
От начального до среднего уровня: Объединение (II)

Введение
Представленные здесь материалы предназначены только для обучения. Ни в коем случае нельзя рассматривать это приложение как окончательное, цели которого будут иные, кроме изучения представленных концепций.
В предыдущей статье От начального до среднего уровня: объединение (I), мы начали говорить о том, что такое объединение, поскольку, на самом деле, эта тема уже готовилась к рассмотрению с момента написания первой статьи, так как всё, что раскрывается здесь и в следующих статьях, так или иначе связано друг с другом. В любом случае, материал из предыдущей статьи, - это только начало правильного изложения, каким должно быть объединение. На самом деле данная тема довольно объемная, как и всё то, что связано с вопросами о массивах.
В этой статье мы не только узнаем больше о объединениях, но и расширим наши знания о массивах. Итак, устраивайтесь поудобнее и давайте перейдем к первой теме данной статьи.
Массивы и объединения
Объединения - это действительно интересная тема, которая открывает двери к гораздо более сложным темам в области программирования. Однако мы должны быть осторожны, чтобы не совершить ошибку, думая, что мы уже понимаем тему только потому что рассмотрели её основы.
Причина в том, что многие игнорируют данную концепцию и цепляются лишь за хрупкую и непродуктивную идею, полагая, что, объявив объединение, мы ограничиваем всё той простой моделью, которая была создана во время объявления, тогда как на самом деле мы можем сделать гораздо больше, если правильно применим концепцию данного инструмента.
В предыдущей статье мы упоминали, что, объявляя, как будет собираться объединение, мы создаем особый тип данных, похожий на строку. Однако многие могут с некоторой опаской относиться к определенным структурам, использующим этот тип созданных данных.
Чтобы понять, как это может показаться интересным и почему кто-то поступил бы таким образом, необходимо разобраться в одной маленькой детали. Поскольку объединение - это, по сути, новый и особый тип, мы можем использовать его по-разному, как в объявлении, так и в способе использования этого типа данных, специально созданного для конкретной ситуации. Ниже можно увидеть первый пример.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits; 07. uchar u8_bits[4]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info[2]; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. for (uchar c = 0; c < info.Size(); c++) 20. info[c] = Swap(info[c]); 21. View(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg[], ulong value) 25. { 26. arg[0].u32_bits = (uint)(value >> 32); 27. arg[1].u32_bits = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg[]) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg[c].u32_bits); 35. } 36. //+------------------------------------------------------------------+ 37. un_01 Swap(const un_01 &arg) 38. { 39. un_01 info = arg; 40. 41. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = info.u8_bits[i]; 44. info.u8_bits[i] = info.u8_bits[j]; 45. info.u8_bits[j] = tmp; 46. } 47. 48. return info; 49. } 50. //+------------------------------------------------------------------+
Код 01
Запустив код 01, мы увидим в терминале MetaTrader 5 следующий вывод:
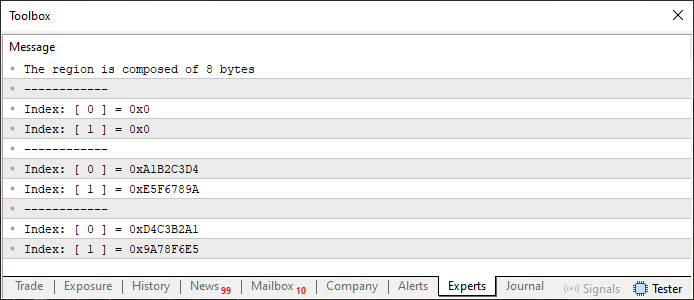
Рисунок 01
В коде 01 мы применим всё, что видели ранее, как в отношении схемы и работы с массивами, так и в отношении работы с объединением. Обратите внимание, что в строке 12 мы объявляем массив статического типа. Это может показаться странным, поскольку вы, возможно, до сих пор думаете, что в массивах можно использовать только дискретные типы. Но здесь мы используем специальный тип, который был объявлен в строке 4. Всё очень просто.
Однако при выполнении строки 14 можно заметить, что на первом месте выводится информация о том, что переменная info состоит из 8 байт. Но на первый взгляд это не имеет смысла. Если у вас возникло такое чувство, советую вернуться и изучить предыдущую статью, потому что на самом деле переменная info состоит из 8 байт, так как в качестве наибольшей возможной ширины у нас есть переменная u32_bits, которая имеет тип uint. Поэтому на самом деле это будет выглядеть так, как если бы мы объявили что-то вроде такого:
. . . 12. uint info[2]; . . .
Я думаю, это вас не запутает. Однако в этой же строке есть скрытое утверждение, которое более наблюдательный программист также мог бы заметить. Это именно то, что видим ниже:
. . . 12. uchar info[2][4]; . . .
Ух ты! Секунду, что за историю вы мне рассказываете о том, что у нас есть два способа взглянуть на один и тот же код и два способа написать одно и то же? Теперь я совсем запутался, это не имеет для меня никакого смысла.
Что ж, именно поэтому я настаиваю на том, чтобы вы изучали и практиковали то, что показано в каждой статье. Самая большая проблема, которую я вижу почти у всех новичков, заключается в том, что они слишком сильно придерживаются форм и моделей программирования, они не стремятся понять концепцию, которая создается и применяется, они строго придерживаются того, что программируют.
В предыдущей статье я упоминал, что при создании объединения, мы фактически разделяем и делим задачи на более мелкие блоки. Таким образом, можно взять блок памяти, который будет довольно большим, и разделить его на более мелкие блоки, чтобы манипулировать его содержимым. По этой причине мы можем вращать, изменять или менять местами конкретные точки без использования определенных операторов. Это не связано с тем, что объединение - нечто магическое, так происходит, потому что создаваемое нами, в одно и то же время может быть истолковано по-разному.
Хотя мы не упоминали об этом раньше, оба показанных выше способа написания строки 12, представляют собой одно и то же, только они по-разному разделены. В первом случае у нас есть массив с двумя элементами, где каждый элемент состоит из четырех байт. Во втором случае у нас те же два элемента, только на этот раз каждый элемент состоит из четырех байт. Многие люди считают многомерные массивы сложными для понимания. Однако многомерный массив, как можно видеть из второго варианта написания строки 12, - это не что иное, как тот же самый массив, что и раньше, только написанный другим способом.
Многомерные массивы очень полезны для работы в различных ситуациях, но они будут более понятны, когда мы перейдем к другой теме - к матрицам. До этого момента я не вижу особого смысла говорить о многомерных массивах. Так что не переживайте, сосредоточьтесь на том, что показано здесь и сейчас. Другими словами, живите настоящим и не беспокойтесь о будущем.
Хорошо, после того как первые непонятные моменты в коде 01 объяснены, мы можем увидеть кое-что еще в действии.
Важное замечание: мы не будем подробно рассказывать о том, как работает код 01, потому что это уже было сделано в других статьях. Если вам непонятно, то пока я вам рекомендую изучить показанный ранее материал, поскольку я не ожидаю, что вы будете строго придерживаться кода или способа его реализации. Я хочу, чтобы вы поняли то, что мы делаем, и смогли создать свое собственное решение, чтобы получить результат, идентичный тому, который показан на изображениях. Не похожий результат, а ИДЕНТИЧНЫЙ.
Сделав это наблюдение, мы можем перейти к следующему примеру, который показан ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. info = Swap(info); 20. View(info); 21. } 22. //+------------------------------------------------------------------+ 23. void Set(un_01 &arg, ulong value) 24. { 25. arg.u32_bits[0] = (uint)(value >> 32); 26. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 27. } 28. //+------------------------------------------------------------------+ 29. void View(const un_01 &arg) 30. { 31. Print("------------"); 32. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 33. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 34. } 35. //+------------------------------------------------------------------+ 36. un_01 Swap(const un_01 &arg) 37. { 38. un_01 info = arg; 39. 40. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = info.u8_bits[i]; 43. info.u8_bits[i] = info.u8_bits[j]; 44. info.u8_bits[j] = tmp; 45. } 46. 47. return info; 48. } 49. //+------------------------------------------------------------------+
Код 02
Далее мы рассмотрим код, выполнение которого выдает другой результат. Именно это мы видим в коде 02. Он очень похож на код 01, не так ли? Однако при запуске он показывает нам следующее:
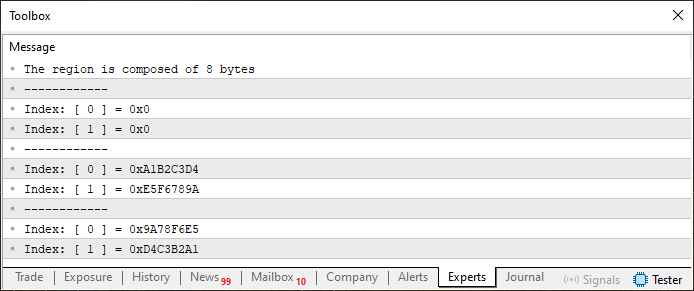
Рисунок 02
Можно подумать: "Но это то же самое, что получили и показали на изображении 1". Еще раз внимательно посмотрите на картинку 2 и сравните ее с картинкой 1. Они всё еще выглядят одинаково, даже если внимательно рассмотреть каждое значение? На самом деле они разные. И причина этого кроется именно в объявлении объединения. Обратите внимание, что теперь у нас есть два массива внутри объединения, и они оба статического типа. Но есть кое-что, что кажется не совсем логичным. В коде 01 массив в строке 7 состоял из четырех элементов, а теперь у нас их восемь. Почему? Разве нельзя было оставить те же четыре элемента?
Чтобы правильно понять это, давайте разберемся по порядку. Сначала нужно понять, зачем менять количество элементов и как это влияет на объединение. По этой причине и чтобы не усложнять код без необходимости, мы изменим значение, которое задается как количество элементов в массиве, объявленном в строке 7 так, чтобы это число всегда было ЧЕТНОЕ. Если оно нечетное, то это приведет к небольшой проблеме, которая затруднит понимание результатов. Поэтому всегда используйте четное число. Давайте предположим, что вместо восьми элементов мы поместили шесть. Весь остальной код должен будет остаться без изменений. Таким образом, мы получим нечто подобное этому:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[6]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Фрагмент 01
Видно, что мы изменили только число в строке 7, и при запуске кода 02 с этим изменением, результат будет таким, как показано ниже:
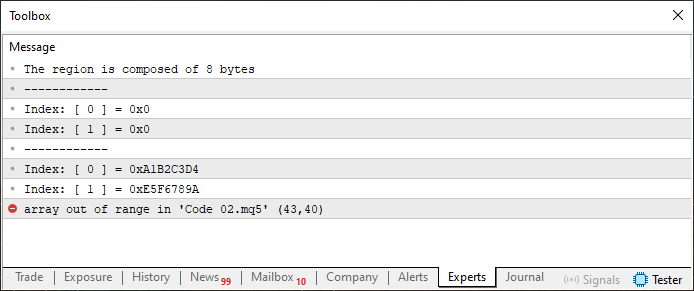
Рисунок 03
Хм, это было не очень приятно. Но теперь давайте изменим значение строки 7 так, чтобы количество элементов равнялось десяти. Таким образом, мы получим следующее:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[10]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Фрагмент 02
Запустив код, можно увидеть в результате то, что показано на изображении ниже:
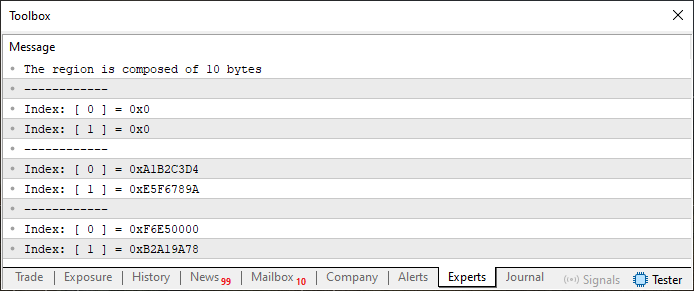
Рисунок 04
Это было не очень приятно, так как, похоже, некоторые значения просто пропали. Я действительно не мог понять, почему такое произошло. Ну что ж, мы для того и собрались здесь, чтобы понять то, что на первый взгляд не имеет особого смысла. Однако, по мере накопления опыта и практики мы будем лучше понимать, как и почему всё работает. Но главное - всегда понимать применяемую концепцию.
В первом случае, когда показали изображение 03 с ошибкой, указывающей на то, что код потерпел бы неудачу из-за попытки доступа к области, находящейся за пределами диапазона, ошибка произошла именно из-за того, что переменная info состоит из восьми байт. Но обратите внимание, в объединении присутствует переменная u8_bits, которая содержит шесть элементов, или шесть байт, поскольку каждый элемент состоит из одного байта, что обусловлено шириной типа uchar. Поэтому, когда мы используем переменную j, которая в этот момент указывает на восьмой элемент u8_bits, происходит сбой при выполнении строки 43. Именно по этой причине код не сработал. Однако при использовании большего или меньшего количества элементов в u8_bits сбоя не произошло. Прежде чем показать, как внесем исправления, чтобы иметь возможность использовать шесть элементов в u8_bits, давайте посмотрим, что произошло во втором случае, где результат именно такой, как мы видим на изображении 04.
В данном случае видно, что info содержит десять байт или десять элементов, именно потому, что в u8_bits есть те же десять элементов. Таким образом, при повороте с помощью функции Swap, присутствующей в строке 36, часть этих значений заменим на значения, инициализированные процедурой в строке 15, то есть на нули, так как ZeroMemory очистит весь блок переменной info.
По этой причине некоторые значения, очевидно, исчезли. Однако, на самом деле они не исчезли, а просто перешли в другое место. Чтобы проверить это, нужно внести небольшое изменение в код. Чтобы избежать такого же результата, как на изображениях 03 и 04, мы чуть ниже покажем новый код, который будем использовать.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. Set(info, 0xA1B2C3D4E5F6789A); 17. View(info); 18. Debug(info); 19. info = Swap(info); 20. View(info); 21. Debug(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg, ulong value) 25. { 26. arg.u32_bits[0] = (uint)(value >> 32); 27. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 35. } 36. //+------------------------------------------------------------------+ 37. void Debug(const un_01 &arg) 38. { 39. string sz = ""; 40. 41. Print("*************"); 42. for(uchar c = 0; c < (uchar)arg.u8_bits.Size(); c++) 43. sz = StringFormat("%s0x%X ", sz, arg.u8_bits[c]); 44. PrintFormat("Number of elements in %cinfo.u8_bits.Size()%c is %d\nInternal content is [ %s ]", 34, 34, arg.u8_bits.Size(), sz); 45. Print("*************"); 46. } 47. //+------------------------------------------------------------------+ 48. un_01 Swap(const un_01 &arg) 49. { 50. un_01 info = arg; 51. 52. for (uchar i = 0, j = (uchar)(info.u8_bits.Size() - 1), tmp; i < j; i++, j--) 53. { 54. tmp = info.u8_bits[i]; 55. info.u8_bits[i] = info.u8_bits[j]; 56. info.u8_bits[j] = tmp; 57. } 58. 59. return info; 60. } 61. //+------------------------------------------------------------------+
Код 03
Когда мы запускаем данный код, мы увидим нечто похожее на изображение ниже.
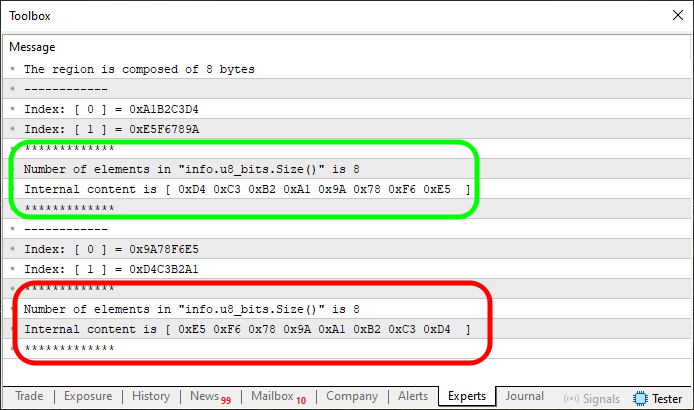
Рисунок 05
Вот то, что значительно облегчит понимание. Обратите внимание, что на изображении 05 мы выделяем две области. Но посмотрите, что код 03 является модификацией кода 02, где строка 7 - это то, что нас здесь интересует. Поскольку для стандартизации и понимания всего процесса нам необходимо некоторое исполнение, в строке 7 этого кода 03 мы используем то же значение, что и в коде 02, так что конечный результат будет именно таким, как на изображении 05.
Теперь будьте внимательны, чтобы вы могли локально воспроизвести то, что будет сделано здесь. Обратите внимание, что в строке 52 кода 03 мы внесли изменение, чтобы ошибка, наблюдаемая на изображении 03, не повторялась. Таким образом, теперь мы можем делать то, что пытались делать раньше.
Для начала воспользуемся фрагментом 01 в коде 03; полученный результат показан ниже:
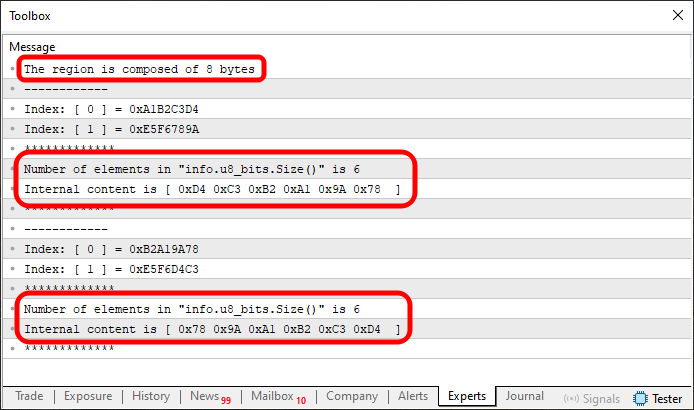
Рисунок 06
В данном случае мы отмечаем больше заслуживающих внимания моментов, потому что очень важно, чтобы вы понимали, что делается в коде. Посмотрите, несмотря на меньшее количество элементов в u8_bits, операция была выполнена. Однако, взглянув на содержимое первого индекса, мы замечаем, что часть его осталась нетронутой. Почему? Прежде чем ответить, давайте посмотрим, что произойдет, если мы используем фрагмент 02 в коде 03.
При этом мы получим результат, показанный ниже:
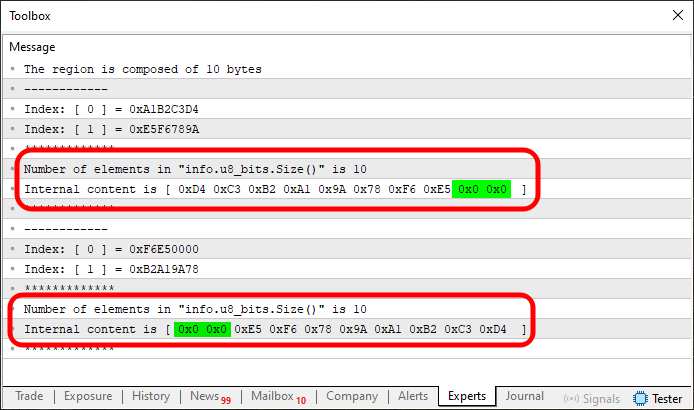
Рисунок 07
Да, на самом деле всё не так просто, как я думал. Не беспокойтесь, мои дорогие читатели, без паники. Всё здесь очень просто и практично. Вам просто нужно быть внимательным и практиковаться, чтобы понять, как всё работает. Недостаточно просто прочитать статью и всё, необходима практика. Как видно на изображениях 06 и 07, память вращается или становится зеркальной, как и ожидалось. Но результат, наблюдаемый в индексах массива при прямом доступе к элементам в u32_bits, может не соответствовать тому, что вы себе представляли. И причина этого как раз в том, что в памяти происходят разные составы.
В случае, когда объявленный в памяти состав массива полностью покрывает все байты, присутствующие в данной области, получается идеальное моделирование. Мы видим, что изображение 05 проявляет себя и показывает нам именно то, что мы представляли себе. Однако, когда мы оставляем некоторые байты неохваченными или охватываем большую часть, чем нужно, мы получаем совершенно другой (разброшенный) результат. Мы это показываем на изображениях 06 и 07, где на один из них охватывает меньший регион, а на другой - больший.
Теперь вы понимаете, почему нужно было изменить значение количества элементов в строке 7? Если сделать это неправильно, то в некоторых ситуациях мы получим недостаточный охват. Именно поэтому необходимо практиковаться и пробовать новые методы действий. Файлы находятся в приложении, но не для того, чтобы приукрасить статью, а для того, чтобы вы могли воспользоваться ими и понять, что происходит, когда мы что-то меняем в способе реализации того или иного решения. Используйте их для изучения и развития собственного представления о каждом элементе программирования, который мы показываем в этих статьях. Только тогда вы станете хорошим программистом, а не просто программистом из серий "копировать и вставить".
Ну что ж, думаю, что у нас уже есть хорошая основа для изучения того, что было показано здесь в статьях. Соответственно, я полагаю, что вы готовы решить вопрос, который был поднят в статье От начального до среднего уровня: Массив (IV). На самом деле мы собираемся сделать данный код гораздо интереснее. Чтобы объяснить это, мы перейдем к новой теме.
Сделаем еще лучше то, что и так было хорошо
Мы собираемся реализовать что-то очень веселое и хорошее. Однако, чтобы стопроцентно понять то, что будет сделано здесь, необходимо освоить материал, изложенный в предыдущей теме. Если вы не выполнили это предварительное условие, то можете запутаться в материалах данной темы. Так что не торопитесь. Лучше изучите неторопливо то, что рассматривалось до сих пор, и только потом попробуйте поиграть с MQL5.
После данного небольшого предупреждения, перейдем к нашему главному вопросу по данной теме. Для этого давайте рассмотрим код с другой статьи, о которой я недавно упоминал. Это можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Код 04
После его выполнения, код 04 выдаст следующий результат:
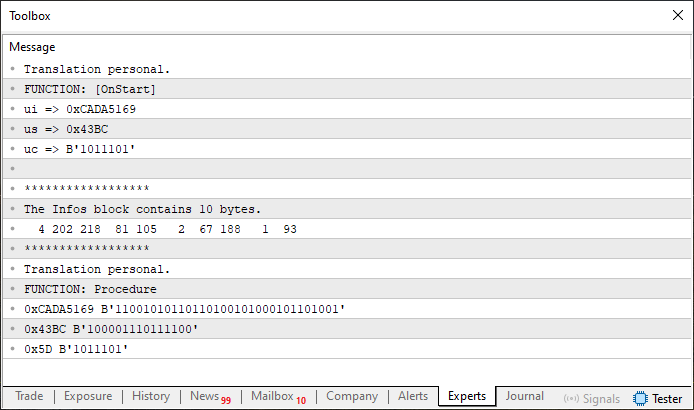
Рисунок 08
Игра и вызов, которые нам предстоит решить, как раз и заключаются в том, чтобы превратить код 04 в нечто более простое для реализации, причем таким образом, чтобы использовать уже имеющиеся ресурсы. Вы, наверное, думаете: "Как я, начинающий программист, могу использовать рассмотренные материалы, чтобы сделать код еще лучше? Это непросто. Что ж, тот, кто не практикует и не бросает себе вызов время от времени, в итоге остается позади, поскольку появляются новые моменты и концепции, более подходящие для выполнения той же самой деятельности.
И по мере появления упомянутых новых концепций наша нагрузка снижается, наша продуктивность растет, в то время как программистам из серий "копировать и вставить" становится всё труднее следовать за нами. Потому что на каждом шагу мы видим новые способы достижения того же результата, но более простым способом. Затем мы узнаем, как использовать полученные знания для улучшения кода 04. Для этого нужно сначала проанализировать, что именно делается.
В принципе, видно, что у нас есть несколько переменных и что они расположены в определенной последовательности; наибольшая ширина у типа uint, присутствующий в строке 8 и используемый между строками 28 и 35, а все остальные типы меньше. Ну что ж, раз так, то можно придумать решение, при котором массив Infos, объявленный в строке 12, получает информацию таким образом, чтобы выдать то же самое внутреннее содержимое в своей области памяти. Но что это за содержимое? Нам нужно это знать, иначе как мы можем быть уверены в правильности реализации?
Посмотрите на изображение 08, и вы увидите, что в определенный момент отображается точное содержимое массива Info. Поэтому всё, что нам нужно сделать, - это повторить тот же результат, но так, чтобы код был более приятным в использовании.
Отлично. Теперь у нас есть с чего начать. И, как показано здесь и в предыдущей статье, мы можем использовать объединение, чтобы лучше структурировать данные. Но как? Первое, что нужно сделать, - это создать правильный оператор объединения, чтобы поместить в него значения. Поскольку нам понадобятся значения типов uint, ushort и uchar (это связано со строками с 28 по 48, в которых мы обращаемся к переменным и константам, объявленным в строках 8, 9 и 10), то, вероятно, можно представить, что нам понадобится объявить три объединения. Однако достаточно объявить одну, как показано в приведенном ниже фрагменте.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { . . .
Фрагмент 03
Хорошо, обратите внимание, что во фрагменте 03 в шестой строке мы создаем объединение и объявляем дискретный тип в каждой из строк, которая будет использоваться в дальнейшем. На первый взгляд это может показаться немного запутанным, но на самом деле важна именно строка 11, поскольку именно в ней разрешен доступ ко всей области, принадлежащей объединению типов. Обратите внимание, что мы объявляем статический массив с количеством элементов, равным наибольшему дискретному типу в объединении. Это можно делать до тех пор, пока мы сомневаемся в том, сколько байт необходимо для объединения.
Вы, наверное, думаете: "Но подождите минутку... Если я правильно понимаю, когда мы изменяем значение (точнее, переменную), присутствующее в объединении, мы изменяем не только конкретную переменную, но и все остальные, поскольку они являются частью одной и той же области памяти. Я прав?" Да, дорогой читатель, вы правы. "Значит, мы не можем использовать объединение, объявленное в этом фрагменте, потому что, как только мы присваиваем значение одной из переменных, значение остальных также будет изменено?" Действительно, вы снова правы. Однако я еще не упомянул о ссылках, которые мы будем использовать.
Нас интересует значение, которое будет присвоено одной из переменных. Нас интересует содержимое массива. Именно это важно для нас, чтобы построить нужную нам систему. Если вы хорошо усвоили то, что объяснялось во всех предыдущих статьях, и практиковались, то вы заметили, что мы можем копировать массив внутри другого массива. Таким образом, зная количество элементов, которые мы хотим скопировать, и имея массив, который мы хотим скопировать, мы можем значительно улучшить код между строками 28 и 48. Очень просто: копируем массивы. Для этого мы воспользуемся кодом, который показан ниже.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Код 05
Запустив код 05, мы увидим результат, показанный ниже.
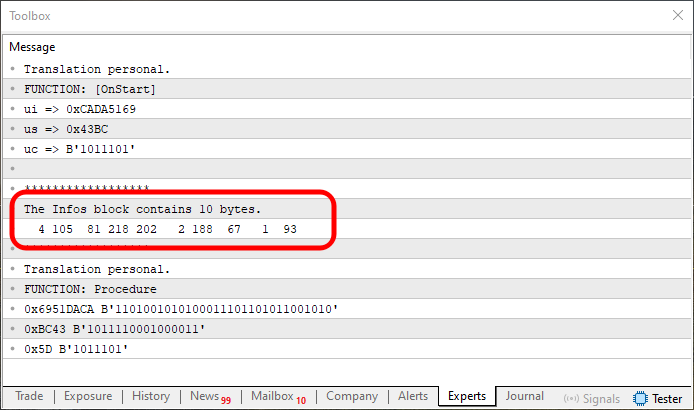
Рисунок 09
Кажется, всё сработало. Но это не совсем то, что произошло. Если посмотреть на область, которую мы отметили на изображении 09, и сравните ее с изображением 08, мы увидим, что значения повернуты или зеркально отражены. Для нас это не проблема, поскольку мы уже показали, как мы можем отражать значения. Но прежде, чем сделать это, хочу показать вам другое решение, которое может оказаться достаточным в зависимости от ситуации.
Обратите внимание, что значения, показанные на изображении 09, также зеркально отражают значения, отображаемые в OnStart и в Procedure. Однако, в зависимости от ситуации - и это важно прояснить - мы можем игнорировать факт зеркального отображения массива и использовать информацию, приведенную ниже.
. . . 62. //+------------------------------------------------------------------+ 63. void Procedure(const uchar &arg[]) 64. { 65. un_Model data; 66. 67. Print("Translation personal.\n" + 68. "FUNCTION: ", __FUNCTION__); 69. 70. for (uchar c = 0; c < arg.Size(); ) 71. { 72. ZeroMemory(data.array); 73. c += (uchar)(ArrayCopy(data.array, arg, 0, c + 1, arg[c]) + 1); 74. Print("0x", ValueToString(data.u32, FORMAT_HEX), " B'", ValueToString(data.u32, FORMAT_BINARY), "'"); 75. } 76. } 77. //+------------------------------------------------------------------+
Фрагмент 04
Если (и пусть это будет предельно ясно) можно использовать фрагмент 04 в коде 05, то конечный результат будет таким:
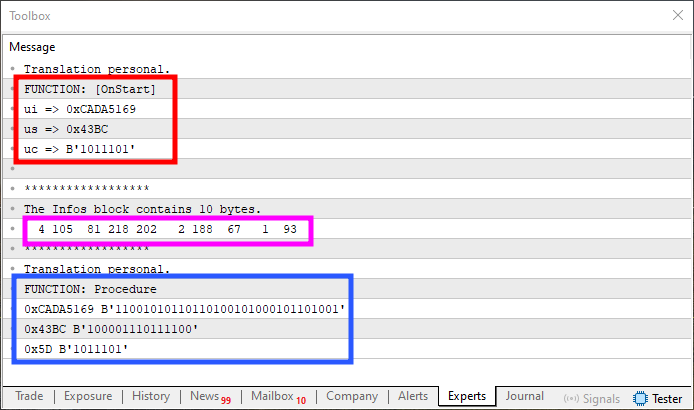
Рисунок 10
А теперь будьте внимательны. Обратите внимание, что в красной области изображения 10 находятся исходные значения. В синей области находятся полученные значения. Как видите, они не отражаются по отношению к исходным значениям, как это было на изображении 09. Однако розовая область, которая в точности представляет содержимое памяти, зеркальна или беспорядочна, как показано на изображении 09. Результат выхода и входа изображения 10 такой же, как и у изображения 08.
Таким образом, если содержимое памяти можно игнорировать, а целью является получение входных и выходных данных с правильными значениями, как показано на изображении 10, можно использовать решение, приведенное во фрагменте 4. Но, в зависимости от случая, данный вид решения не соответствует тому, что мы действительно хотим или можем использовать, поэтому необходимо зеркально отразить данные, чтобы получить конечный результат, показанный на рисунке 8.
Поэтому нам нужно внести небольшое дополнение к коду, чтобы отражать значения перед тем, как поместить их в память для передачи. Это очень просто: нам надо изменить код на тот, который видим ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { 16. const uint ui = 0xCADA5169; 17. ushort us = 0x43BC; 18. uchar uc = B'01011101'; 19. 20. uchar Infos[], 21. counter = 0; 22. 23. PrintFormat("Translation personal.\n" + 24. "FUNCTION: [%s]\n" + 25. "ui => 0x%s\n" + 26. "us => 0x%s\n" + 27. "uc => B'%s'\n", 28. __FUNCTION__, 29. ValueToString(ui, FORMAT_HEX), 30. ValueToString(us, FORMAT_HEX), 31. ValueToString(uc, FORMAT_BINARY) 32. ); 33. 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(uc)); 51. } 52. 53. Print("******************"); 54. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 55. ArrayPrint(Infos); 56. Print("******************"); 57. 58. Procedure(Infos); 59. 60. ArrayFree(Infos); 61. } 62. //+------------------------------------------------------------------+ 63. un_Model Swap(const un_Model &arg) 64. { 65. un_Model info = arg; 66. 67. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 68. { 69. tmp = info.array[i]; 70. info.array[i] = info.array[j]; 71. info.array[j] = tmp; 72. } 73. 74. return info; 75. } 76. //+------------------------------------------------------------------+ 77. void Procedure(const uchar &arg[]) 78. { 79. Print("Translation personal.\n" + 80. "FUNCTION: ", __FUNCTION__); 81. 82. ulong value; 83. 84. for (uchar c = 0; c < arg.Size(); ) 85. { 86. value = 0; 87. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 88. value = (value << 8) | arg[c]; 89. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 90. } 91. } 92. //+------------------------------------------------------------------+
Код 06
Ну что ж, изменения внесены. Но давайте сначала посмотрим на результат, показанный ниже.
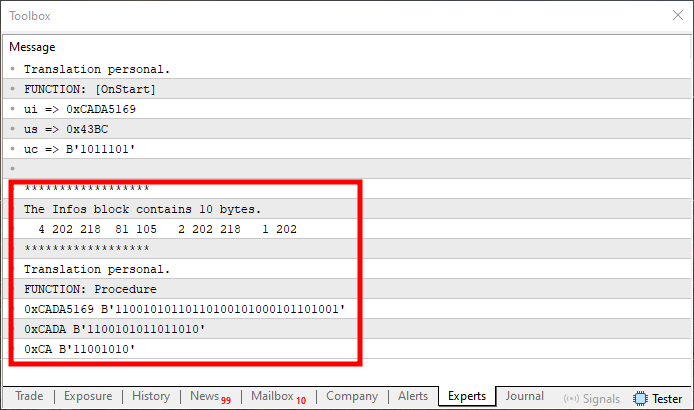
Изображение 11
Это, как правило, "убивает" многих новичков. Это происходит так, потому что правильным является только первое значение, как показано на рисунке 08. Однако остальные неправильные. Почему? Причина кроется именно в вопросе начального значения, которое необходимо правильно задать, что можно найти в строках 45 и 50. Поскольку значение start равно нулю, начальная позиция неверна, и копируется только первый элемент массива, присутствующий в объединении. И, как мы видели в предыдущей теме, массив был повернут таким образом, что первый элемент стал последним.
Чтобы исправить это, нам нужно изменить строки 45 и 50 на следующее:
. . . 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(us), sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(uc), sizeof(uc)); 51. } . . .
Фрагмент 05
Если выполнить код 06 с изменениями, показанными во фрагменте 05, то результат будет таким, как показано на изображении 12, то есть таким же, как ожидалось по изображению 08. Другими словами, он работает идеально. Однако при взгляде на фрагмент 05 вскоре становится ясно, что мы можем поместить его в цикл, потому что в нем есть много повторяющихся частей. Ниже приведен окончательный код, который можно изучить в приложении.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Код 07
Заключительные идеи
В этой статье мы рассмотрели несколько очень интересных моментов с четкой целью понять, как данные размещаются в памяти и как это работает. Хотя то, что здесь было показано, может потребовать от вас продвинуться немного дальше, чем многие готовы пойти, но любой прогресс в понимании того, что здесь показано, принесет вам большую пользу в будущем.
Здесь можно увидеть, что не всё так сложно, как кажется на первый взгляд, и не всё не настолько просто, чтобы можно было всё понять при беглом чтении. Необходимо постоянно практиковаться и учиться. Но, прежде всего, необходимо приложить усилия, чтобы понять концепции, связанные с разработкой любого приложения.
Простое принятие того факта, что тот или иной код, созданный другим программистом, кажется нам более подходящим, нисколько не поможет нам создать что-то подходящее. На первый взгляд он может показаться адекватным, но когда он будет введен в эксплуатацию, то в итоге разочарует нас ошибками и проблемами, которые мы не сможем решить из-за недостатка знаний. Так что развлекайтесь с кодами в приложении и старайтесь практиковаться и изучать то, что вы здесь увидели. А мы с вами увидимся в следующей статье.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15503
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Помощник Connexus (Часть 5): HTTP-методы и коды состояния
Помощник Connexus (Часть 5): HTTP-методы и коды состояния
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования