
Von der Grundstufe bis zur Mittelstufe: Struktur (V)

Einführung
Im vorigen Artikel, „Von der Grundstufe zur Mittelstufe: Struct (IV)“ haben wir begonnen, die Programmierung zur Erstellung von strukturiertem Code ernsthafter und anwendungsorientierter zu diskutieren. Vielen mögen diese Punkte albern und praxisfern erscheinen, zumal der Schwerpunkt heutzutage fast ausschließlich auf der objektorientierten Programmierung liegt. Und viele sind sich nicht bewusst, dass OOP nicht über Nacht entstanden ist. Sie ist das Ergebnis umfangreicher Forschungen und Debatten innerhalb der gesamten Programmiergemeinschaft und entstand erst, als die Grenzen der strukturellen Programmierung offensichtlich wurden.
Im Gegensatz zur konventionellen Programmierung, bei der wir Variablen, Funktionen und Prozeduren deklarieren, um eine bestimmte Aufgabe zu lösen, zielt die strukturelle Programmierung jedoch auf einen Ansatz ab, bei dem wir nicht nur eine Aufgabe, sondern eine ganze Reihe miteinander verbundener Probleme lösen können.
Ich weiß, dass viele von Ihnen (insbesondere Anfänger) wahrscheinlich denken: „Freund, ich will das nicht lernen. Ich möchte lernen, wie man einen Expert Advisor oder einen Indikator erstellt. Zu lernen, wie man Lösungen implementiert, die ich gar nicht nutzen will, ist einfach nichts für mich“. Na gut, Sie haben das Recht, so zu denken. Aber wenn Sie nicht verstehen, wie man Lösungen implementiert, die nichts mit einem Indikator oder sogar einem Stück EA-Code zu tun haben, werden Sie schneller in eine Sackgasse geraten, als Sie denken. Dies geschieht, weil Sie nicht verstehen, wie man Lösungen umsetzt, die weder offensichtlich noch einfach sind.
Um alle auftretenden Probleme lösen zu können, müssen Sie die Denkweise eines Programmierers haben. Und eines dieser Probleme ist genau das, was bisher noch nicht erklärt wurde: wie man die strukturelle Programmierung erweitern kann, um umfassendere Aufgaben zu lösen. Mit anderen Worten: Wenn wir einen Code zur Lösung eines Problems mit ganzzahligen Typen erstellen, wie können wir dann eine Lösung für Fließkommadaten implementieren, ohne alles von Grund auf neu zu machen? Das ist eine sehr interessante Frage, die aber auch sehr verwirrend sein kann, da es verschiedene Wege gibt, um das Gleiche zu erreichen.
Ich werde versuchen, mindestens zwei verschiedene Möglichkeiten zu erläutern, dies zu tun. Die zweite Methode beinhaltet Speichermanipulationen, und ich weiß nicht, ob Sie dazu bereit sind. Beginnen wir jedoch mit der einfachsten Variante. So erhalten Sie eine allgemeine Vorstellung davon, wie Sie das Problem angehen können. Es ist also an der Zeit, sich darauf zu konzentrieren, worum es in diesem Artikel geht. Jetzt wird es interessant.
Wie man Vorlagen in Strukturen verwendet
Hier werden wir die erste Methode der Verwendung von Vorlagen in Datenstrukturen analysieren, die die einfachste Art ist, zu verstehen, wie Strukturen überladen werden. Denken Sie daran, dass alles, was hier gezeigt wird, nur zu Bildungszwecken dient. Dieses Material sollte unter keinen Umständen als endgültiger Code betrachtet werden, der ohne entsprechende Vorsichtsmaßnahmen verwendet werden kann.
Beginnen wir mit dem Code aus dem vorigen Artikel, denn er enthält etwas, das ich in Bezug auf das, was wir hier tun werden, recht praktisch und leicht verständlich finde. Die Version, die wir verwenden werden, ist unten dargestellt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Code 01
Wenn wir den Code 01 in der MetaTrader 5-Plattform ausführen, erhalten wir das folgende Ergebnis:

Abbildung 01
Noch nichts Besonderes. Stellen Sie sich jedoch die folgende Situation vor: Code 01 ist so implementiert, dass er uns zwei Dinge sagt: den Durchschnittswert und den Median einer Reihe von Werten. Dies ist jedoch nur bei Fließkommawerten möglich, insbesondere bei Double-Werten, da es Float-Werte nicht versteht, obwohl auch dies ein Fließkomma-Datentyp ist. Von ganzzahligen Werten ganz zu schweigen.
In diesem Fall ist der Code 01 trotz seiner offensichtlichen Zweckmäßigkeit weitgehend nutzlos, denn um mit anderen numerischen Datentypen als double zu arbeiten, müssten wir die Struktur immer wieder neu implementieren, bis alle numerischen Datentypen abgedeckt sind.
Solche Situationen werden als Überladung bezeichnet. Das Überladen von Strukturen funktioniert jedoch nicht auf die gleiche Weise wie das Überladen von Funktionen und Prozeduren. In diesem Fall müssten wir beim Überladen den Namen der Struktur ändern, d. h. die in Zeile 04 von Code 01 verarbeiteten Informationen.
Als Ergebnis würden wir eine Reihe neuer Strukturen mit demselben Zweck, demselben Kontext und denselben gekapselten Daten, aber mit völlig unterschiedlichen Namen erstellen. Mit anderen Worten: ein völliges Chaos und ein riesiger Arbeitsaufwand.
Programmierer, und ich spreche aus Erfahrung, mögen keine zusätzliche Arbeit. Wenn wir einen Code mehr als einmal wiederholen müssen, beginnen wir uns zu langweilen und verlieren das Interesse. Wir lieben es, über die Lösung von Problemen nachzudenken. Aber Code zu duplizieren, nur um ein Detail zu ändern, ist nicht nach unserem Geschmack. Ich hasse es definitiv, es zu tun. Andere Programmierer, wie ich, haben auch herausgefunden, wie man ein solches Problem lösen kann, und haben einen Mechanismus geschaffen, der das Überladen von Dingen, die nicht überladen werden können, ermöglicht. So wurde die Idee geboren, Strukturvorlagen zu verwenden.
In ihrer Grundform haben wir Vorlagen bereits in einer kurzen Serie von fünf Artikeln erläutert, von denen der erste „Von der Grundstufe bis zur Mittelstufe: Vorlage und Typenname (I)“ heißt. Es ist also sehr wichtig, dass Sie alle dort erläuterten Kenntnisse und Konzepte beherrschen, um zu verstehen, was nun zu tun ist. Der Grund dafür ist, dass das, was zuvor erklärt wurde, unklar bleibt. Was wir jetzt tun werden, macht keinen Sinn.
Aber was wir zeigen werden, ist der einfachste und leichteste Weg, um mit Strukturüberladung zu arbeiten, obwohl es andere Wege gibt, die viel komplexer sind und sehr spezifische Ziele haben. Ich werde überlegen, ob es sich lohnt, einen Artikel zu erstellen, in dem andere Methoden vorgestellt werden. In jedem Fall ist es am einfachsten, eine Vorlage zu verwenden.
Gehen wir also einen Schritt zurück, denn bevor wir die Anwendung einer Strukturvorlage auf eine strukturierte Implementierung in Betracht ziehen, müssen wir sehen, wie sie auf eine allgemeinere Struktur anwendbar ist. Mit anderen Worten: Wir müssen untersuchen, wie eine Strukturvorlage in regulärem Code verwendet wird. Zu diesem Zweck ändern wir den Code 01 von strukturell in regulär. Das Endergebnis wird wie folgt aussehen:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
Code 02
Also gut, Code 02 hat jetzt ein reguläres Format. Bei der Ausführung im MetaTrader 5 erhalten wir das folgende Ergebnis:

Abbildung 02
Nach allem, was bisher erklärt wurde, bin ich zuversichtlich, dass Sie leicht verstehen werden, was der Code 02 tut und wie er funktioniert. Genauso wie wir mit einem Gleitkommatyp arbeiten können, können wir hier Funktions- und Prozedurvorlagen implementieren. Der Code 02 wird also wie folgt lauten:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
Code 03
„Was für eine kosmische Komplikation. Mein Freund, was ist das für ein verrückter und verrückter Code? Müssen wir das wirklich durchmachen?“ Beruhigen Sie sich, dieser Code ist nicht so verrückt wie derjenige, der Speichermanipulation verwendet. Ich werde also überlegen, ob es sich lohnt, zu zeigen, wie man die Strukturüberladung durch Speichermanipulation implementiert. Ein Großteil des Codes 03 wird Ihnen jedoch bereits bekannt und verständlich sein. Vielleicht sind die Zeilen 44 und 45 die einzigen, die eine gewisse Überraschung bieten.
Etwas Ähnliches wurde übrigens in dem Artikel „From Basic to Intermediate: Template and Type Name (IV)“ diskutiert, aber nicht in Bezug auf die Verwendung von Strukturen, sondern in Bezug auf die Verwendung von Unions. Die Funktionsprinzipien sind in jedem Fall dieselben. Und da dort bereits alles erklärt wurde, sehe ich keine Notwendigkeit, dasselbe Konzept noch einmal zu erklären, zumal dies in zwei Artikeln notwendig war.
Wenn Sie also nicht verstehen, was in Code 03 passiert, empfehle ich Ihnen, zu den vorherigen Artikeln zurückzugehen. Wie ich schon sagte, sammelt sich das Wissen mit der Zeit an. Der Versuch, Stufen zu überspringen und zu glauben, man könne etwas Komplexeres verstehen, ohne zuerst die grundlegenden Konzepte zu erfassen, führt selten zu einem guten Ergebnis.
Gut, aber es gibt hier ein kleines Detail, das auf den ersten Blick vielleicht nicht irritierend ist: der Datentyp, den der Median zurückgibt. Das Problem hängt damit zusammen, dass, wenn das Array eine gerade Anzahl von Elementen enthält, der Test in Zeile 28 den Ablauf so verändert, dass Zeile 32 ausgeführt wird. Wenn die Anzahl der Elemente jedoch ungerade ist, wird Zeile 34 ausgeführt, was in vielen Fällen zu einem anderen Wert als dem erwarteten führt.
Dies liegt daran, dass ein Array mit Integer-Elementen im Prinzip keinen Gleitkommawert zurückgeben sollte, wie es hier der Fall ist. Daher stimmt das auf dem Terminal ausgegebene Ergebnis nicht ganz mit den Werten des in Zeile 42 deklarierten Arrays überein, da das Array Ganzzahl-Elemente hat, der zurückgegebene Wert aber vom Fließkomma-Typ ist. Aber da dieser Code rein lehrreich ist, ziehe ich es vor, diese kleine Diskrepanz zu lassen, anstatt ein völlig falsches Ergebnis zu zeigen.
Wenn man also Code 03 betrachtet und darüber nachdenkt, wie man ihn in etwas Ähnliches wie Code 01 umwandeln kann, der eine strukturelle Implementierung hat, ist es einfach, den richtigen Weg zu erkennen, denn es reicht aus, Code 01 so zu ändern, dass die in Code 03 gezeigte Template-Deklaration ausgeführt wird.
Aber vielleicht stört Sie die Tatsache, dass wir in Code 03 die Funktionen als Vorlagen implementieren mussten. „Müssen wir also dasselbe mit Code 01 tun, damit die strukturelle Implementierung korrekt funktioniert und der Compiler weiß, wie er die Struktur überladen kann?“ Nun, in diesem Fall ist das nicht nötig, weil der Kontext selbst recht einfach ist und es nicht viel hinzuzufügen gibt.
Im Gegensatz zu Code 03, bei dem die Werte der Struktur per Verweis übergeben werden, ist dies bei Code 01 jedoch nicht möglich. Der Grund dafür wurde bereits im vorangegangenen Artikel erläutert, in dem die Frage des Kontexts zusammen mit der Frage der Datenkapselung behandelt wurde. Die einzige Möglichkeit, neue Werte einzuführen, ist die Prozedur Set, die in Code 01 enthalten ist. Daher wird dieser Punkt einer der wenigen sein, bei dem wir etwas anderes implementieren müssen als das, was ursprünglich in Code 01 vorhanden ist. Im Folgenden zeigen wir den neuen Code 01, der bereits die Überladung von Strukturen berücksichtigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
Code 04
Bitte beachten Sie, wie einfach es ist, den Code 01 in einen Code umzuwandeln, der strukturelle Überladung erzeugen kann und schließlich zu einem vollständig strukturellen Code führt. Da die Funktionen und Prozeduren im Kontext der Struktur deklariert werden, erben sie deren eigene Deklaration. Dies geschieht, wenn der Compiler die Überladung der Struktur selbst vornimmt.
Wie bereits erwähnt, ergibt sich das Problem mit den Rückgabewerten gerade deshalb, weil wir an einigen Stellen Ganzzahlwerte in Fließkommazahlen umwandeln werden, insbesondere vom Typ double, was in einigen Fällen problematisch werden kann. Dies ist in den Zeilen 20 und 30 von Code 04 zu sehen. „Aber warte mal kurz. Ich verstehe nicht, warum das ein Problem sein könnte. Und wenn ja, gibt es eine Möglichkeit, sie zu überwinden, um unnötige Risiken zu vermeiden?“
Um dies zu verstehen, müssen wir zunächst sehen, was das Ergebnis der Ausführung von Code 04 sein wird. Siehe unten:
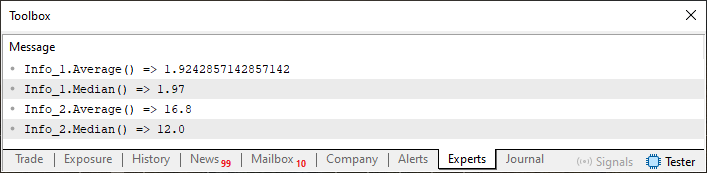
Abbildung 03
Achten Sie nun auf ein Detail in Bild 03. Beachten Sie, dass es sich bei dem von Info_2.Median zurückgegebenen Wert um einen Fließkommawert handelt, während Info_2, wenn es im Code deklariert wird, vom Typ Ganzzahl ist, wie in Zeile 55 zu sehen ist. Das Problem liegt darin, dass die Struktur eine solche Situation nicht gut handhabt, wenn wir sie auffordern, den in der Datenstruktur selbst vorhandenen Medianwert zurückzugeben, und das System am Ende einen anderen Typ zurückgibt. Korrekterweise sollte es einen Integer-Wert zurückgeben, aber wir geben einen Fließkommawert zurück.
Solche scheinbar einfach zu lösenden Probleme erweisen sich in der Praxis und im realen Code als viel komplexer. Vor allem aber verwenden viele Programmierer (und ich sage das im allgemeinen Sinne) eine Methode, bei der sie immer mehr Funktionen und Prozeduren hinzufügen, um ein internes Problem der Struktur selbst zu lösen. In den meisten Fällen löst dies das Problem, auch wenn es oft zu Lösungen oder Implementierungen führt, die für andere Programmierer prinzipiell nicht viel Sinn machen. Der Grund dafür ist einfach: Der beste Weg, ein Problem zu lösen, besteht nicht darin, es zu lösen, sondern Mechanismen bereitzustellen, die es ermöglichen, das Problem in kleinere Teile zu zerlegen.
„Aber wie kann das sein? Hier scheint es einen Widerspruch zu geben“. Um dies zu verstehen, müssen wir den Code 04 als Lehrmechanismus verwenden. „Erster Punkt: Warum müssen wir den Durchschnittswert direkt über eine Funktion zurückgeben?“ Man könnte antworten, dass der Code einfacher wird, wenn man die Struktur selbst verwendet. Das wäre in der Tat ein gutes Argument.
Aber kehren wir zurück zum Fall der Ganzzahlen, wie in der Anweisung in Zeile 55. Der Durchschnitt der Elemente, die wir dort, d.h. in Zeile 61, platzieren, ist in Wirklichkeit eine Gleitkommazahl, in diesem Fall 16,8. Aber betrachten Sie eine Situation, in der wir einen Durchschnittswert benötigen, der eine ganze Zahl sein sollte. Das würde eine Rundung erfordern. Für solche Situationen gibt es Rundungsregeln, aber das ist nicht der Fall.
Das Ziel ist, dass der Programmierer, der diese Struktur verwendet, weiß, wie, wann und warum er den Wert runden muss. Die Aufgabe besteht darin, einen ganzzahligen Wert zu erhalten.
Um dies zu erreichen, müssen wir den Kontext dessen, was wir in der Struktur umsetzen, ändern. Häufig entfernen wir nicht Teile des Codes, sondern fügen neue hinzu und schaffen so kleinere und präzisere Blöcke. Um dies besser zu verstehen, wollen wir uns ein praktisches Beispiel ansehen. Wie Sie sehen, gibt es in Zeile 20 des Codes 04 eine Funktion, die den Durchschnitt der eigenen Werte der Struktur errechnet. Bislang nichts Außergewöhnliches.
Um diesen Durchschnitt zu erhalten, müssen wir jedoch zwei Dinge tun: erstens die Summe der Elemente ermitteln und zweitens herausfinden, wie viele Elemente es insgesamt gibt. Sie werden jetzt vielleicht denken: „Richtig, was kommt als Nächstes?“ Wenn wir dies nicht direkt in der Funktion Durchschnitt tun, sondern zwei andere Funktionen erstellen, können wir dem Nutzer der Struktur die Möglichkeit geben, zu wählen, wie, wo und warum die Durchschnittswerte der Strukturelemente gerundet werden sollen.
Ich weiß nicht, ob Sie, liebe Leserinnen und Leser, das Wesentliche verstanden haben, aber sehen wir uns einmal an, wie das in der Praxis abläuft. Hierfür verwenden wir den folgenden Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
Code 05
In Code 05 modellieren wir also etwas, von dem viele denken, dass es nur bei der Arbeit mit OOP vorkommt, das aber seinen Ursprung in der strukturellen Programmierung hat: die Zerlegung von Code in kleine Blöcke. Bitte beachten Sie, dass wir in Zeile 20 dieses Codes nun eine Funktion haben, deren Zweck es ist, die Summe aller Elemente in der Struktur zurückzugeben. Der Rückgabetyp hängt von der Art der Daten ab, die in der Struktur selbst enthalten sind. Achten Sie darauf, denn es ist wichtig. Außerdem gibt es eine weitere Funktion in Zeile 30, die die Anzahl der Elemente in der Struktur selbst zurückgeben soll.
Jetzt beginnt der interessanteste Teil. Da sich der Durchschnitt aus der Division dieser beiden Größen ergibt, die wir in den oben genannten Funktionen berechnen, haben wir in Zeile 37 eine Berechnung, die sich am Kontext der Struktur orientiert. Aber das ist der springende Punkt. Bitte beachten Sie, dass wir den Compiler anweisen, das Ergebnis der Funktion Summe in den Typ double zu konvertieren. Warum das? Die Antwort ist im Ausführungsbild von Code 05 zu sehen. Und zwar so:
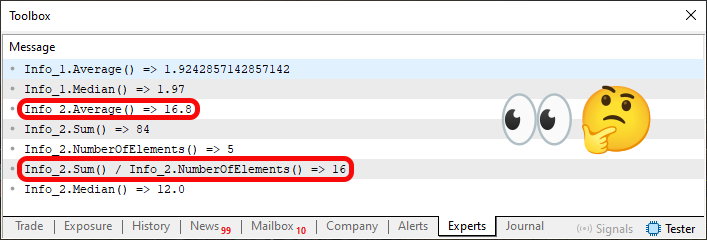
Abbildung 04
In diesem Bild fallen zwei Informationsfragmente auf: das eine entspricht der Ausführung der Zeile 72, das andere der Zeile 75. Bitte beachten Sie jedoch, dass die beiden vorgestellten Datentypen unterschiedlich sind. Die eine ist eine Fließkommazahl, die andere eine Ganzzahl. Im Folgenden wird erklärt, warum das Ergebnis der Funktion Summe in Zeile 37 in double umgewandelt wird. Man beachte, dass dieselbe Berechnung, die in Zeile 37 durchgeführt wurde, in Zeile 75 wiederholt wird, aber in einem Fall wird der Wert 84, der das Ergebnis der Summierung der Elemente in Zeile 62 wäre, in Double umgewandelt, im anderen Fall nicht. Obwohl der Kontext uns erlaubt, den Durchschnitt direkt innerhalb der Struktur zu berechnen, wie in Zeile 37 geschehen, können wir dies auch außerhalb der Struktur tun. Aus diesem Grund können wir genau kontrollieren, wie das Ergebnis in Bezug auf den verwendeten Datentyp aussehen wird.
Das mag absurd erscheinen, aber wir haben dem Programmierer die Möglichkeit gegeben, die Darstellung des Ergebnisses zu kontrollieren, anzupassen und sogar auszuwählen, ohne das Wesen der Dinge zu verändern – etwas, das sonst sehr viel schwieriger und zeitaufwändiger gewesen wäre. All dies wurde einfach dadurch erreicht, dass Berechnungen (die zuvor in einer Funktion durchgeführt wurden) in mehrere Funktionen verlagert wurden, die außerhalb des Strukturkörpers zugänglich sind. Dabei gelingt es uns jedoch, den Kontext der Struktur selbst zu erhalten, denn wenn wir uns die Zeile 75 ansehen, wissen wir, welche Art von Informationen wir brauchen.
Wenn Sie solche Dinge studieren, werden Sie verstehen, dass dies in den meisten Fällen gemeint ist, wenn wir über Klassen und objektorientierte Programmierung sprechen. Mit diesem einfachen Code haben wir jedoch gezeigt, dass dieses Konzept unabhängig von OOP existiert. Wenn man Ihnen also in Zukunft von diesem Programmiermodell erzählt, haben Sie bereits eine gute Grundlage, denn Sie werden sehen, dass OOP genau darauf abzielt, die Lücken zu füllen, die die strukturierte Programmierung nicht schließen kann.
„Gut, das war interessant, aber könnten wir etwas anderes machen, ohne die Dinge zu sehr zu verkomplizieren?“ Ja, mein lieber Leser. Es gibt ein Konzept – wenn auch nicht unbedingt ein Konzept, sondern eher eine Technik, die verschiedene Programmierer in ihrem Code verwenden, um vieles von dem zu vereinfachen, was wir hier gesehen haben. Aber wenn Sie nicht verstehen, was hier besprochen wurde, wird es für Sie schwierig sein zu verstehen, was wir tun können, um strukturelle Überladungen zu erzeugen. Es lohnt sich, daran zu denken, dass die Überladung, die wir besprochen haben, darauf abzielt, eine allgemeinere Struktur zu schaffen, aber mit einem sehr spezifischen Kontext.
Da wir noch ein wenig Zeit haben, kann ich kurz skizzieren, was das erwähnte Manöver mit sich bringt. Doch dazu müssen wir innehalten und einige Punkte bedenken. Beachten Sie zunächst, dass es in den Zeilen 64 und 65 von Code 05 eine Anweisung gibt, deren Zweck es ist, diskrete Daten zu speichern, d. h. Werte, die Ganzzahlen oder Gleitkommazahlen sein können. Wenn man jedoch darüber nachdenkt, sind auch Unions und Strukturen Formen von Daten, sodass auch sie als Datentyp deklariert werden können, um in einer Struktur verwendet zu werden, deren Code überladen wird, um ein für diesen spezifischen Datentyp geeignetes Modell zu erstellen.
Ich denke, Sie haben dies bereits begriffen und wahrscheinlich in den Artikeln geübt, in denen wir besprochen haben, wie Überladung und die Verwendung von Vorlagen im Code funktionieren. Im Gegensatz zu diskreten Datentypen sind Typen wie Unions und Strukturen jedoch komplexer, da sie eine Vielzahl von Dingen enthalten können. Nehmen wir zum Beispiel die Struktur MqlRates. Sie definiert Elemente wie Eröffnungskurs, Schlusskurs, Spread, Volumen usw. Obwohl wir also im Prinzip eine Strukturvorlage deklarieren können, die jede Art von Information aufnehmen kann, seien es komplexe oder diskrete Werte, gibt es komplizierende Faktoren, die uns daran hindern, komplexe Typen zu definieren, wo diskrete Typen erwartet wurden. Das hält uns aber nicht davon ab, spezifische Mechanismen zu schaffen, die für die Lösung bestimmter Aufgaben auf weniger kostspielige Weise erforderlich sind.
Ich möchte also, dass Sie darüber nachdenken, wie wir Daten wie Unions oder Strukturen in einem Code verwenden können, der dem in Code 05 ähnelt, um das Überladen der Struktur auf verschiedene Weise zu verallgemeinern und so einen vollständig strukturellen Code zu erstellen. Ich weiß, dass dies nicht die einfachste Aufgabe ist, aber ich möchte, dass Sie darüber nachdenken, denn im nächsten Artikel werden wir untersuchen, was genau damit zusammenhängt.
Abschließende Gedanken
In diesem Artikel haben wir versucht, das Überladen von strukturellem Code auf die einfachste, didaktischste und praktischste Weise zu erklären. Ich weiß, dass es anfangs schwierig sein kann, das zu verstehen, vor allem, wenn man es zum ersten Mal sieht. Es ist sehr wichtig, dass Sie diese Konzepte erfassen und gut verstehen, bevor Sie versuchen, sich in komplexere und umfangreichere Themen zu vertiefen.
Im Anhang finden Sie die Codes für Studium und Praxis. Im nächsten Artikel werden wir die Messlatte noch höher legen, indem wir diese Art der Implementierung auf Fälle ausweiten, in denen wir jeden Datentyp in der Strukturüberladung selbst verwenden können – etwas, von dem viele glauben, dass es nur in OOP möglich ist. Aber Sie werden sehen, dass wir für die Implementierung bestimmter Arten von Lösungen immer noch kein OOP benötigen. Also, viel Erfolg beim Studium! Wir sehen uns bald wieder.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15869
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.