
Von der Grundstufe bis zur Mittelstufe: Template und Typename (V)

Einführung
Im vorigen Artikel, Von der Grundstufe zur Mittelstufe: Template und Typenname (IV), habe ich (so klar und einfach wie möglich) erklärt, wie wir eine Schablone erstellen können, um einen Modellierungstyp zu verallgemeinern und damit sozusagen eine Datentypüberladung zu erzeugen. Am Ende dieses Artikels habe ich jedoch etwas eingeführt, das für viele Leser schwer zu verstehen sein dürfte: die Übertragung von Daten in eine Funktion oder Prozedur, die selbst als Vorlage implementiert ist. Da dieses Konzept eine ausführlichere Erklärung erfordert, habe ich beschlossen, diesen Artikel diesem Thema zu widmen. Darüber hinaus gibt es ein weiteres Konzept, das eng damit zusammenhängt: Es kann den Unterschied ausmachen, ob man eine bestimmte Lösung mit Hilfe von Vorlagen umsetzen kann oder nicht.
Um diesen Artikel richtig zu beginnen, sollten wir ein neues Thema beginnen, um zu erklären, warum das letzte Stück Code aus dem vorherigen Artikel tatsächlich funktioniert.
Den Geist erweitern
Im letzten Artikel haben wir etwas eingeführt, das eher ungewöhnlich aussah. Ich vermute, dass viele von Ihnen noch nie etwas Vergleichbares gesehen haben. Um zu erklären, was das alles bedeutet, müssen wir uns den verwendeten Code ansehen. Sie können es unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 <T> &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
Code 01
Wenn man bedenkt, dass Sie wahrscheinlich schon viel mit dem Code aus dem vorherigen Artikel experimentiert haben, muss dieser Code 01 Ihre Aufmerksamkeit erregt haben. Insbesondere die Art und Weise, wie die Prozedur in Zeile 35 deklariert wird. Um zu verstehen, was und vor allem warum die Dinge im Code 01 so deklariert sind, müssen wir genauer hinschauen.
Zunächst müssen wir verstehen, dass die Prozedur in Zeile 35 eine ist, die der Compiler bei der Erzeugung des ausführbaren Codes überlädt. Wie im vorigen Artikel erwähnt, habe ich mich der Herausforderung gestellt, einen Code zu erstellen, der die gleiche Aufgabe wie Code 01 erfüllt, aber mit Hilfe von vorlagenbasierten Überladungen für die in Zeile 35 implementierte Prozedur. Das Ziel dieser Übung ist es, zu klären, warum die Prozedur auf diese Art und Weise deklariert werden muss.
In der Theorie scheint diese Übung einfach zu sein, aber in der Praxis kann sie etwas knifflig sein. Lassen Sie uns also gemeinsam daran arbeiten. Auf diese Weise werden Sie verstehen, warum die Erklärung so geschrieben werden muss, wie sie im Code 01 steht.
Wir werden nicht den gesamten Code ändern, sondern nur die Prozedur, sodass wir uns auf das unten gezeigte Fragment konzentrieren können.
. . . 33. //+------------------------------------------------------------------+ 34. void Swap(un_01 <ulong> &arg) 35. { 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. arg.u8_bits[i] = arg.u8_bits[j]; 40. arg.u8_bits[j] = tmp; 41. } 42. } 43. //+------------------------------------------------------------------+ 44. void Swap(un_01 <ushort> &arg) 45. { 46. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 47. { 48. tmp = arg.u8_bits[i]; 49. arg.u8_bits[i] = arg.u8_bits[j]; 50. arg.u8_bits[j] = tmp; 51. } 52. } 53. //+------------------------------------------------------------------+
Fragment 01
Dieses Fragment 01 ersetzt die Prozedur, die in Zeile 35 zu finden ist. Aber passen Sie gut auf: Was Fragment 01 enthält, ist genau das, was der Compiler erzeugt, wenn er die Prozedur in Code 01 übersetzt und überlädt. In diesem Fall werden jedoch nur die Typen ulong und ushort abgedeckt, im Gegensatz zu Code 01, der alle primitiven Typen abdeckt.
Warum also müssen wir die Dinge so deklarieren, wie sie in Fragment 01 erscheinen? Ich glaube, der Grund dafür sollte jetzt viel klarer sein. Wenn Sie die Erläuterung im vorigen Artikel verstanden haben, ist Ihnen wahrscheinlich klar, warum die Zeilen 14 und 24 in Code 01 auf diese spezielle Weise deklariert werden müssen. Und aus demselben Grund müssen auch die Zeilen 34 und 44 im Fragment 01 einer ähnlichen Struktur folgen.
Erinnern Sie sich an etwas, das wir in den ersten Artikeln über die Übergabe als Wert oder als Referenz besprochen haben: Wenn wir eine Variable deklarieren, müssen wir sowohl ihren Typ als auch ihren Namen angeben. Und innerhalb einer Funktions- oder Prozedurdeklaration deklarieren wir tatsächlich eine Variable, die je nach Fall konstant sein kann oder nicht.
Was die Deklaration von Variablen innerhalb einer Prozedur angeht, so scheint alles relativ einfach zu sein. Aber es bleibt eine Frage offen: Als wir vorhin über spezielle Variablen sprachen, erwähnten wir, dass eine Funktion eine dieser Variablen sein kann. Wie könnten wir in der Situation, mit der wir es jetzt zu tun haben, eine Funktion verwenden, um das zu implementieren, was wir brauchen?
Das ist eine ausgezeichnete Frage, lieber Leser. Wenn wir nämlich Werte zurückgeben wollen, müssen wir eine andere Art von Deklaration verwenden als bei Prozeduren. Das zugrundeliegende Konzept bleibt jedoch sehr ähnlich zu dem, was wir bisher gesehen haben. Denken Sie daran: Wenn wir etwas zurückgeben, ist dieser Rückgabewert selbst ein Variablentyp, als ob wir eine Variable deklarieren würden, deren Name der Name der Funktion ist. Mit diesem Gedanken im Hinterkopf können wir das gleiche Grundkonzept erweitern und unseren Code richtig implementieren.
Bevor wir uns der verallgemeinerten Form zuwenden, wollen wir uns einen ähnlichen Ansatz wie in Fragment 01 ansehen. Da sich Funktionen jedoch anders verhalten als Prozeduren, werden wir auch einige Änderungen an Code 01 vornehmen. Das Ergebnis ist unten dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. un_01 <ulong> Swap(const un_01 <ulong> &arg) 33. { 34. un_01 <ulong> local; 35. 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. local.u8_bits[i] = arg.u8_bits[j]; 40. local.u8_bits[j] = tmp; 41. } 42. 43. return local; 44. } 45. //+------------------------------------------------------------------+ 46. un_01 <ushort> Swap(const un_01 <ushort> &arg) 47. { 48. un_01 <ushort> local; 49. 50. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 51. { 52. tmp = arg.u8_bits[i]; 53. local.u8_bits[i] = arg.u8_bits[j]; 54. local.u8_bits[j] = tmp; 55. } 56. 57. return local; 58. } 59. //+------------------------------------------------------------------+
Code 02
Beachten Sie, dass sich dieser Code 02 leicht von Code 01 unterscheidet. Aber trotz dieser Unterschiede führt es zum gleichen Ergebnis. Das heißt, wenn Sie Code 02 kompilieren und im MetaTrader 5 Terminal ausführen, erhalten Sie die unten gezeigte Ausgabe.
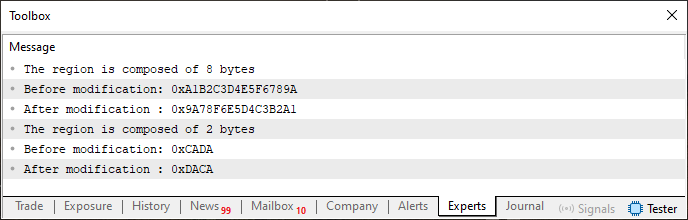
Abbildung 01
Wie Sie sehen, ist das Ergebnis genau dasselbe wie bei der Ausführung von Code 01, auch wenn dessen Prozedur durch Fragment 01 ersetzt wurde. Das Fragment 01 schränkt jedoch die Datentypen ein, die der Compiler bei der Arbeit mit der Union un_01 verwenden kann.
Für diesen Code 02 gilt die gleiche Einschränkung. Nun möchte ich Sie darauf hinweisen, dass Fragment 01 umgeschrieben wurde, damit wir Funktionen anstelle von Prozeduren verwenden können. Achten Sie auf die Zeilen 19 und 28 in Code 02, wo wir eine so genannte Spezialvariable namens „Swap“ verwenden, die eigentlich eine Funktion ist, aber als schreibgeschützte Variable verwendet werden soll.
Ziemlich cool, nicht wahr? Genau wie Fragment 01 zeigt, was die Prozedur in Code 01 tun würde, können wir auch die Funktionen in Code 02 in eine Vorlage umwandeln. Auf diese Weise hätte der Code das gleiche Verhalten und die gleiche Flexibilität bei der Auswahl der Typen wie Code 01. Zu diesem Zweck müssen wir lediglich die gemeinsamen Teile der Funktionen in Code 02 verallgemeinern. Der Compiler kann dann den Datentyp bei Bedarf dynamisch ersetzen. Wenn Sie dieses Konzept verstanden haben, können Sie den Code 02 in den Code 03 umschreiben, wie im Folgenden gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. template <typename T> 33. un_01 <T> Swap(const un_01 <T> &arg) 34. { 35. un_01 <T> local; 36. 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. local.u8_bits[i] = arg.u8_bits[j]; 41. local.u8_bits[j] = tmp; 42. } 43. 44. return local; 45. } 46. //+------------------------------------------------------------------+
Code 03
Dieser Code 03 stellt eine Verbesserung gegenüber Code 02 dar, da wir nun die Möglichkeit haben, jeden beliebigen Datentyp zu verwenden. Der Compiler ist in der Lage, dies korrekt zu interpretieren und automatisch alle notwendigen Überladungen zu erzeugen, damit unsere Anwendung erfolgreich funktioniert.
Damit ist das, was einst äußerst komplex und schwer verständlich erschien, einfach und überschaubar geworden. Jeder Anfänger kann jetzt mit Leichtigkeit Vorlagen verwenden. Haben Sie bemerkt, dass Dinge, die zunächst kompliziert erscheinen, oft einfach werden, wenn wir die zugrunde liegenden Konzepte wirklich verstehen? Deshalb bestehe ich immer wieder darauf, dass Sie das, was gezeigt wird, auch praktizieren. Nicht um auswendig zu lernen, wie man Code schreibt, sondern um zu verstehen, wie die Konzepte in jedem spezifischen Kontext angewendet werden.
Dies ist nun der Teil, den viele als mittelschwer oder sogar fortgeschritten einstufen würden. Meines Erachtens ist das, was wir bisher behandelt haben, jedoch nur die Grundlage. Wir müssen noch etwas Wichtiges besprechen, das wir schon die ganze Zeit verwenden, aber noch nicht explizit angesprochen haben: das reservierte Wort „typename“.
Um dies richtig zu erklären, müssen wir ein neues Thema beginnen, damit wir es in Ruhe und klar studieren können. Das sollten wir jetzt tun.
Typenname: Wofür ist es wirklich gut?
Eine sehr vernünftige und wichtige Frage, die man sich stellen sollte, ist: Was genau ist typename? Und was ist ihr eigentlicher Zweck in einem praktischen Programm? Nun, liebe Leserin, lieber Leser, wenn Sie das verstehen, können Sie einige sehr interessante Arten von Code implementieren. Im Allgemeinen wird typename jedoch für sehr spezifische Zwecke verwendet, die oft mit der Prüfung oder der Typenkontrolle zusammenhängen.
Zumindest soweit ich weiß, wird typename selten für etwas anderes verwendet als dafür, dass eine vom Compiler überladene Funktion oder Prozedur sich nicht unvorhersehbar verhält. Wenn wir etwas als Vorlage implementieren, ist es nicht ungewöhnlich, dass wir bei der Verwendung auf inkonsistente oder inkohärente Ergebnisse stoßen – oft, weil ein bestimmter Typ von der Vorlage nicht korrekt behandelt wurde.
In anderen Fällen möchten wir vielleicht, dass sich eine vom Compiler überladene Funktion oder Prozedur je nach Art der verwendeten Daten unterschiedlich verhält. Dieselbe Funktion kann für einen Typ auf die eine und für einen anderen Typ auf die andere Weise wirken. Das mag verwirrend klingen, aber in der Praxis kann es manchmal notwendig sein. Wenn Sie verstehen, wie typename funktioniert, können Sie mit solchen Situationen sicher umgehen.
Um dies zu demonstrieren, wollen wir ein Beispiel erstellen, das zumindest ein bisschen Spaß macht. Denn die Arbeit mit typename kann ein recht trockenes und technisches Thema sein. Wir werden versuchen, sie ansprechender zu gestalten. Verwenden wir den unten stehenden Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = arg.u8_bits[i]; 43. local.u8_bits[i] = arg.u8_bits[j]; 44. local.u8_bits[j] = tmp; 45. } 46. 47. return local; 48. } 49. //+------------------------------------------------------------------+
Code 04
In diesem Code 04 spielen wir mit allem herum, was wir bisher besprochen haben. Unser Ziel ist es zu verstehen, wie typename in einem echten Programm verwendet werden kann. Ziel ist es, die im Gedächtnis (oder in diesem Fall in einer Variablen) gespeicherte Information so zu spiegeln (oder zu „reflektieren“), dass die rechte Hälfte den Platz mit der linken Hälfte tauscht. Das ist ganz einfach.
Wenn Sie sich Code 04 ansehen, können Sie feststellen, dass es sich im Wesentlichen um eine leichte Abwandlung der Beispiele handelt, mit denen wir gearbeitet haben. Das ist beabsichtigt, denn so können wir uns auf das konzentrieren, was neu und wichtig zu verstehen ist.
Wenn dieser Code 04 im MetaTrader 5 ausgeführt wird, erhalten wir das unten dargestellte Ergebnis.
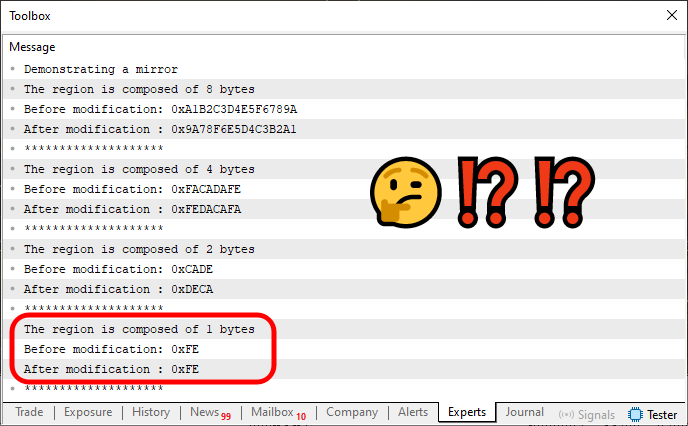
Abbildung 02
Beachten Sie, dass einer der Werte hervorgehoben ist. Der Grund dafür ist einfach: ER IST NICHT GESPIEGELT. Die rechte Seite wird NICHT mit der linken Seite vertauscht. Bei allen anderen Werten funktioniert die Spiegelung jedoch einwandfrei. Das Problem besteht darin, dass wir bei Verwendung eines Datentyps, der nur ein Byte belegt, die Möglichkeit verlieren, eine Seite mit der anderen zu spiegeln.
In MQL5 wissen wir, dass es nur zwei Typen gibt, die dieses Ein-Byte-Kriterium erfüllen: uchar (für vorzeichenlose Werte) und char (für vorzeichenbehaftete Werte). Die Implementierung separater überladener Aufrufe, um diese Typen einzeln zu behandeln, wäre jedoch etwas unpraktisch, da es die Einheitlichkeit unserer Operation aufheben würde. Die ideale Lösung besteht darin, die in Zeile 36 implementierte Funktion „Spiegeln“ weiter zu verwenden, um dieses Verhalten zu behandeln.
Aber jetzt kommt die entscheidende Frage: Wie können wir dem Compiler mitteilen, wie er die Typen uchar oder char behandeln soll, um die Spiegelung durchzuführen?
Nun, liebe Leserin, lieber Leser, es gibt viele Möglichkeiten, dies zu tun. Ein praktischer und einfacher Ansatz wäre, die Bits einzeln zu lesen und sie zu vertauschen – rechts für links und links für rechts. Damit würde die Notwendigkeit entfallen, Funktionen oder Prozeduren zu überladen. Aber das ist nicht unser Ziel. Betrachten Sie das als Hausaufgabe: Versuchen Sie, eine Lösung zu implementieren, die Daten Bit für Bit spiegelt, indem Sie die Bits der Eingangsinformationen vertauschen. Es ist eine hervorragende Übung, um diese Konzepte zu festigen und wie ein echter Programmierer zu denken.
Aber was unseren aktuellen Fall betrifft: Wie können wir dieses Problem lösen? Nun, hier wird es wirklich interessant. Sie sehen, typename kann uns buchstäblich den Namen des empfangenen Datentyps mitteilen. Mit anderen Worten, wir können typename fragen, was der Typ einer bestimmten Variablen oder eines Parameters ist. Um dieses Konzept greifbarer und verständlicher zu machen, nehmen wir eine kleine Änderung an Code 04 vor. Sie können die aktualisierte Version im unten stehenden Code sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Code 05
Wenn Sie diesen Code 05 ausführen, werden Sie etwas sehen, das dem unten gezeigten Bild sehr ähnlich ist.
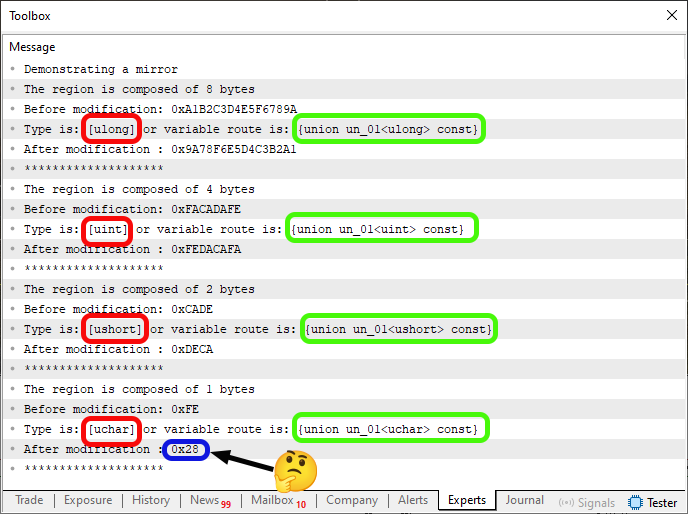
Abbildung 03
In dieser Abbildung 03 tauchte nun etwas auf, das ich einfach nicht verstehen konnte. Diese Darstellung macht einfach keinen Sinn. Deshalb ist sie blau hervorgehoben. Wahrlich bizarr. Aber das ist nicht der Punkt. Was wirklich zählt, sind die rot und grün hervorgehobenen Bereiche. Woher stammen also diese Informationen? Nun, diese Ausgaben wurden aufgrund von Zeile 40 in Code 05 gedruckt. Passen Sie jetzt gut auf – es ist äußerst wichtig, dass Sie dies richtig verstehen. Andernfalls könnten Sie später auf Probleme stoßen, wenn Sie versuchen, die in Abbildung 03 rot und grün hervorgehobenen Informationen zu verwenden.
ALLE ROTEN HINWEISE beziehen sich auf die Tatsache, dass wir den Compiler gebeten haben, uns den PRIMITIVEN DATENTYP mitzuteilen, der von der Funktion verwendet wird. Die GRÜNEN HINWEISE hingegen entsprechen der Antwort des Compilers auf unsere Anfrage nach dem DATENTYP, DER VON DER VARIABLE TATSÄCHLICH VERWENDET WIRD. Es gibt einen feinen Unterschied zwischen diesen beiden Fragen. Aber die Antworten können ganz unterschiedlich ausfallen.
Normalerweise und ziemlich oft werden Sie sehen, dass viele Programmierer den Compiler bitten, den Typ einer Variablen zu verraten. Dies gibt uns jedoch nicht immer die richtige Antwort, oder zumindest nicht die, die wir erwarten. Das liegt daran, dass wir uns in einer Situation befinden können, die der oben gezeigten ähnelt, in der der primitive Datentyp eine Sache ist, der variable Datentyp aber komplexer ist, auch wenn er irgendwie von diesem primitiven Typ abgeleitet ist.
Aber machen Sie sich noch keine Gedanken darüber, wie Sie das überprüfen können. Diese Codes sind unten beigefügt, damit Sie sie studieren und ausprobieren können. Um auf unseren Hauptpunkt zurückzukommen – was uns interessiert, sind die in Abbildung 03 rot hervorgehobenen Informationen. Beachten Sie, dass sie alle genau so geschrieben sind, wie sie in der Code-Implementierungsphase deklariert wurden. Ich möchte Ihre Aufmerksamkeit jedoch auf etwas sehr Wichtiges lenken: Diese Werte sind Zeichenketten. Das bedeutet, dass wir sie während der Laufzeit mit anderen Zeichenketten vergleichen können. Und genau darauf kommt es hier an.
Jetzt haben wir eine Grundlage, von der aus wir arbeiten können. Wir müssen nur einen kleinen Test durchführen, um die Typen uchar oder char (die Ein-Byte-Typen) zu isolieren, damit die Werte richtig gespiegelt werden können. Zu diesem Zweck nehmen wir eine kleine Änderung vor. Diesmal kehren wir zu dem ursprünglichen Code 04 zurück, um die notwendige Anpassung vorzunehmen. Die geänderte Version sehen Sie unten.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 41. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Code 06
Passen Sie jetzt gut auf, liebe Leserin, lieber Leser. Was ich hier tue, kann auf viele verschiedene Arten erreicht werden. Jede hat ihre eigenen Vor- und Nachteile, manche sind leichter zu verstehen als andere. Wenn Sie also nicht ganz verstehst, was in diesem Code 06 passiert, machen Sie sich keine Sorgen. Er ist im Anhang enthalten, sodass Sie sie abändern und damit experimentieren können, bis alles einen Sinn ergibt.
Zuvor ist es jedoch wichtig zu verstehen, was ich implementiert habe und was das Endergebnis sein wird, wenn Sie diesen Code ausführen. Andernfalls könnten Sie etwas ändern und ein anderes Ergebnis als das erwartete erhalten und fälschlicherweise denken, dass alles gut funktioniert.
Lassen Sie uns also weitermachen. Schauen wir uns zunächst das Ergebnis an, wenn wir das Programm im MetaTrader 5 Terminal ausführen. Sie können es unten sehen.
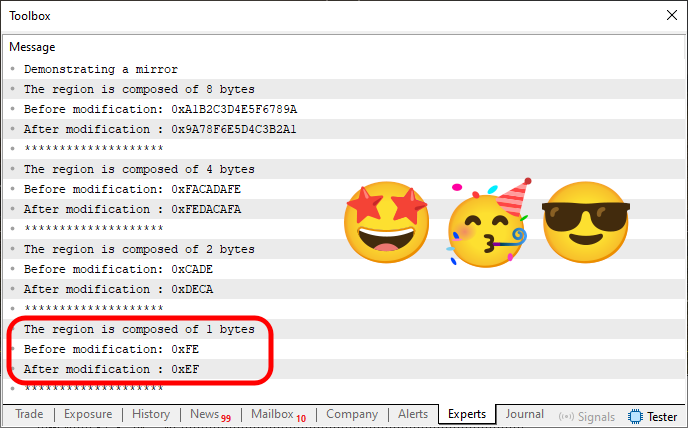
Abbildung 04
Einfach wunderbar. Der Code hat sein Ziel erreicht, nämlich die Werte der einzelnen Variablen so zu spiegeln, dass die rechte Hälfte mit der linken vertauscht wird, genau wie erwartet. Beachten Sie jedoch, dass im Vergleich zu Code 04 der einzige Zusatz in Code 06 die Zeile 40 ist (plus eine kleine Anpassung in Zeile 41). Das ist aber nicht der Teil, den ich hervorheben möchte. Was ich Ihnen wirklich zeigen möchte, ist die Funktion, die ich verwendet habe, um zu testen, welche Methode wir für die Spiegelung verwenden sollten.
Diese Funktion StringFind aus der MQL5-Standardbibliothek ermöglicht die Suche nach einer bestimmten Teilzeichenkette innerhalb der von typename zurückgegebenen Zeichenkette. Dies ist sehr wichtig, denn unabhängig davon, ob wir den deklarierten Typ der Variablen oder den primitiven Typ des Compilers verwenden, kann das gesuchte Fragment in beiden Typen erscheinen. Und das ist der Hauptgrund, warum ich gerade diese Funktion verwende: StringFind wird sowohl „uchar“ als auch „char“ erfolgreich erkennen. Der einzige Unterschied zwischen den beiden ist der Buchstabe „u“ am Anfang von „uchar“. In jedem Fall wird der Test durchgeführt und ein Ergebnis zurückgegeben.
Allerdings ist jeder Fall einzigartig. Je nachdem, was Sie in Ihrem Code aufbauen wollen, kann dieser kleine Unterschied zwischen den Typnamen, auch wenn sie dieselbe Bytegröße haben, das Endergebnis beeinflussen. Das liegt daran, dass wir im einen Fall negative Werte haben können, im anderen Fall aber nicht. Natürlich können wir dies bei Bedarf durch explizite Typisierung korrigieren. Dennoch lohnt es sich, darauf zu achten, wenn Sie sich auf vom Compiler generierte Typinformationen verlassen.
Jetzt beginnt der lustige Teil. Wie Sie vielleicht bemerkt haben, ist das Ergebnis in Abbildung 04 korrekt, alles funktioniert einwandfrei. Wir müssen jedoch noch das seltsame Ergebnis in Abbildung 03 berücksichtigen. Ich habe keine Ahnung, warum der Compiler beschlossen hat, uns einen „kleinen Streich“ zu spielen. Wenn wir Code 06 so ändern, dass er dieselben Informationen anzeigt, die Code 05 gedruckt hat, funktioniert alles einwandfrei. Beim Kompilieren von Code 05 ist jedoch etwas BIZARES passiert, was zu der in Abbildung 03 zu sehenden seltsamen Ausgabe führte.
Um dies zu beweisen, wird der geänderte Code unten gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 42. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 43. { 44. tmp = arg.u8_bits[i]; 45. local.u8_bits[i] = arg.u8_bits[j]; 46. local.u8_bits[j] = tmp; 47. } 48. 49. return local; 50. } 51. //+------------------------------------------------------------------+
Code 07
Beachten Sie, dass Code 07 eine Kombination aus Code 05 und Code 06 ist. Wenn wir es ausführen, erhalten wir die folgende Ausgabe:
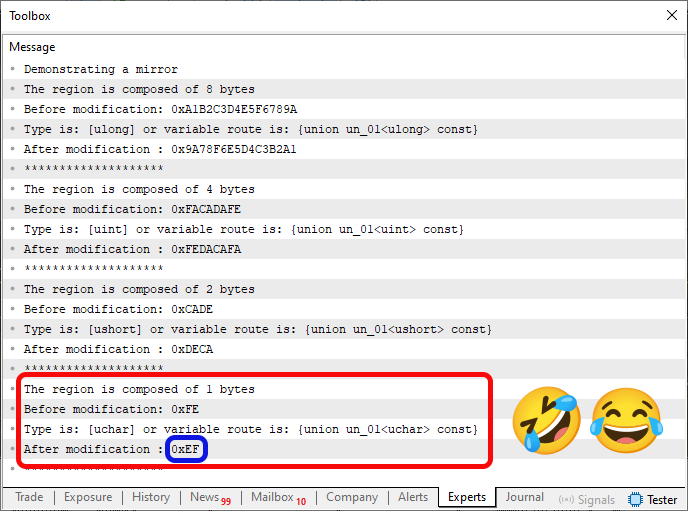
Abbildung 05
Ist das nicht witzig? Wer weiß schon, was bei der Kompilierung oder Ausführung von Code 05 wirklich passiert ist? Zum Glück haben wir es mit Beispielen zu tun, bei denen eine kleine Marotte oder Ungereimtheit nicht viel ausmacht. Dennoch ist es amüsant, diese seltsamen Compiler-Überraschungen zu sehen.
Abschließende Überlegungen
In diesem Artikel haben wir die Erklärungen und Übungen abgeschlossen, die Ihnen helfen sollen, wirklich zu verstehen, was das Überladen von Funktionen und Prozeduren ist. Ziel war es, zu zeigen, wie derselbe Funktions- oder Prozedurname mit verschiedenen Datentypen wiederverwendet werden kann.
Wir begannen diese Reise mit einfachen Beispielen, wie denen in Von der Grundstufe bis zur Mittelstufe: Überladen und gingen allmählich zu komplexeren Fällen über, indem Vorlagen für Funktionen und Prozeduren erstellt wurden. Da diese Konzepte über Funktionen und Prozeduren hinausgehen, begannen wir mit der Verwendung von Vorlagen, um den Codierungsaufwand zu verringern. Durch die Verwendung von Vorlagen können wir die Erzeugung von überladenen Versionen effektiv an den Compiler delegieren, was unser Leben als Programmierer sehr viel einfacher macht.
Das Konzept der Vorlagen lässt sich jedoch noch weiter ausbauen, zum Beispiel um komplexere Datentypen zu erstellen und zu verwalten. In dieser Serie haben wir uns speziell auf unions konzentriert und unsere Beispiele innerhalb dieses Modellierungsrahmens gehalten. Dies ermöglichte es uns, mit Typüberladungen zu experimentieren. Dies wiederum eröffnete die Möglichkeit, mit weniger Code mehr zu erreichen. Der Compiler übernahm die Verantwortung für die Wahrung der Konsistenz und Korrektheit. Unsere Aufgabe bestand lediglich darin, ihm mitzuteilen, welchen primitiven Typ er verwenden sollte.
Wir können jedoch noch weiter gehen und Möglichkeiten zur Steuerung des Verhaltens einführen, je nachdem, welcher primitive Typ in unserem Code verwendet wird. Um dies zu erreichen, verwenden wir typename, wodurch wir den genauen Typ identifizieren können, der gehandhabt wird, entweder durch den Compiler oder durch die Variable selbst bestimmt.
Ich weiß, dass vielen von Ihnen, insbesondere Anfängern, all dies kompliziert oder verwirrend erscheinen mag. Aber denken Sie daran, dass wir uns immer noch auf der grundlegendsten und zugänglichsten Ebene der Programmierkonzepte befinden. Mein Rat an Sie, liebe Leserin, lieber Leser, ist also, alles zu lernen und zu üben, was wir hier behandelt haben. Achten Sie genau auf jedes Konzept, das in diesen Artikeln bisher erklärt wurde, denn von nun an werden die Dinge nur noch anspruchsvoller und interessanter. Und für diejenigen unter Ihnen, die das Programmieren wirklich lieben – wir sind dabei, eine brandneue Spielwiese namens MQL5 zu betreten.
Wir sehen uns im nächsten Artikel, in dem wir uns mit einem noch faszinierenderen und unterhaltsameren Thema beschäftigen werden.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15671
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.