
From Basic to Intermediate: Union (II)

Introduction
The content presented here is intended solely for educational purposes. Under no circumstances should the application be viewed for any purpose other than to learn and master the concepts presented.
In the previous article From Basic to Intermediate: Union (I), we began discussing what a union is. In fact, this topic has been building up since the very first article, as everything discussed thus far, and everything that will be covered in future articles, is interconnected in some way. What was presented in that previous article represents only the initial part of the broader topic of unions. This subject is quite extensive, much like the topic of arrays, which is closely related.
With that in mind, in this article, we'll explore unions further. We'll also expand our understanding of arrays a bit more. So sit back, get comfortable, and let's dive into the first topic of this article.
Arrays and Unions
Unions are a truly interesting topic in programming, opening the door to more advanced concepts. However, it's important to proceed with caution. One common pitfall is assuming that understanding the basics equates to mastering the concept.
Many people misunderstand unions because they believe that by declaring a union, they've limited to a simple model defined at declaration. In reality, far more is possible when we apply the concepts correctly.
In the previous article, I mentioned that when we create - or more accurately, declare - a union, we are defining a new, specialized data type. Similar, in some ways, to how a string is treated. Yet, some readers may feel uneasy or skeptical when they see certain constructs being used with such a data type.
To show how useful this can be and why someone might choose to do this, we need to understand one small but crucial detail. Since a union is indeed a new and special data type, we can use it in various ways, both in its declaration and in how we manipulate it in a given context. Let's take a look at our first example.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits; 07. uchar u8_bits[4]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info[2]; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. for (uchar c = 0; c < info.Size(); c++) 20. info[c] = Swap(info[c]); 21. View(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg[], ulong value) 25. { 26. arg[0].u32_bits = (uint)(value >> 32); 27. arg[1].u32_bits = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg[]) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg[c].u32_bits); 35. } 36. //+------------------------------------------------------------------+ 37. un_01 Swap(const un_01 &arg) 38. { 39. un_01 info = arg; 40. 41. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = info.u8_bits[i]; 44. info.u8_bits[i] = info.u8_bits[j]; 45. info.u8_bits[j] = tmp; 46. } 47. 48. return info; 49. } 50. //+------------------------------------------------------------------+
Code 01
When we run Code 01, the MetaTrader 5 terminal will display the following output:
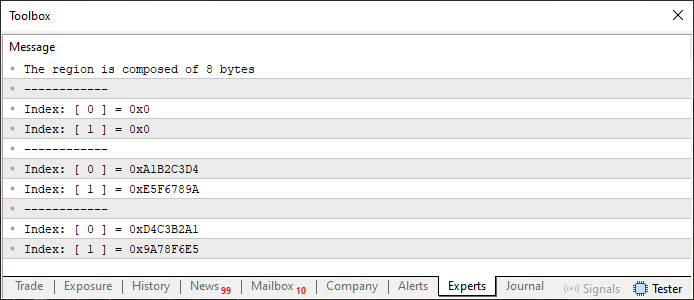
Figure 01
In this Code 01 example, we're applying everything we've covered so far, both in how we work with arrays and how we work with unions. Notice line 12: we're declaring a static array. At first glance, this may seem a bit odd, especially if you've been assuming that only primitive types can be used in arrays. But here, we're using a special type, which we defined back in line 4. Simple as that.
Now, in line 14, the first piece of printed information tells us that the variable 'info' is made up of 8 bytes. At first, this might not make much sense. If that's your reaction, dear reader, I encourage you to revisit the previous article. Because 'info' really is 8 bytes in size - this is due to the largest member in the union, u32_bits, which is of type uint. Essentially, what we're declaring is something very much like the structure shown below.
. . . 12. uint info[2]; . . .
I don't think this will confuse you. However, there is a hidden statement in this same line that a more observant programmer might also notice. This is exactly what we see below:
. . . 12. uchar info[2][4]; . . .
Wow! Wait a second - what are you saying here? Are there two different ways to view the same code? Two ways to write the same thing? Now I'm really confused - this doesn't make sense to me.
And that, dear reader, is exactly why I've been emphasizing the need to study and practice what's shown in each article. One common issue I see, especially among beginners, is an over-reliance on syntax and coding patterns. Many don't actually try to understand the underlying concept; they just focus on the code as written.
As mentioned in the previous article, when we create a union, we're essentially creating a way to break down and share data in smaller segments. You can take a long memory block and divide it into smaller parts to manipulate specific segments of it. That's how we can rotate, shift, or modify certain points without explicitly using specific operators. Not because unions are magical, but because they allow us to interpret the same memory in multiple ways simultaneously.
Although I didn't mention this earlier, both ways of writing line 12 represent the same thing. The difference lies only in how the data is segmented. In the first case, we have an array with two elements, each 4 bytes in size. In the second case, we again have two elements, each still 4 bytes, but structured differently. or many people multidimensional arrays are difficult to understand. But really, a multidimensional array (like the one in the second version of line 12) is just the same array, written in a different form.
Multidimensional arrays are incredibly useful in various contexts, but it they will become easier to understand when we delve into the topic of matrices, which we'll cover in some future article. Until then, there's no need to go into that just yet. Be patient, dear reader, and focus on what we're exploring here and now. In other words, live in the present, don't worry about what comes next.
With this initial explanation provided, and having clarified some potentially confusing points regarding Code 01, we can now move on to something new.
One important note: I won't go into detail about how Code 01 works, as this has already been covered in previous articles. Everything being done there has been shown and explained before. If you're having trouble understanding it, I encourage you to review the earlier material. I want you to understand what's being done so that you can create your own solution - one that produces the exact same result shown in the images. Not a similar result, but an identical one.
With that clarification, let's move on to our next example, presented below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. info = Swap(info); 20. View(info); 21. } 22. //+------------------------------------------------------------------+ 23. void Set(un_01 &arg, ulong value) 24. { 25. arg.u32_bits[0] = (uint)(value >> 32); 26. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 27. } 28. //+------------------------------------------------------------------+ 29. void View(const un_01 &arg) 30. { 31. Print("------------"); 32. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 33. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 34. } 35. //+------------------------------------------------------------------+ 36. un_01 Swap(const un_01 &arg) 37. { 38. un_01 info = arg; 39. 40. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = info.u8_bits[i]; 43. info.u8_bits[i] = info.u8_bits[j]; 44. info.u8_bits[j] = tmp; 45. } 46. 47. return info; 48. } 49. //+------------------------------------------------------------------+
Code 02
Now let's take a look at a code example that, when executed, produces a different result. This is what we observe in Code 02. At first glance, it may seem almost identical to Code 01, doesn't it? However, once executed, it generates a different output:
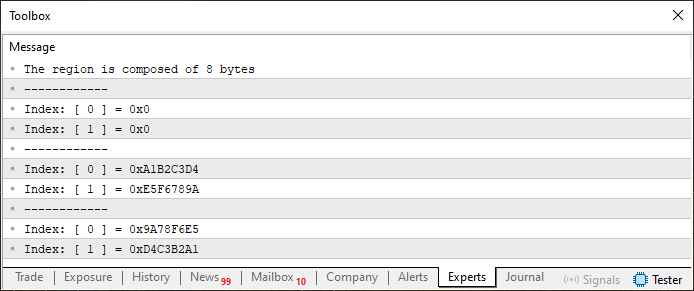
Figure 02
You might be thinking: "But this looks exactly like what was shown in Image 01!" Well, take another look, paying even closer attention to Figure 02 and compare it with Figure 01. Do they still seem identical to you, even after carefully examining each value? Because in reality, they are different. And the reason lies in the way the union is declared. This time, the union contains two arrays, and both are static. But something about that doesn't seem quite logical. In Code 01, the array declared on line 7 had four elements. But now, it has eight. Why? Couldn't we have just kept the same four elements?
To understand this properly, let's break it down. First, we need to consider why the number of elements was changed and what impact this has on the union. Due to a small mathematical detail, and to avoid unnecessarily complicating the code, we're going to change the number of elements in the array declared on line 7 so that it is always EVEN. If it's an odd number, it introduces a minor issue that makes the results harder to interpret. So always use an even number there. Let's suppose that instead of eight elements, we set it to six. Everything else in the code remains unchanged. This results in the following structure:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[6]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragment 01
Here, we’ve only changed the value on line 7. When we run Code 02 with this modification, the output we get is as shown below:
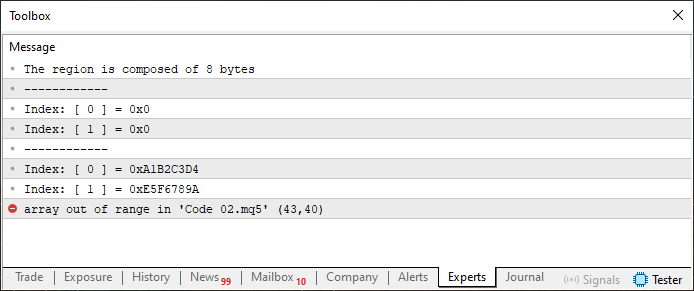
Figure 03
Hmm, that didn't go well. Now let's change the value on line 7 again, this time to ten elements. The updated version looks like this:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[10]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragment 02
When you execute this version, the output is as follows:
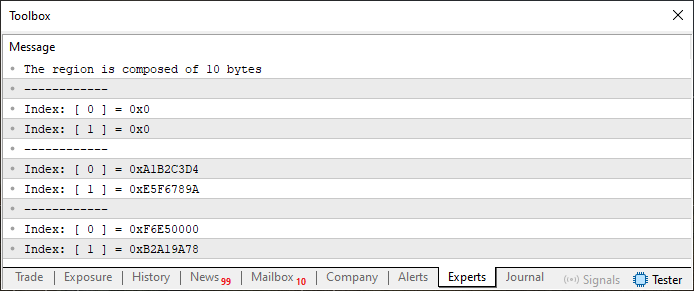
Figure 04
This result also doesn't look very promising. Some of the values seem to have disappeared. At this point, you might be wondering: Why did this happen? Well, that's exactly why we're here - to help you understand something that may not make much sense at first glance. But as you gain experience and keep practicing, it'll become easier to see how and why things behave the way they do. The key, always, is to focus on understanding the concept being applied.
Let's go back to the first modified case, the one that resulted Figure 03 and threw an error indicating that the code attempted to access memory out of bounds. This error happened because the 'info' variable is made up of eight bytes. Now pay close attention: within the union, the u8_bits array contains six elements, or six bytes, since each element is of type uchar, which is one byte wide. So, when the variable j (which at that point is referencing the eighth element of u8_bits) is used, the program tries to access memory that doesn't belong to the array. That’s why the code fails at line 43. But this failure isn't due to using more or fewer elements in u8_bits. Before we go into how to properly adjust the code to allow for six elements in u8_bits, let's first understand what's happening in the second case - the one corresponding to Image 04.
In this second scenario, you can see that info contains ten bytes, or ten elements. That's because u8_bits was declared with ten elements as well. So when the Swap function is executed (as seen on line 36), part of the values are overwritten by zeros, which were initialized by the procedure on line 15. In other words, ZeroMemory clears the entire memory block associated with the 'info' variable.
That's why some values appear to have "disappeared". But in reality, they've simply been moved or replaced elsewhere in memory. To demonstrate this, we'll make a small change to the code. And to avoid running into the same issues we saw in Images 03 and 04, the new version of the code is shown below:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. Set(info, 0xA1B2C3D4E5F6789A); 17. View(info); 18. Debug(info); 19. info = Swap(info); 20. View(info); 21. Debug(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg, ulong value) 25. { 26. arg.u32_bits[0] = (uint)(value >> 32); 27. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 35. } 36. //+------------------------------------------------------------------+ 37. void Debug(const un_01 &arg) 38. { 39. string sz = ""; 40. 41. Print("*************"); 42. for(uchar c = 0; c < (uchar)arg.u8_bits.Size(); c++) 43. sz = StringFormat("%s0x%X ", sz, arg.u8_bits[c]); 44. PrintFormat("Number of elements in %cinfo.u8_bits.Size()%c is %d\nInternal content is [ %s ]", 34, 34, arg.u8_bits.Size(), sz); 45. Print("*************"); 46. } 47. //+------------------------------------------------------------------+ 48. un_01 Swap(const un_01 &arg) 49. { 50. un_01 info = arg; 51. 52. for (uchar i = 0, j = (uchar)(info.u8_bits.Size() - 1), tmp; i < j; i++, j--) 53. { 54. tmp = info.u8_bits[i]; 55. info.u8_bits[i] = info.u8_bits[j]; 56. info.u8_bits[j] = tmp; 57. } 58. 59. return info; 60. } 61. //+------------------------------------------------------------------+
Code 03
When we run this code, we will see something similar to the image below.
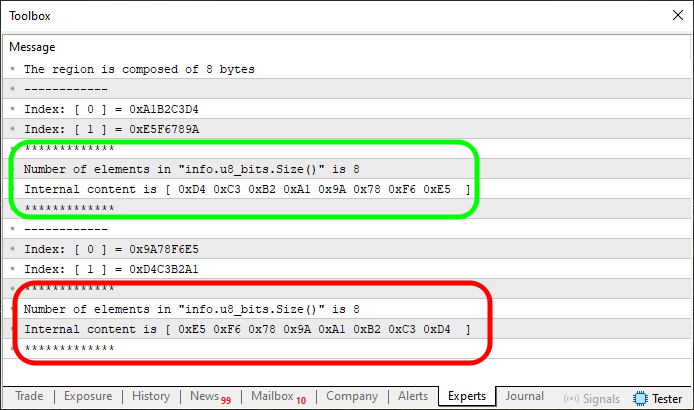
Figure 05
This is where things start to become much easier to understand. Two specific regions are highlighted in Figure 05. Keep in mind, this Code 03 is a modified version of Code 02, and once again, line 7 is what we're interested in. In order to standardize and properly understand what's going on, we've reused the same value for the array on line 7 in Code 03 that was used previously in Code 02. This gives us the output shown in Figure 05.
Now, pay close attention, dear reader. This is crucial if you want to reproduce these results on your own machine. On line 52 of Code 03, I made a change to prevent the same error seen earlier in Figure 03. That modification now allows us to do what we previously attempted.
First, let's apply Fragment 01 to Code 03. When we do this, the result we get is what you can see below:
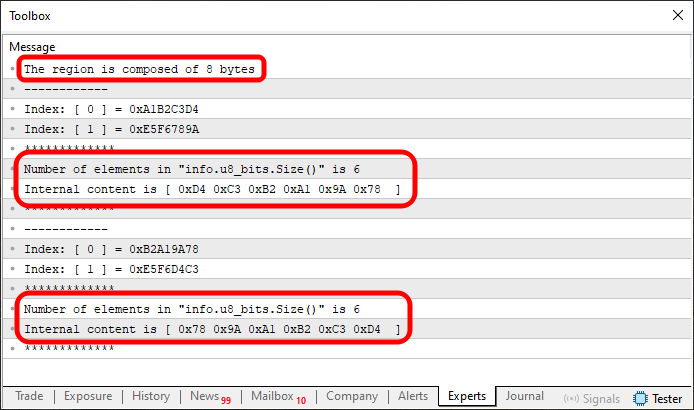
Figure 06
Once again, I've marked important points of interest, because it's essential that you understand what's happening under the hood. Even though we're working with a smaller number of elements in u8_bits, the operation still occurs. However, look at the content at index one. You’ll notice part of the data remains unchanged. Why? Before we answer that, let's apply Fragment 02 to Code 03.
Upon doing that, we get the result shown in the image below:
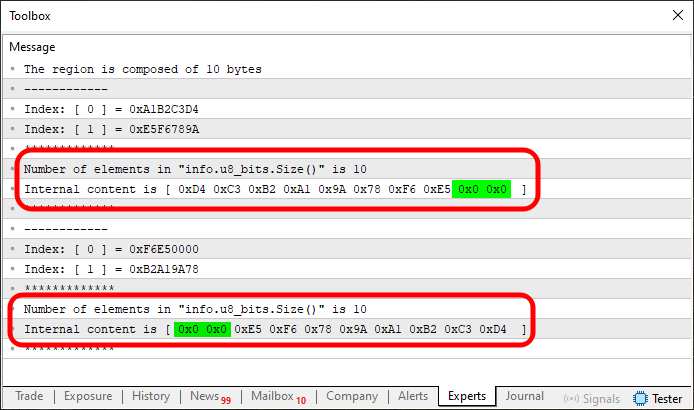
Figure 07
Yes, it's clear now that things are not as simple as they seemed at first. But don't worry, dear reader. Everything here is actually simple and practical. You just need to take the time to focus and practice. You can't just read through the article and expect to master it. You need hands-on practice. In both Figure 06 and Figure 07, you can observe that the memory is being rotated or mirrored, just as expected. However, the values shown in the array indices, when directly accessing the u32_bits elements, might not be what you initially anticipated. That's because we're dealing with different memory compositions.
When the array you've declared fully covers the memory region, you get a perfect representation. That's why Figure 05 appears exactly as expected. But if you underfill or overfill that memory block, leaving parts uncovered or adding more than needed, the result becomes distorted and scattered. This is what you see in Figures 06 and 07. One underfills the region, and the other overfills it.
Now do you understand why it was so important to modify the number of elements on line 7? If you don't handle that correctly, you end up with incorrect memory coverage in certain situations. That's why it's essential to experiment and try different ways of doing things. The attached files aren't just decorative elements for the article, they're there for you to use and learn from. Test them, tweak them, and observe what changes. Only then will you start developing a solid understanding of each programming element covered in these articles. That's how you move from being a "copy-paste" coder to becoming a truly excellent programmer.
We've laid a solid foundation on how to study and interpret the materials presented here. I believe you;re ready to tackle a problem that was presented earlier in the article From Basic to Intermediate: Arrays (IV). In fact, we're going to take that code and make it even better. To explain how, we're moving into a new topic.
Making Something Good Even Better
What we’re about to do here is both fun and practical. However, to fully understand what follows, you must have mastered the content of the previous section. If not, you might find yourself confused and lost. So don't rush. Take your time to carefully study everything shown so far and only then should you move on to this next challenge using MQL5.
Now that the warning is out of the way, let's get into the heart of this topic. To begin, we'll revisit a piece of code that was shared in the earlier article I just mentioned. This example is shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Code 04
When executed, this Code 04 produces the result shown below:
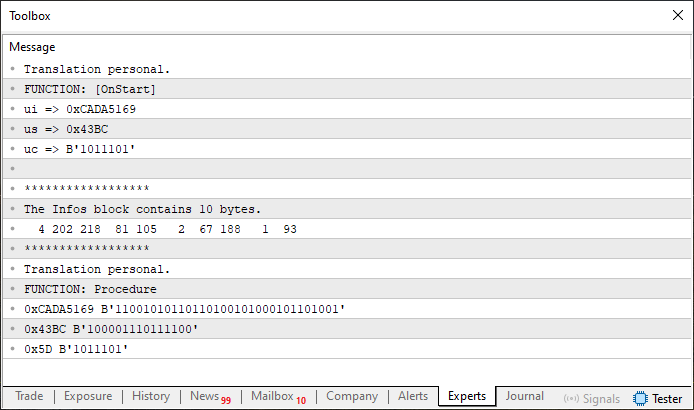
Figure 08
Here's the challenge: your task is to turn Code 04 into something easier and more elegant to implement using what you've learned up to this point. You might be thinking: "How am I, someone who's just learning to code, supposed to take what I've learned and actually improve this code? That's insane!" But those who don't challenge themselves or step out of their comfort zones quickly fall behind.
New techniques and better concepts emerge all the time, making our work easier, our code more efficient, and separating real programmers from those who only copy and paste. Because at every step we see new ways to achieve the same result, but in a simpler way. So let's dive into how we can apply the concepts from earlier to improve Code 04. To do this, we first need to analyze what the current code is actually doing.
Essentially, you'll see a few variables being declared and used in a specific sequence. The variable with the largest memory width is of type uint, declared on line 8 and used between lines 28 and 35. The other data types used are smaller. Knowing this, we can start thinking of a solution where the array 'Info', declared on line 12, receives the information in such a way that it produces the same internal memory structure. But what is this memory structure, exactly? How can we know if our new implementation is correct?
Look at Figure 08 - at a certain point the exact contents of the 'Info' array are displayed. So all we need to do is replicate the same result, but in a way that makes the code more pleasant to use.
Great. That's the goal. And as demonstrated throughout this and the previous article, we can use unions to better organize the data. So how exactly do we do that? First, dear reader, you'll need to create a properly declared union to hold the values. Since we'll be using uint, ushort, and uchar values (based on the operations between lines 28 and 48), you might think you need three different unions. But in fact, you'll only need one. Here's how it looks in the following code fragment:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { . . .
Fragment 03
Very well. Take a look at Fragment 03. On line six, we're creating a union, and in the lines that follow, we're declaring discrete types to be used later on. At first glance, this might seem a bit confusing. However, the part we truly care about is line eleven. That's where we enable access to the entire memory region encompassed by the union data types. Notice how I declare a static array with a number of elements equal to the size of the largest discrete type within the union. This is a good approach when you're unsure how many bytes are required within a union.
Now you might be thinking: "Wait a minute. If I understand correctly, when we modify a value (or better said, a variable0 in a union, we're not just changing one specific variable. We're also affecting all others, since they share the same memory space. Is that right?" Yes, dear reader, you're absolutely right. And so you might then conclude: "We can't use the union declared in this fragment. Because as soon as we assign a value to one of its variables, the others will also be affected." And once again, you'd be correct to think so. However, I haven't yet explained what we'll take advantage of here.
We're not really interested in the specific value assigned to a particular variable. What we care about is contained in the array. That's what matters for constructing the system. If you've thoroughly understood the material presented across the previous articles (and more importantly, if you've practiced) you should have realized that we can copy one array into another. Knowing how many elements we want to copy and which array we're copying from, we can significantly improve the block of code running from lines 28 through 48. It's very simple: we copy arrays. To do this, we will use the code shown below.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Code 05
When we run code 05, we will see the following result.
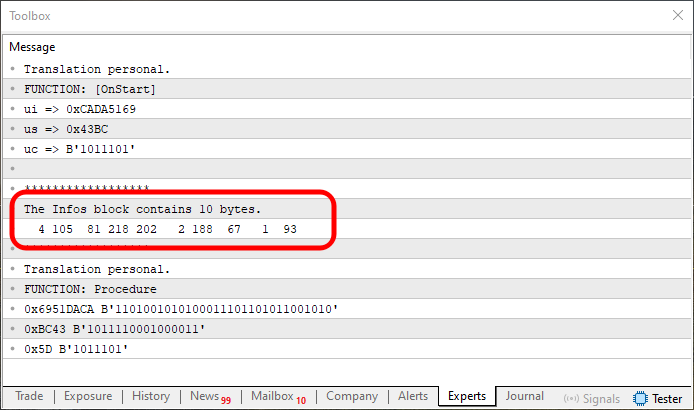
Figure 09
It seems to have worked. But that’s not exactly what happened here. If you closely examine the highlighted region in Figure 09 and compare it to Figure 08, you'll notice the values appear rotated or mirrored. That, however, isn't a problem for us, since I've already shown how to reverse or mirror values. But before we go down that path, I want to show you another possible solution, which, depending on the case, might be sufficient.
Notice that the values shown in Image 09 are mirrored not only in the memory, but also between the output displayed in OnStart and that seen in Procedure. However, depending on the specific context - and this is important to emphasize - we might be able to ignore the fact that the array is mirrored and instead apply the approach shown below.
. . . 62. //+------------------------------------------------------------------+ 63. void Procedure(const uchar &arg[]) 64. { 65. un_Model data; 66. 67. Print("Translation personal.\n" + 68. "FUNCTION: ", __FUNCTION__); 69. 70. for (uchar c = 0; c < arg.Size(); ) 71. { 72. ZeroMemory(data.array); 73. c += (uchar)(ArrayCopy(data.array, arg, 0, c + 1, arg[c]) + 1); 74. Print("0x", ValueToString(data.u32, FORMAT_HEX), " B'", ValueToString(data.u32, FORMAT_BINARY), "'"); 75. } 76. } 77. //+------------------------------------------------------------------+
Fragment 04
If (and let me stress this clearly) it's acceptable to use Fragment 04 within Code 05, then the resulting output will appear as shown below:
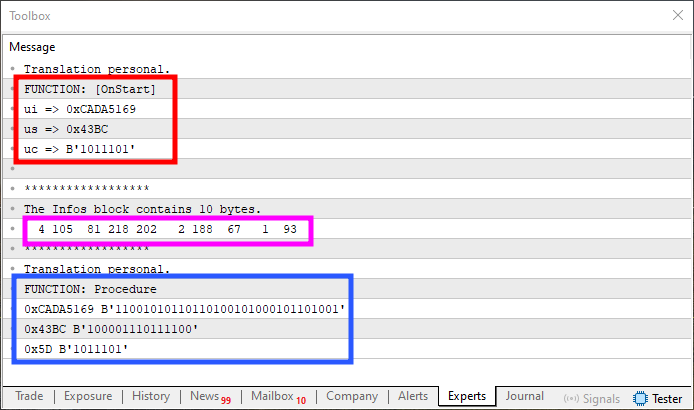
Figure 10
Now pay very close attention, dear reader. In the red-highlighted region of Figure 10, we have the original values. In the blue region, we see the output values. Notice that, unlike what we saw in Figure 09, these values are not mirrored but match the originals. However, the pink-highlighted region, which represents the exact content in memory, is still mirrored or disordered—just like it appeared in Figure 09. That said, the input and output values in Figure 10 are identical to those shown in Figure 08.
So, if the actual memory content can be ignored, and the goal is simply to obtain correct input and output values (as shown in Figure 10), then the solution presented in Fragment 04 could indeed be valid. But, depending on the situation, this kind of solution might not be appropriate for what we really want or are allowed to use. In such cases, it becomes necessary to mirror the data explicitly so that the final result matches exactly what's shown in Figure 08.
To achieve this, we'll need to make a small adjustment to the code, specifically to mirror the values before placing them into the memory that will be transferred. This is quite simple . Just replace the previous code the below one.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { 16. const uint ui = 0xCADA5169; 17. ushort us = 0x43BC; 18. uchar uc = B'01011101'; 19. 20. uchar Infos[], 21. counter = 0; 22. 23. PrintFormat("Translation personal.\n" + 24. "FUNCTION: [%s]\n" + 25. "ui => 0x%s\n" + 26. "us => 0x%s\n" + 27. "uc => B'%s'\n", 28. __FUNCTION__, 29. ValueToString(ui, FORMAT_HEX), 30. ValueToString(us, FORMAT_HEX), 31. ValueToString(uc, FORMAT_BINARY) 32. ); 33. 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(uc)); 51. } 52. 53. Print("******************"); 54. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 55. ArrayPrint(Infos); 56. Print("******************"); 57. 58. Procedure(Infos); 59. 60. ArrayFree(Infos); 61. } 62. //+------------------------------------------------------------------+ 63. un_Model Swap(const un_Model &arg) 64. { 65. un_Model info = arg; 66. 67. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 68. { 69. tmp = info.array[i]; 70. info.array[i] = info.array[j]; 71. info.array[j] = tmp; 72. } 73. 74. return info; 75. } 76. //+------------------------------------------------------------------+ 77. void Procedure(const uchar &arg[]) 78. { 79. Print("Translation personal.\n" + 80. "FUNCTION: ", __FUNCTION__); 81. 82. ulong value; 83. 84. for (uchar c = 0; c < arg.Size(); ) 85. { 86. value = 0; 87. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 88. value = (value << 8) | arg[c]; 89. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 90. } 91. } 92. //+------------------------------------------------------------------+
Code 06
Alright, we've made the change. But even though the adjustment was implemented, take a look at the result.
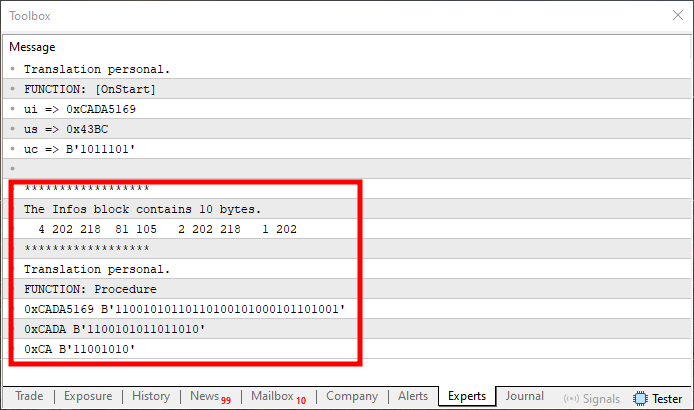
Figure 11
This is the kind of issue that often discourages beginners. That's because only the first value is correct, matching what we saw in Figure 08. The remaining values are wrong. Why? The problem lies in how the start value is being handled - it needs to be set correctly. This occurs in lines 45 and 50. Since the 'start' value is currently set to zero, we end up with the wrong starting position. The copy operation affects only the first element in the array inside the union. And as you saw in the previous topic, that array was reversed. So what is now the first element was originally the last.
To fix this, we need to modify lines 45 and 50 as shown below:
. . . 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(us), sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(uc), sizeof(uc)); 51. } . . .
Fragment 05
When you run Code 06, incorporating the changes shown in Fragment 05, the output will be as in Figure Image 12 - precisely what we expected based on Figure 08. In other words, it works perfectly. However, upon reviewing Fragment 05, you'll quickly realize that we could easily wrap this into a loop, since there are quite a few repeated sections. So, here's the final code which can be found in the appendix.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Code 07
Final Thoughts
In this article, we've explored several fascinating topics with the clear objective of understanding how data is placed in memory and how it works. While what has been covered here may require you to go a little further than many are willing to go, any progress in understanding what has been shown here will benefit you greatly in the future.
Here you can see that not everything is as complicated as it seems at first glance, and not everything is so simple that you can understand everything with a quick read. It is crucial to constantly practice and learn. But first of all, you need to make an effort to understand the concepts involved in developing any application.
Simply accepting the fact that some code written by another programmer seems more suitable to us will not help us create something suitable. It might seem suitable at the time, but when put to use, it could end up disappointing you due to unexpected issues that you won't be able to fix without the right knowledge. So explore the codes in the attachment and try to practice and learn what you see here. I'll see you in the next article.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15503
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use