
Von der Grundstufe bis zur Mittelstufe: Template und Typename (IV)

Einführung
Die hier zur Verfügung gestellten Materialien sind ausschließlich für Bildungszwecke bestimmt. Sie sollte in keiner Weise als endgültige Bewerbung angesehen werden. Es geht nicht darum, die vorgestellten Konzepte zu erforschen.
Im vorherigen Artikel: „Von der Grundstufe zur Mittelstufe: Template und Typenname (III)“ haben wir ein Thema aufgegriffen, das für viele Neulinge eine besondere Herausforderung darstellt. Das liegt daran, dass viele Menschen ein Konzept nicht verstanden haben, das für MQL5-Programmierer sehr wichtig ist: das Konzept des Templates. Da ich weiß, dass viele Leser nur sehr wenig über das Programmieren wissen, versuche ich, das Material so didaktisch wie möglich zu gestalten.
Deshalb haben wir den vorherigen Artikel ziemlich abrupt beendet, er endete mit einem Bild eines Fehlers und einem Code, der keine ausführbare Datei erzeugte. Ich weiß, dass viele Menschen enttäuscht sein könnten, wenn sie so etwas in einem Artikel lesen. Ich habe jedoch gerade erst damit begonnen, Sie in ein Thema einzuführen, das sich beim ersten Kennenlernen als recht schwierig erweist: das Thema der Typüberladung. Tatsächlich handelt es sich nicht um eine Typüberladung, sondern um ein Template-Typ, der es dem Compiler ermöglicht, für jede zu bewältigende Situation den richtigen Typ zu erzeugen.
Da im Prinzip jeder Code, der in einem Artikel bereitgestellt wird, funktionieren sollte, haben wir in der Erklärung eine kleine Einschränkung gemacht. Aber ich versuche es zu erklären, damit Sie verstehen, dass der Code nicht immer funktioniert, wenn wir ihn implementieren. Ich kenne viele Leute, die lernen wollen, wie sie Probleme in ihrem Code lösen können. Die große Mehrheit von ihnen kann jedoch Probleme nicht lösen, weil sie nicht die richtigen Vorstellungen von dieser Ressource oder dieser Programmiersprache haben. Und ohne diese ist es schwierig zu erklären, wie man bestimmte Arten von Aufgaben löst, die für professionelle Programmierer eine Kleinigkeit, für einen Anfänger aber ein großes Problem sind.
Bisher haben wir uns mit dem Überladen von Funktionen und Prozeduren mit Hilfe eines Templates befasst, aber bei der Anwendung auf andere Anwendungstypen werden die Dinge etwas komplizierter, wie am Ende des vorherigen Artikels gezeigt wurde. Lassen Sie uns also ein neues Thema beginnen.
Verwendung eines Template-Typs
Das anzuwendende Konzept ist in der Tat einfach. Es ist jedoch recht schwierig, sie so zu visualisieren, dass das Konzept korrekt umgesetzt werden kann. Beginnen wir mit dem, was wir bereits im vorherigen Artikel gesehen haben. Zuvor sollten wir uns jedoch mit dem Quellcode befassen, der funktioniert und kompiliert werden kann. Er ist gleich hier:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. union un_01 15. { 16. ulong value; 17. uchar u8_bits[sizeof(ulong)]; 18. }; 19. 20. { 21. un_01 info; 22. 23. info.value = 0xA1B2C3D4E5F6789A; 24. PrintFormat("The region is composed of %d bytes", sizeof(info)); 25. PrintFormat("Before modification: 0x%I64X", info.value); 26. macro_Swap(info); 27. PrintFormat("After modification : 0x%I64X", info.value); 28. } 29. 30. { 31. un_01 info; 32. 33. info.value = 0xCADA; 34. PrintFormat("The region is composed of %d bytes", sizeof(info)); 35. PrintFormat("Before modification: 0x%I64X", info.value); 36. macro_Swap(info); 37. PrintFormat("After modification : 0x%I64X", info.value); 38. } 39. } 40. //+------------------------------------------------------------------+
Code 01
Wenn Code 01 kompiliert und in MetaTrader 5 ausgeführt wird, erhält man die folgenden Ergebnisse.
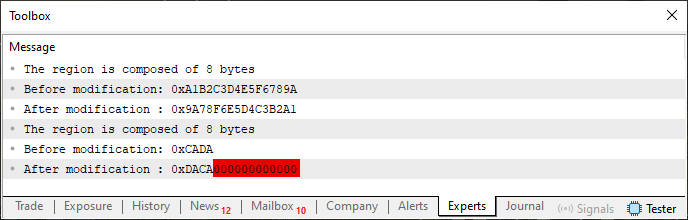
Bild 01
Offensichtlich ist dieses Ergebnis nicht ganz korrekt. Dies ist mit dem hervorgehobenen Bereich 01 in diesem Bild verbunden. Je nach Anwendungsfall kann dieses Ergebnis jedoch richtig sein. Aber das ist nicht das, was wir wollen. Der in Zeile 33 angegebene Wert soll zwei Bytes breit sein. Aber gerade weil die „union“ acht Bytes breit ist, sind wir gezwungen, diese Art von Deklaration zu verwenden, was das Endergebnis völlig unzureichend macht, wie Sie in Abbildung 01 sehen können.
Im vorigen Artikel haben wir den Template-Typ jedoch bereits direkt erstellt. Selbst wenn der Code, den Sie dort gesehen haben, nicht falsch war, aber etwas fehlte, ist es schwer zu erklären, warum alles genau so ausgeführt werden sollte, wie wir es tun werden. Damit möchte ich diesen Artikel abschließen und Ihnen Gelegenheit geben, in Ruhe über dieses Thema nachzudenken und es zu erkunden. Das Ziel ist es, zu verstehen, warum der Code nicht funktioniert. Und hier werden wir herausfinden, wie man sich richtig verhält und warum der Code auf eine ganz bestimmte Weise implementiert werden sollte, damit der Compiler versteht, was zu tun ist.
Der nächste logische Schritt wäre, Code 01 durch einen etwas anderen Code zu ersetzen. Dies geschieht, bevor wir das erreichen, was im vorherigen Artikel gezeigt wurde. Daraus ergibt sich der folgende Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. //+----------------+ 07. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 08. { \ 09. tmp = X.u8_bits[i]; \ 10. X.u8_bits[i] = X.u8_bits[j]; \ 11. X.u8_bits[j] = tmp; \ 12. } 13. //+----------------+ 14. 15. { 16. union un_01 17. { 18. ulong value; 19. uchar u8_bits[sizeof(ulong)]; 20. }; 21. 22. un_01 info; 23. 24. info.value = 0xA1B2C3D4E5F6789A; 25. PrintFormat("The region is composed of %d bytes", sizeof(info)); 26. PrintFormat("Before modification: 0x%I64X", info.value); 27. macro_Swap(info); 28. PrintFormat("After modification : 0x%I64X", info.value); 29. } 30. 31. { 32. union un_01 33. { 34. ushort value; 35. uchar u8_bits[sizeof(ushort)]; 36. }; 37. 38. un_01 info; 39. 40. info.value = 0xCADA; 41. PrintFormat("The region is composed of %d bytes", sizeof(info)); 42. PrintFormat("Before modification: 0x%I64X", info.value); 43. macro_Swap(info); 44. PrintFormat("After modification : 0x%I64X", info.value); 45. } 46. } 47. //+------------------------------------------------------------------+
Code 02
Wenn wir den Code 02 ausführen, sieht das Endergebnis so aus, wie wir es in der folgenden Abbildung sehen.
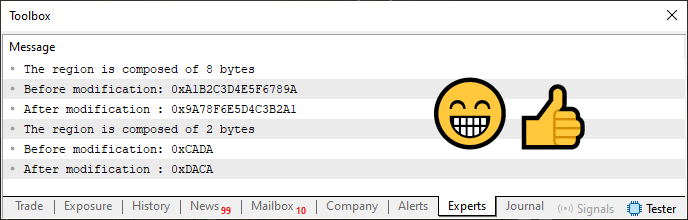
Bild 02
Bitte beachten Sie, dass wir mit diesem Bild 02 genau das erreicht haben, was wir erreichen wollten. Das heißt, wir haben jetzt einen Typwert, der angezeigt wird und acht Bytes benötigt. Und ein weiterer Wert, der ebenfalls angezeigt wird und wie erwartet zwei Bytes benötigt. Aber sehen Sie sich an, wie es gemacht wurde. Selbst wenn es funktioniert, überfordern wir uns mit der Erstellung von Code und den entsprechenden Änderungen. Dies erhöht die Fehlerwahrscheinlichkeit, wenn der Code wächst und komplexer wird, da wir immer mehr neue Elemente hinzufügen müssen.
Wie Sie sehen können, machen wir etwas sehr Einfaches, aber der Code wird langsam etwas verwirrend. An diesem Punkt kommt die Idee auf, Typ-Templates zu verwenden. Der Grund dafür ist, dass der einzige Unterschied zwischen dem Codeblock zwischen den Zeilen 15 und 29 und dem Codeblock zwischen den Zeilen 31 und 45 in dem Typ besteht, der innerhalb der „union“ definiert ist. Sie können es in den Zeilen 18 und 34 von Code 02 sehen.
Daher haben wir mit der Erstellung eines Templates begonnen, deren Hauptzweck darin besteht, denselben Code 02 zu vereinfachen, da die auszuführende „union“ darin überladen ist. Die Anwendung des vorgestellten Konzepts dient also der Erstellung eines Templates für eine Funktion oder Prozedur, die in diesem Fall überladen werden kann. Als Ergebnis erhalten wir einen solchen Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
Code 03
Hier beginnt die Verwirrung. Und das hat mit Folgendem zu tun: Code 03 versucht, das zu erzeugen, was in Code 02 gezeigt wird, aber mit etwas, das dem in Code 01 gezeigten sehr ähnlich ist. Beim Kompilieren von Code 03 gibt der Compiler jedoch die folgende Fehlermeldung aus.
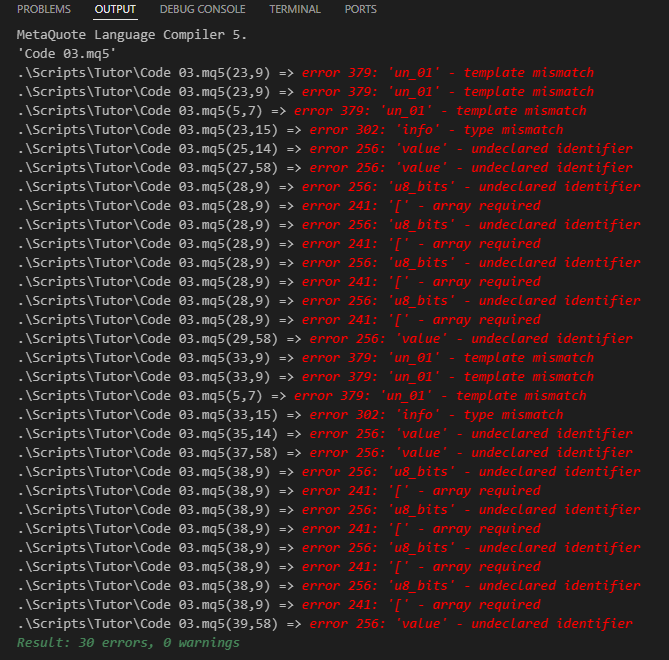
Bild 03
Hier stimmt definitiv etwas nicht, aber auf den ersten Blick ergibt es keinen Sinn. Denn auf den ersten Blick deklarieren wir das Template korrekt. Was ist also an Code 03 falsch, dass er nicht kompiliert werden kann? Wenn es sich nicht kompilieren lässt, dann versteht der Compiler nicht, was zu tun ist.
Nun, ich weiß, dass viele Leute immer versuchen, die Probleme zu lösen, die der Compiler meldet und auf die er uns hinweist. Dies ist von entscheidender Bedeutung. Aber in diesem Fall zeigen die vom Compiler ausgegebenen Meldungen, die in Abbildung 03 zu sehen sind, nicht an, wo das Problem liegt.
Es gibt jedoch ein Konzept, das wir in den ersten Artikeln über Variablen und Konstanten erläutert haben. Dieses Konzept ist jetzt sehr wichtig, damit wir wissen, wie wir uns in solchen Situationen verhalten sollen. Wie Sie sehen können, deklarieren wir in Zeile 07 von Code 03 eine Variable, richtig? Ich frage nur: Welche Variable deklarieren wir in Zeile 07? Das ist der springende Punkt. Wenn weder ich noch ein anderer Programmierer das weiß, wie soll dann der Compiler davon erfahren?
Nun, Sie können mir antworten: „In Zeile 25 geben wir an, dass wir einen Typ mit einer Breite von acht Bytes wollen, und in Zeile 35 zwei Bytes.“ Richtig. Dies sagt dem Compiler jedoch nicht, welcher Typ von Variable zu verwenden ist. Bitte beachten Sie, dass wir in den Zeilen 25 und 35 die VARIABLE NICHT DEKLARIEREN. Wir weisen ihr einen Wert zu. Diese Erklärung ist in den Zeilen 23 und 33 enthalten. Verstehen Sie jetzt das Problem?
Aber es gibt noch ein anderes, noch schwerwiegenderes Problem, das zu all den Fehlermeldungen führt, die in Abbildung 03 zu sehen sind. Denn obwohl die Deklaration in den Zeilen 23 und 33 erscheint, deklariert sie etwas, das dem Compiler unbekannt ist, nämlich den Typ der Variablen in Zeile 07. Beachten Sie, dass sich die Zeilen 23 und 33 auf den in Zeile 05 deklarierten Typ beziehen. Mit anderen Worten: eine „union“.
Diese „union“ ist jedoch ein Muster. Daher wird der zu verwendende Datentyp vom Compiler bestimmt. Da er nicht weiß, welchen Datentyp es verwenden soll, werden alle diese Fehlermeldungen angezeigt. Aber jetzt gibt es ein Konzept, das akzeptiert werden sollte. Wenn Sie wissen, wie das Template in Funktionen und Prozeduren verwendet wird, wissen Sie wahrscheinlich, dass an einem bestimmten Punkt eine Variable deklariert wird. Wenn eine Funktion oder Prozedur überladen wird, kennt der Compiler bereits den Datentyp, sodass er die entsprechende Prozedur erstellen kann.
Da Sie dies wissen, fragen Sie sich vielleicht: Wie weise ich den Compiler darauf hin, welchen Datentyp er verwenden soll? In der Regel wird ein Datentyp gefolgt von einem Variablennamen verwendet. Und da wir dies in den Zeilen 23 und 33 von Code 03 tun, habe ich keine Ahnung, wie ich dieses Problem lösen soll. Wenn Sie diesen Punkt erreicht und all diese Konzepte verstanden haben, ist es an der Zeit zu sehen, wie Sie das Problem lösen können, um Templates zu verwenden und verschiedene Typen zu überladen. Zu diesem Zweck verwendet MQL5 eine spezielle Deklaration von Variablen, die lokal oder global sein können und die es bereits in den Sprachen C und C++ gibt. Aber denken Sie daran: Das Wichtigste ist, das Konzept zu verstehen, und nicht nur, sich daran zu erinnern, wie man es macht. Die Lösung finden Sie weiter unten.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. //+----------------+ 14. #define macro_Swap(X) for (uchar i = 0, j = sizeof(X) - 1, tmp; i < j; i++, j--) \ 15. { \ 16. tmp = X.u8_bits[i]; \ 17. X.u8_bits[i] = X.u8_bits[j]; \ 18. X.u8_bits[j] = tmp; \ 19. } 20. //+----------------+ 21. 22. { 23. un_01 <ulong> info; 24. 25. info.value = 0xA1B2C3D4E5F6789A; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. macro_Swap(info); 29. PrintFormat("After modification : 0x%I64X", info.value); 30. } 31. 32. { 33. un_01 <ushort> info; 34. 35. info.value = 0xCADA; 36. PrintFormat("The region is composed of %d bytes", sizeof(info)); 37. PrintFormat("Before modification: 0x%I64X", info.value); 38. macro_Swap(info); 39. PrintFormat("After modification : 0x%I64X", info.value); 40. } 41. } 42. //+------------------------------------------------------------------+
Code 04
Schauen Sie sich an, was wir im Moment tun, denn es handelt sich um eine sehr subtile Veränderung. Wenn wir jedoch versuchen, den Code 04 zu kompilieren, sehen wir Folgendes.
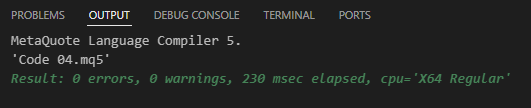
Bild 04
Das heißt, etwas scheinbar Unbedeutendes, das im Moment nicht viel Sinn macht, ermöglicht die Kompilierung des Codes. Das Ergebnis der Ausführung von Code 04 ist in der folgenden Abbildung zu sehen.
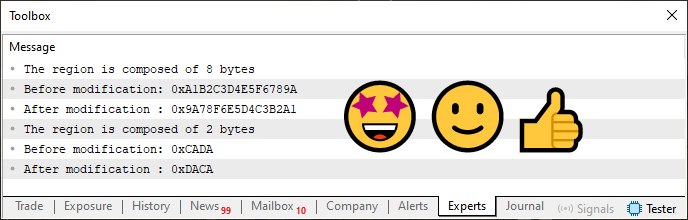
Bild 05
Was für eine schöne und erstaunliche Sache, nicht wahr? Aber was ist hier passiert, warum funktioniert Code 04, aber Code 03 nicht, und warum machen wir diese seltsame Erklärung in den Zeilen 23 und 33? „Jetzt bin ich völlig ratlos. Und verblüfft. Denn ich verstehe absolut nicht, was hier vor sich geht.“
Okay, sehen wir uns an, was hier passiert ist und warum die Erklärung so abgegeben werden muss, wie sie in den Zeilen 23 und 33 abgegeben wird. Dies ist also unser vierter Artikel über Templates und Typename. Im zweiten Artikel haben wir erörtert, wie man den Compiler zwingen kann, einen bestimmten Datentyp zu verwenden, sodass der Typ dem Parameter entspricht, den die Funktion oder Prozedur erhält. In diesem Fall erfolgt die Typkonvertierung während der Wertzuweisung. Dazu haben wir eine explizite Typkonvertierung verwendet, indem wir den Zieltyp in Klammern eingeschlossen haben. Dies geschieht sehr oft zu verschiedenen Zeiten, wie Sie vielleicht schon bei anderen Codes festgestellt haben. Es ist jedoch eine Sache, einer bereits deklarierten Variablen einen Wert zuzuweisen, und eine andere Sache, einer noch nicht deklarierten Variablen einen Typ zuzuweisen.
Da der Zweck von Templates darin besteht, ein Modell einer Funktion, einer Prozedur oder eines Datentyps zu erstellen, das wir in Zukunft verwenden können, werden sie von einer Deklaration von Typenames begleitet. Und genau das ist die Frage. Wie in früheren Artikeln erläutert, ist der Buchstabe T, der die Typename-Deklaration begleitet, eigentlich eine Kennzeichnung für die Definition von etwas Späterem. Wenn der Compiler also T ersetzt, erhalten wir die Typdefinition, die wir verwenden müssen. Und der Compiler wird den Code korrekt erstellen können. Wenn wir also in den Deklarationen in den Zeilen 23 und 33 den Typ so deklarieren, wie wir es tun, teilen wir dem Compiler mit, welchen Datentyp er anstelle des T, das die Typename-Deklaration begleitet, verwenden soll.
Da wir noch nicht im Detail besprochen haben, wie diese Erklärung zu verwenden ist, kann es eine Weile dauern, bis Sie sie verstehen. Aber wie Sie sehen können, funktioniert es. Daher sollte die Erklärung auf diese Weise gestaltet werden.
Wenn Sie das interessant fanden, dann wird Ihnen der nächste Schritt gefallen, denn jetzt werden wir das Makro von Code 04 in eine Funktion oder Prozedur umwandeln. Ziel ist es, dass Code 04 weiterhin funktioniert und das in Abbildung 05 gezeigte Ergebnis erzielt wird. Da dies jedoch die Anwendung des heutigen Materials in einer fortgeschritteneren Form voraussetzt, werden wir dieses Thema gesondert behandeln.
Warum kompliziert, wenn man es vereinfachen kann?
Viele von Ihnen mögen denken, dass unser Handeln hier unlogisch ist, dass dieses Material zu fortgeschritten ist und dass wir nicht lernen müssen, wie es geht. In der Tat muss ich dieser Aussage zustimmen. Wenn Sie nur wissen, wie man Funktionen und Prozeduren erstellt, Variablen deklariert und einige grundlegende Anweisungen verwendet, können Sie fast alles erstellen. Je mehr Werkzeuge und Ressourcen uns zur Verfügung stehen, desto einfacher ist es, sie umzusetzen und zu entwickeln. Mit einem einzigen Nagel können Sie sogar einen Getreidespeicheraufzug bauen. Dies ist bereits geschehen. Aber es wäre viel einfacher, wenn wir mehr Ressourcen als „Nägel“ verwenden könnten.
Hier und jetzt werden wir eine Funktion erstellen, die das in Zeile 14 von Code 04 definierte Makro ersetzen wird. Das wird sehr interessant werden. Doch zunächst muss ich Sie alle daran erinnern, dass unser Ziel darin besteht, zu lernen. Bevor wir versuchen zu verstehen, was wir hier tun, ist es notwendig zu verstehen, was im vorherigen Thema getan wurde. Nur dann wird alles einen Sinn haben.
Weiter weg. Beginnen wir mit der ursprünglichen Idee. Das heißt, Sie entfernen das Makro aus Code 04 und versuchen, es in eine Funktion zu verwandeln. Aber bevor wir das tun, sollten wir ein Verfahren entwickeln, das meiner Meinung nach leichter zu verstehen ist. Dann können Sie den folgenden Code erstellen, wie unten gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. void Swap(un_01 &arg) 35. { 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. arg.u8_bits[i] = arg.u8_bits[j]; 40. arg.u8_bits[j] = tmp; 41. } 42. } 43. //+------------------------------------------------------------------+
Code 05
Wenn wir versuchen, Code 05 zu kompilieren, erscheint zu unserer Überraschung und Enttäuschung das folgende Ergebnis auf dem Bildschirm. Siehe unten.
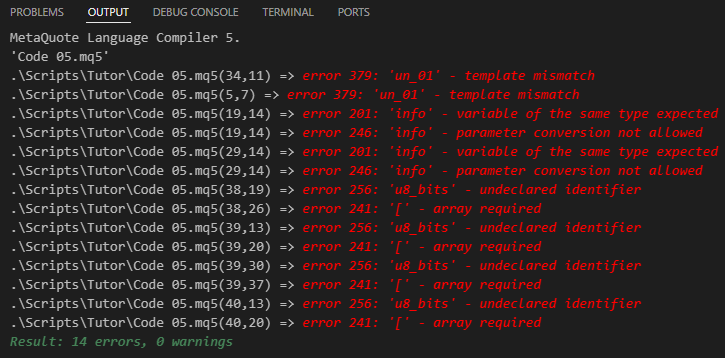
Bild 06
Schon wieder? Das ist nicht mehr lustig. Beruhigen Sie sich, es gibt keinen Grund zur Panik oder Verzweiflung. Bis jetzt. Das Problem ähnelt sehr dem, das im vorherigen Thema angesprochen wurde. Aber in diesem Fall ist die Lösung anders. Bitte beachten Sie Folgendes: In den Zeilen 19 und 29 wird die Prozedur in Zeile 34 aufgerufen. So weit, so gut. Das Problem ist, dass die Prozedur genau die Art von Daten erwartet, die in Zeile 05 definiert ist. Und da es sich bei diesem Typ um ein Template handelt, weiß der Compiler nicht, was er damit anfangen soll, da wir ihm nicht sagen können, welchen Datentyp er verwenden soll.
„Aber warte. Wie meinen Sie das? Wir deklarieren den Datentyp in den Zeilen 14 und 24.“ Ja, aber in diesen Zeilen 14 und 24 definieren wir lokal den zu verwendenden Datentyp. Dieser wird jedoch nicht an die Prozedur aus Zeile 34 übergeben, eben weil es sich um einen komplexen Typ handelt und nicht um einen primären, wie es in der Vergangenheit der Fall war, als alles so übergeben wurde, wie es ist. Da ist noch eine Kleinigkeit. Da der Datentyp das Überladen von Typen erlaubt, müssen wir bei der Übergabe innerhalb einer Funktion oder Prozedur sicherstellen, dass die Funktion oder Prozedur ebenfalls überladen werden kann. Deshalb habe ich gesagt, dass solche Momente interessant sind.
Das heißt, da das Argument in der OnStart-Prozedur überladen werden kann, muss die Funktion oder Prozedur, die denselben Datentyp erhält, ebenfalls überladen werden. So wird alles passen und der Compiler wird den Code verstehen können, um die gewünschte ausführbare Datei zu erstellen.
Sobald wir dies verstanden haben und wissen, wie man eine überladene Funktion erstellt, die ein Template verwendet, nehmen wir Code 05 und ändern ihn, um Code 06 zu erstellen, den wir gerade unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
Code 06
Großartig! Jetzt haben wir einen korrekten Code. Der Compiler wird endlich in der Lage sein, herauszufinden, was wir zu tun versuchen. Wir werden also den Compiler auffordern, eine ausführbare Datei zu erstellen, da die Überladung mit einem Template implementiert wurde, wie Sie in Code 06 sehen können. Doch leider sagt uns der Compiler, was wir unten sehen.
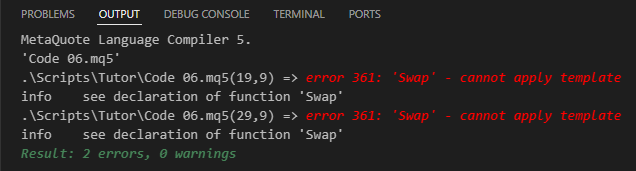
Bild 07
„Jetzt schikaniert uns dieses System definitiv. Sonst nichts. Es tut mir leid, aber ich verstehe nicht, warum das passiert ist“. Machen Sie sich keine Sorgen, liebe Leser. Wir tun etwas, das viele Menschen dazu zwingt, Codes jedes Mal auf die gleiche Art und Weise zu erstellen, wodurch Dinge, die viel einfacher und mit geringerer Fehlerwahrscheinlichkeit hätten erledigt werden können, zu etwas Monströsem werden und verschiedene Punkte wiederholt werden, die hätten verbessert werden können.
Die Erstellung eines Templates ist nicht gerade die einfachste Aufgabe. Daher ist es schwierig, Codes zu finden, die diese Art von Ressourcen verwenden. Dies zu verstehen, wird uns jedoch in vielen Punkten helfen, da es den Code aus der Sicht der Programmierung stark vereinfacht, da es alle Komplexitäten an den Compiler überträgt. Lassen Sie uns nun herausfinden, warum dieser Fehler auftritt. Am Anfang machen uns solche Dinge sehr zu schaffen. Ich versuche schon seit langem zu lernen, wie man das richtig macht, da ähnliche Elemente oft in C und C++ verwendet werden. Da MQL5 auf vielen Konzepten von C und C++ basiert, war das Erlernen von MQL5 so einfach wie das ABC, sobald ich gelernt hatte, wie man mit diesen Sprachen arbeitet. Fast wie ein Kinderspiel. Aber es war ziemlich schwierig, das zu lernen, was wir hier erläutern.
Seien Sie vorsichtig. Obwohl der Compiler meldet, dass der Fehler in den Zeilen 19 und 29 liegt, führt er uns an die falsche Stelle. Es ist nicht die Schuld des Compilers, es ist unsere. Lassen Sie mich erklären, warum. Erinnern Sie sich daran, dass es im vorherigen Thema notwendig war, Schritte zu unternehmen, damit der Compiler verstehen konnte, welche Daten wir verwenden? Wir haben eine Erklärung erstellt, die in Code 06 in den Zeilen 14 und 24 zu sehen ist.
Wenn dies in der OnStart-Prozedur korrekt geschieht, dann geschieht dies nicht in der Swap-Prozedur. Man könnte sogar denken, dass die Deklaration der Swap-Prozedur in dem Template korrekt ist, aber das ist nicht ganz richtig. Dies wurde in drei früheren Artikeln erörtert. Aber es ist schwer, hier einen Fehler zu erkennen. Wenn Sie nicht sehen können, wo der Fehler liegt, liegt das daran, dass Sie noch nicht herausgefunden haben, wie die Funktions- oder Prozedurvorlage mit Überladung umgeht.
Bitte beachten Sie, dass wir bei der Deklaration des Templates in Zeile 34 angeben, dass wir den Typ T verwenden werden, um eine Überladung zu erzeugen, richtig? Schauen Sie sich jetzt noch einmal Zeile 35 an. Welches Argument, das in diesem Fall das einzige ist, erhält diesen T-Typ? Es gibt kein Argument, das diesen T-Typ akzeptiert. Das heißt, obwohl die Erklärung besagt, dass wir ein Template erstellen, wird sie nicht tatsächlich verwendet. Kehren wir nun zu früheren Artikeln zurück und sehen wir uns an, wie die Erklärung zustande gekommen ist. Sie werden etwas Ähnliches sehen wie hier:
. . . 15. template <typename T> 16. T Averange(const T &arg[]) . . .
Codefragment 01
Beachten Sie in Codefragment 01 die folgende Tatsache: Der Typ T wird in Zeile 15 deklariert, aber gleich danach verwenden wir ihn in Zeile 16. Dies ist notwendig, damit das Argument den Typ verwenden kann, wenn der Compiler eine Funktion oder Prozedur erstellt. Wenn dies nicht geschieht, weiß der Compiler nicht, wie er weiter vorgehen soll. Das Gleiche passiert im Code 06: Wir haben eine Erklärung, aber wir verwenden sie nicht. Mit anderen Worten: Wir sagen dem Compiler nicht, wie er die Deklaration verwenden soll. Zu diesem Zweck sollten wir den Code 06 erneut ändern, damit der Compiler versteht, was wir tun wollen. Im Folgenden finden Sie den Code, der funktioniert.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 <T> &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
Code 07
Natürlich haben wir jetzt einen funktionierenden Code, der das gleiche Ergebnis wie in Abbildung 05 liefert. Aber ich frage Sie: Haben Sie herausgefunden, warum Code 07 funktioniert? Stellen Sie sich vor, dass Sie in einer Programmierprüfung aufgefordert werden, einen Code zu erstellen, der dasselbe Ergebnis liefert wie Code 07, der eine Funktion oder Prozedur verwendet.
Aber ohne ein Template zu verwenden, und notwendigerweise unter Verwendung der in Zeile 04 von Code 07 deklarierten „union“-Template. Wären Sie dazu in der Lage? Wären Sie in der Lage, dieses Problem zu lösen, um einen Job als Programmierer zu bekommen, oder würden Sie einfach sagen, dass es unmöglich ist? An einer Stelle haben wir erwähnt, dass eine Prozedur oder Funktion in diesem Fall ein Template verwenden muss, um generiert zu werden.
Es gibt Konzepte und Details, die die Dinge recht interessant machen. Zum Beispiel können wir Code 07 auf eine andere Art und Weise erstellen, um Überladungen direkt zu verwalten, ohne dafür ein Template zu verwenden. Da das Verständnis solcher Dinge einer angemessenen Erklärung bedarf, werden wir dieses Thema im nächsten Artikel behandeln.
Abschließende Überlegungen
In diesem Artikel haben wir besprochen, wie man Templates verwaltet und wie man sie allgemeiner und präziser erstellt. Da ich weiß, dass dieser Inhalt auf Anhieb sehr schwer zu verstehen ist, da ich ihn selbst durchgemacht habe, als ich zu Beginn meiner Programmierkarriere C und C++ studierte, bitte ich Sie um etwas Geduld. Ich empfehle Ihnen, das in diesen Artikeln Gezeigte zu üben und vor allem zu versuchen, die vorgestellten Konzepte zu verstehen. Wenn man sie versteht, kann man fast jeden Code erstellen, und zwar mit viel weniger Schwierigkeiten als diejenigen, die darauf bestehen, Codeschnipsel und Syntax einer Programmiersprache auswendig zu lernen. Üben Sie daher in Ruhe und studieren Sie den Inhalt der Bewerbung. Und wir sehen uns im nächsten Artikel wieder.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15670
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.