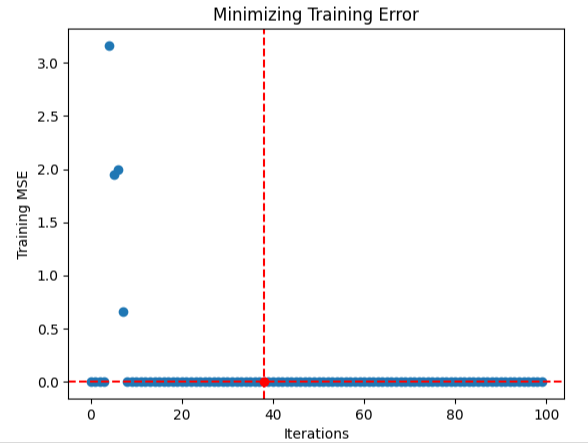
Figura 9: Visualización de la optimización de una red neuronal profunda.
Prueba de sobreajuste
El sobreajuste es un efecto no deseado mediante el cual nuestro modelo aprende representaciones sin sentido a partir de los datos que le proporcionamos. Esto no es deseable porque un modelo en este estado arrojará niveles de precisión bajos. Podemos determinar si nuestro modelo está sobreajustado comparándolo con estudiantes más débiles y con instancias predeterminadas de una red neuronal similar. Si nuestro modelo aprende el ruido y no logra captar la señal en los datos, será superado por los aprendices más débiles. Sin embargo, incluso si nuestro modelo supera a los estudiantes más débiles, aún existe la posibilidad de que esté sobreajustado.
#Testing for overfitting #Benchmark benchmark = LinearRegression() #Default default_nn = MLPRegressor(max_iter=500) #Randomized NN random_search_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=tuner.best_params_["alpha"], tol=tuner.best_params_["tol"], learning_rate_init=tuner.best_params_["learning_rate_init"] ) #LBFGS NN lbfgs_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=result.x[0], tol=result.x[1], learning_rate_init=result.x[2] )
Ajuste los modelos y evalúe su precisión. Podemos ver claramente una disparidad en el rendimiento: el modelo de regresión lineal superó a todas nuestras redes neuronales profundas. Decidí entonces intentar ajustar un SVM lineal. Funcionó mejor que las redes neuronales, pero no logró superar la regresión lineal.
#Fit the models on the training sets benchmark = LinearRegression() benchmark.fit(((train.loc[:,ohlc_predictors])),train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],benchmark.predict(((test.loc[:,ohlc_predictors])))) #Test the default default_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],default_nn.predict(test.loc[:,ohlc_predictors])) #Test the random search random_search_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],random_search_nn.predict(test.loc[:,ohlc_predictors])) #Test the lbfgs nn lbfgs_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lbfgs_nn.predict(test.loc[:,ohlc_predictors])
| Regresión lineal | NN predeterminado | Búsqueda aleatoria | LBFGS NN |
|---|---|---|---|
| 2.609826e-07 | 1.996431e-05 | 0.00051 | 0.000398 |
Ajustemos nuestro LinearSVR, es más probable que detecte las interacciones no lineales en nuestros datos.
#From experience, I'll try LSVR from sklearn.svm import LinearSVR
Inicializamos el modelo y lo ajustamos a todos los datos que tenemos. Observe que los niveles de error de SVR son mejores que los de la red neuronal, pero no tan buenos como los de la regresión lineal.
#Initialize the model lsvr = LinearSVR() #Fit the Linear Support Vector lsvr.fit(train.loc[:,["Open","High","Low","Close"]],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lsvr.predict(test.loc[:,["Open","High","Low","Close"]]))
Exportando a ONNX
Open Neural Network Exchange (ONNX) nos permite crear modelos de aprendizaje automático en un lenguaje y luego compartirlos con cualquier otro lenguaje que admita la API ONNX. El protocolo ONNX está cambiando rápidamente la cantidad de entornos en los que se puede aprovechar el aprendizaje automático. ONNX nos permite integrar sin problemas la IA en nuestro Asesor Experto MQL5.
#Let's export the LSVR to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Crea una nueva instancia del modelo.
model = LinearSVR()
Ajuste el modelo a todos los datos que tenemos.
model.fit(data.loc[:,["Open","High","Low","Close"]],data.loc[:,"Price Target"])
Define la forma de entrada del modelo.
#Define the input type initial_types = [("float_input",FloatTensorType([1,4]))]
Cree una representación ONNX del modelo.
#Create the ONNX representation onnx_model = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Guarde el modelo ONNX.
# Save the ONNX model onnx.save_model(onnx_model,"EURUSD SVR M1.onnx")

Figura 10: Visualización de nuestro modelo ONNX.
Implementación en MQL5
Ahora podemos comenzar a implementar nuestra estrategia en MQL5. Queremos crear una aplicación que compre siempre que el precio esté por encima de la media móvil y la IA prediga que los precios se apreciarán.
Para comenzar con nuestra aplicación, primero incluiremos el archivo ONNX que acabamos de crear en nuestro Asesor Experto.
//+--------------------------------------------------------------+ //| EURUSD AI | //+--------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://metaquotes.com/en/users/gamuchiraindawa" #property version "2.1" #property description "Supports M1" //+--------------------------------------------------------------+ //| Resources we need | //+--------------------------------------------------------------+ #resource "\\Files\\EURUSD SVR M1.onnx" as const uchar onnx_buffer[];
Ahora cargaremos la biblioteca comercial.
//+--------------------------------------------------------------+ //| Libraries | //+--------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade trade;
Define algunas constantes que ahora cambiarán.
//+--------------------------------------------------------------+ //| Constants | //+--------------------------------------------------------------+ const double stop_percent = 1; const int ma_period_shift = 0;
Permitiremos al usuario controlar los parámetros de los indicadores técnicos y el comportamiento general del programa.
//+--------------------------------------------------------------+ //| User inputs | //+--------------------------------------------------------------+ input group "TAs" input double atr_multiple =2.5; //How wide should the stop loss be? input int atr_period = 200; //ATR Period input int ma_period = 1000; //Moving average period input group "Risk" input double risk_percentage= 0.02; //Risk percentage (0.01 - 1) input double profit_target = 1.0; //Profit target
Definamos ahora todas las variables globales que necesitamos.
//+--------------------------------------------------------------+ //| Global variables | //+--------------------------------------------------------------+ double position_size = 2; int lot_multiplier = 1; bool buy_break_even_setup = false; bool sell_break_even_setup = false; double up_level = 0.03; double down_level = -0.03; double min_volume,max_volume_increase, volume_step, buy_stop_loss, sell_stop_loss,ask, bid,atr_stop,mid_point,risk_equity; double take_profit = 0; double close_price[3]; double moving_average_low_array[],close_average_reading[],moving_average_high_array[],atr_reading[]; long min_distance,login; int ma_high,ma_low,atr,close_average; bool authorized = false; double tick_value,average_market_move,margin,mid_point_height,channel_width,lot_step; string currency,server; bool all_closed =true; long onnx_model; vectorf onnx_output = vectorf::Zeros(1); ENUM_ACCOUNT_TRADE_MODE account_type;
Nuestro experto primero verificará que el usuario haya habilitado a los Expertos para operar en la cuenta, luego intentará cargar el modelo ONNX y, finalmente, si tiene éxito hasta ahora, cargaremos nuestros indicadores técnicos.
//+------------------------------------------------------------------+ //| On initialization | //+------------------------------------------------------------------+ int OnInit() { //--- Authorization if(!auth()) { return(INIT_FAILED); } //--- Load the ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- Everything went fine else { load(); return(INIT_SUCCEEDED); } }
Si nuestro Asesor no está en uso, liberaremos la memoria asignada al modelo ONNX.
//+------------------------------------------------------------------+ //| On deinitialization | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { OnnxRelease(onnx_model); }Cada vez que recibamos información de precios actualizada, actualizaremos nuestras variables de mercado global y luego verificaremos si hay señales comerciales si no tenemos posiciones abiertas. De lo contrario, actualizaremos nuestro stop loss dinámico.
//+------------------------------------------------------------------+ //| On every tick | //+------------------------------------------------------------------+ void OnTick() { //On Every Function Call update(); static datetime time_stamp; datetime time = iTime(_Symbol,PERIOD_CURRENT,0); Comment("AI Forecast: ",onnx_output[0]); //On Every Candle if(time_stamp != time) { //Mark the candle time_stamp = time; OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,min_volume,ask,margin); calculate_lot_size(); if(PositionsTotal() == 0) { check_signal(); } } //--- If we have positions, manage them. if(PositionsTotal() > 0) { check_atr_stop(); check_profit(); } } //+------------------------------------------------------------------+ //| Check if we have any valid setups, and execute them | //+------------------------------------------------------------------+ void check_signal(void) { //--- Get a prediction from our model model_predict(); if(onnx_output[0] > iClose(Symbol(),PERIOD_CURRENT,0)) { if(above_channel()) { check_buy(); } } else if(below_channel()) { if(onnx_output[0] < iClose(Symbol(),PERIOD_CURRENT,0)) { check_sell(); } } }
Esta función es responsable de actualizar todas nuestras variables de mercado global.
//+------------------------------------------------------------------+ //| Update our global variables | //+------------------------------------------------------------------+ void update(void) { //--- Important details that need to be updated everytick ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); buy_stop_loss = 0; sell_stop_loss = 0; check_price(3); CopyBuffer(ma_high,0,0,1,moving_average_high_array); CopyBuffer(ma_low,0,0,1,moving_average_low_array); CopyBuffer(atr,0,0,1,atr_reading); ArraySetAsSeries(moving_average_high_array,true); ArraySetAsSeries(moving_average_low_array,true); ArraySetAsSeries(atr_reading,true); risk_equity = AccountInfoDouble(ACCOUNT_BALANCE) * risk_percentage; atr_stop = (((min_distance + (atr_reading[0]* 1e5) * atr_multiple) * _Point)); mid_point = (moving_average_high_array[0] + moving_average_low_array[0]) / 2; mid_point_height = close_price[0] - mid_point; channel_width = moving_average_high_array[0] - moving_average_low_array[0]; }
Ahora debemos definir la función que garantizará que nuestra aplicación pueda ejecutarse; si no puede ejecutarse, la función le dará instrucciones al usuario sobre qué hacer y devolverá falso, lo que detendrá la inicialización.
//+------------------------------------------------------------------+ //| Check if the EA is allowed to be run | //+------------------------------------------------------------------+ bool auth(void) { if(!TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { Comment("Press Ctrl + E To Give The Robot Permission To Trade And Reload The Program"); return(false); } else if(!MQLInfoInteger(MQL_TRADE_ALLOWED)) { Comment("Reload The Program And Make Sure You Clicked Allow Algo Trading"); return(false); } return(true); }
Durante la inicialización, necesitamos una función responsable de cargar todos nuestros indicadores técnicos y obtener detalles importantes del mercado. La función de carga hará exactamente eso por nosotros y, dado que hace referencia a variables globales, su tipo de retorno será nulo.
//+---------------------------------------------------------------------+ //| Load our needed variables | //+---------------------------------------------------------------------+ void load(void) { //Account Info currency = AccountInfoString(ACCOUNT_CURRENCY); server = AccountInfoString(ACCOUNT_SERVER); login = AccountInfoInteger(ACCOUNT_LOGIN); //Indicators atr = iATR(_Symbol,PERIOD_CURRENT,atr_period); ma_high = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_HIGH); ma_low = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_LOW); //Market Information min_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); max_volume_increase = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MAX) / SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); min_distance = SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL); tick_value = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_VALUE_PROFIT) * min_volume; lot_step = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); average_market_move = NormalizeDouble(10000 * tick_value,_Digits); }
Por otro lado, nuestro modelo ONNX se cargará mediante una llamada de función separada. La función creará nuestro modelo ONNX a partir del búfer que definimos anteriormente y validará la forma de entrada y salida.
//+------------------------------------------------------------------+ //| Load our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); ulong onnx_input [] = {1,4}; ulong onnx_output[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,onnx_input)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } if(!OnnxSetOutputShape(onnx_model,0,onnx_output)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } return(true); }
Definamos ahora la función que obtendrá predicciones de nuestro modelo.
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { vectorf onnx_inputs = {iOpen(Symbol(),PERIOD_CURRENT,0),iHigh(Symbol(),PERIOD_CURRENT,0),iLow(Symbol(),PERIOD_CURRENT,0),iClose(Symbol(),PERIOD_CURRENT,0)}; OnnxRun(onnx_model,ONNX_DEFAULT,onnx_inputs,onnx_output); }
Nuestro stop loss se ajustará según el valor de ATR. Dependiendo de si la operación actual es de compra o de venta, ese es el principal factor determinante que nos ayuda a saber si debemos actualizar nuestro stop loss hacia arriba, sumando el valor actual del ATR, o hacia abajo, restando el valor actual del ATR. También podemos utilizar un múltiplo del valor actual de ATR, para brindarle al usuario un control más preciso sobre sus niveles de riesgo.
//+------------------------------------------------------------------+ //| Update the ATR stop loss | //+------------------------------------------------------------------+ void check_atr_stop() { for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); double type = PositionGetInteger(POSITION_TYPE); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (ask - (atr_stop)); double atr_take_profit = (ask + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } else if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (bid + (atr_stop)); double atr_take_profit = (bid - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } } } }
Por último necesitamos definir 2 funciones encargadas de abrir posiciones de compra y venta, y sus pares complementarios para cerrar la posición.
//+------------------------------------------------------------------+ //| Open buy positions | //+------------------------------------------------------------------+ void check_buy() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Buy(min_volume * lot_multiplier,_Symbol,ask,buy_stop_loss,0,"BUY"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Open sell positions | //+------------------------------------------------------------------+ void check_sell() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Sell(min_volume * lot_multiplier,_Symbol,bid,sell_stop_loss,0,"SELL"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Close all buy positions | //+------------------------------------------------------------------+ void close_buy() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_BUY) { trade.PositionClose(ticket); } } } } } //+------------------------------------------------------------------+ //| Close all sell positions | //+------------------------------------------------------------------+ void close_sell() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_SELL) { trade.PositionClose(ticket); } } } } }
Mantengamos un registro de los últimos tres niveles de precios.
//+------------------------------------------------------------------+ //| Get the last 3 quotes | //+------------------------------------------------------------------+ void check_price(int candles) { for(int i = 0; i < candles;i++) { close_price[i] = iClose(_Symbol,PERIOD_CURRENT,i); } }
Esta comprobación booleana devolverá verdadero si estamos por encima del promedio móvil.
//+------------------------------------------------------------------+ //| Are we completely above the MA? | //+------------------------------------------------------------------+ bool above_channel() { return (((close_price[0] - moving_average_high_array[0] > 0)) && ((close_price[0] - moving_average_low_array[0]) > 0)); }
Comprobamos si estamos por debajo de la media móvil.
//+------------------------------------------------------------------+ //| Are we completely below the MA? | //+------------------------------------------------------------------+ bool below_channel() { return(((close_price[0] - moving_average_high_array[0]) < 0) && ((close_price[0] - moving_average_low_array[0]) < 0)); }
Cerrar todas las posiciones que tenemos.
//+------------------------------------------------------------------+ //| Close all positions we have | //+------------------------------------------------------------------+ void close_all() { if(PositionsTotal() > 0) { ulong ticket; for(int i =0;i < PositionsTotal();i++) { ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } }
Calcular el tamaño de lote óptimo a utilizar para que nuestro margen sea igual a la cantidad de capital que estamos dispuestos a arriesgar.
//+------------------------------------------------------------------+ //| Calculate the lot size to be used | //+------------------------------------------------------------------+ void calculate_lot_size() { //--- This is the total percentage of the account we're willing to part with for margin, or to keep a position open in other words. Print("Risk Equity: ",risk_equity); //--- Now that we're ready to part with a discrete amount for margin, how many positions can we afford under the current lot size? //--- By default we always start from minimum lot position_size = risk_equity / margin; //--- We need to keep the number of positions lower than 10 if(position_size > 10) { //--- How many times is it greater than 10? int estimated_lot_size = (int) MathFloor(position_size / 10); position_size = risk_equity / (margin * estimated_lot_size); Print("Position Size After Dividing By margin at new estimated lot size: ",position_size); int estimated_position_size = position_size; //--- Can we increase the lot size this many times? if(estimated_lot_size < max_volume_increase) { Print("Est Lot Size: ",estimated_lot_size," Position Size: ",estimated_position_size); lot_multiplier = estimated_lot_size; position_size = estimated_position_size; } } }
Cerrar posiciones abiertas y verificar si podemos operar nuevamente.
//--- This function will help us keep track of which side we need to enter the market void close_all_and_enter() { if(PositionSelect(Symbol())) { // Determine the type of position check_signal(); } else { Print("No open position found."); } }
Si hemos alcanzado nuestro objetivo de ganancias, cerramos todas las posiciones que tengamos para obtener ganancias y luego verificamos si podemos ingresar nuevamente.
//+------------------------------------------------------------------+ //| Chekc if we have reached our profit target | //+------------------------------------------------------------------+ void check_profit() { double current_profit = (AccountInfoDouble(ACCOUNT_EQUITY) - AccountInfoDouble(ACCOUNT_BALANCE)) / PositionsTotal(); if(current_profit > profit_target) { close_all_and_enter(); } if((current_profit * PositionsTotal()) < (risk_equity * -1)) { Comment("We've breached our risk equity, consider closing all positions"); } }
Por último, necesitamos una función que cierre todas nuestras operaciones no rentables.
//+------------------------------------------------------------------+ //| Close all losing trades | //+------------------------------------------------------------------+ void close_profitable_trades() { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetDouble(POSITION_PROFIT)>profit_target) { ulong ticket; ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } } } //+------------------------------------------------------------------+
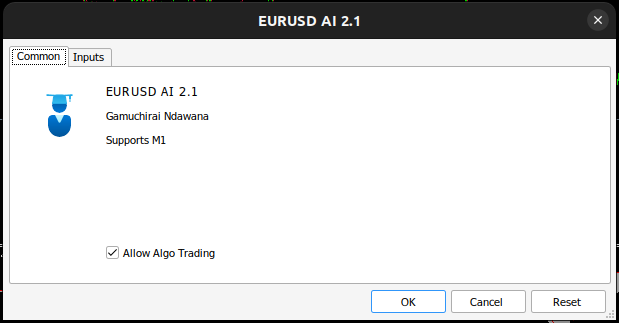
Figura 11: Nuestro asesor experto.
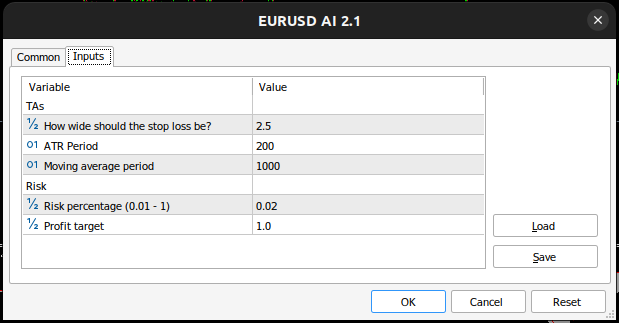
Figura 12: Los parámetros que estamos usando para probar la aplicación.
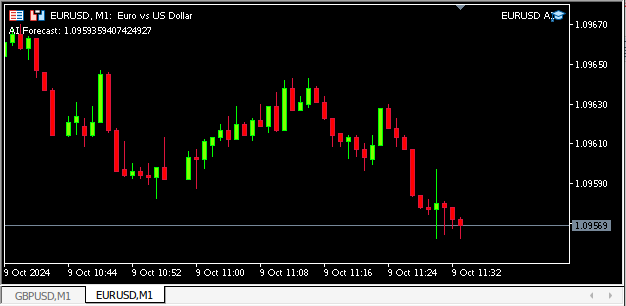
Figura 13: Nuestra aplicación en acción.
Conclusión
Aunque nuestros resultados no fueron alentadores, están lejos de ser concluyentes. Hay otras formas de interpretar el indicador MACD que puede valer la pena evaluar. Por ejemplo, durante una tendencia alcista, la línea de señal MACD cruza por encima de la línea principal, y cae por debajo de la línea principal en una tendencia bajista. Considerar el indicador desde esta perspectiva podría producir diferentes métricas de error. No podemos simplemente asumir que todas las estrategias de interpretación del MACD producirán niveles de error uniformes. Sería razonable para nosotros probar la efectividad de diferentes estrategias basadas en el MACD antes de poder formarnos una opinión sobre la efectividad del indicador.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16066
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Creación de un asesor experto MQL5 basado en la estrategia de ruptura del rango diario (Daily Range Breakout)
Creación de un asesor experto MQL5 basado en la estrategia de ruptura del rango diario (Daily Range Breakout)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso