
Von der Grundstufe bis zur Mittelstufe: Struct (VI)

Einführung
Im vorigen Artikel, „Von der Grundstufe zur Mittelstufe: Struct (V)“ haben wir gezeigt und erklärt, wie man einfache Strukturvorlagen erstellt. Ziel war es, das Überladen der Struktur für andere Datentypen zu ermöglichen, ohne dass der gesamte strukturelle Kontext neu programmiert werden muss. Auch wenn dieser Artikel etwas schwierig zu verstehen ist, haben wir uns bemüht, ihn so einfach und praktisch wie möglich zu erklären. Unser Ziel ist es, dass jeder in der Lage ist, den Themen zu folgen, sie zu lernen und die in den einzelnen Artikeln vorgestellten und behandelten Konzepte praktisch anzuwenden.
Alles, was in diesem Artikel behandelt wird, ist jedoch der einfache Teil einer Reihe von Konzepten und Informationen, die in erster Linie darauf abzielen, ein breites und vielfältiges Spektrum von Aktionen, die ein erfahrener Programmierer durchführen kann, unter einem einzigen Dach zusammenzufassen.
Das Material, das wir heute zu erforschen beginnen (wir werden es nach und nach zeigen), ist so konzipiert, dass es buchstäblich auf dem aufbaut, was im vorherigen Artikel besprochen wurde. Aus diesem Grund wird dieses Thema in vielen Programmier- und Datenanalysekursen behandelt. Erwarten Sie also nicht, dass Sie alles in einem einzigen Artikel finden: Es wird eine große Anzahl von Artikeln nötig sein, um dieses Thema angemessen zu behandeln. Und das sogar ohne Berücksichtigung der objektorientierten Programmierung (OOP).
Warum betone ich dies? Der Grund dafür ist, dass ich festgestellt habe, dass viele Leute lernen wollen, wie man Klassen und Ähnliches nutzt. Dennoch fehlt diesen Personen oft das Grundwissen, um OOP zu verstehen. Diese Konzepte sind das Ergebnis eines guten Verständnisses der strukturellen Programmierung. Um dies zu begreifen, muss man viel Zeit investieren. Es ist etwas, das nur mit der Zeit und der Erfahrung kommt.
Das Ziel dieser Artikel ist es jedoch gerade, diese Lernphase zu beschleunigen. Was Jahre dauern würde, kann also in wenigen Monaten oder sogar Wochen erreicht werden, je nach Aufwand und Hintergrund. Glauben Sie mir, wenn man einen Programmierhintergrund hat, ist es äußerst hilfreich, sich den Stoff schnell anzueignen. Ohne ihn kann man zwar lernen, verschiedene Dinge zu erschaffen, aber leider kommt der Moment, an dem man nicht mehr weiterkommt. Unser Ziel in diesen Artikeln ist genau das: Ihnen zu zeigen, dass es mit Gelassenheit, Geduld und Entschlossenheit keine Rolle spielt, ob Sie einen geeigneten Hintergrund haben oder nicht. Jeder kann ein guter Programmierer werden.
Fangen wir also mit dem neuen Thema an. Auf diese Weise werden wir überprüfen, was wir im vorherigen Artikel getan haben, und einige Details untersuchen, die wir vielleicht übersehen haben. Dies ist entscheidend für das Verständnis einiger Aspekte, die wir in Kürze analysieren werden.
Denken wir an alltägliche Aufgaben
Eine der einfachsten ist die Suche nach einem Kontakt in einem Adressbuch. Dies ist natürlich eine sehr einfache und grundlegende Aufgabe, wie die Suche nach Synonymen oder der Definition eines Wortes in einem Wörterbuch. Selbst ein Kind kann dies lernen. Aber haben Sie sich schon einmal gefragt, wie es wäre, wenn Sie nicht wüssten, wie Sie einen Kontakt in einem Adressbuch oder eine Telefonnummer in einem Telefonbuch finden, oder wie Ihr Webbrowser schnell die von Ihnen angeforderte Webseite findet? Allen diesen Aufgaben liegt dieselbe grundlegende Basis zugrunde: Strukturen.
Ja, das Konzept ist dasselbe, aber die Art der gespeicherten Informationen kann sehr unterschiedlich sein. Ein Adressbuch kann zum Beispiel einen Namen, eine Adresse oder eine Telefonnummer enthalten. In einem Wörterbuch hingegen findet man ein Wort, gefolgt von seiner Definition. All dies kann auf sehr einfache und praktische Weise organisiert werden. Wirklich bemerkenswert ist jedoch die Implementierung eines Codes, der diese verschiedenen Strukturtypen ohne umfangreiche Änderungen handhabt. Es gibt Möglichkeiten, dies zu tun, aber wir werden nicht so weit gehen – es ist nicht notwendig. Unser Ziel für Sie und mich ist es, zu zeigen, wie man einfache Dinge umsetzen kann.
Im vorigen Artikel haben wir erklärt, wie man mit einer sehr einfachen Art von Strukturcode arbeitet, der diskrete Daten innerhalb der Struktur selbst für verschiedene Zwecke verwendet. Diese Art von Lösung ist jedoch nicht geeignet, um umfassendere Aufgaben zu lösen. Zu Ihrem Verständnis werden wir einen sehr einfachen und klaren Code erstellen, wie Sie unten sehen können:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. }; 26. //+------------------------------------------------------------------+ 27. #define PrintX(X) Print(#X, " => ", X) 28. //+------------------------------------------------------------------+ 29. void OnStart(void) 30. { 31. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 32. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 33. 34. st_Data <double> Info_1; 35. st_Data <uint> Info_2; 36. 37. Info_1.Set(H); 38. Info_2.Set(K); 39. 40. PrintX(Info_1.Get(Info_2.Get(3))); 41. } 42. //+------------------------------------------------------------------+
Code 01
Dieser Binärcode kann sehr interessant sein, je nachdem, wie man ihn analysiert, noch bevor man versteht, was ich erklären möchte. Darin schaffen wir eine auflösbare Beziehung zwischen zwei Entitäten. Aber wir wollen nichts überstürzen, denn das Konzept, das wir verstehen müssen, hilft uns dabei, herauszufinden, wie alltägliche Probleme auf eine Art und Weise modelliert werden können, die eine sehr einfache und relativ vollständige strukturelle Programmierung verwendet.
In Code 01 versuchen wir, mit Hilfe der Strukturprogrammierung eine Beziehung zwischen den Elementen der Felder K und H herzustellen. Natürlich könnten wir dasselbe auch auf herkömmliche Weise tun. Wenn wir jedoch strukturell kodieren, werden wir bald sehen, wie viel einfacher es ist, dies auf die Lösung anderer Probleme anzuwenden. Es besteht keine Notwendigkeit, den bereits erstellten Code zu ändern.
Wenn Sie den Inhalt der Artikel studiert haben, wissen Sie genau, zu welchem Ergebnis dieser Code führt. Und Sie wissen, warum dieser Code dieses bestimmte Ergebnis erzeugt, wenn Sie sich Code 01 ansehen. Aber für diejenigen, die dieses Niveau noch nicht erreicht haben, zeigen wir das Ergebnis, das auf dem MetaTrader 5-Terminal ausgedruckt wird, wie in der folgenden Abbildung zu sehen ist:

Abbildung 01
Frage: Warum wird in Zeile 40 in Bild 01 ein solcher Wert angezeigt? Antwort: Denn wir verwenden ein Element aus dem Array K, um ein Element im Array H zu indizieren, aber das ist nicht genau das, was wir vorhatten zu tun. Eigentlich sollte ein Wert in Feld K mit dem entsprechenden Wert in Feld H verknüpft werden, aber die Verbindung ist nicht wie erwartet zustande gekommen.
Um die Idee hier zu verdeutlichen, müssen Sie Folgendes verstehen: Array K sollte als Schlüssel dienen, wobei jeder seiner Werte ein Index für den Zugriff auf oder die Identifizierung eines Wertes in Array H wäre. Allerdings ist Array K ungeordnet, und das wurde absichtlich so gemacht, damit Sie verstehen können, warum die Lösung nicht immer sofort ersichtlich ist.
Um Ihnen zu verdeutlichen, wie sich diese Beziehung entwickeln wird, ändern wir Code 01 in Code 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. uint NumberOfElements(void) 26. { 27. return Values.Size(); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 35. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 36. 37. st_Data <double> Info_1; 38. st_Data <uint> Info_2; 39. 40. Info_1.Set(H); 41. Info_2.Set(K); 42. 43. for (uint c = 0; c < Info_2.NumberOfElements(); c++) 44. PrintFormat("Index [%d] => [%.2f]", Info_2.Get(c), Info_1.Get(c)); 45. } 46. //+------------------------------------------------------------------+
Code 02
Vielleicht wird jetzt, mit Code 02, alles klarer werden. In Zeile 43 verwenden wir eine Schleife, um alle Elemente zu durchlaufen und zu zeigen, wie sich ein Array zu einem anderen verhält. Wenn wir Code 02 ausführen, erhalten wir folgendes Ergebnis:
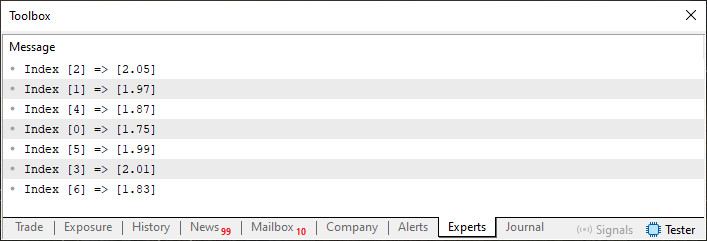
Abbildung 02
Gut, jetzt können wir zur Frage in Code 01 zurückkehren, denn anhand von Bild 02 wissen wir, dass es für jeden in Array K deklarierten Index einen entsprechenden Wert in Array H gibt. Wenn wir also in Code 01 nach dem Wert bei Index 03 fragen, beziehen wir uns eigentlich nicht auf den in Bild 01 dargestellten Wert. Dies ist der Fall, weil der Index 03 in der Reihe K gleich Null ist, ungeachtet der Tatsache, dass die Reihen nicht geordnet sind. Wenn wir jedoch den entsprechenden Wert anzeigen lassen wollen, verweisen wir nicht auf den korrekten Index im Array H. Ich weiß, das mag kompliziert erscheinen, aber Sie werden bald verstehen, worauf ich hinaus will.
Das erste Problem ist also, dass die Arrays ungeordnet sind und für eine wirklich effiziente Suche sortiert werden müssen. Denken Sie daran, dass die in Abbildung 02 gezeigte Beziehung beibehalten werden muss, da ein Feld als Suchquelle und das andere als Antwortquelle dienen wird.
Viele Anfänger haben sofort eine Lösung parat. Die naheliegendste ist, die Funktion ArraySort zu verwenden, um die Arrays zu ordnen, oder die Funktion ArrayBsearch, um innerhalb des Arrays selbst zu suchen. Um unser Ziel zu erreichen, müssen wir auf jeden Fall den Code 01 ändern. Dies führt zu folgendem Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. T Search(const uint index) 26. { 27. return ArrayBsearch(Values, index); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. #define PrintX(X) Print(#X, " => ", X) 33. //+------------------------------------------------------------------+ 34. void OnStart(void) 35. { 36. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 37. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 38. 39. st_Data <double> Info_1; 40. st_Data <uint> Info_2; 41. 42. Info_1.Set(H); 43. Info_2.Set(K); 44. 45. PrintX(Info_1.Get(Info_2.Search(3))); 46. } 47. //+------------------------------------------------------------------+
Code 03
Mit dem Code 03 haben wir endlich die richtige und notwendige Verbindung hergestellt. Dies ergibt die unten stehende Antwort:

Abbildung 03
Bitte beachten Sie, dass der als Antwort zurückgegebene Wert sozusagen dem gesuchten Index in unserer Liste entspricht, wie aus der Entsprechung zwischen den Feldern K und H in Abbildung 02 ersichtlich ist. Es gibt jedoch einfachere Möglichkeiten, die gleiche Art von Beziehung herzustellen, die es uns ermöglichen, effektiver zu arbeiten, indem wir eine engere Verbindung zwischen den Feldern K und H aufrechterhalten.
Eine solche Methode ist die Verwendung mehrdimensionaler Arrays. Mehrdimensionale Arrays eignen sich jedoch nicht sehr gut für die Arbeit mit verschiedenen Arten von Informationen, sodass wir zum Erstellen dieser Art von Verbindung eine andere Methode verwenden müssen. Erinnern wir uns daran, dass es darum geht, einen Code zu erstellen, der in einer Struktur enthalten ist.
Deshalb müssen wir einen Schritt zurück und dann zwei Schritte vorwärts machen. Das Ziel ist es, die Lösung klarer zu machen. Um dies nicht gesondert zu untersuchen, sollten wir das Thema wechseln.
Strukturen von Strukturen
Ein Punkt, der viele Anfänger verwirrt, ist der Übergang von Konzepten, die separat besprochen wurden, zu einem kombinierten Format. Ich weiß, dass die Diskussion darüber seltsam erscheinen mag, da das Konzept selbst im Wesentlichen erhalten bleibt. Wenn wir jedoch Konzepte kombinieren und tiefergehend anwenden, ergeben sich neue Möglichkeiten, die Ihnen vielleicht zunächst völlig unklar sind.
Um dies zu erklären, werden wir den Code 03 (der im vorigen Thema besprochen wurde) so abändern, dass er einfach zu verstehen ist, es uns aber dennoch ermöglicht, die Erklärung auf unser Hauptziel zu konzentrieren. Mit anderen Worten, wir werden eine Art Verbindung zwischen einer Reihe von Werten und einer völlig anderen Reihe von Werten herstellen.
Zu diesem Zweck verwenden wir den nachstehend beschriebenen Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. struct st_Reg 07. { 08. double h_value; 09. uint k_value; 10. }Values[]; 11. }; 12. //+------------------------------------------------------------------+ 13. bool Set(st_Data &dst, const uint &arg1[], const double &arg2[]) 14. { 15. if (arg1.Size() != arg2.Size()) 16. return false; 17. 18. ArrayResize(dst.Values, arg1.Size()); 19. for (uint c = 0; c < arg1.Size(); c++) 20. { 21. dst.Values[c].k_value = arg1[c]; 22. dst.Values[c].h_value = arg2[c]; 23. } 24. 25. return true; 26. } 27. //+------------------------------------------------------------------+ 28. string Get(const st_Data &src, const uint index) 29. { 30. for (uint c = 0; c < src.Values.Size(); c++) 31. if (src.Values[c].k_value == index) 32. return DoubleToString(src.Values[c].h_value, 2); 33. 34. return "-nan"; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 43. 44. st_Data info; 45. 46. Set(info, K, H); 47. PrintX(Get(info, 3)); 48. } 49. //+------------------------------------------------------------------+
Code 04
Bevor ich Ihnen im Detail erkläre, was Code 04 tut, müssen Sie Folgendes verstehen: Was wir hier sehen, ist einfach eine Möglichkeit, etwas mit einem vordefinierten Ziel zu implementieren.
Betrachten Sie die nachstehende Methode keinesfalls als die einzige, denn es gibt noch andere, einfachere oder komplexere Methoden, die die Verwendung mehrdimensionaler Arrays beinhalten. Dies beruht auf dem, was wir bis hierher bereits erklärt und gezeigt haben.
Aber es gibt eine noch bessere Möglichkeit, dies zu tun. Dazu kommen wir später. Sehen wir uns zunächst an, was Code 04 bewirkt. Schauen wir uns zunächst das Ausführungsergebnis an, das Sie weiter unten finden:

Abbildung 04
Was für ein interessantes Ergebnis, nicht wahr? Man könnte meinen: Wenn Zeile 47 ausgeführt wird, geschieht etwas sehr Ähnliches wie in Code 01 gezeigt. Wenn Sie sich jedoch die Get-Funktion in Zeile 28 von Code 04 ansehen, können Sie erkennen, dass der Indexwert innerhalb der Menge der Elemente des Arrays K gesucht wird.
Der entscheidende und wirklich interessante Punkt ist jedoch, dass wir bei erfolgreicher Ausführung von Zeile 31 nicht den Index des Elements aus Array K, sondern den Wert mit demselben Index aus Array H zurückgeben und damit eine Verknüpfung herstellen. Beachten Sie nun Folgendes: Da die Anzahl der Elemente gering ist, brauchen wir uns um die Ausführungszeit des Codes keine Sorgen zu machen.
In einer normalen und realen Situation sollte die in Zeile 4 erstellte Struktur jedoch in irgendeiner Weise geordnet sein. Bei der in Zeile 28 durchgeführten Suche wird die Ausführungszeit also so gering wie möglich sein.
Daraus ergibt sich eine neue Idee: Wie können wir einen Code erstellen, der näher an der Realität ist? Nun, dafür müssen wir dieser Struktur einen eigenen Kontext geben. Genau hier setzt das an, was in der Informatik als Datenanalyse bezeichnet wird.
Wenn wir die Datenanalyse auf unsere Codes anwenden, müssen wir sie irgendwie strukturieren, aber es gibt keine perfekte Struktur für alle Fälle. In manchen Situationen muss der Code auf eine bestimmte Art und Weise implementiert werden, in anderen wiederum auf eine ganz andere Art. Daher erfordert jedes Problem ein angemessenes Maß an Wissen, um das beste Ergebnis in kürzester Zeit zu erzielen.
Sie denken jetzt wahrscheinlich: „Werden wir anfangen, Datenanalyse zu lernen?“ Noch nicht, lieber Leser. Vorher müssen wir noch einige Dinge beachten. Damit könnten wir bald beginnen, aber im Moment tun wir das nicht. Da wir nun wissen, dass es eine Verbindung zwischen der Menge der Elemente in Array K und der Menge der Elemente in Array H gibt, können wir darüber nachdenken, wie wir die Struktur aus Zeile 04 in eine kontextbezogene Struktur umwandeln können, die die notwendigen Mechanismen enthält, um diese Verbindung zwischen den Elementen aufrechtzuerhalten, zu verwalten und sicherzustellen, dass sie ordnungsgemäß hergestellt bleibt.
Dazu werden wir zunächst Code 04 verwenden, um diese Simulation zu erstellen. Mit anderen Worten, wir werden den Mechanismus noch nicht verallgemeinern; dies ermöglicht es dem Compiler, Typüberladungen zu erzeugen. Der neue, geänderte Code ist nachstehend abgebildet:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. struct st_Reg 10. { 11. double h_value; 12. uint k_value; 13. }Values[]; 14. //+----------------+ 15. public: 16. //+----------------+ 17. bool Set(const uint &arg1[], const double &arg2[]) 18. { 19. if (arg1.Size() != arg2.Size()) 20. return false; 21. 22. ArrayResize(Values, arg1.Size()); 23. for (uint c = 0; c < arg1.Size(); c++) 24. { 25. Values[c].k_value = arg1[c]; 26. Values[c].h_value = arg2[c]; 27. } 28. 29. return true; 30. } 31. //+----------------+ 32. string Get(const uint index) 33. { 34. for (uint c = 0; c < Values.Size(); c++) 35. if (Values[c].k_value == index) 36. return DoubleToString(Values[c].h_value, 2); 37. 38. return "-nan"; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. #define PrintX(X) Print(#X, " => ", X) 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 48. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 49. 50. st_Data info; 51. 52. info.Set(K, H); 53. PrintX(info.Get(3)); 54. } 55. //+------------------------------------------------------------------+
Code 05
Passen Sie nun gut auf, damit Sie den Faden der Erklärung nicht verlieren. Wenn Code 05 ausgeführt wird, sehen wir im MetaTrader 5-Terminal die gleichen grundlegenden Informationen wie in Bild 04, jedoch mit einem kleinen Unterschied, der unten zu sehen ist:

Abbildung 05
Im Gegensatz zu Code 04 ist Code 05 strukturell. Aufgrund der in den Zeilen 11 und 12 implementierten Typdeklaration sind wir jedoch an einen bestimmten Datentyp gebunden, der hier verwendet werden kann. Angenommen, wir wollen oder müssen ein anderes System schaffen, bei dem wir anstelle von numerischen Werten textuelle Werte, d. h. Zeichenketten, anstelle der in Code 05 verwendeten Werte verknüpfen wollen. Wie können wir dies erreichen, indem wir so wenig wie möglich am Code 05 ändern?
Wenn Sie die vorherigen Artikel nicht gelesen haben, ist das schade: Sie erklären einige Details, die ich hier nicht wiederholen werde. Wir werden jedoch untersuchen, wie man die in Zeile 04 deklarierte Struktur so verallgemeinern kann, dass der Compiler die notwendige Typüberladung erzeugt und damit Fälle abdeckt, die sonst offensichtlich unmöglich wären.
Der Einfachheit halber werden wir zunächst nur einen Basistyp verallgemeinern – den in Zeile 11 definierten. Der neue Code ist unten abgebildet:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. struct st_Reg 11. { 12. T h_value; 13. uint k_value; 14. }Values[]; 15. //+----------------+ 16. string ConvertToString(T arg) 17. { 18. if ((typename(T) == "double") || (typename(T) == "float")) return DoubleToString(arg, 2); 19. if (typename(T) == "string") return arg; 20. 21. return IntegerToString(arg); 22. } 23. //+----------------+ 24. public: 25. //+----------------+ 26. bool Set(const uint &arg1[], const T &arg2[]) 27. { 28. if (arg1.Size() != arg2.Size()) 29. return false; 30. 31. ArrayResize(Values, arg1.Size()); 32. for (uint c = 0; c < arg1.Size(); c++) 33. { 34. Values[c].k_value = arg1[c]; 35. Values[c].h_value = arg2[c]; 36. } 37. 38. return true; 39. } 40. //+----------------+ 41. string Get(const uint index) 42. { 43. for (uint c = 0; c < Values.Size(); c++) 44. if (Values[c].k_value == index) 45. return ConvertToString(Values[c].h_value); 46. 47. return "-nan"; 48. } 49. //+----------------+ 50. }; 51. //+------------------------------------------------------------------+ 52. #define PrintX(X) Print(#X, " => ", X) 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 57. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 58. 59. st_Data <double> info; 60. 61. info.Set(K, H); 62. PrintX(info.Get(3)); 63. } 64. //+------------------------------------------------------------------+
Code 06
Richtig interessant wird es jetzt mit der Konstruktion des Code 06. Das liegt daran, dass wir in Code 06 damit beginnen können, die Struktur zu verallgemeinern, sodass der Compiler bei Bedarf Überladungen vornehmen kann. So können wir mit verschiedenen Arten von Daten arbeiten, um einen Suchmechanismus zu erstellen. Wenn wir jedoch versuchen, diesen Code zu kompilieren, fällt auf, dass die Meldung im Gegensatz zu den vorherigen anders ausfällt.
Dies ist gleich unten zu sehen:

Abbildung 06
Sie erinnern sich vielleicht, dass ich erwähnt habe, dass es Situationen gibt, in denen Compiler-Meldungen ignoriert werden können, und andere, in denen dies nicht möglich ist. Dies ist ein typisches Beispiel dafür, dass wir die Compiler-Warnungen ignorieren können, und zwar ausschließlich deshalb, weil der Compiler NICHT VERSTEHT, was wir in den Zeilen 19 und 21 tun, die nur in ganz bestimmten Fällen ausgeführt werden, ebenso wie die Zeile 18 selbst. Es gibt eine Möglichkeit, die Anzeige dieser Meldungen zu verhindern, aber ich werde sie ein anderes Mal zeigen, vielleicht im nächsten Artikel, da sich dieser Artikel dem Ende zuneigt.
Da wir also einen der Werte verallgemeinern, müssen wir dem Compiler mitteilen, welche Informationen verwendet werden sollen. Dann können wir den entsprechenden Code für diesen Datentyp erstellen. Zu diesem Zweck deklarieren wir in Zeile 59 eine Variable, die uns den Zugriff auf die Struktur ermöglicht. Da der in Zeile 56 deklarierte Basistyp double ist, müssen wir einen kompatiblen oder identischen Typ in der Deklaration in Zeile 59 verwenden. Andernfalls wird es Probleme mit der Suche nach Datenstrukturen geben.
„Aber wie ist das möglich? Diesen Teil habe ich nicht verstanden. Ich verstehe natürlich den Grund für die Erklärung in Zeile 59 dank der Erklärung in der Struktur. Ich verstehe jedoch nicht, warum wir einen passenden Typ deklarieren müssen, wie in Zeile 56. Wenn wir etwas Gattungsspezifisches schaffen, hat das nicht viel Sinn“.
Nun, da dies ziemlich schwierig zu erklären ist, werde ich den Rest des Artikels diesem Thema widmen und einen großen Teil des Materials für den nächsten Artikel aufheben.
Ich möchte Sie darauf aufmerksam machen, dass wir zu Beginn des Artikels einen Code verwendet haben, der dem Code 06 sehr ähnlich ist. Aber als wir das taten, war das Ergebnis in gewisser Weise im Voraus bekannt, weil wir uns nicht um die Konvertierung oder Rückgabe des richtigen Datentyps kümmerten.
In Code 01 hängt die Art der zurückgegebenen Daten von der Art der gespeicherten Daten ab. Aber, und das ist der springende Punkt, in Code 06 wird immer ein Datentyp zurückgegeben, unabhängig vom Typ der gespeicherten Daten. In diesem Fall werden wir Daten vom Typ double speichern. Die Antwort wird jedoch IMMER vom Typ String sein.
Allein die Tatsache, dass dies geschieht, führt sozusagen zu einer Verwirrung des Systems selbst, denn diese Umwandlung wird vom Programmierer, der die von uns definierte Struktur verwendet, nicht erwartet. Sie fragen sich wahrscheinlich: Wie ist das möglich? Natürlich werden sie es wissen. Das ist aber nicht immer der Fall, denn wir können Codebibliotheken erstellen und sie zu verschiedenen Zeitpunkten verwenden. Und wenn wir von einer Code-Bibliothek sprechen, meinen wir nicht, dass Sie eine Menge Quellcode anhäufen.
Diese Bibliotheken bestehen in der Regel aus ausführbarem Code, wie die berühmten DLLs. In ihnen wissen wir nicht genau, wie der interne Code funktioniert; wir haben nur eine Vorstellung davon, weil wir der DLL Werte übergeben und sie ein Ergebnis zurückgibt. Es ist wichtig, den Typ der Daten zu kennen, die wir an die Struktur übergeben, da wir sie möglicherweise in den ursprünglichen Typ zurückkonvertieren müssen, da das Ergebnis immer eine Zeichenkette sein wird.
Ja. „Aber können wir es nicht einfach allgemein halten? Mit anderen Worten, wenn wir die Daten nicht in einen Stringtyp konvertieren, sondern sie in ihrem ursprünglichen Typ belassen würden, hätten wir dieses Problem nicht, über das wir vor einer Minute gesprochen haben. Habe ich Recht?“ Ja, mein Freund, Sie haben Recht. Denken Sie jedoch daran, dass das Ziel hier das Lernen ist und nicht das Erstellen von Code, der in einer realen Situation verwendet werden könnte.
Da ich Ihnen jedoch die Möglichkeit geben möchte, einen Moment innezuhalten und über einige Dinge nachzudenken, werden wir den Code 06 so ändern, dass in dem oben gezeigten Code nur das unten gezeigte Fragment geändert wird. Und allein die Tatsache, dass wir dies getan haben, zeigt, dass wir es hier mit einer völlig anderen Situation zu tun haben, die hier dargestellt und umgesetzt wird. Schauen wir uns das geänderte Fragment an:
. . . 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const string T = "possible loss of data due to type conversion"; 57. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 58. 59. st_Data <string> info; 60. string H[]; 61. 62. StringSplit(T, ' ', H); 63. info.Set(K, H); 64. PrintX(info.Get(3)); 65. } 66. //+------------------------------------------------------------------+
Code 07
Kein Grund zur Sorge, denn im Anhang erhalten Sie vollen Zugriff auf den gesamten Code, sodass Sie jedes hier gezeigte Detail ausprobieren und üben können. Auf jeden Fall möchte ich, dass Sie innehalten und darüber nachdenken, was wir hier tun: Indem wir Code 06 in das Fragment von Code 07 ändern, können wir allein durch die Änderung der Art der Informationen, die in der Struktur enthalten sind, Dinge bauen, die viele für unwahrscheinlich oder schwierig zu implementieren halten werden.
Ein Tipp zum Nachdenken: Je nachdem, wie wir die Informationen in der Variablen in Zeile 60 von Code 07 erstellen und anordnen, können wir einen Code erstellen, der in jeder Sprache funktionieren kann, vorausgesetzt natürlich, wir implementieren und ordnen die Informationen in der Variablen in Zeile 60 entsprechend an.
Denken Sie darüber nach, wie dies geschehen kann und wie es sich auf eine ganze Generation von Code auswirken wird, den Sie erstellen können.
Abschließende Gedanken
In diesem Artikel haben wir einige Grundlagen der Programmierung vertieft und untersucht, wie man mit der Implementierung einer gemeinsamen Codebasis beginnen kann. Ziel ist es, den Programmieraufwand zu verringern und das volle Potenzial der Programmiersprache selbst – in diesem Fall MQL5 – zu nutzen. Ich habe sehr lange gebraucht, um das, was wir hier zeigen oder erklären, zu verinnerlichen.
Das lag jedoch daran, dass sie zu der Zeit, als ich diese Dinge lernte, gerade erst geschaffen wurden. Heutzutage sagt fast jeder, dass OOP das Beste ist. Und ja, sie ist wirklich sehr gut und nützlich. Aber warum? Es ist sinnlos, den Code einer Klasse zu sehen, ihn zu verwenden oder gar zu ändern, ohne zu verstehen, warum er funktioniert. Um wirklich zu verstehen und zu lernen, muss man zunächst begreifen, wie Programmiersprachen dieses Niveau erreicht haben, warum OOP geschaffen wurde und warum es so weit verbreitet ist.
Dieses Verständnis kann nur durch Übung und Experimentieren erlangt werden, indem Code mit Prinzipien verwendet wird, die nur in der OOP diskutiert werden, die aber im Grunde genommen nicht wie die Methoden und Fähigkeiten geschaffen werden, die nur die OOP bietet. In Wirklichkeit wurden diese Prinzipien in der strukturellen Programmierung geboren – ein Thema, über das heute kaum noch jemand spricht und das wir hier zu studieren beginnen.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15889
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.