
Von der Grundstufe bis zur Mittelstufe: Template und Typenname (III)

Einführung
Die hier zur Verfügung gestellten Materialien sind ausschließlich für Bildungszwecke bestimmt. Sie sollte in keiner Weise als endgültige Bewerbung angesehen werden. Es geht nicht darum, die vorgestellten Konzepte zu erforschen.
Im vorherigen Artikel: „Von der Grundstufe zur Mittelstufe: Template und Typenname (II)“, haben wir erklärt, wie man mit einigen spezifischen Alltagssituationen für Programmierer umgeht. Ob es sich um ein vorübergehendes Hobby handelt oder ob Sie ein professioneller Programmierer sind, die Verwendung von Templates für Funktionen oder Prozeduren kann in bestimmten Situationen sehr nützlich sein. Obwohl dies in MQL5 nicht sehr häufig vorkommt und nicht immer anwendbar ist, ist es nützlich zu wissen, dass ein solches Konzept für die Anwendung zur Verfügung steht und dass es seine eigenen Punkte hat, die man richtig verstehen sollte, um nicht durcheinander zu kommen, wenn man versucht, den Code zu ändern, der schließlich eine solche Simulation verwendet.
Templates gelten nicht nur für Funktionen und Prozeduren. In der Tat haben sie eine breite Palette von praktischen Anwendungen, die mehr oder weniger von der Art der Anwendung abhängen, die Sie entwickeln wollen. Es ist erwähnenswert - und ich betone dies noch einmal -, dass wir die gleiche Art von Anwendung auch ohne die Verwendung von Templates implementieren können. Die Verwendung eines solchen Werkzeugs und der Ressourcen von MQL5 macht die Umsetzungsphase jedoch einfacher und angenehmer. Außerdem lassen sich so einige komplexe und lästige Erkennungsfehler vermeiden.
Muster in lokalen Variablen
In den beiden vorangegangenen Artikeln, in denen wir nur über Templates in Funktionen oder Prozeduren gesprochen haben, war alles recht einfach und sogar interessant. Dank der Erläuterungen wurde jedoch klar, dass Templates für Funktionen oder Prozeduren eine gute Möglichkeit sind, die Arbeit an den Compiler zu delegieren, sofern eine Überlastung der Funktion oder Prozedur auftritt. Die angeführten Beispiele waren jedoch sehr einfach, da die Art der verwendeten Daten nur im Zusammenhang mit den Eingabeparametern der Funktion oder Prozedur angegeben wurde. Allerdings kann man sich auf ein etwas höheres Niveau des Wissens begeben.
Um dies zu verstehen, wollen wir mit einem einfachen Beispiel beginnen: der Berechnung von Durchschnittswerten. Ja, auch wenn es eine einfache Sache ist, können wir sehen, wie man Templates in einer ähnlichen Situation anwenden kann. Ich möchte Sie jedoch daran erinnern, dass die hier zur Verfügung gestellten Codes ausschließlich für Bildungszwecke bestimmt sind. Sie stellen nicht unbedingt einen Code dar, der in der realen Welt verwendet wird.
Da ich davon ausgehe, dass Sie bereits verstanden haben, wie das Überladen einer Funktion oder Prozedur funktioniert, können wir uns nur auf die Teile konzentrieren, die wirklich Aufmerksamkeit verdienen, indem wir alles Unnötige aus dem Code entfernen. Daraus ergibt sich der unten dargestellte Code aus erster Hand.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. double Averange(const double &arg[]) 16. { 17. double local = 0; 18. 19. for (uint c = 0; c < arg.Size(); c++) 20. local += arg[c]; 21. 22. return local / arg.Size(); 23. } 24. //+------------------------------------------------------------------+ 25. long Averange(const long &arg[]) 26. { 27. long local = 0; 28. 29. for (uint c = 0; c < arg.Size(); c++) 30. local += arg[c]; 31. 32. return local / arg.Size(); 33. } 34. //+------------------------------------------------------------------+
Code 01
Wir haben einen einfachen Code vor uns, dessen Zweck es ist, den Durchschnittswert eines Datensatzes zu berechnen. Für diejenigen, die es nicht verstehen: Die Durchschnittsberechnung besteht darin, alle Werte zu addieren und dann das Ergebnis einer bestimmten Summe durch die Anzahl der in der Berechnung vorhandenen Elemente zu teilen. Obwohl diese Art der Berechnung einfach ist, gibt es ein kleines Problem: Die Werte können sowohl positiv als auch negativ sein. Wir erhalten möglicherweise einen verzerrten Mittelwert, der nicht das widerspiegelt, was wir wirklich wissen wollen. Aber das ist eine unbedeutende Sache, die hier nicht wichtig ist. Wir haben dies nur erwähnt, damit Sie wissen, dass der Code uns nicht immer die Informationen liefert, die wir brauchen, selbst wenn er von jemand anderem erstellt wurde. Außerdem führt die Tatsache, dass ein anderer Programmierer einen bestimmten Code erstellt hat, dazu, dass der Code auf das reagiert, was dieser Programmierer gesucht hat, und nicht auf das, was wir vielleicht suchen.
Ich glaube jedoch nicht, dass es notwendig ist, zu erklären, wie der Code 01 abläuft, da er die Überladung nutzt, um die Faktorisierung auf die am besten geeignete Weise auszuführen. Das Ergebnis dieses Vorgangs ist in der folgenden Abbildung zu sehen.
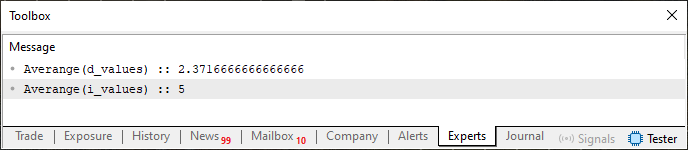
Abbildung 01
Mit anderen Worten, es handelt sich um etwas Triviales und Einfaches. Aber ich möchte, dass Sie sich die in den Zeilen 15 und 25 implementierte Funktion genau ansehen. Was haben sie gemeinsam? Wir können sagen, dass sie fast identisch sind, bis auf ein bestimmtes Detail. Dieser Teil bezieht sich auf die Art der verwendeten Daten. Ansonsten sind sie identisch und weisen keine offensichtlichen Unterschiede auf. Und in der Tat, wenn Sie dies bemerkt haben, bedeutet es, dass Sie an etwas denken: Wir können diese beiden in Code 01 gezeigten Funktionen in ein Template umwandeln. Dadurch wird die Aufgabe vereinfacht. „Ich habe jedoch Zweifel daran. Beide Funktionen haben eine lokale Variable, die in den Zeilen 17 und 27 zu sehen ist. Ich weiß, wie man einen Funktionsaufruf als Template deklariert und implementiert, weil ich das schon in früheren Artikeln gesehen habe. Allerdings stört mich diese lokale Variable, und ich weiß nicht, wie ich damit umgehen soll. Vielleicht kann ich etwas Ähnliches wie den unten stehenden Code machen.“
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. double local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return (T)(local / arg.Size()); 24. } 25. //+------------------------------------------------------------------+
Code 02
In der Tat können Sie das tun, was in Code 02 gezeigt wird. Wenn Sie jedoch versuchen, diesen Code zu kompilieren, erhalten Sie diese Warnung des Compilers:
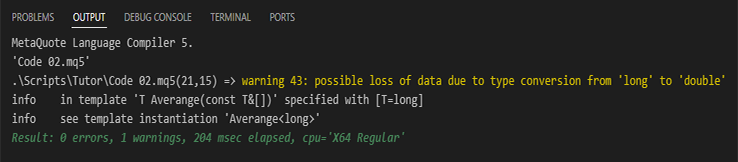
Abbildung 02
Bitte beachten Sie, dass es sich hierbei nicht um eine Fehlermeldung, sondern um eine Warnung handelt. Dies geschieht, weil in Zeile 21, wo wir die Array-Werte summieren, ein Moment eintritt, in dem wir einen Gleitkommawert mit einem Ganzzahlwert summieren. Dies kann zu einer Verfälschung des Endergebnisses führen. Das Endergebnis, wenn wir den Code (02) ausführen, ist jedoch das gleiche wie in Abbildung 01. Diese Compiler-Warnung könnte jedoch für einige Programmierer etwas beunruhigend sein. Wie kann ich dieses Problem beheben? Um das Problem zu lösen, müssen wir eine Typkonvertierung durchführen, genau wie in Zeile 23, nur dass die Konvertierung hier in Zeile 21 durchgeführt wird. Aber Vorsicht: Sie sollten nicht das verwenden, was unten gezeigt wird.
local += (T)arg[c];
Dies wird das Problem mit der Warnung nicht lösen, da wir die Konvertierung durchführen müssen, damit der Wert im Array mit dem Variablenwert in Zeile 18 kompatibel ist. Auch wenn es kompliziert erscheinen mag, ist es in Wirklichkeit sehr einfach und überschaubar. Alles, was wir tun müssen, ist, die Zeile 21 von Code 02 in die Zeile zu ändern, die Sie gerade unten sehen.
local += (double)arg[c]; Jetzt haben wir unser Problem gelöst. Wir haben eine Durchschnittsfunktion als Template implementiert, und sie funktioniert hervorragend. Es gibt jedoch eine andere Möglichkeit, diese Probleme zu beheben, ohne den Code so stark zu verändern. Kehren wir zu Code 01 zurück. Bitte beachten Sie, dass Code 02 dem entspricht, was in Code 01 implementiert ist. Wenn die Probleme auf eine lokale Variable zurückzuführen sind, wie oben gezeigt, warum dann nicht etwas Komplizierteres tun? Der Compiler kümmert sich also von selbst um solche Probleme. Das klingt gewagt, nicht wahr?
Aber wenn Sie wirklich verstanden hätten, wie Code 01 in Code 02 umgewandelt wurde und wie wir mit der vom Compiler ausgegebenen Warnung umgegangen sind, hätten Sie eine andere Lösung finden müssen. Eine dieser Lösungen, die es Ihnen ermöglicht, den Typ der in Zeile 18 von Code 02 deklarierten Variablen zu ändern. Das wäre eine wirklich interessante Lösung, und das ist genau das, was wir im Umsetzungsprozess sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " :: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const double d_values[] = {2.5, 3.4, 1.25, 2.48, .85, 3.75}; 09. const long i_values[] = {8, 3, 4, 6, 4, 5, 7}; 10. 11. PrintX(Averange(d_values)); 12. PrintX(Averange(i_values)); 13. } 14. //+------------------------------------------------------------------+ 15. template <typename T> 16. T Averange(const T &arg[]) 17. { 18. T local = 0; 19. 20. for (uint c = 0; c < arg.Size(); c++) 21. local += arg[c]; 22. 23. return local / arg.Size(); 24. } 25. //+------------------------------------------------------------------+
Code 03
Code 03 ergibt das gleiche Ergebnis wie in Bild 01 und gibt keine Warnungen des Compilers aus. Warum ist das so? Wenn der Compiler merkt, dass wir einen Integer-Typ wollen, passt er den Typ der Variablen an den Integer-Typ an. Wenn der Compiler feststellt, dass wir einen Fließkommatyp benötigen, wird er die in Zeile 18 deklarierte Variable in den entsprechenden Typ für die Verwendung mit Fließkomma umwandeln.
Auf diese Weise erhalten wir einen viel einfacheren Code als Code 01, und obwohl er dem Code 02 sehr ähnlich ist, müssen wir nicht alle verschiedenen Anpassungen vornehmen. Dadurch wird sichergestellt, dass eine Typkonvertierung stattfindet und keine Compilerwarnungen ausgegeben werden. Es ist großartig, nicht wahr? Wenn Sie einen ähnlichen Code schon einmal gesehen haben, können Sie sich wahrscheinlich vorstellen, wie er funktioniert. Aber wenn man die grundlegenden Konzepte versteht und sieht, wie alles zusammenpasst, dann werden die Codes, die vorher kompliziert erschienen, einfacher und interessanter.
Okay, das war der angenehmste Teil. Und jetzt werden wir einen wirklich interessanten Teil sehen. Angesichts der in Code 03 vorgestellten Anwendungsfälle möchte ich nun mit anderen Datentypen experimentieren.
Da wir bisher nur den von „union“ verwendeten Datentyp gezeigt haben, können wir versuchen, mit derselben Technik wie in Code 03 eine noch größeres Template zu erstellen. Um die Aufgaben richtig aufzuteilen, werden wir dies jedoch in einem anderen Thema diskutieren.
Verwendung von Elementen in Unions
Betrachten wir zunächst das, was in Code 03 gezeigt wird, in einer etwas einfacheren Form, zumindest am Anfang. Eigentlich werden wir den Code 03 nicht mehr ändern, aber wir werden dieses Konzept nutzen, um einen dynamischen Speicherbereich innerhalb der Union zu schaffen. Mit anderen Worten, wir werden ein Template für die Erstellung einer Union zwischen einem Array und einem beliebigen Datentyp erstellen.
Als wir untersucht haben, wie eine Union definiert ist, haben wir gesehen, dass sie aus einem Block fester Größe besteht. Dieser Block, der in Bytes definiert ist, hat den Wert der Anzahl von Bytes, die zum größten Typ in der Union gehören. Wir können dafür sorgen, dass dies nicht die absolute Wahrheit ist, d.h. wir können diese Union dynamisch durch den Compiler konfigurieren, was es uns ermöglicht, eine Union zu erstellen, die im Prinzip eine dynamische Blockgröße hat, da die Breite in Bytes zum Zeitpunkt der Kompilierung unseres Codes bestimmt wird. Von diesem Zeitpunkt an hat sie eine feste Größe.
Jetzt denken Sie vielleicht: „Das scheint mir eine sehr schwierige Aufgabe zu sein. Auf den ersten Blick weiß ich nicht, wie ich dem Compiler sagen sollen, wie er mit diesem Ansatz oder dieser Implementierung arbeiten soll. Brauchen wir das jetzt?“ Nun, in gewisser Weise mögen einige dieses Konzept als fortgeschritten betrachten, aber meiner Meinung nach ist es immer noch ein grundlegendes Konzept, das jeder Anfänger kennen sollte, da es die Erstellung verschiedener Arten von Code für breitere Zwecke erheblich erleichtert.
Ich weiß, dass viele Leute denken, dass wir zu schnell vorankommen. Wir gehen jedoch so langsam wie möglich vor, ohne ein einziges Konzept oder eine Erklärung auszulassen. Wenn diese Wissensbasis gut ausgebildet ist und wahrgenommen wird, wird alles, was folgt, viel natürlicher und leichter zu verstehen sein. Da ich aber weiß, dass zukünftige Materialien anfangs etwas verwirrend sein können, werden wir mit einem einfacheren Code beginnen. Dadurch wird das Lernen neuer Konzepte angenehmer und einfacher. Beginnen wir mit dem unten stehenden Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ulong info = 0xA1B2C3D4E5F6789A; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. ulong Swap(ulong arg) 13. { 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }info; 19. 20. info.value = arg; 21. 22. PrintFormat("The region is composed of %d bytes", sizeof(info)); 23. 24. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 25. { 26. tmp = info.u8_bits[i]; 27. info.u8_bits[i] = info.u8_bits[j]; 28. info.u8_bits[j] = tmp; 29. } 30. 31. return info.value; 32. } 33. //+------------------------------------------------------------------+
Code 04
In diesem Code wird die Template-Ressource noch nicht verwendet. Da dies bereits in einem anderen Artikel erklärt wurde, als wir das Thema Union eingeführt haben, sehe ich keine Notwendigkeit, die Funktionsweise erneut zu erklären. Bei der Einführung von Code 04 waren wir jedoch nicht daran interessiert, ihn zu erweitern. Die Funktion aus Zeile 12 existierte also gar nicht. Alles wurde im Rahmen von OnStart durchgeführt. Da wir nun aber über Templates in Unions sprechen werden, ist es angebracht, alles in einem separaten Block zu behandeln. Dies wird den ersten Kontakt mit den Templates zu Unions erleichtern. Dann werden wir sehen, dass es möglich ist, alles in ein einziges Code-Stück zu packen, wie es anfangs gemacht wurde.
Sobald Sie den Code 04 kompiliert und ausgeführt haben, sehen Sie die Antwort im MetaTrader 5 Terminal.
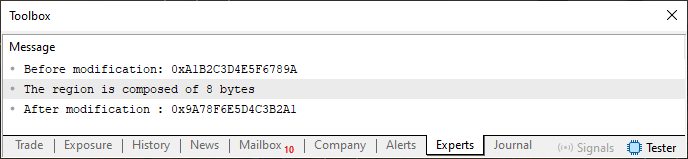
Abbildung 03
Mit anderen Worten: Wir verschieben die Bits. Alles ist einfach. Wie kann man Bits anderer Datentypen ändern? Denn wenn wir einen Typ wie ushort haben, der 2 Bytes hat, und wir diesen Typ an die Funktion in Zeile 12 senden, erhalten wir ein falsches Ergebnis oder zumindest etwas ziemlich Seltsames. Um dies zu überprüfen, ändern Sie einfach die Zeile 06 von Code 04 in die unten gezeigte Zeile.
const ushort info = 0xCADA;
Wenn wir nun den Code 04 mit der oben gezeigten Zeile ausführen, wird das Ergebnis das sein, was wir auf dem Bildschirm des MetaTrader 5 Terminals sehen.
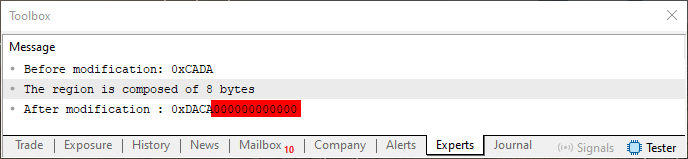
Abbildung 04
Bitte beachten Sie eine Sache in Bild 04: den Bereich, den ich rot markiert habe. Dies sind unnötige Daten, die dem Wert vom Typ ushort hinzugefügt werden. Selbst wenn Sie feststellen, dass die Drehung tatsächlich stattgefunden hat, stellen diese Bytes ein Problem dar. Vor allem, wenn wir den Typ ushort speichern müssen. In diesem Fall kommt das Template zur Hilfe.
Wie bereits im vorangegangenen Thema gezeigt, ist die Arbeit mit Werten verschiedener Art sehr einfach, praktisch und sicher. Auf diese Weise lässt sich der Mittelwert berechnen. Tatsächlich kann unsere Anwendung sowohl mit Ganzzahl- als auch mit Fließkommawerten problemlos arbeiten. Aber wie machen wir das Gleiche hier, wo wir eine Union verwenden und brauchen, um den Code zu vereinfachen? Nun, das ist der interessanteste Teil.
Zunächst müssen wir den Code 04 in einen template-freundlichen Code umwandeln. Nach dem zu urteilen, was bisher gezeigt wurde, ist es sehr einfach, dies zu tun, vor allem, wenn man die skizzierten Konzepte wirklich versteht. Dann erstellen wir ohne Probleme den unten stehenden Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. ulong value; 18. uchar u8_bits[sizeof(ulong)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Code 05
Wenn Sie jedoch versuchen, Code 05 zu kompilieren, gibt der Compiler eine Warnung aus. Diese Warnung ist in der Abbildung unten zu sehen.

Abbildung 05
Denken Sie jetzt mit mir nach. Sie sehen diese Warnung, die besagt, dass der Wert in Zeile 32 nicht mit dem zurückgegebenen Wert kompatibel ist, da sie von unterschiedlichem Typ sind. Wo haben Sie das schon einmal gesehen? Wenn Sie im selben Artikel ein Stück zurückgehen, sehen Sie etwas Ähnliches in Abbildung 02. Auf dieser Grundlage verfügen Sie bereits über die Mittel, um genau dieses Problem zu lösen. Sie können in beide Richtungen gehen. Wie Sie jedoch im vorigen Thread bemerkt haben sollten, ist die beste Methode, die uns zwingt, weniger Änderungen am Code vorzunehmen, diejenige, die eine Variable eines falschen Typs in den erwarteten Typ als Rückgabe umwandelt. Mit anderen Worten, ändern Sie NICHT die Zeile 32, sondern die Zeile 15, in der die Union der Werte deklariert wird.
Warum sage ich wohl nicht, dass wir Zeile 17 ändern sollten? Schließlich befindet sich dort die Variable, die in Zeile 32 verwendet wird, um den Wert zurückzugeben. Der Grund dafür ist, dass wir nicht nur Zeile 17, sondern auch das Array in Zeile 18 ändern wollen. Und wenn wir nur Zeile 17 ändern, beheben wir nur einen Teil des Problems. Das Problem besteht jedoch darin, dass wir uns von einem Ort zum anderen bewegen, da wir die Breite der Union nicht verändern werden. Deshalb ist es wichtig, genau darauf zu achten, was programmiert wird. Wenn wir die nötige Sorgfalt walten lassen, wird es keine Probleme geben, und unser Code wird nützlicher und deckt mehr Fälle mit viel weniger Risiko und Aufwand ab.
Nachdem wir nun die notwendigen Schritte überprüft haben, können wir den Code 05 wie unten gezeigt ändern.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const ushort info = 0xCADA; 07. 08. PrintFormat("Before modification: 0x%I64X", info); 09. PrintFormat("After modification : 0x%I64X", Swap(info)); 10. } 11. //+------------------------------------------------------------------+ 12. template <typename T> 13. T Swap(T arg) 14. { 15. union un_01 16. { 17. T value; 18. uchar u8_bits[sizeof(T)]; 19. }info; 20. 21. info.value = arg; 22. 23. PrintFormat("The region is composed of %d bytes", sizeof(info)); 24. 25. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 26. { 27. tmp = info.u8_bits[i]; 28. info.u8_bits[i] = info.u8_bits[j]; 29. info.u8_bits[j] = tmp; 30. } 31. 32. return info.value; 33. } 34. //+------------------------------------------------------------------+
Code 06
Durch die Ausführung von Code 06, der nur eine Abwandlung von Code 05 ist, erhalten wir das in der folgenden Abbildung gezeigte Ergebnis.
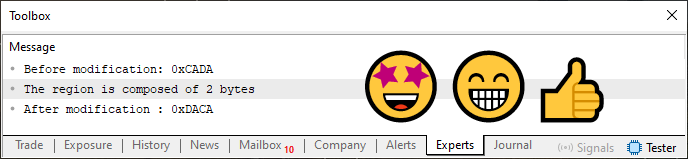
Abbildung 06
Einfach perfekt. Jetzt haben wir die richtige Antwort. Außerdem haben wir den Code 04 in einen viel fortschrittlicheren Code umgewandelt. Da der Compiler nun überladene Funktionen oder Prozeduren für uns erstellen und generieren kann, können wir ohne Bedenken beliebige Datentypen verwenden. Auf der Grundlage der Codevorlage 06 erstellt der Compiler geeignete Prozeduren für die korrekte Ausführung der Routine, die stets die erwarteten Ergebnisse liefert.
Da wir bereits ein viel interessanteres Modell geschaffen haben, könnte man meinen: „Das war's dann wohl. Jetzt weiß ich, wie man Templates für Unions erstellt“. Richtig, Sie wissen bereits, wie Sie dies in einem sehr einfachen Fall tun können. Jedoch ist das, was wir hier gezeigt haben, Kein Template EINER UNION. Es geht nur um die Eignung der Union für die Verwendung des Templates in einer Funktion oder Prozedur. Um das zu erreichen, was ein Template für Unions werden würde, ist die Frage, wie einige sagen, ein wenig tiefer. Aber um die Fragen richtig zu trennen, werden wir uns in einem anderen, neuen Thema damit beschäftigen, wie man das macht. Es besteht also keine Gefahr, das eine mit dem anderen zu verwechseln.
Definition des Templates für Unions
Lassen Sie uns nun etwas tiefer in die Materie einsteigen, wie man mit Templates arbeitet. Im Gegensatz zu dem, was wir bisher gesehen haben, wollen wir bei der Definition eines Templates für die Union, wie auch für andere Typen, die wir später besprechen werden, einige Entscheidungen treffen, die für Programmieranfänger von Bedeutung sind, nämlich wie der Code implementiert werden soll. Das liegt daran, dass ein Teil des Codes, den wir erstellen werden, zum Beispiel exotisch aussehen kann.
Wenn Sie den Eindruck haben, dass der Code zu kompliziert wird, beruhigen Sie sich bitte und treten Sie einen Schritt zurück. Idealerweise sollten wir uns bemühen, das bisher Gezeigte zu studieren und zu praktizieren, bis wir ein richtiges Verständnis der Prinzipien und Konzepte erlangen. Erst dann gehen Sie zurück und beginnen an der Stelle, an der Sie vor der Pause aufgehört haben.
Versuchen Sie nicht, sich selbst zu übertreffen, und glauben Sie nicht, dass Sie etwas herausgefunden haben, nur weil Sie einen Code gesehen haben, der eine bestimmte Ressource verwendet, denn nicht alles funktioniert so, wie es sollte. Wenn Sie dieses Konzept richtig verstehen, wird alles viel einfacher und klarer werden.
Was wir jetzt tun werden, ist eigentlich ziemlich verwirrend für ein so frühes Stadium. Wir werden im nächsten Artikel über die Verwirrung sprechen. Auf jeden Fall ist es notwendig, das zu tun, was hier gezeigt wird, und Sie müssen verstehen, was passiert, wenn Sie auf so etwas stoßen oder wenn Sie etwas auf die gezeigte Weise umsetzen müssen.
Wie üblich werden wir mit einer einfachen Sache beginnen. Unser Ziel ist etwas Ähnliches wie der im vorherigen Abschnitt vorgestellte Code 06. Jedoch VERWENDEN WIR KEINE FUNKTION ODER PROZESSE. Wir werden später darüber sprechen, denn es ist etwas schwieriger zu verstehen. Daher werden wir in diesem Stadium alles in der OnStart-Funktion erledigen. Lassen Sie uns loslegen! Zunächst wird der Code unten angegeben.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }; 19. 20. { 21. un_01 info; 22. 23. info.value = 0xA1B2C3D4E5F6789A; 24. PrintFormat("The region is composed of %d bytes", sizeof(info)); 25. PrintFormat("Before modification: 0x%I64X", info.value); 26. macro_Swap(info); 27. PrintFormat("After modification : 0x%I64X", info.value); 28. } 29. 30. { 31. un_01 info; 32. 33. info.value = 0xCADA; 34. PrintFormat("The region is composed of %d bytes", sizeof(info)); 35. PrintFormat("Before modification: 0x%I64X", info.value); 36. macro_Swap(info); 37. PrintFormat("After modification : 0x%I64X", info.value); 38. } 39. } 40. //+------------------------------------------------------------------+
Code 07
Wenn wir Code 07 ausführen, erhalten wir ein Ergebnis, das dem von Code 04 sehr ähnlich ist. Hier geben wir jedoch zwei Werte gleichzeitig ein, um alles auf einmal anzuzeigen. Das tatsächliche Ergebnis der Ausführung von Code 07 ist also das, was wir gerade unten sehen.
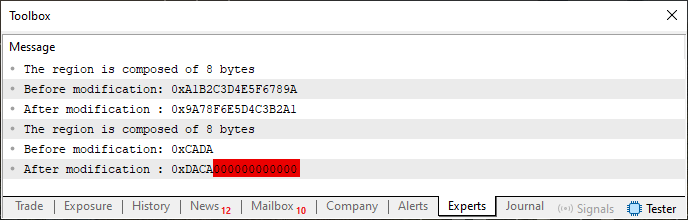
Abbildung 07
Genau wie in Abbildung 04, wo unpassende Werte in das Endergebnis eingeflossen sind, sehen wir in Abbildung 07, dass die gleichen Werte wieder auftauchen. Um es ein wenig zu vereinfachen: Wir haben einen Wert, der eine Kurzvariable sein könnte, der aber durch andere falsche Werte behindert wird. Ich weiß, dass dieser Code auf den ersten Blick korrekt erscheinen mag, und er mag sogar korrekt sein, je nachdem, was darin implementiert ist. Diese Studie soll jedoch dazu beitragen, ein Template zu erstellen, die es ermöglicht, die Dinge so zu nutzen, dass ein ähnliches Ergebnis wie im vorangegangenen Abschnitt erzielt wird.
Allerdings ohne Verwendung von Funktionen oder Prozeduren. Bitte beachten Sie noch einen weiteren Punkt: Um die Verwendung einer Funktion oder Prozedur in diesem Stadium zu vermeiden, übergeben wir den allgemeinen Teil des Codes an ein Makro. Sie können es ab Zeile 07 und darüber hinaus sehen. Da die Funktionsweise von Makros bereits beschrieben wurde, werde ich nicht näher darauf eingehen, da ich in diesem speziellen Fall keine Notwendigkeit dafür sehe.
Gut, kommen wir zum Hauptthema. Im Gegensatz zum vorherigen Thema haben wir es hier mit einer anderen Art von Situation zu tun, aber mit einem ähnlichen Ziel. Bitte beachten Sie, dass das Konzept, das vorher angewendet werden konnte, nicht mehr angewendet werden kann. Dies geschieht, weil wir in Code 07 keine Funktion oder Prozedur haben, auf die das Template angewendet werden kann. Das Grundkonzept, das hier angewandt wird, ist jedoch dem bereits angewandten sehr ähnlich, nur ist es anfangs etwas verwirrend.
Seien Sie vorsichtig, mein lieber Leser. Unser Ziel ist es, einen Code zu schaffen, der mit jeder Art von Daten arbeiten kann, so wie wir es bei der Entwicklung des späteren Codes 06 getan haben. Um dieses Ziel zu erreichen, müssen wir jedoch auf eine etwas andere Art der Überlastung zurückgreifen. Bislang wurde das Überladen auf Funktionen oder Prozeduren angewandt. Aber jetzt brauchen wir eine Typüberladung. Dies mag etwas verwirrend erscheinen, aber das Grundkonzept ist dasselbe wie bei der Verwendung von Überladungen für Funktionen oder Prozeduren.
Dann beachten Sie Folgendes: Die in Zeile 14 von Code 07 deklarierte Union muss genauso funktionieren wie die in Code 06 verfügbare Union. Aber wie können wir das tun? Es ist ganz einfach. Es genügt zu sagen, dass die Union von Zeile 14 ein Template ist. „Das verstehe ich nicht. Wie sollen wir das machen?“ Nun, wie ich schon sagte, kann es etwas verwirrend sein, wenn man diese Art von Simulation zum ersten Mal kennenlernt. Zunächst einmal ist der Link in Zeile 14 ein lokaler Link. Und jedes Template MUSS GLOBAL sein. Daher muss diese Erklärung als erstes aus der Prozedur OnStart entfernt werden. Wir hingegen wandeln die Erklärung in ein globales Modell um. Dann wollen wir nur noch das hinzufügen, was wir bereits gewohnt sind, nämlich die Umwandlung der Union in ein Template, wie es bei einer Funktion oder Prozedur der Fall ist. Daraus ergibt sich die nachstehende Darstellung von Code 08.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
Code 08
Bisher war alles sehr leicht und einfach, weil wir uns genau mit dem beschäftigen, was wir bereits tun können. Doch genau hier beginnen die Schwierigkeiten: Wenn Sie versuchen, Code 08 zu kompilieren, werden Sie scheitern. Der Grund dafür ist, dass der Code aus Sicht des Compilers eine Art von Fehler enthält, der für Anfänger schwer zu verstehen ist. Im Folgenden wird gezeigt, welche Art von Informationen der Compiler liefert, wenn wir versuchen, diesen Code zu kompilieren.
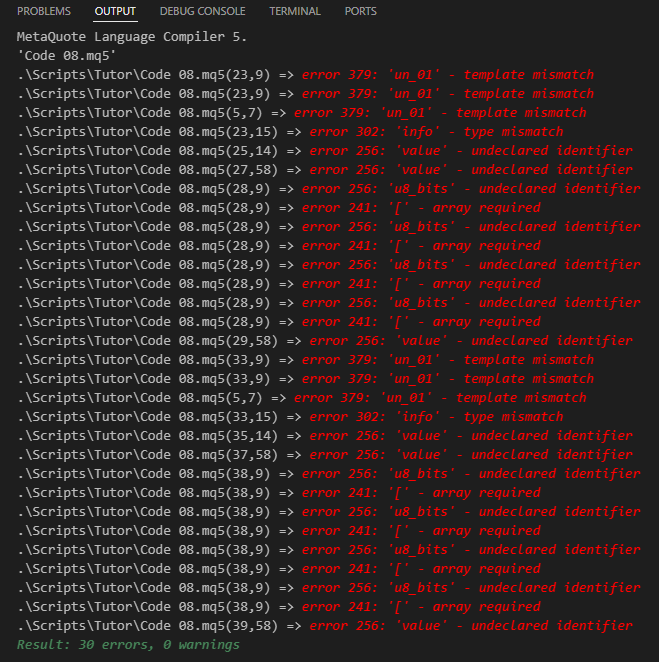
Abbildung 08
Es scheint, dass wir nicht auf dem richtigen Weg sind, denn diese Anzahl von Fehlern ist etwas entmutigend. Doch genau hier liegt das Problem, das viele Anfänger wirklich verwirrt. Denn alle diese Fehler, die in Abbildung 08 zu sehen sind, treten auf, weil der Compiler NICHT WEISS, welcher Datentyp zu verwenden ist. Da ich in diesem Artikel bereits viele Erklärungen zu verschiedenen Themen gegeben habe und Sie nicht mit der Lösung dieses Problems verwirren möchte, mache ich eine Pause und überlasse diese Frage der Erklärung im nächsten Artikel.
Abschließende Überlegungen
In diesem Artikel haben wir begonnen, ein sehr schwieriges Thema zu erforschen, es sei denn, Sie praktizieren, was Ihnen gezeigt wird. Da ich jedoch möchte, dass Sie richtig lernen, habe ich beschlossen, das letzte Thema dieses Artikels zu unterbrechen. Eine richtige Erklärung, wie man dem Compiler sagt, was er tun soll, braucht Zeit, und ich möchte ein Thema, das schon kompliziert genug ist, nicht noch weiter verwirren.
Versuchen Sie daher, das in diesem Artikel Gezeigte in die Praxis umzusetzen. Versuchen Sie jedoch herauszufinden, wie Sie dem Compiler mitteilen können, welche Daten verwendet werden sollen, damit der am Ende dieses Artikels bereitgestellte Code 08 tatsächlich funktioniert. Denken Sie in Ruhe darüber nach, denn im nächsten Artikel werden wir sehen, wie Sie es tatsächlich tun und wie Sie es zu Ihrem Vorteil nutzen können.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15669
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
un_01 <ulong> info;